


Introducing DB2 BLU Acceleration
This chapter introduces DB2 with BLU Acceleration. It describes the Seven Big Ideas behind this significant technology innovation from IBM and an example of how the technology works in action and under the covers. This chapter also describes technologies that work together with BLU Acceleration, and how users can get started with BLU Acceleration.
The following topics are covered:
1.1 DB2 with BLU Acceleration
BLU Acceleration is one of the most significant pieces of technology that has ever been delivered in DB2 and arguably in the database market in general. Available with the DB2 10.5 release, BLU Acceleration delivers unparalleled performance improvements for analytic applications and reporting using dynamic in-memory optimized columnar technologies.
A brainchild of the IBM Research and Development labs, BLU Acceleration is available with DB2 10.5 Advanced Enterprise Server Edition, Advanced Workgroup Server Edition, and Developer Edition. While the industry is abuzz with discussion of in-memory columnar data processing, BLU Acceleration offers so much more. It delivers significant improvements in database compression but does not require you to have all your data in memory.
Although BLU Acceleration is important new technology in DB2, it is built directly into the DB2 kernel as shown in Figure 1-1. It is not only an additional feature; it is a part of DB2, and every part of DB2 is aware of it. BLU Acceleration still uses the same storage unit of pages, the same buffer pools, and the same backup and recovery mechanisms. For that reason, BLU Acceleration tables can coexist with traditional row tables in the same schema, storage, and memory. You can query a mix of traditional row and BLU Acceleration tables at the same time. Converting a row-based table to a BLU Acceleration table can be easy.

Figure 1-1 DB2 10.5 engine with BLU Acceleration
1.2 BLU Acceleration: Seven Big Ideas
DB2 with BLU Acceleration includes several features that work together to make it a significant advancement in technology. We refer to these as the BLU Acceleration Seven Big Ideas.
1.2.1 Big Idea 1: Simplicity and ease of use
Simplicity and ease of use is one important design principle of BLU Acceleration. As a result, much autonomics and intelligence is built into the DB2 engine to optimize the current hardware for analytic workloads. Users do not necessarily have to purchase new hardware for a BLU Acceleration deployment. In addition, the goal is to minimize the complexity for deployment and further database maintenance tasks for DBAs.
From a deployment perspective, many manual tuning efforts are minimized. It is replaced with a single registry variable DB2_WORKLOAD=ANALYTICS that automates initial tuning of an analytics database environment. With this registry variable set, database manager and database parameters are automatically tuned by DB2 engine to optimize analytic-type workloads. For example, database memory parameters and intraquery parallelism are set to optimize the current system resources available. Workload management is also enabled automatically to handle different types of concurrent running queries more efficiently.
With the database environment set and optimized, BLU Acceleration is simple to implement and easy to use. BLU Acceleration tables coexist with traditional row-organized tables in the same database, the same table spaces, and the same buffer pools. All you have to do is create your BLU Accelerated tables, load the data into tables, and run your queries. Because of the nature of BLU Acceleration processing designed to speed analytic workloads, there is no need to create user-defined indexes, partition tables, or aggregates, define multidimensional clustering tables, build materialized tables or views, create statistical views, provide optimizer hints, and so on. Database administrators (DBAs) no longer need to spend effort in creating these objects to boost query performance. BLU Acceleration does it naturally for us.
From an ongoing maintenance perspective, without the auxiliary database objects, manual administrative and maintenance efforts from DBAs are significantly reduced. Aside from that, many administrative tasks are also automatic. For example, REORG is done automatically to reclaim space without intervention by DBAs. Of course, BLU Acceleration is built into DB2 overall, all of the database tools that DB2 DBAs are familiar with remain the same. DBAs do not have to spend time learning new skills to use BLU Acceleration.
1.2.2 Big Idea 2: Column store
BLU Acceleration is a dynamic in-memory columnar technology. Each column is physically stored in a separate set of data pages.
A column-organized approach offers many benefits to analytic workloads. Most analytic workloads tend to do more table joins, grouping, aggregates, and so on. They often access only a subset of columns in a query. By storing data in column-organized tables, DB2 pulls only the column data you want into memory rather than the entire row. As a result, more column data values can be packed into processor cache and memory, significantly reducing I/O from disks. Therefore, it achieves better query performance.
Another benefit is that column-organized tables typically compress much more effectively. BLU Acceleration compresses data per column. The probability of finding repeating patterns on a page is high when the data on the page is from the same column.
By being able to store both row and column-organized tables in the same database, users can use BLU Acceleration even in database environments where mixed online transaction processing (OLTP) and online analytical processing (OLAP) workloads are required. Again, BLU Acceleration is built into the DB2 engine; the SQL, optimizer, utilities, and other components are fully aware of both row- and column-organized tables at the same time.
1.2.3 Big Idea 3: Adaptive compression
One of the key aspects of DB2 with BLU Acceleration is how the data is encoded on disk. This is important not only because it results in significant compression, but also because DB2 is using a different encoding scheme that allows data to be scanned or compared while it remains encoded. The ability to scan with compressed data directly allows DB2 to delay materialization as long as possible and do as much work without decoding the data. The result is savings in processing effort and I/O throughput. The result is that DB2 does as much as it can without decompression.
We first explain how compression works in BLU Acceleration. First, because BLU Acceleration stores data using column-organization, each column is compressed with its own compression dictionaries. When BLU Acceleration compresses data, it uses a form of Huffman encoding, with the traditional adaptive mechanisms. The key principle is that data is compressed based on frequency of values in a column. That is, something that appears many times should be compressed more than other values that do not appear as often. Because data values are likely similar in pattern, DB2 achieves a favorable compression rate by compressing values in column-level rather than in table-wide-level.
For instance, taking a US state column as an example, because of the population of the states, the California state might appear more frequently than the Vermont state. So DB2 can encode California with a shorter, single bit (1). The result is good compression for this state that appears often in a column. At the same time, for Vermont state that might not appear as often in the same column, DB2 can encode it with a longer eight bits (11011001). The result is that those values, appearing more often in a column, obtain higher level of compression. Aside from approximate Huffman encoding, DB2 also combines this with prefix encoding and offset coding to give a more complete compression in different scenarios.
In addition to column-level compression, BLU Acceleration also uses page-level compression when appropriate. This helps further compress data based on the local clustering of values on individual data pages.
Because BLU Acceleration is able to handle query predicates without decoding the values, more data can be packed in processor cache and buffer pools. This results in less disk I/O, better use of memory, and more effective use of the processor. Therefore, query performance is better. Storage use is also reduced.
1.2.4 Big Idea 4: Parallel vector processing
Single-instruction, multiple-data (SIMD) is a common technology used in modern day processors. DB2 with BLU Acceleration has special algorithms to take advantage of the built-in parallelism in the processors automatically, if SIMD-enabled hardware is available. This is another big idea in BLU Acceleration; it includes being able to use special hardware instructions that work on multiple data elements with a single instruction.
For instance, assume that a query requires a predicate comparison sales order shipped in December 2013, as illustrated in Figure 1-2 on page 6. Without SIMD, the processor must process data elements one at a time. Data elements can be loaded into its own processor register one at a time, for example from September, October, November, and so on. As a result, multiple iterations are required to process a single instruction. With BLU Acceleration using SIMD parallelism on a processor and the ability to process predicates encoded from efficient columnar compression, multiple-encoded data values can be packed into the processor register at the same time. It is possible to take all compressed September, October, November, and December data values for a single comparison concurrently if they are in the same processor register. Therefore, the predicate processing is much faster.
|
Note: DB2 uses the power of the SIMD-enabled processors to do arithmetic operations, and can also do scans, joins, and grouping operations.
|

Figure 1-2 Efficient use of SIMD processor packing in BLU Acceleration
One of the many benefits of BLU Acceleration is cost-efficiency. BLU Acceleration does not require users to acquire new hardware. If a SIMD-enabled processor is not available in current hardware, BLU Acceleration still functions and speeds query processing using other big ideas. In some cases, BLU Acceleration even emulates SIMD parallelism with its advanced algorithms to deliver similar SIMD results.
1.2.5 Big Idea 5: Core-friendly parallelism
BLU Acceleration is a dynamic in-memory technology. It makes efficient use of the number of processor cores in the current system, allowing queries to be processed using multi-core parallelism and scale across processor sockets. The idea is to maximize the processing from processor caches, and minimize the latencies having to read from memory and, last, from disk.
Much effort was invested in comprehensive algorithms that do what is called core-friendly parallelism. The algorithms are designed so that they delicately place and align data that are likely to be revisited into the processor cache lines. This maximizes the hit rate to the processor cache, increasing effectiveness of cache lines.
An example is shown in Figure 1-3. When a query is run, first, BLU Acceleration uses a separate agent per available processor core to fetch individual column data values. Each agent can then work on different query functions. In the illustration, each processor core 0, 1, 2, 3 works on fetching data for different columns being queried. This is only one level of parallelism.

Figure 1-3 Multiple cores are used in parallel on multiple columns with BLU Acceleration
Figure 1-4 illustrates another level of parallelism. BLU Acceleration has intelligent algorithms that effectively place and align data onto processor caches. This helps reduce the number of cache misses and maximize processor cache hit rates. With data being available for reading from the processor cache without reading from the main memory or disks, query performance is improved significantly.
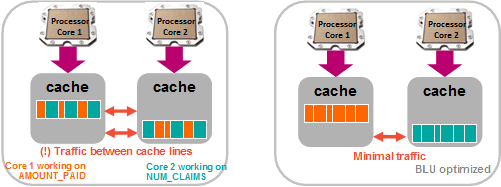
Figure 1-4 BLU Acceleration optimizes data alignment in cache lines
With the advanced technologies that IBM research and development groups have put together in BLU Acceleration, BLU Acceleration delivers a whole new level of query performance. Also worth mentioning is that BLU Acceleration does all the parallelism without DBAs intervention or maintenance.
1.2.6 Big Idea 6: Scan-friendly memory caching
BLU Acceleration is designed for the demands of a big data world where it maybe less likely that all of the data that queries need can fit into memory. As we mentioned before, the product is cost-efficient. Users are not required to purchase the latest or fastest hardware to run BLU Acceleration. Although DB2 would make good use of having as much hot (active) data in memory as possible, it is not a requirement to fit everything in memory.
BLU Acceleration includes a set of big data-aware algorithms, for cleaning out memory pools, that is more advanced than the typical least recently used (LRU) algorithms that are associated with traditional row-organized database technologies. These BLU Acceleration algorithms are designed from the ground up to detect “interested” data patterns that are likely to be revisited, and to hold those pages in the buffer pool as long as possible. These algorithms work with the DB2 traditional row-based algorithms. Along with the effective columnar compression, even more hot data can fit into the buffer pool. Clients typically have a memory-to-disk ratio of 15% to 50%. What this means is that they cannot possibly fit their entire table, or even the data that is required to run a complex query, entirely into memory. With BLU Acceleration, at least 70% - 80% of active data can likely fit into memory. The net result is that you can get significant performance boosts from data that is already in memory, although memory on your database server might not be as big as your tables.
1.2.7 Big Idea 7: Data skipping
To speed query processing, BLU Acceleration can skip ranges of data that are not relevant to the current query, reducing unnecessary I/O. For instance, if a report will be looking for the sales orders from December 2013, scanning through sales orders that were made in October, November, and so on, is not necessary. BLU Acceleration goes straight to the ranges of data that contain sales orders from December 2013, and computes the rest of the query.
This is how BLU Acceleration does data skipping. As data is loaded into column-organized tables, BLU Acceleration tracks the minimum and maximum values on ranges of rows in metadata objects that are called the synopsis tables. These metadata objects (or synopsis tables) are dynamically managed and updated by the DB2 engine without intervention from the DBA. When a query is run, BLU Acceleration looks up the synopsis tables for ranges of data that contain the value that matches the query. It effectively avoids the blocks of data values that do not satisfy the query, and skips straight to the portions of data that matches the query. The net effect is that only necessary data is read or loaded into system memory, which in turn provides dramatic increase in speed of query execution because much of the unnecessary scanning is avoided.
1.2.8 The seven big ideas in action
You might have noticed that from all of the big ideas, BLU Acceleration is designed to be simple, and easy to use. First, the effort required to deploy and maintain a BLU Acceleration environment is minimal. Second, advanced technologies such as columnar compression, parallel vector processing, core-friendly parallelism, scan-friendly memory caching, and data skipping are all used by DB2 automatically without DBAs having to explicitly deploy extra auxiliary structures for it to work. It is in the DB2 engine’s nature to process queries using these technologies.
With our client base who are using BLU Acceleration, we found that clients have experienced an average, conservatively, of approximately 10 times compression on their analytics databases, without any complex tuning. In terms of performance, we observed that their queries ran 35 - 73 times faster on average (and some are even faster).
To help you understand how DB2 clients are observed to have significant performance and storage improvements using BLU Acceleration, we go through an example there. This example can help you understand how BLU Acceleration works under the layers when running a query on a large amount of data.
Assume that we have an analytics environment with the following attributes:
•Raw data is of 12 TB data in size.
•Database server has SIMD-enabled processor, 30 cores, and 240 GB of memory.
•Database stores two years of data (2012 - 2013).
•Sales order table has 100 columns.
When a query is run to look for sales orders that are shipped in December 2013, the following actions occur:
•Query:
SELECT SUM(ORDER_TOTAL) FROM SALES_FACT WHERE MONTH='201312'
•Columnar compression: From raw data of 12 TB data in size, conservatively we assume five times the compression rate. (This assumption is conservative because BLU Acceleration is often observed to have average of about 10x.) This lowers data size to 2.4 TB.
•Column store: Query is accessing the ORDER_TOTAL and MONTH columns of a total of 100 columns. Access to column-organized tables decreases the size of interested data to 2/100 columns = 1/50 of compressed data (which means 48 GB).
•Data skipping: With use of synopsis tables, BLU Acceleration skips to the data that matches the predicate without decoding or any evaluation processing. Consider query is accessing ORDER_TOTAL that is in December 2013. This is one month out of total of two years (1/24) of records in the entire database. This brings down the interested data to 48 GB / 24 = 2 GB.
•Core-friendly parallelism: Data is processed in parallel across 30 available processor cores. That is, 2 GB / 30 = 68 MB.
•Parallel vector processing: Data can be scanned using a SIMD-enabled processor to achieve faster performance. The improvement depends on various processors. With a conservative assumption that this SIMD-enabled processor obtains 4 times faster per byte, DB2 only has to scan approximately 68 MB / 4 =~ 17 MB of data.
To summarize this example, DB2 must process only about 17 MB of data at the end. This is roughly the size of a few high-quality digital pictures or cell phone apps. Consider a modern processor that processes 17 MB of data; results can be returned almost instantly. This example demonstrates how BLU Acceleration can easily achieve significant performance and storage improvements for analytic workloads.
1.3 Next generation analytics: Cognos BI and DB2 with BLU Acceleration
In the first few chapter of this book, we use Cognos Business Intelligence (BI) as an example to demonstrate deployment, testing, and verification of BLU Acceleration in analytic workloads from Cognos BI. First, we give a brief introduction of how Cognos BI and DB2 with BLU Acceleration work together.
All DB2 editions that support BLU Acceleration include five authorized user license entitlements to Cognos BI 10.2. The following BLU Acceleration editions are supported in DB2 10.5 FP3:
•DB2 Advanced Workgroup Server Edition (AWSE)
•Advanced Enterprise Server Edition (AESE)
•Developer Edition (DE)
Cognos Business Intelligence is a proven scalable enterprise BI platform that provides customers with the power of analytics and helps drive better business decisions. Cognos Business Intelligence 10.2.1 includes Dynamic Cubes technology that helps boost query performance by making efficient use of memory. With Cognos Dynamic Cubes, aggregates, expressions, results, and data can all be stored in memory. Ad-hoc queries or detailed drill-down reports can have instant responses across terabytes of data. Besides Dynamic Cubes, Cognos BI 10.2 also achieves faster load time in Active Report through improved use of compression and engine optimization. There are also other new extensible, customizable visualization features that help enhance the BI user reports experience.
Enhanced performance from database layer
Although Cognos BI provides various techniques such as Dynamic Cubes to optimize analytics on a large amount of data, completely bypassing access to the underlying database is almost unavoidable. For instance, sometimes data might not be found in the Dynamic Cubes so the system then needs to access the required data from the relational database. DB2 with BLU Acceleration complements the optimizations in Cognos with dynamic in-memory column store technologies on the database layer. It is optimized for analytic workloads, providing an efficient data platform for accessing large amount of data for specific columns when needed.
Different from other fully in-memory database technologies in the market, DB2 with BLU Acceleration does not require all data to be stored in memory. You can continue to use your existing hardware with BLU Acceleration, making this a flexible, cost-effective, and yet efficient data platform solution for Cognos users.
In performance tests with Cognos BI and DB2 with BLU Acceleration running together, Cognos cube loading is tested to achieve faster performance through the improved data compression, hardware instructions, and column-data processing in BLU Acceleration technologies. Cognos BI modelers can now use less time to load and refresh data cubes; users can run more conditional queries in much less time. Furthermore, Cognos report workload performance is also tested to achieve faster performance. Users can now experience click-through of their reports much faster.
Simplicity of the combined solutions
The combination of Cognos BI and DB2 with BLU Acceleration provides enhanced performance improvement for analytic workloads and simplicity in usage and maintenance.
First, Cognos engine recognizes BLU Acceleration column-organized tables as regular DB2 tables. For Cognos BI developers or users, existing Cognos reports or definitions do not require being changed when converting existing row-organized data into BLU Acceleration column-organized tables.
Second, BLU Acceleration is deployed with even more autonomics. For DBAs, the needs for creating and managing indexes or materialized query tables (MQTs), aggregates, partitioning, tuning, SQL changes and schema changes are gone and replaced with the DB2 engine doing all the hard work. In sum, the Cognos BI and DB2 with BLU Acceleration combined solution provides speed-of-thought performance for reports, and reduces storage costs with enhanced data compression from both solutions and fewer database objects required from BLU Acceleration. The combined solution is thoroughly tested, optimized together to achieve most optimal analytics for existing or new Cognos BI users.
1.4 IBM DB2 with BLU Acceleration offerings
IBM DB2 with BLU Acceleration includes several offerings to address various client needs. As with the key design principle of DB2 with BLU Acceleration, these offerings further simplify deployment by providing an integrated hardware and software platform for an enterprise business intelligence environment. The following offerings are described in this section:
•IBM Business Intelligence with BLU Acceleration Pattern
•IBM BLU Acceleration for Cloud
•IBM BLU Acceleration Solution – IBM Power Systems™ Edition
1.4.1 Simplified IBM Business Intelligence with BLU Acceleration Pattern deployment on IBM PureApplication Systems
As data volumes grow exponentially and demands on analytics increase, having a ready-to-use optimized BI analytics environment built in a short amount of time is beneficial. IBM Business Intelligence with DB2 BLU Acceleration pattern is for businesses that require fast access to an available enterprise analytics solution. It is an automation deployment package that speeds deployment of DB2 with BLU Acceleration and IBM Cognos Business Intelligence with Dynamic Cubes. The pattern comes together with expertise deployment preferred practices. It can be deployed on pattern-enabled hardware, such as the IBM PureApplication® system, with a complete functioning BI environment in as short amount of time as 1 hour. After the system is deployed, users can start loading data for analytics, modeling, and start deploying their projects immediately.
The IBM PureApplication System on which the Business Intelligence with BLU Acceleration Pattern can be deployed, builds an open and scalable cloud application platform for web and database applications. A PureApplication System is preassembled and includes predefined patterns to simplify and automate IT lifecycle tasks of applications. Patterns can deploy application architectures, including platform services, and manage infrastructures to help customers and partners reduce time and cost, adjust to rapid changes, and identify problems faster. The PureApplication System is available in scalable configurations ranging from small development and testing to large enterprise environments that can be managed and updated through a single console.
With the Business Intelligence Pattern with BLU Acceleration, users do not have to build hardware and software systems from scratch. The result is a short deployment, which provides a virtual application instance on the PureApplication System that includes the following components:
•IBM Cognos Business Intelligence: A web-based business intelligence solution with integrated reporting, analysis, and event management features.
•IBM WebSphere® Application Server: A web application server for hosting Java-based web applications.
•IBM Tivoli® Directory Integrator: Synchronizes data across multiple repositories.
•Cognos content store database on IBM DB2: Stores Cognos metadata such as application data, including security, configuration data, models, metrics, report specifications, and report output in a DB2 database.
•IBM DB2 with BLU Acceleration: A database used for the BI Pattern.
For more information about IBM Cognos Business Intelligence, consult the following website that includes the Business Intelligence Pattern with BLU Acceleration Installation and Administration Guide:
Also, you can find an entry point into the IBM PureApplication System at this location:
1.4.2 IBM BLU Acceleration for Cloud
With cloud computing being a popular trend, DB2 with BLU Acceleration is also available in a software service on-the-cloud offering. This allows companies to launch their new analytics projects or prototypes on the cloud platform without having to add new IT infrastructure requirements and capitals. The software stack includes DB2 with BLU Acceleration and Cognos Business Intelligence, a combined optimized data warehousing and analytics solution for data analytics. Companies can choose a preferred cloud provider (Softlayer or AWS), or have IBM managed services to help you move to a cloud environment.
For more information, visit the following website:
1.4.3 IBM BLU Acceleration Solution – Power Systems Edition
IBM BLU Acceleration Solution – Power Systems Edition includes IBM AIX®, IBM PowerVM®, and DB2 with BLU Acceleration on a Power ESE server. This combined solution is designed to take advantage of the multiple cores and simultaneous multi-threading capability in IBM POWER7+™ processors and provides fast performance data warehouse infrastructure for analytic workloads.
For more information, see the following web page:
1.5 Obtaining DB2 with BLU Acceleration
Several methods are available for trying DB2 with BLU Acceleration:
•IBM DB2 BLU Acceleration Kit for Trial: Install a fresh operating system and DB2 software stack together with minimal system setup hassle.
•IBM DB2 with BLU Acceleration for Cloud Beta: Access DB2 with BLU Acceleration on the cloud with your Internet browser for up to 5 hours.
•Download DB2 with BLU Acceleration Trial: Download 90-day DB2 trial software and install it on your own systems.
•Attend an IBM DB2 BLU Bootcamp or IBM Education: Attend bootcamps and education classes with presentations and hands-on lab exercises to learn and try everything about BLU Acceleration.
1.5.1 IBM DB2 BLU Acceleration Kit for Trial
The IBM DB2 BLU Acceleration Kit for Trial is ideal for users who want to try DB2 with BLU Acceleration on their own existing hardware with minimal system setup hassle. Essentially, it is an installable .iso file or raw USB image that installs a full DB2 and operating system software stack on any x86_64 physical and virtual machine. The kit includes automated scripts and simple installation wizards to quickly get a running DB2 trial system including the following components:
•SUSE Linux Enterprise Server operating system
•IBM DB2 10.5 with BLU Acceleration (90 days trial)
•IBM Data Studio
•IBM Database Conversion Workbench
|
Attention: This installation kit wipes out any existing operating system and data on an existing system.
|
For more information and to download the kit, visit Information Management Solution Portal at the following website:
1.5.2 IBM BLU Acceleration for Cloud trial option
For users who want to experience DB2 with BLU Acceleration without any setup, the BLU Acceleration for Cloud trial plan provides a fully functional analytics environment for up to 5 hours at no charge. For more information, see the IBM BLU Acceleration for Cloud website:
1.5.3 DB2 with BLU Acceleration trial software
To install DB2 with BLU Acceleration trial software on your own platforms, download the 90-day no-charge trial software from the Get DB2 with BLU Acceleration website:
1.5.4 IBM DB2 BLU bootcamps and education
Extensive training materials are available for DB2 with BLU Acceleration, including bootcamps and IBM education offerings. For more information, contact your IBM Software Group representative for details.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.