
Chapter 14. Too Many Regions
Consequences
Having too many regions can impact your HBase application in many ways.
The most common consequence is related to HFile compactions. Regions are sharing the memstore memory area. Therefore, the more regions there are, the smaller the memstore flushes will be. When the memstore is full and forced to flush to disk, it will create an HFile containing data to be stored in HDFS. This means the more regions you have, the smaller the generated HFiles will be. This will force HBase to execute many compaction operations to keep the number of HFiles reasonably low. These compactions will cause excessive churn on the cluster, affecting performance. When specific operations are triggered (automatic flush, forced flush, and user call for compactions), if required, HBase will start compactions. When many compactions run in tandem, it is known as a compaction storm.
Tip
Compactions are normal HBase operations. You should expect them, and there is nothing to worry about when minor compactions are running. However, it is recommended to monitor the number of compactions. The compaction queue should not be constantly growing. Spikes are fine, but the key needs to stay close to zero most of the time. Constant compactions can be a sign of poor project design or a cluster sizing issue. We call constant compactions a situation where the compaction queue for a given RegionServer never goes down to zero or is constantly growing.
Certain operations can timeout as a result of having too many regions.
HBase commands like splits, flushes, bulkloads, and snapshots (when using flush) perform operations on each and every region.
As an example, when the flush <table> command is called, HBase needs to store a single HFile into HDFS for each column family in each region of <table> where there are pending writes in the memstore.
The more regions you have, the more files will be created in the filesystem.
Because all of those new file creations and data transfers will occur at the same time, this can overwhelm the system and impact SLAs.
If the time taken to complete the operation is greater than the configured timeout for your operation, you will start to see some timeout failures.
Here is a quick summary of the problems you might encounter on your cluster as a result of having too many regions:
-
Snapshots timeout
-
Compaction storms
-
Client operations can timeout (like flush)
-
Bulk load timeouts (might be reported as
RegionTooBusyException)
Causes
There are multiple root causes for having too many regions, ranging from misconfiguration to misoperation. These root causes will be discussed in greater detail in this section:
-
Maximum region size set too low
-
Configuration settings not updated following an HBase upgrade
-
Accidental configuration settings
-
Over-splitting
-
Improper presplitting
Misconfiguration
In previous HBase versions, 1 GB was the default recommendation for region size. HBase can now easily handle regions ranging in size from 10 to 40 GB, thanks to optimizations in HBase and ever-increasing default memory size in hardware. For more details on how to run HBase with more memory, refer to Chapter 17. When an older HBase cluster is migrated into a recent version (0.98 or greater), a common mistake is to retain previous configuration settings. As a result, HBase tries to keep regions under 1 GB when it will be better letting them grow up to 10 GB or more. Also, even if the cluster has not been migrated from an older version, the maximum region size configuration might have been mistakenly modified to a smaller value, resulting in too many regions.
Misoperation
There are also multiple manual operations that might cause HBase to have too many regions to serve.
Over-splitting
The first one is a misuse of the split feature. HBase’s “Table Details” Web UI allows administrators to split all the regions of a given table. HBase will split the regions even if they are small, as long as the amount of data in the region meets the minimum size required to qualify for manual splitting. This option can sometimes be very useful, but abusing it can easily create too many regions for a single table. Take as an example a 128 region table on a four-node cluster where each RegionServer hosts only 32 regions. This is a correct load for a cluster of that size. The use of the split option three times will create up to 1,024 regions, which represents 256 regions per server!
Improper presplitting
It is also possible to create too many regions when using the presplit HBase feature. Presplitting is very important to help spread the load across all the RegionServers in the cluster; however, it needs to be well thought out beforehand. There should be a fundamental understanding of row key design, HBase writes, and desired region count to correctly presplit a table. A poorly split table can result in many regions (hundreds or even thousands) with only a few of them being used.
Solution
Depending on the HBase version you use, there are different ways to address the issue of having too many regions. But in both scenarios, the final goal is to reduce the total number of regions by merging some of them together. What differs between the HBase versions is the ways to achieve this.
Before 0.98
Before version 0.98, there are two main options to merge regions together: copying the table to a new presplit table or merging regions. Before HBase 0.98, regions could be merged offline only.
The first option is to create a new table with the same definitions as the existing table but with a different table name.
Copy the data from the original table into this table.
To complete the process, drop the original table and then rename the new table to the original table name.
In this method, we will use the HBase snapshot feature so HBase 0.94.6 or above is required.
Also, you will need to run the MapReduce CopyTable job on top of the HBase cluster, so you will need to make sure that the MapReduce framework is available and running.
Last, this method will require a temporary suspension of data ingestion.
This interruption will be short but is the important part of the process.
Warning
Because this method will duplicate the initial table, it will consume space on your cluster equal to the original tables size. Ensure the extra space is available before starting. It is also important to understand the impact of running MapReduce on the HBase cluster.
The new table should be presplit with the expected newly merged region boundaries.
Figure 14-2 illustrates this.
Once the presplit step is completed, use the CopyTable command to copy data from the original table to the new table.
The CopyTable tool accepts a date range as an argument and will then copy data from time t0 to t1 directly into the target table, into the correct regions.
This will allow you to transfer the oldest data first and rerun the tool again to transfer newly created data.
CopyTable also allows you to rename or drop unnecessary column families, which can be very useful in case of table redesign.
Warning
As illustrated in Figure 14-1, if you are doing puts and deletes with modified timestamps, you might want to avoid this method, as some of your deletes and puts might not be copied correctly if any compaction occurs on the source side between the two CopyTable calls.
It is almost never a good idea to be modifying internal HBase timestamps.
In Figure 14-1, CopyTable is done between t0 and t1 to copy data from one table to another.
By the time CopyTable is run for data between t1 and current time, some data with old timestamps is inserted into the source table.
Because only data with a timestamp greater than t1 will be consider by the second run of CopyTable, this newly inserted data in the past will be ignored (i.e., it will not be copied over to the new table and will be lost if the source table is dropped).
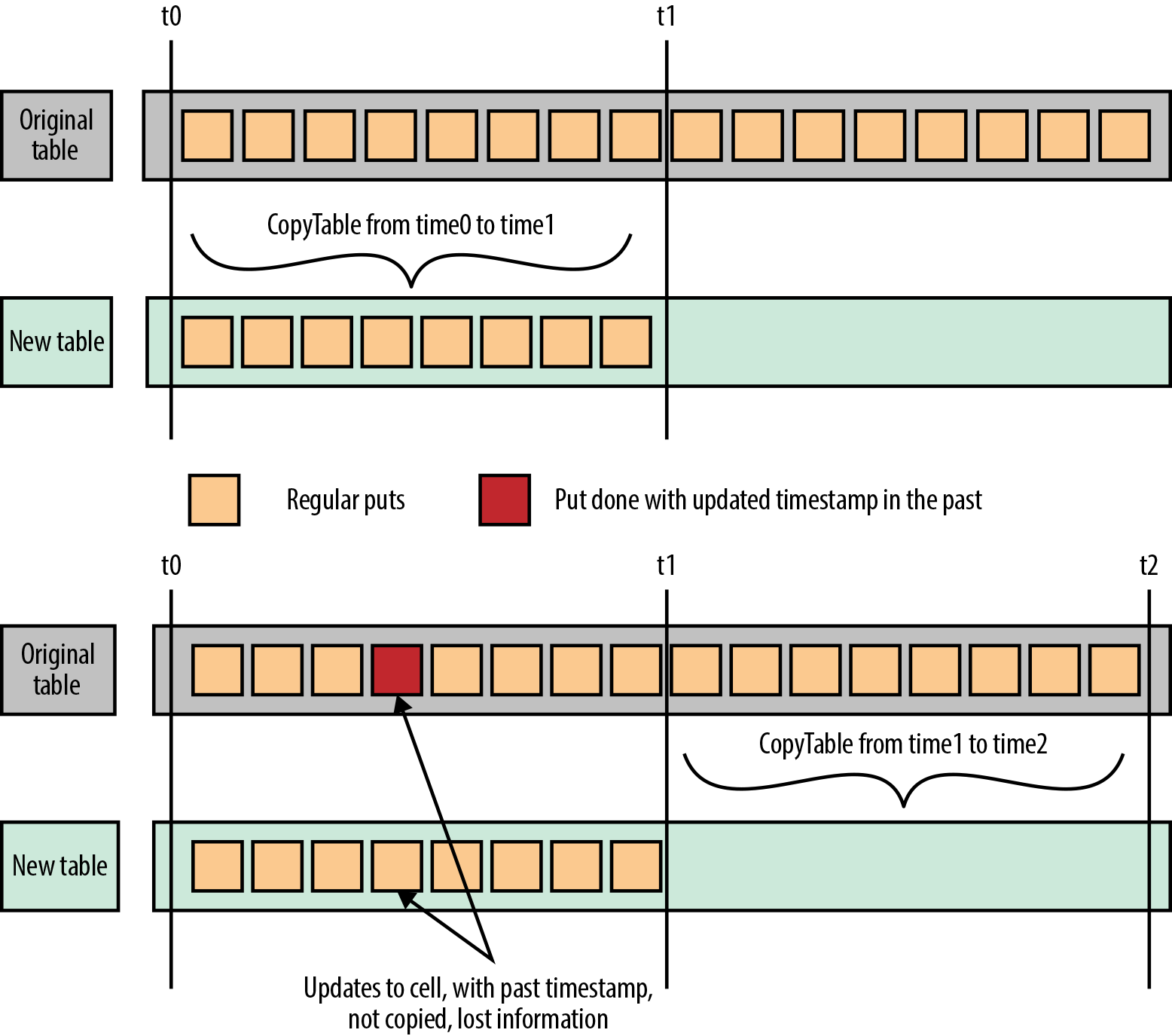
Figure 14-1. Risk when performing updates with timestamp of cells in the past
Figure 14-2 is an example to better understand how this can be done. Consider that you built an application that stores transactions into a table using the transaction ID as the row key. Your initial assumption was that the transaction ID would be a unique randomly generated readable string. Based on this assumption, the initial table was split into 26 regions from A to Z. However, after running the application for a few weeks, you notice that the transaction ID is a hexadecimal ID. Therefore, instead of going from A to Z, it goes from 0 to F. With the new distribution, regions greater than F will never be used, while the first region will get way more data than the others (puts from 0 to A) and will split into many new regions as it grows. In this case, we’re only moving 26 region to 8 regions; but if you scale this example, you can easily see how hundreds of regions may have been initially created to handle more load and how the same issue of data balancing can occur.
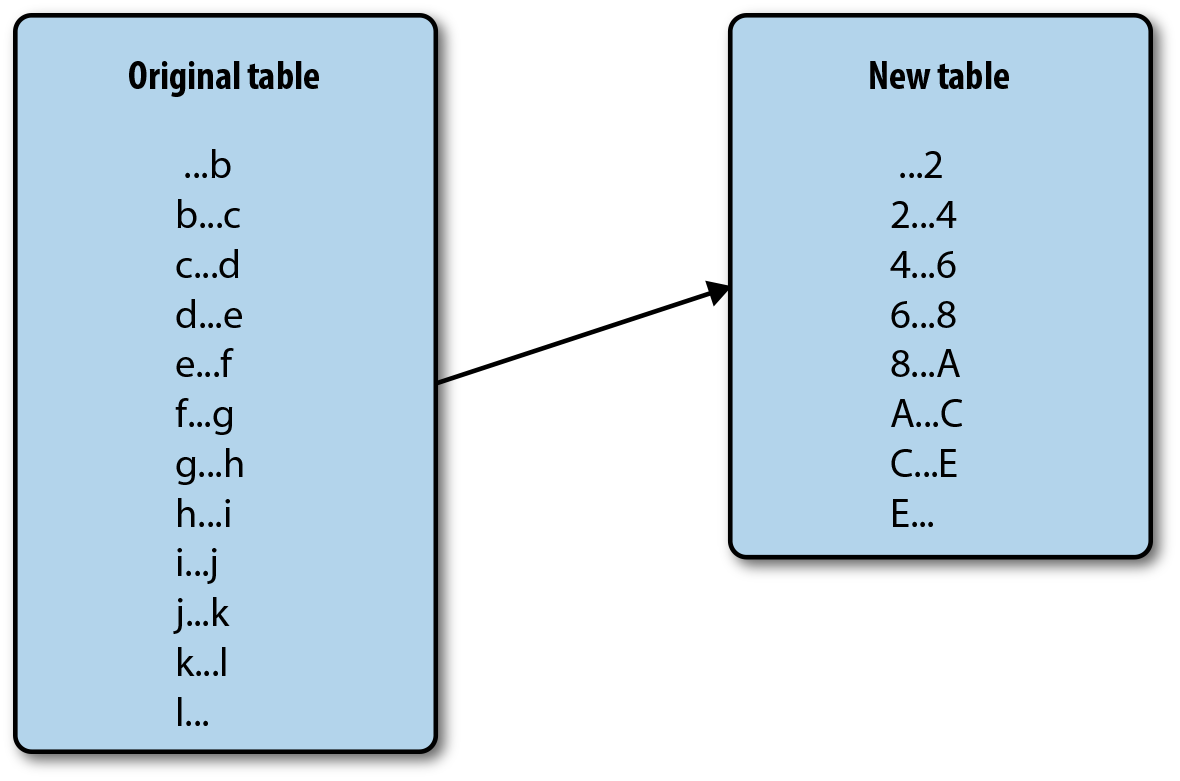
Figure 14-2. Regions redesign
In order to fix this, we will create a new table where regions are already presplit on hexadecimal boundaries.
Using the CopyTable command, we will copy data from the existing table to the new table, from t0 to the current day:
hbase org.apache.hadoop.hbase.mapreduce.CopyTable --starttime=0 --endtime=1411264757000 --new.name=new_table previous_table
The goal of the starttime and endtime parameters is to make sure we copy a specific and controlled section of the source table.
Because this operation might take some time, before going to the next steps, and to reduce the input table downtime, we want to copy as much data as possible; but we also want to make sure we will be able to restart the copy from a specific point in time.
Depending on the size of your dataset, this copy might take several hours to a few days. While the copy is running, normal operations can continue on the cluster and on the initial table.
Once the first CopyTable operation is done, the new table contains almost all of the existing data except what has been added between when your previous operation was started (t=141126475700, in this example) and now.
Depending on the time it takes to run the first copy, this can represent a considerable amount of data.
Because of that, and to make sure the next steps are going to be as short as possible, we will rerun the CopyTable command again.
Because the endtime parameter that we used in the previous command is exclusive, we will use it for our current starttime:
hbase org.apache.hadoop.hbase.mapreduce.CopyTable --starttime=1411264757000 --endtime=1411430414000 --new.name=new_table previous_table
This second operation should be faster, as most of the data was copied in the initial operation.
When the two CopyTable operations are done and before doing the last run, to not lose any data, you will have to stop the ingestion to your existing table while you are performing the following operations.
In production environments, it is sometimes very sensitive to stop data ingestion.
If that is the case, you can think about mitigation solutions.
One of them consists of pushing the data into the newly created table.
Another is to design the ingestion such that it can accept those pauses.
Applications such as Kafka and Flume can be used to queue the data being ingested to HBase and can be paused without losing any information.
Typically, the remaining steps might be accomplished in less than one hour.
It is hard to quantify how long it will take to bring in the delta.
It can be computed from the previous runs, but it can vary widely.
Finally, you will need to do one last run of the CopyTable tool to copy the remaining data.
The time between the end of the last run and when you disabled the data ingestion is only a couple minutes, so it should run even faster.
This time, because we want to copy all the remaining data, we will again use the last endtime value as the starttime parameter, but we will not specify any endtime:
hbase org.apache.hadoop.hbase.mapreduce.CopyTable --starttime=1411264757000 --new.name=new_table previous_table
This should run for a few seconds up to a few minutes. At the end of this operation, we will have a duplicate of the original table in our new table, with the new regions boundaries. The last step is to run some snapshot commands to rename the newly created table:
disable 'events_table' drop 'events_table' disable 'new_events_table' snapshot 'new_events_table', 'snap1' clone_snapshot 'snap1', 'events_table' delete_snapshot 'snap1' drop 'new_events_table'
At the end of all those operations, you will have a table containing the exact same data but with a reduced number of regions.
Offline merges
The second option to reduce the number of regions you have is to perform offline merges. To be able to perform the following steps, you will need to run HBase 0.94.13 or higher. Offline merge before 0.94.13 can fail and can leave corrupted files in your system (see HBASE-9504). One major constraint with offline merges is that they require total cluster downtime.
The steps to perform offline merges are as follows (we’ll look at the details momentarily):
-
Stop the cluster.
-
Perform one or more merge operations.
-
Start the cluster.
To stop and start your HBase cluster, you can use the bin/stop-hbase.sh and bin/start-hbase.sh commands. If you are using a management tool such as Cloudera Manager, you will find the HBase actions in the HBase service management page.
Using HBase command
Performing an offline merge is done using the HBase Merge class called from the command line:
bin/hbase org.apache.hadoop.hbase.util.Merge testtable
"testtable,,1411948096799.77873c05283fe40822ba69a30b601959."
"testtable,11111111,1411948096800.e7e93a3545d36546ab8323622e56fdc4."
This command takes three parameters: the first is the table name, and the other two are the regions to merge.
You can capture the region names from the HBase web interface.
However, depending on the key design, it can be very difficult to run from the command line.
Your key may contain some reserved characters (e.g., $, ^, etc.), which can make the formatting a bit difficult.
If that’s the case and you are not able to format the command, it may be prudent to use the Java API method described next.
Once the command has been run, HBase will first test that the cluster is stopped.
HBase will then perform many operations to merge all the content of those two regions into a single region.
This will also create a new region with the new boundaries, create the related directory structure, move content into this new region, and update the HBase .META. information.
The duration of the operation will depend on the size of the regions you are merging.
Using the Java API
To perform the same operation using the Java API, we will make use of the HBase merge utility class and call it while giving the correct parameters. This example is specific to HBase 0.94 and 0.96, and will not compile with later HBase versions. We have omitted parts of this code here, but provide a snippet in Example 14-1.
Example 14-1. Java merge for HBase 0.94
publicintmergeRegion(Configurationconfig,StringtableName,Stringregion1,Stringregion2){String[]args={tableName,region1,region2};intstatus=-1;try{status=ToolRunner.run(config,neworg.apache.hadoop.hbase.util.Merge(),args);}catch(Exceptione){e.printStackTrace();}returnstatus;}
This method allows you to bypass the command line parsing challenge by directly passing the table and region names. It is still available in HBase 1.0, but because online merge is also available, it is no longer the recommended approach.
Starting with 0.98
HBASE-7403 introduces online merge into HBase starting at version 0.98. Online merge allows you to concatenate two regions into a single one without having to shut down the HBase cluster or disable the target table. This is a big improvement in the merge process. Assuming a high enough version of HBase, this is currently the preferred way to solve the issue of too many regions.
Using HBase shell
Using the HBase shell, you will need to use the merge_region command.
This command simply takes the two region-encoded names as parameters:
merge_region 'ENCODED_REGIONNAME', 'ENCODED_REGIONNAME'
The region-encoded name is the last token of the entire region name.
From the region testtable,22222222,1411566070443.aaa5bdc05b29931e1c9e9a2ece617f30. “testtable” is the table name, “22222222” is the start key, “1411566070443” is the timestamp, and finally, “aaa5bdc05b29931e1c9e9a2ece617f30” is the encoded name (note that the final dot is part of the encoded name and is sometimes required, but not for the merge command).
Command call and output should look like this:
hbase(main):004:0> merge_region 'cec1ed0e20002c924069f9657925341e',
'1d61869389ae461a7971a71208a8dbe5'
0 row(s) in 0.0140 seconds
At the end of the operation, it is possible to validate from the HBase web UI that regions were merged and a new region has been created to replace them, including the boundaries of the two initial regions.
Using the Java API
The same merge operation is available from the HBase Java API. Example 14-2 will look up a table, retrieve the list of regions, and merge them two by two. At the end of the execution, the original table will have half the number of regions.
Example 14-2. Online Java merge
Configurationconf=HBaseConfiguration.create();Connectionconnection=ConnectionFactory.createConnection(conf);HBaseAdminadmin=(HBaseAdmin)connection.getAdmin();List<HRegionInfo>regions=admin.getTableRegions(TableName.valueOf("t1"));LOG.info("testtable contains "+regions.size()+" regions.");for(intindex=0;index<regions.size()/2;index++){HRegionInforegion1=regions.get(index*2);HRegionInforegion2=regions.get(index*2+1);LOG.info("Merging regions "+region1+" and "+region2);admin.mergeRegions(region1.getEncodedNameAsBytes(),region2.getEncodedNameAsBytes(),false);}admin.close();

Retrieves the existing regions for a given table
Performs the merge operation
Output of this example over a nine-region table will look like the following (some of the output has been truncated to fit the width of this page):
2014-09-24 16:38:59,686 INFO [main] ch18.Merge: testtable contains 9 regions. 2014-09-24 16:38:59,686 INFO [main] ch18.Merge: Merging regions ... and ... 2014-09-24 16:38:59,710 INFO [main] ch18.Merge: Merging regions ... and ... 2014-09-24 16:38:59,711 INFO [main] ch18.Merge: Merging regions ... and ... 2014-09-24 16:38:59,713 INFO [main] ch18.Merge: Merging regions ... and ...
Each region will print the following information in the output:
-
The encoded region name in the form of a 32-character long hexadecimal string:
4b673c906173cd99afbbe03ea3dceb15 -
The region name formed by the table name, the start key, the timestamp, and the encoded name, comma separated:
testtable,aaaaaaa8,1411591132411,4b673c906173cd99afbbe03ea3dceb15 -
The start key:
aaaaaaa8 -
The end key:
c71c71c4
Keys used in the example table are string based and can be printed by HBase.
However, when your keys contain nonprintable characters, HBase will format them in hexadecimal form.
A key containing a mix of printable and nonprintable characters, represented by the byte array [42, 73, 194] will be printed *IxC2.
Prevention
There are multiple ways to prevent an HBase cluster from facing issues related to the number of regions.
Tip
Keep in mind that you need to consider not only the number of regions, but also the number of column families in each of those regions.
Indeed, for each column family within a region, HBase will keep track of it in memory and in the hbase:meta table.
Therefore, having 400 regions of two column families is not better than having 800 regions of a single column family.
Having too many column families in a table also creates problems, as we will explore in Chapter 15.
Regions Size
First, you will want to make sure the maximum file size is set to at least 10 GB. It is not an issue to have regions smaller than that, but you want to make sure that when required, regions can get as big as 10 GB. Presplitting is discussed later in this section. It is recommended to monitor region sizes using a visualization tool such as Hannibal. Watch for regions that are growing faster than others, and look to split them during off-peak usage times. Figure 14-3 illustrates how Hannibal helps you to view the size of each region.
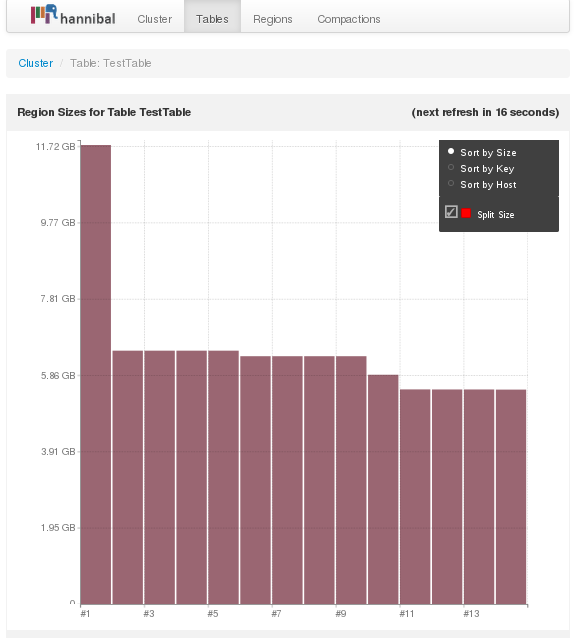
Figure 14-3. Visual overview of region sizes courtesy of Hannibal
HBase default split policy (org.apache.hadoop.hbase.regionserver.IncreasingToUpperBoundRegionSplitPolicy) ensures that regions never go above the configured maximum file size (hbase.hregion.max.filesize).
However, it might create many smaller regions when cluster load is small (fewer than 100 regions).
To make sure your regions can grow to a decent size, validate that hbase.hregion.max.filesize property is configured to at least 10 GB.
This property is represented in bytes; therefore it should be 10737418240.
However, it is also a common practice to set the maximum file size value to a higher number up to 100 GB. When using larger region sizes, it is important to manage the splits manually.
This will make sure the splits occur at the right time and have a minimum impact on the HBase cluster operations and SLAs.
Caution
We do not recommend disabling splits or setting the split size to very big values like 200 GB or more. A region can easily grow to an unwieldy size if there’s a spike in volume, if there are uncleansed records, or if the admin takes a vacation. If a region does not get split and continues to grow up to a very big size, it might crash the RegionServer. Upon failure, all regions from the server will be reassigned to another server, which will cause a cascading effect of crashes because of the size. From RegionServer to RegionServer, the culprit region will be reassigned and each time it will cause the target host to fail. If this is not recognized early, the entire cluster might go down.
Even if you expect your table to be small, you can still presplit it to increase distribution across RegionServers or manually trigger the splits to make sure you have up to as many regions as you have RegionServers. However, because HBase works better with bigger regions, make sure all your regions are at least 1 GB.
Key and Table Design
The second thing you want to look at is how your application has been designed. One of the most common mistakes in HBase application design is to abuse the number of column families. Because a memstore for a specific region will be divided between the different column families, having too many of them will reduce the size of the memory available for each and might result in very small flushes for some column families. Also, because of the size of the flushed files, it will generate extra compactions. Reducing the number of column families will allow more memory per region for the remaining column families, will reduce the required flushes and compactions, and will allow you to host more regions per server.
Another common mistake on table design is related to presplitting. Based on your key design and the size of the dataset, you will want to make sure that the table is correctly presplit before starting to inject data into the cluster. If the table has not been presplit correctly, you may end up with many unused or underutilized regions. Unused and underutilized regions still require resources such as memory and CPU, and still require periodic compactions. If your data is not evenly distributed but the table is evenly split, you will also end up with some regions being heavily used and some others being almost not used.