Once feature sets get finalized in our last section, what follows is to estimate all the parameters of the selected models, for which we have adopted an approach of using SPSS on Spark and also R notebooks in the Databricks environment, plus MLlib directly on Spark. However, for the purpose of organizing workflows better, we focused our effort on organizing all the codes into R notebooks and also coding SPSS Modeler nodes.
For this project, as mentioned earlier, we will also conduct some exploratory analysis for descriptive statistics and for visualization, for which we can take the MLlib codes and get them implemented directly. Also, with R codes, we obtained quick and good results.
For the best modelling, we need to arrange distributed computing, especially for this case, with various locations in combination with various customer segments.
For this distributed computing part, you need to refer to previous chapters, and we will use SPSS Analytics Server with Apache Spark as well as Databrick's environment.
As we discussed in the Methods for service forecasting section, we will use two methods, regression and decision tree, for the supervised machine learning part. From what you learned so far, for regression, you can complete the model estimation either with SPSS or with R. As for some modelling with random forest, it is better to use R so that you can implement the methods with R codes in the Databricks environment, for which we should refer to Chapter 3, A Holistic View on Spark and Chapter 5, Risk Scoring on Spark.
With the feature list we have from the previous section, we have our target variables of whether or not the subscriber departed and also another target variable of Call Center calls. When modelling subscriber churn, the variable of Call Center calls will also be used as one of the predictors.
For decision tree modelling, the following code in R is what is needed, as we need some R packages:
library(languageR) library(rms) library(Party) data.controls <- cforest_unbiased(ntree=1000, mtry=3) set.seed(47) data.cforest <- cforest(CustomerChurn ~ x + y + z…, data = mob_churn, controls=data.controls)
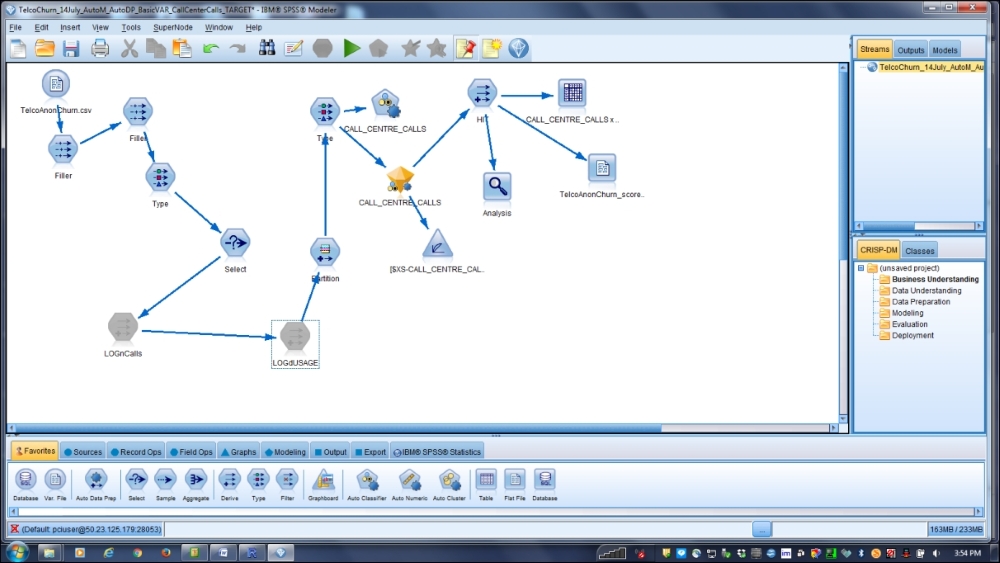
Besides, we used R in the Databricks environment. At the same time, we used the SPSS Modeler to estimate these predictive models, for which we need to use the SPSS Analytics Server. The following screenshot shows the SPSS Modeler with nodes developed: