
30. The Payroll Case Study: Package Analysis

© Jennifer M. Kohnke
Rule of thumb: if you think something is clever and sophisticated, beware—it is probably self-indulgence.
—Donald A. Norman, The Design of Everyday Things, 1990
We have done a great deal of analysis, design, and implementation of the payroll problem. However, we still have many decisions to make. For one thing, only two programmers—Bob and Micah—have been working on the problem. The current structure of the development environment is consistent with this. All the program files are located in a single directory. There is no higher-order structure. There are no packages, no subsystems, no releasable components other than the entire application. This will not do going forward.
We must assume that as this program grows, the number of people working on it will grow, too. In order to make it convenient for multiple developers, we are going to have to partition the source code into components—assemblies, DLLs—that can be conveniently checked out, modified, and tested.
The payroll application currently consists of 4,382 lines of code divided into about 63 classes and 80 source files. Although this is not a huge number, it does represent an organizational burden. How should we manage these source files and divide them into independently deployable components?
Similarly, how should we divide the work of implementation so that the development can proceed smoothly without the programmers’ getting in one another’s way? We would like to divide the classes into groups that are convenient for individuals or teams to checkout and support.
Component Structure and Notation
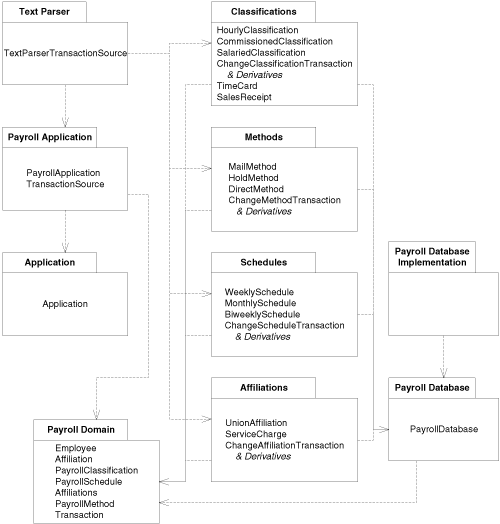
Figure 30-1 shows a possible component structure for the payroll application. We will address the appropriateness of this structure later. For now, we will confine ourselves to how such a structure is documented and used.
Figure 30-1. Possible payroll component diagram

By convention, component diagrams are drawn with the dependencies pointing downward. Components at the top are dependent. Components at the bottom are depended on.
Figure 30-1 has divided the payroll application into eight components. The PayrollApplication component contains the PayrollApplication class and the TransactionSource and TextParserTransactionSource classes. The Transactions component contains the complete Transaction-class hierarchy. The constituents of the other components should be clear by carefully examining the diagram.
The dependencies should also be clear. The PayrollApplication component depends on the Transactions component because the PayrollApplication class calls the Transaction::Execute method. The Transactions component depends on the PayrollDatabase component because each of the many derivatives of Transaction communicates directly with the PayrollDatabase class. The other dependencies are likewise justifiable.
What criteria did we use to group these classes into components? We simply stuck the classes that look like they belonged together into the same components. As we learned in Chapter 28, this is probably not a good idea, however.
Consider what happens if we make a change to the Classifications component. This change will force a recompilation and retest of the EmployeeDatabase component, and well it should. But it will also force a recompilation and retest of the Transactions component. Certainly, the ChangeClassificationTransaction and its three derivatives from Figure 27-13 should be recompiled and retested, but why should the others be recompiled and retested?
Technically, those other transactions don’t need recompilation and retest. However, if they are part of the Transactions component, and if that component is going to be rereleased to deal with the changes to the Classifications component, it could be viewed as irresponsible not to recompile and retest the component as a whole. Even if all the transactions aren’t recompiled and retested, the package itself must be rereleased and redeployed, and then all its clients will require revalidation at the very least and probably recompilation as well.
The classes in the Transactions component do not share the same closure. Each one is sensitive to its own particular changes. The ServiceChargeTransaction is open to changes to the ServiceCharge class, whereas the TimeCardTransaction is open to changes to the TimeCard class. In fact, as Figure 30-1 implies, some portion of the Transactions component is dependent on nearly every other part of the software. Thus, this component suffers a high rate of release. Every time something is changed anywhere below, the Transactions component will have to be revalidated and rereleased.
The PayrollApplication package is even more sensitive: Any change to any part of the system will affect this package, so its release rate must be enormous. You might think that this is inevitable—that as one climbs higher up the package-dependency hierarchy, the release rate must increase. Fortunately, however, this is not true, and avoiding this symptom is one of the major goals of OOD.
Applying the Common Closure Principle (CCP)
Consider Figure 30-2, which groups the classes of the payroll application together according to their closure. For example, the PayrollApplication component contains the PayrollApplication and TransactionSource classes. Both of these two classes depend on the abstract Transaction class, which is in the PayrollDomain component. Note that the TextParserTransactionSource class is in another component that depends on the abstract PayrollApplication class. This creates an upside-down structure in which the details depend on the generalities, and the generalities are independent. This conforms to DIP.
Figure 30-2. A closed-component hierarchy for the payroll application
The most striking case of generality and independence is the PayrollDomain component. This component contains the essence of the whole system, yet it depends upon nothing! Examine this component carefully. It contains Employee, PaymentClassification, PaymentMethod, PaymentSchedule, Affiliation, and Transaction. This component contains all the major abstractions in our model, yet it has no dependencies. Why? Because all the classes it contains are abstract.
Consider the Classifications component, which contains the three derivatives of PaymentClassification, along with the ChangeClassificationTransaction class and its three derivatives, as well as TimeCard and SalesReceipt. Note that any change made to these nine classes is isolated; other than TextParser, no other component is affected! Such isolation also holds for the Methods component, the Schedules component and the Affiliations component. This is quite a bit of isolation.
Note that the bulk of the detailed code that will eventually be written is in components that have few or no dependents. Since almost nothing depends on them, we call them irresponsible. The code within those components is tremendously flexible; it can be changed without affecting many other parts of the project. Note also that the most general packages of the system contain the least amount of code. These components are heavily depended on but depend on nothing. Since many components depend on them, we call them responsible, and since they don’t depend upon anything, we call them independent. Thus, the amount of responsible code (i.e., code in which changes would affect lots of other code) is very small. Moreover, that small amount of responsible code is also independent, which means that no other modules will induce it to change. This upside-down structure, with highly independent and responsible generalities at the bottom and highly irresponsible and dependent details at the top, is the hallmark of object-oriented design.
Compare Figure 30-1 with Figure 30-2. Note that the details at the bottom of Figure 30-1 are independent and highly responsible. This is the wrong place for details! Details should depend on the major architectural decisions of the system and should not be depended on. Note also that the generalities—the components that define the architecture of the system—are irresponsible and highly dependent. Thus, the components that define the architectural decisions depend on, and are thus constrained by, the components that contain the implementation details. This is a violation of SAP. It would be better if the architecture constrained the details!
Applying the Reuse/Release Equivalence Principle (REP)
What portions of the payroll application can we reuse? Another division of our company wanting to reuse our payroll system but having a different set of policies could not reuse Classifications, Methods, Schedules, or Affiliations but could reuse PayrollDomain, PayrollApplication, Application, PayrollDatabase, and, possibly, PDImplementation. On the other hand, another department wanting to write software that analyzed the current employee database could reuse PayrollDomain, Classifications, Methods, Schedules, Affiliations, PayrollDatabase, and PDImplementation. In each case, the granule of reuse is a component.
Seldom, if ever, would only a single class from a component be reused. The reason is simple: The classes within a component should be cohesive. That is, that they depend on one another and cannot be easily or sensibly separated. It would make no sense, for example, to use the Employee class without using the PaymentMethod class. In fact, in order to do so, you would have to modify the Employee class so that it did not contain a PaymentMethod instance. Certainly, we don’t want to support the kind of reuse that forces us to modify the reused components. Therefore, the granule of reuse is the component. This gives us another cohesion criterion to use when trying to group classes into components: The classes should not only be closed together but also reusable together in conformance with REP.
Consider again our original component diagram in Figure 30-1. The components that we might like to reuse, such as Transactions or PayrollDatabase, are not easily reusable, because they drag along a lot of extra baggage. The PayrollApplication component depends on everything. If we wanted to create a new payroll application that used a different set of schedule, method, affiliation, and classification policies, we would not be able to use this package as a whole. Instead, we would have to take individual classes from PayrollApplication, Transactions, Methods, Schedules, Classifications, and Affiliations. By disassembling the components in this way, we destroy their release structure. We cannot say that release 3.2 of PayrollApplication is reusable.
Since Figure 30-1 violates CRP, the reuser, having accepted the reusable fragments of our various components, will not be able to depend on our release structure. By reusing the PaymentMethod class, the reuser is affected by a new release of Methods. Most of the time, the changes will be to classes not being reused, yet the reuser must still track our new release number and probably recompile and retest the code.
This will be so difficult to manage that the reuser’s most likely strategy will be to make a copy of the reusable components and evolve that copy separately from ours. This is not reuse. The two pieces of code will become different and will require independent support, effectively doubling the support burden.
These problems are not exhibited by the structure in Figure 30-2. The components in that structure are easier to reuse. PayrollDomain does not drag along much baggage. It is reusable independently of any of the derivatives of PaymentMethod, PaymentClassification, PaymentSchedule, and so on.
The astute reader will notice that the component diagram in Figure 30-2 does not completely conform to CRP. Specifically, the classes within PayrollDomain do not form the smallest reusable unit. The Transaction class does not need to be reused with the rest of the component. We could design many applications that access the Employee and its fields but never use a Transaction.
This suggests a change to the component diagram, as shown in Figure 30-3. This separates the transactions from the elements they manipulate. For example, the classes in the MethodTransactions component manipulate the classes in the Methods component.
Figure 30-3. Updated payroll component diagram
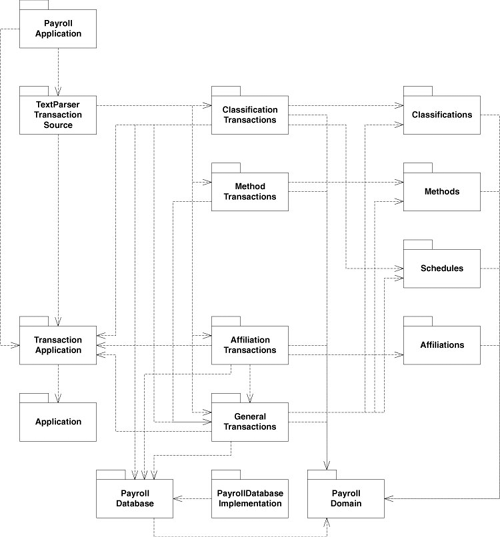
We have moved the Transaction class into a new component, named TransactionApplication, which also contains TransactionSource and a class named TransactionApplication. These three form a reusable unit. The PayrollApplication class has now become the grand unifier. It contains the main program and also a derivative of TransactionApplication, called PayrollApplication, which ties the TextParserTransactionSource to the TransactionApplication.
These manipulations have added yet another layer of abstraction to the design. The TransactionApplication component can now be reused by any application that obtains Transactions from a TransactionSource and then Executes them. The PayrollApplication component is no longer reusable, since it is extremely dependent. However, the TransactionApplication component has taken its place and is more general. Now, we can reuse the PayrollDomain component without any Transactions.
This certainly improves the reusability and maintainability of the project, but the cost is five extra components and a more complex dependency architecture. The value of the trade-off depends on the type of reuse that we might expect and the rate at which we expect the application to evolve. If the application remains stable and few clients reuse it, perhaps this change is overkill. On the other hand, if many applications will reuse this structure or if we expect the application to experience many changes, perhaps the new structure would be superior; it’s a judgment call, and it should be driven by data rather a speculation. It is best to start simple and grow the component structure as necessary. Component structures can always be made more elaborate, if necessary.
Coupling and Encapsulation
Just as the coupling among classes is managed by encapsulation boundaries in C#, so the couplings among components can be managed by declaring the classes within them public or private. If a class within one component is to be used by another component, that class must be declared public. A class that is private to a component should be declared internal.
We may want to hide certain classes within a component to prevent afferent couplings. Classifications is a detailed component that contains the implementations of several payment policies. In order to keep this component on the main sequence, we want to limit its afferent couplings, so we hide the classes that other packages don’t need to know about.
TimeCard and SalesReceipt are good choices for internal classes. They are implementation details of the mechanisms for calculating an employee’s pay. We want to remain free to alter these details, so we need to prevent anyone else from depending on their structure.
A quick glance at Figures 27-7 through 27-10 and Listing 27-10 shows that the TimeCardTransaction and SalesReceiptTransaction classes already depend on TimeCard and SalesReceipt. We can easily resolve this problem, however, as shown in Figures 30-4 and 30-5.
Figure 30-4. Revision to TimeCardTransaction to protect TimeCard privacy

Figure 30-5. Revision to SalesReceiptTransaction to protect SalesReceipt privacy
Metrics
As we showed in Chapter 28, we can quantify the attributes of cohesion, coupling, stability, generality, and conformance to the main sequence with a few simple metrics. But why should we want to? To paraphrase Tom DeMarco: You can’t manage what you can’t control, and you can’t control what you don’t measure.1 To be effective software engineers or software managers, we must be able to control software development practice. If we don’t measure it, however, we will never have that control.
By applying the heuristics that follow, and by calculating some fundamental metrics about our OODs, we can begin to correlate those metrics with measured performance of the software and of the teams that develop it. The more metrics we gather, the more information we will have, and the more control we will eventually be able to exert.
The metrics we describe have been successfully applied to a number of projects since 1994. Several automatic tools will calculate them for you, and they are not difficult to calculate by hand. It is also not difficult to write a simple shell, Python, or Ruby script to walk through your source files and calculate them.2
• H (relational cohesion) can be represented as the average number of internal relationships per class in a component. Let R be the number of class relationships that are internal to the component (i.e., that do not connect to classes outside the component. Let N be the number of classes within the component). The extra 1 in the formula prevents H = 0 when N = 1 and represents the relationship that the package has to all its classes:
![]()
• Ca (afferent coupling) can be calculated as the number of classes from other components that depend on the classes within the subject component. These dependencies are class relationships, such as inheritance and association.
• Ce (efferent coupling) can be calculated as the number of classes in other components that the classes in the subject component depend on. As before, these dependencies are class relationships.
• A (abstractness, or generality) can be calculated as the ratio of the number of abstract classes or interfaces in the component to the total number of classes and interfaces in the component.3 This metric ranges from 0 to 1.
![]()
• I (instability) can be calculated as the ratio of efferent coupling to total coupling. This metric also ranges from 0 to 1.
![]()
• D (distance from the main sequence) = |(A + I -1) ÷ D2|. The main sequence is idealized by the line A + I = 1. The formula calculates the distance of any particular component from the main sequence. It ranges from ~.7 to 0; the closer to 0, the better.4
![]()
• D′ (normalized distance from the main sequence) represents the D metric normalized to the range [0,1]. It is perhaps a little more convenient to calculate and to interpret. The value 0 represents a component that is coincident with the main sequence. The value 1 represents a component that is as far from the main sequence as is possible.
D′= |A + I - 1|
Applying the Metrics to the Payroll Application
Table 30-1 shows how the classes in the payroll model have been allocated to components. Figure 30-6 shows the component diagram for the payroll application with all the metrics calculated. And Table 30-2 shows all of the metrics calculated for each component.
Table 30-1. Class Allocation to Component
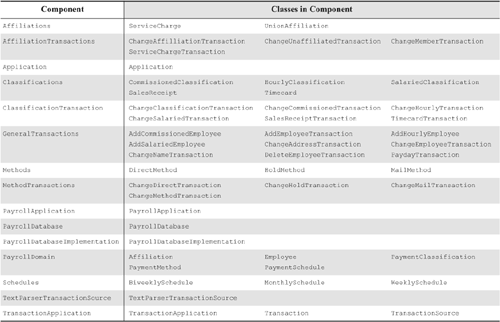
Figure 30-6. Component diagram with metrics
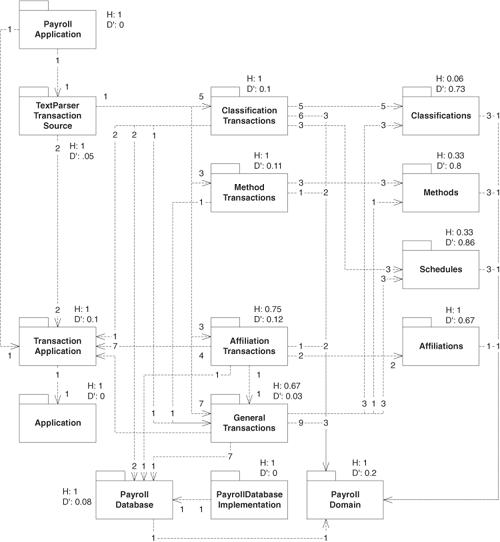
Table 30-2. Metrics for Each Component Q

Each dependency in Figure 30-6 is adorned with two numbers. The number closest to the depender represents the number of that component’s classes that depend on the dependee. The number closest to the dependee represents the number of that component’s classes that the depender component depends on.
Each component in Figure 30-6 is adorned with the metrics that apply to it. Many of these metrics are encouraging. PayrollApplication, PayrollDomain, and PayrollDatabase, for example, have high relational cohesion and are either on or close to the main sequence. However, the Classifications, Methods, and Schedules components show generally poor relational cohesion and are almost as far from the main sequence as is possible!
These numbers tell us that the partitioning of the classes into components is weak. If we don’t find a way to improve the numbers, the development environment will be sensitive to change, which may cause unnecessary rerelease and retesting. Specifically, we have low-abstraction components, such as ClassificationTransaction, depending heavily on other low-abstraction components, such as Classifications. Classes with low abstraction contain most of the detailed code and are therefore likely to change, which will force rerelease of the components that depend on them. Thus, the ClassificationTransaction component will have a very high release rate since it is subject to both its own high change rate and that of Classifications. As much as possible, we would like to limit the sensitivity of our development environment to change.
Clearly, if we have only two or three developers, they will be able to manage the development environment in their heads, and the need to maintain components on the main sequence, for this purpose, will not be great. The more developers there are, however, the more difficult it is to keep the development environment sane. Moreover, the work required to obtain these metrics is minimal compared to the work required to do even a single retest and rerelease.5 Therefore, it is a judgment call as to whether the work of computing these metrics will be a short-term loss or gain.
Object Factories
Classifications and ClassificationTransaction are so heavily depended on because the classes within them must be instantiated. For example, the TextParserTransactionSource class must be able to create AddHourlyEmployeeTransaction objects; thus, there is an afferent coupling from the TextParserTransactionSource package to the ClassificationTransactions package. Also, the ChangeHourlyTransaction class must be able to create HourlyClassification objects, so there is an afferent coupling from ClassificationTransaction to Classifications.
Almost every other use of the objects within these components is through their abstract interface. Were it not for the need to create each concrete object, the afferent couplings on these components would not exist. For example, if TextParserTransactionSource did not need to create the different transactions, it would not depend on the four packages containing the transaction implementations.
This problem can be significantly mitigated by using the FACTORY pattern. Each component provides an object factory that is responsible for creating all the public objects within that package.
The object factory for TransactionImplementation
Figure 30-7 shows how to build an object factory for the TransactionImplementation component. The TransactionFactory component contains the abstract base class, which defines the abstract methods that represent the constructors for the concrete transaction objects. The TransactionImplementation component contains the concrete derivative of the TransactionFactory class and uses all the concrete transactions in order to create them.
Figure 30-7. Object factory for transactions

The TransactionFactory class has a static member declared as a TransactionFactory pointer. This member must be initialized by the main program to point to an instance of the concrete TransactionFactoryImplementation object.
Initializing the factories
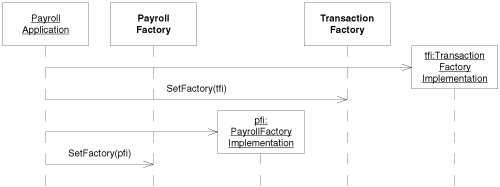
If other factories are to create objects using the object factories, the static members of the abstract object factories must be initialized to point to the appropriate concrete factory. This must be done before any user attempts to use the factory. The best place to do this is usually the main program, which means that the main program depends on all the factories and on all the concrete packages. Thus, each concrete package will have at least one afferent coupling from the main program. This will force the concrete package off the main sequence a bit, but it cannot be helped.6 It means that we must rerelease the main program every time we change any of the concrete components. Of course, we should probably rerelease the main program for each change anyway, since it will need to be tested regardless. Figures 30-8 and 30-9 show the static and dynamic structure of the main program in relation to the object factories.
Figure 30-8. Static structure of main program and object factories

Figure 30-9. Dynamic structure of main program and object factories
Rethinking the Cohesion Boundaries
We initially separated Classifications, Methods, Schedules, and Affiliations in Figure 30-1. At the time, it seemed like a reasonable partitioning. After all, other users may want to reuse our schedule classes without reusing our affiliation classes. This partitioning was maintained after we split out the transactions into their own components, creating a dual hierarchy. Perhaps this was too much. The diagram in Figure 30-6 is very tangled.
A tangled package diagram makes the management of releases difficult if it is done by hand. Although component diagrams would work well with an automated project-planning tool, most of us don’t have that luxury. Thus, we need to keep our component diagrams as simple as is practical.
In my view, the transaction partitioning is more important than the functional partitioning. Thus, we will merge the transactions into a single TransactionImplementation component. We will also merge the Classifications, Schedules, Methods, and Affiliations components into a single PayrollImplementation package.
The Final Packaging Structure
Table 30-3 shows the final allocation of classes to components. Table 30-4 contains the metrics spreadsheet. Figure 30-10 shows the final component structure, which uses object factories to bring the concrete components near the main sequence
Table 30-3. Final Allocation of Classes to Components
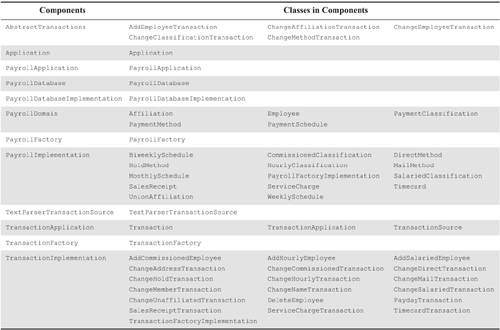
Table 30-4. Metrics Spreadsheet

Figure 30-10. Final payroll component structure
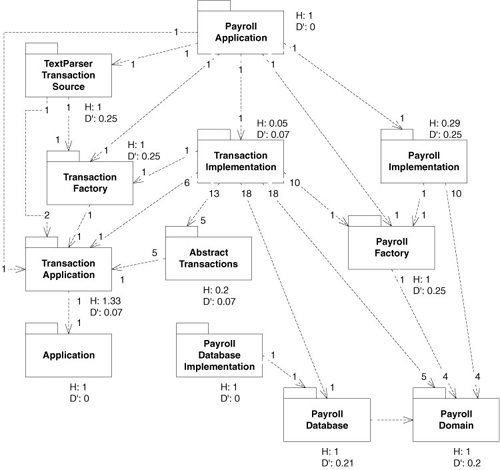

The metrics on this diagram are heartening. The relational cohesions are all very high, thanks in part to the relationships of the concrete factories to the objects they create, and there are no significant deviations from the main sequence. Thus, the couplings between our components are appropriate to a sane development environment. Our abstract components are closed, reusable, and heavily depended on but have few dependencies of their own. Our concrete components are segregated on the basis of reuse, are heavily dependent on the abstract components, and are not heavily depended on themselves.
Conclusion
The need to manage component structures is a function of the size of the program and the size of the development team. Even small teams need to partition the source code so that team members can stay out of one another’s way. Large programs can become opaque masses of source files without some kind of partitioning structure. The principles and metrics described in this chapter have helped me, and many other development teams, manage their component dependency structures.
Bibliography
[Booch94] Grady Booch, Object-Oriented Analysis and Design with Applications, 2d ed., Addison-Wesley, 1994.
[DeMarco82] Tom DeMarco, Controlling Software Projects, Yourdon Press, 1982.