
![]()
Big Data Introduction
Why Big Data
As you will see, this entire book is in problem-solution format. This chapter discusses topics in big data in a general sense, so it is not as technical as other chapters. The idea is to make sure you have a basic foundation for learning about big data. Other chapters will provide depth of coverage that we hope you will find useful no matter what your background. So let’s get started.
Problem
What is the need for big data technology when we have robust, high-performing, relational database management systems (RDBMS)?
Solution
Since the theory of relational databases was postulated in 1980 by Dr. E. F. Codd (known as “Codd’s 12 rules”) most data has been stored in a structured format, with primary keys, rows, columns, tuples, and foreign keys. Initially, it was just transactional data, but as more and more data accumulated, organizations started analyzing the data in an offline mode using data warehouses and data marts. Data analytics and business intelligence (BI) became the primary drivers for CxOs to make forecasts, define budgets, and determine new market drivers of growth.
This analysis was initially conducted on data within the enterprise. However, as the Internet connected the entire world, data existing outside an organization became a substantial part of daily transactions. Even though things were heating up, organizations were still in control even though the data was getting voluminous with normal querying of transactional data. That data was more or less structured or relational.
Things really started getting complex in terms of the variety and velocity of data with the advent of social networking sites and search engines like Google. Online commerce via sites like Amazon.com also added to this explosion of data. Traditional analysis methods as well as storage of data in central servers were proving inefficient and expensive. Organizations like Google, Facebook, and Amazon built their own custom methods to store, process, and analyze this data by leveraging concepts like map reduce, Hadoop distributed file systems, and NoSQL databases.
The advent of mobile devices and cloud computing has added to the amount and pace of data creation in the world, so much so that 90 percent of the world’s total data has been created in the last two years and 70 percent of it by individuals, not enterprises or organizations. By the end of 2013, IDC predicts that just under 4 trillion gigabytes of data will exist on earth. Organizations need to collect this data from social media feeds, images, streaming video, text files, documents, meter data, and so on to innovate, respond immediately to customer needs, and make quick decisions to avoid being annihilated by competition.
However, as I mentioned, the problem of big data is not just about volume. The unstructured nature of the data (variety) and the speed at which it is created by you and me (velocity) is the real challenge of big data.
Aspects of Big Data
Problem
What are the key aspects of a big data system?
Solution
A big data solution must address the three Vs of big data: data velocity, variety, and complexity, in addition to volume.
Velocity of the data is used to define the speed with which different types of data enter the enterprise and are then analyzed.
Variety addresses the unstructured nature of the data in contrast to structured data in weblogs, radio frequency ID (RFID), meter data, stock-ticker data, tweets, images, and video files on the Internet.
For a data solution to be considered as big data, the volume has to be at least in the range of 30–50 terabytes (TBs).
However, large volume alone is not an indicator of a big data problem. A small amount of data could have multiple sources of different types, both structured and unstructured, that would also be classified as a big data problem.
How Big Data Differs from Traditional BI
Problem
Can we use traditional business intelligence (BI) solutions to process big data?
Solution
Traditional BI methodology works on the principle of assembling all the enterprise data in a central server. The data is generally analyzed in an offline mode. The online transaction processing (OLTP) transactional data is transferred to a denormalized environment called as a data warehouse. The data is usually structured in an RDBMS with very little unstructured data.
A big data solution, however, is different in all aspects from a traditional BI solution:
- Data is retained in a distributed file system instead of on a central server.
- The processing functions are taken to the data rather than data being taking to the functions.
- Data is of different formats, both structured as well as unstructured.
- Data is both real-time data as well as offline data.
- Technology relies on massively parallel processing (MPP) concepts.
Problem
What is the potential big data opportunity?
Solution
The amount of data is growing all around us every day, coming from various channels (see Figure 1-1). As 70 percent of all data is created by individuals who are customers of some enterprise or the other, organizations cannot ignore this important source of feedback from the customer as well as insight into customer behavior.
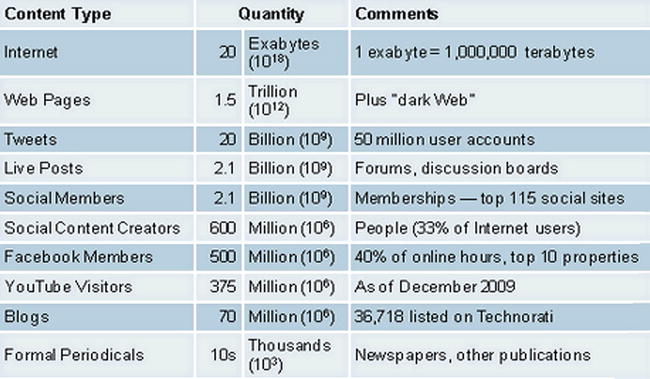
Figure 1-1. Information explosion
Big data drove an estimated $28 billion in IT spending last year, according to market researcher Gartner, Inc. That figure will rise to $34 billion in 2013 and $232 billion in IT spending through 2016, Gartner estimates.
The main reason for this growth is the potential Chief Information Officers (CIOs) see in the greater insights and intelligence contained in the huge unstructured data they have been receiving from outside the enterprise. Unstructured data analysis requires new systems of record—for example, NoSQL databases—so that organizations can forecast better and align their strategic plans and initiatives.
Deriving Insight from Data
Problem
What are the different insights and inferences that big data analysis provides in different industries?
Solution
Companies are deriving significant insights by analyzing big data that gives a combined view of both structured and unstructured customer data. They are seeing increased customer satisfaction, loyalty, and revenue. For example:
- Energy companies monitor and combine usage data recorded from smart meters in real time to provide better service to their consumers and improved uptime.
- Web sites and television channels are able to customize their advertisement strategies based on viewer household demographics and program viewing patterns.
- Fraud-detection systems are analyzing behaviors and correlating activities across multiple data sets from social media analysis.
- High-tech companies are using big data infrastructure to analyze application logs to improve troubleshooting, decrease security violations, and perform predictive application maintenance.
- Social media content analysis is being used to assess customer sentiment and improve products, services, and customer interaction.
These are just some of the insights that different enterprises are gaining from their big data applications.
Problem
How is big data affected by cloud-based virtualized environments?
Solution
The inexpensive option of storage that big data and Hadoop deliver is very well aligned to the “everything as a service” option that cloud-computing offers.
Infrastructure as a Service (IaaS) allows the CIO a “pay as you go” option to handle big data analysis. This virtualized option provides the efficiency needed to process and manage large volumes of structured and unstructured data in a cluster of expensive virtual machines. This distributed environment gives enterprises access to very flexible and elastic resources to analyze structured and unstructured data.
Map reduce works well in a virtualized environment with respect to storage and computing. Also, an enterprise might not have the finances to procure the array of inexpensive machines for its first pilot. Virtualization enables companies to tackle larger problems that have not yet been scoped without a huge upfront investment. It allows companies to scale up as well as scale down to support the variety of big data configurations required for a particular architecture.
Amazon Elastic MapReduce (EMR) is a public cloud option that provides better scaling functionality and performance for MapReduce. Each one of the Map and Reduce tasks needs to be executed discreetly, where the tasks are parallelized and configured to run in a virtual environment. EMR encapsulates the MapReduce engine in a virtual container so that you can split your tasks across a host of virtual machine (VM) instances.
As you can see, cloud computing and virtualization have brought the power of big data to both small and large enterprises.
Structured vs. Unstructured Data
Problem
What are the various data types both within and outside the enterprise that can be analyzed in a big data solution?
Solution
Structured data will continue to be analyzed in an enterprise using structured access methods like Structured Query Language (SQL). However, the big data systems provide tools and structures for analyzing unstructured data.
New sources of data that contribute to the unstructured data are sensors, web logs, human-generated interaction data like click streams, tweets, Facebook chats, mobile text messages, e-mails, and so forth.
RDBMS systems will continue to exist with a predefined schema and table structure. Unstructured data is data stored in different structures and formats, unlike in a a relational database where the data is stored in a fixed row-column like structure. The presence of this hybrid mix of data makes big data analysis complex, as decisions need to be made regarding whether all this data should be first merged and then analyzed or whether only an aggregated view from different sources has to be compared.
We will see different methods in this book for making these decisions based on various functional and nonfunctional priorities.
Analytics in the Big Data World
Problem
How do I analyze unstructured data, now that I do not have SQL-based tools?
Solution
Analyzing unstructured data involves identifying patterns in text, video, images, and other such content. This is different from a conventional search, which brings up the relevant document based on the search string. Text analytics is about searching for repetitive patterns within documents, e-mails, conversations and other data to draw inferences and insights.
Unstructured data is analyzed using methods like natural language processing (NLP), data mining, master data management (MDM), and statistics. Text analytics use NoSQL databases to standardize the structure of the data so that it can be analyzed using query languages like PIG, Hive, and others. The analysis and extraction processes take advantage of techniques that originated in linguistics, statistics, and numerical analysis.
Problem
What are the key big data challenges?
Solution
There are multiple challenges that this great opportunity has thrown at us.
One of the very basic challenges is to understand and prioritize the data from the garbage that is coming into the enterprise. Ninety percent of all the data is noise, and it is a daunting task to classify and filter the knowledge from the noise.
In the search for inexpensive methods of analysis, organizations have to compromise and balance against the confidentiality requirements of the data. The use of cloud computing and virtualization further complicates the decision to host big data solutions outside the enterprise. But using those technologies is a trade-off against the cost of ownership that every organization has to deal with.
Data is piling up so rapidly that it is becoming costlier to archive it. Organizations struggle to determine how long this data has to be retained. This is a tricky question, as some data is useful for making long-term decisions, while other data is not relevant even a few hours after it has been generated and analyzed and insight has been obtained.
With the advent of new technologies and tools required to build big data solutions, availability of skills is a big challenge for CIOs. A higher level of proficiency in the data sciences is required to implement big data solutions today because the tools are not user-friendly yet. They still require computer science graduates to configure and operationalize a big data system.
Defining a Reference Architecture
Problem
Is there a high-level conceptual reference architecture for a big data landscape that’s similar to cloud-computing architectures?
Solution
Analogous to the cloud architectures, the big data landscape can be divided into four layers shown vertically in Figure 1-2:
- Infrastructure as a Service (IaaS): This includes the storage, servers, and network as the base, inexpensive commodities of the big data stack. This stack can be bare metal or virtual (cloud). The distributed file systems are part of this layer.
- Platform as a Service (PaaS): The NoSQL data stores and distributed caches that can be logically queried using query languages form the platform layer of big data. This layer provides the logical model for the raw, unstructured data stored in the files.
- Data as a Service (DaaS): The entire array of tools available for integrating with the PaaS layer using search engines, integration adapters, batch programs, and so on is housed in this layer. The APIs available at this layer can be consumed by all endpoint systems in an elastic-computing mode.
- Big Data Business Functions as a Service (BFaaS): Specific industries—like health, retail, ecommerce, energy, and banking—can build packaged applications that serve a specific business need and leverage the DaaS layer for cross-cutting data functions.
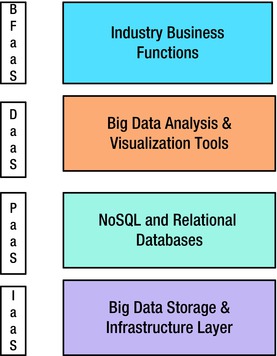
Figure 1-2. Big data architecture layers
You will see a detailed big data application architecture in the next chapter that essentially is based on this four-layer reference architecture.
Need for Architecture Patterns
Problem
Why do we need big data architecture patterns?
Solution
Though big data offers many benefits, it is still a complex technology. It faces the challenges of both service-oriented architecture (SOA) and cloud computing combined with infrastructure and network complexities. SOA challenges, like distributed systems design, along with cloud challenges, like hybrid-system synchronization, have to be taken care of in big data solutions.
A big data implementation also has to take care of the “ilities” or nonfunctional requirements like availability, security, scalability, performance, and so forth. Combining all these challenges with the business objectives that have to be achieved, requires an end-to-end application architecture view that defines best practices and guidelines to cope with these issues.
Patterns are not perfect solutions, but in a given context they can be used to create guidelines based on experiences where a particular solution or pattern has worked. Patterns describe both the problem and solution that can be applied repeatedly to similar scenarios.
Summary
You saw how the big data revolution is changing the traditional BI world and the way organizations run their analytics initiatives. The cloud and SOA revolution are the bedrock of this phenomenon, which means that big data faces the same challenges that were faced earlier, along with some new challenges in terms of architecture, skills, and tools. A robust, end-to-end application architecture is required for enterprises to succeed in implementing a big data system. In this journey, if we can help you by showing you some guidelines and best practices we have encountered to solve some common issues, it will make your journey faster and relatively easier. Let’s dive deep into the architecture and patterns.