
CHAPTER GOALS
Understanding XML elements and attributes
Understanding the concept of an XML parser
Being able to read and write XML documents
Being able to design Document Type Definitions for XML documents
In this chapter, you will learn about the Extensible Markup Language (XML), a mechanism for encoding data that is independent of any programming language. XML allows you to encode complex data in a form that the recipient can easily parse. XML is very popular for data exchange. It is simple enough that a wide variety of programs can easily generate XML data. XML data has a nested structure, so you can use it to describe hierarchical data sets—for example, an invoice that contains many items, each of which consists of a product and a quantity. Because the XML format is standardized, libraries for parsing the data are widely available and—as you will see in this chapter—easy to use for a programmer.
It is particularly easy to read and write XML documents in Java. In fact, it is generally easier to use XML than it is to use an "ad hoc" file format. Thus, using XML makes your programs easier to write and more professional.
To understand the advantages of using XML for encoding data, let's look at a typical example. We will encode product descriptions, so that they can be transferred to another computer. Your first attempt might be a naïve encoding like this:
Toaster 29.95
In contrast, here is an XML encoding of the same data:
<product> <description>Toaster</description> <price>29.95</price> </product>
Note
XML allows you to encode complex data, independent from any programming language, in a form that the recipient can easily parse.
The advantage of the XML version is clear: You can look at the data and understand what they mean. Of course, this is a benefit for the programmer, not for a computer program. A computer program has no understanding of what a "price" is. As a programmer, you still need to write code to extract the price as the content of the price element. Nevertheless, the fact that an XML document is comprehensible by humans is a huge advantage for program development.
Note
XML files are readable by computer programs and by humans.
A second advantage of the XML version is that it is resilient to change. Suppose the product data change, and an additional data item is introduced, to denote the manufacturer. In the naïve format, the manufacturer might be added after the price, like this:
Toaster 29.95 General Appliances
Note
XML-formatted data files are resilient to change.
A program that can process the old format might get confused when reading a sequence of products in the new format. The program would think that the price is followed by the name of the next product. Thus, the program needs to be updated to work with both the old and new data formats. As data get more complex, programming for multiple versions of a data format can be difficult and time-consuming.
When using XML, on the other hand, it is easy to add new elements:
<product> <description>Toaster</description> <price>29.95</price> <manufacturer>General Appliances</manufacturer> </product>
Now a program that processes the new data can still extract the old information in the same way—as the contents of the description and price elements. The program need not be updated, and it can tolerate different versions of the data format.
If you know HTML, you may have noticed that the XML format of the product data looked somewhat like HTML code. However, there are some differences that we will discuss in this section.
Let's start with the similarities. The XML tag pairs, such as <price> and </price> look just like HTML tag pairs, for example <li> and </li>. Both in XML and in HTML, tags are enclosed in angle brackets < >, and a start-tag is paired with an endtag that starts with a slash / character.
However, web browsers are quite permissive about HTML. For example, you can omit an end-tag </li> and the browser will try to figure out what you mean. In XML, this is not permissible. When writing XML, pay attention to the following rules:
In XML, you must pay attention to the letter case of the tags; for example,
<li>and<LI>are different tags that bear no relation to each other.Every start-tag must have a matching end-tag. You cannot omit tags, such as
</li>. However, if a tag has no end-tag, it must end in/>, for example<img src="hamster.jpeg"/>
When the parser sees the
/>, it knows not to look for a matching end-tag.Finally, attribute values must be enclosed in quotes. For example,
<img src="hamster.jpeg" width=400 height=300/>
is not acceptable. You must use
<img src="hamster.jpeg" width="400" height="300"/>
Moreover, there is an important conceptual difference between HTML and XML. HTML has one specific purpose: to describe web documents. In contrast, XML is an extensible syntax that can be used to specify many different kinds of data. For example, the VRML language uses the XML syntax to describe virtual reality scenes. The MathML language uses the XML syntax to describe mathematical formulas. You can use the XML syntax to describe your own data, such as product records or invoices.
Most people who first see XML wonder how an XML document looks inside a browser. However, that is not generally a useful question to ask. Most data that are encoded in XML have nothing to do with browsers. For example, it would probably not be exciting to display an XML document with nothing but product records (such as the ones in the previous section) in a browser. Instead, you will learn in this chapter how to write programs that analyze XML data. XML does not tell you how to display data; it is merely a convenient format for representing data.
Note
XML describes the meaning of data, not how to display them.
In this section, you will see the rules for properly formatted XML. In XML, text and tags are combined into a document. The XML standard recommends that every XML document start with a declaration
<?xml version="1.0"?>
Note
An XML document starts out with an XML declaration and contains elements and text.
Next, the XML document contains the actual data. The data are contained in a root element. For example,
<?xml version="1.0"?> <invoice> more data </invoice>
The root element is an example of an XML element. An element has one of two forms:
<elementName>content</elementName>
or
<elementName/>In the first case, the element has content—elements, text, or a mixture of both. A good example is a paragraph in an HTML document:
<p>Use XML for <strong>robust</strong> data formats.</p>
The p element contains
The text: "Use XML for "
A
strongchild elementMore text: " data formats."
For XML files that contain documents in the traditional sense of the term, the mixture of text and elements is useful. The XML specification calls this type of content mixed content. But for files that describe data sets—such as our product data—it is better to stick with elements that contain either other elements or text. Content that consists only of elements is called element content.
Note
An element can contain text, child elements, or both (mixed content). For data descriptions, avoid mixed content.
An element can have attributes. For example, the a element of HTML has an href attribute that specifies the URL of a hyperlink:
<a href="http://java.sun.com"> ... </a>
An attribute has a name (such as href) and a value. In XML, the value must be enclosed in single or double quotes.
An element can have multiple attributes, for example
<img src="hamster.jpeg" width="400" height="300"/>
And, as you have already seen, an element can have both attributes and content.
<a href="http://java.sun.com">Sun's Java web site</a>
Programmers often wonder whether it is better to use attributes or child elements. For example, should a product be described as
<product description="Toaster" price="29.95"/>
or
<product>
<description>Toaster</description> <price>29.95</price> </product>
The former is shorter. However, it violates the spirit of attributes. Attributes are intended to provide information about the element content. For example, the price element might have an attribute currency that helps interpret the element content. The content 29.95 has a different interpretation in the element
<price currency="USD">29.95</price>
than it does in the element
<price currency="EUR">29.95</price>
You have now seen the components of an XML document that are needed to use XML for encoding data. There are other XML constructs for more specialized situations—see http://www.xml.com/axml/axml.html

What does your browser do when you load an XML file, such as the
items.xmlfile that is contained in the companion code for this book?Why does HTML use the
srcattribute to specify the source of an image instead of<img>hamster.jpeg</img>?
Random Fact 23.1 Word Processing and Typesetting Systems
You have almost certainly used a word processor for writing letters or reports. A word processor is a program to write and edit documents made up of text and images. The text can contain characters in various fonts. It can be arranged in paragraphs, tables, and footnotes.

Paragraphs can be formatted in various ways, such as ragged right (that is, the left ends of the lines of text are aligned under each other, but the right ends aren't), centered, and fully justified (that is, both the left and right ends of the lines are aligned). What is characteristic of modern word processors is their "what you see is what you get" operation. You enter text and commands, using the keyboard and the mouse. The computer screen instantly shows what the printed document will look like (see Figure 1).
However, there are disadvantages to the "what you see is what you get" (WYSIWYG, pronounced wis-ee-wig) nature of a word processor. You may labor to arrange various related images and tables on the same page. Later, you find that you need to add a couple of paragraphs on the preceding page. Now half of the material moves to the next page, and you have do the arranging all over again. It would have been more useful if you could have told the word processor your intention, namely: "Always keep these images and tables together on the same page". In general, "what you see is what you get" programs are very good in letting you arrange material, but they don't know why you arranged the material in a certain way. Thus, they can't keep the arrangement when your document changes. Some people call these programs "what you see is all you've got".
More fundamentally, "what you see is what you get" programs break down when you need to publish the same material in multiple ways. You may want to format product information as a product parts list and an advertising brochure. Or you may want to publish the information in printed form, on the Web, and in spoken form for telephone retrieval. Now you no longer want to "get" a single result, so it isn't as helpful to see what you get. Instead, it becomes much more important to visualize the structure of the information.
A program for editing structured text needs to capture three pieces of information:
The text itself
The structural element (paragraph, bulleted list, heading, and so on) to which each part of the text belongs
The rules for formatting the structural elements
To make it easy to interchange structured documents between computer systems, the structural information is often encoded in markup tags. For example, XML and HTML use tags that are enclosed in angle brackets, such as the familiar <p>, <ul>, and <h1> tags.
In the 1970s, when publishers began to move away from traditional manual typesetting to computer-based typesetting, the result at first was inferior quality, particularly for mathematical formulas. Arranging the symbols in complex formulas in a way that makes mathematical sense is an art that requires practice and good judgment, and the first typesetting programs were definitely not up to the job. Frustrated by this situation, the famous computer scientist Donald Knuth of Stanford University decided to do something about it and invented a typesetting program that he called TEX (pronounced "tek" because the "X" is a capital Greek chi). Input to that program consists of text with markup tags that start with a backslash; curly braces {} for grouping; and other special markup symbols, such as _ and ^ to indicate subscript and superscript. For example, to specify a summation, you type
sum_{i=1}^n i^2The TEX program typesets the summation as shown in Figure 2. Note that the expression is formatted one way when it occurs inside text and another way when it appears as part of a displayed formula.
A markup tag such as <h1> in HTML or sum in TEX is mainly beneficial for exchanging documents among different computer systems. Only the most hardened HTML or TEX authors produce the markup by hand. For HTML in particular, many programs are available that display the structure of an HTML document and allow authors to edit both text and structure in a convenient way that combines the benefits of visual feedback and structure editing.
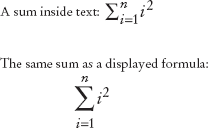
To read and analyze the contents of an XML document, you need an XML parser. A parser is a program that reads a document, checks whether it is syntactically correct, and takes some action as it processes the document.
Two kinds of XML parsers are in common use. Streaming parsersread the XML input one token at a time and report what they encounter: a start tag, text, an end tag, and so on. In contrast, a tree-based parser builds a tree that represents the parsed document. Once the parser is done, you can analyze the tree.
Note
A parser is a program that reads a document, checks whether it is syntactically correct, and takes some action as it processes the document.
Streaming parsers are more efficient for handling large XML documents whose tree structure would require large amounts of memory. Tree-based parsers, however, are easier to use for most applications—the parse tree gives you a complete overview of the data, whereas a streaming parser gives you the information in bits and pieces.
Note
A streaming parser reports the building blocks of an XML document. A tree-based parser builds a document tree.
In this section, you will learn how to use a tree-based parser that produces a tree structure according to the DOM (Document Object Model) standard. The DOM standard defines interfaces and methods to analyze and modify the tree structure that represents an XML document.
In order to parse an XML document into a DOM tree, you need a Document-Builder. To get a DocumentBuilder object, first call the static newInstance method of the DocumentBuilderFactory class, then call the newDocumentBuilder method on the factory object.
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); DocumentBuilder builder = factory.newDocumentBuilder();
Once you have a DocumentBuilder, you can read a document. To read a document from a file, first construct a File object from the file name, then call the parse method of the DocumentBuilder class.
String fileName = ...; File f = new File(fileName); Document doc = builder.parse(f);
Note
A DocumentBuilder can read an XML document from a file, URL, or input stream. The result is a Document object, which contains a tree.
If the document is located on the Internet, use an URL:
String urlName = ...; URL u = new URL(urlName); Document doc = builder.parse(u);
You can also read a document from an arbitrary input stream:
InputStream in = ...; Document doc = builder.parse(in);
Once you have created a new document or read a document from a file, you can inspect and modify it.
The easiest method for inspecting a document is the XPath syntax. An XPath describes a node or set of nodes, using a syntax that is similar to directory paths. For example, consider the following XPath, applied to the document in Figure 3 and Figure 4:

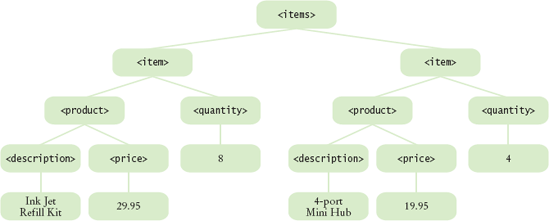
This XPath selects the quantity of the first item, that is, the value 8. (In XPath, array positions start with 1. Accessing /items/item[0] would be an error.)
Similarly, you can get the price of the second product as
/items/item[2]/product/price
To get the number of items, use the XPath expression
count(/items/item)
In our example, the result is 2.
The total number of children can be obtained as
count(/items/*)
In our example, the result is again 2 because the items element has exactly two children.
To select attributes, use an @ followed by the name of the attribute. For example,
/items/item[2]/product/price/@currency
would select the currency price attribute if it had one.
Finally, if you have a document with variable or unknown structure, you can find out the name of a child with an expression such as the following:
name(/items/item[1]/*[1])
The result is the name of the first child of the first item, or product.
That is all you need to know about the XPath syntax to analyze simple documents. (See Table 1 for a summary.) There are many more options in the XPath syntax that we do not cover here. If you are interested, look up the specification (http://www.w3.org/TR/xpathhttp://www.zvon.org/xxl/XPathTutorial/General/examples.html
To evaluate an XPath expression in Java, first create an XPath object:
XPathFactory xpfactory = XPathFactory.newInstance(); XPath path = xpfactory.newXPath();
Then call the evaluate method, like this:
String result = path.evaluate(expression, doc)Here, expression is an XPath expression and doc is the Document object that represents the XML document. For example, the statement
String result = path.evaluate("/items/item[2]/product/price", doc)sets result to the string "19.95".
Now you have all the tools that you need to read and analyze an XML document. The example program at the end of this section puts these techniques to work. (The program uses the LineItem and Product classes from Chapter 12.) The class ItemListParser can parse an XML document that contains a list of product descriptions. Its parse method takes the file name and returns an array list of LineItem objects:
ItemListParser parser = new ItemListParser();
ArrayList<LineItem> items = parser.parse("items.xml");The ItemListParser class translates each XML element into an object of the corresponding Java class. We first get the number of items:
int itemCount = Integer.parseInt(path.evaluate("count(/items/item)", doc));For each item element, we gather the product data and construct a Product object:
String description = path.evaluate(
"/items/item[" + i + "]/product/description", doc);
double price = Double.parseDouble(path.evaluate(
"/items/item[" + i + "]/product/price", doc));
Product pr = new Product(description, price);Then we construct a LineItem object in the same way, and add it to the items array list. Here is the complete source code.
ch23/parser/ItemListParser.java
1import java.io.File;2import java.io.IOException;3import java.util.ArrayList;4import javax.xml.parsers.DocumentBuilder;
5import javax.xml.parsers.DocumentBuilderFactory;6import javax.xml.parsers.ParserConfigurationException;7import javax.xml.xpath.XPath;8import javax.xml.xpath.XPathExpressionException;9import javax.xml.xpath.XPathFactory;10import org.w3c.dom.Document;11import org.xml.sax.SAXException;1213/**14An XML parser for item lists.15*/16public class ItemListParser17{18private DocumentBuilder builder;19private XPath path;2021/**22Constructs a parser that can parse item lists.23*/24public ItemListParser()25throws ParserConfigurationException26{27DocumentBuilderFactory dbfactory28= DocumentBuilderFactory.newInstance();29builder = dbfactory.newDocumentBuilder();30XPathFactory xpfactory = XPathFactory.newInstance();31path = xpfactory.newXPath();32}3334/**35Parses an XML file containing an item list.36@param fileName the name of the file37@return an array list containing all items in the XML file38*/39public ArrayList<LineItem> parse(String fileName)40throws SAXException, IOException, XPathExpressionException41{42File f = new File(fileName);43Document doc = builder.parse(f);4445ArrayList<LineItem> items = new ArrayList<LineItem>();46int itemCount = Integer.parseInt(path.evaluate(47"count(/items/item)", doc));48for (int i = 1; i <= itemCount; i++)49{50String description = path.evaluate(51"/items/item[" + i + "]/product/description", doc);52double price = Double.parseDouble(path.evaluate(53"/items/item[" + i + "]/product/price", doc));54Product pr = new Product(description, price);55int quantity = Integer.parseInt(path.evaluate(56"/items/item[" + i + "]/quantity", doc));57LineItem it = new LineItem(pr, quantity);58items.add(it);59}60return items;61}62}
ch23/parser/ItemListParserDemo.java
1import java.util.ArrayList;23/**4This program parses an XML file containing an item list.5It prints out the items that are described in the XML file.6*/7public class ItemListParserDemo8{9public static void main(String[] args) throws Exception10{11ItemListParser parser = new ItemListParser();12ArrayList<LineItem> items = parser.parse("items.xml");13for (LineItem anItem : items)14System.out.println(anItem.format());15}16}
Program Run
Ink Jet Refill Kit 29.95 8 239.6
4-port Mini Hub 19.95 4 79.8Which XPath statement yields the name of the root element of any XML document?
Random Fact 23.2 Grammars, Parsers, and Compilers
Grammars are very important in many areas of computer science to describe the structure of computer programs or data formats. To introduce the concept of a grammar, consider this set of rules for a set of simple English language sentences:
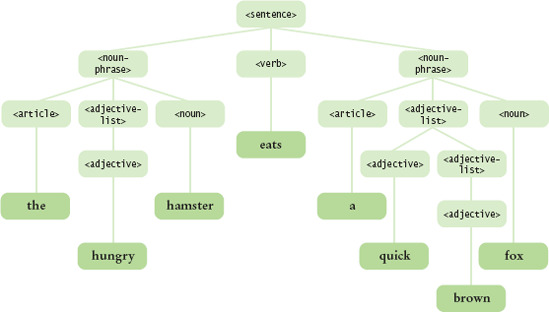
A sentence has a noun phrase followed by a verb and another noun phrase.
A noun phrase consists of an article followed by an adjective list followed by a noun.
An adjective list consists of an adjective or an adjective followed by an adjective list.
Articles are "a" and "the".
Adjectives are "quick", "brown", "lazy", and "hungry".
Nouns are "fox", "dog", and "hamster".
Verbs are "jumps over" and "eats".
Here are two sentences that follow these rules:
The quick brown fox jumps over the lazy dog.
The hungry hamster eats a quick brown fox.
Symbolically, these rules can be expressed by a formal grammar:
<sentence> ::= <noun-phrase> <verb> <noun-phrase> <noun-phrase> ::= <article> <adjective-list> <noun> <adjective-list> ::= <adjective> | <adjective> <adjective-list> <article> ::= a | the <adjective> ::= quick | brown | lazy | hungry <noun> ::= fox | dog | hamster <verb> ::= jumps over | eats
Here the symbol ::= means "can be replaced with" and | separates alternate choices. For example, <article> can be replaced with "a" or "the".
The grammar symbols, such as <noun>, happen to be enclosed in angle brackets just like XML tags, but they are different from tags. One purpose of a grammar is to produce strings that are valid according to the grammar, by starting with the start symbol (<sentence> in this example) and applying replacement rules until the resulting string is free from symbols. See the table on the facing page for an example of the replacement process.
If you have a grammar and a string, such as "the hungry hamster eats a quick brown fox" or "a brown jumps over hamster quick lazy", you can parse the sentence: that is, check whether the sentence is described by the grammar rules and, if it is, show how it can be derived from the start symbol. One way to show the derivation is to construct a parse tree(see Figure 5).
String | Rule |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
A parser is a program that reads strings and decides whether the input conforms to the rules of a certain grammar. Some parsers—such as the DOM XML parser—build a parse tree in the process or report an error message when a parse tree cannot be constructed. Other parsers—such as the SAX XML parser—call user-specified methods whenever a part of the input was successfully parsed.
The most important use for parsers is inside compilers for programming languages. Just as our grammar can describe (some) simple English language sentences, the valid "sentences" in a programming language can be described by a grammar. The actual grammar for the Java programming language occupies about 15 pages in The Java Language Specification (http://java.sun.com/docs/book/jls
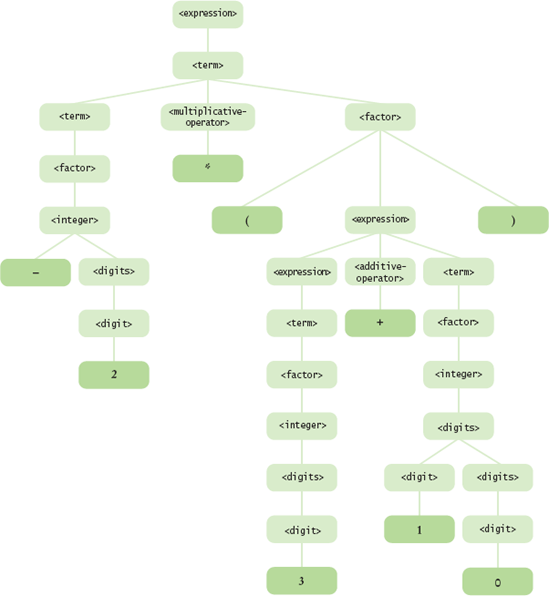
<expression> ::= <term> | <expression> <additive-operator> <term> <additive-operator> ::= + | - <term> ::= <factor> | <term> <multiplicative-operator> <factor>
<multiplicative-operator> ::= * | / <factor> ::= <integer> | ( <expression> ) <integer> ::= <digits> | - <digits> <digits> ::= <digit> | <digit> <digits> <digit> ::= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
An example of a valid expression in this grammar is
−2 * (3 + 10)
Figure 6 shows the parse tree for this expression.
In a compiler, parsing the program source is the first step toward generating code that the target processor (the Java virtual machine in the case of Java) can execute. Writing a parser is a challenging and interesting task. You may at one point in your studies take a course in compiler construction, in which you learn how to write a parser and how to generate code from the parsed input. Fortunately, to use XML you don't have to know how the parser does its job. You simply ask the XML parser to read the XML input and then process the resulting Document tree.
In the preceding section, you saw how to read an XML file into a Document object and how to analyze the contents of that object. In this section, you will see how to do the opposite—build up a Document object and then save it as an XML file. Of course, you can also generate an XML file simply as a sequence of print statements. However, that is not a good idea—it is easy to build an illegal XML document in this way, as when data contain special characters such as < or &.
Recall that you needed a DocumentBuilder object to read in an XML document. You also need such an object to create a new, empty document. Thus, to create a new document, first make a document builder factory, then a document builder, and finally the empty document:
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); DocumentBuilder builder = factory.newDocumentBuilder(); Document doc = builder.newDocument(); // An empty document
Now you are ready to insert nodes into the document. You use the createElement method of the Document interface to create the elements that you need.
Element priceElement = doc.createElement("price");Note
The Document interface has methods to create elements and text nodes.
You set element attributes with the setAttribute method. For example,
priceElement.setAttribute("currency", "USD");You have to work a bit harder for inserting text. First create a text node:
Text textNode = doc.createTextNode("29.95");Then add the text node to the element:
priceElement.appendChild(textNode);
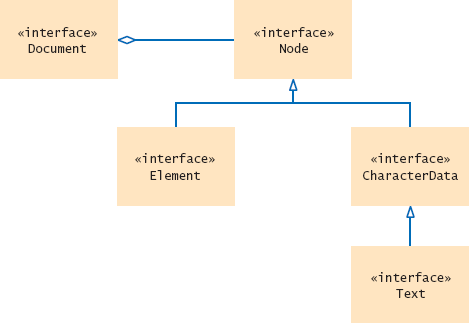
Figure 7 shows the DOM interfaces for XML document nodes. To construct the tree structure of a document, it is a good idea to use a set of helper methods.
We start out with a helper method that creates an element with text:
private Element createTextElement(String name, String text)
{
Text t = doc.createTextNode(text);
Element e = doc.createElement(name);
e.appendChild(t);
return e;
}Using this helper method, we can construct a price element like this:
Element priceElement = createTextElement("price", "29.95");Next, we write a helper method to create a product element from a Product object:
private Element createProduct(Product p)
{
Element e = doc.createElement("product");
e.appendChild(createTextElement("description", p.getDescription()));
e.appendChild(createTextElement("price", "" + p.getPrice()));
return e;
}This helper method is called from the createItem helper method:
private Element createItem(LineItem anItem)
{
Element e = doc.createElement("item");
e.appendChild(createProduct(anItem.getProduct()));
e.appendChild(createTextElement("quantity", "" + anItem.getQuantity()));
return e;
}A helper method
private Element createItems(ArrayList<LineItem> items)
for the items element is implemented in the same way—see the program listing at the end of this section.
Now you build the document as follows:
ArrayList<LineItem> items = ...; doc = builder.newDocument(); Element root = createItems(items); doc.appendChild(root);
Once you have built the document, you will want to write it to a file. The DOM standard provides the LSSerializer interface for this purpose. Unfortunately, the DOM standard uses very generic methods, which makes the code that is required to obtain a serializer object look like a "magic incantation":
DOMImplementation impl = doc.getImplementation();
DOMImplementationLS implLS
= (DOMImplementationLS) impl.getFeature("LS", "3.0");
LSSerializer ser = implLS.createLSSerializer();Note
Use an LSSerializer to write a DOM document.
Once you have the serializer object, you simply use the writeToString method:
String str = ser.writeToString(doc);
By default, the LSSerializer produces an XML document without spaces or line breaks. As a result, the output looks less pretty, but it is actually more suitable for parsing by another program because it is free from unnecessary white space.
If you want white space, you use yet another magic incantation after creating the serializer:
ser.getDomConfig().setParameter("format-pretty-print", true);Here is an example program that shows how to build and print an XML document.
ch23/builder/ItemListBuilder.java
1import java.util.ArrayList;2import javax.xml.parsers.DocumentBuilder;3import javax.xml.parsers.DocumentBuilderFactory;4import javax.xml.parsers.ParserConfigurationException;5import org.w3c.dom.Document;6import org.w3c.dom.Element;7import org.w3c.dom.Text;89/**10Builds a DOM document for an array list of items.11*/12public class ItemListBuilder13{14private DocumentBuilder builder;15private Document doc;1617/**18Constructs an item list builder.19*/20public ItemListBuilder()21throws ParserConfigurationException22{23DocumentBuilderFactory factory24= DocumentBuilderFactory.newInstance();25builder = factory.newDocumentBuilder();26}27
28/**29Builds a DOM document for an array list of items.30@param items the items31@return a DOM document describing the items32*/33public Document build(ArrayList<LineItem> items)34{35doc = builder.newDocument();36doc.appendChild(createItems(items));37return doc;38}3940/**41Builds a DOM element for an array list of items.42@param items the items43@return a DOM element describing the items44*/45private Element createItems(ArrayList<LineItem> items)46{47Element e = doc.createElement("items");4849for (LineItem anItem : items)50e.appendChild(createItem(anItem));5152return e;53}5455/**56Builds a DOM element for an item.57@param anItem the item58@return a DOM element describing the item59*/60private Element createItem(LineItem anItem)61{62Element e = doc.createElement("item");6364e.appendChild(createProduct(anItem.getProduct()));65e.appendChild(createTextElement(66"quantity", "" + anItem.getQuantity()));6768return e;69}7071/**72Builds a DOM element for a product.73@param p the product74@return a DOM element describing the product75*/76private Element createProduct(Product p)77{78Element e = doc.createElement("product");7980e.appendChild(createTextElement(81"description", p.getDescription()));82e.appendChild(createTextElement(83"price", "" + p.getPrice()));8485return e;86}
8788private Element createTextElement(String name, String text)89{90Text t = doc.createTextNode(text);91Element e = doc.createElement(name);92e.appendChild(t);93return e;94}95}
ch23/builder/ItemListBuilderDemo.java
1import java.util.ArrayList;2import org.w3c.dom.DOMImplementation;3import org.w3c.dom.Document;4import org.w3c.dom.ls.DOMImplementationLS;5import org.w3c.dom.ls.LSSerializer;67/**8This program demonstrates the item list builder. It prints the XML9file corresponding to a DOM document containing a list of items.10*/11public class ItemListBuilderDemo12{13public static void main(String[] args) throws Exception14{15ArrayList<LineItem> items = new ArrayList<LineItem>();16items.add(new LineItem(new Product("Toaster", 29.95), 3));17items.add(new LineItem(new Product("Hair dryer", 24.95), 1));1819ItemListBuilder builder = new ItemListBuilder();20Document doc = builder.build(items);21DOMImplementation impl = doc.getImplementation();22DOMImplementationLS implLS23= (DOMImplementationLS) impl.getFeature("LS", "3.0");24LSSerializer ser = implLS.createLSSerializer();25String out = ser.writeToString(doc);2627System.out.println(out);28}29}
This program uses the Product and LineItem classes from Chapter 12. The LineItem class has been modified by adding getProduct and getQuantity methods.
Program Run
<?xml version="1.0" encoding="UTF-8"?><items><item><product> <description>Toaster</description><price>29.95</price></product> <quantity>3</quantity></item><item><product><description>Hair dryer </description><price>24.95</price></product><quantity>1</quantity> </item></items>
How would you write a document to the file
output.xml?
In this section you will learn how to specify rules for XML documents of a particular type. There are several mechanisms for this purpose. The oldest and simplest mechanism is a Document Type Definition (DTD), the topic of this section. We discuss other mechanisms in Special Topic 23.1 on page 938.
Consider a document of type items. Intuitively, items denotes a sequence of item elements. Each item element contains a product and a quantity. A product contains a description and a price. Each of these elements contains text describing the product's description, price, and quantity. The purpose of a DTD is to formalize this description.
A DTD is a sequence of rules that describes
The valid attributes for each element type
The valid child elements for each element type
Note
A DTD is a sequence of rules that describes the valid child elements and attributes for each element type.
Let us first turn to child elements. The valid child elements of an element are described by an ELEMENT rule:
<!ELEMENT items (item*)>
This means that an item list must contain a sequence of 0 or more item elements.
As you can see, the rule is delimited by <! ... >, and it contains the name of the element whose children are to be constrained (items), followed by a description of what children are allowed.
Next, let us turn to the definition of an item node:
<!ELEMENT item (product, quantity)>
This means that the children of an item node must be a product node, followed by a quantity node.
The definition for a product is similar:
<!ELEMENT product (description, price)>
Finally, here are the definitions of the three remaining node types:
<!ELEMENT quantity (#PCDATA)> <!ELEMENT description (#PCDATA)> <!ELEMENT price (#PCDATA)>
The symbol #PCDATA refers to text, called "parsed character data" in XML terminology. The character data can contain any characters. However, certain characters, such as < and &, have special meaning in XML and need to be replaced if they occur in character data. Table 2 shows the replacements for special characters.
The complete DTD for an item list has six rules, one for each element type:
<!ELEMENT items (item*)> <!ELEMENT item (product, quantity)> <!ELEMENT product (description, price)> <!ELEMENT quantity (#PCDATA)> <!ELEMENT description (#PCDATA)> <!ELEMENT price (#PCDATA)>
Let us have a closer look at the descriptions of the allowed children. Table 3 shows the expressions used to describe the children of an element. The EMPTY reserved word is self-explanatory: an element that is declared as EMPTY may not have any children. For example, the HTML DTD defines the img element to be EMPTY—an image has only attributes, specifying the image source, size, and placement, and no children.
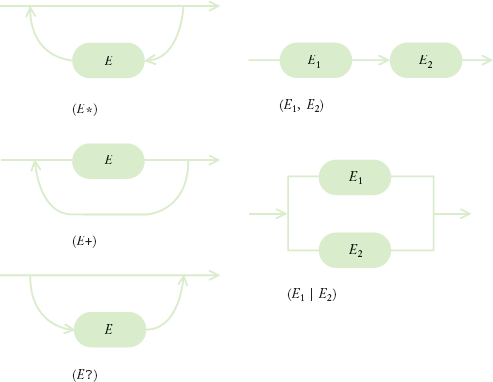
Table 23.3. Regular Expressions for Element Content
Rule Description | Element Content |
|---|---|
No children allowed | |
| Any sequence of 0 or more elements E |
| Any sequence of 1 or more elements E |
| Optional element E (0 or 1 occurrences allowed) |
| Element E1, followed by E2, ... |
| Element E1 or E2 or ... |
| Text only |
| Any sequence of text and elements E1, E2, ..., in any order |
| Any children allowed |
More interesting child rules can be formed with the regular expression operations (* + ?, |). (See Table 3 and Figure 8. Also see Productivity Hint 11.1 for more information on regular expressions.) You have already seen the * ("0 or more") and, (sequence) operations. The children of an items element are 0 or more item elements, and the children of an item are a sequence of product and description elements.
You can also combine these operations to form more complex expressions. For example,
<!ELEMENT section (title, (paragraph | (image, title?))+)
defines an element section whose children are:
A
titleelementA sequence of one or more of the following:
paragraphelementsimageelements followed by optionaltitleelements
Thus,
<section> <title/> <paragraph/> <image/> <title/> <paragraph/> </section>is valid, but
<section> <paragraph/> <paragraph/> <title/> </section>
is not—there is no starting title, and the title at the end doesn't follow an image.
You already saw the (#PCDATA) rule. It means that the children can consist of any character data. For example, in our product list DTD, the description element can have any character data inside.
You can also allow mixed content—any sequence of character data and specified elements. However, in mixed content, you have no control over the order in which the elements appear. As explained in Quality Tip 23.2 on page 912, you should avoid mixed content for DTDs that describe data sets. This feature is intended for documents that contain both text and markup instructions, such as HTML pages.
Finally, you can allow a node to have children of any type—you should avoid that for DTDs that describe data sets.
You now know how to specify what children a node may have. A DTD also gives you control over the allowed attributes of an element. An attribute description looks like this:
<!ATTLISTElementAttributeTypeDefault>
The most useful attribute type descriptions are listed in Table 4. The CDATA type describes any sequence of character data. As with #PCDATA, certain characters, such as < and &, need to be encoded (as <, & and so on). There is no practical difference between the CDATA and #PCDATA types. Simply use CDATA in attribute declarations and #PCDATA in element declarations.
Table 23.4. Common Attribute Types
Type Description | Attribute Type |
|---|---|
| Any character data |
| One of V1, V2, ... |
Rather than allowing arbitrary attribute values, you can specify a finite number of choices. For example, you may want to restrict a currency attribute to U.S. dollar, euro, and Japanese yen. Then use the following declaration:
<!ATTLIST price currency (USD | EUR | JPY) #REQUIRED>
You can use letters, numbers, and the hyphen (-) and underscore (_) characters for the attribute values.
There are other type descriptions that are less common in practice. You can find them in the XML reference (http://www.xml.com/axml/axml.html
The attribute type description is followed by a "default" declaration. The reserved words that can appear in a "default" declaration are listed in Table 5.
For example, this attribute declaration describes that each price element must have a currency attribute whose value is any character data:
<!ATTLIST price currency CDATA #REQUIRED>
To fulfill this declaration, each price element must have a currency attribute, such as <price currency="USD">. A price without a currency would not be valid.
For an optional attribute, you use the #IMPLIED reserved word instead.
<!ATTLIST price currency CDATA #IMPLIED>
That means that you can supply a currency attribute in a price element, or you can omit it. If you omit it, then the application that processes the XML data implicitly assumes some default currency.
A better choice would be to supply the default value explicitly:
<!ATTLIST price currency CDATA "USD">
That means that the currency attribute is understood to mean USD if the attribute is not specified. An XML parser will then report the value of currency as USD if the attribute was not specified.
Finally, you can state that an attribute can only be identical to a particular value. For example, the rule
<!ATTLIST price currency CDATA #FIXED "USD">
means that a price element must either not have a currency attribute at all (in which case the XML parser will report its value as USD), or specify the currency attribute as USD. Naturally, this kind of rule is not very common.
Table 23.5. Attribute Defaults
Default Declaration | Explanation |
|---|---|
| Attribute is required |
| Attribute is optional |
V | Default attribute, to be used if attribute is not specified |
| Attribute must either be unspecified or contain this value |
You have now seen the most common constructs for DTDs. Using these constructs, you can define your own DTDs for XML documents that describe data sets. In the next section, you will see how to specify which DTD an XML document should use, and how to have the XML parser check that a document conforms to its DTD.
When you reference a DTD with an XML document, you can instruct the parser to check that the document follows the rules of the DTD. That way, the parser can check errors in the document.
In the preceding section you saw how to develop a DTD for a class of XML documents. The DTD specifies the permitted elements and attributes in the document. An XML document has two ways of referencing a DTD:
Note
An XML document can contain its DTD or refer to a DTD that is stored elsewhere.
A DTD is introduced with the DOCTYPE declaration. If the document contains its DTD, then the declaration looks like this:
<!DOCTYPErootElement[rules]>
For example, an item list can include its DTD like this:
<?xml version="1.0"?>
<!DOCTYPE items [
<!ELEMENT items (item*)>
<!ELEMENT item (product, quantity)>
<!ELEMENT product (description, price)>
<!ELEMENT quantity (#PCDATA)>
<!ELEMENT description (#PCDATA)>
<!ELEMENT price (#PCDATA)>
]>
<items>
<item>
<product>
<description>Ink Jet Refill Kit</description>
<price>29.95</price>
</product>
<quantity>8</quantity>
</item>
<item>
<product>
<description>4-port Mini Hub</description>
<price>19.95</price>
</product>
<quantity>4</quantity>
</item>
</items>However, if the DTD is more complex, then it is better to store it outside the XML document. In that case, you use the SYSTEM reserved word inside the DOCTYPE declaration to indicate that the system that hosts the XML processor must locate the DTD. The SYSTEM reserved word is followed by the location of the DTD. For example, a DOCTYPE declaration might point to a local file
<!DOCTYPE items SYSTEM "items.dtd">
Alternatively, the resource might be an URL anywhere on the Web:
<!DOCTYPE items SYSTEM "http://www.mycompany.com/dtds/items.dtd">
For commonly used DTDs, the DOCTYPE declaration can contain a PUBLIC reserved word. For example,
<!DOCTYPE faces-config PUBLIC "-//Sun Microsystems, Inc.//DTD JavaServer Faces Config 1.0//EN" "http://java.sun.com/dtd/web-facesconfig_1_0.dtd">
A program parsing the DTD can look at the public identifier. If it is a familiar identifier, then it need not spend time retrieving the DTD from the URL.
Note
When referencing an external DTD, you must supply an URL for locating the DTD.
When you include a DTD with an XML document, then you can tell the parser to validate the document. That means that the parser will check that all child elements and attributes of an element conform to the ELEMENT and ATTLIST rules in the DTD. If a document is invalid, then the parser reports an error. To turn on validation, you use the setValidating method of the DocumentBuilderFactory class before calling the newDocumentBuilder method:
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); factory.setValidating(true); DocumentBuilder builder = factory.newDocumentBuilder(); Document doc = builder.parse(...);
Note
When your XML document has a DTD, you can request validation when parsing.
Validation can simplify your code for processing XML documents. For example, if the DTD specifies that the child elements of each item element are product and quantity elements in that order, then you can rely on that fact and don't need to put tedious checks in your code.
Note
When you parse an XML file with a DTD, tell the parser to ignore white space.
If the parser has access to the DTD, it can make another useful improvement. By default, the parser converts all spaces in the input document to text, even if the spaces are only used to logically line up elements. As a result, the document contains text nodes that are wasteful and can be confusing when you analyze the document tree.
To make the parser ignore white space, call the setIgnoringElementContentWhitespace method of the DocumentBuilderFactory class.
factory.setValidating(true); factory.setIgnoringElementContentWhitespace(true);
Finally, if the parser has access to the DTD, it can fill in default values for attributes. For example, suppose a DTD defines a currency attribute for a price element:
<!ATTLIST price currency CDATA "USD">
If a document contains a price element without a currency attribute, then the parser can supply the default:
String attributeValue = priceElement.getAttribute("currency");
// Gets "USD" if no currency specifiedThis concludes our discussion of XML. You now know enough XML to put it to work for describing data formats. Whenever you are tempted to use a "quick and dirty" file format, you should consider using XML instead. By using XML for data interchange, your programs become more professional, robust, and flexible. This chapter covers the most important aspects of XML for everyday programming. For more advanced features that can be useful in specialized situations, please see http://www.xml.com/axml/axml.htmlhttp://www.w3c.org/xmlhttp://java.sun.com/xml
How can a DTD specify that a
productelement can contain adescriptionand apriceelement, in any order?How can a DTD specify that the
descriptionelement has an optional attributelanguage?
Describe the purpose of XML and the structure of an XML document.
XML allows you to encode complex data, independent from any programming language, in a form that the recipient can easily parse.
XML files are readable by computer programs and by humans.
XML-formatted data files are resilient to change.
XML describes the meaning of data, not how to display them.
An XML document starts out with an XML declaration and contains elements and text.
An element can contain text, child elements, or both (mixed content). For data descriptions, avoid mixed content.
Elements can have attributes. Use attributes to describe how to interpret the element content.
Use a parser and the XPath language to process an XML document.
A parser is a program that reads a document, checks whether it is syntactically correct, and takes some action as it processes the document.
A streaming parser reports the building blocks of an XML document. A tree-based parser builds a document tree.
A
DocumentBuildercan read an XML document from a file, URL, or input stream. The result is aDocumentobject, which contains a tree.An XPath describes a node or node set, using a notation similar to that for directory paths.
Write Java programs that create XML documents.
The
Documentinterface has methods to create elements and text nodes.Use an
LSSerializerto write a DOM document.
Explain the use of DTDs for validating XML documents.
A DTD is a sequence of rules that describes the valid child elements and attributes for each element type.
An XML document can contain its DTD or refer to a DTD that is stored elsewhere.
When referencing an external DTD, you must supply an URL for locating the DTD.
When your XML document has a DTD, you can request validation when parsing.
When you parse an XML file with a DTD, tell the parser to ignore white space.
javax.xml.parsers.DocumentBuilder org.w3c.dom.DOMConfiguration
newDocument setParameter
parse org.w3c.dom.DOMImplementation
javax.xml.parsers.DocumentBuilderFactory getFeature
newDocumentBuilder org.w3c.dom.Element
newInstance getAttribute
setIgnoringElementContentWhitespace setAttribute
setValidating org.w3c.dom.ls.DOMImplementationLS
javax.xml.xpath.XPath createLSSerializer
evaluate org.w3c.dom.ls.LSSerializer
javax.xml.xpath.XPathExpressionException getDomConfig
javax.xml.xpath.XPathFactory writeToString
newInstance
newXPath
org.w3c.dom.Document
createElement
createTextNode
getImplementationR23.1 Give some examples to show the differences between XML and HTML.
R23.2 Design an XML document that describes a bank account.
R23.3 Draw a tree view for the XML document you created in Exercise R23.2.
R23.4 Write the XML document that corresponds to the parse tree in Figure 5.
R23.5 Write the XML document that corresponds to the parse tree in Figure 6.
R23.6 Make an XML document describing a book, with child elements for the author name, the title, and the publication year.
R23.7 Add a description of the book's language to the document of the preceding exercise. Should you use an element or an attribute?
R23.8 What is mixed content? What problems does it cause?
R23.9 Design an XML document that describes a purse containing three quarters, a dime, and two nickels.
R23.10 Explain why a paint program, such as Microsoft Paint, is a WYSIWYG program that is also "what you see is all you've got".
R23.11 Consider the XML file
<purse>
<coin>
<value>0.5</value>
<name lang="en">half dollar</name>
</coin>
<coin><value>0.25</value>
<name lang="en">quarter</name>
</coin>
</purse>What are the values of the following XPath expressions?
/purse/coin[1]/value/purse/coin[2]/name/purse/coin[2]/name/@langname(/purse/coin[2]/*[1])count(/purse/coin)count(/purse/coin[2]/name)
R23.12 With the XML file of Exercise R23.11, give XPath expressions that yield:
the value of the first coin.
the number of coins.
the name of the first child element of the first
coinelement.the name of the first attribute of the first coin's
nameelement. (The expression@*selects the attributes of an element.)the value of the
langattribute of the second coin'snameelement.
R23.13 Design a DTD that describes a bank with bank accounts.
R23.14 Design a DTD that describes a library patron who has checked out a set of books. Each book has an ID number, an author, and a title. The patron has a name and telephone number.
R23.15 Write the DTD file for the following XML document
<?xml version="1.0"?>
<productlist>
<product>
<name>Comtrade Tornado</name>
<price currency="USD">2495</price>
<score>60</score>
</product>
<product>
<name>AMAX Powerstation 75</name>
<price>2999</price>
<score>62</score>
</product>
</productlist>R23.16 Design a DTD for invoices, as described in How To 23.3 on page 936.
R23.17 Design a DTD for simple English sentences, as described in Random Fact 23.2 on page 920.
R23.18 Design a DTD for arithmetic expressions, as described in Random Fact 23.2 on page 920.
P23.1 Write a program that can read XML files, such as
<purse>
<coin>
<value>0.5</value>
<name>half dollar</name>
</coin>
...
</purse>Your program should construct a Purse object and print the total value of the coins in the purse.
P23.2 Building on Exercise P23.1, make the program read an XML file as described in that exercise. Then print an XML file of the form
<purse>
<coins>
<coin>
<value>0.5</value>
<name>half dollar</name>
</coin>
<quantity>3</quantity>
</coins>
<coins>
<coin>
<value>0.25</value>
<name>quarter</name>
</coin>
<quantity>2</quantity>
</coins>
</purse>P23.3 Repeat Exercise P23.1, using a DTD for validation.
P23.4 Write a program that can read XML files, such as
<bank>
<account>
<number>3</number>
<balance>1295.32</balance>
</account>
...
</bank>Your program should construct a Bank object and print the total value of the balances in the accounts.
P23.5 Repeat Exercise P23.4, using a DTD for validation.
P23.6 Enhance Exercise P23.4 as follows: First read the XML file in, then add 10 percent interest to all accounts, and write an XML file that contains the increased account balances.
P23.7 Write a DTD file that describes documents that contain information about countries: name of the country, its population, and its area. Create an XML file that has five different countries. The DTD and XML should be in different files. Write a program that uses the XML file you wrote and prints:
The country with the largest area.
The country with the largest population.
The country with the largest population density (people per square kilometer).
P23.8 Write a parser to parse invoices using the invoice structure described in How To 23.1 on page 909. The parser should parse the XML file into an Invoice object and print out the invoice in the format used in Chapter 12.
P23.9 Modify Exercise P23.8 to support separate shipping and billing addresses. Supply a modified DTD with your solution.
P23.10 Write a document builder that turns an invoice object, as defined in Chapter 12, into an XML file of the format described in How To 23.1 on page 909.
P23.11 Modify Exercise P23.10 to support separate shipping and billing addresses.
P23.12 Write a program that can read an XML document of the form
<rectangle> <x>5</x> <y>10</y> <width>20</width> <height>30</height> </rectangle>
and draw the shape in a window.
P23.13 Write a program that can read an XML document of the form
<ellipse> <x>5</x> <y>10</y> <width>20</width> <height>30</height> </ellipse>
and draw the shape in a window.
P23.14 Write a program that can read an XML document of the form
<rectangularshape shape="ellipse"> <x>5</x> <y>10</y> <width>20</width> <height>30</height> </rectangularshape>
Support shape attributes "rectangle", "roundrectangle", and "ellipse".
Draw the shape in a window.
P23.15 Write a program that can read an XML document of the form
<polygon>
<point>
<x>5</x>
<y>10</y>
</point>
...</polygon>
and draw the shape in a window.
P23.16 Write a program that can read an XML document of the form
<drawing>
<rectangle>
<x>5</x>
<y>10</y>
<width>20</width>
<height>30</height>
</rectangle>
<line>
<x1>5</x1>
<y1>10</y1>
<x2>25</x2>
<y2>40</y2>
</line>
<message>
<text>Hello, World!</text>
<x>20</x>
<y>30</y>
</message>
</drawing>and show the drawing in a window.
P23.17 Repeat Exercise P23.16, using a DTD for validation.
Project 23.1 Following Exercise P12.7, design an XML format for the appointments in an appointment calendar. Write a program that first reads in a file with appointments, then another file of the format
<commands>
<add>
<appointment>
...
</appointment>
</add>
...
<remove>
<appointment>
...
</appointment>
</remove>
</commands>Your program should process the commands and then produce an XML file that consists of the updated appointments.
Project 23.2 Write a program to simulate an airline seat reservation system, using XML documents. Reference Exercise P12.8 for the airplane seat information. The program reads a seating chart, in an XML format of your choice, and a command file, in an XML format of your choice, similar to the command file of the preceding exercise. Then the program processes the commands and produces an updated seating chart.
Your answer should look similar to this:
<student> <name>James Bond</name> <id>007</id> </student>
Most browsers display a tree structure that indicates the nesting of the tags. Some browsers display nothing at all because they can't find any HTML tags.
The text
hamster.jpgis never displayed, so it should not be a part of the document. Instead, thesrcattribute tells the browser where to find the image that should be displayed.29.95.
name(/*[1]).The
createTextElementmethod is useful for creating other documents.First construct a string, as described, and then use a
PrintWriterto save the string to a file.<!ELEMENT item (product, quantity?)><!ELEMENT product ((description, price) | (price, description))><!ATTLIST description language CDATA #IMPLIED>