
So far, everything we've covered has been designed to work solely with in-memory data. From lists (Chapter 3) to hash tables (Chapter 11) and binary search trees (Chapter 10), all of the data structures and associated algorithms have assumed that the entire data set is held only in main memory, but what if the data exists on disk—as is the case with most databases? What if you wanted to search through a database for one record out of millions? In this chapter, you'll learn how to handle data that isn't stored in memory.
This chapter discusses the following topics:
Why the data structures you've learned so far are inadequate for dealing with data stored on disk
How B-Trees solve the problems associated with other data structures
How to implement a simple B-Tree-based map implementation
You've already seen how you can use binary search trees to build indexes as maps. It's not too much of a stretch to imagine reading and writing the binary tree to and from disk. The problem with this approach, however, is that when the number of records grows, so too does the size of the tree. Imagine a database table holding a million records and an index with keys of length ten. If each key in the index maps to a record in the table (stored as integers of length four), and each node in the tree references its parent and child nodes (again each of length four), this would mean reading and writing 1,000,000 × (10 + 4 + 4 + 4 + 4) = 1,000,000 × 26 = 26,000,000 or approximately 26 megabytes (MB) each time a change was made!
That's a lot of disk I/O and as you are probably aware, disk I/O is very expensive in terms of time. Compared to main memory, disk I/O is thousands, if not millions, of times slower. Even if you can achieve a data rate of 10MB/second, that's still a whopping 2.6 seconds to ensure that any updates to the index are saved to disk. For most real-world applications involving tens if not hundreds of concurrent users, 2.6 seconds is going to be unacceptable. One would hope that you could do a little better than that.
You already know that a binary search tree is composed of individual nodes, so maybe you could try reading and writing the nodes individually instead of all in one go. While this sounds like a good idea at first, in practice it turns out to be rather less than ideal. Recall that even in a perfectly balanced binary search tree, the average number of nodes traversed to find a search key will be O(log N). For our imaginary database containing a million records, this would therefore be log2 1,000,000 = 20. This is fine for in-memory operations for which the cost of accessing a node is very small, but not so great when it means performing 20 disk reads. Even though each node is quite small—in our example, only 26 or so bytes—data is stored on disks in much larger blocks, sometimes referred to as pages, so the cost of reading one node is no more or less expensive than reading, for example, 20 nodes. That's great, you say, you only need to read 20 nodes, so why not just read them all at once?
The problem is that given the way a binary search tree is built, especially if some kind of balancing is occurring, it's highly unlikely that related nodes will be located anywhere near each other, let alone in the same sector. Even worse, not only will you incur the cost of making the 20 or so disk reads, known as transfer time, but before each disk read is performed, the heads on the disks need to be repositioned, known as seek time, and the disks must be rotated into position, known as latency. All of this adds up. Even if you employed some sophisticated caching mechanisms in order to reduce the number of physical I/Os performed, the overall performance would still be unacceptable. You clearly need something better than this.
B-Trees are specifically designed for managing indexes on secondary storage such as hard disks, compact discs, and so on, providing efficient insert, delete, and search operations.
There are many variations on the standard B-Tree, including B+Trees, B×Trees, and so on. All are designed to solve other aspects of searching on external storage. However, each of these variations has its roots in the basic B-Tree. For more information on B-Trees and their variations, see [Cormen, 2001], [Sedgewick, 2002], and [Folk, 1991].
Like binary search trees, B-Trees contain nodes. Unlike binary search trees, however, the nodes of a B-Tree contain not one, but multiple, keys, up to some defined maximum—usually determined by the size of a disk block. The keys in a node are stored in sorted order, with an associated child node holding keys that sort lower than it—every nonleaf node containing k keys must have k+1 children.
Figure 15-1 shows a B-Tree holding the keys A through K. Each node holds at most three keys. In this example, the root node is only holding two keys—D and H—and has three children. The leftmost child holds all keys that sort lower than D. The middle child holds all keys that sort between D and H. The rightmost child holds all other keys greater than H.
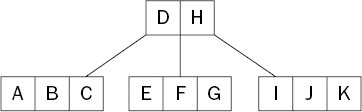
Looking for a key in a B-Tree is similar to looking for a key in a binary search tree, but each node contains multiple keys. Therefore, instead of making a choice between two children, a B-Tree search must make a choice between multiple children.
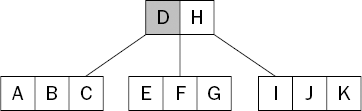
As an example, to search for the key G in the tree shown in Figure 15-1, you start at the root node. The search key, G, is first compared with D (see Figure 15-2).
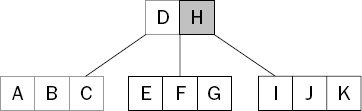
Because G sorts after D, the search continues to the next key, H (see Figure 15-3).
This time, the search key sorts before the current key in the node, so you follow the link to the left child (see Figure 15-4).
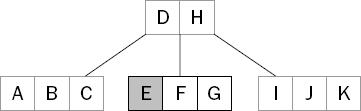
Figure 15.4. The search key falls below the current key so the search continues by following the left child link.
This continues until eventually you find the key for which you are searching (see Figure 15-5).
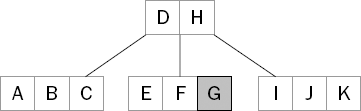
Even though the search performed five key comparisons, only two nodes were traversed in the process. Like a binary search tree, the number of nodes traversed is related to the height of the tree. However, because each node in a B-Tree contains multiple keys, the height of the tree remains much lower than in a comparable binary search tree, resulting in fewer node traversals and consequently fewer disk I/Os.
Going back to our original example, if we assume that our disk blocks hold 8,000 bytes each, this means that each node can contain around 8,000 / 26 = 300 or so keys. If you have a million keys, this translates into 1,000,000 / 300 = 3,333 nodes. You also know that, like a binary search tree, the height of a B-Tree is O(log N), where N is the number of nodes. Therefore, you can say that the number of nodes you would need to traverse to find any key would be in the order of log300 3,333 = 2. That's an order of magnitude better than the binary search tree.
To insert a key into a B-Tree, start at the root and search all the way down until you reach a leaf node. Once the appropriate leaf node has been found, the new value is inserted in order. Figure 15-6 shows the B-Tree from Figure 15-1 after the key L has been inserted.
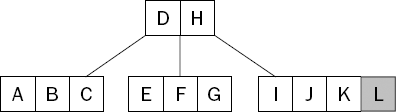
Notice that the node into which the new key was inserted has now exceeded the maximum allowed—the maximum number of keys allowed in this example was set at three. When a node becomes "full," it is split into two nodes, each containing half the keys from the original, as shown in Figure 15-7.
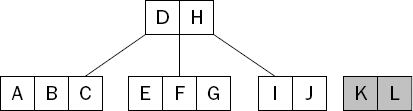
Next, the "middle" key from the original node is then moved up to the parent and inserted in order with a reference to the newly created node. In this case, the J is pushed up and added after the H in the parent node, and references the node containing the K and L, as shown in Figure 15-8.
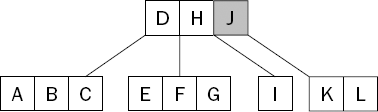
In this way, the tree spreads out, rather than increasing in height; B-Trees tend to be broader and shallower than most other tree structures, so the number of nodes traversed tends to be much smaller. In fact, the height of a B-Tree never increases until the root node becomes full and needs to be split.
Figure 15-9 shows the tree from Figure 15-8 after the keys M and N have been inserted. Once again, the node into which the keys have been added has become full, necessitating a split.
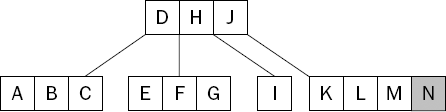
Once again, the node is split in two and the "middle" key—the L—is moved up to the root, as shown in Figure 15-10.
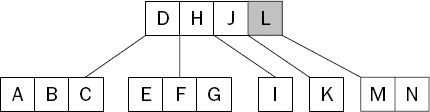
This time, however, the root node has also become full—it contains more than three keys—and therefore needs to be split. Splitting a node usually pushes one of the keys into the parent node, but of course in this case it's the root node and as such has no parent. Whenever the root node is split, a new node is created and becomes the new root.
Figure 15-11 shows the tree after the root node has been split and a new node is created above it, increasing the height of the tree. A new node containing the key H is created as the parent of the two nodes split from the original root node.
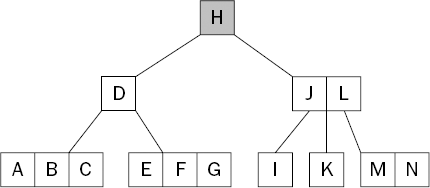
Deletion from a B-Tree is rather more complicated than both search and insert as it involves the merging of nodes. For example, Figure 15-12 shows the tree after deleting the key K from the tree shown in Figure 15-11. This is no longer a valid B-Tree because there is no longer a middle child (between the keys J and L). Recall that a nonleaf node with k keys must always have k+1 children.
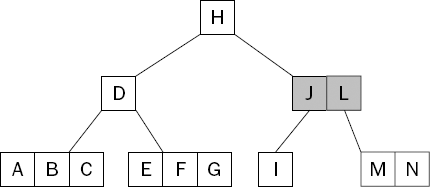
To correct the structure, it is necessary to redistribute some of the keys among the children—in this case, the key J is pushed down to the node containing the single key I, shown in Figure 15-13.
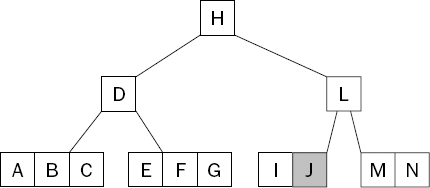
This is only the simplest situation. If, for example, the keys I and J were deleted, then the tree would look like the one shown in Figure 15-14.
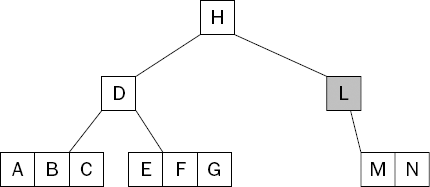
Again, a redistribution of keys is required to correct the imbalance in the tree. You can achieve this in several ways. No matter how the keys are redistributed, however, keys from parent nodes are merged with those of child nodes. At some point, the root node must be pulled down (or removed, for that matter). When this happens, the height of the tree is reduced by one.
For the purposes of this example, you'll merge the L into its child and pull down the root node, H, as the parent (see Figure 15-15).
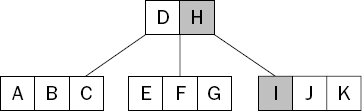
Figure 15.15. The height of the tree drops whenever the root node is either merged into a child or deleted completely.
As you can see, deletion is a rather complicated process and involves many different scenarios. (For a more in-depth explanation, refer to [Cormen, 2001].)
Now that you understand how B-Trees work and why they are useful, it's time to try your hand at implementing one. As mentioned earlier, B-Trees are usually used as indexes, so in this simple example you'll create an implementation of the Map interface from Chapter 13, based on a B-Tree. However, to avoid detracting from the underlying workings of the algorithms involved, the class you create will be purely in-memory, rather than on disk.
You'll implement all the methods from the Map interface using your understanding of B-Trees as the basis of the underlying data structure. To this end, you'll implement the get(), contains(), and set() methods based on the search and insertion algorithms discussed earlier. For the delete() method, however, you're going to cheat a little. Because the algorithm for deleting from a B-Tree is extremely complicated—involving at least three different scenarios requiring entries to be redistributed among nodes—rather than actually delete the entries, you'll instead simply mark them as deleted. While this does have the rather unfortunate side-effect that the B-Tree will never release any memory, it is sufficient for the purposes of this example. For a more detailed explanation of B-Tree deletion, see [Cormen, 2001].
In the next Try It Out section, you create the tests to ensure that your B-Tree map implementation works correctly.
You already developed the test cases in Chapter 13, so all you needed to do was extend AbstractMapTestCase. The only other thing you need to do is implement the method createMap() and return an instance of the BTreeMap class. The BTreeMap constructor takes two parameters: a comparator for ordering the keys and the maximum number of keys per node. In this case, you force the number of keys per node to be as small as possible, ensuring the maximum number of nodes possible. Although this would seem to defeat the purpose of a B-Tree—the whole point being to keep the height and number of nodes as small as possible—by doing so in the test, you'll ensure that all the special cases, such as leaf-node and root-node splitting, are exercised.
Tests in place, in the next Try It Out section you create the actual B-Tree map implementation.
The BTreeMap class holds a comparator to use for ordering the keys, the maximum number of keys per node, the root node, and the number of entries in the map. Notice that the minimum number of keys allowed per node is two. Because a node is split, there needs to be at least one key in the left child, one in the right, and one to move into the parent node. If the minimum number of keys was set at one, a node would be considered full with only two keys and therefore there would be too few to perform a split:
package com.wrox.algorithms.btrees; import com.wrox.algorithms.iteration.Iterator; import com.wrox.algorithms.lists.ArrayList; import com.wrox.algorithms.lists.EmptyList; import com.wrox.algorithms.lists.List; import com.wrox.algorithms.maps.DefaultEntry; import com.wrox.algorithms.maps.Map;
import com.wrox.algorithms.sorting.Comparator;
public class BTreeMap implements Map {
private static final int MIN_KEYS_PER_NODE = 2;
private final Comparator _comparator;
private final int _maxKeysPerNode;
private Node _root;
private int _size;
public BTreeMap(Comparator comparator, int maxKeysPerNode) {
assert comparator != null : "comparator can't be null";
assert maxKeysPerNode >= MIN_KEYS_PER_NODE : "maxKeysPerNode can't be < "
+ MIN_KEYS_PER_NODE;
_comparator = comparator;
_maxKeysPerNode = maxKeysPerNode;
clear();
}
...
}There are also two inner classes—Entry and Node—that represent a Map.Entry and a B-Tree node, respectively.
In addition to extending DefaultEntry, the Entry inner class also holds a Boolean flag indicating whether it has been deleted or not. This flag can be switched on and off as appropriate and is used for deleting entries:
private static final class Entry extends DefaultEntry {
private boolean _deleted;
public Entry(Object key, Object value) {
super(key, value);
}
public boolean isDeleted() {
return _deleted;
}
public void setDeleted(boolean deleted) {
_deleted = deleted;
}
}The Node inner class is where most of the work is performed, so we'll discuss this class first, before the methods on the main BTreeMap class.
Each node is constructed with a Boolean to indicate whether it is to be a leaf node or not. Recall that leaf nodes have no children, which is reflected in the constructor: If the node is a leaf, the list of children is set to the empty list; otherwise, a new array list is allocated to hold the children. This is reflected in the method isLeaf(), which is used to determine whether a node is a leaf or not. In addition, there is a method, isFull(), for determining whether a node contains more than the maximum allowable number of keys:
private final class Node {
private final List _entries = new ArrayList();
private final List _children;
public Node(boolean leaf) {
_children = !leaf ? new ArrayList() : (List) EmptyList.INSTANCE;
}
public boolean isFull() {
return _entries.size() > _maxKeysPerNode;
}
private boolean isLeaf() {
return _children == EmptyList.INSTANCE;
}
...
}The first thing you need is a method for searching the entries to find a key. The indexOf() method performs a simple linear search of the entries to find a matching key. If found, the position within the list (0, 1, 2, . . .) is returned; otherwise, a negative index is returned to indicate where the key would have been, had it existed. (If you're interested in a more in-depth discussion of how linear searching works, refer to Chapter 9, as the code is identical to the search() method of LinearListSearcher except that it first retrieves the key from the entry before calling compare().)
private int indexOf(Object key) {
int index = 0;
Iterator i = _entries.iterator();
for (i.first(); !i.isDone(); i.next()) {
int cmp = _comparator.compare(key, ((Entry) i.current()).getKey());
if (cmp == 0) {
return index;
} else if (cmp < 0) {
break;
}
++index;
}
return -(index + 1);
}Now that you can find a key within a node, searching through the nodes to find an entry is fairly straightforward.
The search() method first searches for a matching key. If one is found (index >= 0), it is returned immediately. Otherwise, if the node is not a leaf, the search continues recursively in the appropriate child; otherwise, it terminates without finding a matching entry—leaf nodes have no children. Notice that the search() method ignores entries that are marked as deleted. This is an important point to remember later:
public Entry search(Object key) {
int index = indexOf(key);
if (index >= 0) {
Entry entry = (Entry) _entries.get(index);
return !entry.isDeleted() ? entry : null;
}
return !isLeaf() ? ((Node) _children.get(-(index + 1))).search(key)
: null;
}Next, you want to be able to insert keys into a node, but before doing so, it will be necessary to implement some code to split a node.
The split() method takes a reference to the parent node and a position into which the newly created node will be inserted. The first thing split() does is create a new node as its sibling—hence, the leaf flag is also copied (a sibling of a leaf is also a leaf). Next, all the entries and children from the midpoint on are moved from the node into the sibling. Then, the middle entry is inserted into the parent, followed by the reference to the sibling. A reference to the node being split is only ever inserted into the parent when the parent is a newly created root node, i.e., it has no children:
public void split(Node parent, int insertionPoint) {
assert parent != null : "parent can't be null";
Node sibling = new Node(isLeaf());
int middle = _entries.size() / 2;
move(_entries, middle + 1, sibling._entries);
move(_children, middle + 1, sibling._children);
parent._entries.insert(insertionPoint, _entries.delete(middle));
if (parent._children.isEmpty()) {
parent._children.insert(insertionPoint, this);
}
parent._children.insert(insertionPoint + 1, sibling);
}
private void move(List source, int from, List target) {
assert source != null : "source can't be null";
assert target != null : "target can't be null";
while (from < source.size()) {
target.add(source.delete(from));
}
}Now that you can split a node, you can go about adding new entries, remembering that a map guarantees uniqueness of keys. For this reason, entries are not always inserted. Instead, if an entry with a matching key already exists, the associated value is updated.
The first set() method starts by obtaining the position to the key within the node. If the key was found (index >= 0), the corresponding entry is retrieved, the value updated, and the old value returned. If the key wasn't found, then it might need to be inserted, but then again it might also exist within a child node. This logic is handled by the second set() method.
The second set() method first determines whether the node is a leaf. If it is, then the key doesn't exist anywhere in the tree and is therefore inserted along with the value as a new entry, and the size of the map is incremented accordingly. If the node has children, however, the appropriate child is found and a recursive call is made to the first set() method. In this case, if after insertion the child becomes full, it will need to be split:
public Object set(Object key, Object value) {
int index = indexOf(key);
if (index >= 0) {
return ((Entry) _entries.get(index)).setValue(value);
}
return set(key, value, -(index + 1));
}
private Object set(Object key, Object value, int index) {
if (isLeaf()) {
_entries.insert(index, new Entry(key, value));
++_size;
return null;
}
Node child = ((Node) _children.get(index));
Object oldValue = child.set(key, value);
if (child.isFull()) {
child.split(this, index);
}
return oldValue;
}The only other method on the node—traverse()—is used for iteration. This method adds all the entries in the tree into a list. It starts by adding all nondeleted entries in the current node. It then recursively calls each of its children to do the same. This is essentially a pre-order traversal (it is also possible to implement an in-order traversal, an exercise left to the reader):
public void traverse(List list) {
assert list != null : "list can't be null";
Iterator entries = _entries.iterator();
for (entries.first(); !entries.isDone(); entries.next()) {
Entry entry = (Entry) entries.current();
if (!entry.isDeleted()) {
list.add(entry);
}
}
Iterator children = _children.iterator();for (children.first(); !children.isDone(); children.next()) {
((Node) children.current()).traverse(list);
}
}Now that you've covered the Node inner class, you can proceed to the remaining BTreeMap methods required by the Map interface.
The get() method returns the value associated with a key. The search() method of the root node is called with the specified key. If an entry is found, the associated value is returned; otherwise, null is returned to indicate that the key doesn't exist in the tree:
public Object get(Object key) {
Entry entry = _root.search(key);
return entry != null ? entry.getValue() : null;
}The contains() method determines whether a key exists within the tree. Again, the search() method is called on the root node and true is returned if an entry is found:
public boolean contains(Object key) {
return _root.search(key) != null;
}The set() method adds or updates the value associated with a specified key. Here, the set() method on the root node is called to do most of the work. After the method returns, the root node is checked to determine whether it is now full. If so, a new root node is created and the existing one is split. If not, no special handling is required. In either case, the old value associated with the key (if any) is returned to the caller as required by the Map interface:
public Object set(Object key, Object value) {
Object oldValue = _root.set(key, value);
if (_root.isFull()) {
Node newRoot = new Node(false);
_root.split(newRoot, 0);
_root = newRoot;
}
return oldValue;
}The delete() method removes a specified key—and its associated value—from the map. Again, the search() method is called on the root node to find the entry for the specified key. If no entry is found, then null is returned to indicate that the key didn't exist. Otherwise, the entry is marked as deleted, the size of the map is decremented accordingly, and the associated value is returned to the caller:
public Object delete(Object key) {
Entry entry = _root.search(key);
if (entry == null) {
return null;
}
entry.setDeleted(true);−−_size;
return entry.setValue(null);
}The iterator() method returns an iterator over all the entries in the map, in no particular order. The traverse() method on the root node is called, passing in a list to populate with all the entries in the tree, from which an iterator is returned and passed back to the caller:
public Iterator iterator() {
List list = new ArrayList(_size);
_root.traverse(list);
return list.iterator();
}The clear() method removes all entries from the map. To empty the tree, the root node is set to a leaf node—as it has no children—and the size is reset to 0:
public void clear() {
_root = new Node(true);
_size = 0;
}Finally, the size() and isEmpty() methods complete the interface:
public int size() {
return _size;
}
public boolean isEmpty() {
return size() == 0;
}The implementation you've just created only works in memory. Creating a version that can be saved to and restored from some external medium such as a hard disk requires a little work, but it's relatively straightforward. See [Cormen, 2001] for more information.
This chapter demonstrated the following key points:
B-Trees are ideally suited for searching on external storage such as hard disks, compact discs, and so on.
B-Trees grow from the leaves up.
Each nonroot node is always at least half full.
Nodes split whenever they become "full."
When a node splits, one of the keys is pushed up into the parent.
The height of a B-Tree only increases when the root node splits.
B-Trees remain "balanced," guaranteeing
O(log N)search times.