In a master/slaves scenario, there are two types of Solr servers: an indexer (the master) and one or more searchers (the slaves).
The master is the server that manages the index. It receives update requests and applies those changes. A searcher, on the other hand, is a Solr server that exposes search services to external clients.
The index, in terms of data files, is replicated from the indexer to the searcher through HTTP by means of a built-in RequestHandler that must be configured on both the indexer side and searcher side (within the solrconfig.xml configuration file).
On the indexer (master), a replication configuration looks like this:
<requestHandler
name="/replication"
class="solr.ReplicationHandler">
<lst name="master">
<str name="replicateAfter">startup</str>
<str name="replicateAfter">optimize</str>
<str name="confFiles">schema.xml,stopwords.txt</str>
</lst>
</requestHandler>The replication mechanism can be configured to be triggered after one of the following events:
In the preceding example, we want the index to be replicated after startup and optimize commands. Using the confFiles parameter, we can also indicate a set of configuration files (schema.xml and stopwords.txt, in the example) that must be replicated together with the index.
On the searcher side, the configuration looks like the following:
<requestHandler name="/replication" class="solr.ReplicationHandler"> <lst name="slave"> <str name="masterUrl">http://<localhost>:<port>/solrmaster</str> <str name="pollInterval">00:00:10</str> </lst> </requestHandler>
You can see that a searcher periodically keeps polling the master (the pollInterval parameter) to check whether a newer version of the index is available. If it is, the searcher will start the replication mechanism by issuing a request to the master, which is completely unaware of the searchers.
The replicability status of the index is actually indicated by a version number. If the searcher has the same version as the master, it means the index is the same. If the versions are different, it means that a newer version of the index is available on the master, and replication can start.
Other than separating responsibilities, this deployment configuration allows us to have a so-called diamond architecture, consisting of one indexer and several searchers. When the replication is triggered, each searcher in the ring will receive a whole copy of the index. This allows the following:
- Load balancing of the incoming (query) requests.
- An increment to the availability of the whole system. In the event of a server crash, the other searchers will continue to serve the incoming requests.
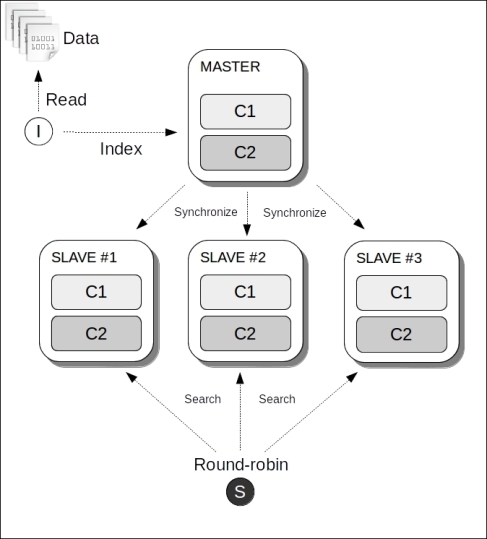
The following diagram illustrates a master/slave deployment scenario with one indexer, three searchers, and two cores:
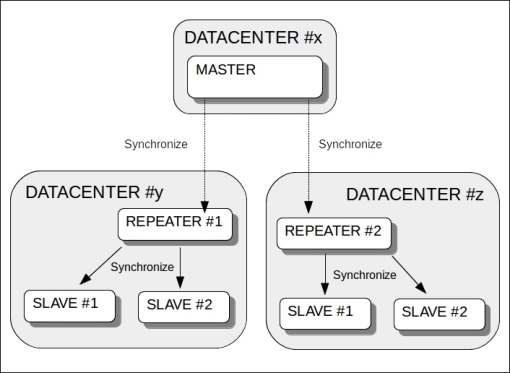
If the searchers are in several geographically dislocated data centers, an additional role called repeater can be configured in each data center in order to rationalize the replication data traffic flow between nodes. A repeater is simply a node that acts as both a master and a slave. It is a slave of the main master, and at the same time, it acts as master of the searchers within the same data center, as shown in this diagram: