
Chapter 3. HBase Ecosystem
As we know, HBase is designed as part of the Hadoop ecosystem. The good news is that when creating new applications, HBase comes with a robust ecosystem. This should come as no surprise, as HBase is typically featured in a role of serving production data or powering customer applications. There are a variety of tools surrounding HBase, ranging from SQL query layers, ACID compliant transactional systems, management systems, and client libraries. In-depth coverage of every application for HBase will not be provided here, as the topic would require a book in and of itself. We will review the most prominent tools and discuss some of the pros and cons behind them. We will look at a few of the most interesting features of the top ecosystem tools.
Monitoring Tools
One of the hottest topics around Hadoop, and HBase in general, is management and monitoring tools. Having supported both Hadoop and HBase for numerous years, we can testify that any management software is better than none at all. Seriously, take the worst thing you can think of (like drowning in a vat of yellow mustard, or whatever scares you the most); then double it, and that is debugging a distributed system without any support. Hadoop/HBase is configured through XML files, which you can create manually. That said, there are two primary tools for deploying HBase clusters in the Hadoop ecosystem. The first one is Cloudera Manager, and the second is Apache Ambari. Both tools are capable of deploying, monitoring, and managing the full Hadoop suite shipped by the respective companies. For installations that choose not to leverage Ambari or Cloudera Manager, deployments typically use automated configuration management tools such as Puppet or Chef in combination with monitoring tools such as Ganglia or Cacti. This scenario is most commonly seen where there is an existing infrastructure leveraging these toolsets. There is also an interesting visualization out there called Hannibal that can help visualize HBase internals after a deployment.
Cloudera Manager
The first tool that comes to mind for managing HBase is Cloudera Manager (yeah, we might be a little biased). Cloudera Manager (CM) is the most feature-complete management tool available. Cloudera Manager has the advantage of being first to market and having a two-year lead on development over Apache Ambari. The primary downside commonly associated with CM is its closed source nature. The good news is that CM has numerous amazing features, including a point-and-click install interface that makes installing a Hadoop cluster trivial. Among the most useful features of Cloudera Manager are parcels, the Tsquery language, and distributed log search.
Parcels are an alternative method for installing Cloudera Distribution of Apache Hadoop (CDH). Parcels, in their simplest form, are “glorified tarballs.” What is implied by tarballs is that Cloudera packages up all the necessary start/stop scripts, libs/jars, and other files necessary for CM functions. Cloudera Manager will use this setup to easily manage the deployed services. Figure 3-1 shows an example of Cloudera Manager listing available and installed packages. Parcels allow for full stack rolling upgrades and restarts without having to incur downtime between minor releases. They also contain the necessary dependencies to make deploying Hadoop cleaner than using packages. CM will take advantage of the unified directory structure to generate and simplify classpath and configuration management for the different projects.
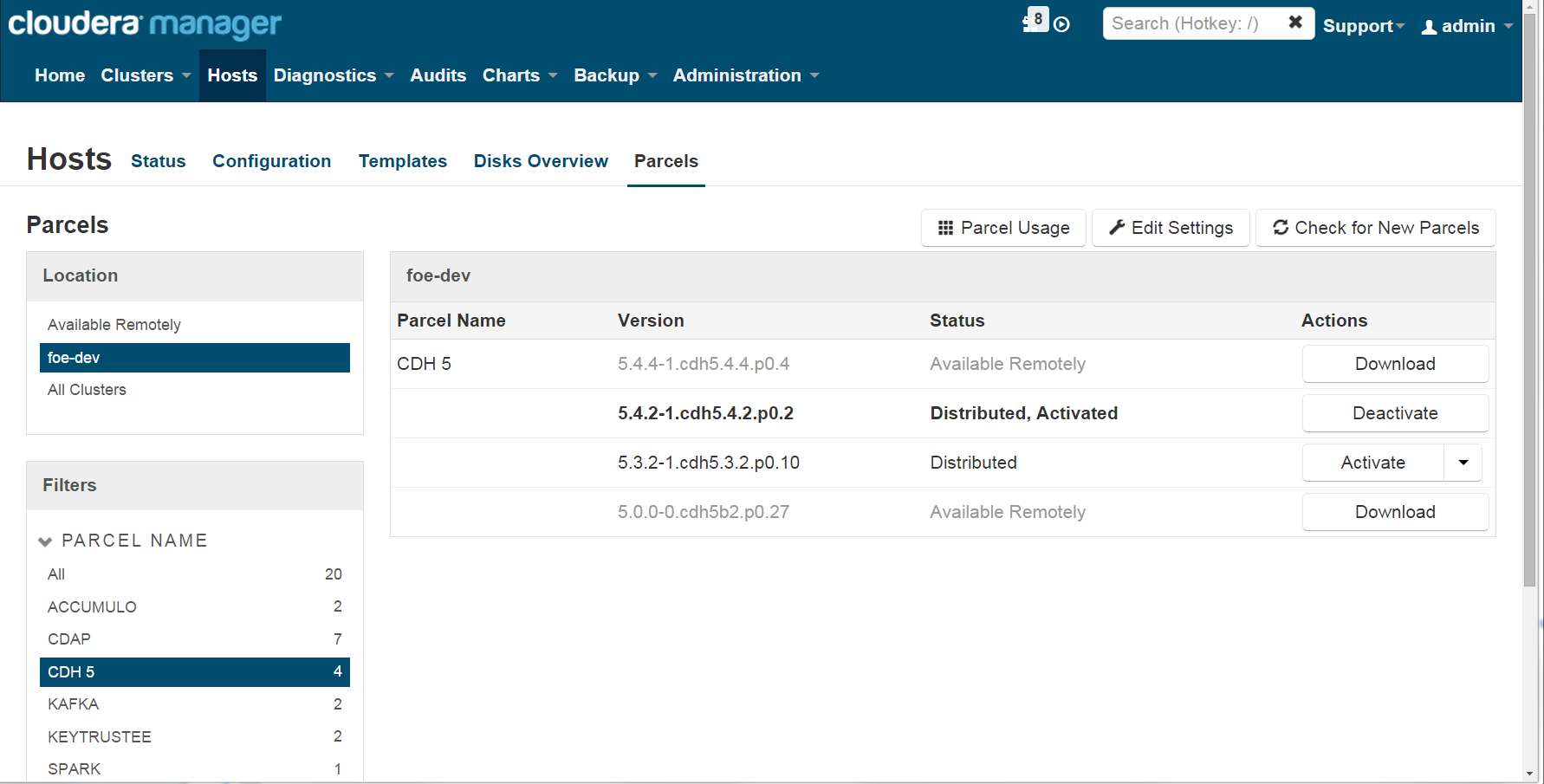
Figure 3-1. Listing of available and currently deployed parcels
Monitoring is key to any successful Hadoop or HBase deployment. CM has impressive monitoring and charting features built in, but it also has an SQL-like language known as “Tsquery.” As shown in Figure 3-2, administrators can use Tsquery to build and share custom charts, graphs, and dashboards to monitor and analyze clusters’ metrics.
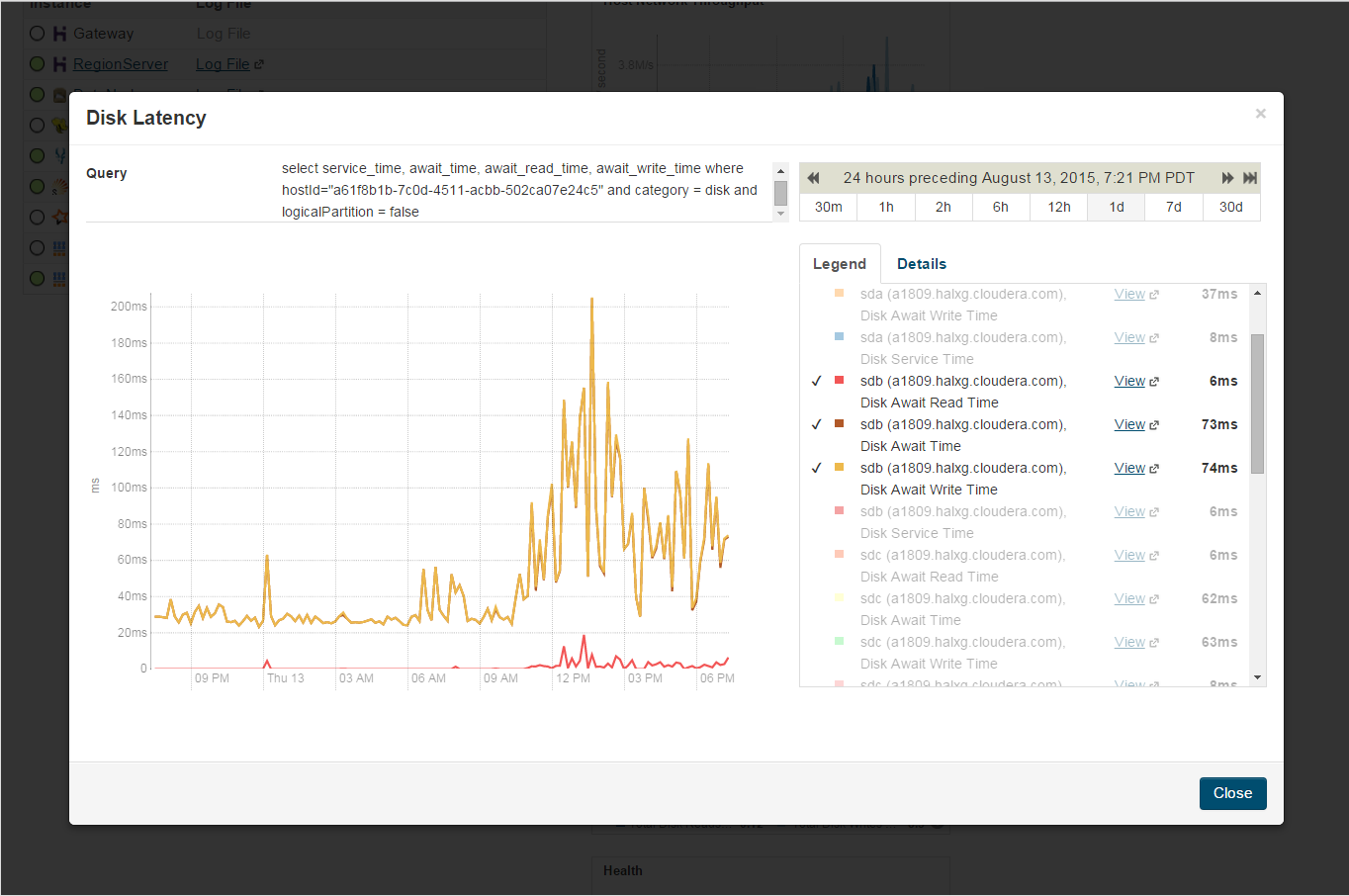
Figure 3-2. Executed query showing average wait time per disk
Finally, troubleshooting in distributed systems like Hadoop is frustrating, to say the least. Logs are stored on different systems by different daemons, and searching through these logs can quickly escalate from tedious to pure insanity. CM has a distributed-log search feature (Figure 3-3) that can search and filter logs based on hostname, service, error level, and other parameters. Administrators can use CM’s log search to quickly locate and identify related errors that occur on different machines.
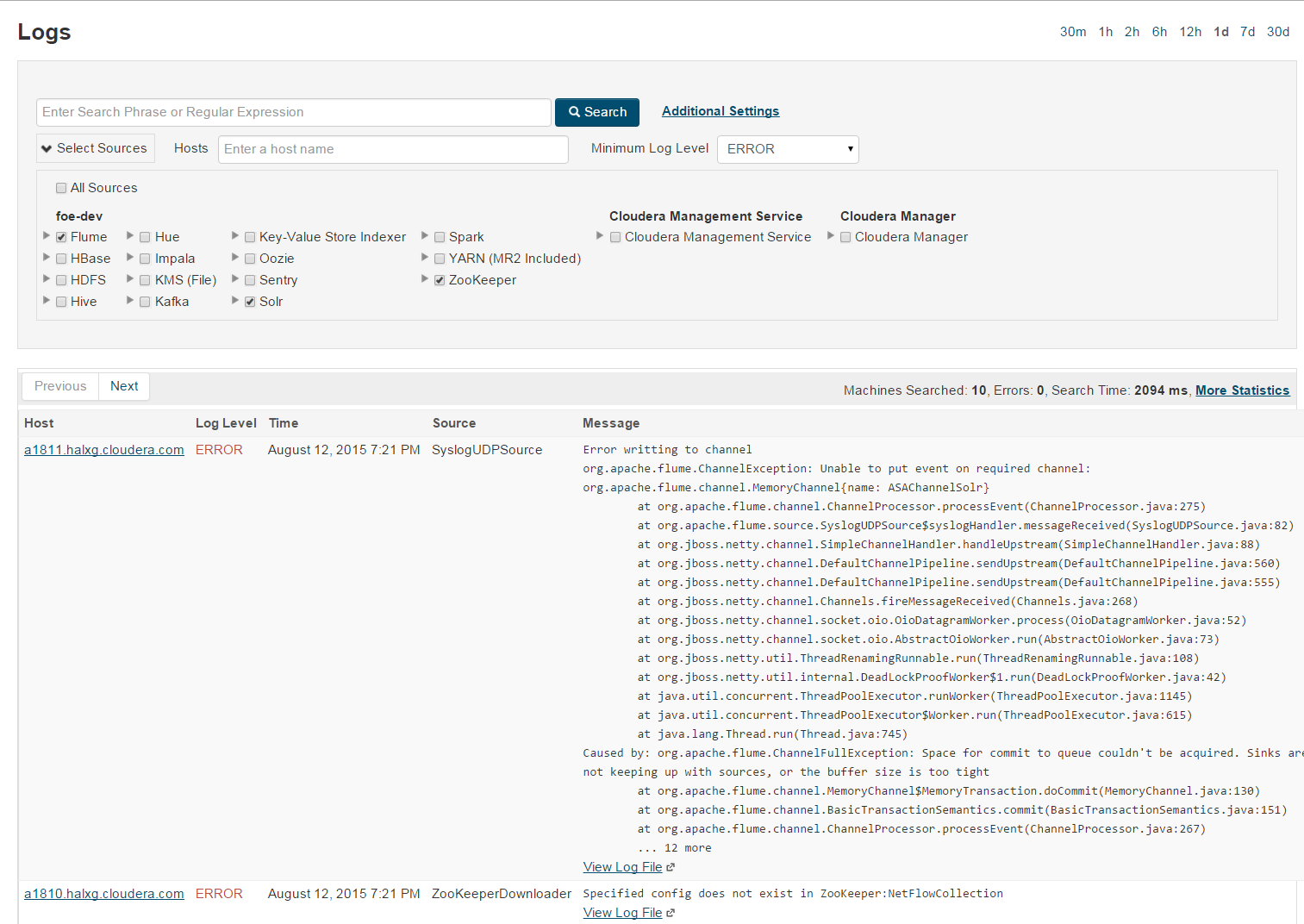
Figure 3-3. Distributed log search, spanning numerous nodes and services looking for ERROR-level logs
For more information, visit the Cloudera website.
Apache Ambari
Apache Ambari is Cloudera Manager’s open source counterpart. Ambari is part of the Apache Foundation and became a top-level project in December 2013. Ambari is equipped with all of the management tool features you would expect; it is capable of deploying, managing, and monitoring a Hadoop cluster. Ambari has some very interesting features that help it stand out as a first-class management tool. The primary differentiating features for Ambari are the support of deployment templates called Blueprints, extensible frameworks like Stacks, and user views for Tez.
The Blueprints architecture is an interesting concept for cluster deployment. Blueprints allow a user to deploy a cluster by specifying a Stack (more on this momentarily), basic component layout, and the configurations for the desired Hadoop cluster instance. Blueprints leverages the REST API, and allows deployment without having to run an install wizard. Blueprints allows users to create their own templates from scratch or by exporting the configuration of a previous cluster. Having seen numerous job failures when promoting from development to quality assurance to production, or from testing disaster recovery plans, being able to export a cluster configuration for deployment is an amazing feature. Blueprints is designed to be utilized without UI interaction; the screenshot in Figure 3-4 shows the Ambari UI in action.
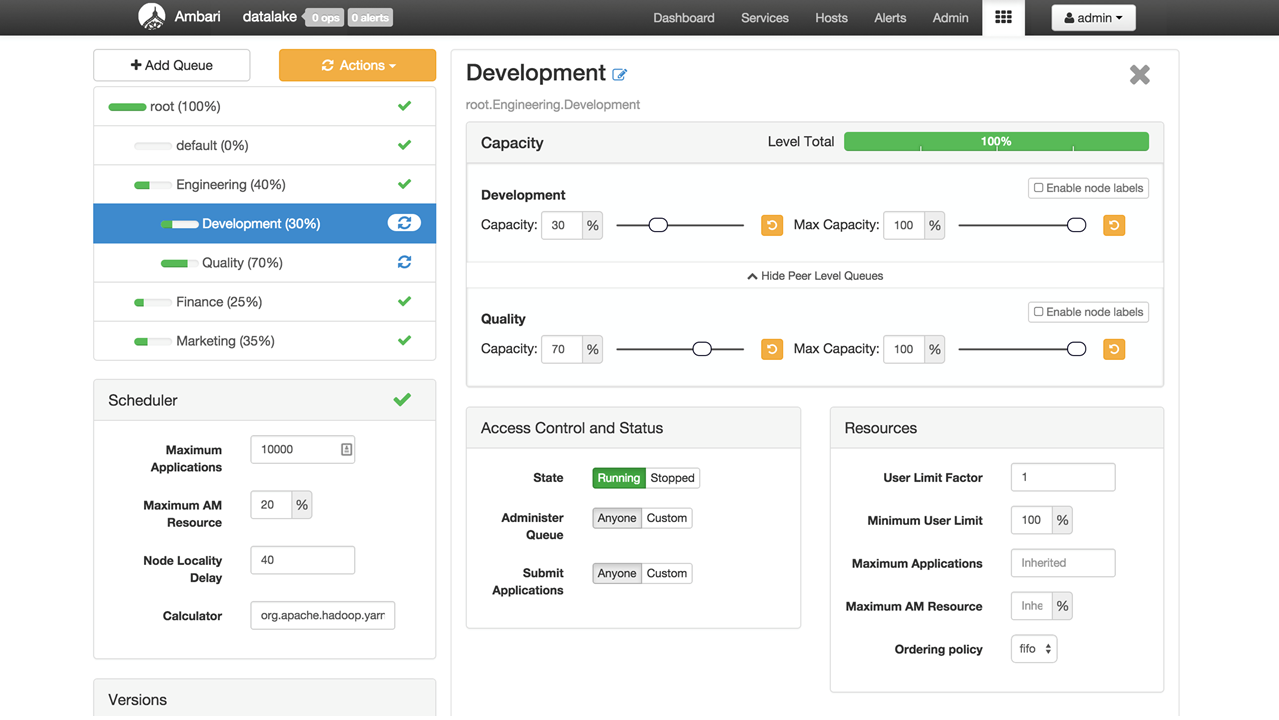
Figure 3-4. Easy YARN scheduler deployment with convenient overview, slide bars, and toggles
Ambari offers an extensible framework called Stacks. Stacks allows users to quickly extend Ambari to leverage custom services. Stacks allows for the addition of custom services and custom client services to be added to the Ambari server for management. This is an amazing feature that can make running services outside the core HDP (Hortonworks Data Platform) release much simpler by unifying the management source. A couple examples of this could be Pivotal HAWQ or Apache Cassandra. Our friends over at ZData Inc. have done a lot of work with Stacks and sent over this example of adding Greenplum to Ambari.
Looking at Figure 3-5, starting in the top left and going clockwise: the first image is creating a configuration, the second image is creating the service, and the final image creating the start/stop script.

Figure 3-5. Example configuration for adding Greenplum
In Figure 3-6, the top screenshot is of the services installed and heartbeating into the Ambari server. The bottom screenshot is selecting the custom Stack to install, which has been provided through the custom configurations.
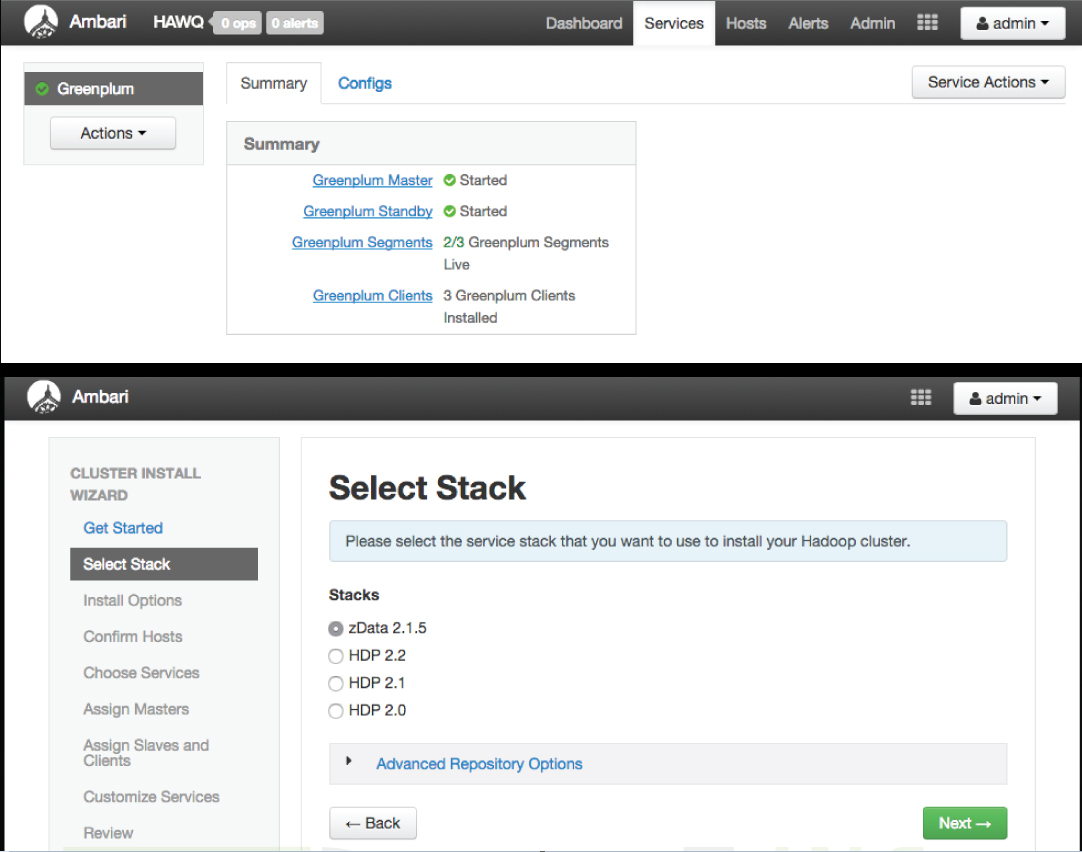
Figure 3-6. Loading the custom stack into the UI
User Views are a particularly exciting way to visualize data. Like Stacks, Ambari Views offers an ability to plug in third-party UI sources to manage data and services not included in stock Ambari. Also, Ambari is kind enough to bundle in a couple out-of-the box DAG flow tools in User Views to get you started. Ambari ships with Capacity Scheduler View and Tez View. Of all the Ambari features, Tez View is by far the coolest, and it showcases what will be possible down the line (Figure 3-7). Tez View offers a visual of the DAGs that have been run. Each job that has been run can be drilled down into a visualization layer that quickly shows how many tasks are running for each part of the job to allow for quick optimizations against skews. Before this feature was available, it took drilling into numerous jobs and logs to attempt to optimize these jobs.
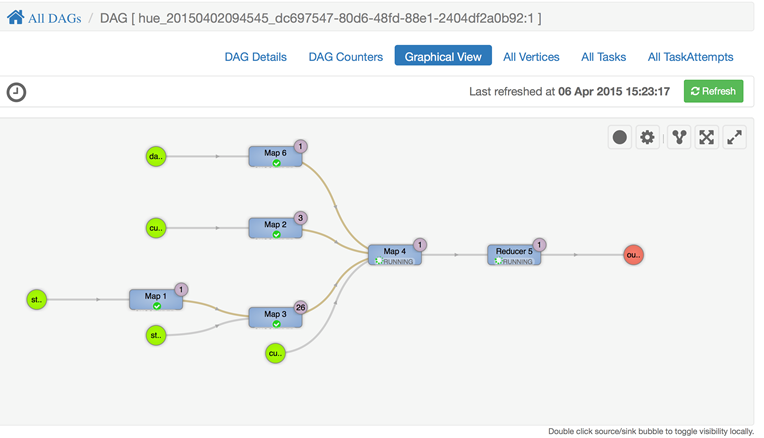
Figure 3-7. Ability to view physical execution of Tez jobs
For more information, visit the Apache Ambari website.
Hannibal
The last management tool we want to mention is not a standalone tool and complements any environment regardless if it is CM, Ambari, or a standalone Puppet/Chef infrastructure. Hannibal is a tool for visualizing different aspects of the HBase internals such as region distribution, region size per table, and region evolution over time. This is extremely powerful information to visualize. All of the information Hannibal presents is available in the HBase logs and quite difficult to parse manually. Hannibal really shines when following best practices, such as manual splitting of regions, as it allows the end user to quickly visualize the largest regions in the table and determine when is the best time to split the region. Region history is also a very fascinating feature, as it allows you to look at the behavior of a region (e.g., HFile count, sizes, and memstore sizes) over a period of time. This is very helpful when adding additional load or nodes to the cluster to verify you are getting the expected behavior. Now for the bad news: it appears that Hannibal is no longer being developed. However, because Hannibal still works with HBase 0.98 and earlier, we felt it was still worthy of inclusion here.
For more information, visit the Hannibal GitHub.
SQL
One of hottest topics for Big Data is SQL on Hadoop. HBase, with numerous offerings, is never one to be left out of the mix. The vast majority of the tools that bring SQL functionality to the Hadoop market are mostly aimed at providing business intelligence functionality. With HBase, there are a few tools that focus on business intelligence, but on an arguably more interesting side, there are a few that focus on full-blown transactional systems. There are three main solutions we will look at: Apache Phoenix, Trafodion, and Splice Machine.
Apache Phoenix
Apache Phoenix was contributed by our friends at Salesforce.com. Phoenix is designed as a relational database layer set on top of HBase designed to handle SQL queries. It is important to note that Phoenix is for business intelligence rather than absorbing OLTP workloads. Phoenix is still a relatively new project (it reached incubator status in December 2013 and recently graduated to a top-level project in May 2014). Even with only a couple years in the Apache Foundation, Phoenix has seen a nice adoption rate and is quickly becoming the de facto tool for SQL queries. Phoenix’s main competitors are Hive and Impala for basic SQL on HBase. Phoenix has been able to establish itself as a superior tool through tighter integration by leveraging HBase coprocessors, range scans, and custom filters. Hive and Impala were both built for full file scans in HDFS, which can greatly impact performance because HBase was designed for single point gets and range scans.
Phoenix offers some interesting out-of-the-box functionality. Secondary indexes are probably the most popular request we receive for HBase, and Phoenix offers three different types: functional indexing, global indexing, and local indexing. Each index type targets a different type of workload; whether it is read heavy, write heavy, or needs to be accessed through expressions, Phoenix has an index for you. Phoenix will also help to handle the schema, which is especially useful for time series records. You just have to specify the number of salted buckets you wish to add to your table. By adding the salted buckets to the key and letting Phoenix manage the keys, you will avoid very troublesome hot spots that tend to show their ugly face when dealing with time series data.
For more information, visit the Apache Phoenix website.
Apache Trafodion
Trafodion is an open source tool and transactional SQL layer for HBase being designed by HP and currently incubating in Apache. Unlike Phoenix, Trafodion is more focused on extending the relational model and handling transactional processes. The SQL layer offers the ability to leverage consistent secondary indexes for faster data retrieval. Trafodion also offers some of its own table structure optimizations with its own data encoding for serialization and optimized column family and column names. The Trafodion engine itself has implemented specific technology to support large queries as well as small queries. For example, during large joins and grouping, that Trafodion will repartition the tables into executor server processes (ESPs), outside of the HBase RegionServers, then the queries will be performed in parallel. An added bonus is Trafodion will optimize the SQL plan execution choices for these types of queries. Another interesting feature is the ability to query and join across data sources like Hive and Impala with HBase. Like Phoenix, Trafodion does not offer an out-of the-box UI, but expects BI tools or custom apps built on ODBC/JDBC to connect to Trafodion.
For more information, visit the Apache Trafodion website.
Splice Machine
Splice Machine is a closed source offering targeting the OLTP market. Splice Machine has leveraged the existing Apache Derby framework for its foundation. Splice Machine’s primary goal is to leverage the transaction and SQL layer to port previous relational databases on to HBase. Splice Machine has also developed its own custom encoding format for the data which heavily compresses the data and lowers storage and retrieval costs. Similar to the previously discussed SQL engines, the parallel transaction guarantees are handled through custom coprocessors, which enables the high level of throughput and scalability these transactional systems are able to achieve. Like Trafodion, Splice Machine can also just leverage the SQL layer for business reporting from not just HBase, but Hive and Impala as well.
For more information, visit Splice Machine’s website.
Honorable Mentions (Kylin, Themis, Tephra, Hive, and Impala)
There are also numerous other systems out there to bring SQL and transaction functionality to HBase:
-
Apache Kylin (originally contributed by eBay) is designed for multidimensional online analytical processing (MOLAP) and relational online analytical processing (ROLAP). Kylin is interesting because the data cubes have to be pre-created in Hive and then pushed over to HBase. Kylin is designed for large-scale reporting as opposed to real-time ingest/serving systems.
-
Themis is a cross row/cross table transaction built on top of HBase sponsored by XiaoMi.
-
Tephra is another transaction system brought to us by the team at Cask.
-
Finally, Hive and Apache Impala are storage engines both designed to run full table or partitioned scans against HDFS. Hive and Impala both have HBase storage handlers allowing them to connect to HBase and perform SQL queries. These systems tend to pull more data than the other systems, which will greatly increase query times. Hive or Impala make sense when a small set of reference data lives in HBase, or when the queries are not bound by SLAs.
Frameworks
Another interesting aspect of the HBase ecosystem is frameworks. There are many different types of frameworks available on the market for HBase. Some frameworks specialize in handling time series data, while others focus on codifying best practices, handling the use of different languages, or moving to an asynchronous client model. We will take a deeper look at the OpenTSDB framework, which is really almost a standalone application, before moving on to discuss Kite, HappyBase, and AsyncHBase.
OpenTSDB
OpenTSDB is one of the most interesting applications we will talk about. OpenTSDB is not a framework itself, but it takes the place of a custom framework for handling time series data. OpenTSDB is designed as a time series database on top of HBase. It has a full application layer integrated for querying and presenting the data, as well as frameworks written on top of it for ingesting the time series data. It is a pretty straightforward system, where individual, stateless collectors called time series daemons (TSDs) receive the time series data from the servers. Those TSDs then act as clients and write the data to HBase using a schema designed for fetching the series data over a period of time in an efficient manner. The end user never directly accesses HBase for any of the data. All necessary calls are funneled through the TSDs. OpenTSDB also has a basic UI (Figure 3-8) built into it for graphing the different metrics from the time series data. The TSDs can also expose an HTTP API for easily querying data to be consumed by third-party monitoring frameworks or reporting dashboards.
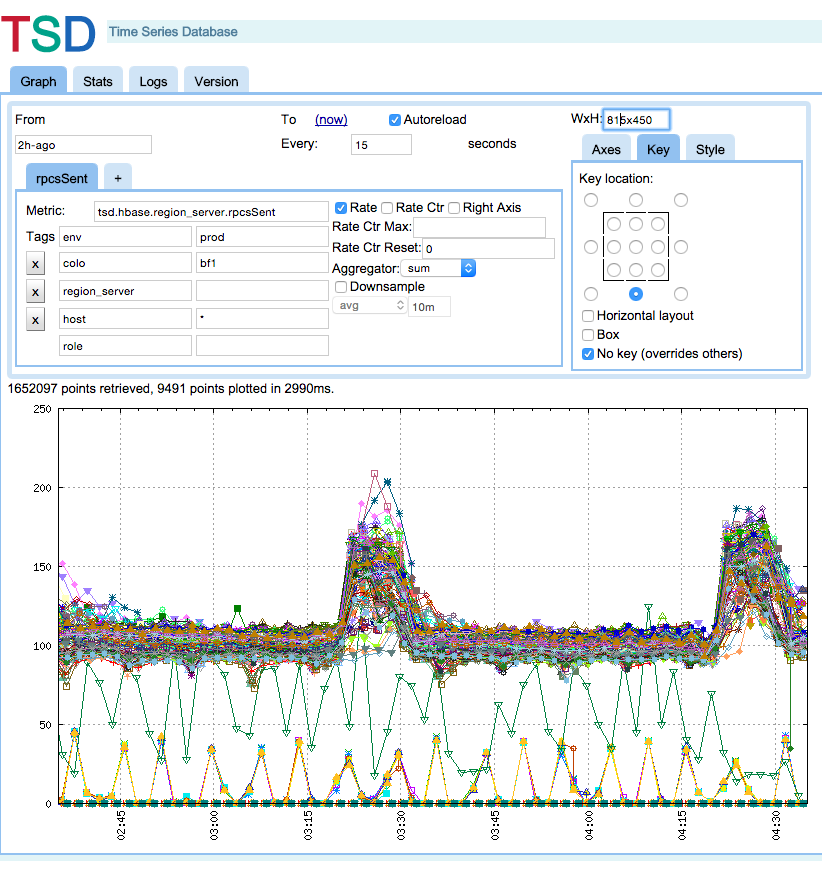
Figure 3-8. OpenTSDB offers a fully functional UI out of the box
For more information, visit OpenTSDB’s website.
Kite
There are quite a few different frameworks that either replace or alter the HBase client’s behavior. Kite is a whole SDK designed to codify Hadoop best practices. Kite also comes with a prebuilt transformation, aggregation, and extract library set called Morphlines. Kite on HBase is relatively new and still flagged as experimental. The portion of Kite designed for HBase is in heavy use in Cloudera for its Customer Operations Tools Team. It is being based on the internal library known as HBase-common. The goal is to codify how the records should be stored in HBase columns to optimize for storage and performance efficiency. Kite offers the ability to map specific HBase columns, and has many different flexible options. The column mapping is stored in JSON and is used to write the Avro records into the HBase table structure. Kite also offers a simple way to load data into the cluster. Once the configuration has been stored, all Kite writers know exactly how to put the data into the dataset without having to reconfigure each writer. Kite also leverages the concept of datasets. The dataset used can be Hadoop, Hive, or HBase. By pre-creating these datasets, Kite knows how and where to write the data into Hadoop, thus saving many hours of direct coding.
For more information, visit Kite’s website.
HappyBase
The HappyBase framework is designed to allow the end user to leverage the HBase client through the use of Python. HappyBase is designed to allow Python to access the HBase system by leveraging the Thrift gateway. HappyBase supports the vast majority of functions an HBase application needs in order to flourish, right down to atomic counters and batch mutations. HappyBase is great for getting an application up and running, but leveraging the Thrift interface brings a few different issues to light. You should consider how you are going to load balance and handle failovers (pro tip: HAProxy is your friend), and the thrift interface will be slower than the direct Java API.
For more information visit the HappyBase website.
AsyncHBase
Finally, the AsyncHBase project (which happens to be part of OpenTSDB) is one we run into out in the field constantly. AsyncHBase is a client replacement that offers better throughput and performance if your data can be processed asynchronously. One of the coolest features of AsyncHBase is the ease of deploying a multithreaded application using the single client. You should keep in mind that it is not a trivial matter to switch back and forth between the clients, as they require almost a complete rewrite. This is a very popular library for handling time series data without fully deploying OpenTSDB.
For more information, visit the OpenTSDB’s GitHub.