
The simple answer is: speed and ease of use. DataFrames provide the benefits of optimization, speed, automatic schema discovery, working with multiple sources, and multiple languages support; they read less data, and provide inter-operability between RDDs. Let's delve into these concepts.
Catalyst provides optimization for DataFrames. It provides two optimizations:
- Predicate push down to sources, to read only the data needed
- Creates a physical plan for execution and generates JVM bytecode that is better optimized than handwritten code
The DataFrame is not defining Directed Acyclic Graph (DAG) as in the case of RDDs. Abstract Syntax Trees (AST) are created, which the catalyst engine will parse, check, and improve using both rules-based optimization and cost-based optimization.
Figure 4.4 shows the phase of query planning in Spark Sql. So, any DataFrame, Dataset operation or SQL query will follow the same optimization path to create a physical plan and execute on the Spark Cluster.

Figure 4.4: Phases in Spark SQL Catalyst optimizer. Rounded rectangles are catalyst trees.
Just like RDD, DataFrames and Datasets can be cached as well. When cached, they automatically store data in an efficient columnar format that is significantly more compact than Java/Python objects and provide optimizations.
Since the optimizer generates JVM bytecode for execution, Scala and Python programs provide similar performance as shown in Figure 4.5. The chart shows groupBy aggregation on 10 million integer pairs on a single machine. The Scala and Python DataFrame operations provide similar execution time since they are compiled into the same JVM bytecode for execution. Source: https://databricks.com/blog/2015/02/17/introducing-DataFrames-in-spark-for-large-scale-data-science.html.

Figure 4.5: DataFrames performance in Scala and Python languages
Datasets use optimized encoders to serialize and deserialize objects for processing and transmitting over the network. Encoders provide significantly higher performance than Java or Kryo serialization as shown in Figure 4.6.
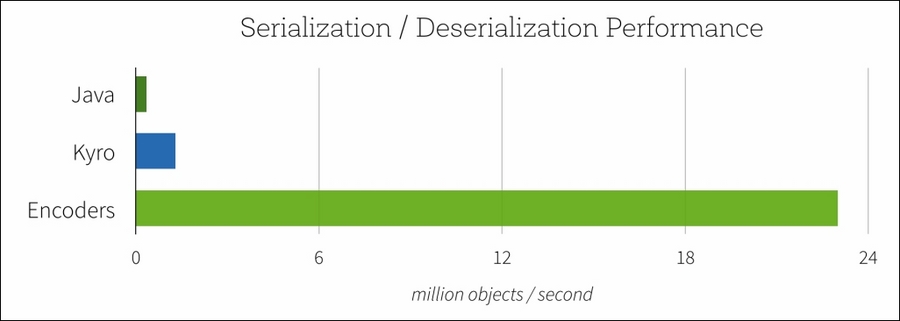
Figure 4.6: Encoder serialization/deserialization performance
To create a DataFrame from an RDD, a schema must be provided. When creating a DataFrame from JSON, Parquet, and ORC files, a schema is automatically discovered including the partitions discovery. This is possible because of the Data Sources API framework.
Big Data Analytical applications need to collect and analyze data from a variety of data sources and formats. The DataFrame API enables reading and writing from most widely used formats including JSON files, Parquet files, ORC files, and Hive tables. It can read from local file systems, HDFS, S3, and external RDBMS databases using the JDBC protocol. Spark SQL's Data Sources API can be extended to support any third-party data formats or sources. Existing third-party extensions are available for Avro, CSV, XML, HBase, ElasticSearch, Cassandra, and so on. The URL http://spark-packages.org/ provides a complete list of third-party packages.
Spark SQL can be implemented in the Java, Scala, Python, and R languages. Using the distributed SQL engine of Spark SQL, pure SQLs can also be written.
Datasets and DataFrames can interoperate with RDDs easily. DataFrames can be converted to RDDs or Pandas DataFrames and vice versa using the .rdd, .toDF, and .toPandas .toDS methods. Also, DataFrames can be used with Spark Streaming and Machine learning libraries as well.
One of the good features of Datasets, DataFrames, and Datasources API is to provide richer optimizations by pushing the predicates to the source systems. Column pruning, predicate pushdown, and partition pruning is done automatically by the framework. So, only the data that is needed is read and processed.