
Chapter 2. HBase Principles
In the previous chapter, we provided a general HBase overview, and we will now go into more detail and look at HBase principles and internals. Although it is very important to understand HBase principles in order to create a good design, it is not mandatory to know all of the internals in detail. In this chapter, we will focus the discussion on describing those HBase internals that will steer you toward good design decisions.
Table Format
Like traditional databases, HBase stores data in tables and has the concept of row keys and column names. Unlike traditional databases, HBase introduces the concept of column families, which we will describe later. But compared to RDBMSs, while the nomenclature is the same, tables and columns do not work the same way in HBase. If you’re accustomed to traditional RDBMSs, most of this might seem very familiar, but because of the way it is implemented, you will need to hang up your legacy database knowledge and put your preconceptions aside while learning about HBase.
In HBase, you will find two different types of tables: the system tables and the user tables.
Systems tables are used internally by HBase to keep track of meta information like the table’s access control lists (ACLs), metadata for the tables and regions, namespaces, and so on.
There should be no need for you to look at those tables.
User tables are what you will create for your use cases.
They will belong to the default namespace unless you create and use a specific one.
Table Layout
An HBase table is composed of one or more column families (CFs), containing columns (which we will call columns qualifiers, or CQ for short) where values can be stored. Unlike traditional RDBMSs, HBase tables may be sparsely populated—some columns might not contain a value at all. In this case, there is no null value stored in anticipation of a future value being stored. Instead, that column for that particular row key simply does not get added to the table. Once a value is generated for that column and row key, it will be stored in the table.
Tip
The HBase world uses many different words to describe different parts: rows, columns, keys, cells, values, KeyValues, timestamps, and more. To make sure we talk about the same thing, here is a clarification: a row is formed of multiple columns, all referenced by the same key. A specific column and a key are called a cell. It is possible to have multiple versions of the same cell, all differentiated by the timestamp. A cell can also be called a KeyValue pair. So a row, referenced by a key, is formed of a group of cells, each being a specific column for the given row.
Only columns where there is a value are stored in the underlying filesystem. Also, even if column families need to be defined at the table creation, there is no need to define the column names in advance. They can be dynamically generated as data is inserted into the column family. Therefore, it is possible to have millions of columns with dynamically created names, where columns names are different between all the rows.
To allow a faster lookup access, keys and columns are alphabetically sorted within a table but also in memory.
Warning
HBase orders the keys based on the byte values, so “AA” will come before “BB”. If you store numbers as character chains, keep in mind that “1234” will come before “9”. If you have to store numbers, then to save on space and to keep the ordering, you will need to store their byte representation. In this model, the integer 1234 will be stored as 0x00 0x00 0x04 0xD2, while 9 will be 0x00 0x00 0x00 0x09. Sorting those two values, we can see that 0x00 0x00 0x00 0x09 will come before 0x00 0x00 0x04 0xD2.
The easiest way to understand how an HBase table is structured is to look at it. Figure 2-1 shows a standard data representation for a table where some columns for some rows are populated and some others are not.
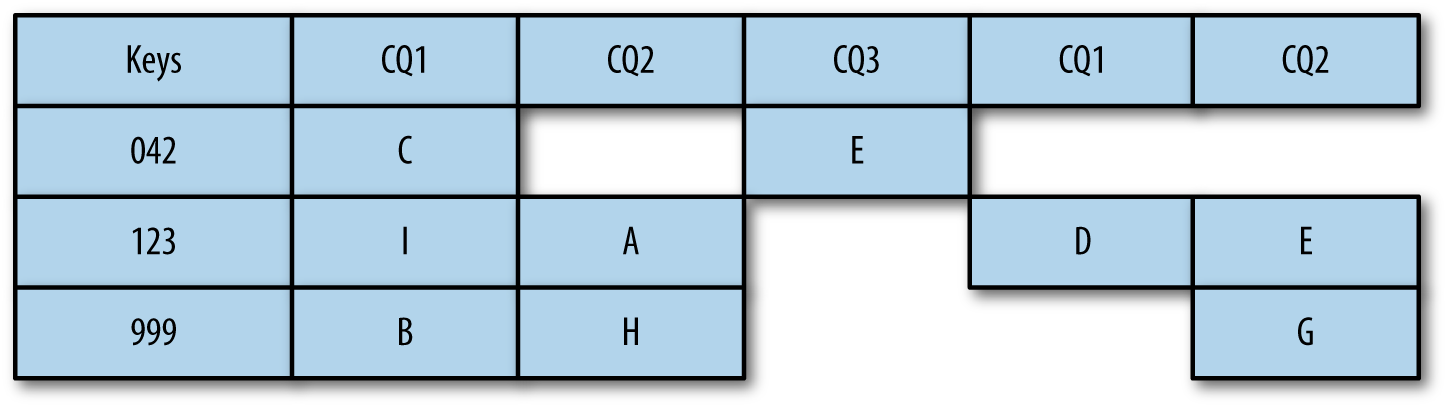
Figure 2-1. Logical representation of an HBase table
Because they will be used to create files and directories in the filesystem, the table name and the column family names need to use only printable characters. This restriction doesn’t apply to the column qualifiers, but if you are using external applications to display table content, it might be safer to also use only printable characters to define them.
Table Storage
There are multiple aspects of the table storage. The first aspect is how HBase will store a single value into the table. The second aspect is related to how all those cells are stored together in files to form a table.
As shown in Figure 2-2, from the top to the bottom, a table is composed of one to many regions, composed of one to many column families, composed of a single store, composed of a unique memstore plus one to many HFiles, composed of blocks composed of cells.
On a RegionServer, you will have as many memstores as you have regions multiplied by the number of column families receiving writes, all sharing the same reserved memory area.
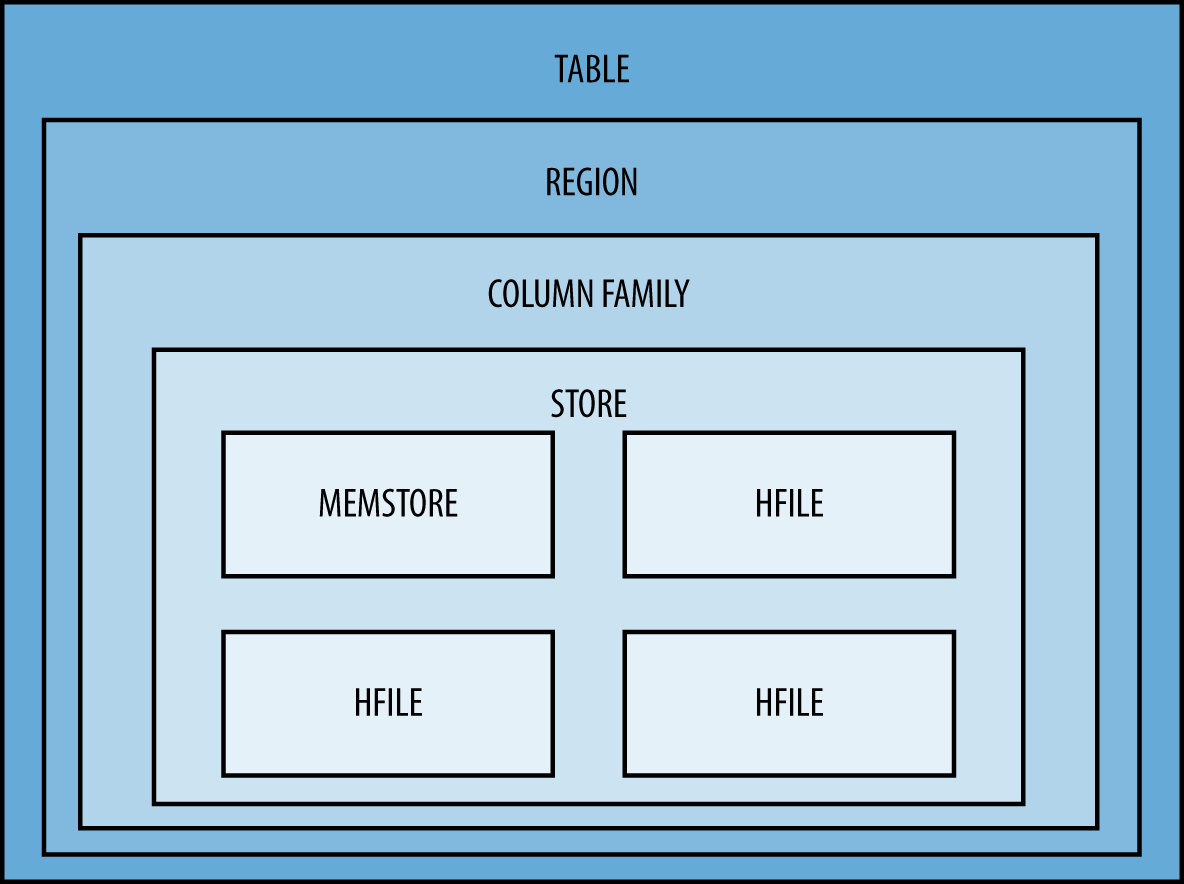
Figure 2-2. Storage layers
The following subsections provide a quick overview of all those different layers.
Regions
All the rows and related columns, together, form a table. But to provide scalability and fast random access, HBase has to distribute the data over multiple servers. To achieve this, tables are split into regions where each region will store a specific range of data. The regions are assigned to RegionServers to serve each region’s content. When new regions are created, after a configured period of time, the HBase load balancer might move them to other RegionServers to make sure the load is evenly distributed across the cluster. Like presplitting, there are many good practices around regions. All of these points are addressed in subsequent chapters.
Each region will have a start key and an end key that will define its boundaries.
All this information will be stored within the files into the region but also into the hbase:meta table (or .META., for versions of HBase prior to 0.96), which will keep track of all the regions.
When they become too big, regions can be split.
They can also be merged if required.
Column family
A column family is an HBase-specific concept that you will not find in other RDBMS applications. For the same region, different column families will store the data into different files and can be configured differently. Data with the same access pattern and the same format should be grouped into the same column family. As an example regarding the format, if you need to store a lot of textual metadata information for customer profiles in addition to image files for each customer’s profile photo, you might want to store them into two different column families: one compressed (where all the textual information will be stored), and one not compressed (where the image files will be stored). As an example regarding the access pattern, if some information is mostly read and almost never written, and some is mostly written and almost never read, you might want to separate them into two different column families. If the different columns you want to store have a similar format and access pattern, regroup them within the same column family.
The write cache memory area for a given RegionServer is shared by all the column families configured for all the regions hosted by the given host. Abusing column families will put pressure on the memstore, which will generate many small files, which in turn will generate a lot of compactions that might impact the performance. There is no technical limitation on the number of column families you can configure for a table. However, over the last three years, most of the use cases we had the chance to work on only required a single column family. Some required two column families, but each time we have seen more than two column families, it has been possible and recommended to reduce the number to improve efficiency. If your design includes more than three column families, you might want to take a deeper look at it and see if all those families are really required; most likely, they can be regrouped. If you do not have any consistency constraints between your two columns families and data will arrive into them at a different time, instead of creating two column families for a single table, you can also create two tables, each with a single column family. This strategy is useful when it comes time to decide the size of the regions. Indeed, while it was better to keep the two column families almost the same size, by splitting them accross two different tables, it is now easier to let me grow independently.
Chapter 15 provides more details regarding the column families.
HFiles
HFiles are created when the memstores are full and must be flushed to disk. HFiles are eventually compacted together over time into bigger files. They are the HBase file format used to store table data. HFiles are composed of different types of blocks (e.g., index blocks and data blocks). HFiles are stored in HDFS, so they benefit from Hadoop persistence and replication.
Blocks
HFiles are composed of blocks. Those blocks should not be confused with HDFS blocks. One HDFS block might contain multiple HFile blocks. HFile blocks are usually between 8 KB and 1 MB, but the default size is 64 KB. However, if compression is configured for a given table, HBase will still generate 64 KB blocks but will then compress them. The size of the compressed block on the disk might vary based on the data and the compression format. Larger blocks will create a smaller number of index values and are good for sequential table access, while smaller blocks will create more index values and are better for random read accesses.
Warning
If you configure block sizes to be very small, it will create many HFiles block indexes, which ultimately will put some pressure on the memory, and might produce the opposite of the desired effect. Also, because the data to compress will be small, the compression ratio will be smaller, and data size will increase. You need to keep all of these details in mind when deciding to modify the default value. Before making any definitive changes, you should run some load tests in your application using different settings. However, in general, it is recommended to keep the default value.
The following main block types can be encountered in an HFile (because they are mostly internal implementation details, we will only provide a high-level description; if you want to know more about a specific block type, refer to the HBase source code):
- Data blocks
-
A data block will contain data that is either compressed, or uncompressed, but not a combination of both. A data block includes the
deletemarkers as well as theputs. - Index blocks
-
When looking up a specific row, index blocks are used by HBase to quickly jump to the right location in an HFile.
- Bloom filter block
-
These blocks are used to store bloom filter index related information. Bloom filter blocks are used to skip parsing the file when looking for a specific key.
- Trailer block
-
This block contains offsets to the file’s other variable-sized parts. It also contains the HFile version.
Blocks are stored in reverse order. It means that instead of having the index at the beginning of the file followed by the other blocks, the blocks are written in reverse order. Data blocks are stored first, then the index blocks, then the bloom filter blocks; the trailer blocks are stored at the end.
Cells
HBase is a column-oriented database. That means that each column will be stored individually instead of storing an entire row on its own. Because those values can be inserted at different time, they might end up in different files in HDFS.
Figure 2-3 represents how HBase will store the values from Figure 2-1.
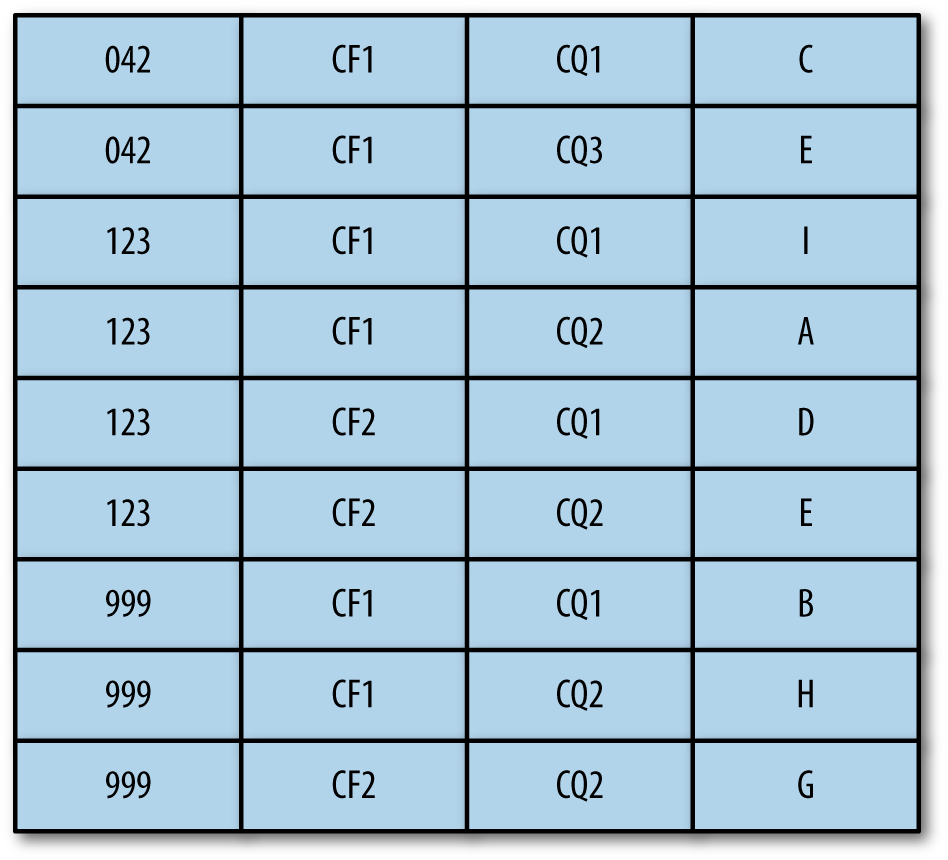
Figure 2-3. Physical representation of an HBase table
As you can see, only columns with values are stored. All columns where no value is defined are ignored.
Internally, each row will be stored within a specific format. Figure 2-4 represents the format of an individual HBase cell.
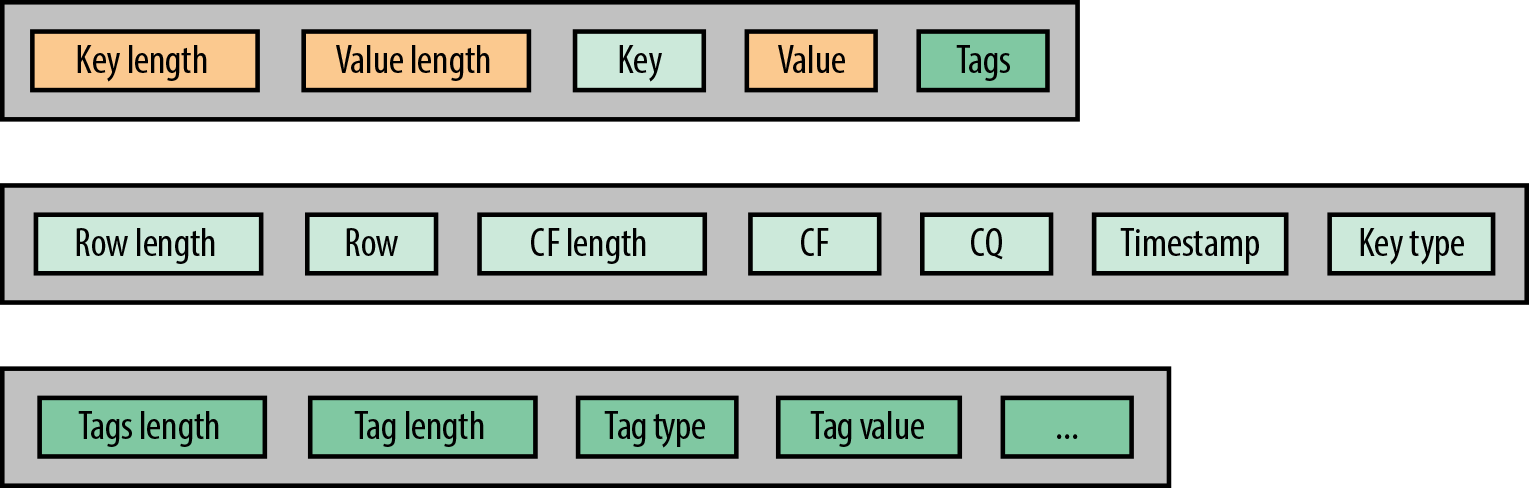
Figure 2-4. Format of an individual HBase cell
Figure 2-5 represents how the first cell from the table shown in Figure 2-3 will be stored by HBase. The tags are optional and are available only with version 3 of the HFiles format. When a cell doesn’t require any tag, they are simply not stored.
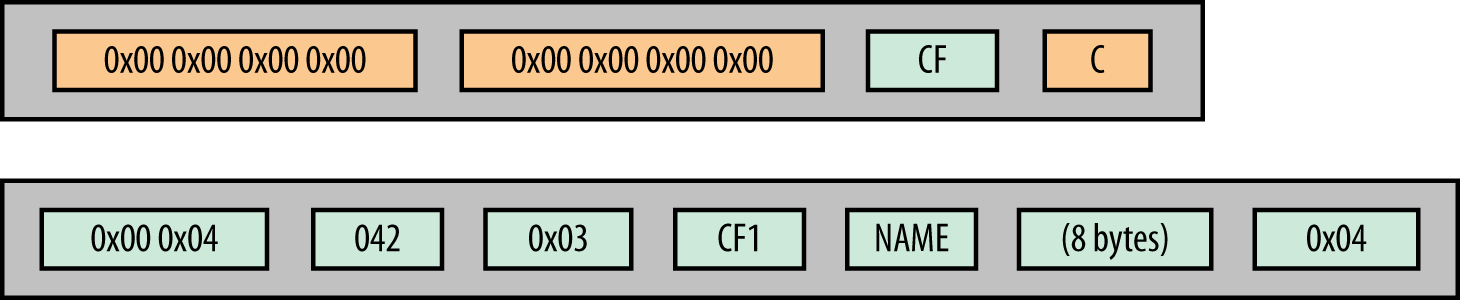
Figure 2-5. Cell example
The “key type” field represents the different possible HBase operations among the following:
-
Put -
Delete -
DeleteFamilyVersion -
DeleteColumn -
DeleteFamily
The way HBase stores the data will greatly impact the design of the HBase schema. From the preceding example, we can see that to store 1 byte, HBase had to add an extra 31 bytes. This overhead varies depending on the CQ name, the CF name, and some other criteria, but it is still very significant.
Tip
HBase implements some mechanisms to perform key compression. At a high level, only the delta between the current and the previous key is stored. For tall tables, given large and lexicographically close keys like URLs, this can provide some good space saving. However, it creates a small overhead, as the current key needs to be rebuilt from the previous one. Because columns are stored separately, this kind of compression also works well with wide tables that have many columns for the same key, as the key needs to be repeated frequently. The size of the key will be reduced, which will reduce the overall size of the entire row. This feature is called block encoding and will be discussed in more detail in “Data block encoding”.
Because of its storage format, HBase has some limitations regarding the size of those different fields (to simplify the understanding of those limitations, the reference in parentheses corresponds to Figure 2-4):
-
The maximum length for the row key plus the column family and the column qualifier is stored as four bytes and is 2^31 – 1 – 12 or, 2,147,483,635 (key length).
-
The maximum length for the value is stored as four bytes and is 2^31 – 1 or 2,147,483,647 (value length).
-
The maximum length for the row key is stored as two signed bytes and is 32,767 (row length).
-
Because it is stored in one signed byte, the maximum length for the column family is 127 (CF length).
-
The maximum length for all the tags together is stored as two bytes and is 65,535 (tags length).
Internal Table Operations
HBase scalability is based on its ability to regroup data into bigger files and spread a table across many servers. To reach this goal, HBase has three main mechanisms: compactions, splits, and balancing. These three mechanisms are transparent for the user. However, in case of a bad design or improper usage, it might impact the performance of servers. Therefore, it is good to know about these mechanisms to understand server reactions.
Compaction
HBase stores all the received operations into its memstore memory area. When the memory buffer is full, it is flushed to disk (see “Memory” for further details about the memstore and its flush mechanisms). Because this can create many small files in HDFS, from time to time, and based on specific criteria that we will see later, HBase can elect files to be compacted together into a bigger one. This will benefit HBase in multiple ways. First, the new HFile will be written by the hosting RegionServer, ensuring the data is stored locally on HDFS. Writing locally will allow the RegionServer local lookups for the file rather than going over the network. Second, this will reduce the number of files to look at when a user is requesting some data. That will allow HBase to do faster lookups and will reduce the pressure on HDFS to keep track of all the small files. Third, it allows HBase to do some cleanup on the data stored into those files. If the time to live (TTL) causes some cells to expire, they will not be rewritten in the new destination file. The same applies for the deletes under certain conditions that are detailed momentarily.
There exist two types of compactions.
Minor compaction
A compaction is called minor when HBase elects only some of the HFiles to be compacted but not all. The default configurable threshold triggers HBase compaction when there are three files (HFiles) or more in the current region. If the compaction is triggered, HBase will elect some of those files based on the compaction policy. If all the files present in the store are elected, the compaction will be promoted into a major compaction.
Minor compactions can perform some cleanup on the data, but not everything can be cleaned. When you perform a delete of a cell, HBase will store a marker to say that all identical cells older than that one have been deleted. Therefore, all the cells with the same key but a previous timestamp should be removed. When HBase performs the compaction and finds a delete marker, it will make sure that all older cells for the same key and column qualifier will be removed. However, because some cells might still exist in other files that have not been elected for compaction, HBase cannot remove the marker itself, as it still applies and it cannot make sure no other cells need to be removed. The same thing is true if the delete marker is present on a file that has not been elected for compaction. If that’s the case, cells that should have been deleted because of the marker will still remain until a major compaction is performed. Expired cells based on the TTL defined on the column family level will be deleted because they don’t depend on the content of the other non-elected files, except if the table has been configured to keep a minimal number of versions.
Warning
It is important to understand the relationship of cell version count and compactions. When deciding the number of versions to retain, it is best to treat that number as the minimum version count available at a given time. A great example of this would be a table with a single column family configured to retain a maximum version count of 3. There are only two times that HBase will remove extra versions. The first being on flush to disk, and the second on major compaction. The number of cells returned to the client are normally filtered based on the table configuration; however, when using the RAW => true parameter, you can retrieve all of the versions kept by HBase.
Let’s dive deeper into a few scenarios:
-
Doing four puts, followed immediately by a scan without a flush, will result in four versions being returned regardless of version count.
-
Doing four puts, followed by a flush and then a scan, will result in three versions being returned.
-
Doing four puts and a flush, followed by four puts and a flush, and then a scan, will result in six versions being returned.
-
Doing four puts and a flush, followed by four puts and a flush, and then a major compaction followed by a scan, will result in three versions being returned.
Major compaction
We call it a major compaction when all the files are elected to be compacted together. A major compaction works like a minor one except that the delete markers can be removed after they are applied to all the related cells and all extra versions of the same cell will also be dropped. Major compactions can be manually triggered at the column family level for a specific region, at the region level, or at the table level. HBase is also configured to perform weekly major compactions.
Warning
Automatic weekly compactions can happen at any time depending on when your cluster was started. That means that it can be overnight when you have almost no HBase traffic, but it also means that it can be exactly when you have your peak activity. Because they need to read and rewrite all the data, major compactions are very I/O intensive and can have an impact on your cluster response time and SLAs. Therefore, it is highly recommended to totally disable those automatic major compactions and to trigger them yourself using a cron job when you know the impact on your cluster will be minimal. We also recommend that you do not compact all the tables at the same time. Instead of doing all the tables once a week on the same day, spread the compactions over the entire week. Last, if you really have a very big cluster with many tables and regions, it is recommended to implement a process to check the number of files per regions and the age of the oldest one and trigger the compactions at the region level only if there are more files than you want or if the oldest one (even if there is just one file) is older than a configured period (a week is a good starting point). This will allow to keep the region’s data locality and will reduce the I/O on your cluster.
Splits (Auto-Sharding)
Split operations are the opposite of compactions. When HBase compacts multiple files together, if not too many values are dropped over the compaction process, it will create a bigger file. The bigger the input files, the more time it takes to parse them, to compact them, and so on. Therefore, HBase tries to keep them under a configurable maximum size. In HBase 0.94 and older, this default maximum size was 1 GB. Later, this value was increased to 10 GB. When one of the column families of a region reaches this size, to improve balancing of the load, HBase will trigger a split of the given region into two new regions. Because region boundaries apply to all the column families of a given region, all the families are split the same way even if they are much smaller than the configured maximum size. When a region is split, it is transformed into two new smaller regions where the start key of the first one is the start key of the original region, and the end key of the second one is the end key of the original region. The keys for the end of the first region and the beginning of the second one are decided by HBase, which will choose the best mid-point. HBase will do its best to select the middle key; however we don’t want this to take much time, so it is not going to split within an HFile block itself.
There are a few things you need to keep in mind regarding the splits. First, HBase will never split between two columns of the same row. All the columns will stay together in the same region. Therefore, if you have many columns or if they are very big, a single row might be bigger than the maximum configured size and HBase will not be able to split it. You want to avoid this situation where an entire region will serve only a single row.
You also need to remember that HBase will split all the column families. Even if your first column reached the 10 GB threshold but the second one contains only a few rows or kilobytes, both of them will be split. You might end up with the second family having only very tiny files in all the regions. This is not a situation you want to find yourself in, and you might want to review your schema design to avoid it. If you are in this situation and you don’t have a strong consistency requirement between your two column families, consider splitting them into two tables.
Finally, don’t forget that splits are not free.
When a region is balanced after being split, it loses its locality until the next compaction.
This will impact the read performance because the client will reach the RegionServer hosting the region, but from there, the data will have to be queried over the network to serve the request.
Also, the more regions you have, the more you put pressure on the master, the hbase:meta table, and the region services.
In the HBase world, splits are fine and normal, but you might want to keep an eye on them.
Figure 2-6 shows a two-column family table before and after a split. As you will note in the figure, one CF is significantly bigger than the other.
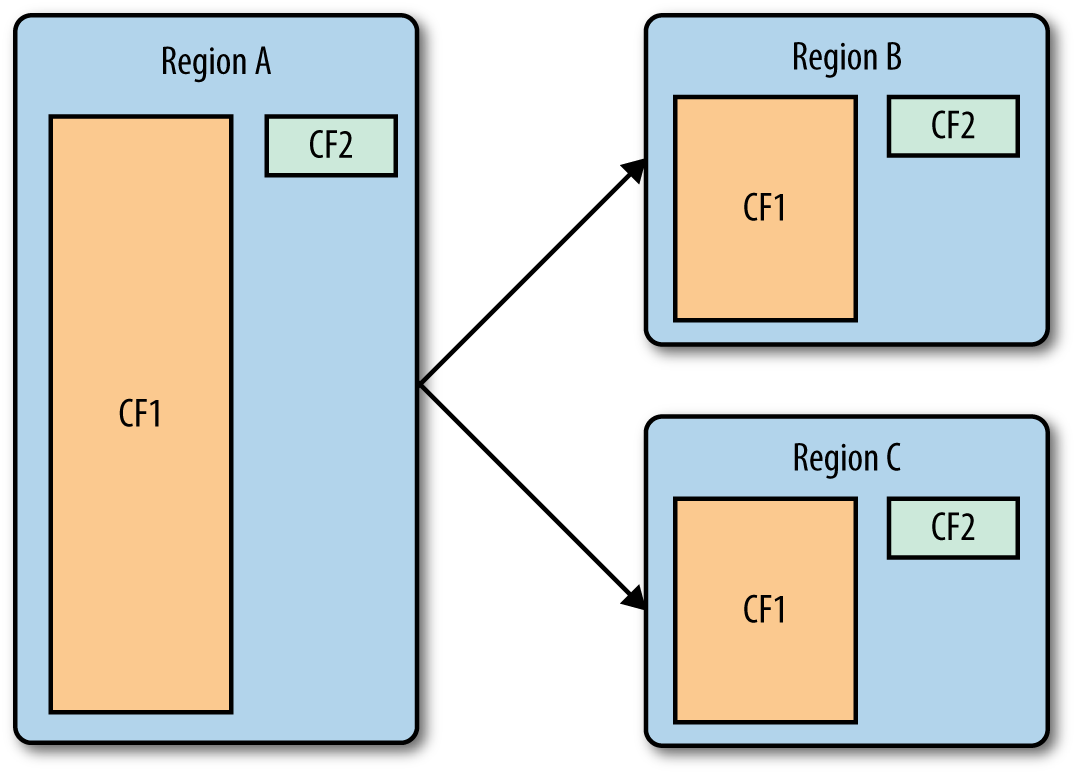
Figure 2-6. A two-column family table, before and after a split
Balancing
Regions get split, servers might fail, and new servers might join the cluster, so at some point the load may no longer be well distributed across all your RegionServers. To help maintain a good distribution on the cluster, every five minutes (default configured schedule time), the HBase Master will run a load balancer to ensure that all the RegionServers are managing and serving a similar number of regions.
HBase comes with a few different balancing algorithms.
Up to version 0.94, HBase used the SimpleLoadBalancer, but starting with HBase 0.96, it uses the StochasticLoadBalancer. Although it is recommended to stay with the default configured balancer, you can develop you own balancer and ask HBase to use it.
Warning
When a region is moved by the balancer from one server to a new one, it will be unavailable for a few milliseconds, and it will lose its data locality until it gets major compacted.
Figure 2-7 shows how the master reassigns the regions from the most loaded servers to the less loaded ones. Overloaded servers receive the instruction from the master to close and transition the region to the destination server.
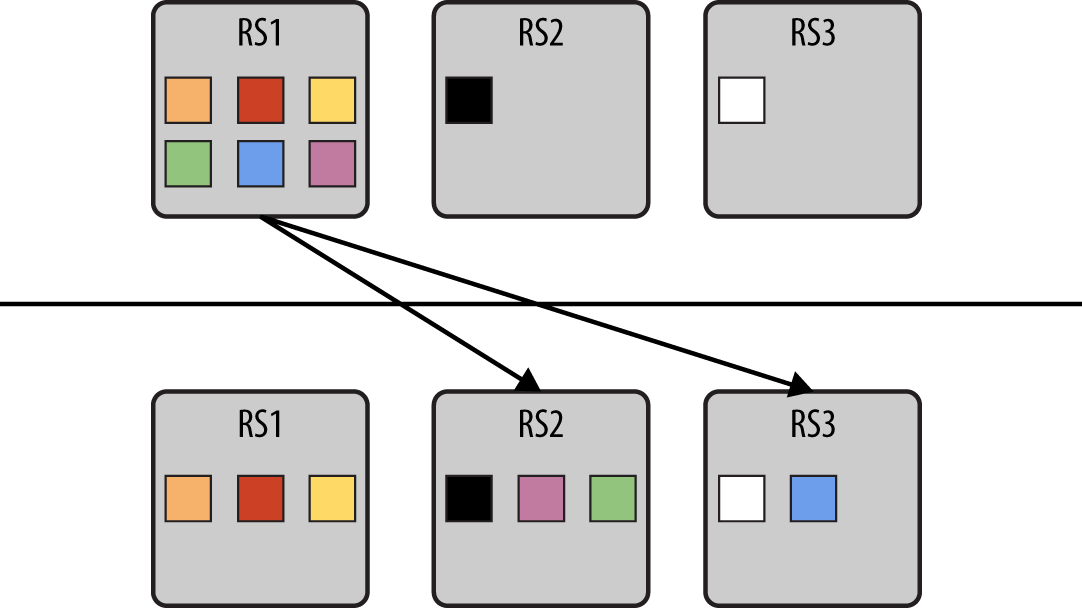
Figure 2-7. Example migration from overworked RegionServer
Dependencies
To run, HBase only requires a few other services and applications to be available. Like HDFS, HBase is written in Java and will require a recent JDK to run. As we have seen, HBase relies on HDFS. However, some work has been done in the past to run it on top of other filesystems, including Amazon S3.
HBase will need HDFS to run on the same nodes as the HBase nodes. It doesn’t mean that HBase needs to run on all the HDFS nodes, but it is highly recommended, as it might create very unbalanced situations. HBase also relies on ZooKeeper to monitor the health of its servers, to provide high-availability features, and to keep track of information such as replication progress, current active HBase Master, the list of existing tables, and so on.
There is work in progress in HBase 2.0 to reduce its dependency on ZooKeeper.
HBase Roles
HBase is composed of two primary roles: the master (also sometime called HBase Master, HMaster, or even just HM) and the RegionServers (RS). It is also possible to run Thrift and REST servers to access HBase data using different APIs.
Figure 2-8 shows how the different services need to be collocated on the different types of servers. Recent HDFS versions allow more than two NameNodes. It allows all the master servers to have a consistent list of services running (HMaster, NameNode, and ZooKeeper). Running with only two NameNodes instead of three is also totally fine.
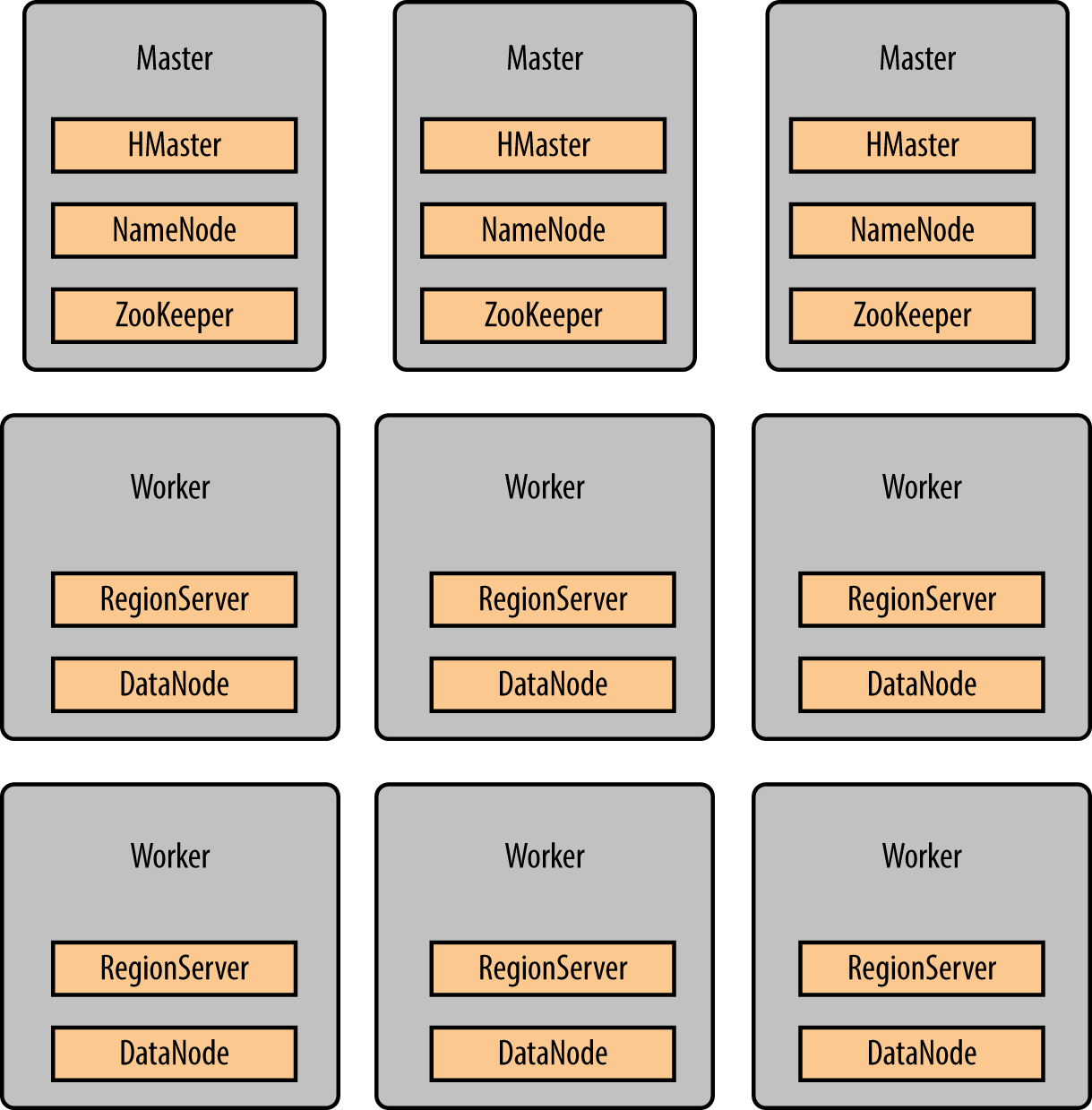
Figure 2-8. Services layout for an ideal deployment
Master Server
The HBase master servers are the head of the cluster and are responsible for few a operations:
-
Region assignment
-
Load balancing
-
RegionServer recovery
-
Region split completion monitoring
-
Tracking active and dead servers
For high availability, it is possible to have multiple masters in a single cluster. However, only a single master will be active at a time and will be responsible for those operations.
Unlike HBase RegionServers, the HBase Master doesn’t have much workload and can be installed on servers with less memory and fewer cores. However, because it is the brain of your cluster, it has to be more reliable. You will not lose your cluster if you lose two RegionServers, but losing your two Masters will put you at high risk. Because of that, even though RegionServers are usually built without disks configured as RAID or dual power supplies, etc., it is best to build more robust HBase Masters. Building HBase Masters (and other master services like NameNodes, ZooKeeper, etc.) on robust hardware with OS on RAID drives, dual power supply, etc. is highly recommended. To improve overall cluster stability, there is work in progress in HBase 2.0 to let the master track some of the information currently tracked by Zookeeper.
A cluster can survive without a master server as long as there is no RegionServer failing nor regions splitting.
RegionServer
A RegionServer (RS) is the application hosting and serving the HBase regions and therefore the HBase data. When required (e.g., to read and write data into a specific region), calls from the Java API can go directly to the RegionServer. This is to ensure the HBase master or the active ZooKeeper server are not bottlenecks in the process.
A RegionServer will decide and handle the splits and the compactions but will report the events to the master.
Even if it is technically doable to host more than one RegionServer on a physical host, it is recommended to run only one server per host and to give it the resources you will have shared between the two servers.
Tip
When a client tries to read data from HBase for the first time, it will first go to ZooKeeper to find the master server and locate the hbase:meta region where it will locate the region and RegionServer it is looking for.
In subsequent calls from the same client to the same region, all those extra calls are skipped, and the client will talk directly with the related RegionServer.
This is why it is important, when possible, to reuse the same client for multiple operations.
Thrift Server
A Thrift server can be used as a gateway to allow applications written in other languages to perform calls to HBase. Even if it is possible to use Java to call HBase through the Thrift server, it is recommended to directly call the Java API instead. HBase provides the Apache Thrift schema that you will have to compile for the language you want to use. There are currently two versions of the Thrift schema. Version 1 is the legacy schema and is kept for compatibility for external applications built against it. Version 2 is the new version and includes an updated schema. The two schemas can be found in the HBase code under the following locations:
- Version 1 (legacy)
-
hbase-thrift/src/main/resources/org/apache/hadoop/hbase/thrift/Hbase.thrift
- Version 2
-
hbase-thrift/src/main/resources/org/apache/hadoop/hbase/thrift2/hbase.thrift
Unlike the Java client that can talk to any RegionServer, a C/C++ client using a Thrift server can talk only to the Thrift server. This can create a bottleneck, but starting more than one Thrift server can help to reduce this point of contention.
Warning
Not all the HBase Java API calls might be available through the Thrift API. The Apache HBase community tries to keep them as up to date as possible, but from time to time, some are reported missing and are added back. If the API call you are looking for is not available in the Thrift schema, report it to the community.
REST Server
HBase also provides a REST server API through which all client and administration operations can be performed.
A REST API can be queried using HTTP calls directly from client applications or from command-line applications like curl.
By specifying the Accept field in the HTTP header, you can ask the REST server to provide results in different formats.
The following formats are available:
-
text/plain(consult the warning note at the end of this chapter for more information) -
text/xml -
application/octet-stream -
application/x-protobuf -
application/protobuf -
application/json
Let’s consider a very simple table created and populated this way:
create 't1', 'f1' put 't1', 'r1', 'f1:c1', 'val1'
Here is an example of a call to the HBase REST API to retrieve in an XML format the cell we have inserted:
curl -H "Accept: text/xml" http://localhost:8080/t1/r1/f1:c1
This will return the following output:
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<CellSet>
<Row key="cjE=">
<Cell column="ZjE6YzE=" timestamp="1435940848871">dmFsMQ==</Cell>
</Row>
</CellSet>
where values are base64 encoded and can be decoded from the command line:
$ echo "dmFsMQ==" | base64 -d val1
If you don’t want to have to decode XML and based64 values, you can simply use the octet-stream format:
curl -H "Accept: application/octet-stream" http://localhost:8080/t1/r1/f1:c1
which will return the value as it is:
val1
Warning
Even if the HBase code makes reference to the text/html format, it is not implemented and cannot be used.
Because it is not possible to represent the responses in all the formats, some of the calls are implemented for only some of the formats.
Indeed, even if you can call the /version or the /t1/schema URLs for the text/plain format, it will fail with the /t1/r1/f1:c1 call.
Therefore, before choosing a format, make sure all the calls you will need work with it.