
Chapter 14
Other Numerical Variable Types
In This Chapter
![]() Reviewing the limitations of integers
Reviewing the limitations of integers
![]() Introducing real numbers to C++
Introducing real numbers to C++
![]() Examining the limitations of real numbers
Examining the limitations of real numbers
![]() Looking at some variable types in C++
Looking at some variable types in C++
![]() Overloading function names
Overloading function names
The programs so far have limited themselves to variables of type int with just a few chars thrown in. Integers are great for most calculations — more than 90 percent of all variables in C++ are of type int. Unfortunately, int variables aren’t adapted to every problem. In this chapter, you see both variations of the basic int as well as other types of intrinsic variables. An intrinsic type is one that’s built into the language. In Chapter 19, you see how the programmer can define her own variable types.
 Some programming languages allow you to store different types of data in the same variable. These are called weakly typed languages. C++, by contrast, is a strongly typed language — it requires you to declare the type of data the variable is to store. A variable, once declared, cannot change its type.
Some programming languages allow you to store different types of data in the same variable. These are called weakly typed languages. C++, by contrast, is a strongly typed language — it requires you to declare the type of data the variable is to store. A variable, once declared, cannot change its type.
The Limitations of Integers in C++
The int variable type is the C++ version of an integer. As such, int variables suffer the same limitations as their counting integer equivalents in mathematics do.
Integer round-off
It isn’t that an integer expression can’t result in a fractional value. It’s just that an int has no way of storing the fractional piece. The processor lops off the part to the right of the decimal point before storing the result. (This lopping off of the fractional part of a number is called truncation.)
Consider the problem of calculating the average of three numbers. Given three int variables — nValue1, nValue2, and nValue3 — their average is given by the following expression:
int nAverage = (nValue1 + nValue2 + nValue3)/3;
Suppose that nValue1 equals 1, nValue2 equals 2, and nValue3 equals 2 — the sum of this expression is 5. This means that the average is 5 /3 or either 1 2/3 or 1.666, depending upon your personal preference. But that’s not using integer math.
Because all three variables are integers, the sum is assumed to be an integer as well. And because 3 is also an integer, you guessed it, the entire expression is taken to be an integer. Thus, given the same values of 1, 2, and 2, C++ will calculate the unreasonable-but-logical result of 1 for the value of nAverage.
The problem is much worse in the following mathematically equivalent formulation:
int nAverage = nValue1/3 + nValue2/3 + nValue3/3;
Plugging in the same values of 1, 2, and 2, the resulting value of nAverage is now 0 (talk about logical-but-unreasonable, there it is). To see how this can occur, consider that 1/2 truncates to 0, 2/3 truncates to 0, and 2/3 truncates to 0. The sum of 0, 0, and 0 is (surprise!) 0.
You can see that there are times when integer truncation is completely unacceptable.
Limited range
A second problem with the int variable type is its limited range. A normal int can store a maximum value of 2,147,483,647 and a minimum value of −2,147,483,648 — that’s roughly from positive 2 billion to negative 2 billion — for a total range of 4 billion.
 That’s on a modern PC, Mac, or other common processor. If you have a much older machine, the int may not be nearly so expansive in its range. I will have a little more to say about that later in this chapter.
That’s on a modern PC, Mac, or other common processor. If you have a much older machine, the int may not be nearly so expansive in its range. I will have a little more to say about that later in this chapter.
Two billion is a very large number — plenty big enough for most applications. That’s why the int is useful. But it’s not large enough for some applications, including computer technology. In fact, your computer probably executes faster than 2 GHz (gigahertz) (2 GHz is two billion cycles per second). A single strand of fiber cable (the kind that’s strung back and forth from one side of the country to the other) can carry way more than 2 billion bits per second. (I won’t even start on the number of stars in the Milky Way.)
A Type That “doubles” as a Real Number
The limitations of the int variable are unacceptable in some applications. Fortunately, C++ understands decimal numbers that have a fractional part. (Mathematicians call these real numbers.) In C++, decimal numbers are called floating-point numbers or simply floats. This is because the decimal point can float around from left to right to handle fractional values.
Floating-point variables come in two basic flavors in C++. The small variety is declared by using the keyword float as follows:
float fValue1; // declare a floating point
float fValue2 = 1.5; // initialize it at declaration
Oddly enough, the standard floating-point variable in C++ is its larger sibling, the double-precision floating point or simply double. You declare a double-precision floating point as follows:
double dValue1;
double dValue2 = 1.5;
 Because the native floating-point type for C++ is the double, I generally avoid using float. The float does take up less memory, but this is not an issue for most applications. I stick with double for the remainder of this book. In addition, when I say “floating-point variable,” you can assume that I’m talking about a variable of type double.
Because the native floating-point type for C++ is the double, I generally avoid using float. The float does take up less memory, but this is not an issue for most applications. I stick with double for the remainder of this book. In addition, when I say “floating-point variable,” you can assume that I’m talking about a variable of type double.
Solving the truncation problem
To see how the double fixes our truncation problem, consider the average of three floating-point variables dValue1, dValue2, and dValue3 given by the formula
double dAverage = dValue1/3.0 + dValue2/3.0 + dValue3/3.0;
Assume, once again, the initial values of 1.0, 2.0, and 2.0. This renders the expression just given here as equivalent to
double dAverage = 1.0/3.0 + 2.0/3.0 + 2.0/3.0;
which is, in turn, equivalent to
double dAverage = 0.333... + 0.6666... + 0.6666...;
resulting in a final value of
double dAverage = 1.666...;
I have written the preceding expressions as though there were an infinite number of sixes after the decimal point. In fact, this isn’t the case. The accuracy of a double is limited to about 14 significant digits. The difference between 1.666666666666 and 1 2/3 is small, but not zero. I have more to say about this a little later in this chapter.
When an integer is not an integer
C++ assumes that a number followed by a decimal point is a floating-point constant. Thus it assumes that 2.5 is a floating point. This decimal-point rule is true even if the value to the right of the decimal point is zero. Thus 3.0 is also a floating point. The distinction between 3 and 3.0 looks small to you and me, but not to C++.
Actually, you don’t have to put anything to the right of the decimal point. Thus C++ also sees 3. as a double. However, it’s considered good style to include the 0 after the decimal point for all floating-point constants.
Computer geeks will be interested to know that the internal representations of 3 and 3.0 are totally different (yawn). More importantly, the constant int 3 is subject to int rules, whereas 3.0 is subject to the rules of floating-point arithmetic.
Thus you should try to avoid expressions like the following:
double dValue = 1.0;
double dOneThird = dValue/3;
Technically this is what is known as a mixed-mode expression because dValue is a double but 3 is an int. Okay, C++ is not a total idiot — it knows what you want in a case like this, so it converts the 3 to a double and performs floating-point arithmetic.
There’s a name for this bit of magic: We say that C++ promotes the int 3 to a double.
C++ also allows you to assign a floating-point result to an int variable:
int nValue = dValue / 3.0;
Assigning a double to an int is known as a demotion.
Some C++ compilers generate a warning when promoting a variable, but Code::Blocks/gcc does not. All C++ compilers generate a warning (or error) when demoting a result due to the loss of precision.
You should get in the habit of avoiding mixed-mode arithmetic. If you have to change the type of an expression, do it explicitly by using a cast, as in the following example:
void fn(int nArg)
{
// calculate one third of nArg; use a cast to
// promote it to a floating point
double dOneThird = (double)nArg / 3.0;
// ...function continues on
I am using the naming convention of starting double-precision double variables with the letter d. That is merely a convention. You can name your variables any way you like — C++ doesn’t care.
Discovering the limits of double
Floating-point variables come with their own limitations. They cannot be used to count things, they take longer to process, they consume more memory, and they also suffer from round-off error (though not nearly as bad as int). Now to consider each one of these problems in turn.
Counting
You can’t use a floating-point variable in an application where counting is important. In C++, you can’t say that there are 7.0 characters in my first name. Operators involved in counting don’t work on floating-point variables. In particular, the auto-increment (++) and auto-decrement (- -) operators are strictly verboten on double.
Calculation speed
Computers can perform integer arithmetic faster than they can do floating-point arithmetic. Fortunately, floating-point processors have been built into CPUs for many years now, so the difference in performance is not nearly as significant as it once was. I wrote the following loop just as a simple example, first using integer arithmetic:
int nValue1 = 1, nValue2 = 2, nValue3 = 2;
for (int i = 0; i < 1000000000; i++)
{
int nAverage = (nValue1 + nValue2 + nValue3) / 3;
}
This loop took about 5 seconds to execute on my laptop. I then executed the same loop in floating-point arithmetic:
double dValue1 = 1, dValue2 = 2, dValue3 = 2;
for (int i = 0; i < 1000000000; i++)
{
double dAverage = (dValue1 + dValue2 + dValue3) / 3.0;
}
This look took about 21 seconds to execute on the same laptop. Calculating an average 1 billion times in a little over 20 seconds ain’t shabby, but it’s still four times slower than the processing time for its integer equivalent.
Consume more memory
Table 14-2 shows the amount of memory consumed by a single variable of each type. On a PC or Macintosh, an int consumes 4 bytes, whereas a double takes up 8 bytes. That doesn’t sound like much — and, in fact, it isn’t — but if you had a few million of these things to keep in memory … well, it still wouldn’t be much. But if you had a few hundred million, then the difference would be considerable.
This is another way of saying that unless you need to store a heck of a lot of objects, don’t worry about the difference in memory taken by one type versus another. Instead, pick the variable type that meets your needs.
If you do just happen to be programming an application that needs (say) to manipulate the age of every human being on the planet at the same time, then you may want to lean toward the smaller int (or one of the other integer types I discuss in this chapter) because it consumes lessmemory. (Do you do that sort of thing often?)
Loss of accuracy
A double variable has about 16 significant digits of accuracy. Consider that a mathematician would express the number 1/3 as 0.333..., where the ellipses indicate that the threes go on forever. The concept of an infinite series makes sense in mathematics, but not in computing. A computer only has a finite amount of memory and a finite amount of accuracy. Therefore it has to round off, which results in a tiny (but real) error.
C++ can correct for round-off error in a lot of cases. For example, on output if a variable is 0.99999999999999, C++ will just assume that it’s really 1.0 and display it accordingly. However, C++ can’t correct for all floating-point round-off errors, so you need to be careful. For example, you can’t be sure that 1/3 + 1/3 + 1/3 is equal to 1.0:
double d1 = 23.0;
double d2 = d1 / 7.0;
if (d1 == (d2 * 7.0))
{
cout << "Did we get here?" << endl;
}
You might think that this code snippet would always display the "Did we get here?" string, but surprisingly it does not. The problem is that 23 divided by 7 cannot be expressed exactly in a floating-point number. Something is lost. Thus d2 * 7 is very close to 23, but is not exactly equal.
Rather than looking for exact equality between two floating-point numbers, you should be asking, “Is d2 * 7 vanishingly close to d1 in value?” You can do that as follows:
double d1 = 23.0;
double d2 = d1 / 7.0;
// Is d2 * 7.0 within delta of d1?
double difference = (d2 * 7.0) - d1;
double delta = 0.00001;
if (difference < delta && difference > -delta)
{
cout << "Did we get here?" << endl;
}
This code snippet calculates the difference between d1 and d2 * 7.0. If this difference is less than some small delta, the code calls it a day and says that d1 and d2 * 7 are essentially equal.
Not-so-limited range
The largest number that a double can store is roughly 10 to the 38th power. That’s a 1 with 38 zeroes after it; that eats the puny 2 billion maximum size for an int for breakfast. That’s even more than the national debt (at least, at the time of this writing). I’m almost embarrassed to call this a limit, but I suppose there are applications where 38 zeroes aren’t enough.
Remember that only the first 16 digits are significant. The remaining 22 digits are noise, having already succumbed to standard floating-point round-off error.
Variable Size — the “long” and “short” of It
C++ allows you to expand on integer variable types by adding the following descriptors on the front: const, unsigned, short, or else long. Thus you could declare something like the following:
unsigned long int ulnVariable;
A const variable cannot be modified. All numbers are implicitly const. Thus, 3 is of type const int, while 3.0 is a const double, and ‘3’ is a const char.
An unsigned variable can take on non-negative values only; however, it can handle a number roughly twice as large as its signed sibling. Thus an unsigned int has a range of 0 to 4 billion (as opposed to the regular signed int’s range of −2 billion to 2 billion).
C++ allows you to declare a short int and a long int. For example, a short int takes less space but has a more limited range than a regular int, whereas a long int takes more storage and has a significantly larger range.
The int is assumed. Thus the following two declarations are both accepted and completely equivalent:
long int lnVar1; // declare a long int
long lnVar2; // also a long int; int is assumed
 The C++ 2011 Standard even defines a long long int and a long double. These are just like long int and double, respectively, only more so — more accuracy and larger range.
The C++ 2011 Standard even defines a long long int and a long double. These are just like long int and double, respectively, only more so — more accuracy and larger range.
Not all combinations are allowed. For example, unsigned can be applied only to the counting types int and char. Table 14-1 shows the legal combinations and their meaning, along with how to declare a constant of that type.
Table 14-1 The Common C++ Variable Types
|
Type |
Declaring a Constant |
What It Is |
|
int |
1 |
A simple counting number, either positive or negative. |
|
unsigned int |
1U |
A non-negative counting number. |
|
short int |
--- |
A potentially smaller version of the int. It uses less memory but has a more limited range. |
|
long int |
1L |
A potentially larger version of the int. It may use more memory but has a larger range. There is no difference between long and int on the Code::Blocks/gcc compiler. |
|
long long int |
1LL |
A version of the int that is potentially even larger. |
|
float |
1.0F |
A single-precision real number. |
|
double |
1.0 |
A double-precision real number. |
|
long double |
--- |
A potentially larger floating-point number. On the PC, long double is the native size for numbers internal to the numeric processor. |
|
char |
‘c’ |
A single char variable stores a single character. Not suitable for arithmetic. |
|
wchar_t |
L’c’ |
A wide character. Used to store larger character sets such as Chinese ideograms and Japanese kanji symbols. Also known as UTF or Unicode. |
How far do numbers range?
It may seem odd, but the C++ standard doesn’t actually say exactly how big a number each data type can accommodate. The standard addresses only the relative size of each variable type. For example, it says that the maximum long int is at least as large as the maximum int. (The 2011 standard says a little bit more than that — for example, a long int must be at least 32 bits — but it still doesn’t specify the size of every variable type.)
The authors of C++ weren’t trying to be mysterious. They wanted to allow the compiler to implement the absolute fastest code possible for the base machine. The standard was designed to work for all different types of processors, running different operating systems.
In fact, the standard size of an int has changed over the past decades. Before 2000, the standard int on most PCs was 2 bytes and had a range of plus or minus 64,000. Some time around 2000, the basic word size on the Intel processors changed to 32 bits. Most compilers changed to the default int of today — it’s 4 bytes and has a range of plus or minus 2 billion.
Table 14-2 provides the size and range of each variable type on the Code::Blocks/gcc compiler (and most other compilers meant for an Intel processor running on a 32-bit operating system).
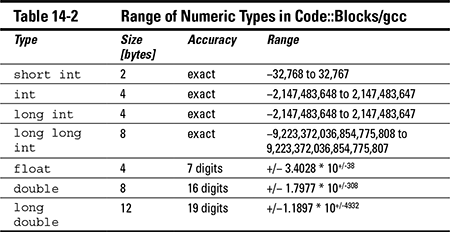
Attempting to calculate a number that is beyond the range of a variable’s type is known as an overflow. The C++ standard generally leaves the results of an overflow undefined. That’s another way that the inventors of C++ wanted to leave the language flexible so that the machine code generated would be as fast as possible.
On the PC, a floating-point overflow generates an exception that, if not handled, will cause your program to crash. (For more about exception handling, refer to Chapter 32.) As bad as that sounds, an integer overflow is even worse — C++ generates an incorrect result without complaint.
Types of Constants
Here’s where the const declaration (mentioned earlier in this chapter and again in Table 14-1) rears its head again. I’d like to take a minute to expand upon constants.
A constant value is an explicit number or character such as 1 or 0.5 or ‘c’.
- Constant values cannot be changed; that is, they cannot appear on the left-hand side of an assignment statement.
- Every constant value has a type. The type of 1 is const int. The type of 0.5 is const double.
Table 14-1 explains how to declare constant values with different types. For example, 1L is of type const long.
A variable can be declared constant using the const keyword:
const double PI = 3.14159; // declare a constant variable
A const variable must be initialized when it is declared since you will not get another chance in the future — just like a constant value, a const variable cannot appear on the left-hand side of an assignment statement.
It is common practice to declare const variables using all capitals. Multiple words within a variable name are divided by an underscore as in TWO_PI. As always, this is just convention — C++ doesn’t care.
It may seem odd to declare a variable and then say that it can’t be changed. Why bother? Largely because a carefully named constant can make a program a lot easier to understand. Consider the following two equivalent expressions:
double dC = 6.28318 * dR; // what does this mean?
double dCircumference = TWO_PI * dRadius; // this is a lot
// easier to understand
It should be a lot clearer to the reader of this code that the second expression is multiplying the radius by 2π to calculate the circumference.
The 2011 C++ standard allows you to specify the type of a variable from the type of the initialization value. To do this, declare the variable with the keyword auto rather than with a type:
long function();
auto nIntVar = 1;
auto lLongVar = function();
auto dVar = 1.0;
Here the variable nIntVar is declared to be an int because 1 is an int. Similarly, lLongVar is a long because function() is declared as returned a long.
Notice that the type of the initialization value must be known at compile time and once declared, the type of the variable is fixed; you can’t change it later.
Passing Different Types to Functions
Floating-point variables and variables of different size are passed to function in the same way that int variables are as demonstrated in the following code snippet. This example snippet passes the value of the variable dArg along with the const double 0.0 to the function maximumFloat().
// maximumFloat - return the larger of two floating
// point arguments
double maximumFloat(double d1, double d2)
{
if (d1 > d2)
{
return d1;
}
return d2;
}
void otherFunction()
{
double dArg = 1.0;
double dNonNegative = maximumFloat(dArg, 0.0);
// ...function continues...
I discuss functions in Chapter 11.
Overloading function names
The type of the arguments are part of the extended name of the function. Thus the full name of the earlier example function is maximumFloat(double, double). In Chapter 11, you see how to differentiate between two functions by the number of arguments. You can also differentiate between two functions by the type of the arguments, as shown in the following example:
double maximum(double d1, double2);
int maximum(int n1, int n2);
When you do the declaration this way, it’s clear that the call maximum(1, 2) refers to maximum(int, int), while the call maximum(3.0, 4.0) refers to maximum(double, double).
Defining functions that have the same name but different arguments is called function overloading.
You can differentiate by the signedness and length as well:
int maximum(int n1, int n2);
long maximum(long l1, long l2);
unsigned maximum(unsigned un1, unsigned un2);
Fortunately, this is rarely necessary in practice.
Mixed-mode overloading
The rules can get really weird when the arguments in the call don’t line up exactly with the declarations. Consider the following example code snippet:
double maximum(double d1, double d2);
int maximum(int n1, int n2);
void otherFunction()
{
// which function is invoked by the following?
double dNonNegative = maximum(dArg, 0);
// ...function continues...
Here the arguments don’t line up exactly with either declaration. There is no maximum(double, int). C++ could reasonably take any one of the following three options:
- Promote the 0 to a double and call maximum(double, double).
- Demote the double to an int and invoke maximum(int, int).
- Throw up its electronic hands and report a compiler error.
The general rule is that C++ will promote arguments in order to find a match but will not automatically demote an argument. However, you can’t always count on this rule. In this particular case, Code::Blocks generates an error that says the call is ambiguous. That is, the third option wins.
My advice is to not rely on C++ to figure out what you mean; instead, make the necessary conversions explicit:
void otherFunction(int nArg1, double dArg2)
{
// use an explicit cast to make sure that the
// proper function is called
double dNonNegative = maximum((double)nArg1, dArg2);
Now it’s clear that I mean to call maximum(double, double).