
Chapter 10. Use Case: HBase as a Master Data Management Tool
Next, we will take a look at the New York–based digital advertising company Collective. Collective is an advertising technology company that helps companies impact the bottom line by connecting brands and customers together. This approach is known as customer 360, and to execute efficiently, it requires numerous data sources and boatloads of data. Collective leverages Hadoop and HBase to help offer their clients a unified view of the consumer and allowing brands to seamlessly message across channels and devices, including PCs, tablets, and smartphones.
When looking at customer 360, Hadoop is the obvious choice. A solid customer 360 implementation gets better and better as data sources are added. Most data sources that customers interact with on a regular basis tend to create unstructured data. Some of the typical data sources seen in a customer 360 are clickstream through offerings like Adobe Omniture or IBM Tealeaf and social media data either directly through Twitter and Facebook, or more often, from curated data services providers such as Gnip and Datasift; these data sources are then joined with the all-powerful (and homegrown) customer profile. Maintaing an up-to-date, complete customer profile on an immutable filesystem like HDFS is not a trival task. Collective needed a system that could combine these numerous data sources, which fit poorly into a relational system, into a unified customer—and that’s where HBase comes in.
At first, Collective tried a couple standalone relational systems and was attempting to push the data from the Hadoop ETL jobs. The company started to run into problems of serving the data to end users when the cache on a node or two became full. This caused the disks to start thrashing, and would require a major hardware overhaul to handle the data in a traditional manner. Most of these relational systems require vertical scalability as opposed to horizontal scalability. These relational systems typically require more memory and leverage expensive solid-state drives (SSDs). On the flip side, HBase utilizes commodity hardware and SATA drives. This is what led Collective to start looking at HBase. Luckily, Collective already had a Hadoop cluster in play, and had the advantage of seamlessly integrating HBase into the existing infrastructure with minor development and cost overhead.
Collective currently has 60 RegionServers deployed serving 21 TBs of data out of HBase alone. Collective’s HBase deployment is pretty straightforward. For this use case, there is a single table that handles the user profile data. The table is broken into three column families consisting of visitor, export, and edge. The “visitor” CF contains the metadata about the user. This will consist of information such as date of birth, behavior information, and any third-party lookup IDs. The “export” CF contains the segment information (an example of a segment would be male, 25 years old, likes cars), and any relevant downstream syndication information needed for processing. The “edge” CF contains the activity information of the user, along with any of the additional data that may come in from the batch imported data:
COLUMN CELL edge:batchimport ts=1391769526303, value=x00x00x01Dx0BxA3xE4. export:association:cp ts=1390163166328, value=6394889946637904578 export:segment:13051 ts=1390285574680, value=x00x00x00x00x00x00x00x00 export:segment:13052 ts=1390285574680, value=x00x00x00x00x00x00x00x00 export:segment:13059 ts=1390285574680, value=x00x00x00x00x00x00x00x00 … visitor:ad_serving_count ts=1390371783593, value=x00x00x00x00x00x00x1A visitor:behavior:cm.9256:201401 ts=1390163166328, value=x00x00x00x0219 visitor:behavior:cm.9416:201401 ts=1390159723536, value=x00x00x00x0119 visitor:behavior:iblocal.9559:2 ts=1390295246778, value=x00x00x00x020140120 visitor:behavior:iblocal.9560:2 ts=1390296907500, value=x00x00x00x020140120 visitor:birthdate ts=1390159723536, value=x00x00x01CxABxD7xC4( visitor:retarget_count ts=1390296907500, value=x00x00x00x00x00x00x00x07
As already mentioned, Collective is a digital advertising company that enhances offers and profiles through consumer interactions. Each user is tracked through a custom cookie ID that is generated upstream in the process. The row key is a reverse of that cookie ID. This begs the question of why to reverse a generated UUID. There are two primary offenders that require reverse keys: websites and time series data. In this case, the beginning of the cookie ID has the timestamp on it. This would lead to monotonically increasing row keys; by simply reversing the row key, the randomly generated portion now occurs first in the row key.
Ingest
In Chapters 8 and 9, we looked at near real-time ingest pipelines and batch loading processes. Next, we are going to look at combining the two while using HBase as the system of record, which is sometimes referred to as master data management (MDM); a system of record is used as the “golden copy” of the data. The records contained in HBase will be used to rebuild any Hive or other external data sources in the event of bad or wrong data. The first piece we will examine is batch processing. For this system, Collective built a tool that pulls in third-party data sources from numerous data sources covering S3, SFTP sites, and a few proprietary APIs (Figure 10-1). The tool pulls from these data sources on an hourly basis and loads the data into a new HDFS directory using the Parquet file format. A new Hive partition is then created on top of the newly loaded data, and then linked to the existing archive table.
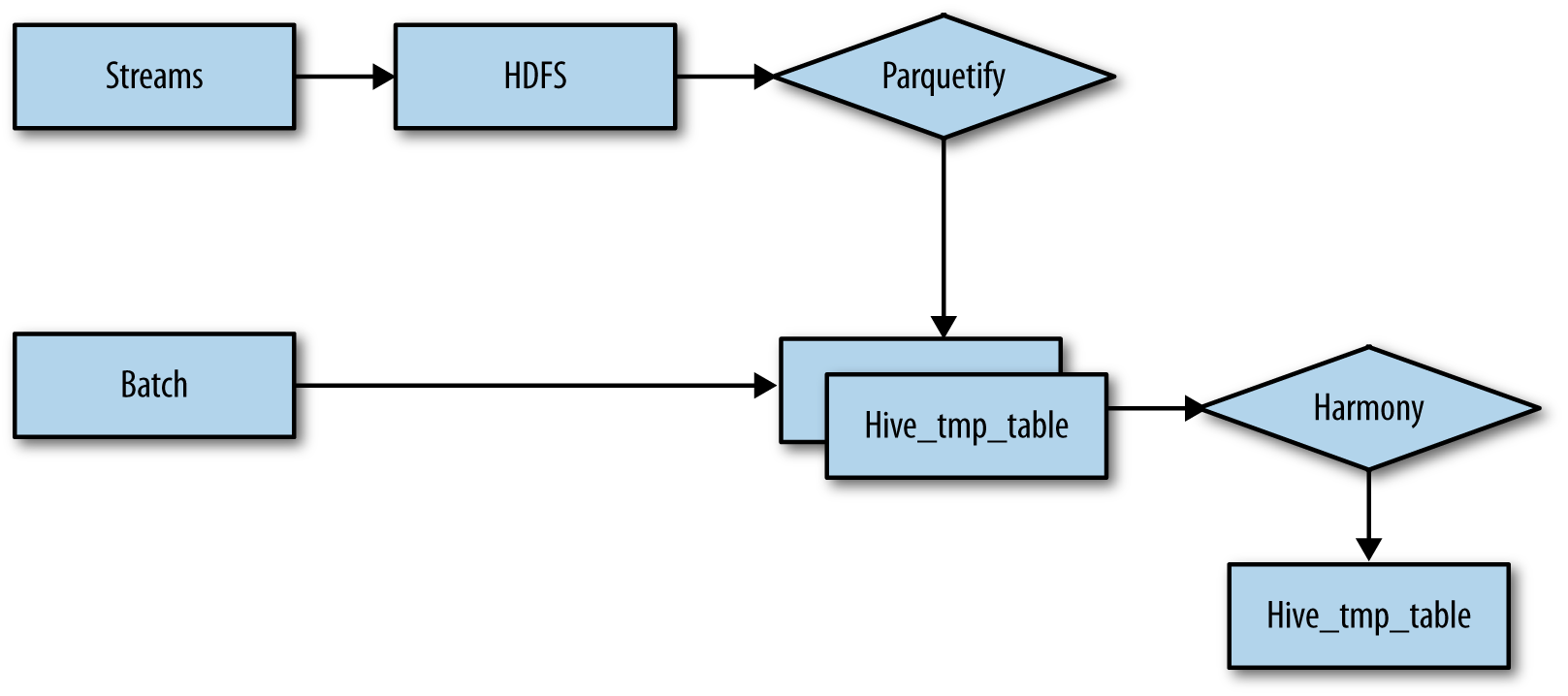
Figure 10-1. Ingest dataflow
The other side of the house is the near real-time processing, which is currently being handled by Flume. Flume brings in data from different messaging services, which is pushed into a system known as Parquetify. The Parquetify system, which runs hourly, prepares the data into a unified file format, wraps a temporary table around the data, and then inserts the data into the main archive Hive tables. In this case, the file format used for this data is Parquet files. Once the data is loaded into the system, the aptly named preprocessor Harmony is run every hour in a custom workflow from Celos. Harmony collects and preprocesses the necessary data from the previously listed sources. This is used to normalize the output together for the formal transformation stages. Currently this runs in a series of Flume dataflows, MapReduce jobs, and Hive jobs. Collective is in the process of porting all of this to Kafka and Spark, which will make processing both easier and faster.
Processing
Once Harmony has joined the inbound data together, it is then sent for final processing into another internal system that coordinates a series of MapReduce jobs together known as Pythia (Figure 10-2). The MapReduce jobs create a write-ahead log (WAL) for maintaining data consistency in case of failures. There are three total steps in this process:
-
Aggregator
-
ProfileMod
-
Update MDM system
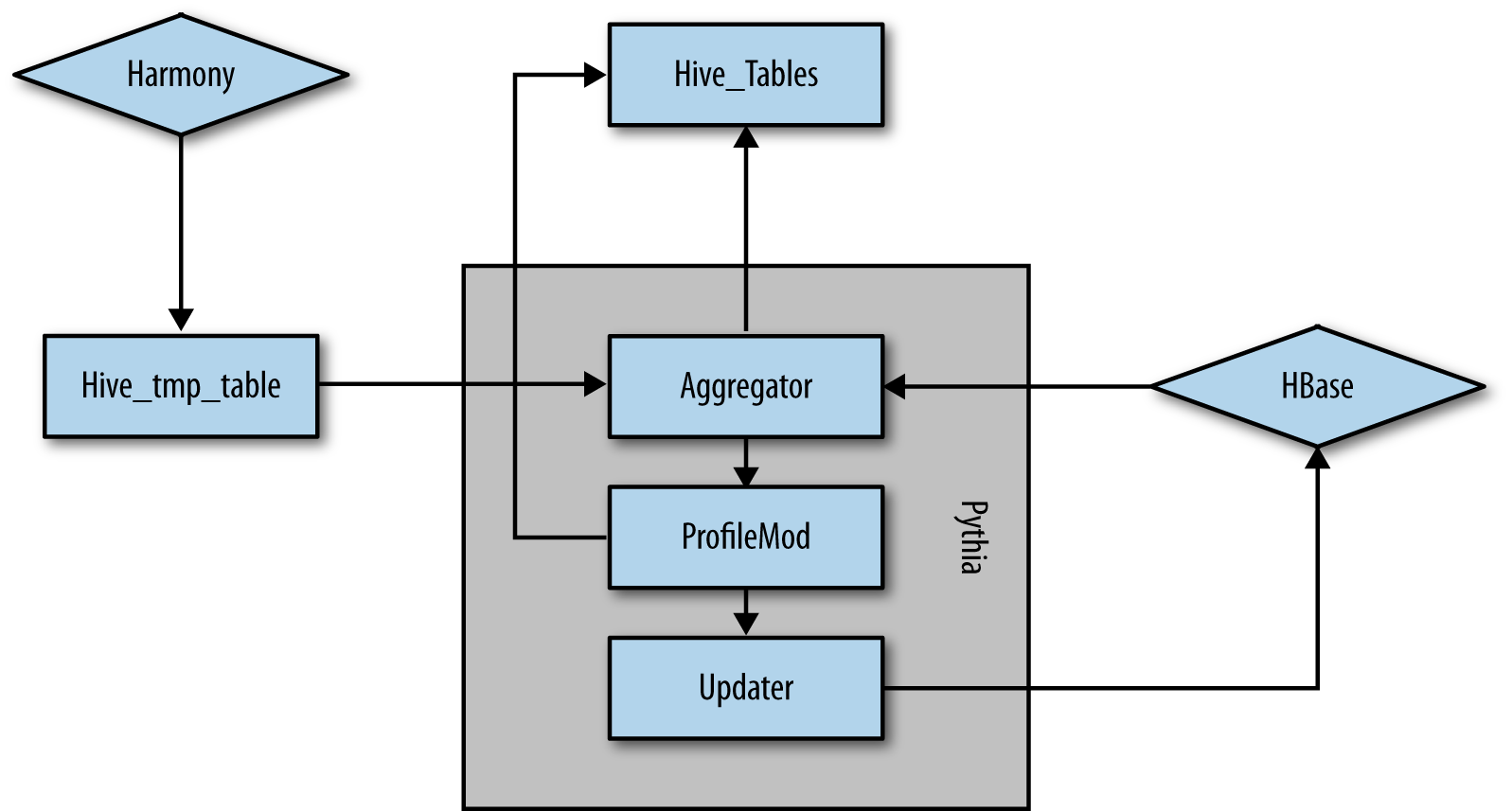
Figure 10-2. Processing dataflow
Both the Aggregator and ProfileMod steps in the pipeline also represent backed and partitioned Hive/Impala tables. The first thing done is to read the output of the Harmony job into an Avro file for our Aggregator job. Once new edits (Harmony) and previous hour of data (HDFS) are read and grouped in the mapper, they are passed to the reducer. During the Reduce phase, numerous HBase calls are made to join the full profile together for the next hourly partition. The reducer will pull the full HBase record for each record that has an existing profile. The Aggregator job then outputs a set of differences (typically known as diffs) that is applied during the ProfileMod stage. These diffs are used as a sort of WAL that can be used to rectify the changes if any of the upstream jobs fail.
Next, the ProfileMod job is executed. ProfileMod will be a Map job because we already extracted the data we needed from HBase in the reducer from the Aggregator flow. The mapper will read all of the data from the previous output and rectify the diffs. Once the diffs are all combined together, ProfileMod will use these as the actual diffs that need to be written back to HBase. The final output of this job is a new hourly partition in the ProfileMod Hive table.
Finally, the MDM system of record (HBase) needs to get updated. The final step is another MapReduce job. This job (the Updater) reads the output of the profile mode data and then builds the correct HBase row keys based off the data. The reducer then updates the existing rows with the new data to be used in the next job. Figure 10-3 shows the complete dataflow from the different inputs (stream and bach) up to the destination Hive table.