
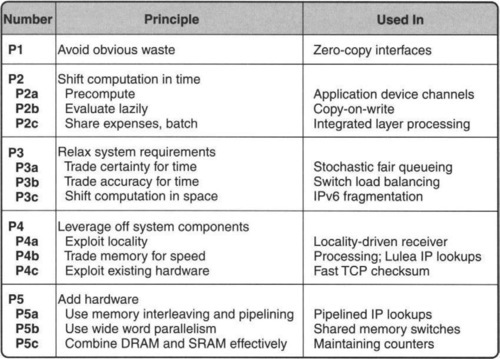
Fifteen Implementation Principles
Instead of computing, I had to think about the problem, a formula for success that I recommend highly.
—IVAN SUTHERLAND
After understanding how queens and knights move in a game of chess, it helps to understand basic strategies, such as castling and the promotion of pawns in the endgame. Similarly, having studied some of the rules of the protocol implementation game in the last chapter, you will be presented in this chapter with implementation strategies in the form of 15 principles. The principles are abstracted from protocol implementations that have worked well. Many good implementors unconsciously use such principles. The point, however, is to articulate such principles so that they can be deliberately applied to craft efficient implementations.
This chapter is organized as follows. Section 3.1 motivates the use of the principles using a ternary CAM problem. Section 3.2 clarifies the distinction between algorithms and algorithmics using a network security forensics problem. Section 3.3 introduces 15 implementation principles; Section 3.4 explains the differences between implementation and design principles. Finally, Section 3.5 describes some cautionary questions that should be asked before applying the principles.
The reader pressed for time should consult the summaries of the 15 principles found in Figures 3.1, 3.2, and 3.3. Two networking applications of these principles can be found in a ternary CAM update problem (Section 3.1) and a network security forensics problem (Section 3.2).
3.1 MOTIVATING THE USE OF PRINCIPLES — UPDATING TERNARY CONTENT-ADDRESSABLE MEMORIES
Call a string ternary if it contains characters that are either 0,1, or *, where * denotes a wildcard that can match both a 0 and a 1. Examples of ternary strings of length 3 include S1 = 01 * and S2 = *1*; the actual binary string Oil matches both SI and S2, while 111 matches only S2.
A ternary content-addressable memory (CAM) is a memory containing ternary strings of a specified length together with associated information; when presented with an input string, the CAM will search all its memory locations in parallel to output (in one cycle) the lowest memory location whose ternary string matches the specified input key.
Figure 3.4 shows an application of ternary CAMs to the longest-matching-prefix problem for Internet routers. For every incoming packet, each Internet router must extract a 32-bit destination IP address from the incoming packet and match it against a forwarding database of IP prefixes with their corresponding next hops. An IP prefix is a ternary string of length 32 where all the wildcards are at the end. We will change notation slightly and let * denote any number of wildcard characters, so 101* matches 10100 and not just 1010.
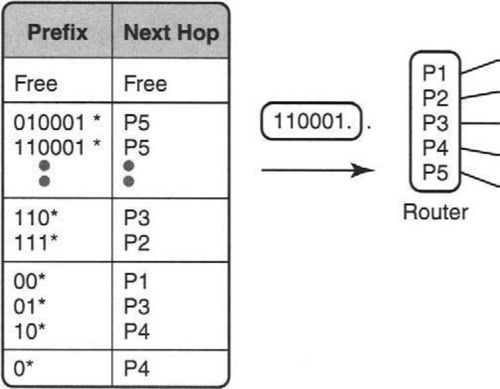
Thus in Figure 3.4 a packet sent to a destination address that starts with 010001 matches the prefixes 010001* and 01* but should be sent to Port P5 because Internet forwarding requires that packets be forwarded using the longest match. We will have more to say about this problem in Chapter 11. For now, note that if the prefixes are arranged in a ternary CAM such that all longer prefixes occur before any shorter prefixes (as in Figure 3.4), the ternary CAM provides the matching next hop in one memory cycle.
While ternary CAMs are extremely fast for message forwarding, they require that longer prefixes occur before shorter prefixes. But routing protocols often add or delete prefixes. Suppose in Figure 3.4 that a new prefix, 11*, with next hop Port 1 must be added to the router database. The naive way to do insertion would make space in the group of length-2 prefixes (i.e., create a hole before 0*) by pushing up by one position all prefixes of length 2 or higher.
Unfortunately, for a large database of around 100,000 prefixes kept by a typical core router, this would take 100,000 memory cycles, which would make it very slow to add a prefix. We can obtain a better solution systematically by applying the following two principles (described later in this chapter as principles P13 and P15).
UNDERSTAND AND EXPLOIT DEGREES OF FREEDOM
In looking at the forwarding table on the left of Figure 3.4 we see that all prefixes of the same length are arranged together and all prefixes of length i occur after all prefixes of length j > i.
However, in the figure all prefixes of the same length are also sorted by value. Thus 00* occurs before 01*, which occurs before 10*. But this is unnecessary for the CAM to correctly return longest matching prefixes: We only require ordering between prefixes of different lengths; we do not require ordering between prefixes of the same length.
In looking at the more abstract view of Figure 3.4 shown in Figure 3.5, we see that if we are to add an entry to the start of the set of length-i prefixes, we have to create a hole at the end of the length-(i + 1) set of prefixes. Thus we have to move the entry X, already at this position, to another position. If we move X one step up, we will be forced into our prior inefficient solution.
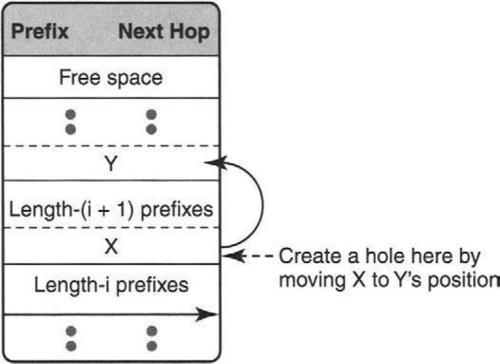
However, our observation about degrees of freedom says that we can place X anywhere adjacent to the other length-(i + 1) prefixes. Thus, an alternative idea is to move X to the position held by Y, the last length-(i + 2) prefix. But this forces us to find a new position for Y. How does this help? We need a second principle.
USE ALGORITHMIC TECHNIQUES
Again, recursion suggests itself: We solve a problem by reducing the problem to a “smaller” instance of the same problem. In this case, the new problem of assigning Y a new position is “smaller” because the set of length-(i + 2) prefixes are closer to the free space at the top of the CAM than the set of length-(i + 1) prefixes. Thus we move Y to the end of the length-(i + 3) set of prefixes, etc.
While recursion is a natural way to think, a better implementation is to unwind the recursion by starting from the top of the CAM and working downward by creating a hole at the end of the length-1 prefixes,1 creating a hole at the end of the length-2 prefixes, etc., until we create a hole at the end of the length-i prefixes. Thus the worst-case time is 32 – i memory accesses, which is around 32 for small i.
Are we done? No, we can do better by further exploiting degrees of freedom. First, in Figure 3.5 we assumed that the free space was at the top of the CAM. But the free space could be placed anywhere. In particular, it can be placed after the length-16 prefixes. This reduces the worst-case number of memory accesses by a factor of 2 [SG01].
A more sophisticated degree of freedom is as follows. So far the specification of the CAM insertion algorithm required that “a prefix of length i must occur before a prefix of length j if i > j.” Such a specification is sufficient for correctness but is not necessary. For example, 010* can occur before 111001* because there is no address that can match both prefixes!
Thus a less exacting specification is “if two prefixes P and Q can match the same address, then P must come before Q in the CAM if P is longer than Q.” This is used in Shah and Gupta [SG01] to further reduce the worst-case number of memory accesses for insertion for some practical databases.
While the last improvement is not worth its complexity, it points to another important principle. We often divide a large problem into subproblems and hand over the subproblem for a solution based on a specification. For example, the CAM hardware designer may have handed over the update problem to a microcoder, specifying that longer prefixes be placed before shorter ones.
But, as before, such a specification may not be the only way to solve the original problem. Thus changes to the specification (principle P3) can yield a more efficient solution. Of course, this requires curious and confident individuals who understand the big picture or who are brave enough to ask dangerous questions.
3.2 ALGORITHMS VERSUS ALGORITHMICS
It may be possible to argue that the previous example is still essentially algorithmic and does not require system thinking. One more quick example will help clarify the difference between algorithms and algorithmics.
SECURITY FORENSICS PROBLEM
In many intrusion detection systems, a manager often finds that a flow (defined by some packet header, for example, a source IP address) is likely to be misbehaving based on some probabilistic check. For example, a source doing a port scan may be identified after it has sent 100,000 packets to different machines in the attacked subnet.
While there are methods to identify such sources, one problem is that the evidence (the 100,000 packets sent by the source) has typically disappeared (i.e., been forwarded from the router) by the time the guilty source is identified. The problem is that the probabilistic check requires accumulating some state (in, say, a suspicion table) for every packet received over some period of time before a source can be deemed suspicious. Thus if a source is judged to be suspicious after 10 seconds, how can one go back in time and retrieve the packets sent by the source during those 10 seconds?
To accomplish this, in Figure 3.6 we keep a queue of the last 100,000 packets that were sent by the router. When a packet is forwarded we also add a copy of the packet (or just keep a pointer to the packet) to the head of the queue. To keep the queue bounded, when the queue is full we delete from the tail as well.
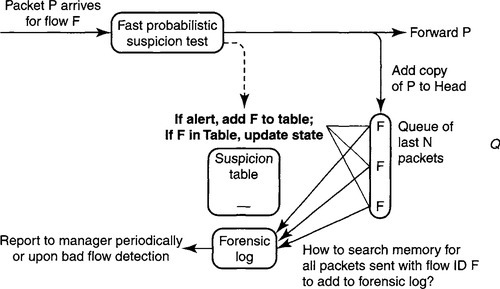
The main difficulty with this scheme is that when a guilty flow is detected there may be lots of the flow’s packets in the queue (Figure 3.6). All of these packets must be placed in the forensic log for transmission to a manager. The naive method of searching through a large DRAM buffer is very slow.
The textbook algorithms approach would be to add some index structure to search quickly for flow IDs. For example, one might maintain a hash table of flow IDs that maps every flow to a list of pointers to all packets with that flow ID in the queue. When a new packet is placed in the queue, the flow ID is looked up in the hash table and the address of the new packet in the queue is placed at the end of the flow’s list. Of course, when packets leave the queue, their entries must be removed from the list, and the list can be long. Fortunately, the entry to be deleted is guaranteed to be at the head of the queue for that flow ID.
Despite this, the textbook scheme has some difficulties. It adds more space to maintain these extra queues per flow ID, and space can be at a premium for a high-speed implementation. It also adds some extra complexity to packet processing to maintain the hash table, and requires reading out all of a flow’s packets to the forensic log before the packet is overwritten by a packet that arrives 100,000 packets later. Instead the following “systems” solution may be more elegant.
SOLUTION
Do not attempt to immediately identify all of a flow F’s packets when F is identified, but lazily identify them as they reach the end of the packet queue. This is shown in Figure 3.7. When we add a packet to the head of the queue, we must remove a packet from the end of the queue (at least when the queue is full).

If that packet (say, Q, see Figure 3.6) belongs to flow F that is in the Suspicion Table and flow F has reached some threshold of suspicion, we then add packet Q to the forensic log. The log can be sent to a manager. The overhead of this scheme is significant but manageable; we have to do two packet-processing steps, one for the packet being forwarded and one for the packet being removed from the queue. But these two packet-processing steps are also required in the textbook scheme; on the other hand, the elegant scheme requires no hashing and uses much less storage (no pointers between the 100,000 packets)
3.3 FIFTEEN IMPLEMENTATION PRINCIPLES — CATEGORIZATION AND DESCRIPTION
The two earlier examples and the warm-up exercise in Chapter 1 motivate the following 15 principles, which are used in the rest of the book. They are summarized inside the front cover. To add more structure they are categorized as follows:
• Systems Principles: Principles 1–5 take advantage of the fact that a system is constructed from subsystems. By taking a systemwide rather than a black-box approach, one can often improve performance.
• Improving Efficiency While Retaining Modularity: Principles 6–10 suggest methods for improving performance while allowing complex systems to be built modularly.
• Speeding It Up: Principles 11–15 suggest techniques for speeding up a key routine considered by itself.
Amazingly, many of these principles have been used for years by Chef Charlie at his Greasy Spoon restaurant. This chapter sometimes uses illustrations drawn from Chef Charlie’s experience, in addition to computer systems examples. One networking example is also described for each principle, though details are deferred to later chapters.
3.3.1 Systems Principles
The first five principles exploit the fact that we are building systems.
P1: AVOID OBVIOUS WASTE IN COMMON SITUATIONS
In a system, there may be wasted resources in special sequences of operations. If these patterns occur commonly, it may be worth eliminating the waste. This reflects an attitude of thriftiness toward system costs.
For example, Chef Charlie has to make a trip to the pantry to get the ice cream maker to make ice cream and to the pantry for a pie plate when he makes pies. But when he makes pie à la mode, he has learned to eliminate the obvious waste of two separate trips to the pantry.
Similarly, optimizing compilers look for obvious waste in terms of repeated subexpressions. For example, if a statement calculates i = 5.1 * n + 2 and a later statement calculates j (5.1 * n + 2) * 4, the calculation of the common subexpression 5.1 * n + 2 is wasteful and can be avoided by computing the subexpression once, assigning it to a temporary variable t, and then calculating i: = t and j: = t * 4. A classic networking example, described in Chapter 5, is avoiding making multiple copies of a packet between operating system and user buffers.
Notice that each operation (e.g., walk to pantry, line of code, single packet copy) considered by itself has no obvious waste. It is the sequence of operations (two trips to the pantry, two statements that recompute a subexpression, two copies) that have obvious waste. Clearly, the larger the exposed context, the greater the scope for optimization. While the identification of certain operation patterns as being worth optimizing is often a matter of designer intuition, optimizations can be tested in practice using benchmarks.
P2: SHIFT COMPUTATION IN TIME
Systems have an aspect in space and time. The space aspect is represented by the subsystems, possibly geographically distributed, into which the system is decomposed. The time aspect is represented by the fact that a system is instantiated at various time scales, from fabrication time, to compile time, to parameter-setting times, to run time. Many efficiencies can be gained by shifting computation in time. Here are three generic methods that fall under time-shifting.
• P2a: Precompute. This refers to computing quantities before they are actually used, to save time at the point of use. For example, Chef Charlie prepares crushed garlic in advance to save time during the dinner rush. A common systems example is table-lookup methods, where the computation of an expensive function f in run time is replaced by the lookup of a table that contains the value of f for every element in the domain of f. A networking example is the precomputation of IP and TCP headers for packets in a connection; because only a few header fields change for each packet, this reduces the work to write packet headers (Chapter 9).
• P2b: Evaluate Lazily. This refers to postponing expensive operations at critical times, hoping that either the operation will not be needed later or a less busy time will be found to perform the operation. For example, Chef Charlie postpones dishwashing to the end of the day. While precomputation is computing before the need, lazy evaluation is computing only when needed.
A famous example of lazy evaluation in systems is copy-on-write in the Mach operating system. Suppose we have to copy a virtual address space A to another space, B, for process migration. A general solution is to copy all pages in A to B to allow for pages in B to be written independently. Instead, copy-on-write makes page table entries in B’s virtual address space point to the corresponding page in A. When a process using B writes to a location, then a separate copy of the corresponding page in A is made for B, and the write is performed. Since we expect the number of pages that are written in B to be small compared to the total number of pages, this avoids unnecessary copying.
A simple networking example occurs when a network packet arrives to an endnode X in a different byte order than X’s native byte order. Rather than swap all bytes immediately, it can be more efficient to wait to swap the bytes that are actually read.
• P2c: Share Expenses. This refers to taking advantage of expensive operations done by other parts of the system. An important example of expense sharing is batching, where several expensive operations can be done together more cheaply than doing each separately. For example, Charlie bakes several pies in one batch. Computer systems have used batch processing for years, especially in the early days of mainframes, before time sharing. Batching trades latency for throughput. A simple networking example of expense sharing is timing wheels (Chapter 7), where the timer data structure shares expensive per-clock-tick processing with the routine that updates the time-of-day clock.
P3: RELAX SYSTEM REQUIREMENTS
When a system is first designed top-down, functions are partitioned among subsystems. After fixing subsystem requirements and interfaces, individual subsystems are designed. When implementation difficulties arise, the basic system structure may have to be redone, as shown in Figure 3.8.

As shown in Chapter 1, implementation difficulties (e.g., implementing a Divide) can sometimes be solved by relaxing the specification requirements for, say, Subsystem 1. This is shown in the figure by weakening the specification of Subsystem 1 from, say, S to W, but at the cost of making Subsystem 2 obey a stronger property, Q, compared to the previous property, P.
Three techniques that arise from this principle are distinguished by how they relax the original subsystem specification.
• P3a: Trade Certainty for Time. Systems designers can fool themselves into believing that their systems offer deterministic guarantees, when in fact we all depend on probabilities. For example, quantum mechanics tells us there is some probability that the atoms in your body will rearrange themselves to form a hockey puck, but this is clearly improbable.2 This opens the door to consider randomized strategies when deterministic algorithms are too slow.
In systems, randomization is used by millions of Ethernets worldwide to sort out packet-sending instants after collisions occur. A simple networking example of randomization is Cisco’s NetFlow traffic measurement software: If a router does not have enough processing power to count all arriving packets, it can count random samples and still be able to statistically identify large flows. A second networking example is stochastic fair queuing (Chapter 14), where, rather than keep track exactly of the networking conversations going through a router, conversations are tracked probabilistically using hashing.
• P3b: Trade Accuracy for Time. Similarly, numerical analysis cures us of the illusion that computers are perfectly accurate. Thus it can pay to relax accuracy requirements for speed. In systems, many image compression techniques, such as MPEG, rely on lossy compression using interpolation. Chapter 1 used approximate thresholds to replace divides by shifts. In networking, some packet-scheduling algorithms at routers (Chapter 14) require sorting packets by their departure deadlines; some proposals to reduce sorting overhead at high speeds suggest approximate sorting, which can slightly reduce quality-of-service bounds but reduce processing.
• P3c: Shift Computation in Space. Notice that all the examples given for this principle relaxed requirements: Sampling may miss some packets, and the transferred image may not be identical to the original image. However, other parts of the system (e.g., Subsystem 2 in Figure 3.8) have to adapt to these looser requirements. Thus we prefer to call the general idea of moving computation from one subsystem to another (“robbing Peter to pay Paul”) shifting computation in space. In networking, for example, the need for routers to fragment packets has recently been avoided by having end systems calculate a packet size that will pass all routers.
P4: LEVERAGE OFF SYSTEM COMPONENTS
A black-box view of system design is to decompose the system into subsystems and then to design each subsystem in isolation. While this top-down approach has a pleasing modularity, in practice performance-critical components are often constructed partially bottom-up. For example, algorithms are designed to fit the features offered by the hardware. Here are some techniques that fall under this principle.
• P4a: Exploit Locality. Chapter 2 showed that memory hardware offers efficiencies if related data is laid out contiguously — e.g., same sector for disks, or same DRAM page for DRAMs. Disk-search algorithms exploit this fact by using search trees of high radix, such as B-trees. IP-lookup algorithms (Chapter 11) use the same trick to reduce lookup times by placing several keys in a wide word, as did the example in Chapter 1.
• P4b: Trade Memory for Speed. The obvious technique is to use more memory, such as lookup tables, to save processing time. A less obvious technique is to compress a data structure to make it more likely to fit into cache, because cache accesses are cheaper than memory accesses. The Lulea IP-lookup algorithm described in Chapter 11 uses this idea by using sparse arrays that can still be looked up efficiently using space-efficient bitmaps.
• P4c: Exploit Hardware Features. Compilers use strength reduction to optimize away multiplications in loops; for example, in a loop where addresses are 4 bytes and the index i increases by 1 each time, instead of computing 4 * i, the compiler calculates the new array index as being 4 higher than its previous value. This exploits the fact that multiplies are more expensive than additions on many modern processors. Similarly, it pays to manipulate data in multiples of the machine word size, as we will see in the fast IP-checksum algorithms described in Chapter 9.
If this principle is carried too far, the modularity of the system will be in jeopardy. Two techniques alleviate this problem. First, if we exploit other system features only to improve performance, then changes to those system features can only affect performance and not correctness. Second, we use this technique only for system components that profiling has shown to be a bottleneck.
P5: ADD HARDWARE TO IMPROVE PERFORMANCE
When all else fails, goes the aphorism, use brute force. Adding new hardware,3 such as buying a faster processor, can be simpler and more cost effective than using clever techniques. Besides the brute-force approach of using faster infrastructure (e.g., faster processors, memory, buses, links), there are cleverer hardware–software trade-offs. Since hardware is less flexible and has higher design costs, it pays to add the minimum amount of hardware needed.
Thus, baking at the Greasy Spoon was sped up using microwave ovens. In computer systems, dramatic improvements each year in processor speeds and memory densities suggest doing key algorithms in software and upgrading to faster processors for speed increases. But computer systems abound with cleverer hardware–software trade-offs.
For example, in a multiprocessor system, if a processor wishes to write data, it must inform any “owners” of cached versions of the data. This interaction can be avoided if each processor has a piece of hardware that watches the bus for write transactions by other processors and automatically invalidates the cached location when necessary. This simple hardware snoopy cache controller allows the remainder of the cache-consistency algorithm to be efficiently performed in software.
Decomposing functions between hardware and software is an art in itself. Hardware offers several benefits. First, there is no time required to fetch instructions: Instructions are effectively hardcoded. Second, common computational sequences (which would require several instructions in software) can be done in a single hardware clock cycle. For example, finding the first bit set in, say, a 32-bit word may take several instructions on a RISC machine but can be computed by a simple priority encoder, as shown in the previous chapter.
Third, hardware allows you to explicitly take advantage of parallelism inherent in the problem. Finally, hardware manufactured in volume may be cheaper than a general-purpose processor. For example, a Pentium may cost $ 100 while an ASIC in volume with similar speeds may cost $10.
On the other hand, a software design is easily transported to the next generation of faster chips. Hardware, despite the use of programmable chips, is still less flexible. Despite this, with the advent of design tools such as VHDL synthesis packages, hardware design times have decreased considerably. Thus in the last few years chips performing fairly complex functions, such as image compression and IP lookups, have been designed.
Besides specific performance improvements, new technology can result in a complete paradigm shift. A visionary designer may completely redesign a system in anticipation of such trends. For example, the invention of the transistor and fast digital memories certainly enabled the use of digitized voice in the telephone network.
Increases in chip density have led computer architects to ponder what computational features to add to memories to alleviate the processor-memory bottleneck. In networks, the availability of high-speed links in the 1980s led to use of large addresses and large headers. Ironically, the emergence of laptops in the 1990s led to the use of low-bandwidth wireless links and to a renewed concern for header compression. Technology trends can seesaw!
The following specific hardware techniques are often used in networking ASICs and are worth mentioning. They were first described in Chapter 2 and are repeated here for convenience.
• P5a: Use Memory Interleaving and Pipelining. Similar techniques are used in IP lookup, in classification, and in scheduling algorithms that implement QoS. The multiple banks can be implemented using several external memories, a single external memory such as a RAMBUS, or on-chip SRAM within a chip that also contains processing logic.
• P5b: Use Wide Word Parallelism. A common theme in many networking designs, such as the Lucent bit vector scheme (Chapter 12), is to use wide memory words that can be processed in parallel. This can be implemented using DRAM and exploiting page mode or by using SRAM and making each memory word wider.
• P5c: Combine DRAM and SRAM. Given that SRAM is expensive and fast and that DRAM is cheap and slow, it makes sense to combine the two technologies to attempt to obtain the best of both worlds. While the use of SRAM as a cache for DRAM databases is classical, there are many more creative applications of the idea of a memory hierarchy. For instance, the exercises explore the effect of a small amount of SRAM on the design of the flow ID lookup chip. Chapter 16 describes a more unusual application of this technique to implement a large number of counters, where the low-order bits of each counter are stored in SRAM.
3.3.2 Principles for Modularity with Efficiency
An engineer who had read Dave Clark’s classic papers (e.g., Ref. Cla85) on the inefficiences of layered implementations once complained to a researcher about modularity. The researcher (Radia Perlman) replied, “But that’s how we got to the stage where we could complain about something.” Her point, of course, was that complex systems like network protocols could only have been engineered using layering and modularity. The following principles, culled from work by Clark and others, show how to regain efficiencies while retaining modularity.
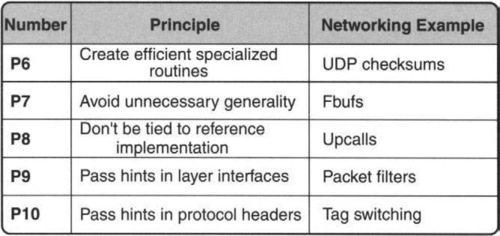
P6: CREATE EFFICIENT SPECIALIZED ROUTINES BY REPLACING INEFFICIENT GENERAL-PURPOSE ROUTINES
As in mathematics, the use of abstraction in computer system design can make systems compact, orthogonal, and modular. However, at times the one-size-fits-all aspect of a generalpurpose routine leads to inefficiencies. In important cases, it can pay to design an optimized and specialized routine.
A systems example can be found in database caches. Most general-purpose caching strategies would replace the least recently used record to disk. However, consider a query-processing routine processing a sequence of database tuples in a loop. In such a case, it is the most recently used record that will be used furthest in the future so it is the ideal candidate for replacement. Thus many database applications replace the operating system caching routines with more specialized routines. It is best to do such specialization only for key routines, to avoid code bloat. A networking example is the fast UDP processing routines that we describe in Chapter 9.
P7: AVOID UNNECESSARY GENERALITY
The tendency to design abstract and general subsystems can also lead to unnecessary or rarely used features. Thus, rather than building several specialized routines (e.g., P6) to replace the general-purpose routine, we might remove features to gain performance.4
Of course, as in the case of P3, removing features requires users of the routine to live with restrictions. For example, in RISC processors, the elimination of complex instructions such as multiplies required multiplication to be emulated by firmware. A networking example is provided by Fbufs (Chapter 5), which provide a specialized virtual memory service that allows efficient copying between virtual address spaces.
P8: DON’T BE TIED TO REFERENCE IMPLEMENTATIONS
Specifications are written for clarity, not to suggest efficient implementations. Because abstract specification languages are unpopular, many specifications use imperative languages such as C. Rather than precisely describe what function is to be computed, one gets code that prescribes how to compute the function. This has two side effects.
First, there is a strong tendency to overspecify. Second, many implementors copy the reference implementation in the specification, which is a problem when the reference implementation was chosen for conceptual clarity and not efficiency. As Clark [Cla85] points out, implementors are free to change the reference implementation as long as the two implementations have the same external effects. In fact, there may be other structured implementations that are efficient as well as modular.
For example, Charlie knows that when a recipe tells him to cut beans and then to cut carrots, he can interchange the two steps. In the systems world, Clark originally suggested the use of upcalls [Cla85] for operating systems. In an upcall, a lower layer can call an upper layer for data or advice, seemingly violating the rules of hierarchical decomposition introduced in the design of operating systems. Upcalls are commonly used today in network protocol implementations.
P9: PASS HINTS IN MODULE INTERFACES
A hint is information passed from a client to a service that, if correct, can avoid expensive computation by the service. The two key phrases are passed and if correct. By passing the hint in its request, a service can avoid the need for the associative lookup needed to access a cache. For example, a hint can be used to supply a direct index into the processing state at the receiver. Also, unlike caches, the hint is not guaranteed to be correct and hence must be checked against other certifiably correct information. Hints improve performance if the hint is correct most of the time.
This definition of a hint suggests a variant in which information is passed that is guaranteed to be correct and hence requires no checking. For want of an established term, we will call such information a tip. Tips are harder to use because of the need to ensure correctness of the tip.
As a systems example, the Alto File system [Lam89] has every file block on disk carry a pointer to the next file block. This pointer is treated as only a hint and is checked against the file name and block number stored in the block itself. If the hint is incorrect, the information can be reconstructed from disk. Incorrect hints must not jeopardize system correctness but result only in performance degradation.
P10: PASS HINTS IN PROTOCOL HEADERS
For distributed systems, the logical extension to Principle P9 is to pass information such as hints in message headers. Since this book deals with distributed systems, we will make this a separate principle. For example, computer architects have applied this principle to circumvent inefficiencies in message-passing parallel systems such as the Connection Machine.
One of the ideas in active messages (Chapter 5) is to have a message carry the address of the interrupt handler for fast dispatching. Another example is tag switching (Chapter 11), where packets carry additional indices besides the destination address to help the destination address to be looked up quickly. Tags are used as hints because tag consistency is not guaranteed; packets can be routed to the wrong destination, where they must be checked.
3.3.3 Principles for Speeding Up Routines
While the previous principles exploited system structure, we now consider principles for speeding up system routines considered in isolation.
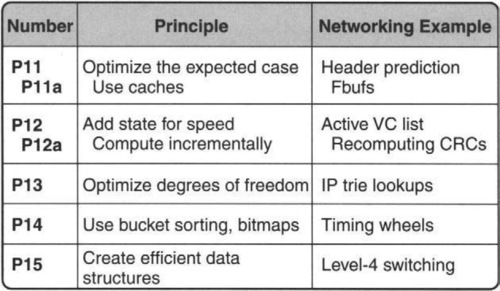
P11: OPTIMIZE THE EXPECTED CASE
While systems can exhibit a range of behaviors, the behaviors often fall into a smaller set called the “expected case” [HP96], For example, well-designed systems should mostly operate in a fault- and exception-free regime. A second example is a program that exhibits spatial locality by mostly accessing a small set of memory locations. Thus it pays to make common behaviors efficient, even at the cost of making uncommon behaviors more expensive.
Heuristics such as optimizing the expected case are often unsatisfying for theoreticians, who (naturally) prefer mechanisms whose benefit can be precisely quantified in an average or worst-case sense. In defense of this heuristic, note that every computer in existence optimizes the expected case (see Chapter 2) at least a million times a second.
For example, with the use of paging, the worst-case number of memory references to resolve a PC instruction that accesses memory can be as bad as four (read instruction from memory, read first-level page table, read second-level page table, fetch operand from memory). However, the number of memory accesses can be reduced to 0 using caches. In general, caches allow designers to use modular structures and indirection, with gains in flexibility, and yet regain performance in the expected case. Thus it is worth highlighting caching.
P11a: USE CACHES
Besides caching, there are subtler uses of the expected-case principle. For example, when you wish to change buffers in the EMACS editor, the editor offers you a default buffer name, which is the last buffer you examined. This saves typing time in the expected case when you keep moving between two buffers. The use of header prediction (Chapter 9) in networks is another example of optimizing the expected case: The cost of processing a packet can be greatly reduced by assuming that the next packet received is closely related to the last packet processed (for example, by being the next packet in sequence) and requires no exception processing.
Note that determining the common case is best done by measurements and by schemes that automatically learn the common case. However, it is often based on the designer’s intuition. Note that the expected case may be incorrect in special situations or may change with time.
P12: ADD OR EXPLOIT STATE TO GAIN SPEED
If an operation is expensive, consider maintaining additional but redundant state to speed up the operation. For example, Charlie keeps track of the tables that are busy so that he can optimize waiter assignments. This is not absolutely necessary, for he can always compute this information when needed by walking around the restaurant.
In database systems, a classic example is the use of secondary indices. Bank records may be stored and searched using a primary key, say, the customer Social Security number. However, if there are several queries that reference the customer name (e.g., “Find the balance of all Cleopatra’s accounts in the Thebes branch”), it may pay to maintain an additional index (e.g., a hash table or B-tree) on the customer name. Note that maintaining additional state implies the need to potentially modify this state whenever changes occur.
However, sometimes this principle can be used without adding state by exploiting existing state. We call this out as Principle P12a.
P12a: COMPUTE INCREMENTALLY
When a new customer comes in or leaves, Charlie increments the board on which he notes waiter assignments. As a second example, strength reduction in compilers (see example in P4c) incrementally computes the new loop index from the old using additions instead of computing the absolute index using multiplication. An example of incremental computation in networking is the incremental computation of IP checksums (Chapter 9) when only a few fields in the packet change.
P13: OPTIMIZE DEGREES OF FREEDOM
It helps to be aware of the variables that are under one’s control and the evaluation criteria used to determine good performance. Then the game becomes one of optimizing these variables to maximize performance. For example, Charlie first used to assign waiters to tables as they became free, but he realized he could improve waiter efficiency by assigning each waiter to a set of contiguous tables.
Similarly, compilers use coloring algorithms to do register assignment while minimizing register spills. A networking example of optimizing degrees of freedom is multibit trie IP lookup algorithms (Chapter 11). In this example, a degree of freedom that can be overlooked is that the number of bits used to index into a trie node can vary, depending on the path through the trie, as opposed to being fixed at each level. The number of bits used can also be optimized via dynamic programming (Chapter 11) to demand the smallest amount of memory for a given speed requirement.
P14: USE SPECIAL TECHNIQUES FOR FINITE UNIVERSES SUCH AS INTEGERS
When dealing with small universes, such as moderately sized integers, techniques like bucket sorting, array lookup, and bitmaps are often more efficient than general-purpose sorting and searching algorithms.
To translate a virtual address into a physical address, a processor first tries a cache called the TLB. If this fails, the processor must look up the page table. A prefix of the address bits is used to index into the page table directly. The use of table lookup avoids the use of hash tables or binary search, but it requires large page table sizes. A networking example of this technique is timing wheels (Chapter 7), where an efficient algorithm for a fixed timer range is constructed using a circular array.
P15: USE ALGORITHMIC TECHNIQUES TO CREATE EFFICIENT DATA STRUCTURES
Even where there are major bottlenecks, such as virtual address translation, systems designers finesse the need for clever algorithms by passing hints, using caches, and performing table lookup. Thus a major system designer is reported to have told an eager theoretician: “I don’t use algorithms, son.”
This book does not take this somewhat anti-intellectual position. Instead it contends that, in context, efficient algorithms can greatly improve system performance. In fact, a fair portion of the book will be spent describing such examples. However, there is a solid kernel of truth to the “I don’t use algorithms” putdown. In many cases, Principles P1 through P14 need to be applied before any algorithmic issues become bottlenecks.
Algorithmic approaches include the use of standard data structures as well as generic algorithmic techniques, such as divide-and-conquer and randomization. The algorithm designer must, however, be prepared to see his clever algorithm become obsolete because of changes in system structure and technology. As described in the introduction, the real breakthroughs may arise from applying algorithmic thinking as opposed to merely reusing existing algorithms.
Examples of the successful use of algorithms in computer systems are the Lempel–Ziv compression algorithm employed in the UNIX utility gzip, the Rabin–Miller primality test algorithm found in public key systems, and the common use of B-trees (due to Bayer–McCreight) in databases [CLR90]. Networking examples studied in this text include the Lulea IP-lookup algorithm (Chapter 11) and the RFC scheme for packet classification (Chapter 12).
3.4 DESIGN VERSUS IMPLEMENTATION PRINCIPLES
Now that we have listed the principles used in this book, three clarifications are needed. First, conscious use of general principles does not eliminate creativity and effort but instead channels them more efficiently. Second, the list of principles is necessarily incomplete and can probably be categorized in a different way; however, it is a good place to start.
Third, it is important to clarify the difference between system design and implementation principles. Systems designers have articulated principles for system design. Design principles include, for example, the use of hierarchies and aggregation for scaling (e.g., IP prefixes), adding a level of indirection for increased flexibility (e.g., mapping from domain names to IP addresses allows DNS servers to balance load between instances of a server), and virtualization of resources for increased user productivity (e.g., virtual memory).5
A nice compilation of design principles can be found in Lampson’s article [Lam89] and Keshav’s book [Kes97]. Besides design principles, both Lampson and Keshav include a few images directly? implementation principles (e.g., “use hints” and “optimize the expected case”). This book, by contrast, assumes that much of the network design is already given, and so we focus on principles for efficient protocol implementation. This book also adds several principles for efficient implementation not found in Keshav [Kes91] or Lampson [Lam89]
On the other hand, Bentley’s book on “efficient program design” [Ben82] is more about optimizing small code segments than the large systems that are our focus; thus many of Bentley’s principles (e.g., fuse loops, unroll loops, reorder tests) are meant to speed up critical loops rather than speed up systems as a whole.
3.5 CAVEATS
Performance problems cannot be solved only through the use of Zen meditation.
— PARAPHRASED FROM JEFF MOGUL, A COMPUTER SCIENTIST AT HP LABS
The best of principles must be balanced with wisdom to understand the important metrics, with profiling to determine bottlenecks, and with experimental measurements to confirm that the changes are really improvements. We start with two case studies to illustrate the need for caution.
Case Study 1: Reducing Page Download Times
Figure 3.9 shows that in order for a Web client to retrieve a Web page containing images, it must typically send a GET request for the page. If the page specifies inline images, then the client must send separate requests to retrieve the images before it can display the page. A natural application of principle P1 is to ask why separate requests are needed. Why can’t the Web server automatically download the images when the page is requested instead of waiting for a separate request? This should reduce page download latency by at least half a round-trip delay.
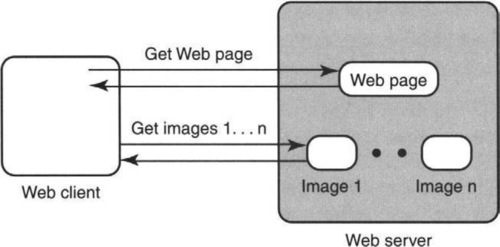
To test our hypothesis, we modified the server software to do so and measured the resulting performance. To our surprise, we found only minimal latency improvement. Using a network analyzer based on tcpdump, we found two reasons why this seeming improvement was a bad idea.
• Interaction with TCP: Web transfer is orchestrated by TCP as described in Chapter 2. To avoid network congestion, TCP increases its rate slowly, starting with one packet per round-trip, then to two packets per round-trip delay, increasing its rate when it gets acks. Since TCP had to wait for acks anyway to increase its rate, waiting for additional requests for images did not add latency.
• Interaction with Client Caching: Many clients already cache common images, such as .gif files. It is a waste of bandwidth to have the Web server unilaterally download images that the client already has in its cache. Note that having the client request the images avoids this problem because the client will only request images it does not already have.
A useful lesson from this case study is the difficulty of improving part of a system (e.g., image downloading) because of interactions with other parts of the system (e.g., TCP congestion control.)
3.5.1 Eight Cautionary Questions
In the spirit of the two case studies, here are eight cautionary questions that warn against injudicious use of the principles.
Q1: IS IT WORTH IMPROVING PERFORMANCE?
If one were to sell the system as a product, is performance a major selling strength? People interested in performance improvement would like to think so, but other aspects of a system, such as ease of use, functionality, and robustness, may be more important. For example, a user of a network management product cares more about features than performance. Thus, given limited resources and implementation complexity, we may choose to defer optimizations until needed. Even if performance is important, which performance metric (e.g., latency throughput, memory) is important?
Other things being equal, simplicity is best. Simple systems are easier to understand, debug, and maintain. On the other hand, the definition of simplicity changes with technology and time. Some amount of complexity is worthwhile for large performance gains. For example, years ago image compression algorithms such as MPEG were considered too complex to implement in software or hardware. However, with increasing chip densities, many MPEG chips have come to market.
Q2: IS THIS REALLY A BOTTLENECK?
The 80–20 rule suggests that a large percentage of the performance improvements comes from optimizing a small fraction of the system. A simple way to start is to identify key bottlenecks for the performance metrics we wish to optimize. One way to do so is to use profiling tools, as we did in Case Study 2.
Q3: WHAT IMPACT DOES THE CHANGE HAVE ON THE REST OF THE SYSTEM?
A simple change may speed up a portion of the system but may have complex and unforeseen effects on the rest of the system. This is illustrated by Case Study 1. A change that improves performance but has too many interactions should be reconsidered.
Q4: DOES THE INITIAL ANALYSIS INDICATE SIGNIFICANT IMPROVEMENT?
Before doing a complete implementation, a quick analysis can indicate how much gain is possible. Standard complexity analysis is useful. However, when nanoseconds are at stake, constant factors are important. For software and hardware, because memory accesses are a bottleneck, a reasonable first-pass estimate is the number of memory accesses.
For example, suppose analysis indicates that address lookup in a router is a bottleneck (e.g., because there are fast switches to make data transfer not a bottleneck). Suppose the standard algorithm takes an average of 15 memory accesses while a new algorithm indicates a worst case of 3 memory accesses. This suggests a factor of 5 improvement, which makes it interesting to proceed further.
Q5: IS IT WORTH ADDING CUSTOM HARDWARE?
With the continued improvement in the price–performance of general-purpose processors, it is tempting to implement algorithms in software and ride the price–performance curve. Thus if we are considering a piece of custom hardware that takes a year to design, and the resulting price–performance improvement is only a factor of 2, it may not be worth the effort. On the other hand, hardware design times are shrinking with the advent of effective synthesis tools. Volume manufacturing can also result in extremely small costs (compared to general-purpose processors) for a custom-designed chip. Having an edge for even a small period such as a year in a competitive market is attractive. This has led companies to increasingly place networking functions in silicon.
Q6: CAN PROTOCOL CHANGES BE AVOIDED?
Through the years there have been several proposals denouncing particular protocols as being inefficient and proposing alternative protocols designed for performance. For example, in the 1980s, the transport protocol TCP was considered “slow” and a protocol called XTP [Che89] was explicitly designed to be implemented in hardware. This stimulated research into making TCP fast, which culminated in Van Jacobson’s fast implementation of TCP [CJRS89] in the standard BSD release. More recently, proposals for protocol changes (e.g., tag and flow switching) to finesse the need for IP lookups have stimulated research into fast IP lookups.
Q7: DO PROTOTYPES CONFIRM THE INITIAL PROMISE?
Once we have successfully answered all the preceding questions, it is still a good idea to build a prototype or simulation and actually test to see if the improvement is real. This is because we are dealing with complex systems; the initial analysis rarely captures all effects encountered in practice. For example, understanding that the Web-image-dumping idea does not improve latency (see Case Study 1) might come only after a real implementation and tests with a network analyzer.
A major problem is finding a standard set of benchmarks to compare the standard and new implementations. For example, in the general systems world, despite some disagreement, there are standard benchmarks for floating point performance (e.g., Whetstone) or database performance (e.g., debit–credit). If one claims to reduce Web transfer latencies using differential encoding, what set of Web pages provides a reasonable benchmark to prove this contention? If one claims to have an IP lookup scheme with small storage, which benchmark databases can be used to support this assertion?
Q8: WILL PERFORMANCE GAINS BE LOST IF THE ENVIRONMENT CHANGES?
Sadly, the job is not quite over even if a prototype implementation is built and a benchmark shows that performance improvements are close to initial projections. The difficulty is that the improvement may be specific to the particular platform used (which can change) and may take advantage of properties of a certain benchmark (which may not reflect all environments in which the system will be used). The improvements may still be worthwhile, but some form of sensitivity analysis is still useful for the future.
For example, Van Jacobson performed a major optimization of the BSD networking code that allowed ordinary workstations to saturate 100-Mbps FDDI rings. The optimization, which we will study in detail in Chapter 9, assumes that in the normal case the next packet is from the same connection as the previous packet, P, and has sequence number one higher than P. Will this assumption hold for servers that have thousands of simultaneous connections to clients? Will it hold if packets get sent over parallel links in the network, resulting in packet reordering? Fortunately, the code has worked well in practice for a number of years. Despite this, such questions alert us to possible future dangers.
3.6 SUMMARY
This chapter introduced a set of principles for efficient system implementation. A summary can be found in Figures 3.1, 3.2, and 3.3. The principles were illustrated with examples drawn from compilers, architecture, databases, algorithms, and networks to show broad applicability to computer systems. Chef Charlie’s examples, while somewhat tongue in cheek, show that these principles also extend to general systems, from restaurants to state governments. While the broad focus is on performance, cost is an equally important metric. One can cast problems in the form of finding the fastest solution for a given cost. Optimization of other metrics, such as bandwidth, storage, and computation, can be subsumed under the cost metric.
A preview of well-known networking applications of the 15 principles can be found in Figures 3.1, 3.2, and 3.3. These applications will be explained in detail in later chapters. The first five principles encourage systems thinking. The next five principles encourage a fresh look at system modularity. The last five principles point to useful ways to speed up individual subsystems.
Just as chess strategies are boring until one plays a game of chess, implementation principles are lifeless without concrete examples. The reader is encouraged to try the following exercises, which provide more examples drawn from computer systems. The principles will be applied to networks in the rest of the book. In particular, the next chapter seeks to engage the reader by providing a set of 15 self-contained networking problems to play with.
3.7 EXERCISES
1. Batching, Disk Locality, and Logs: Most serious databases use log files for performance. Because writes to disk are expensive, it is cheaper to update only a memory image of a record. However, because a crash can occur any time, the update must also be recorded on disk. This can be done by directly updating the record location on disk, but random writes to disk are expensive (see P4a). Instead, information on the update is written to a sequential log file. The log entry contains the record location, the old value (undo information), and the new value (redo information).
• Suppose a disk page of 4000 bytes can be written using one disk I/O and that a log record is 50 bytes. If we apply batching (2c), what is a reasonable strategy for updating the log? What fraction of a disk I/O should be charged to a log update?
• Before a transaction that does the update can commit (i.e., tell the user it is done), it must be sure the log is written. Why? Explain why this leads to another form of batching, group commit, where multiple transactions are committed together.
• If the database represented by the log gets too far ahead of the database represented on disk, crash recovery can take too long. Describe a strategy to bound crash recovery times.
2. Relaxing Consistency Requirements in a Name Service: The Grapevine system [Be82] offers a combination of a name service (to translate user names to inboxes) and a mail service. To improve availability, Grapevine name servers are replicated. Thus any update to a registration record (e.g., Joe → MailSlot3) must be performed on all servers implementing replicas of that record. Standard database techniques for distributed databases require that each update be atomic; that is, the effect should be as if updates were done simultaneously on all replicas. Because atomic updates require that all servers be available, and registration information is not as important as, say, bank accounts, Grapevine provides only the following loose semantics (P3): All replicas will eventually agree if updates stop. Each update is timestamped and passed from one replica to the other in arbitrary order. The highest timestamped update wins.
• Give an example of how a user could detect inconsistency in Joe’s registration during the convergence process.
• If Joe’s record is deleted, it should eventually be purged from the database to save storage. Suppose a server purges Joe’s record immediately after receiving a Delete update. Why might Add updates possibly cause a problem? Suggest a solution.
• The rule that the latest timestamp wins does not work well when two administrators try to create an entry with the same name. Because a later creation could be trapped in a crashed server, the administrator of the earlier creation can never know for sure that his creation has won. The Grapevine designers did not introduce mechanisms to solve this problem but relied on “some human-level centralization of name creation.” Explain their assumption clearly.
3. Replacing General-Purpose Routines with Special-Purpose Routines and Efficient Storage Allocators: Consider the design of a general storage allocator that is given control of a large contiguous piece of memory and may be asked by applications for smaller, variable-size chunks. A general allocator is quite complex: As time goes by, the available memory fragments and time must be spent finding a piece of the requested size and coalescing adjacent released pieces into larger free blocks.
• Briefly sketch the design of a general-purpose allocator. Consult a textbook such as Horwitz and Sahni [HS78] for example allocators.
• Suppose a profile has shown that a large fraction of the applications ask for 64 bytes of storage. Describe a more efficient allocator that works for the special case (P6) of allocating just 64-byte quantities.
• How would you optimize the expected case (P11) and yet handle requests for storage other than 64 bytes?
4. Passing Information in Interfaces: Consider a file system that is reading or writing files from disk. Each random disk Read/Write involves positioning the disk over the correct track (seeking). If we have a sequence of say three Reads to Tracks 1, 15, and 7, it may pay to reorder the second and third Reads to reduce waste in terms of seek times. Clearly, as in P1, the larger the context of the optimization (e.g., the number of Reads or Writes considered for reordering), the greater the potential benefits of such seek optimization.
A normal file system only has an interface to open, read, and write a single file. However, suppose an application is reading multiple files and can pass that information (P9) in the file system call.
• What information about the pattern of file accesses would be useful for the file system to perform seek optimization? What should the interface look like?
• Give examples of applications that process multiple files and could benefit from this optimization. For more details, see the paper by H. Patterson et al. [Pe95]. They call this form of tip a disclosure.
5. Optimizing the Expected Case, Using Algorithmic Ideas, and Scavenging Files: The Alto computer used a scavenging system [Lam89] that scans the disk after a crash to reconstruct file system indexes that map from file names and blocks to disk sectors. This can be done because each disk sector that contains a file block also contains the corresponding file identifier. What complicates matters is that main memory is not large enough to hold information for every disk sector. Thus a single scan that builds a list in memory for each file will not work. Assume that the information for a single file will fit into memory. Thus a way that will work is to make a single scan of the disk for each file; but that would be obvious waste (P1) and too slow.
Instead, observe that in the expected case, most files are allocated contiguously. Thus suppose File X has pages 1–1000 located on disk sectors 301–1301. Thus the information about 1000 sectors can be compactly represented by three integers and a file name. Call this a run node.
• Assume the expected case holds and that all run nodes can fit in memory. Assume also that the file index for each file is an array (stored on disk) that maps from file block number to disk sector number. Show how to rebuild all the file indexes.
• Now suppose the expected case does not hold and that the run nodes do not all fit into memory. Describe a technique, based on the algorithmic idea of divide-and-conquer (P15), that is guaranteed to work (without reverting to the naive idea of building the index for one file at a time unless strictly necessary).