
Chapter 16. Hotspotting
As previously discussed, to maintain its parallel nature, HBase takes advantage of regions contained in RegionServers distributed across the nodes. In HBase, all read and write requests should be uniformly distributed across all of the regions in the RegionServers. Hotspotting occurs when a given region serviced by a single RegionServer receives most or all of the read or write requests.
Consequences
HBase will process the read and write requests based on the row key. The row key is instrumental for HBase to be able to take advantage of all regions equally. When a hotspot occurs, the RegionServer trying to process all of the requests can become overwhelmed while the other RegionServers are mostly idle. Figure 16-1 illustrates a region being hotspotted. The higher the load is on a single RegionServer, the more I/O intensive and blocking processes that will have to be executed (e.g., compactions, garbage collections, and region splits). Hotspotting can also result in increased latencies, which from the client side create timeouts or missed SLAs.
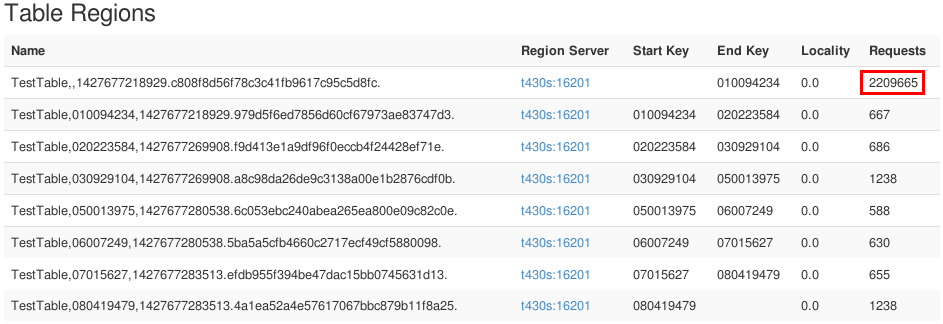
Figure 16-1. Region being hotspotted
Causes
The main cause of hotspotting is usually an issue in the key design. In the following sections, we will look at some of the most common causes of hotspotting, including monotonically incrementing or poorly distributed keys, very small reference tables, and applications issues.
Monotonically Incrementing Keys
Monotonically incrementing keys are keys where only the last bits or bytes are slowly incrementing. This means that most of the new key being written to or read from HBase is extremely similar to the previously written or read key. The most commonly seen monotonically incrementing key occurs when the timestamp is used as the key. When timestamp is used as the row key, the key will slowly increment from the first put. Let’s take a look at a quick example: in HBase, keys are stored ordered in lexicographical order. Our row keys will update as shown here:
1424362829 1424362830 1424362831 1424362832 ... 1424362900 1424362901 1424362902 1424362903 1424362904
If requests are writes, each of the preceding updates is going to go into the same region until it reaches the key of the next region or its maximum configured size. At that point, the region will split, and we will begin incrementally updating the next region. Notice that most of the write operations are against the same region, thereby burdening a single RegionServer. Unfortunately, when this issue is detected after a deployment, there is nothing you can do to prevent hotspotting. The only way to avoid this kind of issue is to prevent it with a good key design.
Poorly Distributed Keys
As stated before, key design is very important, as it will impact not only the scalability of your application, but also its performance. However, in the first iteration of schema design in a use case, it is not uncommon for keys to be poorly designed and therefore wrongly distributed. This can occur due to a lack of information at the time of the schema design but also because of issues when implementing the application. A good example of a poorly distributed key is when you expect the source data to send you keys with digits distributed between “0” and “9”; but you end up receiving keys always prefixed with value before the expected “0” to “9” values. In this case, the application expects to receive “1977” and “2001” but gets “01977” and “02001” instead. In this example, if you had properly presplit the table into 10 regions (up to “1”, “1” to “2”, “2” to “3”, etc.), then all the values you received and stored in HBase would be written to the first region (up to “1”) while all of the other regions would remain un-touched. In this case, even though we had the right intentions with the schema design, the data will never get fully distributed. This issue should be discovered during proper testing, but if you discover this issue after the application has been deployed, don’t despair—all is not lost. It is recommended to split the hotspotting region into multiple regions. This should restore the expected distribution. In this example, you will have to split the first region into 10 regions to account for the leading zero. The new region range distribution being “00”, then “00” to “01”, “01 to “02”, and so on. The other regions, after “1”, will not be used if the keys are always prefixed by “0” and can be merged together one by one through region “10”.
Small Reference Tables
This common hotspotting issue refers to the bottleneck that results from the use of small reference tables typically to perform joins in HBase. For this example, we have two reference tables consisting of a single region defining postal codes and city names. In this case, we perform a MapReduce join over a billion-row orders table. All the generated mappers are going to query those two tables to perform the lookups. As a result, the two RegionServers hosting the two reference regions will be overwhelmed by calls from all the other servers in the cluster. If you are really unlucky, those two regions will be served by the same RegionServer. This kind of contention/bottleneck will increase latency and create delays that can lead to job failures due to timeouts. The good news is that there are multiple ways to avoid this situation. The first and easiest option is to presplit your reference tables. The goal would be to have close to as many regions as you have RegionServers. Presplitting the reference table may not be an option if the table is too small or if you have too many RegionServers on HBase at the current time.
The other option here would be to distribute this table to all the nodes before performing the join. The distribution of this data will be done using the MapReduce distributed cache mechanism. The distributed cache framework will copy the data to the slave node before any tasks are executed. The efficiency of this approach stems from the fact that the files are copied only once per job.
When all servers have a local copy of the data, and if the data is small enough to fit into memory, it can then be loaded from the setup method of the MapReduce code, and lookups can now be performed into memory instead of reading from the disk.
This will increase performance, while also fixing the hotspotting issue.
Warning
If MapReduce also updates or enriches the reference table, the distributed cache is not a viable option. Indeed, distributing a copy of the table at the beginning means the content is fixed for the duration of the job. If updates to the reference table are required in your use case, then the best option is to presplit your reference table to ensure even distribution of the table across the RegionServers.
Applications Issues
The final example of region hotspotting is related to application design or implementation issues. When a region is hotspotting, it is very important to identify the root cause. To accomplish this, we need to determine the source of the offending calls. If the data is very well distributed into the table, the hotspotting may be coming from a bug causing writes to always land in the same region. This is where mistakenly added prefix fields, double or triple writes, or potentially badly converted data types can manifest themselves as application issues. Let’s imagine the system is expected to receive a four-byte integer value, but the backend code converts that to a height byte value. The four initial bytes might have been very well distributed over the entire range of data, however, adding four empty bytes to this value will create a never incrementing prefix of four empty bytes [0x00, 0x00, 0x00, 0x00] all landing into the same HBase region and creating the hotspot.
Meta Region Hotspotting
Another commonly seen issue is applications hotspotting the META region. When creating a connection to an HBase cluster, the application’s first stop is ZooKeeper to acquire HBase Master and the META region location. The application will cache this information, and will then query the META table to send read and write requests to the proper region. Each time a new connection is created, the application will again go to ZooKeeper, and to META. To avoid having all those calls to ZooKeeper and the META table each time you perform a request to HBase, it is recommended to create a single connection and to share it across your application. For a web service application, it is recommended to create a pool of a few HBase connections and share them with all the threads on the application side.
Prevention and Solution
The best way to solve hotspotting is to prevent it from happening. This starts right at the beginning of the project with a well-tested key design (refer back to “Key and Table Design” if you need a refresher on how to do this). It is also important to keep an eye on all your region metrics to have early detection of potential hotspotting. On the HBase Master web interface, the table page shows the number of requests received for each of the table’s regions. Requests column represents the number of read and write requests received by the region since it has been online. When regions are moved to other RegionServers, or when a table is disabled, the region metrics are reset. So when a region shows a very high number compared to the others, it might be hotspotting but could also be due to very recent balancing of the region between two servers. The only way to determine if it is from hotspotting or region transitions is by looking through the logs or monitoring the suspect region over time. The best way to avoid these issues in production is to put your application through proper testing and development cycles.