
The Analysis Process
Abstract
The most important component of NSM is the analysis process. This is where the analyst takes the output from a detection mechanism and accesses various data sources to collect information that can help them determine whether something detrimental to the network or the information stored on it has actually happened. The process the analyst goes through in order to accomplish this is called the analysis process.
The final chapter discusses the analysis process as a whole. This begins with a discussion of the analysis process, and then breaks down into examples of two different analysis processes; relational investigation and differential diagnosis. Following this, the lessons learned process of incident morbidity and mortality is discussed. Finally, we will look at several analysis best practices to conclude the book.
Keywords
Network Security Monitoring; Analysis; Intelligence; Analysis Process; Differential Diagnosis; Relational Investigation; Incident Morbidity and Mortality; Best Practices
Chapter Contents
Step One: Investigate Primary Subjects and Perform PreliminarInvestigation of the Complaint
Step Two: Investigate Primary Relationships and Current Interaction
Step Three: Investigate Secondary Subjects and Relationships
Step Four: Investigate Additional Degrees of Subjects Relation
Relational Investigation Scenario
Step One: Identify and List the Symptoms
Step Two: Consider and Evaluate the Most Common Diagnosis First
Step Three: List All Possible Diagnosis for the Given Symptoms
Step Four: Prioritize the List of Candidate Conditions by Their Severity
Step Five: Eliminate the Candidate Conditions, Starting with the Most Severe
Differential Diagnosis Scenarios
Unless You Created the Packet Yourself, There Are No Absolutes
Be Mindful of Your Abstraction from the Data
Two Sets of Eyes are Always Better than One
Never Invite an Attacker to Dance
Analysis is No More About Wireshark than Astronomy is About a Telescope
When you Hear Hoof Beats, Look for Horses – Not Zebras
The most important component of NSM is the analysis process. This is where the analyst takes the output from a detection mechanism and accesses various data sources to collect information that can help them determine whether something detrimental to the network or the information stored on it has actually happened. The process the analyst goes through in order to accomplish this is called the analysis process.
In almost every SOC I’ve visited and with nearly every analyst I’ve spoken to, the analysis process is an ad-hoc, subjective series of loosely defined steps that every individual defines on their own. Of course, everyone has their own individual style and everyone parses information differently, so this is expected to some degree. However, a codified, systematic analysis process on which all analysts can base their efforts is valuable. The adoption of such a process supports faster decision making, more efficient teamwork, and clearer incident reporting. Most of all, it helps an analyst solve an investigation quicker.
In this chapter, we will look at two different analysis methods that can serve as a framework for performing NSM analysis. One of these methods is taken from a system police investigators use to solve criminal investigations, while the other is taken from a process that doctors use to solve medical investigations. As of the writing of this book, a written framework for the NSM analysis process is something I’ve yet to see in existence. Because of that, if you take nothing else from this book, my hope is that this chapter will provide you with the knowledge necessary to apply one of these two analysis methods to your daily analysis process, and that it serves to hone your analysis skills so that you can achieve better, faster, more accurate results in your investigations.
Once we’ve discussed these analysis methods, I will provide a number of analysis best practices that I’ve learned from my own experience as an NSM analyst and from my colleagues. Finally, we will discuss the incident “morbidity and mortality” process, which can be used for refining collection, detection, and analysis after an investigation has concluded.
Analysis Methods
In general, a method is simply a way of doing something. While there are hundreds of ways to do the “something” that is NSM analysis, every analysis process requires three things: an input, an investigation, and an output. The way these things are done and organized is what defines an analysis method, which is simply a systematic approach to determining if an incident has occurred. In this case, the input is usually some type of IDS alert or another anomaly that catches an analyst’s eye, and the output is the decision of whether an incident has occurred. The steps that occur between those two things during the investigation stage are what we are going to talk about here in defining analysis methods.
Relational Investigation
The term “investigation” is most closely associated with a police investigation. This isn’t just because some information security engineer decided to steal this term twenty years ago; it’s because the processes of investigating an information security breach and investigating a crime are quite similar. As a matter of fact, the approach that police investigators often use to get to the bottom of a crime is something we can use as a framework for an analysis method. This is called a relational investigation.
The relational method is based upon defining linear relationships between entities. If you’ve ever seen an episode of “CSI” or “NYPD Blue” where detectives stick pieces of paper to a corkboard and then connect those items with pieces of yarn, then you’ve seen an example of a relational investigation. This type of investigation relies on the relationships that exist between clues and individuals associated with the crime. A network of computers is not unlike a network of people. Everything is connected, and every action that is taken can result in another action occurring. This means that if we as analysts can identify the relationships between entities well enough, we should be able to create a web that allows us to see the full picture of what is occurring during the investigation of a potential incident.
The relational investigation process flows through four steps (Figure 15.1).
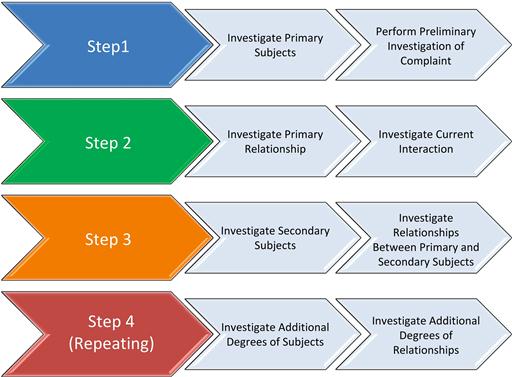
Step One: Investigate Primary Subjects and Perform Preliminary Investigation of the Complaint
In a police investigation, law enforcement is typically notified of an event because of a complaint, which is usually dispatched from the police station. When they receive this complaint, they are given information about the subjects involved with the complaint and the nature of the complaint itself.
When arriving on the scene, the first thing an officer does is identify the subjects involved (the primary subject) and determine if the complaint is worth further investigation. This determination is made based on the law, and the officer’s initial judgement of whether there is the potential for a law to have been broken. If the officer thinks that this potential exists, he will begin collecting information from each of the subjects involved. This might include verifying that they have legitimate identification, viewing the prior criminal history, and performing a pat down to determine if they are in possession of any weapons or illegal items.
In an NSM investigation, the analyst is typically notified of an event by means of alert data, including alerts generated by an IDS. This alert typically includes the hosts involved with the event and the nature of the alert. In this case, the alert is similar to an officer’s complaint, and the hosts are similar to an officer’s subjects. In a similar chain of events, the NSM analyst must make an initial determination of whether the alert is worth further investigation. Usually, this means examining the details of the rule or detection mechanism that caused the generation of the alert, and determining if the traffic associated with it actually matches that alert. Essentially, this is an attempt to quickly determine if a false positive has occurred. If the alert can’t be deemed a false positive, then the analyst’s next step should be to begin collecting information about the primary subjects associated with the alert: the friendly and hostile IP addresses. This includes gathering friendly and tactical threat intelligence like we discussed in Chapter 14.
Step Two: Investigate Primary Relationships and Current Interaction
Once an officer has investigated both subjects, he will investigate the relationship between them. This includes the previous relationship as well as the current interaction. As an example, consider a domestic complaint. The officer will attempt to determine if the two subjects have been in a relationship, the duration of that relationship, if the subjects live together, and so on. Then, the officer will determine what actions occurred that led up to the complaint, when that escalated into the current situation, and what happened afterwards.
The NSM analyst will do the same thing to investigate the primary relationship between the friendly and hostile hosts. They begin by determining the nature of previous communication between the hosts. The following questions might me asked:
• Have these two hosts ever communicated before?
• If yes, what ports, protocols, and services were involved?
Next, the analyst will thoroughly investigate the communication associated with the initial alert. This is where data from multiple sources is retrieved and analyzed to look for connections. This will include actions like:
In some cases the analyst will be able to determine if an incident has occurred at this point. When this happens, the investigation may end here. If the incident is not clearly defined at this point or no concrete determination has been made, then it is time to proceed to the next step.
Step Three: Investigate Secondary Subjects and Relationships
When a police officer is investigating primary subjects and the relationship between them, secondary subjects will often be identified. These are individuals that are related to the complaint in some way, and may include associates of the subject making the complaint, associates of the subject the complaint is made against, or other witnesses. When these subjects are identified, the investigation is typically aided by performing the same investigative steps outlined in the first two steps. This includes an investigation of these subjects, as well as the relationships between them and the primary subjects.
In an NSM investigation, this happens often. For instance, while investigating the relationship between two hosts an analyst may find that the friendly host is communicating with other hostile hosts in the same manner or that the hostile host is communicating with other friendly hosts. Furthermore, analysis of malicious files may yield IP addresses revealing other sources of suspicious communication. These hosts are all considered secondary subjects.
When secondary subjects are identified, they should be investigated in the same manner as primary subjects. Following this, the relationships between secondary subjects and primary subjects should be examined.
Step Four: Investigate Additional Degrees of Subjects Relation
At this point, the investigation of subjects and relationships should repeat as many times as necessary, and may require the inclusion of tertiary and even quaternary subjects. As you go, you should fully evaluate subjects and relationships on a per-level basis, fully exhausting each layer of interaction before moving on to the next. Otherwise, it is easy to get lost down the rabbit hole and miss earlier connections that could impact how you view other hosts. When you are finished, you should be able to describe the relationships between the subjects and how malicious activities have occurred, if at all.
Relational Investigation Scenario
Now that we’ve explained the relational investigation process, let’s go through an example to demonstrate how it might work in a real NSM environment.
Step One: Investigate Primary Subjects and Perform Preliminary Investigation of the Complaint
Analysts are notified that an anomaly was detected with the following Snort alert:
ET WEB_CLIENT PDF With Embedded File
In this alert, the source IP is 192.0.2.5 (Hostile Host A) and the destination IP address is 172.16.16.20 (Friendly Host B). These are the primary subjects. The preliminary examination of the traffic associated with this activity indicates that there does appear to be a PDF file being downloaded. The PCAP data for the communication sequence is obtained, and the PDF is extracted from the file using Wireshark. The MD5 hash of the PDF file is submitted to the Team Cymru Malware Hash Registry, and it determines that 23% of antivirus detection engines think that this file is malicious. Based on this, you should make the decision that further investigation is warranted.
The next step is to gather friendly and tactical threat intelligence related to both hosts. This process determines the following:
Friendly Intelligence for 172.16.16.20:
• This system is a user workstation running Windows 7
• The system has no listening services or open ports
• The user of this system browses the web frequently, and multiple New Asset Notifications exist in PRADS data

Step Two: Investigate Primary Relationships and Current Interaction
In order to investigate the relationship between 172.16.16.20 and 192.0.2.5, the first action that is performed is an analysis of packet data for the communication occurring around the time of the alert. Packet data is downloaded for communication between these two hosts with the time interval set to retrieve data from 10 minutes before the alert happened to 10 minutes after the alert happened. After performing packet analysis on this data, it is determined that the friendly host was redirected to the malicious host from a third-party advertisement on a legitimate website. The friendly host downloaded the file, and the communication with the hostile host ceased.
The next step taken to investigate the relationship between 172.16.16.20 and 192.0.2.5 is to inspect the PDF file that was downloaded. This PDF file is submitted to a Cuckoo sandbox in order to perform automated malware analysis. The behavioral analysis of this file indicates that this PDF contains an executable file. The executable file contains the IP address 192.0.2.6 hard coded in its configuration. No other information was able to be determined from the malware analysis of these files.
At this point, you’ve exhausted your investigation of the primary subjects and the relationship between them. While everything points to this being an incident, you can’t quite make this determination for sure yet. However, we have identified a secondary subject, so we will move on to the next step of our investigation with that data in hand.
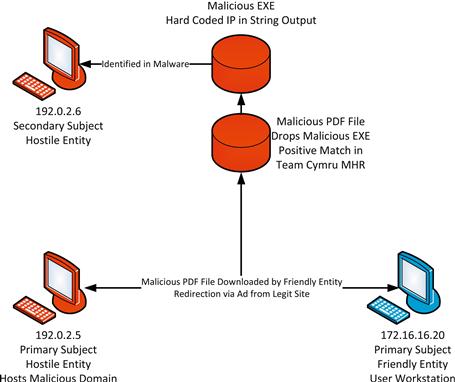
Step Three: Investigate Secondary Subjects and Relationships
We have identified the secondary subject 192.0.2.6 coded into the executable that was dropped by the PDF file downloaded by the primary subject. Now, we must investigate that subject by collecting hostile intelligence for this IP address:
Hostile Intelligence for 192.0.2.6:
• IPVoid returns 2 matches on public blacklists for this IP Address.
• NetFlow data indicates that the primary subject 172.16.16.20 has communicated with this host. This communication occurred approximately thirty minutes after the initial alert.
• NetFlow data indicates that two other friendly hosts on our network have been communicating with this IP address on a periodic basis with low volumes of traffic for the past several days. Their addresses are 172.16.16.30 and 172.16.16.40.
Based upon this information, it appears as though this issue might be larger than we originally thought. Next, we need to determine the relationship between our secondary subject 192.0.2.6 and our primary subject 172.16.16.20. Based upon our hostile intelligence, we already know that communication occurred between these two devices. The next step is to gather PCAP data for communication occurring between these hosts. Once this data is collected, analysis reveals that although these devices are communicating on Port 80, they are not using the HTTP protocol. Instead, they are using a custom protocol, and you can see that commands are being issued to this system. These commands result in the friendly system transmitting system information to the hostile host. At this point that you also notice a periodic call back that is transmitted to the hostile host.
At this point, we have enough information to determine that an incident can be declared, and that 172.16.16.20 has become compromised (Figure 15.4). In some cases, the investigation could end here. However, remember that we identified two additional hosts (now identified as tertiary hosts) that were communicating with the hostile IP 192.0.2.6. This means that there is a good chance those might also be infected.
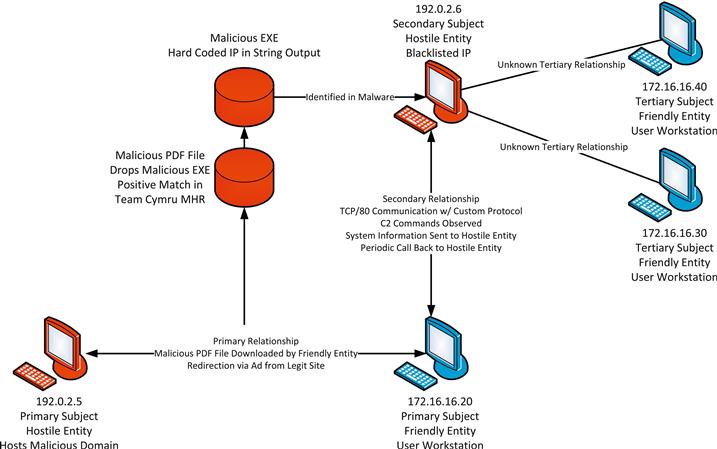
Step Four: Investigate Additional Degrees of Subjects’ Relation
An examination of the packet data transmitted between these tertiary hosts and 172.16.16.20 reveals that it is also participating in the same call back behavior as was identified in the primary friendly host (Figure 15.5). Because of this, you can determine that the tertiary friendly hosts are also compromised.
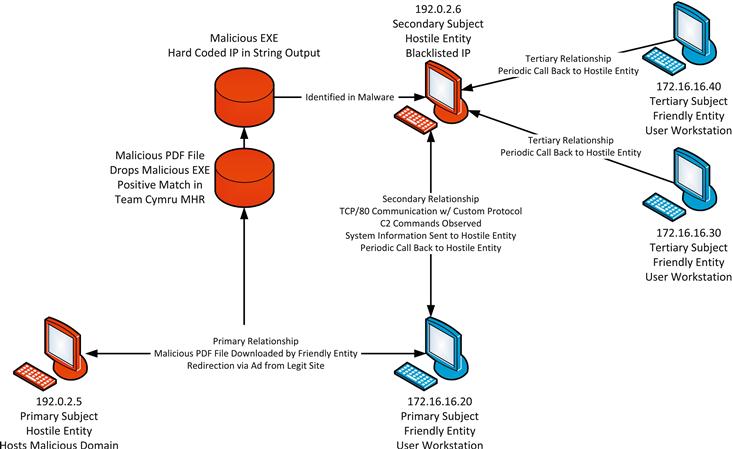
Summarizing the Incident
This scenario was based on a real incident that occurred in a SOC. Using a systematic analysis process to identify hosts and build relationships between them not only allowed us to determine if a compromise occurred, it also allowed us to find other hosts that were also compromised but weren’t identified in the original alert that tipped us off. This is a great example of how a structured process can help an analyst get from A to Z without getting detoured or being overloaded with information. It is very easy to get buried in the weeds in a scenario like this one. The key is approaching each step as it is intended and not venturing too far off the path you are on. If you trust the path, it will eventually get you where you want to go.
Differential Diagnosis
The goal of an NSM analyst is to digest the alerts generated by various detection mechanisms and investigate multiple data sources to perform relevant tests and research to see if a network security breach has happened. This is very similar to the goals of a physician, which is to digest the symptoms a patient presents with and investigate multiple data sources and perform relevant tests and research to see if their findings represent a breach in the person’s immune system. Both practitioners share a similar of goal of connecting the dots to find out if something bad has happened and/or is still happening.
Although NSM has only been around a short while, medicine has been around for centuries. This means that they’ve got a head start on us when it comes to developing their diagnostic method. One of the most common diagnostic methods used in clinical medicine is one called differential diagnosis. If you’ve ever seen an episode of “House” then chances are you’ve seen this process in action. The group of doctors will be presented with a set of symptoms and they will create a list of potential diagnoses on a whiteboard. The remainder of the show is spent doing research and performing various tests to eliminate each of these potential conclusions until only one is left. Although the methods used in the show are often a bit unconventional, they still fit the bill of the differential diagnosis process.
The differential method is based upon a process of elimination. It consists of five distinct steps, although in some cases only two will be necessary. The differential process exists as follows:
Step One: Identify and list the symptoms
In medicine, symptoms are typically conveyed verbally by the individual experiencing them. In NSM, a symptom is most commonly an alert generated by some form of intrusion detection system or other detection software. Although this step focuses primarily on the initial symptoms, more symptoms may be added to this list as additional tests or investigations are conducted.
Step Two: Consider and evaluate the most common diagnosis first
A maxim every first year medical student learns is “If you hear hoof beats, look for horses…not zebras.” That is, the most common diagnosis is likely the correct one. As a result, this diagnosis should be evaluated first. The analyst should focus his investigation on doing what is necessary to quickly confirm this diagnosis. If this common diagnosis cannot confirmed during this initial step, then the analyst should proceed to the next step.
Step Three: List all possible diagnosis for the given symptoms
The next step in the differential process is to list every possible diagnosis based upon the information currently available with the initially assessed symptoms. This step requires some creative thinking and is often most successful when multiple analysts participate in generating ideas. Although you may not have been able to completely confirm the most common diagnosis in the previous step, if you weren’t able to rule it out completely then it should be carried over into the list generated in this step. Each potential diagnosis on this list is referred to as a candidate condition.
Step Four: Prioritize the list of candidate conditions by their severity
Once a list of candidate conditions is created, a physician will prioritize these by listing the condition that is the largest threat to human life at the top. In the case of an NSM analyst you should also prioritize this list, but the prioritization should focus on which condition is the biggest threat to your organization’s network security. This will be highly dependent upon the nature of your organization. For instance, if “MySQL Database Root Compromise” is a candidate condition then a company whose databases contains social security numbers would prioritize this condition much more highly than a company who uses a simple database to store a list of its sales staff’s on-call schedule.
Step Five: Eliminate the candidate conditions, starting with the most severe
The final step is where the majority of the action occurs. Based upon the prioritized list created in the previous step, the analyst should begin doing what is necessary to eliminate candidate conditions, starting with the condition that poses the greatest threat to network security. This process of elimination requires considering each candidate condition and performing tests, conducting research, and investigating other data sources in an effort to rule them out as a possibility. In some cases, investigation of one candidate condition may rule out multiple candidate conditions, speeding up this process. Alternatively, investigation of other candidate conditions may prove inconclusive, leaving one or two conditions that are unable to be definitively eliminated as possibilities. This is acceptable, since sometimes in network security monitoring (as in medicine) there are anomalies that can’t be explained and require more observation before determining a diagnosis. Ultimately, the goal of this final step is to be left with one diagnosis so that an incident can be declared or the alert can be dismissed as a false positive. It’s very important to remember that “Normal Communication” is a perfectly acceptable diagnosis, and will be the most common diagnosis an NSM analyst arrives at.

Differential Diagnosis Scenarios
Now that we’ve explained the differential diagnosis process, let’s go through a couple of practical examples to demonstrate how it might work in a real NSM environment. Since we paint with such broad strokes when performing differential diagnosis, we will look at two unique scenarios.
Scenario 1
Step 1: Identify and List the Symptoms
The following symptoms were observed through IDS alerts and investigation of immediately available data:
Step 2: Consider and Evaluate the Most Common Diagnosis First
Based on these symptoms, it might appear that the most logical assumption is that this machine is infected with some form of malware and is phoning home for further instructions. After all, the traffic is going to a Russian IP address at regular 10 minute intervals. Although those things are worth noting (I wouldn’t have listed them if they weren’t), I don’t think we should buy into the malware theory so hastily. All too often, too much emphasis is placed on the geographic location of IP addresses, so the fact that the remote IP address is Russian means little right off the bat. Additionally, there are a lot of normal communication mechanisms that communicate on regular periodic intervals. This includes things like web-based chat, RSS feeds, web-based e-mail, stock tickers, software update processes, and more. Operating on the principal that all packets are good unless you can prove they are bad, I think the most common diagnosis here is that this is normal traffic.
That said, confirming that something is normal can be hard. In this particular instance we could start with some hostile intelligence collection for the Russian IP. Although it’s located in Russia, a legitimate company still may own it. If we were to look up the host and find that it was registered to a popular AV vendor we might be able to use that information to conclude that this was an AV application checking for updates. I didn’t mention the URL that the HTTPS traffic is going to, but quickly Googling it may yield some useful information that will help you determine if it is a legitimate site or something that might be hosting malware or some type of botnet command and control. Another technique would be to examine system logs or host-based IDS logs to see if any suspicious activities are occurring on the machine at the same intervals the traffic is occurring at. Another route is to examine friendly intelligence for the friendly device. For instance, is the user from Russia? Are they using an Antivirus product that (like Kaspersky) that might have update servers in Russia? Those things might help to determine if the traffic is normal.
For the purposes of this exercise, let’s assume that we weren’t able to make a final determination on whether this was normal communication.
Step 3: List all Possible Diagnoses for the Given Symptoms
There are several potential candidate conditions within the realm of possibility for the current scenario. For the sake of brevity, we’ve only listed a few of those here:
Normal Communication. We weren’t able to rule this out completely in the previous step so we carry it over to this step.
Malware Infection / Installed Malicious Logic. This is used as a broad category. We typically don’t care about the specific strain of malware until we determine that malware may actually exist. If you are concerned about a specific strain then it can be listed separately. Think of this category as a doctor listing “bacterial infection” as a candidate condition knowing that they can narrow it down further once more information has been obtained.
Data Exfiltration from Compromised Host. This condition represents the potential that the host could be sending proprietary or confidential information out of the network in small intervals. This type of event would often be part of a coordinated or targeted attack.
Misconfiguration. It’s well within the realm of possibilities that a system administrator mistyped an IP address and a piece of software that should be trying to communicate periodically with an internal system is now trying to do so with a Russian IP address. This is really quite common.
Step 4: Prioritize the List of Candidate Conditions by their Severity
With candidate conditions identified, we can prioritize these based upon their severity. This prioritization will vary depending on the risk profile for an organization. As a generalization, we’ve selected the following priorities, with priority 1 being the highest:
Step 5: Eliminate the Candidate Conditions, Starting with the Most Severe
Now we can gather data and perform tests to eliminate each potential candidate condition. Once you’ve identified the correct diagnosis you would stop this process, but for this scenario we’ve gone through the motions with every condition.
Priority 1: Data Exfiltration from Compromised Host. This one can be a bit tricky to eliminate as a possibility. Full packet capture won’t provide a lot of help since the traffic is encrypted. If you have session data available, you should be able to determine the amount of data going out. If only a few bytes are going out every 10 minutes then it’s likely that this is not data exfiltration, since this would probably involve a larger amount of outbound data. It would also be valuable to determine if any other hosts on your network are communicating with this IP address or any other IPs in the same address space. Finally, baselining normal communication for your internal host and comparing it with the potentially malicious traffic may provide some useful insight. This can be done with friendly intelligence data, like data collected by PRADS.
Priority 2: Malware Infection / Installed Malicious Logic. At this point the research you’ve already done should give you a really good idea of whether or not this condition is true. It is likely that by examining the potential for data exfiltration, you will rule this condition out as a result or will have already been able to confirm that it is true. In addition to things listed in those steps, you could examine network antivirus or HIDS logs in detail.
Priority 3: Misconfiguration. This condition can best be approached by comparing the traffic of the friendly host against the traffic of one or more hosts with a similar role on the network. If every other workstation on that same subnet has the same traffic pattern, but to a different IP address, then it’s likely that the wrong IP address was entered into a piece of software somewhere. Having access to host-based logs can also be useful in figuring out if a misconfiguration exists since records of the misconfiguration might exist in Windows or Unix system logs.
Priority 4: Normal Communication. If you’ve gotten this far, then the diagnosis of normal communication should be all that remains on your list of candidate conditions.
Making a Diagnosis
At this point you have to use your experience as an analyst and your intuition to decide if you think something malicious is really occurring. If you were able to complete the previous analysis thoroughly, then operating on the assumption that all packets are good unless you can prove they are bad would mean your final diagnosis here should be that this is normal communication. If you still have a hunch something quirky is happening though, there is no shame in monitoring the host further and reassessing once more data has been collected.
Scenario 2
Step 1: Identify and List the Symptoms
The following symptoms were observed through IDS alerts and investigation of immediately available data:
Step 2: Consider and Evaluate the Most Common Diagnosis First
With the amount of traffic received by the internal host being abundant and the packets using the UDP protocol with random destination ports, my inclination would be that this is some form of denial of service attack.
The quickest way to determine whether something is a denial of service is to assess the amount of traffic being received compared with the normal amount of traffic received on that host. This is something that is really easy to do with session data using the throughput calculation statistics we discussed in Chapter 11. If the host is only receiving 20% more traffic than it normally would, then I would consider alternatives to a DoS. However, if the host is receiving 10 or 100 times its normal amount of traffic then DoS is very likely. It’s important to remember that a DoS is still a DoS even if it is unintentional.
Once again, for the sake of this scenario we will continue as though we weren’t able to make a clear determination of whether a DoS condition exists.
Step 3: List all Possible Diagnoses for the Given Symptoms
There are several candidate conditions within the realm of possibility for the current scenario. For the sake of brevity, we’ve only listed a few of those here:
Denial of Service. We weren’t able to rule this out completely in the previous step so we carry it over to this step.
Normal Communication. It doesn’t seem incredibly likely, but there is potential that is normal traffic being generated by a legitimate service.
Misdirected Attacks. When a third party chooses to attack another they will often spoof their source address for the sake of anonymity and to prevent getting DoS’d themselves. This will result in the owner of the spoofed IP they are using seeing that traffic. This web server could be seeing the effects of this.
Misconfigured External Host. A misconfiguration could have happened on someone else’s network just as easily as it could on yours. This misconfiguration could result in an external host generating this traffic and sending it to the web server.
SPAM Mail Relay. The server could be misconfigured or compromised in a manner that allows it to be used for relaying SPAM mail across the Internet.
Step 4: Prioritize the List of Candidate Conditions by their Severity
With candidate conditions identified, we can prioritize these based upon their severity. This prioritization will vary depending on the risk profile for an organization. As a generalization, we’ve selected the following priorities, with priority 1 being the highest:
Step 5: Eliminate the Candidate Conditions, Starting with the Most Severe
Now we can gather data and perform tests to eliminate each potential candidate condition. Once you’ve identified the correct diagnosis you would stop this process, but for this scenario we’ve gone through the motions with every condition.
Priority 1: Denial of Service. We’ve already gone through our paces on this one without being able to identify that it is the definitive diagnosis. Even though this is the most severe we would have to proceed to attempt to eliminate other candidate conditions to help in figuring out if a DoS is occurring. Of course, depending on the effect of the attack it may make the most sense to contain the issue by blocking the traffic before spending more time investigating the root cause.
Priority 2: SPAM Mail Relay. This one is relatively easy to eliminate. If the server were being used as a mail relay then you would have a proportionate amount of traffic going out as you do going in. If that’s not the case and you don’t see any abnormal traffic leaving the server then it is likely that it is not relaying SPAM. You can determine this by generating throughput statistics from session data, like we discussed in Chapter 11. If the web server is also running mail services then you can examine the appropriate logs here as well. If it is not supposed to be running mail services, you can examine the host to see if it is doing so in an unauthorized manner.
Priority 3: Misconfigured External Host. This one is typically pretty tricky. Unless you can identify the owner of the IP address and communicate with them directly then the most you can hope to do is block the traffic locally or report abuse at the ISP level.
Priority 4: Misdirected Attacks. This is another tricky one along the same lines as the previous candidate condition. If it’s an attacker somewhere else whose antics are causing traffic redirection to your server then the most you can do is report the issue to the ISP responsible for the IP address and block the traffic locally.
Priority 5: Normal Communication. This doesn’t seem likely, but you can’t say this for sure without baselining the normal traffic for the host. Using friendly intelligence gathered from a tool like PRADS combined with session data review, you can compare the host’s traffic at similar times on previous days to see if you can draw any conclusions. Is the pattern normal and it’s just the amount of traffic that anomalous? Is it both the pattern and the amount that’s anomalous? Does the server ever talk to the offending IP prior to this? These questions should lead you in the right direction.
Making a Diagnosis
In this scenario, it’s very possible that you are left with as many as three candidate conditions that you cannot rule out. The good thing here is that even though you can’t rule these out, the containment and remediation methods would be the same for all of them. This means that you still have gotten to a state of diagnosis that allows the network to recover from whatever is occurring. This is just like when a doctor knows that an infection is occurring with a patient. Even if the doctor doesn’t know the exact nature of the infection, they know that treating it with antibiotics will help solve the problem.
If the amount of traffic isn’t so large that it is actually preventing services from being delivered, then you may not need to block the activity. This will allow you to continue monitoring it in order to attempt to collect more symptoms that may be useful in making a more accurate diagnosis.
Implementing Analysis Methods
The two analysis methods we’ve described here are very different. There really is no clear-cut formula for choosing the right method as they each have their strengths and weaknesses depending on the current scenario and the strengths and weaknesses of the analyst. From my experience, the relational investigation method tends to work best in complex scenarios where more than a few hosts are involved. This is because it better allows you to keep track of a large number of entities and relationships without getting overwhelmed or going off on an odd tangent. The differential diagnosis method tends to work best in scenarios where you have a smaller number of hosts involved and you are fixated on a few distinct symptoms in route to a singular diagnosis.
The important thing to take away from this section isn’t that you should use one of these analysis methods to the letter. They are merely provided as frameworks that you might be able to adapt to your environment. The thing to take away here is that all analysis is improved through the use of some systematic method that allows the analyst to work through an investigation efficiently.
Analysis Best Practices
Throughout this book we’ve mentioned several “best practices” for analysis. While everyone performs analysis in their own unique way, there are certain truths that I have found to be beneficial to remember when performing analysis. These best practices are compiled through years of experience from the authors of this book, as well as our colleagues.
Unless You Created the Packet Yourself, There Are No Absolutes
Analysis happens in a world of assumptions and best guesses. Most of the decisions you will make are centered on a packet or a log entry, and then honed based upon the review of additional data or intelligence. Because of this, the assumptions and guesses you make will be constantly shifting as new information comes to light. Don’t worry though; there is nothing wrong with that. Ask your friendly neighborhood chemist or physicist. Most of their work is based upon assumptions and they have great success.
The takeaway here is that there are rarely absolutes in analysis, and it is healthy to question assumptions and guesses constantly. Is that IP address REALLY a known legitimate host? Does that domain REALLY belong to XYZ company? Is that DNS server REALLY supposed to be communicating with that database server? Always question yourself and stay on your toes.
Be Mindful of Your Abstraction from the Data
An analyst depends on data to perform their job. This data can come in the form of a PCAP file, a PSTR record, or an IIS file. Since most of your time will be spent using various tools to interact with data it’s crucial to be mindful of how that tool interacts with the data. Humans are imperfect and because they make tools, sometimes “features” can cloud data and prevent proper analysis.
In one scenario, I worked for a SOC that used a very popular commercial SIEM solution. One day, we started seeing weird log entries in the SIEM console that indicated a large amount of internal traffic was going to the IP address 255.255.255.255 on port 80. Investigating the data at a more intimate level uncovered that the traffic generating these logs was actually internal HTTP requests that were being blocked by a web proxy. An update to the parser the SIEM was using to ingest records from that proxy resulting in it not knowing how to handle the destination IP address field, yielding the improper value 255.255.255.255. This is a prime example where knowing your data and being aware of how far abstracted from it you are is crucial.
In a job where reliance upon data is critical, you can’t afford to not understand exactly how your tools interact with that data.
Two Sets of Eyes are Always Better than One
There is a reason that authors have editors, policemen have partners, and there are two guys sitting in every nuclear silo. No matter how much experience you have and how good you are, you will always miss things. This is expected because different people come from different backgrounds, and nobody is operates at 100% efficiency all the time. After all, we are only human.
I come from a military network defense background, so the first thing I look at when examining network traffic is the source and destination country. Now, I know that in most cases geolocation data doesn’t matter much since those values can easily be spoofed or represent another compromised host being used by someone in a differing country. However, it’s just how I’m programed. On the flip side, several of my colleagues come from a systems administration backgrounds and as a result, will look at the port number of the traffic first. As another example, I’ve worked with people who have a number crunching background, who will look at the amount of data transferred in a communication sequence first. This subtle technique helps demonstrate that our experiences help to shape our tactics a bit differently. This means that the numbers guy might see something that the sysadmin didn’t see, or that the military guy might have insight that the numbers guy doesn’t.
Whenever possible it’s always a good idea to have a second set of eyes look at the issue you are facing. In any SOC I manage, I usually implement a two-person rule stating that at least two analyst are required to confirm an incident.
Never Invite an Attacker to Dance
My coworker, SANS Senior Instructor, and packet ninja master Mike Poor phrased it best when I first heard him say, “Never invite an attacker to dance.” As an analyst, it’s very tempting to want to investigate a hostile IP address a bit beyond conventional means. Trust me, there have been many occasions where I’ve been tempted to port scan a hostile entity that kept sending me poorly crafted UDP packets. Even more so, any time someone attempts to DoS a network I’m responsible for defending, I wish for nothing more than to be able to unleash the full fury of a /8 network on their poor unsuspecting DSL connection.
The problem with this is that 99% of the time we don’t know who or what we are dealing with. Although you may just be seeing scanning activity, the host that is originating the traffic could be operated by a large group of attackers or even a military division of another country. Even something as simple as a ping could tip off an attacker that you know they exist, prompting them to change their tactics, change source hosts, or even amplify their efforts. You don’t know who you are dealing with, what their motivation is, and what their capabilities are, so you should never invite them to dance. The simple fact of the matter is that you don’t know if you are capable of handling the repercussions.
Packets are Inherently Good
The ultimate argument in life is whether people are inherently good or inherently evil. This same argument can be had for packets as well. You can either be the analyst that believes all packets are inherently evil or the analyst that believes all packets are inherently good.
In my experience, I’ve noticed that most analysts typically start their career assuming that packets are inherently evil, but eventually progress to assuming that packets are inherently good. That’s because it’s simply not feasible to approach every single piece of network evidence as something that could be a potential root-level compromise. If you do this, you’ll eventually get fired because you spent your entire day running down a single alert or you’ll just get burnt out. There is something to be said for being thorough, but the fact of the matter is that most of the traffic that occurs on a network isn’t going to be evil, and as such, packets should be treated as innocent until proven guilty.
Analysis is No More About Wireshark than Astronomy is About a Telescope
Whenever I interview someone for any analyst position (above entry level), I always ask that person to describe how he or she would investigate a typical IDS alert so that I can understand their thought process. A common answer that I hear sometimes goes like this: “I use Wireshark, Network Miner, Netwitness, and Arcsight.” That’s it.
Although there are processes and sciences in the practice of NSM, it is so much more than that. If this weren’t the case then it wouldn’t even be necessary to have humans in the loop. An effective analyst has to understand that while different tools may be an important part of the job, those things are merely pieces of the puzzle. Just like an astronomer’s telescope is just another tool that allows him to figure out what makes the planets orbit the sun, Wireshark is just another tool in an analyst’s arsenal that allows him to figure out what makes a packet get from point A to point B.
Start with the science, add in a few tools and processes, stay cognizant of the big picture, keep an attention to detail, and eventually the combination of all of those things and the experience you gain over time will help you develop your own analysis technique.
Classification is Your Friend
It won’t be long before you encounter a situation where you have more than one significant event to analyze at a time. When this occurs, it helps to have a system in place that can help you to determine which incident takes precedence for investigation and notification. In most SOC’s, this is an incident classification system. There are several of these in existence, but the one I’ve grown accustomed to using is the DoD Cyber Incident and Cyber Event Categorization system,1 outlined by CJCSM 6510. Table 15.1 outlines these categories, ordered by the precedence each category should take.

While this exact model might not be the best fit for your organization, I think that any group can benefit from implementing a categorization system. Any time an analyst performs a preliminary review of an event and determines that it warrants more investigation, that event should be assigned a category, even if that category is “Investigating “ (CAT 8 Above). The category an investigation is assigned to can change multiple times throughout the investigation, and it is equally as common for the severity of an event to be downgraded as it is for it to be escalated. These things can be tracked in whatever internal ticketing/tracking system the SOC is using, and any change to the category of an event should be accompanied by an explanation by the analyst making that determination.
The Rule of 10’s
New analysts usually have a habit of grabbing too much data or too little data when investigating an event occurring at a specific point in time. On one extreme, the analyst will see an event occurring on 7 October 08:35 and will attempt to retrieve NSM data associated with that host for all of 7 October. This creates a scenario where the analyst has far too much data to analyze efficiently. On the other extreme, the analyst retrieves only data occurring on 7 October 08:35 to the minute. This creates a scenario where the analyst doesn’t have enough information to determine exactly what happened.
To prevent either of these scenarios from occurring with my analysts, I created the rule of 10’s. This rule states that any time you need to perform analysis on an event occurring at a single point in time, you should begin by retrieving data occurring 10 minutes before the event occurred to 10 minutes after the event occurred. I’ve found that this time frame sits in the “sweet spot” where the analyst has enough data to determine what led up to the event and what occurred after the event happened. Once the analyst has analyzed this data, they can make the decision to retrieve more data as necessary. Of course, this rule doesn’t fit every situation, but I’ve found it effective for new analysts in 99% of the investigations they perform.
When you Hear Hoof Beats, Look for Horses – Not Zebras
This is another concept borrowed from the medical community that is drilled into the heads of medical students for the duration of their education. If you see a patient who has a stomachache, it doesn’t make a lot of sense to start performing tests for a lot of obscure diseases and conditions. Instead, ask the patient what they ate last night. If it happens to be two-dozen tacos and half a pizza, then you’ve probably found the problem.
Similarly, we should always consider the most obvious solution first when investigating events. If a system appears to be sending periodic communication to an unknown web server, then you shouldn’t immediately assume that this is a callback to some adversary-run command and control infrastructure. Instead, it might just be a webpage they have open to check sports scores or stock ticker information.
This concept relies upon accepting the principle I spoke of earlier that all packets are inherently good. It also lends itself well to the differential diagnosis analysis method we looked at earlier.
Incident Morbidity and Mortality
It may be a bit cliché, but encouraging the team dynamic within a group of analysts ensures mutual success over individual success. There are a lot of ways to do this, including items we discussed before in Chapter 1, such as fostering the development of infosec superstars or encouraging servant leadership. Beyond these things, there is no better way to ensure team success within your group than to create a culture of learning. Creating this type of culture goes well beyond sending analysts to formalized courses or paying for certifications. It relies upon adopting the mindset that in every action an analyst takes, they should either be teaching or learning, with no exceptions. Once every analyst begins seeing every part of their daily job as an opportunity to learn something new or teach something new to their peers, then a culture of learning is flourishing.
A part of this type of organizational culture is learning from both successes and failures. NSM is centered on technical investigations and cases, and when something bad eventually happens, an incident. This is not unlike medicine, which is also focused on medical investigations and patient cases, and when something bad eventually happens, death.
Medical M&M
When death occurs in medicine, it can usually be classified as something that was either avoidable or inevitable from both a patient standpoint and also as it related to the medical care that was provided. Whenever a death is seen as something that may have been prevented or delayed with modifications to the medical care that was provided, the treating physician will often be asked to participate in something called a Morbidity and Mortality Conference, or “M&M” as they are often referred to casually. In an M&M, the treating physician will present the case from the initial visit, including the presenting symptoms and the patient’s initial history and physical assessment. This presentation will continue through the diagnostic and treatment steps that were taken all the way through the patient’s eventual death.
The M&M presentation is given to an audience of peers, including any other physicians who may have participated in the care of the patient. The audience will also include physicians who had nothing to do with the patient. The general premise is that these peers will question the treatment process in order to uncover any mistakes that may have been made, processes that could be improved upon, or situations that could have been handled differently.
The ultimate goal of the medical M&M is for the team to learn from any complications or errors, to modify behavior and judgment based upon experiences gained, and to prevent repetition of errors leading to complications. This is something that has occurred within medicine for over one hundred years and has proven to be wildly successful.2
Information Security M&M
Earlier, we discussed how the concept of differential diagnosis can be translated from the medical field to information security. The concept of M&M is also something that I think transitions well to information security.
As information security professionals, it is easy to miss things. Since we know that prevention eventually fails, we can’t be expected to live in a world free from compromise. Rather, we must be positioned so that when an incident does occur, it can be detected and responded to quickly. Once that is done, we can learn from whatever mistakes occurred that allowed the intrusion, and be better prepared to prevent, detect, and respond next time.
When an incident occurs we want it to be because of something out of our hands, such as a very sophisticated adversary or an attacker who is using an unknown zero day exploit. The truth of the matter is that not all incidents are that complex and often times there are ways in which detection, analysis, and response could occur faster. The information security M&M is a way to collect that information and put it to work. In order to understand how we can improve from mistakes, we have to understand why they are made. Uzi Arad summarizes this very well in the book, “Managing Strategic Surprise”, a must read for information security professionals.3 In this book, he cites three problems that lead to failures in intelligence management, which also apply to information security:
• The problem of misperception of the material, which stems from the difficulty of understanding the objective reality, or the reality as it is perceived by the opponent.
• The problems stemming form the prevalence of pre-existing mindsets among the analysts that do not allow an objective professional interpretation of the reality that emerges from the intelligence material.
• Group pressures, groupthink, or social-political considerations that bias professional assessment and analysis.
The information security M&M aims to provide a forum for overcoming these problems through strategic questioning of incidents that have occurred.
When to Convene an M&M
In an Information Security M&M, the conference should be initiated after an incident has occurred and been remediated. Selecting which incidents are appropriate for M&M is a task that is usually handled by a team lead or member of management who has the ability to recognize when an investigation could have been handled better. This should occur reasonably soon after the incident so important details are fresh on the minds of those involved, but far enough out from the incident that those involved have time to analyze the incident as a whole, post-mortem. An acceptable time frame can usually be about a week after the incident has occurred.
M&M Presenter(s)
The presentation of the investigation will often involve multiple individuals. In medicine, this may include an initial treating emergency room physician, an operating surgeon, and a primary care physician. In information security, this could include an NSM analyst who detected the incident, the incident responder who contained and remediated the incident, the forensic investigator who performed an analysis of a compromised machine, or the malware analyst who reverse engineered the malware associated with the incident.
M&M Peers
The peers involved with the M&M should include at least one counterpart from each particular specialty, at minimum. This means that for every NSM analyst directly involved with the case, there should be at least one other NSM analyst who had nothing to do with it. This aims to get fresh outside views that aren’t tainted by feeling the need to support any actions that were taken in relation to the specific investigation. In larger organizations and more ideal situations, it is nice to have at least two counterparts from each specialty, with one having less experience than the presenter and one having more experience.
The Presentation
The presenting individual or group should be given at least a few days notice before their presentation. Although the M&M isn’t considered a formal affair, a reasonable presentation is expected to include a timeline overview of the incident, along with any supporting data. The presenter should go through the detection, investigation, and remediation of the incident chronologically and present new findings only as they were discovered during this progression. Once this chronological presentation is given, the incident can then be examined holistically.
During the presentation, peers are expected to ask questions as they arise. Of course, this should be done respectfully by raising your hand as the presenter is speaking, but questions should NOT be saved for after the presentation. This is in order to frame the questions to the presenter as a peer would arrive at them during the investigation process.
Strategic Questioning
Questions should be asked to presenters in such a way as to determine why something was handled in a particular manner, or why it wasn’t handled in an alternative manner. As you may expect, it is very easy to offend someone when providing these types of questions, therefore, it is critical that participants enter the M&M with an open mind and both presenters and peers ask and respond to questions in a professional manner and with due respect.
Initially, it may be difficult for peers to develop questions that are entirely constructive and helpful in overcoming the three problems identified earlier. There are several methods that can be used to stimulate the appropriate type of questioning.
Devils Advocate
One method that Uzi Arad mentions in his contribution to “Managing Strategic Surprise” is the Devils Advocate method. In this method, peers attempt to oppose most every analytical conclusion made by the presenter. This is done by first determining which conclusions can be challenged, then collecting information from the incident that supports the alternative assertion. It is then up to the presenter to support their own conclusions and debunk competing thoughts.
Alternative Analysis (AA)
R.J. Heuer presents several methods for strategic questioning in his paper, “The Limits of Intelligence Analysis”. These methods are part of a set of analytic tools called Alternative Analysis (AA).4 Some of these more commonly used methods are:
Group A / Group B
This analysis involves two groups of experts analyzing the incident separately based upon the same information. This requires that the presenters (Group A) provide supporting data related to the incident prior to the M&M so that the peers (Group B) can work collaboratively to come up with their own analysis to be compared and contrasted during the M&M. The goal is to establish to individual centers of thought. Whenever points arise where the two groups reach a different conclusion, additional discussion is required to find out why the conclusions differ.
Red Cell Analysis
This method focuses on the adversarial viewpoint, where peers assume the role of the adversary involved with the particular incident. They will question the presenter regarding how their investigative steps were completed in reaction to the attacker’s actions. For instance, a typical defender may solely be focused on finding out how to stop malware from communicating back to the attacker, but the attacker may be more concerned with whether the defender was able to decipher the communication that was occurring. This could lead to a very positive line of questioning that results in new analytic methods that help to better assess the impact of the attacker, ultimately benefiting the incident containment process.
What If Analysis
This method is focused on the potential causes and effects of events that may not have actually occurred. During detection, a peer may ask a question related to how the attack might have been detected if the mechanism that did detect it hadn’t been functioning correctly. In the response to the event, a peer might question what the presenter would have done had the attacker been caught during the data exfiltration process rather than after it had already occurred. These questions don’t always relate directly to the incident at hand, but provide incredibly valuable thought-provoking discussion that will better prepare your team for future incidents.
Analysis of Competing Hypotheses
This method is similar to what occurs during a differential diagnosis, where peers create an exhaustive list of alternative assessments of symptoms that may have been presented. This is most effectively done by utilizing a whiteboard to list every potential diagnosis and then ruling those out based on testing and review of additional data.
Key Assumptions Check
Most all sciences tend to make assumptions based on generally accepted facts. This method of questioning is designed to challenge key assumptions and how they affect the investigation of a scenario. This most often pairs with the What If analysis method. As an example, in the spread of malware, it’s been the assumption that when operating within a virtual machine, the malware doesn’t have the ability to escape to the host or other virtual machines residing on it. Given an incident being presented where a virtual machine has been infected with malware, a peer might pose the question of what action might be taken if this malware did indeed escape the virtual environment and infect other virtual machines on the host, or the host itself.
M&M Outcome
During the M&M, all participants should actively take notes. Once the M&M is completed, the presenting individuals should take their notes and combine them into a final report that accompanies their presentation materials and supporting data. This reporting should include a listing of any points which could have been handled differently, and any improvements that could be made to the organization as a whole, either technically or procedurally. This report should be attached to the case file associated with the investigation of the incident. This information ultimately serves as the “lessons learned” for the incident.
Additional M&M Tips
Having organized and participated in several of these conferences and reviews of similar scope, I have a few other pointers that help ensure that they provide value.
• M&M conferences should be held only sporadically, with no more than one per week and no more than three per month.
• It should be stressed that the purpose of the M&M isn’t to grade or judge an individual, but rather, to encourage the culture of learning.
• M&M conferences should be moderated by someone at a team lead or lower management level to ensure that the conversation doesn’t get too heated and to steer questions in the right direction. It is important that this person is technical, and not at an upper management level so that they can fully understand the implications of what is being discussed.
• If you make the decision to institute M&M conferences, it should be a requirement that everybody participates at some point, either as a presenter or a peer.
• The final report that is generated from the M&M should be shared with all technical staff, as well as management.
• Information security professionals, not unlike doctors, tend to have big egos. The first several conferences might introduce some contention and heated debates. This is to be expected initially, but will work itself out over time with proper direction and moderation.
• The M&M should be seen as a casual event. It is a great opportunity to provide food and coordinate other activities before and after the conference to take the edge off.
• Be wary of inviting upper management into these conferences. Their presence will often inhibit open questioning and response and they often don’t have the appropriate technical mindset to gain or provide value to the presentation.
• If you don’t have a lot of real incidents to base your M&M’s on, make some up! This is a great framework for performing tabletop exercises where hypothetical scenarios are discussed. You can also employ red teams to assist in these efforts by generating real attack scenarios.
It is absolutely critical that initiating these conferences is done with care. The medical M&M was actually started in the early 1900s by a surgeon named Dr. Ernest Codman at Massachusetts General Hospital in Boston. MGH was so appalled that Dr. Codman suggested that the competence of surgeons should be evaluated that he eventually lost his staff privileges. Now, M&M is a mainstay in modern medicine and something that is done in all of the best hospitals in the world, including MGH. I’ve seen instances where similar types of shunning can occur in information security when these types of peer review opportunities are suggested. As NSM practitioners it is crucial that we are accepting of this type of peer review and that we encourage group learning and the refinement of our skills.
Conclusion
In this chapter we discussed the analysis process, and two different methods that can be used for performing analysis in a structured, systematic manner. We also looked at a few analysis scenarios using these methods, as well as some analysis best practices. Finally, we covered methods for performing post-mortem lessons learned events.
No matter how hard you try, there will come a point where the network you are defending gets successfully attacked and compromised. In the modern security landscape, it’s inevitable and there isn’t a lot you can do about it because prevention eventually fails. Because of this, you need to be prepared when it happens.
An incident won’t be remembered for how an intrusion occurred, but rather how it was responded to, the amount of downtime that occurred, the amount of information that was lost, and ultimately the amount of money it costs the organization. What recommendations can you make to management to ensure a similar incident doesn’t occur again? What can you show your superiors to explain why the attack wasn’t detected? What shortcomings do your tools have? These are questions that can’t fully be answered until an intrusion has occurred and you have the context of an attack. However, these are questions you should constantly be asking yourself as you seek to improve your collection, detection, and analysis processes. Every event and incident flows through the NSM cycle and the lessons learned from each one will help to improve the process for the next time.
You will get caught off guard, you will be blind sided, and sometimes you will lose the fight. This chapter, and this book, is about equipping you with the right tools and techniques to be prepared when it happens.
1http://www.dtic.mil/cjcs_directives/cdata/unlimit/m651001.pdf
2Campbell, W. (1988). “Surgical morbidity and mortality meetings”. Annals of the Royal College of Surgeons of England 70 (6): 363–365. PMC 2498614.PMID 3207327.
3Arad, Uzi (2008). Intelligence Management as Risk Management. Paul Bracken, Ian Bremmer, David Gordon (Eds.), Managing Strategic Surprise (43-77). Cambridge: Cambridge University Press.
4Heuer, Richards J., Jr. “Limits of Intelligence Analysis.” Orbis 49, no. 1 (2005)