Chapter 8. Use Case: Near Real-Time Event Processing
This next use case focuses on handling claims records for the healthcare industry. The claims processor utilizes a software-as-a-service (SaaS) model to act as a bridge for patients, hospitals, and doctor’s offices. Because medical claims are quite difficult to manage for many hospitals and healthcare providers, the claims processor (also known as a clearinghouse) accepts claims from customers (i.e., hospitals and doctor’s offices) and then formats those claims to send to the payer. This is a difficult and tedious process, as most hospitals and doctor’s offices did not traditionally use a standardized format for claims. This is where the clearinghouse comes in to submit all claims in a unified format designed specifically for the payer.
Compared to the previous use cases, the clearinghouse has a few extra layers of complexity. For example, this data is not just machine-generated data to be loaded in batch; the incoming data has to be processed inflight. In addition, because the data is classified as personally identifiable information (PII) or protected health information (PHI), and thus protected under the Health Insurance Portability and Accountability Act (HIPAA), it requires numerous layers of security. This use case focuses on electronic medical claims records and creating a system to process these records. The end objective for this system is to lower the typical claims processing time from 30 days to eventually processing the claims in real time, by optimizing the claim to ensure all of the necessary information is present, and instantly rejecting claims before sending them to the insurance provider. The ideal service-level agreement (SLA) behind a system like this is to have the claim ready for review from the system in less than 15 seconds to be available for lookup and reference from the customer, claims processor, and payers. Because the system needs to serve external requests in real time, the cluster is required to have a 99.9% uptime, which weighed heavily into the decision to use Hadoop and HBase. There is also a concept of milestones, which require the ability to update the current claims record on the fly without knowing the number of updates a single record may receive. This plays right into HBase’s strengths with the ability to handle sparse data and add thousands of columns without thinking twice.
The claims provider looked at numerous other systems to solve this use case. When evaluating the technologies for this project, the provider was lucky that this was a net new project. This gave a clean slate for technologies to choose from. The first technology looked at was Oracle RAC, which was at the time the current incumbent database. The provider performed some load testing at the volumes of data expected, but unfortunately RAC was not able to keep up. Next up was Netezza, which was nixed for lack of small files and total cost of ownership. Finally, Cassandra was evaluated. Because the use case required access to different processing layers, it was ruled out in favor of the complete Hadoop ecosystem. The current cluster houses roughly 178 TB of data in HDFS with 40 TB of that data living in the HBase instance, which is sized to handle roughly 30,000 events per second, and serve roughly 10 requests per second from Solr.
As mentioned earlier, this cluster currently contains PHI data. The overall requirements for storing this type of protected data are not only limited to technology, but to process as well. We will briefly focus on the technical requirements for storing this data in the system. These strict guidelines also weighed heavily in the choice of technology. These guidelines are taken very seriously, as the administrators of the system can incur large fines as well as jail time if they are found to be in violation of the law. When dealing with PHI, the claims provider is required to offer a strong layer of authentication, authorization, and encryption.
This claims provider wanted to ensure all levels were properly met before deploying the system. For the authentication layer, the provider went with the industry standard of Kerberos. Authorization is controlled from a few different places; the first is leveraging HBase’s built-in ACLs, the second is through HDFS ACLs, and finally, Sentry for the Search and Impala layer. The encryption layer started out with Vormetric, which did not seem to include a large performance hit, but later the provider moved to Gazzang encryption to leverage the integrated KeyStore and AES-NI for offloading the processing to the CPU. The claims provider also leverages Cloudera Navigator for auditing, data lineage, and metadata tagging.
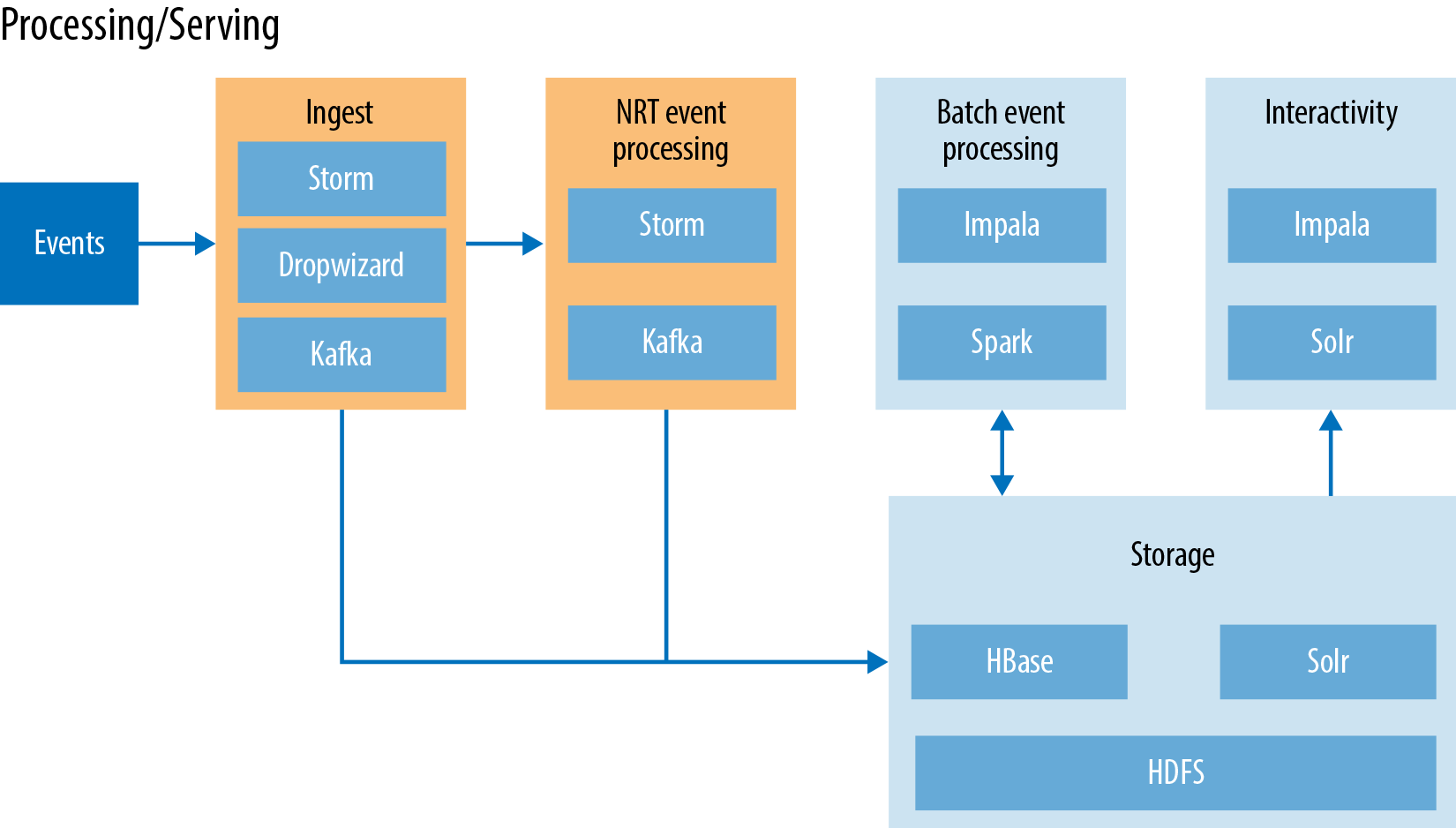
Figure 8-1 illustrates the overall architecture. This diagram might be a bit daunting at first, as it contains a few Hadoop ecosystem technologies that we have not yet reviewed. Before diving into the different layers, let’s spend a minute looking a little deeper into Kafka and Storm, which play a major role in the near real-time pipeline.
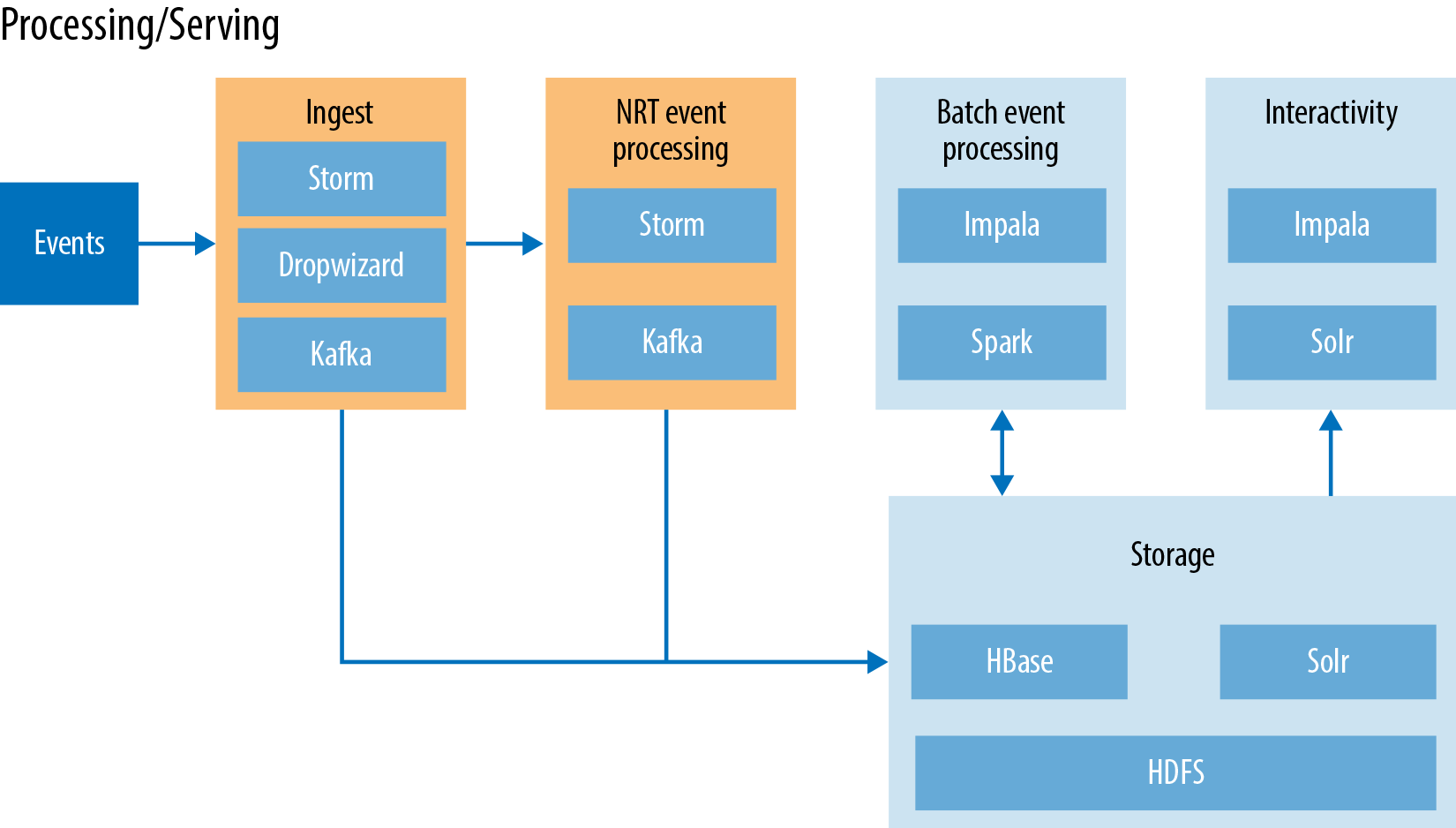
Figure 8-1. Architecture overview
Kafka is going to be a recurring component in the wonderful world of real-time ingest. Kafka maintains different streams of messages referred to as topics. The processes that publish messages to a Kafka topic are called producers. There are numerous pre-created producers (similar to Flume Sources), or you can always write your own producer depending on use case requirements. The processes reading from the topics are known as consumers. Consumers are also typically responsible for writing to the downstream applications. Kafka is traditionally run as a cluster comprised of one or more nodes, each of which is called a broker. These consumers are broken up into consumer groups, each of which handle their own offset allowing for consumers to be able to easily subscribe and unsubscribe without affecting other consumers reading for the same topic. Kafka allows for very high read and write throughput through the use of partitions that can be tuned to take advantage of numerous spindles inside the Kafka nodes.
Now that you have an understanding of the new technologies in play, let’s break the architecture into three separate categories:
-
Ingest/pre-processing
-
Near real-time event processing
-
Processing/serving
Ingest/Pre-Processing
In this use case, we are primarily looking at three different data sources. The first is an enterprise messaging aystem (EMS), the second is from Oracle RAC databases, and the third is from a custom on-premise solution. Both the on-premise and EMS system are sending new claims records, where the Oracle RAC is sending the updated milestones about each record to Kafka (Figure 8-2). Each ingest flow has roughly the same path minus the initial collection tool. In this case, there are two primary tools in place: first is Apache Storm and Dropwizard. Apache Storm is a distributed ingest system designed for processing streams of data in real time. Storm is a very popular choice for ingest as it allows for a higher level of complex event processing (CEP) than offered by Apache Flume. We will spend more time talking about Storm’s CEP capabilities later in this chapter. The other initial ingest tool in place is Dropwizard, which is an open source Apache Licensed Java Framework for quickly developing web services. Dropwizard take numerous production-ready libraries and bundles them together for a quicker development cycle. It also has prebuilt integration with Kafka, eliminating the need to write a custom Kafka producer.
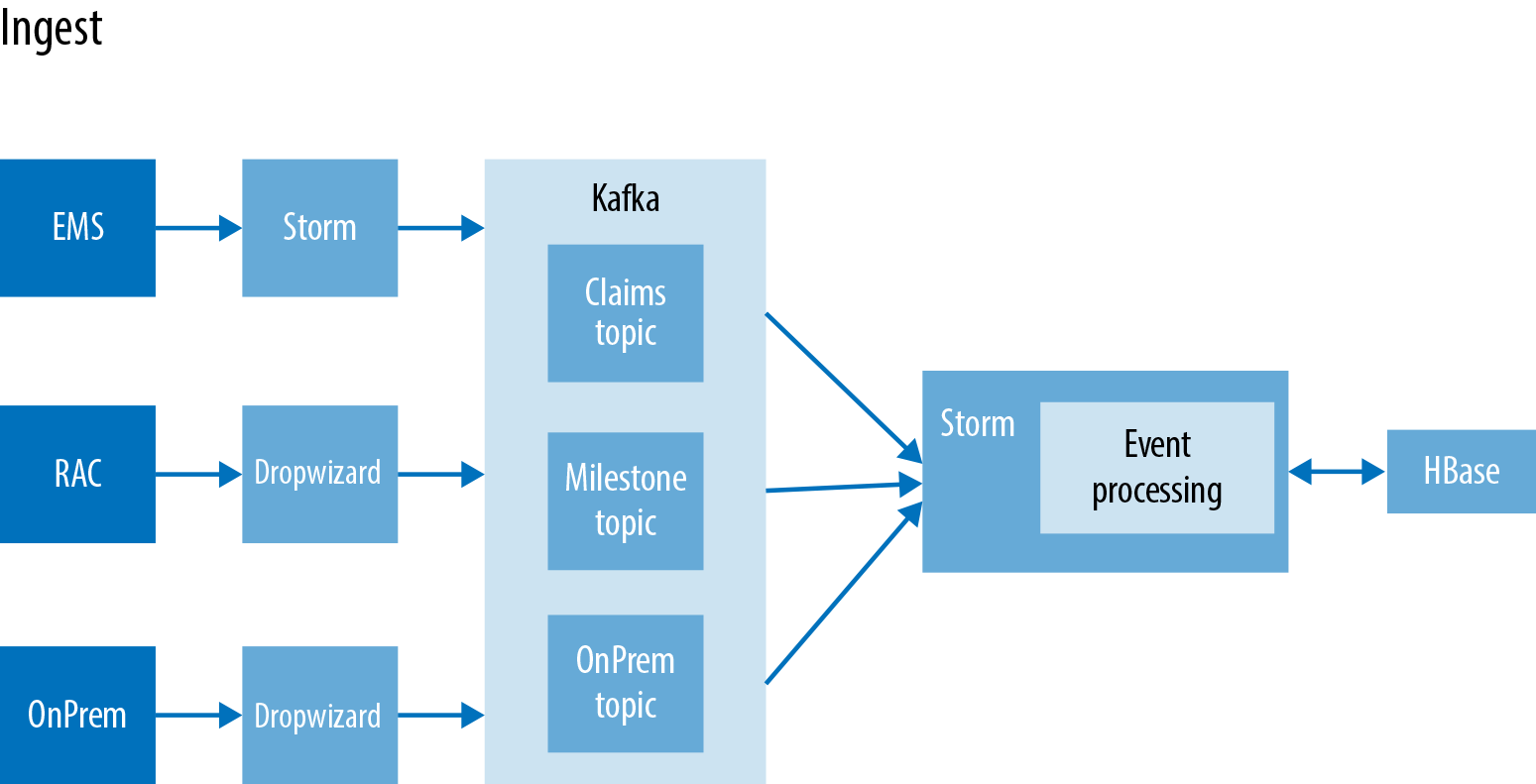
Figure 8-2. Detailed ingest pipeline
In this use case, we are using three separate topics, one for each ingest path. This allows for the end user to be able to add other systems to read from an individual topic without having to receive all of the other unwanted data. In this case, the numerous topics are being used simply for ease of management and future extensibility. From Kafka, we have a single Storm topology pulling from the three main Kafka topics.
Near Real-Time Event Processing
The main portion of the ETL work all resides inside this Storm topology. The Storm topology includes the concept of Bolts, which enable us to perform the CEP tasks that need to be done. The consumers in this case will be Kafka spouts for Storm. The Storm Bolt will receive the events from the Kafka Spout where the event enrichment will occur (Figure 8-3). We have two streams that need to be processed: the new claims records and milestones. They both need some separate processing, which Storm makes easy by allowing numerous streams to occur in a single topology. As the claims come in, they need to be enriched with previously stored data or messages. This process includes adding missing traits, such as name, doctor, hospital, address, the internal claim IDs, and the external claim ID. It is important to remember that the naming structure might differ from one claim provider to the next. It is important for claim providers to be able to identify the same claim every time. The milestones are enriching claims with updated data, and new status levels that are going to be used in the serving layer.
Figure 8-3. Inflight event processing
The HBase row key design has to be carefully considered when dealing with PII data. One of the most important requirements around handling healthcare information is the ability to guarantee never exposing the wrong customer information. In this case, the row key is a concatenation of the customerID and a random hash. Looking at the three relevant tables:
-
Lookups - InternalID
-
ClaimsID - claimsID
-
Claims - CustomerID|random hash
The customer ID must be the first part of the key as this guarantees that when the application does a look up in HBase, only that record is served back. The problem is most customer IDs tend to increment in the system and are usually just a series of numbers. By adding the random hash to the end of the key, it allows for additional lexicographic sort split purposes. The most ideal row key distribution would be a simple MD5 hash, which has an astronomically low collision rate—this would spread the keys around evenly and make for a smoother write path. However, when dealing with PII data, it is a gamble to use the MD5 hash, no matter how low the risk. Remember, people win the lottery every day!
Processing/Serving
We have taken a look at the ingest and CEP layer of the pipeline. Everything we have discussed occurs outside the cluster, except for the Storm bolts calling Gets and Puts for HBase. The claims provider uses a combination of Impala, Spark, Solr, and the almighty HBase (it is the focal point of the book). HBase in this case is used in numerous ways: in addition to being the record of truth for claims, it is also used to rebuild Solr indexes and Impala tables when the data shifts, and to enrich and update incoming claims and milestones. The data coming into HBase is all being loaded through the Java API inside the Storm Bolts through the use of Gets, Puts, and check and swap operations. Once the data is written to HBase, the claims provider then leverages the Lily Indexer to write the new records and updates to Solr. The Lily Indexer is an interesting piece of software, as it allows indexing into SolrCloud without having do any custom coding. The Lily Indexer works by acting as a replication sink for HBase. As with HBase replication, the Indexer processes the write asynchronously as to not interrupt other incoming writes.
One of the coolest features of the Lily Indexer is that it piggybacks on the previously built HBase replication functionality. This means the progress is stored in ZooKeeper and it leverages the HBase HLogs. By using the previously built replication framework, the Lily Indexer is fault tolerant and can survive region and Solr Server failures without having data loss. This is very important when storing medical claims, as accuracy and data protection are two of the top concerns. As discussed in the previous chapter, Solr is not only housing the data being searched, but the HBase row key as well. This row key is going to be used later when we discuss the Spark processing layer. Once the data is in Solr, it can be accessed two different ways (Figure 8-4). The primary way the data is accessed is through Dropwizard services taking advantage of the Solr API to pull the latest claims and milestone data for the end users. The other way is from Spark, which is for running special machine learning over the data.
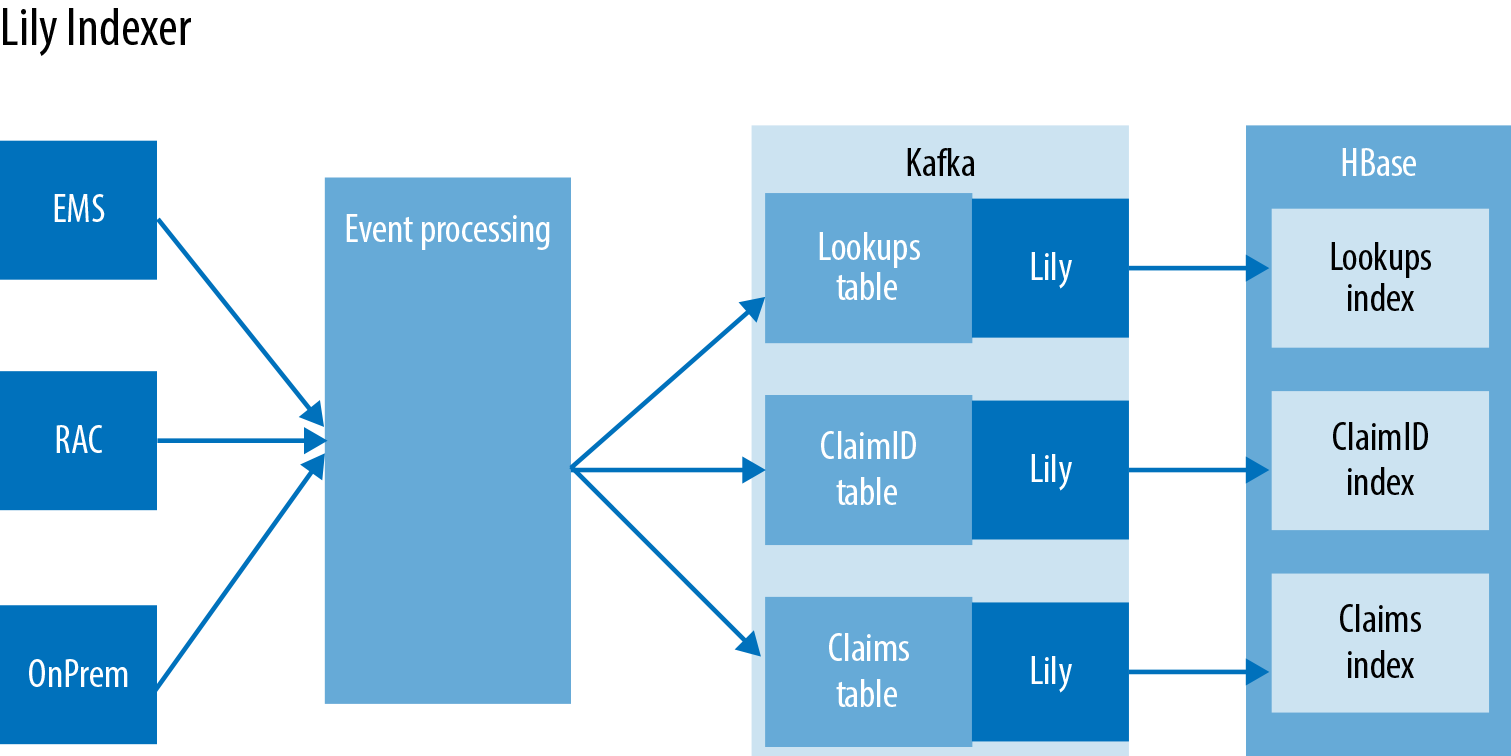
Figure 8-4. Replicating HBase to Solr using Lily
Spark is being used to identify claims that are missing key pieces of data, or have incorrect data processed in the wrong fields. Solr is perfect for this, and can act as secondary, tertiary, quarterly, etc. indexes, because by default HBase can only query the primary row key. The first thing we do is query Solr to pull the specific records that we want; these records will also contain the HBase row key. Once we have the HBase row key, we can perform gets/multigets and scans, depending on the query results from Solr. Once we have the data from HBase, a series of data models (sorry, not trying to be vague, but we do need to protect some IP!) is applied to the result set. The output of Spark is then sent over to the alerting system, which triggers milestones to alert the customer that there are missing fields, or other attributes that need to be filled in before processing can continue (Figure 8-5).
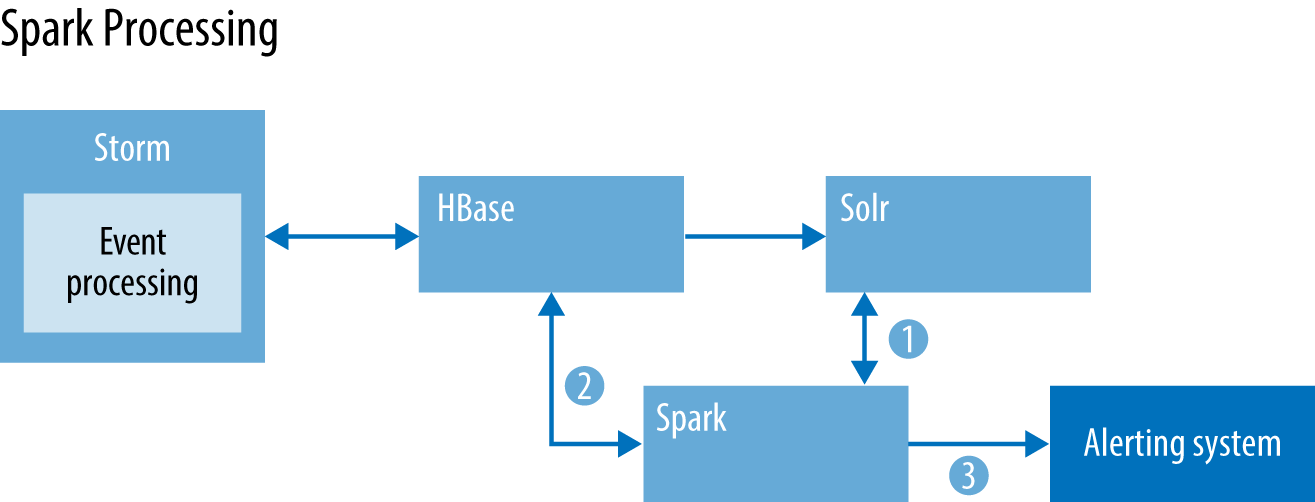
Figure 8-5. Spark processing workflow