Chapter 6. Use Case: HBase as a System of Record
The first use case that we will examine is from Omneo (a division of Camstar, a Siemens Company). Omneo is a big data analytics platform that assimilates data from disparate sources to provide a 360-degree view of product quality data across the supply chain. Manufacturers of all sizes are confronted with massive amounts of data, and manufacturing datasets comprise the key attributes of big data. These datasets are high volume, rapidly generated, and come in many varieties. When tracking products built through a complex, multitier supply chain, the challenges are exacerbated by the lack of a centralized data store and because there is no unified data format. Omneo ingests data from all areas of the supply chain, such as manufacturing, test, assembly, repair, service, and field.
Omneo offers this system to its end customers as a software-as-a-service (SaaS) model. This platform must provide users the ability to investigate product quality issues, analyze contributing factors, and identify items for containment and control. The ability to offer a rapid turnaround for early detection and correction of problems can result in greatly reduced costs and significantly improved consumer brand confidence. Omneo starts by building a unified data model that links the data sources so users can explore the factors that impact product quality throughout the product lifecycle. Furthermore, Omneo provides a centralized data store, and applications that facilitate the analysis of all product quality data in a single, unified environment.
Omneo evaluated numerous NoSQL systems and other data platforms. Its parent company, Camstar, has been in business for over 30 years, giving Omneo a well-established IT operations system. When Omneo was created, the team was given carte blanche to build its own system. Knowing the daunting task of handling all of the data at hand, Omneo decided against building a traditional EDW. Although other big data technologies such as Cassandra and MongoDB were considered, Hadoop was ultimately chosen as the foundation for the Omneo platform. The primary reason for this decision came down to ecosystem or lack thereof from the other technologies. The fully integrated ecosystem that Hadoop offered with MapReduce, HBase, Solr, and Impala allowed Omneo to handle the data in a single platform without the need to migrate the data between disparate systems.
The solution must be able to handle the data of numerous products and customers being ingested and processed on the same cluster. This can make handling data volumes and sizing quite precarious, as one customer could provide 80%–90% of the total records. At the time of writing, Omneo hosts multiple customers on the same cluster for a rough record count of 6+ billion records stored in ~50 nodes. The total combined set of data in the HDFS is approximately 100 TBs. Importantly, as we get into the overall architecture of the system, we will note where duplicating data is mandatory and where savings can be introduced by using a unified data format.
Omneo has fully embraced the Hadoop ecosystem for its overall architecture, and also takes advantage of Hadoop’s Avro data serialization system. Avro is a popular file format for storing data in the Hadoop world. Avro allows for a schema to be stored with data, making it easier for different processing systems (e.g., MapReduce, HBase, and Impala/Hive) to easily access the data without serializing and deserializing the data over and over again.
The high-level Omneo architecture consists of the following phases:
-
Ingest/pre-processing
-
Processing/serving
-
User experience
Ingest/Pre-Processing
The ingest/pre-processing phase includes acquiring the flat files, landing them in HDFS, and converting the files into Avro. As illustrated in Figure 6-1, Omneo currently receives all files in a batch manner. The files arrive in a CSV format or in an XML file format. The files are loaded into HDFS through the HDFS API. Once the files are loaded into Hadoop, a series of transformations are performed to join the relevant datasets together. Most of these joins are done based on a primary key in the data (in the case of electronic manufacturing, this is normally a serial number to identify the product throughout its lifecycle). These transformations are all handled through the MapReduce framework. Omneo wanted to provide a graphical interface for consultants to integrate the data rather than code custom MapReduce. To accomplish this, Omneo partnered with Pentaho to expedite time to production. Once the data has been transformed and joined together, it is then serialized into the Avro format.
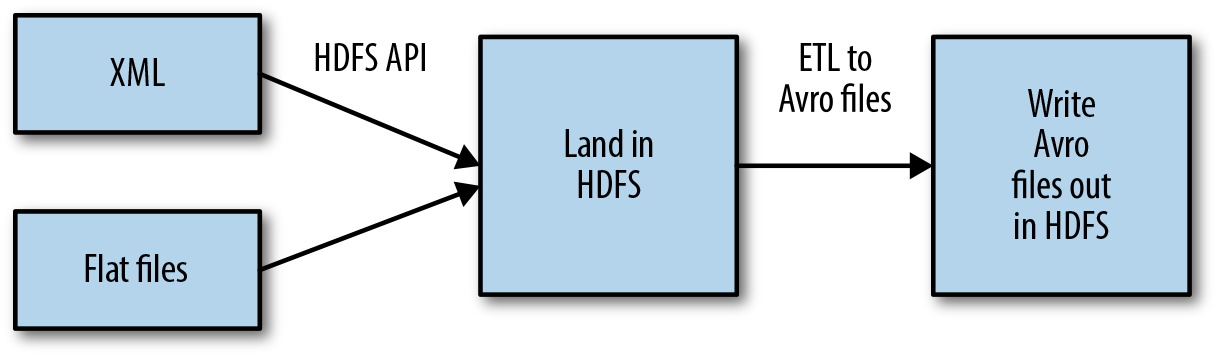
Figure 6-1. Batch ingest using HDFS API
Processing/Serving
Once the data has been converted into Avro, it is loaded into HBase (as illustrated in Figure 6-2). Because the data is already being presented to Omneo in batch, we take advantage of this and use bulk loads. The data is loaded into a temporary HBase table using the bulk loading tool. The previously mentioned MapReduce jobs output HFiles that are ready to be loaded into HBase. The HFiles are loaded through the completebulkload tool, which works by passing in a URL that the tool uses to locate the files in HDFS. Next, the bulk load tool will load each file into the relevant region being served by each RegionServer. Occasionally, a region has been split after the HFiles were created, and the bulk load tool will automatically split the new HFile according to the correct region boundaries.
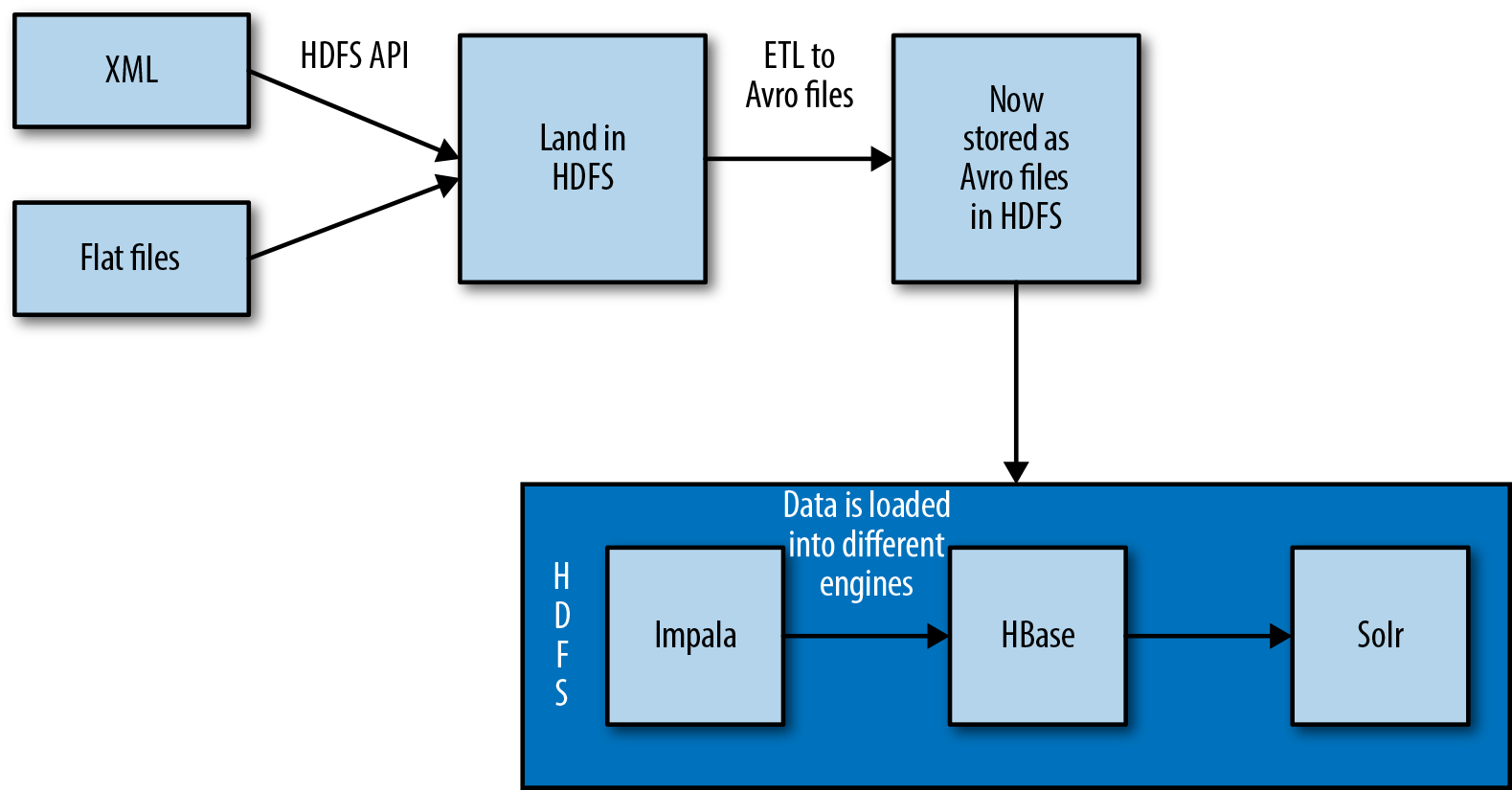
Figure 6-2. Using Avro for a unified storage format
Once the data is loaded into the staging table, it is then pushed out into two of the main serving engines, Solr and Impala. Omneo uses a staging table to limit the amount of data read from HBase to feed the other processing engines. The reason behind using a staging table lies in the HBase key design. One of the cool things about this HBase use case is the simplicity of the schema design. Normally, many hours will be spent figuring out the best way to build a composite key that will allow for the most efficient access patterns, and we will discuss composite keys in later chapters.
However, in this use case, the row key is a simple MD5 hash of the product serial number. Each column stores an Avro record. The column name contains the unique ID of the Avro record it stores. The Avro record is a de-normalized dataset containing all attributes for the record.
After the data is loaded into the staging HBase table, it is then propagated into two other serving engines. The first serving engine is Cloudera Search (Solr) and the second is Impala. Figure 6-3 illustrates the overall load of data into Solr.
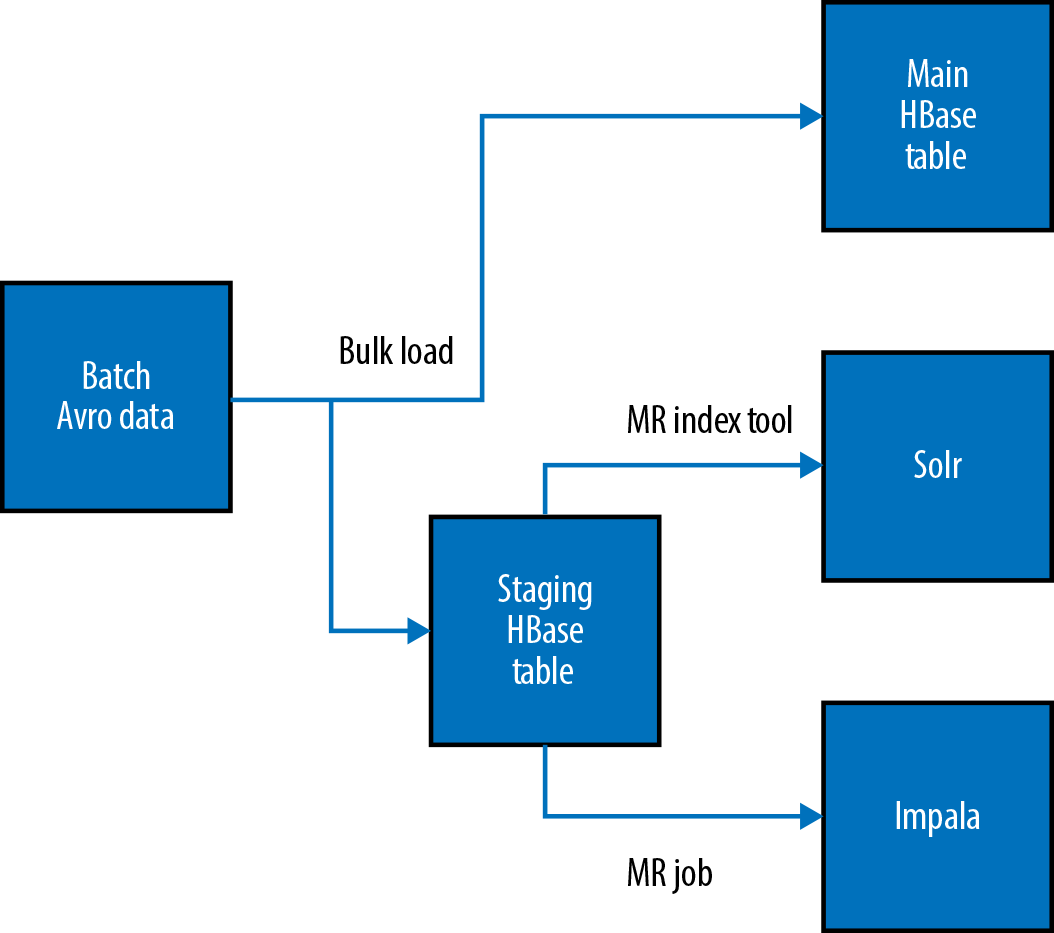
Figure 6-3. Data flowing into HBase
The data is loaded into Search through the use of a custom MapReduceIndexerTool. The default nature of the MapReduceIndexerTool is to work on flat files being read from HDFS. Given the batch aspect of the Omneo use case, the team modified the indexer tool to read from HBase and write directly into the Solr collection through the use of MapReduce. Figure 6-4 illustrates the two flows of the data from HBase into the Solr collections. There are two collections in play for each customer—in this case, there is collection A (active), collection B (backup)—and an alias that links to the “active” collection. During the incremental index, only the current collection is updated from the staging HBase table through the use of the MapReduceIndexerTool. As shown in Figure 6-4, the HBase staging table loads into collection A and the alias points to the active collection (collection A). This approach—that is, using dual collections in addition to an alias—offers the ability to drop all of the documents in a single collection and reprocess the data without suffering an outage. This gives Omneo the ability to alter the schema and push it out to production without taking more downtime.
The bottom half of Figure 6-4 illustrates this action; the MapReduceIndexerTool is re-indexing the main HBase table into collection B while the alias is still pointing to collection A. Once the indexing step completes, the alias will be swapped to point at collection B and incremental indexing will be pointed at collection B until the dataset needs to be re-indexed again.
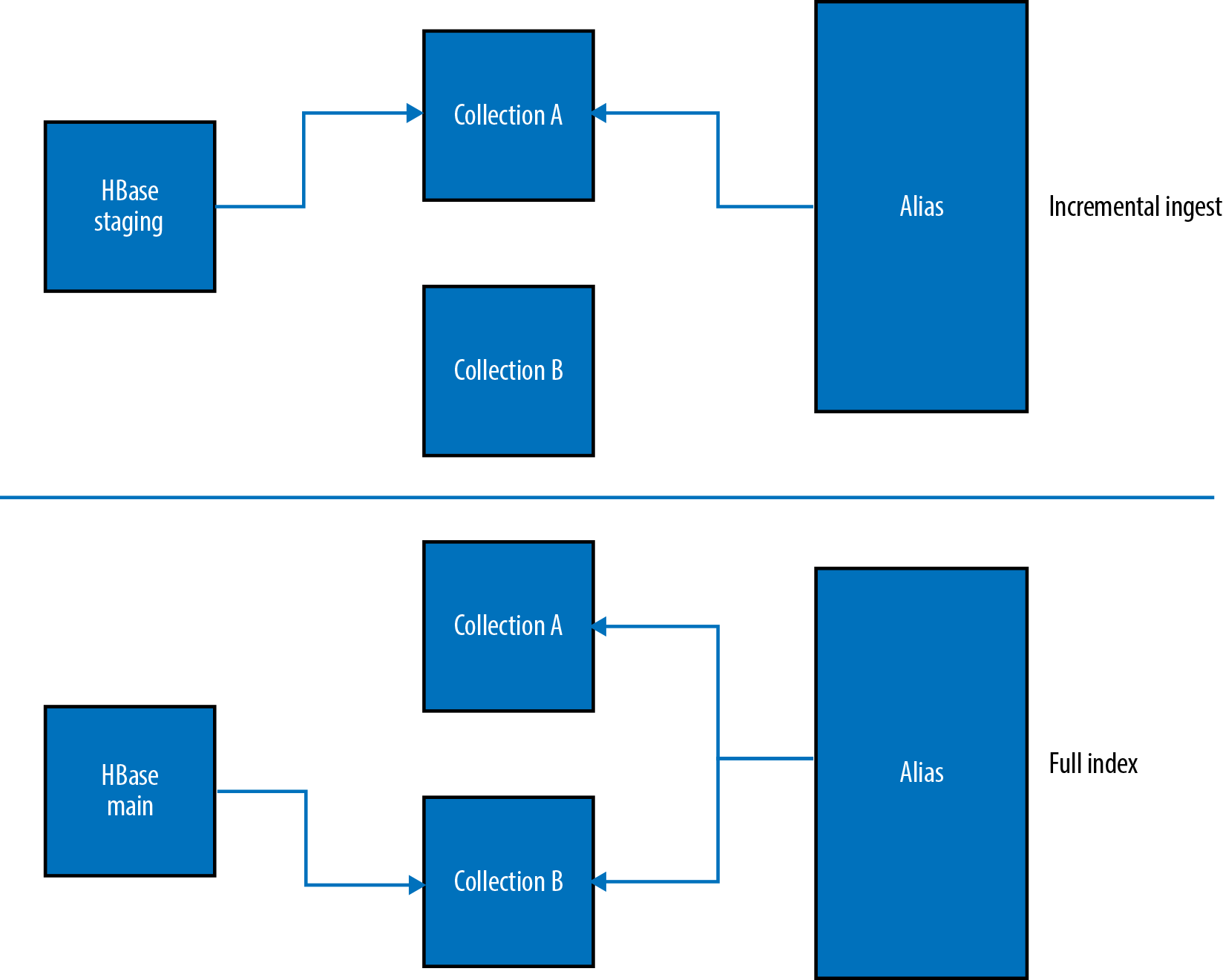
Figure 6-4. Managing full and incremental Solr index updates
This is where the use case really gets interesting. HBase serves two main functions in the overall architecture. The first one is to handle the master data management (MDM), as it allows updates. In this case, HBase is the system of record that Impala and Solr use. If there is an issue with the Impala or Solr datasets, they will rebuild them against the HBase dataset. In HBase, attempting to redefine the row key typically results in having to rebuild the entire dataset. Omneo first attempted to tackle faster lookups for secondary and tertiary fields by leveraging composite keys. It turns out the end users enjoy changing the primary lookups based on the metrics they are looking at. For example, they may look up by part time, test, date, or any other arbitary field in the data. This is one of the reasons Omneo avoided leveraging composite keys, and used Solr to add extra indexes to HBase. The second and most important piece is HBase actually stores all of the records being served to the end user. Let’s look at a couple sample fields from Omneo’s Solr schema.xml:
<schema name="example" version="1.5">
<fields>
<field name="id" type="string" indexed="true" stored="true" required="true"
multiValued="false" />
<field name="rowkey" type="binary" indexed="false" stored="true"
omitNorms="true" required="true"/>
<field name="eventid" type="string" indexed="true" stored="false"
omitNorms="true" required="true"/>
<field name="docType" type="string" indexed="true" stored="false"
omitNorms="true"/>
<field name="partName" type="lowercase" indexed="true" stored="false"
omitNorms="true"/>
<field name="partNumber" type="lowercase" indexed="true" stored="false"
omitNorms="true"/>
…
<field name="_version_" type="long" indexed="true" stored="true"/>
</fields>
Looking at some of the fields in this schema.xml file, we can see that Omneo is only flagging the HBase row key and the required Solr fields (id and _version_) as Stored, which will directly write these results to HDFS. The other fields are flagged as Indexed; which will store the data in a special index directory in HDFS. The indexed attribute makes a field searchable, sortable, and facetable; it is also stored in memory. The stored attributes make the fields retrievable through search and persisted to HDFS. Omneo ingests records that can have many columns present, ranging from hundreds to thousands of fields depending on the product being ingested. For the purposes of faceting and natural language searching, typically only a small subset of those fields are necessary. The amount of fields indexed will vary per customer and use case. This is a very common pattern, as the actual data results displayed to the customer are being served from the application calling scans and multigets from HBase based on the stored data. Just indexing the fields serves multiple purposes:
-
All of the facets are served out of memory from Solr, offering tighter and more predictable SLAs.
-
The current state of Solr Cloud on HDFS writes the data to HDFS per shard and replica. If HDFS replication is set to the default factor of 3, then a shard with two replicas will have nine copies of the data on HDFS. This will not normally affect a search deployment, as memory or CPU is normally the bottleneck before storage, but it will use more storage.
-
Indexing the fields offers lightning-fast counts to the overall counts for the indexed fields. This feature can help to avoid costly SQL or pre-HBase MapReduce-based aggregations
The data is also loaded from HBase into Impala tables from the Avro schemas and converted into the Parquet file format. Impala is used as Omneo’s data warehouse for end users. The data is populated in the same manner as the Solr data, with incremental updates being loaded from the HBase staging table and full rebuilds being pulled from the main HBase table. As the data is pulled from the HBase tables, it is denormalized into a handful of tables to allow for an access pattern conducive to Impala. As shown in Figure 6-5, the data model used is part of Omneo’s secret sauce.

Figure 6-5. Nah, we can’t share that. Get your own!
User Experience
Normally we do not spend a ton of time looking at end applications, as they tend to be quite different per application. However, in this case, it is important to discuss how everything comes together. As shown in Figure 6-6, combining the different engines into a streamlined user experience is the big data dream. This is how companies move from playing around to truly delivering a monumental product.
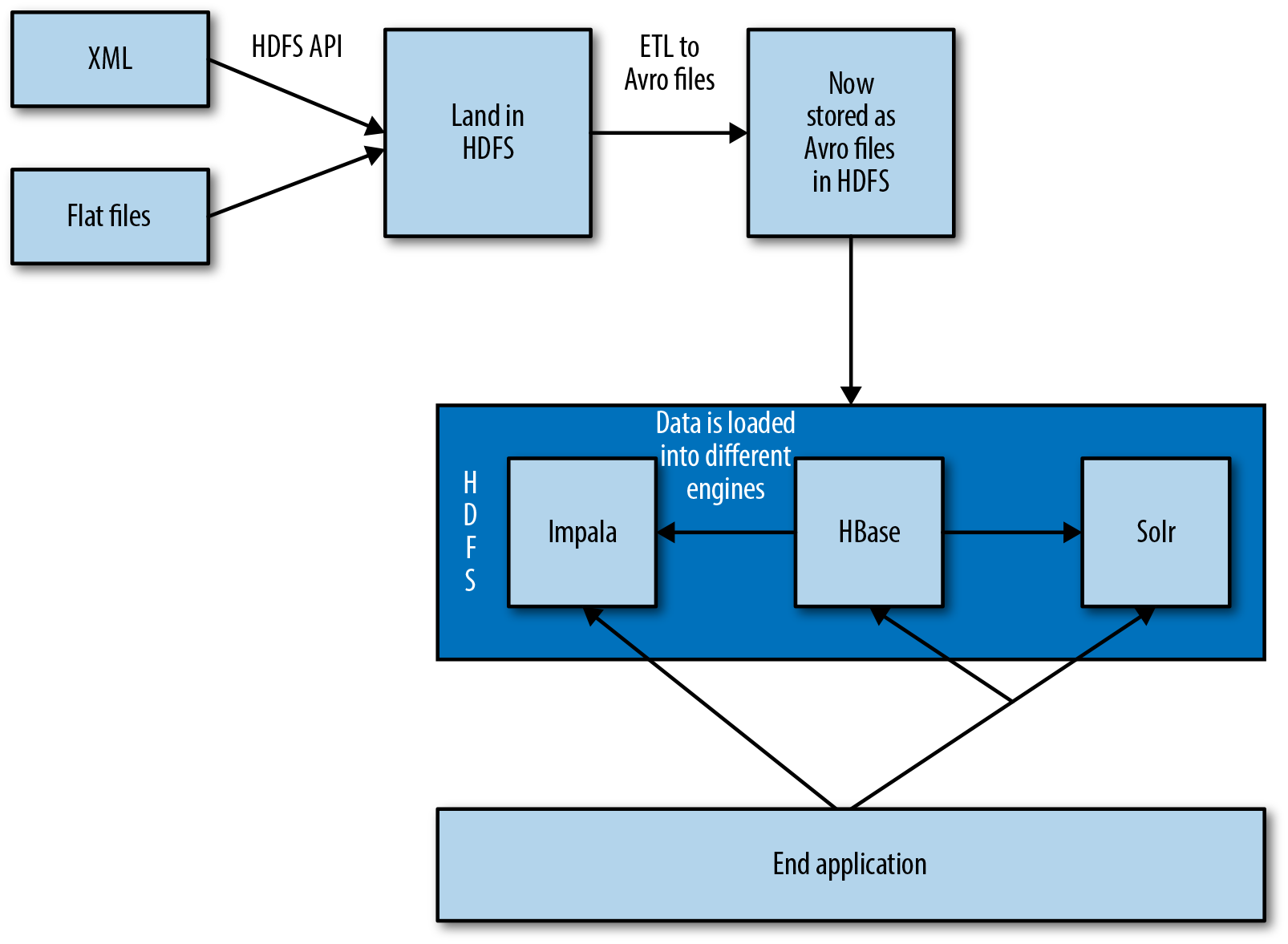
Figure 6-6. Overall data flow diagram, including the user interaction
The application makes use of all three of the serving engines in a single interface. This is important for a couple of key reasons: first, it allows for increased productivity from the analyst, as it’s no longer necessary for the analyst to switch between different UIs or CLIs; second, the analyst is able to use the right tool for the right job. One of the major issues we see in the field is customers attempting to use one tool to solve all problems. By allowing Solr to serve facets and handle natural language searches, HBase to serve the full fidelity records, and Impala to handle the aggregations and SQL questions, Omneo is able to offer the analyst a 360-degree view of the data.
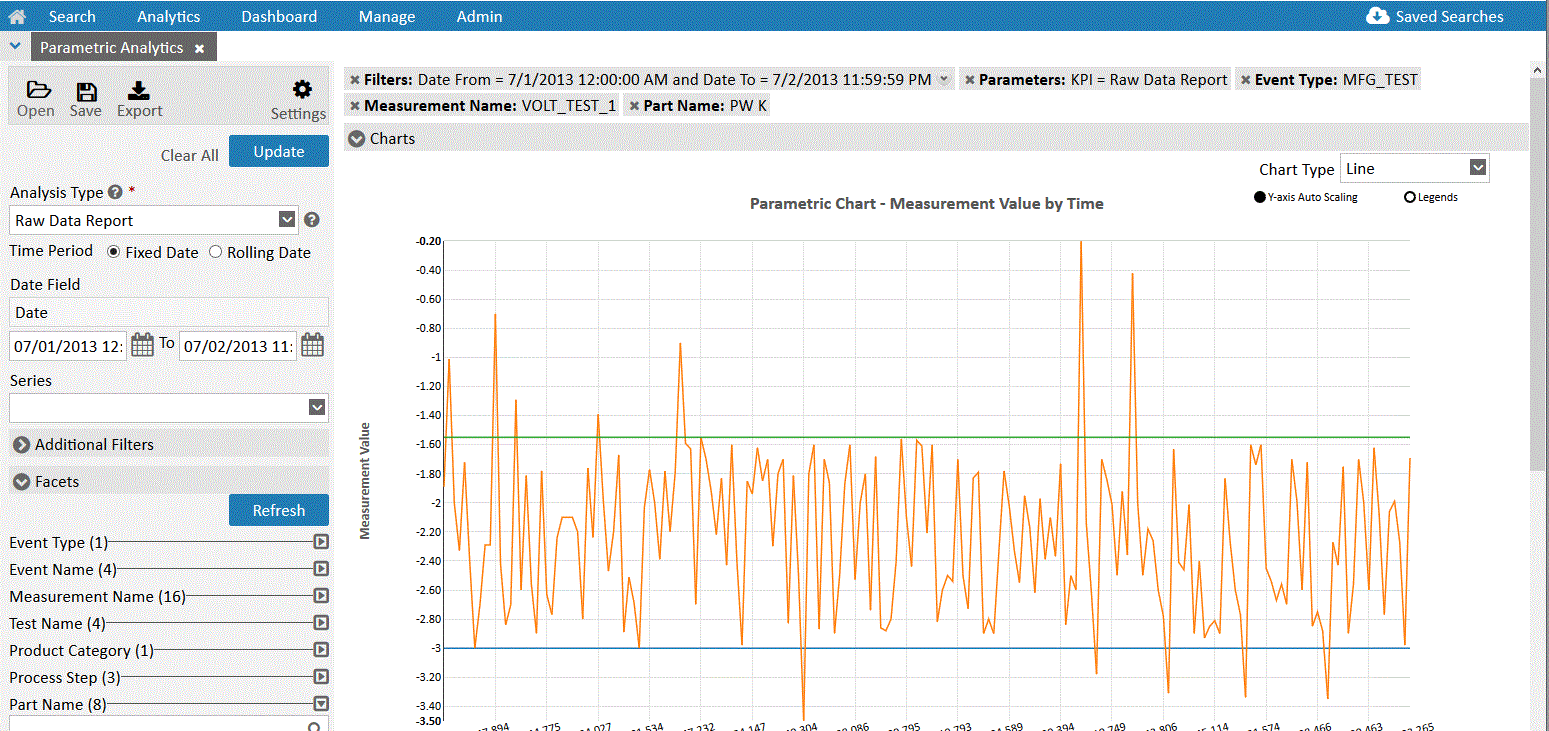
Let’s start by looking at the Solr/HBase side of the house. These are the two most intertwined services of the Omneo application. As mentioned before, Solr stores the actual HBase row key and indexes the vast majority of other fields that the users like to search and facet against. In this case, as the user drills down or adds new facets (Figure 6-7), the raw records are not served back from Solr, but rather pulled from HBase using a multiget of the top 50 records. This allows the analyst to see the full fidelity record being produced by the facets and searches. The same thing holds true if the analyst wishes to export the records to a flat file; the application will call a scan of the HBase table and write out the results for end user.
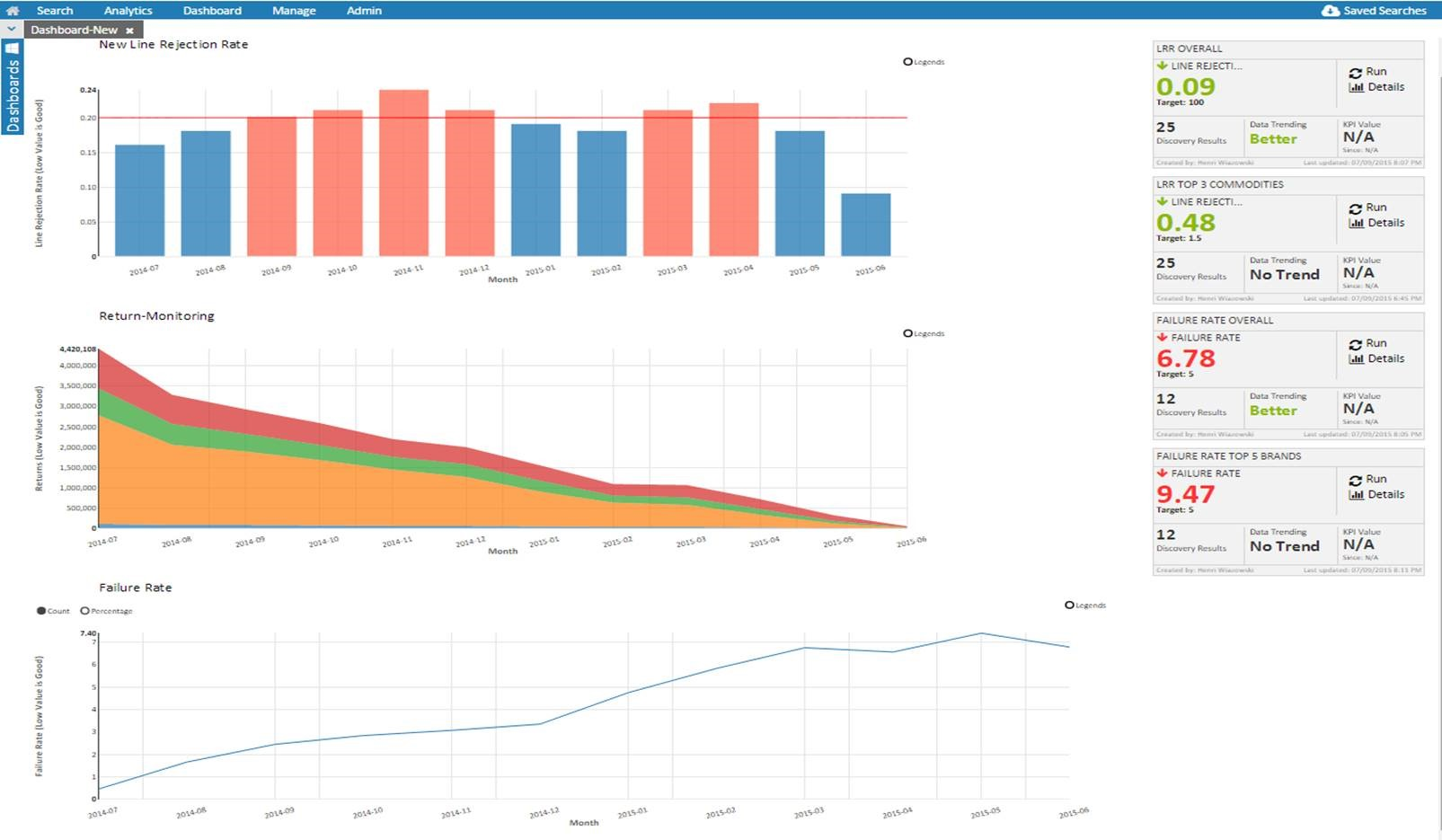
Figure 6-7. Check out this Solr goodness
On the Impala side of the house, also known as performance analytics, models are built and managed to handle SQL-like workloads. These are workloads that would normally be forced into HBase or Solr. Performance analytics was designed to run a set of pre-packed application queries that can be run against the data to calculate key performance indicators (KPIs), as shown in Figure 6-8. The solution does not allow for random free-form SQL queries to be utilized, as long-running rogue queries can cause performance degradation in a multitenant application. In the end, users can select the KPIs they want to look at, and add extra functions to the queries (sums, avg, max, etc.).