
Packet String Data
Abstract
This chapter provides an introduction to packet string (PSTR) data and its usefulness in the NSM analytic process. It defines the qualities of PSTR data and how it can be collected manually or using tools like Httpry or Justniffer. While the collection of PSTR data is simple and its utility is limitless, the concept is fairly new, so there aren’t a ton of organizations utilizing this data type just yet. However, with it having the wide contextual breadth of full packet capture and the speed, small storage footprint, and statistical parsing ability of session data, it is the closest solution you’ll find to a suitable middle ground between FPC and session data that is useful in near real-time and retrospective analysis alike. This chapter also covers tools that can be used to parse and view PSTR data, including Logstash and Kibana.
Keywords
Network Security Monitoring; Packet String Data; PSTR; Logstash; Kibana; Justniffer; Httpry; BASH; Dsniff; URLSnarf
Chapter Contents
A dilemma that a lot of NSM teams run into is the inability to effectively search through large data sets in the course of retrospective analysis; that is, analysis on data older than a few days. In what many would consider the “best case scenario”, an organization might be collecting both full packet capture data and session data, but it is likely that the FPC data is only kept for a few days, or a couple of weeks at most.
In this scenario, we have two problems. First, session data lacks the granularity needed to ascertain detailed information about what occurred in network traffic. Second, FPC data has such large storage requirements that it simply isn’t reasonable to store enough of it to be able to perform retrospective analysis effectively.
This leaves us in a scenario where we must examine data older than our FPC data retention period, and where the session data that is available will leave a lot of unanswered questions. For instance, with only session data available, the following common retrospective analysis scenarios wouldn’t be possible:
• Locating a unique HTTP User Agent that is associated with a newly attributed adversary
• Determine which users received a phishing e-mail that recently resulted in a compromise
• Searching for file download activity occurring after a newly identified and potentially malicious HTTP requests
One answer to this predicament is the collection of packet string data, or PSTR data (pronounced pee-stur), which is what this chapter is dedicated to. In this chapter, we will look at the defining qualities of PSTR data and how it can be collected manually or using tools like Httpry or Justniffer. While the collection of PSTR data is simple and its utility is limitless, the concept is fairly new, so there aren’t a ton of organizations utilizing this data type just yet. However, with it having the wide contextual breadth of full packet capture and the speed, small storage footprint, and statistical parsing ability of session data, it is the closest solution you’ll find to a suitable middle ground between FPC and session data that is useful in near real-time and retrospective analysis alike.
Defining Packet String Data
Packet String Data is a term that is generally defined by the way you choose to use it. Loosely, it is a selection of important human-readable data that is derived from full packet capture data. This data can appear in many different forms. For instance, some SOCs choose to generate PSTR data that is specifically formatted to present header data from common application layer protocols (such as HTTP or SMTP), without unnecessary payload data involved. I carefully use the term “unnecessary” because in the analysis of PSTR data, the idea is not to extract files or analyze traffic byte by byte. The goal is to enable the analyst to get a snapshot view of the data to answer questions that might arise in retrospective analysis. An example of this type of PSTR data is shown in Figure 6.1.

The example in Figure 6.1 represents data commonly accessed by analysts for use in retrospective analysis. Here there are two PSTR records showing the full HTTP request and response headers for an individual HTTP communication sequence. This is a fairly robust implementation where a great deal of the application layer header information is stored. Figure 6.2 shows an example where only a single field is stored.
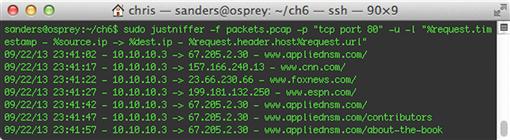
In this example, the PSTR data implementation only stores HTTP URL requests. While many organizations initially choose to store PSTR data for retrospective analysis, this example represents data that is collected on a near real-time basis. This allows the data to have multiple uses, including being more efficiently used by automated reputation detection mechanisms, discussed in Chapter 8. This can be much faster than attempting the same task while parsing FPC data.
A third common implementation of PSTR data is a payload focused deployment, and is concentrated entirely on the packet payload data occurring after the application layer protocol header. This data includes a limited number of non-binary bytes from the payload, which might provide a snapshot into the packet’s purpose. In simpler terms, think of it as running the Unix strings tool against packet capture data. Figure 6.3 shows an example of this type of data.
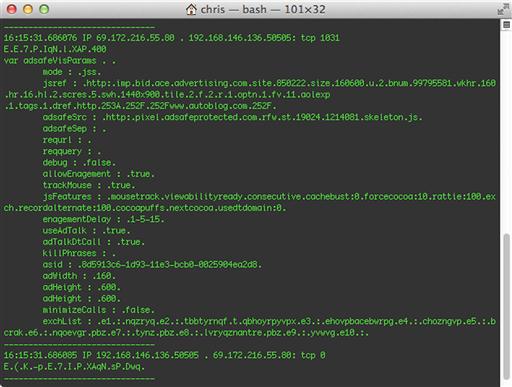
The data shown in Figure 6.3 is a snapshot of the human readable data from a user’s web browsing. Specifically, you can see the content of the page being visited without too much additional detail. This is efficient for data storage because unreadable characters aren’t stored. The disadvantage of using payload style PSTR data is the overhead required to generate it. Further, there is a fair amount of excess data that comes along with it. Just because a byte can be translated into a readable ASCII character doesn’t mean it necessarily makes sense. You can see this with the collection of random stray characters in the Figure above. The storage of these additional, but not very useful bytes, can become burdensome. Lastly, there are few streamlined ways of generating payload style PSTR data, so you will almost certainly be relying on a collection of custom written scripts and other utilities to generate it. Because of this, the overall efficiency might not be up to par when compared to other types of data generated by more refined tools. In regard to multiline PSTR formats, the best bang for your buck is usually to opt for a log style format, such as that for request and response headers seen in Figure 6.1.
PSTR Data Collection
We’ve already discussed FPC data at length, and with that in mind, you might consider PSTR data to be “partial packet capture.” Because of this, it should come as no surprise that some organizations choose to generate PSTR data from FPC data that has already been collected. In contrast to this, it is also possible to collect PSTR data directly from the monitoring port on a sensor, in a manner similar to the way that FPC is collected.
Regardless of whether you choose to collect PSTR data from the wire, or generate it from FPC data, it is beneficial to perform this kind of collection from the same source that you’re gathering other data from, which is the NSM sensor. This helps avoid data correlation errors with other data types during analysis. For instance, I’ve encountered some organizations that choose to generate PSTR data for HTTP communication from web content filtering devices. This can create a scenario where the segment that the web content filter is watching is not in the scope of the NSM visibility window analysts are concerned with, and thus, can’t be used to enhance the analysis process. In addition, when you collect or generate PSTR data from your NSM sensor, you are ultimately in control of it. If you choose to generate this data from another device, especially those provided by third-party vendors, you would be required to accept only the data the vendor makes available, which might be subject to some additional parsing which isn’t entirely clear. As with all NSM data, you should maintain a paranoid level of vigilance with how your data is created and parsed.
Before we start collecting or generating PSTR data, a few items must be considered. First, you must consider the extent of the PSTR data you wish to collect. The ideal solution is one that focuses on collecting as much essential application layer data from clear text protocols as long-term storage will permit. Since there are multiple variations of PSTR data that can be collected, the amount of storage space that this data will utilize is wildly variable. Thus, you should utilize some of the methods discussed in Chapter 3 to determine how much storage you can expect to be utilized by PSTR data, based upon the data format you’ve selected and the makeup of your network assets. This requires that you deploy a temporary sensor with PSTR data collection/generation tools installed on it so that you can sample data at multiple time intervals, and extrapolate that data over longer time periods. This may result in changing the extent of the PSTR data you wish to store in order to be able to retain this data for a longer time.
In parallel with determining the type of PSTR data you will create, you should also consider the time period for which it is retained. FPC data retention is often thought of in terms of hours or days, while session data retention is often thought of in terms of quarter years or years. PSTR data should fall somewhere in between, and should be thought of in terms of weeks or months to fill the void between FPC and session data.
When assessing the storage needs for PSTR data, you should take into account that it is wildly variable. For instance, during lunch time, you might see that the amount of HTTP traffic is at a peak and the amount of traffic generated from other protocols more closely associated with business processes has dipped. This might not impact the total amount of PCAP data being collected during this time period, but it will noticeably increase the amount of PSTR data being collected.
There are a number of free and open source applications that can perform both collection of PSTR data from the wire and generation of the data from FPC data. No matter how you choose to generate this data, it must be functional. When evaluating a PSTR data collection or generation solution, you should ensure that the resulting data is standardized such that it is usable in relation to your detection and analysis tools and processes. In the remainder of this section we will look at some of these tools.
Manual Generation of PSTR Data
Before we look at some tools that can be used to automatically generate PSTR data, let’s look at some alternative ways of generating PSTR data by utilizing tools built into the Linux BASH environment. To generate a baseline, we start by parsing the ASCII data from a PCAP file. With PSTR data, the only data you care to see are collections of human readable characters, so we limit our results by piping the data through the Linux utility “strings”. From here, there are multiple variations of data that you can choose to generate, depending on whether you want to generate log or payload style PSTR data.
The log style script below will generate data similar to that show in Figure 6.2, with single line logs detailing the URI associated with the user’s request.
#!/bin/bash
#Send the ASCII from the full packet capture to stdout
/usr/sbin/tcpdump -qnns 0 -A -r test.pcap |
#Normalizes the PCAP
strings |
#Parse out all timestamp headers and Host fields
grep -e '[0-9][0-9]:[0-9][0-9]:[0-9][0-9].[0-9]{6}|Host:'| grep -B1 “Host:” |
#Clean up the results
grep -v -- “--"| sed 's/(Host.*$)/1 /g'|
tr “ ” “-” | sed 's/--/ /g'| sed 's/-Host:/ -/g'
The payload style script below will generate multiline PSTR log data delimited by a series of dashes. This example extracts all readable strings from all protocols. There are currently few ways to generate this type of data outside of manually generating it.
#!/bin/bash
#Send the ASCII from the full packet capture to stdout
/usr/sbin/tcpdump -qnns 0 -A -r test.pcap |
#Normalizes the PCAP
strings |
#Remove all empty lines
sed '/^$/d' |
#Splits each record with an empty line
sed '/[0-9][0-9]:[0-9][0-9]:[0-9][0-9].[0-9]{6} IP [0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}/{x;p;x;}' |
#Adds a delimiter between records by replacing the empty lines
sed 's/∧$/-------------------------------/g' |
#Removes duplicate special characters
sed 's/[∧[:alnum:][:space:]_():-]+/./g'
While manual solutions are generally slower in processing data, there is no limit to the amount of customization you can perform on that incoming data. Now we will look at some tools that can be used to efficiently generate log style PSTR data.
URLSnarf
The Dsniff suite is a collection of tools that can be useful for network security purposes. The collection of Dsniff tools can be separated into two classifications. Some of these tools are used for more offensive purposes, while the rest, and most significant for our purposes, are the snarf tools that are used to passively monitor the network for interesting information pertaining to files, emails, web requests and more. The tool that we are most interested in for this book is URLsnarf.
URLsnarf passively collects HTTP request data and stores it in common log format (CLF). The Dsniff suite holds a special place in my heart because its tools have been around for a long time, and due to the simplicity of installation and execution of all its tools. URLsnarf is no exception. In the most scenarios, you can install the Dsniff suite via your favorite package management solution. The Dsniff tool suite is not installed on Security Onion by default, so if you wish to use it you can install it with apt:
sudo apt-get install dsniff
With the Dsniff tools installed, you can verify the installation of URLsnarf by running the command with no arguments. Upon execution with no parameters specified, URLsnarf will passively listen on an interface and dump collected data to standard output, visible in your terminal window. By default, it will listen on interface eth0 and it is hardcoded to sniff for traffic on TCP port 80, 8080 and 3128.
URLsnarf only contains 4 options;
• -p: Allows the user to run URLsnarf against an already captured PCAP file
• -i: Specify a network interface
• -n: Parse data without resolving addresses DNS addresses
• -v < expression >: By default, you can specify a specific URL as an expression at run time to display only URLs matching that expression. The –v option allows you to specify an expression that will result in displaying all results that do NOT match the stated URL.
Due to the standard log output, I find it easier to parse the output by piping it to BASH command line tools such as grep, cut, and awk rather than specifying the expressions with the –v option. In Figure 6.4 below, I first captured the traffic using tcpdump and then fed it to URLsnarf with the -p option. Though reading from PCAP with tcpdump is not a requirement, it is likely that you will be utilizing existing FPC data in a production environment. By leaving off the -p option, you will be reading data off the wire.
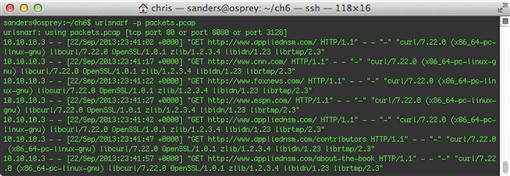
The output shown in Figure 6.4 is a set of standardized logs detailing the HTTP requests from my visit to appliednsm.com. At first glance, the usefulness of this tool is limited to storing logs for retrospective analysis. However, with a careful application of command line kung-fu, this output can translate into serious on-the-fly examination of user traffic across a large network.
While URLsniff is incredibly simple to use, this simplicity can cause problems. If you desire less verbosity in its output, then the data must be manipulated with an external tool. If you desire more verbose output, you are out of luck; URLsnarf will not allow for multiline data output like some other tools do.
Httpry
Httpry is a specialized packet sniffer for displaying and logging HTTP traffic. As you might ascertain from its name, httpry can only parse HTTP traffic. Unlike URLsnarf however, httpry has a lot more options when dealing with the data it can collect, parse, and output. It will allow for the capture and output of any HTTP header in any order. It is the ability to customize the output of each of these tools that make it useful in generating PSTR data that is useful in your environment. Due to the increased amount of customization and post processing that can be performed, the learning curve for httpry is a bit steeper than something like URLsnarf.
Httpry is not included on Security Onion by default, but can be installed fairly easily by building the application from source. In order to do this, you will complete the following steps:
1. Install the libpcap development library, a prerequisite for compiling Httpry
sudo apt-get install libpcap-dev
2. Download the tarball from Jason Bittel’s Httpry website
wget http://dumpsterventures.com/jason/httpry/httpry-0.1.7.tar.gz
3. Extract the archive
tar -zxvf httpry-0.1.7.tar.gz
4. Change into the Httpry directory and then make and install the application
make && sudo make install
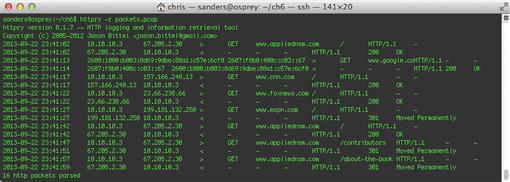
Once installation is completed, you can run the program with no arguments to start gathering HTTP traffic from port 80 on the lowest numbered network interface. In Figure 6.5 below, we show httpry reading traffic from a file using the –r argument and generating output.
Httpry provides several command line arguments, but here are a few of the most useful for getting started:
• -r < file >: Read from an input PCAP file instead of performing a live capture
• -o < file >: Write to an httpry log file (needed for parsing scripts)
• -i < interface >: Capture data from a specified interface
• -q: Run in quiet-mode, suppress non-critical output such as banners and statistics
The default logging format for httpry isn’t always the ideal output for parsing in every environment. Fortunately, with very little command line magic, this data can be converted into something more easily parseable for detection mechanisms and analysis tools. Httpry has several built-in scripts that can manipulate the output to allow better analysis of the data output. By using the -o switch, you can force the data collected by httpry to be output by one of these plugins. Some of these plugins include the ability to output hostname statistics, HTTP log summary information, and the ability to convert output to common log formats, allowing you to generate similar results to what you would have seen from URLsnarf. You’ll notice that the fields are slightly different from URLsnarf output, and due to common log format varying slightly, parsers might see differences.
The ability to create parsing scripts allows for seamless integration of plugins that can automate a PSTR data solution based on httpry. To do the conversions, it requires a separate script called parse_log.pl. This script is located in the httpry scripts/plugins/ directory, and works by utilizing the plugins stored in that directory. As an example, the commands shown below can be utilized for a single parsing script. In this case, we are using the common log format for producing httpry data in a format that is versatile for parsing by detection and analysis tools.
1. Run Httptry and direct the output to a file
httpry –o test.txt
2. Parse the Output
perl scripts/parse_log.pl -p scripts/plugins/common_log.pm test.txt
This command works in a bit of an unexpected manner. If you attempt to generate output with httpry and then pipe it to something that modifies its output, the process will fail due to the lack of proper column headers. Instead, the httpry output must be written to a file first with the -o option. Then, the parse_log.pl script can be executed to parse the data. An example of this output is shown in Figure 6.6.

Generating PSTR data with httpry is typically significantly faster than using URLsnarf to perform the same task. With that said, it is really the flexibility of data output that makes httpry a nice solution for many NSM environments.
Justniffer
Justniffer is a full-fledged protocol analysis tool that allows for completely customizable output, making it useful for generating any TCP specific PSTR data beyond only HTTP traffic. Justniffer was primarily developed for streamlining the network troubleshooting process, and to focus on requests and responses in network traffic to provide only pertinent information used in narrowing down communication issues. This, of course, is exactly what we want to do with PSTR data generated for NSM purposes. In addition to capturing clear-text protocol headers, Justniffer can also be enhanced with simple scripts to do things like streaming its output directly from the wire to a local folder, sorted by host, with a BASH script. In another commonly used example; Justniffer includes a Python script called Justniffer-grab-http-traffic, which will extract files transferred during HTTP communication. Justniffer can also be extended to do performance measuring of response times, connection times, and more. The versatility of Justniffer makes it incredibly useful for a variety of PSTR data collection scenarios.
Justniffer is not included on Security Onion by default, so if you want to try it out then you are going to have to install it yourself. This can be done with these steps:
1. Add the appropriate PPA repository
sudo add-apt-repository ppa:oreste-notelli/ppa
2. Update the repository
sudo apt-get update
3. Install Justniffer with APT
sudo apt-get install justniffer
If you are installing Justniffer on a different distribution, the installation process might require additional steps. These installation steps can be found at http://justniffer.sourceforge.net/#!/install.
While getting started with Justniffer is fairly simple, getting the exact output you want can be tricky. With no command line arguments, Justniffer will function by capturing data on interface eth0, and displaying all HTTP traffic in a format nearly identical to the one used by URLsnarf. Justniffer provides some other useful command line arguments:
• -i < interface >: Select an interface to capture traffic on
• -f < file >: Read from a selected PCAP file
• -p < filter >: Apply a packet filter
The output Justniffer generates by default is a good start, but let’s generate some more interesting logs using the original examples in this chapter. If you recall, the first example we discussed was generating full request and response header data for HTTP communications, and was shown in Figure 6.1. Justniffer makes easy work of this with the request.header and response.header format keywords, utilized here:
sudo justniffer -f packets.pcap -p “tcp port 80” -u -l “%newline%request.header%newline%response.header”
In this example we use the -f option to read a packet capture file (this could easily be substituted for –i < interface > to perform this action live from the wire), the -p option to specify a BPF, the -u option to convert unprintable characters to periods (.), and the -l option to specify our own custom log format. The result of this command is shown in Figure 6.7, and displays two HTTP transactions.
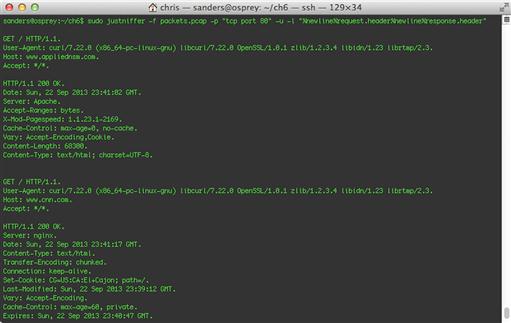
You’ll notice that this example produces similar traffic to that of the original example, but it isn’t entirely useful for analysis due to a critical lack of information. In order to analyze this data appropriately, we need to know the hosts responsible for the communication, and the timestamp indicating when the communication occurred. You have the “what”, but you need the “who” and “when”. We can extend this example by explicitly telling Justniffer to print those fields. Justniffer currently contains 85 different formatting options ranging from simple spacial delimiters to various elemental formatting options relating to requests, responses, and performance measurements. In order to get the formatting we desire, we’re going to need a few more format keywords as well as a custom delimiter at the beginning of each multi-line log. This command is shown here:
sudo justniffer –f packets.pcap -p “tcp port 80” -u -l “------------------------------- %newline%request.timestamp - %source.ip - > %dest.ip %newline%request.ader%newline%response.timestamp - %newline%response.header”
An example of output generated from this command is shown in Figure 6.8.

As you can see, we now have two entire HTTP transactions, complete with the hosts responsible for the communication and a timestamp detailing when the communication happened. We now have the who, the what, and the when. Later we’ll discuss several methods of parsing this data, both with BASH scripts and free open source tools.
We can also use Justniffer to generate data similar to the example shown in Figure 6.2, which is a minimal single line log that shows only the communication timestamp, the source and destination IP address, and the URL requested. Using only a few special delimiters and the request.url variable, we generate this output with the following command:
sudo justniffer –f packets.pcap -p “tcp port 80” -u -l “%request.timestamp - %source.ip - > %dest.ip - %request.header.host%request.url”
The output of this command is shown in Figure 6.9.

Getting this type of output from URLsnarf would take a serious amount of command line kung-fu.
So far, we’ve been focused on HTTP logs because some of these tools are only HTTP aware. Justniffer, however, is a fully functional TCP protocol analyzer, and as such, can parse other non-HTTP traffic with ease. For instance, Justniffer can also be used for pulling clear-text SMTP or POP mail records from FPC data or directly from the wire.
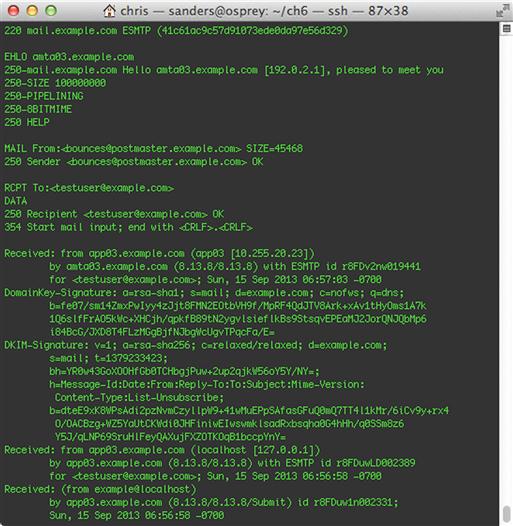
To get results similar to what we’ve already seen, but for SMTP mail data, we can tell Justniffer to look at port 25 traffic with this command:
justniffer -f packets.pcap -r -p “port 25”
An example of this data is shown in Figure 6.10.
Viewing PSTR Data
As with all NSM data, a proper PSTR data solution requires a synergy between the collection and viewing mechanisms. A more customized collection mechanism can require more unique parsing methods. In this section we will examine potential solutions that can be used to parse, view, and interact with PSTR data using several of the data formatting examples we’ve already created.
Logstash
Logstash is a popular log parsing engine that allows for both multi-line and single line logs of various types, including common formats like syslog and JSON formatted logs, as well as the ability to parse custom logs. As a free and open-source tool, it is an incredibly powerful log collector that is relatively easy to set up in large environments. As an example, we will configure Logstash to parse logs that are being collected with URLsnarf. Since Logstash 1.2.1 was released, it includes the Kibana interface for viewing logs, so we’ll also discuss some of its features that can be used for querying the data you need, without getting the data you don’t.
Logstash isn’t included in Security Onion, so if you want to follow along you will need to download it from the project website at www.logstash.net. Logstash is contained entirely in one java package, so you’ll need the Java Runtime Environment (JRE) installed (http://openjdk.java.net/install/, or simply sudo apt-get install java-default). At this point, you can simply execute the program.
In order to parse any type of data, Logstash requires a configuration file that defines how it will receive that data. In a real world scenario, you will probably have a steady stream of data rolling in from a logging source, so in this example, we’ll look at data being written to a specific location. In this example, we’ll call the configuration file urlsnarf-parse.conf. This is a very simple configuration:
input {
file {
type = > “urlsnarf”
path = > “/home/idsusr/urlsnarf.log”
}
}
output {
elasticsearch { embedded = > true }
}
This configuration tells Logstash to listen to data of any kind being written to /home/idsusr/urlsnarf.log and to consider any log written to that file to be a “urlsnarf” type of log, which is the log type we are defining. The output section of this configuration file starts an Elasticsearch instance inside of Logstash to allow for indexing and searching of the received data.
Once we have a configuration file, we can start up Logstash to initiate the log listener for when we start generating data. To begin Logstash with the Kibana web front end enabled, issue this command;
java -jar logstash-1.2.1-flatjar.jar agent -f urlsnarf-parse.conf -- web
The output of this command is shown in Figure 6.11.

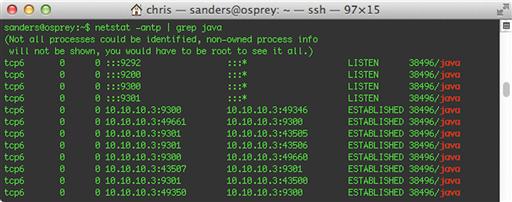
This command will initiate the agent, specifying urlsnarf-parse.conf with the –f option. Ending the command with “ -- web “ will ensure that Kibana is started along with the logging agent. The initial startup can take a minute, and since the Logstash output isn’t too verbose, you can verify that Logstash is running by invoking netstat on the system.
sudo netstat –antp | grep java
If everything is running properly, you should see several ports initiated by the java service opened up. This is shown in Figure 6.12.
Once these are running, go ahead and confirm that the Kibana front end is functioning by visiting http://127.0.0.1:9292 in your web browser, replacing 127.0.0.1 with the IP address of the system you’ve installed Logstash on. This will take you directly to the main Kibana dashboard.
Now that Logstash is listening and the Kibana front-end is functional, you can send data to the file specified in urlsnarf-parse.conf. To create data to parse, you can use your existing installation of the Dsniff tool set and start URLsnarf, sending its output data to a file.
sudo urlsnarf > /home/idsusr/urlsnarf.log
After URLsnarf is initialized, open a web browser (or use curl from the command line) and visit a few sites to generate some data. Once you’ve finished, use Ctrl + C to end the URLsnarf process. After stopping the data collection, go back to the Kibana front end and confirm that logs are arriving in the browser. If they are, you should see some data displayed on the screen, similar to Figure 6.13. If they are not, try making sure you’ve selected the correct time span towards the top of the dashboard.
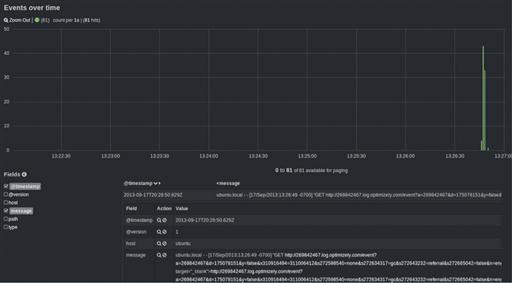
This figure represents “raw” log files that are being ingested, which are for the most part unparsed. So far, if you examine a log, only the timestamp in which it arrived and the hostname of the current device are present. This is because you haven’t specified a filter in the Logstash configuration so that it knows how to parse the individual fields within each log entry. These filters make up the meat of the configuration and define how logs are indexed.
With that said, let’s extend the flexibility of Logstash by defining custom filters to generate stateful information so that Kibana can really stretch its legs. Logstash uses GROK to combine text patterns and regular expressions to match log text in the order that you wish. GROK is a powerful language used by Logstash to make parsing easier than it would normally be when using regular expressions. We will address getting a stateful understanding of the URLsnarf log format shortly, but let’s start with a simpler example in order to understand the syntax. In this example we’ll create a filter that matches text fields in a log that we generated with Justniffer in Figure 6.14, but this time with the addition of a “sensor name” at the end.

To show how Logstash handles basic matches as opposed to prebuilt patterns, we’ll use a “match” filter in the configuration. The basic configuration containing match filters should look like this;
input {
file {
type = > “Justniffer-Logs”
path = > “/home/idsusr/justniffer.log”
}
}
filter {
grok {
type = > “Justniffer-Logs”
match = > [ “message”, “insertfilterhere” ]
}
}
output {
elasticsearch { embedded = > true }
}
We’ll use the existing built-in GROK patterns to generate the data we need for the configuration, which we’ll call justniffer-parse.conf. These patterns can be found at https://github.com/logstash/logstash/blob/master/patterns/grok-patterns. But before we start examining which patterns we want to tie together, the first thing to do is look at the log format and define what fields we want to identify. This data format breaks down like this:
datestamp timestamp – IP - > IP – domain/path – sensorname SENSOR
Now we need to translate this into GROK, which is where the GROK debugger comes in. The debugger is located at http://grokdebug.herokuapp.com/. Here you simply place the log string you want to match in the top line, and in the pattern line enter the GROK pattern you think will match it. The application will show you which data is matched. The key when developing GROK formatted strings is to start with small patterns and extend them gradually to match the entire log line (Figure 6.15).
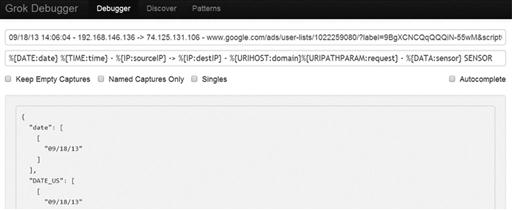
In order to match the log line we are working with, we will use this pattern:
%{DATE:date} %{TIME:time} - %{IP:sourceIP} - > %{IP:destIP} - %{URIHOST:domain}%{URIPATHPARAM:request} - %{DATA:sensor} SENSOR
You’ll notice we included field labels next to each field, which will identify the fields. Applying the filter to the full configuration file gives us a complete configuration that will parse all incoming Justniffer logs matching the format we specified earlier. This is our resulting configuration file:
input {
file {
type = > “Justniffer-Logs”
path = > “/home/idsusr/justniffer.log”
}
}
filter {
grok {
type = > “Justniffer-Logs”
match = > [ “message", “%{DATE:date} %{TIME:time} - %{IP:sourceIP} - > %{IP:destIP} - %{URIHOST:domain}%{URIPATHPARAM:request} - %{DATA:sensor} SENSOR” ]
}
}
output {
elasticsearch { embedded = > true }
}
Once you have this configuration, you can go ahead and start the Logstash collector with this command that uses our new configuration file:
java -jar logstash-1.2.1-flatjar.jar agent -f justniffer-parse.conf --web
When Logstash is up and running, you can start gathering data with the following Justniffer command that will generate log data in the format matching the configuration we’ve just created:
sudo justniffer -p “tcp port 80” -u -l “%request.timestamp - %source.ip - > %dest.ip - %request.header.host%request.url - IDS1 SENSOR” >> /home/idsusr/justniffer.log
Once running, you will once again want to browse to a few websites in order to generate logs. As you gather data, check back into Kibana and see if your logs are showing up. If everything has gone correctly, you should have fully parsed custom logs! Along with viewing these fully parsed logs, you can easily search through them in Kibana’s “Query” field at the bottom of the main dashboard page, or you can narrow down the display parameters to define only the fields you wish to see with the “Fields” Event filter to the left of the query field, shown in Figure 6.16.

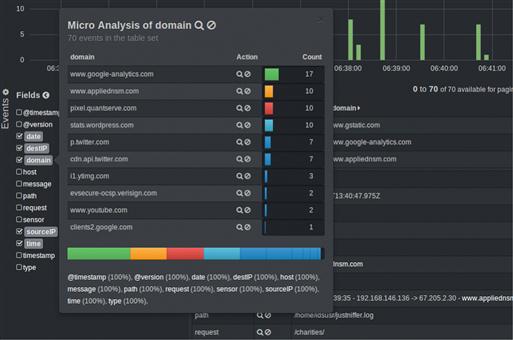
You can also examine metrics for a given field by clicking the field name in the list on the left side of the screen. Figure 6.17 shows field metrics for the Host field, which shows all of the hosts visited in the current logs.
This Justniffer log example provides an excellent way to dive into custom parsing of logs with Logstash. However, some log types will be more extensive and difficult to parse. For instance, if we examine URLsnarf logs, we see that they are nearly identical to Apache access logs, with the exception of a character or two. While Logstash would normally be able to handle Apache access logs with ease, these additional characters can break the built-in filters. For this example, we will look at creating our own GROK filter for replacing the existing filter pattern for Apache access logs in order to adequately parse the URLsnarf logs. Our new filter will take into account the difference and relieve the incongruity created by the additional hyphens. Since the filters are so similar to the built-in pattern, we can manipulate this pattern as needed. The latest GROK patterns can be found at the Logstash GIT repository, https://github.com/logstash/logstash/blob/master/patterns/grok-patterns. If you examine the COMBINEDAPACHELOG filter carefully, you’ll see the issue falls with the lack of a simple hyphen, which has been added below.
COMBINEDAPACHELOG %{IPORHOST:clientip} %{USER:ident} %{USER:auth} [%{HTTPDATE:timestamp}] “(?:%{WORD:verb} %{NOTSPACE:request}(?: HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})” %{NUMBER:response}|- (?:%{NUMBER:bytes}|-) %{QS:referrer} %{QS:agent}
The above filter looks complicated, and that’s because it is. The break down of it is an exercise best left for the GROK debugger. Our changes to the original filter include correcting the hyphen and commented out the inner quotation marks. We can add this GROK filter into the base configuration we created earlier, resulting in this completed configuration file:
input {
file {
type = > “urlsnarf”
path = > “/home/idsusr/urlsnarf.log”
}
}
filter {
grok {
type = > “urlsnarf”
match = > [ “message", “%{IPORHOST:clientip} %{USER:ident} %{USER:auth} [%{HTTPDATE:timestamp}] "(?:%{WORD:verb} %{NOTSPACE:request} (?: HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})” (%{NUMBER:response}|-) (?:%{NUMBER:bytes}|-) %{QS:referrer} %{QS:agent}” ]
}
}
output {
elasticsearch { embedded = > true }
}
Without using a GROK filter, these logs would look like Figure 6.18 in Kibana, with most of the data appearing as a single line that doesn’t allow for any advanced analytics based upon fields.
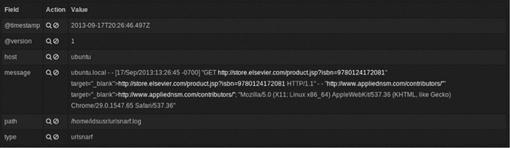
The new log field description is fully parsed using the filter as seen in Figure 6.19.

As you can see, the combination of Logstash, Kibana, and GROK makes a powerful trio that is convenient for parsing logs like the ones generated by PSTR data. If you want to learn more about these tools, you should visit the Logstash website at http://logstash.net/.
Raw Text Parsing with BASH Tools
The combination of Logstash and Kibana is an excellent way to parse single line PSTR data, but those tools might not be the best fit in every environment. Depending on how you are sourcing your data, you might find yourself in need of a broader toolset. Even in cases where log search utilities are present, I always recommend that whenever flat text logs are being used, they should be accessible by analysts directly in some form. In the following examples, we’ll take a look at sample PSTR data that includes multi-line request and response headers.
Earlier we generated PSTR data with Justniffer, and for this example, we will start by doing it again:
sudo justniffer -i eth0 -p “tcp port 80” -u -l “------------------------------- %newline%request.timestamp - %source.ip - > %dest.ip %newline%request.header%newline%response.timestamp - %newline%response.header” > pstrtest.log
This should generate data that looks similar to what is shown in Figure 6.7, and store that data in a file named pstrtest.log.
Parsing raw data with BASH tools such as sed, awk, and grep can sometimes carry a mystical aura of fear that is not entirely deserved. After all, parsing this kind of text is one of the most documented and discussed topics in Unix related forums, and I have yet to come across an unresolvable parsing issue. From the example data above, we can gather a significant amount of useful information for analysis. From a tool perspective, we can search and parse this with grep quite easily. For instance we can search for every Host seen in the data set by performing a simple search for the “Host” field, like this:
cat pstrtest.log | grep “Host:”
This will result in printing every line that contains the word “Host:” in any context, even if it is not the context you wish for. To make sure that it is looking for only lines beginning with the term “Host:”, try extending grep with the –e option and the carrot (∧) symbol:.
cat pstrtest.log | grep -e “∧Host: “
The carrot symbol matches “beginning of a line”, and for every line that has “Host: “ after the beginning of the line, it will match. Currently, this search is case sensitive. To make it case insensitive, add the –i option. Searching with grep is the easiest and most common use for the tool, however, it can be extended to perform powerful regular expression searching, parsing, and massaging of data. For instance, let’s consider searching for Etags of a very specific format, as shown in Figure 6.20.
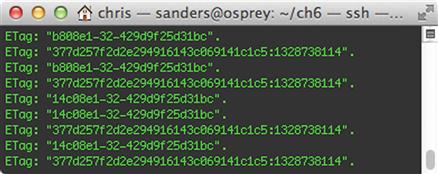
You’ll notice that while most of these entries share similar formats, some will contain additional characters, such having more than one hyphen (-). The fifth line in Figure 6.14 is an example of this, so let’s search for examples matching it. In theory, we are searching for all lines starting with the text “ETag”, and followed by a specific value with two hyphens. We will print only the ETags themselves. The following command will accomplish this goal:
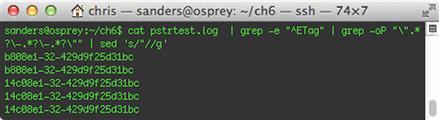
cat pstrtest.log | grep -e “^ETag” | grep -oP “”.*?-.*?-.*?“” | sed 's/“//g'
Despite what appears to be a rather complicated command, it does exactly what we asked. Since this one-liner has multiple elements, let’s break them down individually:
1. cat pstrtest.log
First, we dump to output of the pstrtest.log file to the screen (standard output)
2. grep –e “∧ETag”
Next, we pipe the output of the file to grep, where we search for lines containing the text “ETag” at the beginning of a line.
3. grep -oP “”.*?-.*?-.*?“”
The ETags that are found are piped to another grep command that utilizes a regular expression to locate data in the proper format. This format is any number of characters (.*?) between a quote and a hyphen, followed by any number of characters between that hyphen and another, followed by any number of characters and another quote.
4. sed ‘s/”//g’
Next, we pipe the output of the last Grep command to Sed to remove any quotation marks from the output.
In this example, we introduced Sed into the equation. The sed command is useful for searching and replacing text. In this case, it looks at every line, and replaces every instance of double quotes (“) with nothing. More simply put, it removes all double quotes. The output of this command is shown in Figure 6.21.
Another useful way to massage data is to simply sort and count what you have. This might sound like a simple task, and it is, but it is incredibly useful. For example, let’s take a look at the User Agent string in the HTTP header information that can be contained within PSTR data. We can perform some rudimentary detection by sorting these User Agent strings from least to most visited. This can often times reveal suspicious activity and possible indicators due to user agent strings that are unexpected.
cat pstrtest.log | grep -e “^User Agent: “ | sort | uniq -c | sort –n
In this example we have taken our PSTR data and outputted only lines beginning with “User Agent:”. From here, we pipe this data to the sort command to order the results. This data is then piped to the uniq command, which parses the data by counting each uniq line and providing the total number of times it occurs in a left column. Finally, we pipe that data once more to the sort command and utilize the –n string to sort the data by the count of occurrences. We are left with the data shown in Figure 6.22.
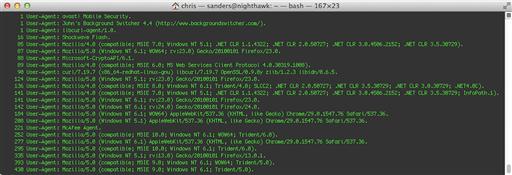
Analyzing this data immediately reveals that a few unique and potentially suspicious user agents exist in this communication. From that point, you could perform a more thorough investigation surrounding this communication. This is an example of generating some basic statistical data from PSTR data.
Conclusion
Packet String Data, in any of its possible forms, is critical for maximizing efficiency in detection and analysis. Given the speed of access, the depth of data, the general ease of deployment, and the lack of intensive storage requirements, PSTR data provides the perfect bridge between FPC and session data. In this chapter we defined PSTR data and discussed a number of ways to collect and parse this data type. In later chapters, we will reference instances in which analysis can be enhanced by referencing PSTR data.