
Training the model is quite interesting, I believe. We will pass the model to the fit() function, having specified the features, response, number of epochs, and validation percentage at each epoch. Here, I have gone with 100 epochs, and 20% of the training data for validation:
> epochs <- 100
> # Fit the model and store training stats
> history <- model %>% fit(
trainT,
train_logy,
epochs = epochs,
validation_split = 0.2,
verbose = 0
)
You can examine the history object on your own, but what is very powerful is to plot the training and validation error for each epoch:
> plot(history, metrics = "mean_absolute_error", smooth = FALSE)
The output of the preceding code is as follows:

Notice how much the error differs between training and validation until we get above 80 epochs. This leads me to believe we should do well on the test data. Let's get our training baseline!
> min(history$metrics$mean_absolute_error)
[1] 0.248
To get the predicted values on the test data, just pipe the model to the predict() function:
> test_predictions <- model %>% predict(testT)
We now call up our metrics as we've done in other chapters. We should look at MAE obviously, but also the % error, and the R-squared:
> MLmetrics::MAE(test_predictions, test_logy)
[1] 0.162
> MLmetrics::MAPE(test_predictions, test_logy)
[1] 0.0133
> MLmetrics::R2_Score(test_predictions, test_logy)
[1] 0.6765795
Well done, I must say. To conclude evaluation, let's examine a base R plot of the predicted values versus the actuals (the log values):
> plot(test_predictions, test_logy)
The output of the preceding code is as follows:
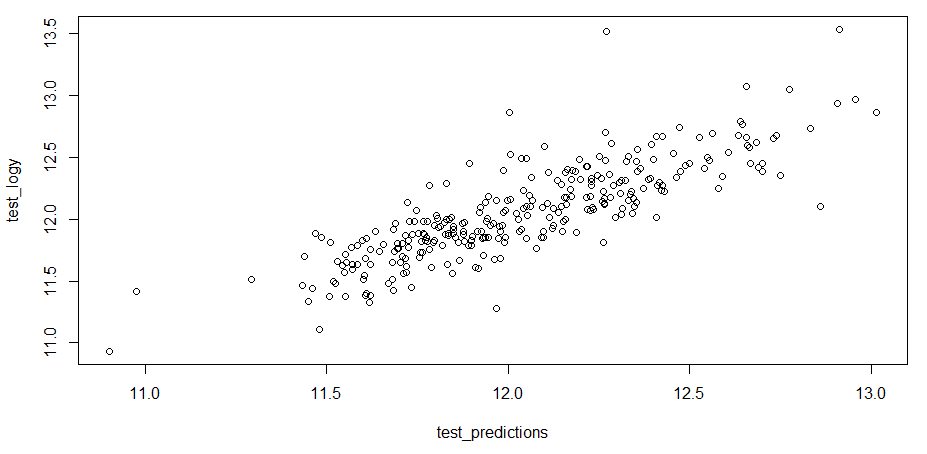
This compares similarly to what we did in Chapter 2, Linear Regression, with a number of outliers and some erratic performance on the lower- and higher-priced houses – all that with hardly any effort to adjust parameters such as the number of hidden neurons, layers, regularization, and maybe adding a linear activation unit somewhere.
In summary, using Keras with TensorFlow can challenge your sanity to code it properly to produce the results you desire, but what we've done here is establish a pipeline to make it possible for regression, and with a couple of changes, it will work for classification. All that, with very little effort around optimizing parameters, which I think is indicative of the power of the technique. Go and do likewise.