
A supervised learning algorithm is applied when one is very clear about the result that needs to be achieved from a problem, however one is unsure about the relationships between the data that affects the output. We would like the ML algorithm that we apply on the data to perceive these relationships between different data elements so as to achieve the desired output.
The concept can be better explained with an example—at a bank, prior to extending a loan, they would like to predict if a loan applicant would pay the loan back. In this case, the problem is very clear. If a loan is extended to a prospective customer X, there are two possibilities: that X would successfully repay the loan or X would not repay the loan. The bank would like to use ML to identify the category into which customer X falls; that is, a successful repayer of the loan or a repayment defaulter.
While the problem definition that is to be solved is clear, please note that the features of a customer that will contribute to successful loan repayment or non-repayment are not clear and this is something we would like the ML algorithm to learn by observing the patterns in the data.
The major challenge here is that we need to provide input data that represents both customers that repaid their loans successfully and also customers that failed to repay. The bank can simply look at the historical data to get the records of customers in both categories and then label each record as paid or unpaid categories as appropriate.
The records, thus labeled, now become input to a supervised learning algorithm so that it can learn the patterns of both categories of customers. The process of learning from the labeled data is called training and the output obtained (algorithm) from the learning process is called a model. Ideally, the bank would keep some part of the labeled data aside from training data so as to be able to test the model created, and this data is termed as test data. It should be no surprise that the labeled data that is used for training the model is called training data.
Once the model has been built, measurements are obtained by testing the model with test data to ensure the model yields a satisfactory level of performance, otherwise model-building iterations are carried out until the desired model performance is obtained. The model that achieved the desired performance on test data can be used by the bank to infer if any new loan applicant will be a future defaulter at all and, if so, make a better decision in terms of extending a loan to that applicant.
In a nutshell, supervised ML algorithms are employed when the objective is very clear and labeled data is available as input for the algorithm to learn the patterns from. The following diagram summarizes the supervised learning process:
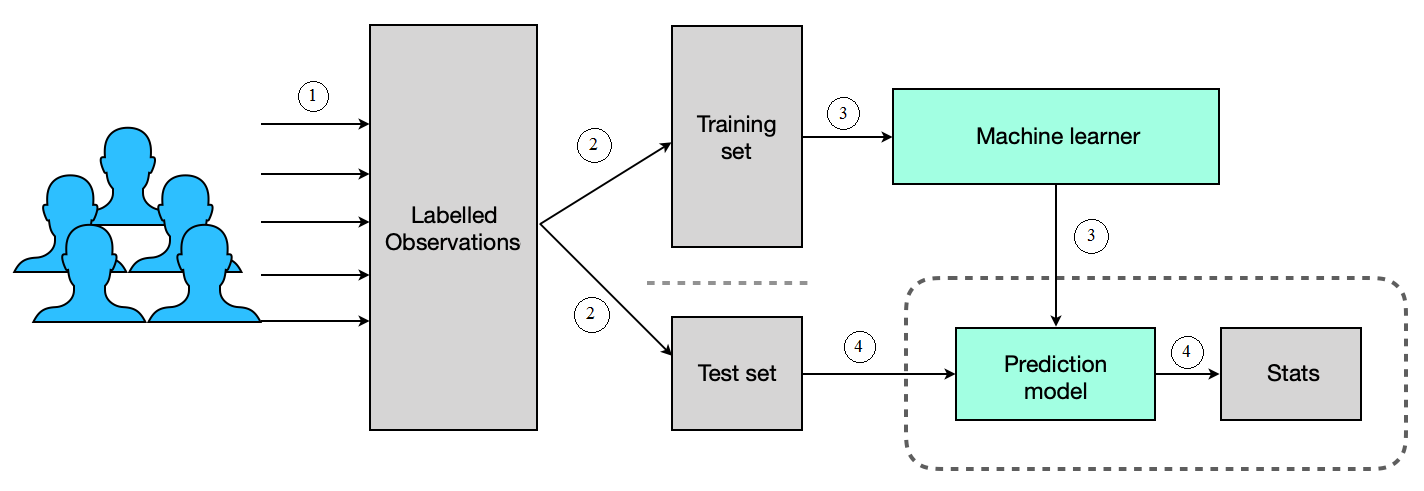
Supervised learning can be further divided into two categories, namely classification and regression. The prediction of a bank loan defaulter explained in this section is an example of classification and it aims to predict a label of a nominal type such as yes or no. On the other hand, it is also possible to predict numeric values (continuous values) and this type of prediction is called regression. An example of regression is predicting the monthly rental of a home in a prime location of a city based on features such as the demand for houses in the area, the number of bedrooms, the dimensions of the house, and accessibility to public transportation.
Several supervised learning algorithms exist, and a few popularly known algorithms in this area include classification and regression trees (CART), logistic regression, linear regression, Naive Bayes, neural networks, k-nearest neighbors (KNN), and support vector machine (SVM).