
Lesson 13. Multithreading
This chapter presents the most difficult core Java technology to understand and master: multithreading. So far, you have been writing code to run in a single thread of execution. It runs serially, start to finish. You may have the need, however, to multithread, or execute multiple passages of code simultaneously.
You will learn about:
• suspending execution in a thread
• creating and running threads by extending Thread
• creating and running threads by implementing Runnable
• cooperative and preemptive multitasking
• synchronization
• BlockingQueue
• stopping threads
• wait and notify methods
• locks and conditions
• thread priorities
• deadlocks
• ThreadLocal
• the timer classes
• basic design principles for multithreading
Multithreading
Many multithreading needs are related to building responsive user interfaces. For example, most word processing applications contain an “autosave” function. You can configure the word processor to save your documents every x minutes. The autosave executes automatically on schedule without needing your intervention. A save may take several seconds to execute, yet you can continue work without interruption.
The word processor code manages at least two threads. One thread, often referred to as the foreground thread, is managing your direct interaction with the word processor. Any typing, for example, is captured by code executing in the foreground thread. Meanwhile, a second, background thread is checking the clock from time to time. Once the configured number of minutes has elapsed, the second thread executes the code in the save function.
On a multiple-processor machine, multiple threads can actually run simultaneously, each thread on a separate processor. On a single-processor machine, threads each get a little slice of time from the processor (which can usually only execute one thing at a time), making the threads appear to execute simultaneously.
Learning to write code that runs in a separate thread is fairly simple. The challenge is when multiple threads need to share the same resource. If you are not careful, multithreaded solutions can generate incorrect answers or freeze up your application. Testing multithreaded solutions is likewise complex.
Search Server
A server class may need to handle a large number of incoming requests. If it takes more than a few milliseconds to handle each request, clients who make the request may have to wait longer than an acceptable period of time while the server works on other incoming requests. A better solution is to have the server store each incoming request as a search on a queue. Another thread can then take searches from the queue in the order they arrived and process them one at a time. This is known as the active object pattern;1 it decouples the method request from the actual execution of the method. See Figure 13.1. All relevant search information is translated into a command object for later execution.
1 [Lavender1996].
Figure 13.1. Active Object
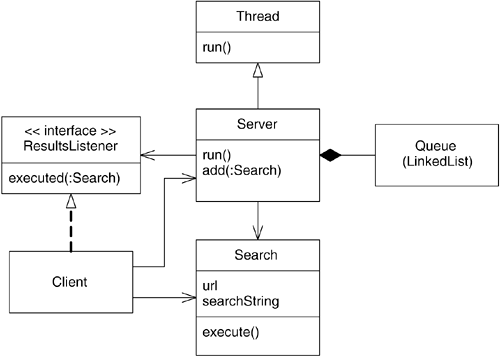
You will build a simple web search server. The server will take a search object consisting of a URL and a search string as a request. As it searches the URL, the server will populate the search object with the number of times the string was found in the document at the URL.
Note: If you're not connected to the Internet, the search test will not execute properly. This is corrected in short time—the section entitled Less Dependent Testing shows how to modify the test to execute against local URLs.
The Search Class
The simplest approach to creating a search server is to follow the Single-Responsibility Principle and first design a class that supports a single search. Once it works, you can concern yourself with the multithreading needs. The benefit is that in keeping each search as a separate object, you have fewer concerns with respect to shared data.
The SearchTest class tests a few possible cases:



The method searchUrl in Search uses a the class java.net.URL to obtain a java.net.URLConnection object. A URLConnection is used to establish communication between the client and the actual URL. Once you send the openConnection message to a URLConnection, you can send the message getInputStream to obtain an InputStream reference. The remainder of the method uses Java IO code (see Lesson 11) to search the file.
Currently, searchUrl invokes the StringUtil method occurrences to count the number of matches within each line read from the input stream. Here are StringUtilTest and StringUtil.

Another solution would be to use Java's regular expression (regex) API. See Additional Lesson III for a discussion of regex.
Less Dependent Testing
If you're unfortunate enough to not be connected to the Internet on your computer, you're probably grousing about your inability to execute ServerTest at all. You will now rectify this situation by changing the search URLs to file URLs.2 This also means you can write out test HTML files to control the content of the “web” pages searched.
2 Another solution would involve installing a local web server, such as Tomcat.

You will need the LineWriter utility; here is the test and production source.


The good part is that the changes to SearchTest are not very invasive. In fact, none of the test methods need change. You are adding setup and teardown methods to write HTML to a local file and subsequently delete that file each time a test completes. You are also changing the URL to use the file protocol instead of the http protocol.
The bad part is that the Search class must change. To obtain an InputStream from a URL with a file protocol, you must extract the path information from the URL and use it to open the stream as a FileInputStream. It's not a significant change. The minor downside is that you now have a bit of code in your production system that will probably only be used by the test.

One other thing you want to consider is that you are no longer exercising the portion of of the code that deals with an http URL. The best approach is to ensure that you have adequate coverage at an acceptance test3 level. Acceptance tests provide a level of testing above unit testing—they test the system from an end user's standpoint. They are executed against as live a system as possible and should not use mocks. For the search application, you would certainly execute acceptance tests that used live web URLs.
3 There are many different nomenclatures for different types of testing. Acceptance tests are the tests that signify that the system meets the acceptance criteria of the customer to whom it's delivered. You may hear these tests referred to as customer tests.
The Server
ServerTest:
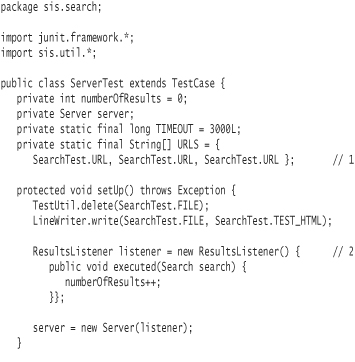
The test first constructs a list of URL strings (line 1).
The setup method constructs a ResultsListener object (line 2). You pass this object as a parameter when constructing a new Server instance.
Your test, as a client, will only be to pass search requests to the server. In the interest of responsiveness, you are designing the server so the client will not have to wait for each request to complete. But the client will still need to know the results each time theserver gets around to processing a search. A frequently used mechanism is a callback.
The term callback is a holdover from the language C, which allows you to create pointers to functions. Once you have a function pointer, you can pass this pointer to other functions like any other reference. The receiving code can then call back to the function located in the originating code, using the function pointer.
In Java, one effective way to implement a callback is to pass an anonymous inner class instance as a parameter to a method. The interface Results-Listener defines an executed method:
package sis.search;
public interface ResultsListener {
public void executed(Search search);
}
In testSearch, you pass an anonymous inner class instance of ResultsListener to the constructor of Server. The Server object holds on to the ResultsListener reference and sends it the executed message when the search has completed execution.
Callbacks are frequently referred to as listeners in Java implementations. A listener interface defines methods that you want called when something happens. User interface classes frequently use listeners to notify other code when an event occurs. For example, you can configure a Java Swing class with a event listener that lets you know when a user clicks on the button to close a window. This allows you to tie up any loose ends before the window actually closes.
In the test, you use the ResultsListener instance simply to track the total number of search executions that complete.
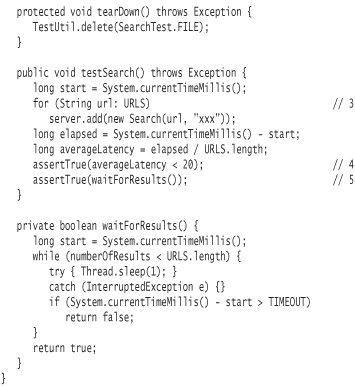
Once you create a Server object, you use a loop (line 3) to iterate through the list of URLs. You use each URL to construct a Search object (the search text is irrelevant). In the interest of demonstrating that Java rapidly dispatches each request, you track the elapsed execution time to create and add a search to the server. You use a subsequent assertion (line 4) to show that the average latency (delay in response time) is an arbitrarily small 20 milliseconds or less.
Since the server will be executing multiple searches in a separate thread, the likelihood is that the code in the JUnit test will complete executing before the searches do. You need a mechanism to hold up processing until the searches are complete—until the number of searches executed is the same as the number of URLs searched.
Waiting in the Test
The assertion at line 5 in the ServerTest listing calls the waitForResults method, which will suspend execution of the current thread (i.e., the thread in which the test is executing) until all search results have been retrieved. The timeout value provides an arbitrary elapsed time after which waitForResults should return false and cause the assertion to fail.

The waitForResults method executes a simple loop. Each time through, the body of the loop pauses for a millisecond, then makes a quick calculation of elapsed time to see if it's passed the timeout limit. The pause is effected by a call to the static Thread method sleep. The sleep method takes a number of milliseconds and idles the currently executing thread for that amount of time.4
4 The thread scheduler will wait at least the specified amount of time and possibly a bit longer.
Since sleep can throw a checked exception of type InterruptedException, you can choose to enclose it in a try-catch block. It is possible for one thread to interrupt another, which is what would generate the exception. But thread interruptions are usually only by design, so the code here shows one of the rare cases where it's acceptable to ignore the exception and provide an empty catch block.
The looping mechanism used in waitForResults is adequate at best. The wait/notify technique, discussed later in this lesson (see Wait/Notify), provides the best general-purpose mechanism of waiting for a condition to occur.
Creating and Running Threads
The Server class needs to accept incoming searches and simultaneously process any requests that have not been executed. The code to do the actual searches will be executed in a separate thread. The main thread of Server, in which the remainder of the code executes, must spawn the second thread.
Java supplies two ways for you to initiate a separate thread. The first requires you to extend the class java.lang.Thread and provide an implementation for the run method. Subsequently, you can call the start method to kick things off. At that point, code in the run method begins execution in a separate thread.
A second technique for spawning threads is to create an instance of a class that implements the interface java.lang.Runnable:
public interface Runnable {
void run();
}
You then construct a Thread object, passing the Runnable object as a parameter. Sending the message start to the Thread object initiates code in the run method. This second technique is often done using anonymous inner class implementations of Runnable.
It is important that you distinguish between a thread, or thread of execution, and a Thread object. A thread is a control flow that the thread scheduler manages. A Thread is an object that manages information about a thread of execution. The existence of a Thread object does not imply the existence of a thread: A thread doesn't exist until a Thread object starts one, and a Thread object can exist long after a thread has terminated.
For now, you'll use the first technique to create a thread and have the Server class extend from Thread. Thread itself implements the Runnable interface. If you extend Thread, you will need to override the run method in order for anything useful to happen.

The Server class defines two fields: a ResultsListener reference and a LinkedList of Search objects, named queue. A flaw exists in the declaration of the queue reference—it is not “thread safe”! For now, your test will likely execute successfully, but the flaw could cause your application to fail. In the section Synchronized Collections in this chapter, you will learn about this thread safety issue and how to correct it.
The java.util.LinkedList class implements the List interface. Instead of storing elements in a contiguous block of memory, as in an ArrayList, a linked list allocates a new block of memory for each element you add to it. The individual blocks of memory thus will be scattered in memory space; each block contains a link to the next block in the list. See Figure 13.2 for a conceptual memory picture of how a linked list works. For collections that require frequent removals or insertions at points other than the end of the list, a LinkedList will provide better performance characteristics than an ArrayList.
Figure 13.2. A Conceptual View of a Linked List
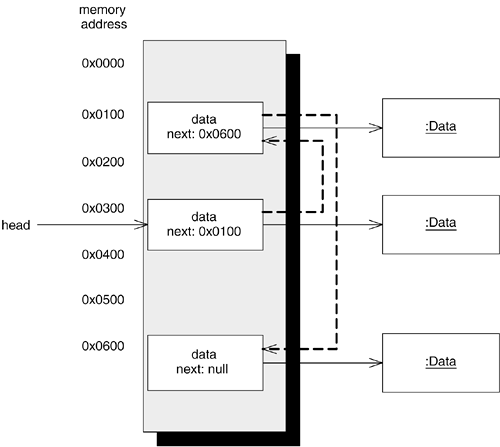
The queue reference stores the incoming search requests. The linked list in this case acts as a queue data structure. A queue is also known as a first-in, first-out (FIFO) list: When you ask a queue to remove elements, it removes the oldest item in the list first. The add method in Server takes a Search parameter and adds it to the end of the queue. So in order for the LinkedList to act as a queue, you must remove Search objects from the beginning of the list.
The constructor of Server kicks off the second thread (often called a worker or background thread) by calling start. The run method is invoked at this point. The run method in Server is an infinite loop—it will keep executing until some other code explicitly terminates the thread (see Stopping Threads in this chapter) or until the application in which it is running terminates (see Shutting Down in this chapter). When you run ServerTest in JUnit, the background thread will keep executing even after all the JUnit tests have completed. It will stop only when you close the JUnit window.
The body of the loop first checks whether the queue is empty. If not, the code removes and executes the first element in the queue. Regardless, the code then calls the Thread method yield. The yield method potentially allows other threads the opportunity to get some time from the processor before the background thread picks up again. The next section on cooperative and preemptive multitasking discusses why the yield might be necessary.
The execute method delegates the actual search to the Search object itself. When the search completes, the ResultsListener reference is sent the message executed with the Search object as a parameter.
You can represent the flow of messages in a successful search using a UML sequence diagram (Figure 13.3). The sequence diagram is a dynamic view of your system in action. It shows the ordered message flow between objects. I find that sequence diagrams can be a very effective means of communicating how a system is wired together with respect to various uses.5
5 Sequence diagrams sometimes are not the best way of representing complex parallel activity. A UML model that is perhaps better suited for representing multithreaded behavior is the activity diagram.
Figure 13.3. Sequence Diagram for the Active Object Search

In a sequence diagram, you show object boxes instead of class boxes. The dashed line that emanates vertically downward from each box represents the object's lifeline. An “X” at the bottom of the object lifeline indicates its termination. The Search object in Figure 13.3 disappears when it is notified that a search has been completed; thus, its lifeline is capped off with an “X.”
You represent a message send using a directed line from the sending object's lifeline to the receiver. Messages flow in order from top to bottom. In Figure 13.3, a Client object sends the first message, creates. This special message shows that the Client object is responsible for creation of a Search object. Note that the Search object starts farther down; it is not in existence until this point.
After the first message send, the Client sends add(Search) to the Server object. This message send is conceptually asynchronous—the Client need not wait for any return information from the Server object.6 You use a half-arrowhead to represent asynchronous message sends. When it receives this add message, the Server's add method passes the Search object off to the queue. You represent the execution lifetime of the add method at the Server object using an activation—a thin rectangle laid over the object lifeline.
6 The way we've implemented it, the message send is synchronous, but since the operation is immediate and returns no information you can represent it as asynchronous.
Meanwhile, the Server thread has sent the message start to its superclass (or, more correctly, to itself). The run method overridden in Server begins execution. Its lifetime is indicated by an activation on the Server object's lifeline. Code in the run method sends the message remove(0) to the Queue to obtain and remove its first Search element. Subsequently the run method sends the message execute to the Search object and notifies the ResultsListener (via executed) when execute completes.
Cooperative and Preemptive Multitasking
In a single-processor environment, individual threads each get a slice of time from the processor in which to execute. The question is, how much time does each thread get before another thread takes over? The answer depends upon many things, including which operating system you are using to run Java and your particular JVM implementation.
Most modern operating systems (including Unix variants and Windows) use preemptive multitasking, in which the operating system (OS) interrupts the currently executing thread. Information about the thread is stored, and the OS goes on to provide a slice of time to the next thread. In this environment, all threads will eventually get some attention from the thread scheduler.
The other possibility is that the operating system manages threads using cooperative multitasking. Cooperative multitasking depends on thread code behaving well by yielding time to other threads frequently. In a cooperative threading model, one poorly written thread could hog the processor completely, preventing all other threads from doing any processing. Threads may yield time by explicitly calling the yield method, by sleeping, when blocking (waiting) on IO operations, and when they are suspended, to mention a few ways.
In the Server class, the while loop in the run method calls the yield method each time through the loop to allow other threads the opportunity to execute.7
7 You may experience significant CPU usage when executing this code, depending on your environment. The yield method may effectively do nothing if there are no other threads executing. An alternative would be to introduce a sleep of a millisecond.

Synchronization
One of the biggest pitfalls with multithreaded development is dealing with the fact that threads run in nondeterministic order. Each time you execute a multithreaded application, the threads may run in a different order that is impossible to predict. The most challenging result of this nondeterminism is that you may have coded a defect that surfaces only once in a few thousand executions, or once every second full moon.8
8 The subtle gravitational pull might cause electrostatic tides that slow the processor for a picosecond.
Two threads that are executing code do not necessarily move through the code at the same rate. One thread may execute five lines of code before another has even processed one. The thread scheduler interleaves slices of code from each executing thread.
Also, threading is not at the level of Java statements, but at a lower level of the VM operations that the statements translate down to. Most statements you code in Java are non-atomic: The Java compiler might create several internal operations to correspond to a single statement, even something as simple as incrementing a counter or assigning a value to a reference. Suppose an assignment statement takes two internal operations. The second operation may not complete before the thread scheduler suspends the thread and executes a second thread.
All this code interleaving means that you may encounter synchronization issues. If two threads go after the same piece of data at the same time, the results may not be what you expect.
![]()
You will modify the sis.studentinfo.Account class to support withdrawing funds. To withdraw funds, the balance of the account must be at least as much as the amount being withdrawn. If the amount is too large, you should do nothing (for simplicity's and demonstration's sake). In any case, you never want the account balance to go below zero.

The withdraw method:
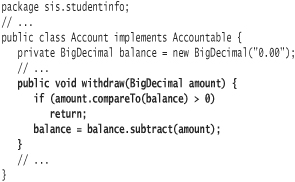
A fundamental problem exists with the withdraw method in a multithreaded environment. Suppose two threads attempt to withdraw $80 from an account with a $100 balance at the same time. One thread should succeed; the other thread should fail. The end balance should be $0. However, the code execution could interleave as follows:
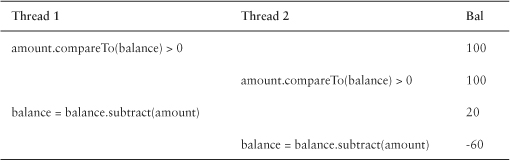
The second thread tests the balance after the first thread has approved the balance but before the first thread has subtracted from the balance. Other execution sequences could cause the same problem.
You can write a short test to demonstrate this problem.

There's definitely some code redundancy in this method. After you understand what the method is doing, make sure you refactor it to eliminate the duplication.
Creating Threads with Runnable
The method testConcurrency introduces two new things. First, it shows how you can create a thread by passing it an instance of the Runnable interface. Remember that the Runnable interface defines the single method run. The test constructs an anonymous inner class instance of Runnable for each thread. Note that the code in the run methods does not execute until the start methods are called.
The second new thing in testConcurrency is the use of the Thread method join. When you send the message join to a thread, execution in the current thread halts until that thread completes. The code in testConcurrency first waits until t1 completes, then t2, before the test can proceed.
When you execute JUnit, testConcurrency will in all likelihood pass. In a small method, where everything executes quickly, the thread scheduler will probably allot enough time to a thread to execute the entire method before moving on to the next thread. You can force the issue by inserting a pause in the withdraw method:

You should now see a red bar.
Synchronized
Semantically, you want all of the code in withdraw to execute atomically. A thread should be able to execute the entire withdraw method, start to finish, without any other thread interfering. You can accomplish this in Java through use of the synchronized method modifier.

This implementation of synchronization in Java is known as mutual exclusion. Another way you can refer to the code protected by mutual exclusion is as a critical section.9 In order to ensure that the withdraw code executes mutually exclusively, Java places a lock on the object in which the thread's code is executing. While one thread has a lock on an object, no other thread can obtain a lock on that object. Other threads that try to do so will block until the lock is released. The lock is released when the method completes execution.
Java uses a concept known as monitors to protect data. A monitor is associated with each object; this monitor protects the object's instance data. A monitor is associated with each class; it protects the class's static data. When you acquire a lock, you are acquiring the associated monitor; only one thread can acquire a lock at any given time.10
10 http://www.artima.com/insidejvm/ed2/threadsynch2.html.
You should always try to lock the smallest amount of code possible, otherwise you may experience performance problems while other threads wait to obtain a lock. If you are creating small, composed methods as I've repetitively recommended, you will find that locking at the method level suffices for most needs. However, you can lock at a smaller atomicity than an entire method by creating a synchronized block. You must also specify an object to use as a monitor by enclosing its reference in parentheses after the synchronized keyword.
The following implementation of withdraw is equivalent to the above implementation.
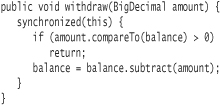
A synchronized block requires the use of braces, even if it contains only one statement.
You can declare a class method as synchronized. When the VM executes a class method, it will obtain a lock on the Class object for which the method is defined.
Synchronized Collections
As I hinted earlier, the Server class contains a flaw with respect to the declaration of the queue as a LinkedList.
![]()
When you work with the Java 2 Collection Class Framework with classes such as ArrayList, LinkedList, and HashMap, you should be cognizant of the fact that they are not thread-safe—the methods in these classes are not synchronized. The older collection classes, Vector and Hashtable, are synchronized by default. However, I recommend you do not use them if you need thread-safe collections.
Instead, you can use utility methods in the class java.util.Collections to enclose a collection instance in what is known as a synchronization wrapper. The synchronization wrapper obtains locks where necessary on the target collection and delegates all messages off to the collection for normal processing. Modify the Server class to wrap the queue reference in a synchronized list:
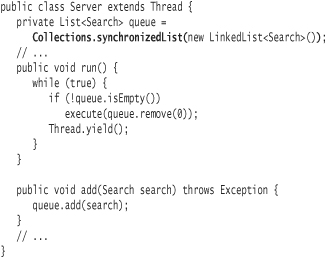
Adding the synchronization wrapper doesn't require you to change any code that uses the queue reference.
Using a bit of analysis, it doesn't seem possible for there to be a synchronization problem with respect to the queue. The add method inserts to the end of the list; the run loop removes from the beginning of the queue only if the queue is not empty. There are no other methods that operate on the queue. However, there is a slim possibility that portions of the add and remove operations will execute at the same time. This concurrency could corrupt the integrity of the LinkedList instance. Using the synchronization wrappers will eliminate the defect.
BlockingQueue
A promising API addition in J2SE 5.0 is the concurrency library of classes, located in the package java.util.concurrent. It provides utility classes to help you solve many of the issues surrounding multithreading. While you should prefer use of this library, its existence doesn't mean that you don't need to learn the fundamentals and concepts behind threading.11
11 The importance of learning how multiplication works before always using a calculator to solve every problem is an analogy.
Since queues are such a useful construct in multithreaded applications, the concurrency library defines an interface, BlockingQueue, along with five specialized queue classes that implement this interface. Blocking queues implement another new interface, java.util.Queue, which defines queue semantics for collections. Blocking queues add concurrency-related capabilities to queues. Examples include the ability to wait for elements to exist when retrieving the next in line and the ability to wait for space to exist when storing elements.
You can rework the Server class to use a LinkedBlockingQueue instead of a LinkedList.

The LinkedBlockingQueue method put adds an element to the end of the queue. The take method removes an element from the beginning of the queue. It also waits until an element is available in the queue. The code doesn't look very different from your original implementation of Server, but it is now thread-safe.
Stopping Threads
A testing flaw still remains in ServerTest. The thread in the Server class is executing an infinite loop. Normally, the loop would terminate when the Server itself terminated. When running your tests in JUnit, however, the thread keeps running until you close down JUnit itself—the Server run method keeps chugging along.
The Thread API contains a stop method that would appear to do the trick of stopping the thread. It doesn't take long to read in the detailed API documentation that the stop method has been deprecated and is “inherently unsafe.” Fortunately, the documentation goes on to explain why and what you should do instead. (Read it.) The recommended technique is to simply have the thread die on its own based on some condition. One way is to use a boolean variable that you initialize to true and set to false when you want the thread to terminate. The conditional in the while loop in the run method can test the value of this variable.
You will need to modify the ServerTest method tearDown to do the shutdown and verify that it worked.
protected void tearDown() throws Exception {
assertTrue(server.isAlive());
server.shutDown();
server.join(3000);
assertFalse(server.isAlive());
TestUtil.delete(SearchTest.FILE);
}
Remember, the tearDown method executes upon completion of each and every test method, regardless of whether or not an exception was thrown by the test. In tearDown, you first ensure that the thread is “alive” and running. You then send the message shutDown to the server. You've chosen the method name shutDown to signal the server to stop.
You then wait on the server thread by using the join method, with an arbitrary timeout of 3 seconds. It will take some time for the thread to terminate. Without the join method, the rest of the code in tearDown will likely execute before the thread is completely dead. Finally, after you issue the shutDown command to the Server, you ensure that its thread is no longer alive. The isAlive method is defined on Thread and Server is a subclass of Thread, so you can send the message isAlive to the Server instance to get your answer.
Since the Server class now uses a LinkedBlockingQueue, you cannot use a boolean flag on the run method's while loop. The LinkedBlockingQueue take method blocks—it waits until a new object is available on the queue. It would wait forever if you left JUnit running.
One way you could get the LinkedBlockingQueue to stop waiting would be to put a special Search object on the queue, one that signifies that you're done. Each time you take an object from the queue, you would need to check to see if it was the special Search object and terminate the run method if it was.
Another way to stop LinkedBlockingQueue from waiting is to interrupt the thread by sending it the interrupt message, which generates an Interrupted-Exception. If you catch an InterruptedException, you can then break out of the infinite while loop. Here is the implementation of this approach:

Wait/Notify
Java provides a mechanism to help you coordinate actions between two or more threads. Often you need to have one thread wait until another thread has completed its work. Java provides a mechanism known as wait/notify. You can call a wait method from within a thread in order to idle it. Another thread can wake up this waiting thread by calling a notify method.
An example? Let's rock! A clock—tic-toc!
![]()
In this example, you'll build a clock class suitable for use in a clock application. A user interface (UI) for the clock application could display either a digital readout or an analog representation, complete with hour, minute, and second hands. While the UI is busy creating output that the user sees, the actual Clock class can execute a separate thread to constantly track the time. The Clock thread will loop indefinitely. Every second, it will wake up and notify the user interface that the time has changed.
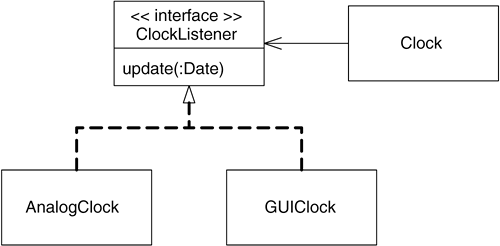
The UI class implements the ClockListener interface. You pass a ClockListener reference to a Clock object; the clock can call back to this listener with the changed time. With this listener-based design, you could replace an analog clock interface with a digital clock interface and not have to change the clock class (see Figure 13.4).
Figure 13.4. A Clock Listener
The tough part is going to be writing a test. Here's a strategy:
• Create a mock ClockListener that stores any messages it receives.
• Create the Clock instance, passing in the mock object.
• Start the clock up and wait until five messages have been received by the mock.
• Ensure that the messages received by the ClockListener, which are date instances, are each separated by one second.
The test below performs each of these steps. The tricky bit is getting the test to wait until the mock gets all the messages it wants. I'll explain that part, but I'll let you figure out the rest of the test, including the verification of the tics captured by the test listener.



After the test creates the Clock instance, it waits (line 5). You can send the wait message to any object—wait is defined in the class Object. You must first obtain a lock on that same object. You do so using either a synchronized block (line 4) or synchronized method, as mentioned above. In the test, you use an arbitrary object stored in the monitor field (line 1) as the object to lock and wait on.
What does the test wait for? In the mock listener implementation, you can store a count variable that gets bumped up by 1 each time the update(Date) method is called. Once the desired number of messages is received, you can tell the ClockTest to stop waiting.
From an implementation standpoint, the test thread waits until the listener, which is executing in another thread, says to proceed. The listener says that things can proceed by sending the notifyAll message to the same object the test is waiting on (line 3). In order to call notifyAll, you must first obtain a lock against the monitor object, again using a synchronized block.
But ... wait! The call to wait was in a synchronized block, meaning that no other code can obtain a lock—including the synchronized block wrapping the notifyAll method—until the synchronized block exits. Yet it won't exit until the waiting is done, and the waiting isn't done until notifyAll is called. This would seem to be a Catch-22 situation.
The trick: Behind the scenes, the wait method puts the current thread on what is called a “wait set” for the monitor object. It then releases all locks before idling the current thread. Thus when code in the other thread encounters the synchronized block wrapping the notifyAll call, there is no lock on the monitor. It can then obtain a lock (line 2). The notifyAll call requires the lock in order to be able to send its message to the monitor.
You may want to go over the discussion of wait/notify a few times until it sinks in.
Here is the ClockListener interface and the Clock class implementation:

The run method in Clock uses the simple technique of testing a boolean flag, run, each time through a while loop to determine when to stop. The stop method, called by the test after its waiting is complete, sets the run boolean to false.
There is a flaw in the Clock implementation. The run method sleeps for at least a full second. As I noted earlier, a sleep call may take a few additional nanoseconds or milliseconds. Plus, creating a new Date object takes time. This means that it's fairly likely that the clock could skip a second: If the last time posted was at 11:55:01.999, for example, and the sleep plus additional execution took 1,001 milliseconds instead of precisely 1,000 milliseconds, then the new time posted would be 11:55:03.000. The clock UI would show 11:55:01, then skip to 11:55:03. In an analog display, you'd see the second hand jump a little bit more—not that big a deal in most applications. If you run enough iterations in the test, it will almost certainly fail.
Here's an improved implementation:
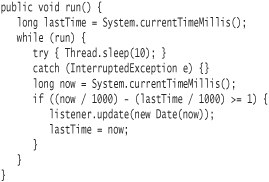
Could you have written a test that would have uncovered this defect consistently? One option for doing so might include creating a utility class to return the current milliseconds. You could then mock the utility class to force a certain time.
The test for Clock is a nuisance. It adds 5 seconds to the execution time of your unit tests. How might you minimize this time? First, it probably doesn't matter if the test proves 5 tics or 2. Second, you might modify the clock class (and test accordingly) to support configurable intervals. Instead of 1 second, write the test to demonstrate support for hundredths of a second (like a stopwatch would require).
Additional Notes on wait and notify
The Object class overloads the wait method with versions that allow you to specify a timeout period. A thread you suspend using one of these versions of wait idles until another thread notifies it or until the timeout period has expired.
Under certain circumstances, it is possible for a spurious wakeup to occur—one that you did not trigger by an explicit notification! This is rare, but if you use wait and notify in production code, you need to guard against this condition. To do so, you can enclose the wait statement in a while loop that tests a condition indicating whether or not execution can proceed. The Java API documentation for the wait method shows how you might implement this.
In a test, you could create a do-while loop that called the verify method each time through. If the verify method were to then fail, you would execute wait again. I view this as an unnecessary complexity for a test. The worst case of not guarding against the unlikely spurious wakeup would be that the test would fail, at which time you could rerun it.
While notifyAll wakes up all threads that are waiting if there is more than one, the notify method chooses an arbitrary thread to be woken up. In most circumstances you will want to use notifyAll. However, in some situations you will want to wake up only a single thread. An example is a thread pool.
The search server currently uses a single thread to process incoming requests. Clients eventually get the results of their search in an asynchronous fashion. While this may be fine for a small number of requests, clients could end up waiting quite a while if a number of other clients have requested searches ahead of them.
You might consider spawning each search request off in a new, separate thread as it arrives. However, each Java thread you create and start carries with it significant overhead costs. Creating one thread for each of thousands of search requests would result in severe performance problems. The Java thread scheduler would spend more time context-switching between threads than it would processing each thread.
A thread pool collects an arbitrary, smaller number of worker Thread objects that it creates and starts running. As a search comes in, you pass it off to the pool. The pool adds the work to the end of a queue, then issues a notify message. Any worker thread that has completed its work checks the queue for any pending tasks. If no tasks are available, the worker thread sits in an idle state by blocking on a wait call. If there are idle threads, the notify message will wake up one of them. The awakened worker thread can then grab and process the next available piece of work.
Locks and Conditions
J2SE 5.0 introduces a new, more flexible mechanism for obtaining locks on objects. The interface java.util.concurrent.locks.Lock allows you to associate one or more conditions with a lock. Different types of locks exist. For example, the ReadWriteLock implementation allows one thread to write to a shared resource, while allowing multiple threads to read from the same resource. You can also add fairness rules to a reentrant lock to do things like allow threads waiting the longest to obtain the lock first. Refer to the API documentation for details.
The listing of ClockTest shows how you would replace the use of synchronization with the new lock idiom.


The modified and slightly refactored implementation of ClockTest uses a ReentrantLock implementation of the Lock interface. A thread interested in accessing a shared resource sends the message lock to a ReentrantLock object. Once the thread obtains the lock, other threads attempt to lock the block until the first thread releases the lock. A thread releases the lock by sending unlock to a Lock object. You should always ensure an unlock occurs by using a try-finally block.
The shared resource in ClockTest is the Condition object. You obtain a Condition object from a Lock by sending it the message newCondition (see the setUp method). Once you have a Condition object, you can block on it by using await. As with the wait method, code in await releases the lock and suspends the current thread.12 Code in another thread signals that the condition has been met by sending the Condition object the message signal or signalAll.
12 Which suggests you may not need to enclose an await call in a try-finally block. Don't risk it—you can't guarantee that something won't go awry with the code in await.
Coupled with the use of Condition objects, the idiom shown in ClockTest effectively replaces the classic wait/notify scheme.
Thread Priorities
Threads can specify different priority levels. The scheduler uses a thread's priority as a suggestion for how often the thread should get attention. The main thread that executes has a default priority assigned to it, Thread.NORM_PRIORITY. A priority is an integer, bounded by Thread.MIN_PRIORITY on the low end and Thread.MAX_PRIORITY on the high end.
You might use a lower priority for a thread that executes in the background. In contrast, you might use a higher priority for user interface code that needs to be extremely responsive. Generally, you will want to deviate from NORM_PRIORITY only by small amounts, such as +1 and -1. Deviating by large amounts can create applications that perform poorly, with some threads dominating and others starving for attention.
Every thread (other than the main thread) starts with the same priority as the thread that spawned it. You can send a thread the message setPriority to specify a different priority.
The following snippet of code from the Clock class shows how you might set the priority for the clock to a slightly lower value.
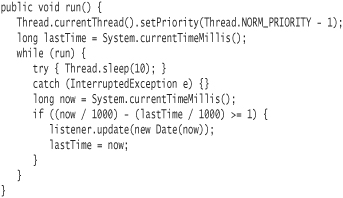
Note use of the currentThread static method, which you can always call to obtain the Thread object that represents the thread that is currently executing.
Deadlocks
If you are not careful in coding multithreaded applications, you can encounter deadlocks, which will bring your system to a screeching halt. Suppose you have an object alpha running in one thread and an object beta running in another thread. Alpha executes a synchronized method (which by definition holds a lock on alpha) that calls a synchronized method defined on beta. If at the same time beta is executing a synchronized method, and this method in turn calls a synchronized method on alpha, each thread will wait for the other thread to relinquish its lock before proceeding. Deadlock!13
13 [Arnold2000].
Solutions for resolving deadlock:
- Order the objects to be locked and ensure the locks are acquired in this order.
- Use a common object to lock.
ThreadLocal
You may have a need to store separate information along with each thread that executes. Java provides a class named ThreadLocal that manages creating and accessing a separate instance, per thread, of any type.
When you interact with a database through JDBC,14 you obtain a Connection object that manages communication between your application and the database. It is not safe for more than one thread to work with a single connection object, however. One classic use of ThreadLocal is to allow each thread to contain a separate Connection object.
14 The Java DataBase Connectivity API. See Additional Lesson III for further information.
However, you've not learned about JDBC yet. For your example, I'll define an alternate use for ThreadLocal.
In this example, you'll take the existing Server class and add logging capabilities to it. You want each thread to track when the search started and when it completed. You also want the start and stop message pairs for a search to appear together in the log. You could store a message for each event (start and stop) in a common thread-safe list stored in Server. But if several threads were to add messages to this common list, the messages would interleave. You'd probably see all the start log events first, then all the stop log events.
To solve this problem, you can have each thread store its own log messages in a ThreadLocal variable. When the thread completes, you can obtain a lock and add all the messages at once to the complete log.
First, modify the Server class to create a new thread for each Search request. This should boost the performance in most environments, but you do want to be careful how many threads you let execute simultaneously. (You might experiment with the number of searches the test kicks off to see what the limits are for your environment.) You may want to consider a thread pool as mentioned in the section Additional Notes on wait and notify.
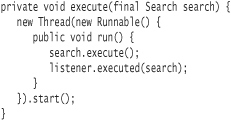
Ensure that your tests still run successfully. Next, let's refactor ServerTest—significantly. You want to add a new test that verifies the logged messages. The current code is a bit of a mess, and it has a fairly long and involved test. For the second test, you will want to reuse most of the nonassertion code from testSearch. The refactored code also simplifies a bit of the performance testing.
Here is the refactored test that includes a new test, testLogs.


The method testLogs executes the searches, waits for them to complete, and verifies the logs. To verify the logs, the test requests the complete log from the Server object, then loops through the log, extracting a pair of lines at a time. It verifies that the search string (the first part of the log message) is the same in each pair of lines.15
15 See Lesson 8 for an in-depth discussion of Java logging and a discussion of whether or not it is necessary to test logging code.
The modifications to the Server class:


You declare a ThreadLocal object by binding it to the type of object you want stored in each thread. Here, threadLog is bound to a List of String objects. The threadLog ThreadLocal instance will internally manage a List of String objects for each separate thread.
You can't simply assign an initial value to threadLog, since each of the List objects it manages need to be initialized. Instead, ThreadLocal provides an initialValue method that you can override. The first time each thread gets its ThreadLocal instance via threadLog, code in the ThreadLocal class calls the initialValue method. Overriding this method provides you with the opportunity to consistently initialize the list.
ThreadLocal defines three additional methods: get, set, and remove. The get and set methods allow you to access the current thread's ThreadLocal instance. The remove method allows you to remove the current thread's ThreadLocal instance, perhaps to save on memory space.
In the search thread's run method, you call the log method before and after executing the search. In the log method, you access the current thread's copy of the log list by calling the get method on threadLog. You then add a pertinent log string to the list.
Once the search thread completes, you want to add the thread's log to the complete log. Since you've instantiated completeLog as a synchronized collection, you can send it the addAll method to ensure that all lines in the thread log are added as a whole. Without synchronization, another thread could add its log lines, resulting in an interleaved complete log.
The Timer Class
![]()
You want to continually monitor a web site over time to see if it contains the search terms you specify. You're interested in checking every several minutes or perhaps every several seconds.
The test testRepeatedSearch in SearchSchedulerTest shows the intent of how this search monitor should work: Create a scheduler and pass to it a search plus an interval representing how often to run the search. The test mechanics involve waiting for a set period of time once the scheduler has started and then verifying that the expected number of searches are executed within that time.

The SearchScheduler class, below, uses the java.util.Timer class as the basis for scheduling and executing searches. Once you have created a Timer instance, you can call one of a handful of methods to schedule TimerTasks. A TimerTask is an abstract class that implements the Runnable interface. You supply the details on what the task does by subclassing TimerTask and implementing the run method.
In SearchScheduler, you use the method scheduleAtFixedRate, which you pass a TimerTask, a delay before start of 0 milliseconds, and an interval (currently specified by the test) in milliseconds. Every interval milliseconds, the Timer object wakes up and sends the run message to the task. This is known as fixed-rate execution.
When you use fixed-rate execution,16 the Timer does its best to ensure that tasks are run every interval milliseconds. If a task takes longer than the interval, the Timer tries to execute tasks more tightly together to ensure that they finish before each interval is up. You can also use one of the delayed-rate execution methods, in which the case the interval from the end of one search to the next remains consistent.
16 [Sun2004b].
You can cancel both timers and timer tasks via the cancel method.

Thread Miscellany
Atomic Variables and volatile
Java compilers try to optimize as much code as possible. For example, if you assign an initial value to a field outside of a loop:

the Java compiler may figure that the value of the prefix field is fixed for the duration of the show method. It may optimize the code to treat the use of prefix within the loop as a constant. Java thus may not bother reading the value of prefix with each iteration through the loop. This is an appropriate assumption, as long as no other code (in a multithread execution) updates the value of prefix at the same time. But if another thread does modify prefix, code in the loop here may never see the changed value.17
17 The actual behavior may depend on your compiler, JVM, and processor configuration.
You can force Java to always read a fresh value for a field by enclosing access to it in a synchronized block. Java uses this awareness that the code could be executing in multiple threads to ensure that it always gets the latest value for all fields contained within. Another way to get Java to read a fresh value is to declare the field as volatile. Doing so essentially tells the compiler that it cannot optimize access to the field.
When you use a shared boolean variable as the conditional for a thread's run loop, you may want to declare the boolean variable as volatile. This will ensure that the while loop reads the updated value of the boolean each time through the loop.
A related consideration is how Java treats common access to fields accessed from multiple threads. Java guarantees that reading or writing a variable—with the exception of a long or double variable—is atomic. This means that the smallest possible operation against the variable is to read or write its entire value. It is not possible for one thread to write a portion of the variable while another thread is writing another portion, which would corrupt the variable.
Thread Information
As mentioned earlier, you can obtain the Thread object for the currently executing thread by using the Thread static method currentThread. The Thread object contains a number of useful methods for obtaining information about the thread. Refer to the Java API documentation for a list of these getter and query methods. Additionally, using setName and getName, you can set and retrieve an arbitrary name for the thread.
Shutting Down
The main thread in an executing application is by default a user thread. As long as there is at least one active user thread, your application will continue to execute. In contrast, you can explicitly designate a thread as a daemon thread. If all user threads have terminated, the application will terminate as well, even if daemon threads continue to execute.
The ThreadTest example demonstrates this behavior with respect to user threads. The code executing in main runs in a user thread. Any threads spawned inherit the execution mode (user, or daemon) of the thread that spawned them, so thread t in the example is a user thread.
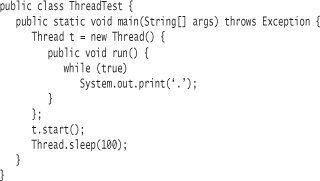
When you execute ThreadTest, it will not stop until you force termination of the process (Ctrl-c usually works from the command line).
Setting a Thread object to execute as a daemon thread is as simple as sending it the message setDaemon with a parameter value of true. You must set the thread execution mode prior to starting the thread. Once a thread has started, you cannot change its execution mode.

You can forcibly exit an application, regardless of whether any user threads remain alive or not, by calling the System static method exit. (The Runtime class has an equivalent method.)

The exit method requires you to pass it an int value. This value represents the application return code, which you can use to control shell scripts or batch files.
In many applications, such as Swing applications, you will not have control over other threads that are spawned. Swing itself executes code in threads. More often than not, threads end up being initiated as user threads. Accordingly, you may need to use the exit method to terminate a Swing application.
Managing Exceptions
When a run method throws an (unchecked18) exception, the thread in which it is running terminates. Additionally, the exception object itself disappears. You may wish to capture the exception, as ServerTest.testException suggests.
18 Since the Runnable run method signature declares no exceptions, you cannot override it to throw any checked exceptions.

The test uses a mock override of the Search execute method to simulate a RuntimeException being thrown. Your expectation is that this exception will be logged to the Server as a failed search. Here is the Server class implementation:

After creating the thread object, but before starting it, you can set an uncaught exception handler on the thread. You create an uncaught exception handler by implementing the method uncaughtException. If the thread throws an exception that is not caught, the uncaughtException method is called. Java passes uncaughtException both the thread and throwable objects.
Thread Groups
Thread groups provide a way to organize threads into arbitrary groups. A thread group can also contain other thread groups, allowing for a containment hierarchy. You can control all threads contained in a thread group as a unit. For example, you can send the message interrupt to a thread group, which will in turn send the interrupt message to all threads contained within the hierarchy.
In Effective Java, Joshua Bloch writes that thread groups “are best viewed as an unsuccessful experiment, and you may simply ignore their existence.”19 They were originally designed to facilitate security management in Java but never satisfactorily fulfilled this purpose.
19 [Bloch 2001].
Prior to J2SE 5.0, one useful purpose for thread groups was to monitor threads for uncaught exceptions. However, you can now fulfill this need by creating an UncaughtExceptionHandler for a thread (see the previous section, Managing Exceptions).
Atomic Wrappers
Even simple arithmetic operations are not atomic. As of J2SE 5.0, Sun supplies the package java.util.concurrent.atomic. This package includes a dozen Atomic wrapper classes. Each class wraps a primitive type (int, long, or boolean), a reference, or an array. By using an atomic wrapper, you guarantee that operations on the wrapped value are thread safe and work against an up-to-date value (as if you had declared the field volatile).
Here is an example use:
AtomicInteger i = new AtomicInteger(50);
assertEquals(55, i.addAndGet(5));
assertEquals(55, i.get());
Refer to the Java API documentation for further details.
Summary: Basic Design Principles for Synchronization
• Avoid it. Introduce synchronization only when necessary.
• Isolate it. Cluster synchronization needs into a single-responsibility class that does as little as possible. Ensure that as few clients as possible interact with a synchronized class. Ensure that as few methods as possible interact with shared data.
• Shared, or “server,” classes should provide synchronization instead of depending on clients to synchronize properly.
• If a server class has not provided synchronization, consider writing a “wrapper” class that adds synchronization and delegates all messages to the server class.
• Use the synchronization class library located in java.util.concurrent.
Exercises
- Create an AlarmClock class. A client can submit a single event and corresponding time. When the time passes, the AlarmClock sends an alarm to the client.
- Eliminate the wait loop in AlarmClockTest (from the previous exercise) by using
waitandnotify. - Modify the alarm clock to support multiple alarms (if it doesn't already). Then add the ability to cancel an alarm by name. Write a test that demonstrates the ability to cancel the alarm. Then analyze your code and note the potential for synchronization issues. Introduce a pause in the production code to force the issue and get your test to fail. Finally, introduce synchronization blocks or modify methods to be synchronized as necessary to fix the problem.
- Change the
runmethod in AlarmClock to use a timer to check for alarms every half-second.