
Chapter 12. Use Case: Document Store
The final use case focuses on leveraging HBase as a document store. This use case is implemented by a large insurance company, which will henceforth be referred to as “the firm.” The information the firm collects is used to determine accident at faults, payouts, and even individual net worth. This particular use case involves data management and curation at a massive scale.
The firm needed to build a document store that would allow it to serve different documents to numerous business units and customers. A company of this size will end up having hundreds to thousands of different business units and millions of end users. The data from these different business units creates massive amounts of information that needs to be collected, aggregated, curated, and then served to internal and external consumers. The firm needed the ability to serve hundreds of millions of documents over thousands of different logical collections. That is a challenge for any platform, unless that platform is HBase.
Leveraging HBase as a document store is a relatively new use case for HBase. Previously, documents larger than a few 100 KB were not recommended for consumption. The competition to earn the production deployment was against a major RDBMS system. In this bake off, reads, writes, and file sizes were tested. The incumbent vendor performed well against HBase. HBase writes were slightly faster on smaller documents (ranging in size from 4 to 100 KB). Yet, the incumbent vendor managed to outperform HBase on larger documents by showing almost twice the write throughput with large documents of 300+ MB. HBase shined through with the reads, which is most important to the end users for this use case. HBase was 4 times faster when reading small files and 3.5 times faster with the large documents over 300 MB in size. Finally, HBase was tested with documents up to 900 MB in size and performed well, though the production deployment will not have any 900 MB cells floating around.
This use case would have been problematic in earlier versions of HBase. Luckily, the Medium Object (MOB) storage feature was introduced in HBASE-11339. Originally HBase struggled with cells up to 100 KB to 1 MB or larger in size. When using these larger sized cells without the MOB feature enabled, HBase suffered from something known as write amplification. This occurs when HBase compactions have to rewrite these larger cells over and over again potentially causing flush delays, blocked updates, disk I/O to spike, and latencies to shoot through the roof. This may be fine in batch-based systems using HBase as a system of record, updating large sets of data in Spark or MR jobs, but real-time systems with SLAs would suffer the most.
The MOB feature allowed HBase to accommodate larger cells with an official recommendation of 100 KB to 10 MB, but we have seen reasonable success with documents over 100 MB. MOB solves this issue by writing the MOB files into a special region. The MOB files are still written to the WAL and block cache to allow for normal replication and faster retrieval. Except when flushing a memstore containing a MOB file, only a reference is written into the HFile. The actual MOB file is written into an offline MOB region to avoid being compacted over and over again during major compactions causing write amplification. Figure 12-1 highlights the read path when leveraging MOB.
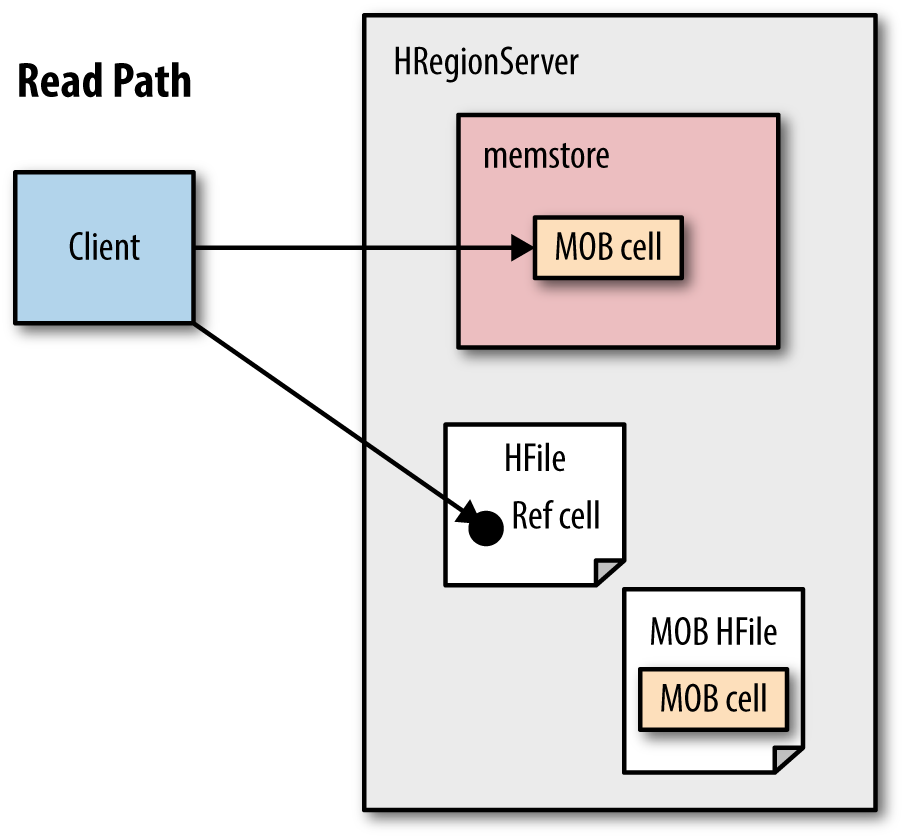
Figure 12-1. Understanding the MOB read path
To accomplish the deployment, the firm needed to have the ability to store 1 PB on the primary cluster and 1 PB on the disaster recovery cluster, while maintaining the ability to stay cost-effective. Staying cost-effective means enabling greater vertical scalability to keep the total node count down. To achieve this, we had to push HBase beyond the known best practices. We leveraged 40 GB for our region size and had roughly 150 regions per RegionServer. This gave us about 6 TB of raw data in HBase alone, not including scratch space for compactions or Solr Indexes. The MOB feature enabled us to take better advantage of the I/O system by isolating the larger files. This allowed the firm to deploy on denser nodes that offered over 24 TB of storage per node. For this use case, we will be focused on serving, ingest, and cleanup.
Serving
We are going to reverse the usual order and start with the serving layer to better understand the key design before getting into how the data is broken up. In step 1, the client (end user) reaches out to the application layer that handles document retrievals (Figure 12-2). In this case, the end client is not going to know how to represent the HBase row key when looking up specific documents. To accomplish this, the firm uses Solr to look up the specific document information. The search engine contains the metadata about the documents needed to construct the HBase row key for the gets. Clients send their search terms to Solr, and based on search results, can request an entire document or numerous documents from HBase based on information from the search result, including:
- GUID
-
This is a hashed document ID.
- Partner ID
-
Identifier for location of document’s originating point (e.g., US, Canada, France, etc.).
- Version ID
-
Version of the document that corresponded to the search.
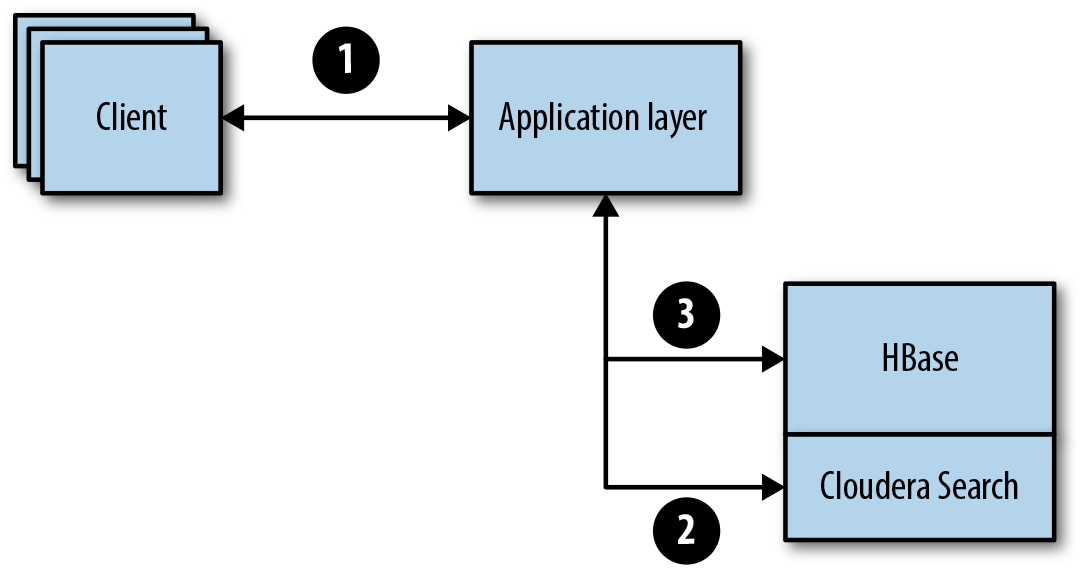
Figure 12-2. Document store serving layer
The application layer will then take retrieved pieces of information from the search engine to construct the row key:
GUID+PartnerID+VersionID
After the application layer has constructed the row key from the search engine, it will then execute a get against HBase. The get is against the entire row, as each row represents the entire document. The application layer is then responsible for reconstructing the document from the numerous cells that document has been chunked into. After the document is reconstructed, it is passed back to the end user to be updated and rewritten back to the document store.
Ingest
The ingest portion is very interesting, because all of the documents will be of varying size (Figure 12-3). In step 1, the client passes an updated or new document to the application layer. The application layer then takes the document and creates the necessary metadata for future document retrieval:
-
GUID
-
Partner ID
-
Version ID
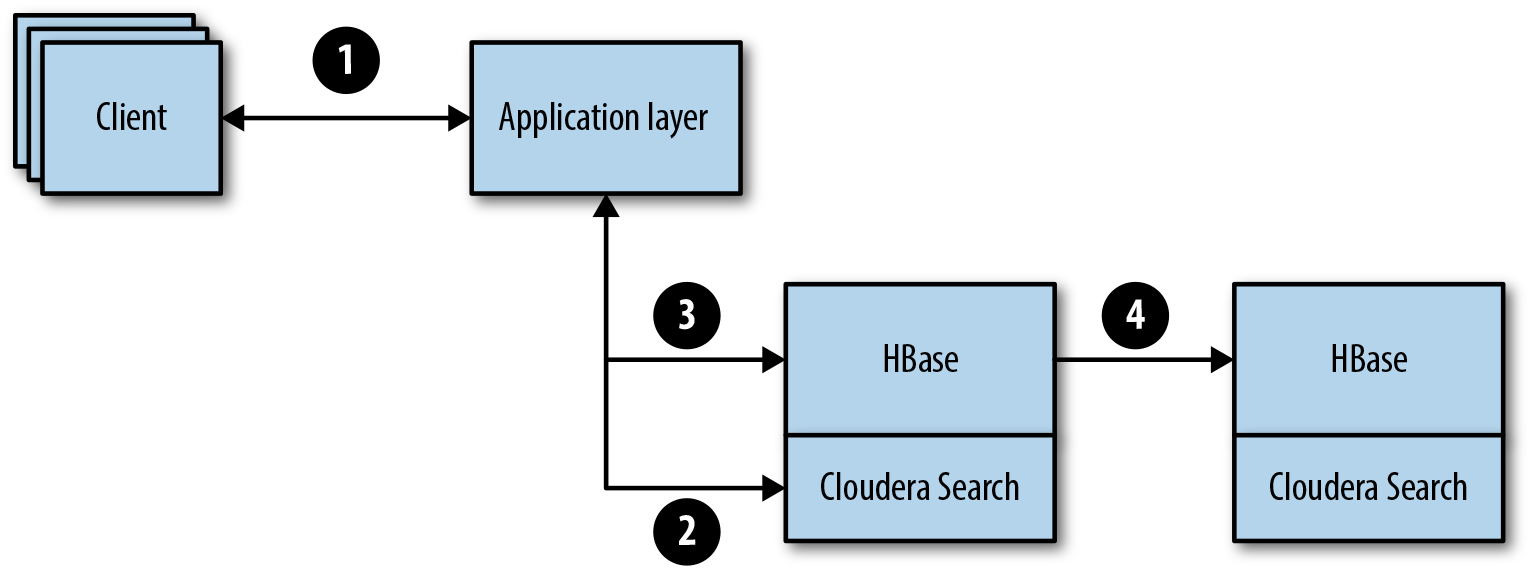
Figure 12-3. Document store ingest layer
To create the new update to the search engine, the application will first do a lookup in the search engine to determine the correct version ID, and then increment to the next level to ensure the latest document is served and that older versions of documents can be retained. Once the search engine has been updated, the application will then determine the document size and break the document up into the correct number of 50 MB cells to be written to HBase. This means a 250 MB document will look like Figure 12-4.

Figure 12-4. Cell layout while chunking large documents
The final HBase schema was different than what was tested during the bake off. HBase showed the best performance when the documents were broken out into chunks, as illustrated in Figure 12-4. The chunking also helps to keep total memstore usage under control, as we can flush numerous chunks at a time without having to buffer the entire large document. Once the HBase application has written the data to both the search engine and HBase, the document is the made available for retrieval from the client.
Once the data has been written to HBase, the Lily Indexer picks up the metadata about each document and writes it into Cloudera Search. While the search engine is indexing some metadata in step 4, HBase is also replicating the data to the disaster recovery cluster, which in turn is also writing the metadata to Cloudera Search through the Lily Indexer (Figure 12-5). This is actually a very clever way to do very quick document counts without having to utilize HBase resources to issue scans to count the total number of documents. Cloudera Search can quickly give back a total count of documents in both sites, ensuring that the document counts stays the same.
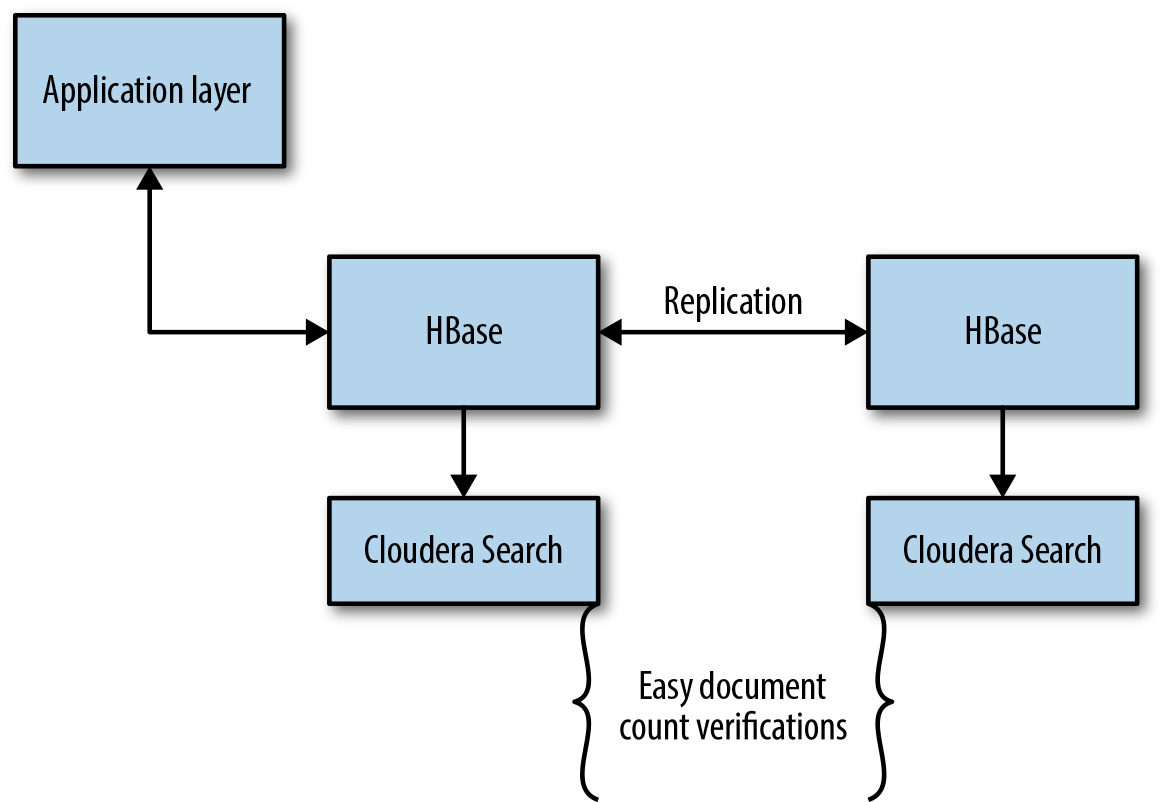
Figure 12-5. Disaster recovery layout
Clean Up
For those of you following along at home, you may be thinking “Hey! Great schema, but how do you control versions?” Normally versions are handled through individual HBase cells and are configurable on the column family level. However, the portion of the row key known as “VersionID” is used to control the versioning. This allows the client to be able to easily pull the latest, or the last X versions with a single scan. If the firm wished to keep all copies of a single document, this would be fine; but depending on the delta rate of the documents, this could balloon out of control fast. Seriously, think about how many times you have changed a sentence, got busy and saved the document, then came changed another sentence, then repeat. To combat this, the firm has written a clean up job that will iterate through the table and delete unneeded versions of their documents.
For the current RDBMS-based solution, the cleanup process runs constantly in order to minimize storage and contain costs on their expensive RDBMS. Because HBase is lower cost, storage is less of an issue, and cleanups can run less frequently. To do this, the firm fires off a Spark job daily.
The Spark job has two primary tasks. First, it collects the version count of each document from the search system. This is an easy way to eliminate the documents that do not exceed the maximum version count. In this case, the firm retains up to the last 10 versions of a document. Once the document list has been built, the Spark job will use the response to build the necessary row keys to issue the deletes. Finally, the job will fire off a series of deletes to HBase, followed by a major compaction to age off all of the tombstones.