
Chapter 16
Arrays with Character
In This Chapter
![]() Introducing the null-terminated character array
Introducing the null-terminated character array
![]() Creating an ASCIIZ array variable
Creating an ASCIIZ array variable
![]() Examining two example ASCIIZ manipulation programs
Examining two example ASCIIZ manipulation programs
![]() Reviewing some of the most common built-in ASCIIZ library functions
Reviewing some of the most common built-in ASCIIZ library functions
In Chapter 15, which introduces the concept of arrays, the example program collects values into an integer array, which is then passed to a function to display and to a separate function to average. However, as useful as an array of integers might be, far and away the most common type of array is the character array. Specifically something known as the ASCIIZ character array, which is the subject of this chapter.
The ASCII-Zero Character Array
Arrays have an inherent problem: You can never know, just by looking at the array, how many values are actually stored in it. Knowing the size of an array is not enough. That tells you how many values the array can hold, not how many it actually does hold. The difference is like the difference between how much gas your car’s tank can hold and how much gas it actually has. Even if your tank holds 20 gallons, you still need a gas gauge to tell you how much is in it.
For a specific example, the ArrayDemo program in Chapter 15 allocates enough room in nScores for 100 integers, but that doesn’t mean the user actually entered that many. He might have entered a lot fewer.
There are essentially two ways of keeping track of the amount of data in an array:
- Keep a count of the number of values in a separate int variable. This is the technique used by the ArrayDemo program. The code that reads the user input keeps track of the number of entries in nCount. The only problem is that the program has to pass nCount along to every function to which it has passed the nScores array. The array isn’t useful without knowledge of how many values it stores.
- Use a special value in the array as an indicator of the last element used. By convention, this is the technique used for character arrays in C++.
Take a look at the table of legal ASCII characters in Chapter 5. You’ll notice that one character in particular is not a legal character: ‘�’. This character is also known as the null character. It’s the character with a numerical value of zero. A program can use the null character as the end of a string of characters. The null character has no purpose other than signaling the end of a character array. The user can never enter a null character. This means that you don’t have to pass a separate count variable around — you can always tell the end of the string by looking for a null.
The designers of C and C++ liked this feature so well that they settled on it as the standard for character strings. They even gave it a name: the ASCII-zero array or ASCIIZ for short.
The null character has another advantageous property. It is the only character whose value is considered false in a comparison expression (such as in a loop or an if statement).
 Remember from Chapter 9 that 0 or null is considered false. All other values evaluate to true.
Remember from Chapter 9 that 0 or null is considered false. All other values evaluate to true.
This makes writing loops that manipulate ASCIIZ strings even easier, as you see in the following examples.
Declaring and Initializing an ASCIIZ Array
I could declare an ASCIIZ character array containing my first name as follows:
char szMyName[8] = {'S', 't', 'e', 'p',
'h', 'e', 'n', '�'};
Actually, the 8 is redundant. C++ is smart enough to count the number of characters in the initialization string and just make the array that big. Thus the following is completely equivalent to the previous example:
char szMyName[] = {'S', 't', 'e', 'p',
'h', 'e', 'n', '�'};
The only problem with this is that it’s awfully clumsy. I have to type a lot more than just the seven characters that make up my name. (I had to type about five keystrokes for every character in my name — that’s a lot of overhead.) ASCIIZ strings are so common in C++ that the language provides a shorthand option:
char szMyName[] = "Stephen";
These two initialization statements are completely equivalent. In fact, a string contained in double quotes is nothing more than an array of constant characters terminated with a null.
The string "Stephen" consists of eight characters — don’t forget to count the terminating null.
Looking at an Example
Let’s take the simple case of displaying a string. You know by now that C++ understands how to display ASCIIZ strings just fine, but suppose it didn’t. What would a function designed to display a string look like? The following DisplayASCIIZ program shows one example:
//
// DisplayASCIIZ - display an ASCIIZ string one character
// at a time as an example of ASCIIZ
// manipulation
//
#include <cstdio>
#include <cstdlib>
#include <iostream>
using namespace std;
// displayString - display an ASCIIZ string one character
// at a time
void displayString(char szString[])
{
for(int index = 0; szString[index] != '�'; index++)
{
cout << szString[index];
}
}
int main(int nNumberofArgs, char* pszArgs[])
{
char szName1[] = {'S', 't', 'e', 'p',
'h', 'e', 'n', '�'};
char szName2[] = "Stephen";
cout << "Output szName1: ";
displayString(szName1);
cout << endl;
cout << "Output szName2: ";
displayString(szName2);
cout << endl;
// wait until user is ready before terminating program
// to allow the user to see the program results
cout << "Press Enter to continue..." << endl;
cin.ignore(10, '
'),
cin.get();
return 0;
}
The displayString() function is the key to this demonstration program. This function iterates through the array of characters passed to it using the variable index. However, rather than rely on a separate variable containing the number of characters in the array, this function loops until the character at szString[index] is the null character, '�'. As long as the current character is not a null character, the loop outputs it to the display.
The main() function creates two versions of my name, first using discrete characters for szName1 and then a second time using the shortcut "Stephen" for szName2. The function then displays both strings, using the displayString() function both to show that the function works and to demonstrate the equivalence of the two strings.
The output from the program appears as follows:
Output szName1: Stephen
Output szName2: Stephen
Press Enter to continue …
Notice that szName1 and szName2 display identically (since they are the same).
Looking at a More Detailed Example
Displaying a string of characters is fairly simple. What about a slightly tougher example? The following program concatenates two strings that it reads from the keyboard.
To concatenate two strings means to tack one onto the end of the other. For example, the result of concatenating "abc" with "DEF" is "abcDEF".
Before you examine the program, think about how you could go about concatenating a string, call it szSource, onto the end of another one called szTarget.
First, you need to find the end of the szTarget string (see the top of Figure 16-1). Once you’ve done that, you copy characters from szSource one at a time into szTarget until you reach the end of the szSource string (as demonstrated at the bottom of Figure 16-1). Make sure that the result has a final null on the end, and you’re done.
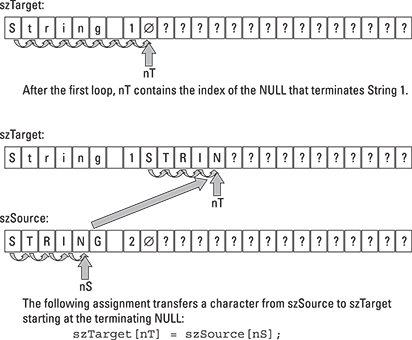
Figure 16-1: To concatenate, the function must (a) find the terminating null of the target string, and then (b) copy characters from the source to the target until reaching the terminating null on the source.
That’s exactly how the concatenateString() function works in the ConcatenateString example program.
//
// ConcatenateString - demonstrate the manipulation of
// ASCIIZ strings by implementing a
// concatenate function
//
#include <cstdio>
#include <cstdlib>
#include <iostream>
using namespace std;
// concatenateString - concatenate one string onto the
// end of another
void concatenateString(char szTarget[],
const char szSource[])
{
// first find the end of the target string
int nT;
for(nT = 0; szTarget[nT] != '�'; nT++)
{
}
// now copy the contents of the source string into
// the target string, beginning at 'nT'
for(int nS = 0; szSource[nS] != '�'; nT++, nS++)
{
szTarget[nT] = szSource[nS];
}
// add the terminator to szTarget
szTarget[nT] = '�';
}
int main(int nNumberofArgs, char* pszArgs[])
{
// Prompt user
cout << "This program accepts two strings
"
<< "from the keyboard and outputs them
"
<< "concatenated together.
" << endl;
// input two strings
cout << "Enter first string: ";
char szString1[256];
cin.getline(szString1, 256);
cout << "Enter the second string: ";
char szString2[256];
cin.getline(szString2, 256);
// now concatenate one onto the end of the other
cout << "Concatenate first string onto the second"
<< endl;
concatenateString(szString1, szString2);
// and display the result
cout << "Result: <"
<< szString1
<< ">" << endl;
// wait until user is ready before terminating program
// to allow the user to see the program results
cout << "Press Enter to continue..." << endl;
cin.ignore(10, '
'),
cin.get();
return 0;
}
The concatenateString() function accepts two strings, szTarget and szSource. Its goal is to tack szSource onto the end of szTarget.
 The function assumes that the szTarget array is large enough to hold both strings tacked together. It has no way of checking to make sure that there is enough room. (More about that a little later in this chapter.)
The function assumes that the szTarget array is large enough to hold both strings tacked together. It has no way of checking to make sure that there is enough room. (More about that a little later in this chapter.)
 Notice that the target argument is passed first and the source second. This sequence may seem backwards, but it really doesn’t matter — either argument can be the source or the target. It’s just a C++ convention that the target goes first.
Notice that the target argument is passed first and the source second. This sequence may seem backwards, but it really doesn’t matter — either argument can be the source or the target. It’s just a C++ convention that the target goes first.
In the first for loop, the function iterates through szTarget by incrementing the index nT until szTarget[nT] == ’�’, that is, until nT points to the terminating null character. This corresponds to the situation at the top of Figure 16-1.
The function then enters a second loop in which it copies each character from szSource into szTarget starting at nT and moving forward. This corresponds to the bottom of Figure 16-1.
This example shows a situation when using the comma operator in a for loop is justified.
Since the for loop terminates before it copies the terminating null from szSource, the function must add the terminating null onto the result before returning.
The main() program prompts the user to enter two strings, each terminated with a newline. The program then concatenates the two strings by calling the new concatenateString() function and displays the results.
The expression cin >> string; stops inputting at the first white space. The getline() function used in the example program reads input from the keyboard just like cin >> string;, but it reads an entire line up to the newline at the end. It does not include the newline in the character string that it returns. Don’t worry about the strange syntax of the call to getline() — I cover that in Chapter 23.
The results of a sample run of the program appear as follows:
This program accepts two strings
from the keyboard and outputs them
concatenated together.
Enter first string: String 1
Enter the second string: STRING 2
Concatenate first string onto the second
Result: <String 1STRING 2>
Press Enter to continue …
 Note that the second argument to concatenateString() is actually declared to be a const char[] (pronounced “array of constant characters”). That’s because the function does not modify the source string. Declaring it to be an array of constant characters allows you to call the function passing it a constant string as in the following call:
Note that the second argument to concatenateString() is actually declared to be a const char[] (pronounced “array of constant characters”). That’s because the function does not modify the source string. Declaring it to be an array of constant characters allows you to call the function passing it a constant string as in the following call:
concatenateString(szString, "The End");
Foiling hackers
How does the concatenateString() function in the earlier example program know whether there’s enough room in szTarget to hold both the source and target strings concatenated together? The answer is simple: It doesn’t.
This is a serious bug. If a user entered enough characters before pressing Enter, he could overwrite large sections of data or even code. In fact, this type of fixed-buffer overwrite bug is one of the ways that hackers gain control of PCs through a browser to plant virus code.
In the following corrected version, concatenateString() accepts an additional argument: the size of the szTarget array. The function checks the index nT against this number to make sure that it does not write beyond the end of the target array.
The program appears as ConcatenateNString in the online material:
// concatenateString - concatenate one string onto the
// end of another (don't write beyond
// nTargetSize)
void concatenateString(char szTarget[],
int nTargetSize,
const char szSource[])
{
// first find the end of the target string
int nT;
for(nT = 0; szTarget[nT] != '�'; nT++)
{
}
// now copy the contents of the source string into
// the target string, beginning at 'nT' but don't
// write beyond the nTargetSize'th element (- 1 to
// leave room for the terminating null)
for(int nS = 0;
nT < (nTargetSize - 1) && szSource[nS] != '�';
nT++, nS++)
{
szTarget[nT] = szSource[nS];
}
// add the terminator to szTarget
szTarget[nT] = '�';
}
The first part of the function starts out exactly the same, incrementing through szTarget looking for the terminating null. The difference is in the second loop. This for loop includes two terminating conditions. Control exits the loop if either of the following is true:
- szSource[nS] is the null character, meaning that you’ve gotten to the final character in szSource.
- nT is greater than or equal to nTargetSize - 1 meaning that you’ve exhausted the space available in szTarget (- 1 because you have to leave room for the terminating null at the end).
This extra check is irritating but necessary to avoid overrunning the array and producing a program that can crash in strange and mysterious ways.
Do I Really Have to Do All That Work?
C++ doesn’t provide much help with manipulating strings in the language itself. Fortunately, the standard library includes a number of functions for manipulating these strings that save you the trouble of writing them yourself. Table 16-1 shows the most common of these functions.
Table 16-1 Common ASCIIZ String Manipulation Functions
|
Function |
Description |
|
isalpha(char c) |
Returns a true if the character is alphabetic (‘A’ through ‘Z’ or ‘a’ through ‘z’). |
|
isdigit(char c) |
Returns a true if the character is a digit (‘0’ through ‘9’). |
|
isupper(char c) |
Returns a true if the character is an uppercase alphabetic. |
|
islower(char c) |
Returns a true if the character is a lowercase alphabetic. |
|
isprint(char c) |
Returns a true if the character is printable. |
|
isspace(char c) |
Returns a true if the character is a form of white space (space, tab, newline, and so on). |
|
strlen(char s[]) |
Returns the number of characters in a string (not including the terminating null). |
|
strcmp(char s1[], char s2[]) |
Compares two strings. Returns 0 if the strings are identical. Returns a 1 if the first string occurs later in the dictionary than the second. Returns a −1 otherwise. |
|
strncpy(char target[], char source[], int size) |
Copies the source string into the target string but not more than ‘size’ characters. |
|
strncat(char target[], char source[], int size) |
Concatenates the source string onto the end of the target string for a total of not more than ‘size’ characters. |
|
tolower(char c) |
Returns the lowercase version of the character passed to it. Returns the current character if it is already lowercase or has no uppercase equivalent (as a digit does not). |
|
toupper(char c) |
Returns the uppercase version of the character passed to it. |
The following example program uses the toupper() function to convert a string entered by the user into all caps:
//
// ToUpper - convert a string input by the user to all
// upper case.
//
#include <cstdio>
#include <cstdlib>
#include <iostream>
using namespace std;
// toUpper - convert every character in an ASCIIZ string
// to uppercase
void toUpper(char szTarget[], int nTargetSize)
{
for(int nT = 0;
nT < (nTargetSize - 1) && szTarget[nT] != '�';
nT++)
{
szTarget[nT] = toupper(szTarget[nT]);
}
}
int main(int nNumberofArgs, char* pszArgs[])
{
// Prompt user
cout << "This program accepts a string
"
<< "from the keyboard and echoes the
"
<< "string in all caps.
" << endl;
// input two strings
cout << "Enter string: ";
char szString[256];
cin.getline(szString, 256);
// now convert the string to all uppercase
toUpper(szString, 256);
// and display the result
cout << "All caps version: <"
<< szString
<< ">" << endl;
// wait until user is ready before terminating program
// to allow the user to see the program results
cout << "Press Enter to continue..." << endl;
cin.ignore(10, '
'),
cin.get();
return 0;
}
The toUpper() function follows a pattern that will quickly become old hat for you: It loops through each element in the ASCIIZ string using a for loop. The loop terminates if either the size of the string is exhausted or the program reaches the terminating null character.
The function passes each character in the string to the standard C++ library toupper() function. It stores the character returned by the function by putting it back into the character array.
It’s not necessary to test first by using islower() to make sure that the character is lowercase.Both the tolower() and the toupper() functions return the character passed to them if the character has no lower- or uppercase equivalent.
The main() function simply prompts the user to enter a string. The program reads the input string by calling getline(). It then converts whatever it reads to uppercase by calling toUpper() and then displays the results.
The following shows the results of a sample run:
This program accepts a string
from the keyboard and echoes the
string in all caps.
Enter string: This is a string 123!@#.
All caps version: <THIS IS A STRING 123!@#.>
Press Enter to continue …
Notice that the input string includes uppercase characters, lowercase characters, digits, and symbols. The lowercase characters are converted to uppercase in the output string, but the uppercase characters, digits, and symbols are unchanged.
This chapter shows how to handle ASCIIZ strings as a special case of character arrays. In practice, however, many standard functions rely on something known as a pointer; the next two chapters detail how pointers work. Then I return to these same example functions and implement them using pointers to demonstrate the elegance of the pointer solution.