
Chapter 15. Too Many Column Families
Many HBase users start to design HBase tables before reading about it and before knowing about all the HBase features and behaviors. People coming from the RDBMS world, with no knowledge of the differences between a column family and a column qualifier, will be tempted to create a column family for each column they have of a table they want to migrate to HBase. As a result, it is common to see tables designed with too many column families.
For years, it has been recommended to keep the number of column families under three. But there is no magic number like this. Why not two? Why not four? Technically, HBase can manage more than three of four column families. However, you need to understand how column families work to make the best use of them. The consequences explained here will give you a very good idea of what kind of pressure column families are putting on HBase. Keep in mind that column families are built to regroup data with a similar format or a similar access pattern. Let’s look at these two factors and how they affect the number of column families:
- Regarding the format
-
If you have to store large text data, you will most probably want to have this column family compressed. But if for the same row you also want to store a picture, then you most probably do not want this to be compressed because it will use CPU cycles to not save any space so will have negative impact on the performances. Using separate column families make sense here.
- Regarding the access pattern
-
The best way to describe this is to consider a real-world example. Imagine you have a table storing customer information. A few huge columns store the customer metadata. They contain a lot and are a few kilobytes in size. Then another column is a counter that stores each time the customer clicks on a page on the website. The metadata columns will almost never change, while the counter column will be updated many times a day. Over time, because of all the operations on the counters, the memstore will be flushed into disk. This will create files that mostly contain only counter operations, which at some point will be compacted. However, when the compaction is performed, it will most probably select HFiles that contain customer metadata. The compaction will rewrite all those huge cells of customer metadata as well as the small counters. As a result, the vast majority of the I/O will be wasted rewriting files with little to no change just to update or compact the small counters. This creates an overhead on the I/Os. HBase triggers compactions at the column family level. By separating the customer metadata and the customer counters into two different columns families, we will avoid unnecessarily rewriting the static information. It will lower the total IOPs on the RegionServers and therefore will improve the overall performances of the applications.
So how many column families is too many? We will not be able to give you a magic number. If it makes sense to separate them from the access pattern or from the format, separate them. But if you read and write them almost the same way and data has almost the same format, then simply keep it together in the same column family.
Consequences
Abusing column families will impact your application’s performance and the way HBase reacts in different ways. Depending how hard you are pushing HBase, it might also impact its stability because timeouts can occur, and RegionServers can get killed.
Memory
The first impact of too many column families is on the memory side. HBase shares its memstore (write cache) among all the regions. Because each region is allowed a maximum configurable cache size of 128 MB, this section has to be shared between all the column families of the same region. Therefore, the more column families you have, the smaller the average available size in the memstore will be for each of them. When one column family’s bucket is full, all of the other column families in that region must be flushed to disk as well, even if they have relatively little data. This will put a lot of pressure on the memory, as many objects and small files will get created again and again, but it will also put some pressure on the disks because those small files will have to be compacted together.
Tip
Some work over HBASE-3149 and HBASE-10201 has been done to flush only the column families that are full instead of flushing all of them. However, this is not yet available in HBase 1.0. Once this feature is available, the memory impact of having too many column families will be drastically reduced, as will the impact on the compactions.
Compactions
The number of column families affects the number of store files created during flushes, and subsequently the number of compactions that must be performed. If a table has eight column families, and region’s 128 MB memstore is full, the data from the eight families is flushed to separate files. Over time, more flushes will occur. When more than three store files exist for a column family, HBase considers those files for compaction. If a table has one column family, one set of files would need to be compacted. With eight column families, eight sets of files need to be compacted, affecting the resources of the RegionServers and HDFS. Configuring fewer column families allows you to have larger memstore size per family; therefore fewer store files need to be flushed, and most importantly, fewer compactions need to occur, reducing the I/Os on the underlying HDFS system. When a table needs to be flushed (like before taking a snapshot, or if administrators trigger flushes from the shell), all the memstores are flushed into disk. Depending on the previous operations, it is possible that doing this will make HBase reach yet another compaction trigger and will start compactions for many if not all the regions and column families. The more column families, the more compactions will go into the queue and the more pressure will be put on HBase and HDFS.
Split
HBase stores columns families’ data into separate files and directories. When one of those directories become bigger than the configured region size, a split is triggered.
Splits affect all column families in a region, not only the column family whose data grew beyond the maximum size.
As a result, if some column families are pretty big while others are pretty small, you might end up with column families containing only a few cells.
RegionServers allocate resources like memory and CPU threads per region and column family.
Very small regions and column families can create unnecessary pressure on those resources.
The HBase master will also need to manage more entries in the hbase:meta table and the underlying HDFS system.
The HDFS DataNodes and NameNodes will also need to manage more I/Os for the small column family files.
If you expect some column families to contain much more data than others, you might want to separate that data into other tables, producing fewer but larger files.
Causes, Solution, and Prevention
The cause of having too many column families is always related to schema design. HBase will not create too many column families on your behalf; there’s no automatic-split behavior that can cause too many column families. Thus, to prevent this problem, you need to carefully consider HBase principles before you begin designing your schema so that you can determine an appropriate number of column families.
Several solutions exist for the issue of having too many column families. Understanding the data in the column families and the access pattern is critical. Sometimes the column families are not required and can simply be dropped—for example, if the data is duplicated/denormalized and is available in another table. Sometimes the column family is present due to the access pattern (i.e., rollups or summary column-families). In that case, maybe the column family can simply be de-coupled from the table and moved to its own table. Other times, the data in the separate column family can be merged together with larger column families.
All the operations in the next sections can be done using the Java API, but they can also very simply be done using the HBase shell or the command line. Because the Java API will not really add any benefit to those operations, we have not documented it.
Delete a Column Family
If you have decided that you don’t need a specific column family, simply remove this column family from the table META information.
The following method will delete the picture column family from the sensors table:
alter 'sensors', NAME => 'picture', METHOD => 'delete'
This operation might take some time to execute because it will be applied in all the regions one by one.
At the end, related files in HDFS will be removed, and the hbase:meta table will be updated to reflect the modification.
Merge a Column Family
Because of a flaw in the original schema design, or a shift in scope in the original use case, you might have separated the data in two different column families but now want to merge it back into a single column family.
As we discussed in “Solution”, CopyTable allows you to copy data from one table into another one.
CopyTable will help us in the current situation.
The idea is that CopyTable will require a source table and a destination table; however, those two tables don’t necessarily need to be different.
Also, CopyTable allows us to rename one column family into a new one (Figure 15-1).
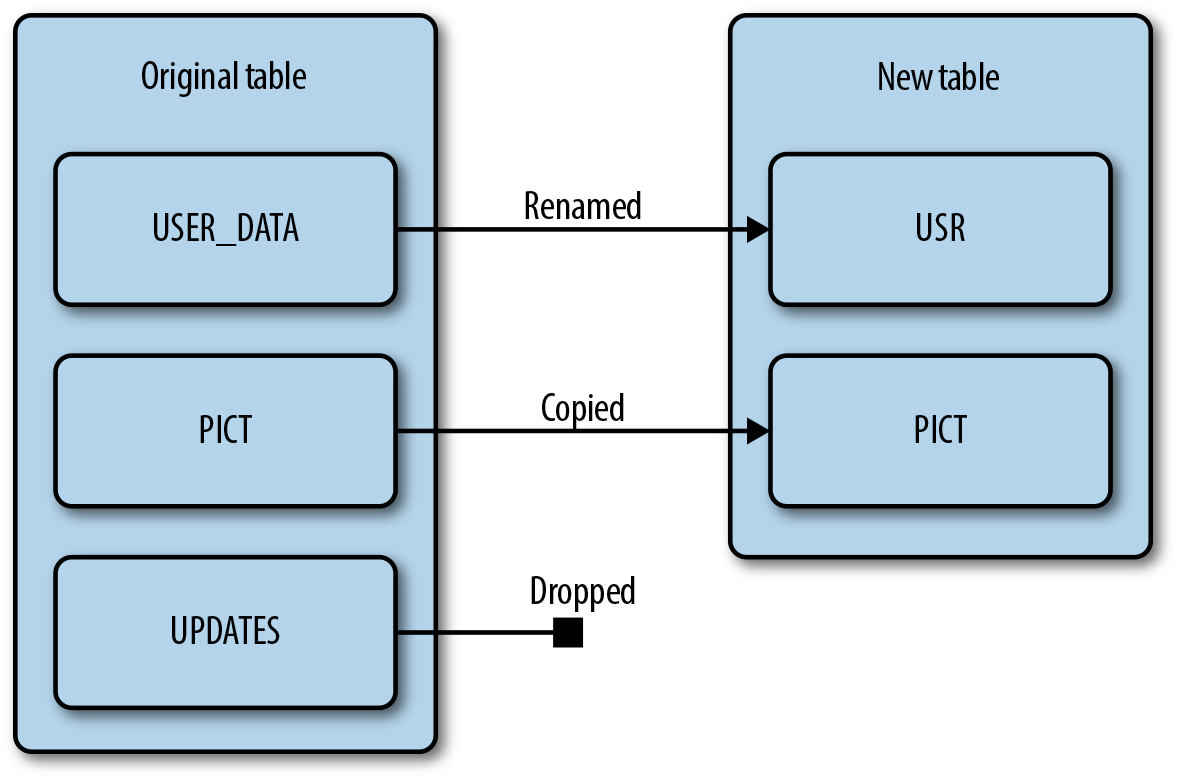
Figure 15-1. CopyTable column families operations
CopyTable will run a MapReduce job over the data you want to read and will emit puts based on what you asked.
If for a given table called customer you want to transfer the data present in the column family address into the column family profile, you simply need to set both the input and the output table to be the customer table, the input column family to be address and the output to be profile.
This operation can be achieved by running the following command:
hbase org.apache.hadoop.hbase.mapreduce.CopyTable --new.name=customer
--families=address:profile customer
At the end of the MapReduce job, all the data in that you had into the address column family will also be present in the profile column family.
You can now delete the address column family using the alter command seen in the preceding code snippet.
Warning
There are few things to keep in mind when using the CopyTable method of merging column families.
Data may be overwritten in the destination column family.
If data with the same row/column qualifier exists in both the source and destination column family, the data in the destination column family will be overwritten.
When copying a column family, there will need to be enough free space in HDFS to hold both copies temporarily.
Before starting this operation, estimate this additional space usage and account for it.
If you run this on a live production table, make sure any updates made to the source column family are also made to the destination column family.
If you are using a supplied or custom timestamp on your puts or deletes, avoid this method on a live table, as there might be unexpected results.
It is also possible to merge back multiple column families into a single column family. You simply need to specify them all by separating them with a comma:
--families=address:profile,phone:profile,status:profile
Separate a Column Family into a New Table
Separating data into different tables might be desired for various reasons.
Perhaps atomicity of operations between a table’s column families is not needed or there are significant differences in data size or access patterns between column families.
Perhaps it just makes more logical sense to have separate tables.
Again, we will make use of CopyTable to perform the operations.
The following command copies the data from column family picture of the customer table to the map table in the same column family:
hbase org.apache.hadoop.hbase.mapreduce.CopyTable --families=picture
--new.name=map customer
Here again, as long as you want to transfer multiple column families into the same destination table, you can specify each desired column family by separating them with a comma.
Both the destination table and the destination column family should exist before you start the MapReduce job.