
3 Technology Use Cases
In the 1970s, the Internet was a small, decentralized collective of DARPA computers, called ARPANET. The personal-computer revolution that followed built upon that foundation, stoking optimism encapsulated by John Perry Barlow’s 1996 manifesto “A Declaration of the Independence of Cyberspace” (www.eff.org/cyberspace-independence). Barlow described a chaotic digital utopia, where “netizens” self-govern and the institutions of old hold no sway. “On behalf of the future, I ask you of the past to leave us alone,” he writes. “You are not welcome among us. You have no sovereignty where we gather.”
This is not the Internet we know today. Two decades later, the vast majority of communications flow through a set of central servers run by a small group of corporations under the influence of those companies and other institutions. Netflix, for instance, now comprises 40 percent of all North American Internet traffic. Engineers anticipated this convergence. In the late 1960s, key architects of the system for exchanging small packets of data that gave birth to the Internet predicted the rise of a centralized “computer utility” that would offer computing much the same way that power companies provide electricity. Today, that model is largely embodied by the cloud-computing giants Amazon, Google, Azure, and other cloud-computing companies. They offer convenience at the expense of privacy. Internet users now regularly submit to terms-of-service agreements that give companies a license to share their personal data with other institutions, from advertisers to governments. In the United States, the Electronic Communications Privacy Act of 1986 (ECPA), a law that predates the Web, allows law enforcement to obtain without a warrant private data that citizens entrust to third parties, including location data passively gathered from cell phones and the contents of emails that have either been opened or left unattended for 180 days. Note that under the ECPA only a subpoena or an 18 U.S.C. §2703(d) order with little judicial review is needed to allow access to the aforementioned private data. As Edward Snowden’s leaks have shown, this massive information set allows intelligence agencies to focus on just a few key targets in order to monitor large portions of the world’s population. The National Security Agency (NSA) wiretaps the connections between data centers owned by Google and Yahoo, allowing the agency to collect users’ data as it flows across the companies’ networks. A lack of trust surrounds the U.S. cloud industry. The NSA collects data through formal arrangements with tech companies, ingests web traffic as it enters and leaves the United States, and deliberately weakens cryptographic standards. The solution, as we have espoused in this book, is to make the Web and cloud computing less centralized and more distributed. For privacy advocates such as Access Now (accessnow.org), the goal is to make it harder to do surveillance. When you couple a secure, self-hosted platform with properly implemented cryptography, you can make NSA-style spying and network intrusion difficult and expensive.
While the peer-to-peer technology that Bitcoin and Ethereum employ is not new, its implementation is a breakthrough technical achievement. The system’s elegance has led some to wonder: if money can be decentralized and somewhat anonymized, can we use the same model for other applications such as storage, communications, and computing? We will explore this as the chapter proceeds, but bear in mind this would require time and effort and lots of change to the existing infrastructure. Since the World Wide Web went mainstream in 1994, we’ve seen the network expand to encompass almost every aspect of human life. The infrastructure of the Internet and the services built on top of it are dependent on each other, one informing the other as new service use cases and technologies arise. There have been two clear generations in the web-based services and structure of the Web thus far, but today we are moving into a third generation.
We will look at the storage technologies that are likely to form its backbone: the decentralized storage network IPFS—the InterPlanetary File System—and its incentive platform Filecoin, and Swarm, an emerging Ethereum-oriented storage platform that uses IPFS. We will also look at decentralized supercomputers like Golem that are creating a global market for computing power, and messaging systems like Whisper, which facilitates secure and decentralized communications. These technologies and others will become the foundation for a new Internet.
Web Versions 1 and 2
Web 1.0, an extension of DARPA’s ARPANET, was the first iteration of a new idea—a return to centralization after the distributed client server idea failed. Just before the Web came into use in the Wall Street business center, personal computers used by businesses had a “fat client” distributed setup, in which each user had all the application code and data on their individual machine. The “fat client” became expensive and impractical to synchronize all these machines and data. So corporate intranets started to emerge with HTML and Java servlets leading the way to the Web 1.0 idea: if we can connect all the computers in the world through a global network—the Internet—then we can trade and exchange assets and for humanity’s sake make the collective knowledge universally accessible. For this mass of data to be usable, it needed to be indexed and browsable. This necessity was behind the innovation that led to the first generation of the World Wide Web. The Netscape browser was the tool used to search, find, and render the response data.
Web 2.0 furthered the use of this global resource. The pool of knowledge and content began growing at an extreme pace. Surface net data has grown fourfold since 2012. Programs could connect and use the Web to store information and communicate with each other. Centralized intermediates, such as Google, created large databases and messaging, offering scalable resources and routing traffic. While these new information-handling organizations have changed our way of life with convenience services, they also use their centralized position for profit and power.
These centralized intermediates (like Google) sell context-sensitive targeted advertising for huge profits and give back nothing more than a convenient messaging interface to the users—the content producers. In their paper “Swap, Swear and Swindle: Incentive System for Swarm,” Viktor Trón, Aron Fischer, Dániel A. Nagy, Zsolt Felföldi, and Nick Johnson characterized this as: “We give you scalable hosting that would cope with any traffic your audience throws at it, but you give us substantial control over your content; we are going to track each member of your audience and learn—and own—as much of their personal data as we can, we are going to pick who can and who cannot see it, we are going to proactively censor it and we may even report on you, for the same reason.”
So the bottom line is that new media organizations and content producers created immense value for their organizations, and we the users receive less than a quid pro quo in exchange.
To further exacerbate the problem, as the Web has grown it has been hampered by scaling limits. Central nodes or servers required increased bandwidth to handle increasing data flow. To compound the problem, the security available using Web 2.0 technology never achieved a level required for the new communications and commerce services provided through the Web. We see data breaches where nefarious syndicates steal our financial access data using SQL and code injection and disable financial, retail, and government websites and their services with denial-of-service attacks which take down these centralized servers almost weekly. According to Juniper Research, “the rapid digitization of consumers’ lives and enterprise records will increase the cost of data breaches to $2.1 trillion globally by 2019, increasing to almost four times the estimated cost of breaches in 2015.” (https://www.juniperresearch.com/press/press-releases/cybercrime-cost-businesses-over-2trillion) The stage is set for a paradigm shift with a host of new technologies emerging.
Web 3.0
Following the trend set by earlier iterations, and to correct some of the issues we have described, Web 3.0 proposes a change in the way content and programs interact. If central intermediaries like Google are removed from the picture, many of the issues we have today are removed with them. Blockchain technologies like Bitcoin and Ethereum use public key cryptography to secure the connection and communication between programs and data. This is an alternative to the centrally issued SSL certificates used today. There is no central intermediary routing traffic, so connections can dynamically find the most efficient pathway through the Internet and route around congestion or damage. Additionally, for the coming Web 3.0 there is a debate about what is the proper definition of its characteristics. See Figure 3-1, which depicts the evolution of the Web, its actors, and components.

FIGURE 3-1 The evolution of the Web
For some, Web 3.0 is powered by the semantic web, where people can access linked information fast and easily. According to Tim Berners-Lee’s explanations, Web 3.0 would be a “read-write-execute” web. Let’s take a look at two things that will form the basis of Web 3.0: semantic markup and web services. Semantic markup refers to the communication gap between human web users and computerized applications. One of the largest organizational challenges of presenting information on the Web was that web applications couldn’t provide context to data and therefore didn’t really understand what was relevant and what was not. While this is still evolving, this notion of formatting data to be understood by software agents leads to the “execute” portion of our definition and provides a way to discuss web service. A web service is a software system designed to support computer-to-computer interaction over the Internet. Web services are vendor agnostic. They are based on industry standards and can be interactive with all devices that can make service calls in standard APIs like SOAP or REST or any other emerging standard. The use and number of web services is trending up as it is a critical part of Web 3.0.
By combining a semantic markup and web services, Web 3.0 provides the potential for applications that can speak to each other directly and for broader searches for information through simpler interfaces. But now, with the emergence of a decentralized web powered by Blockchain technology, and since it enables unmediated transactions, there is a new focus on Web 3.0 based on the trustful nature of the blockchain. It is the “read-write-own” web. Here, the user owns and participates in owning the protocol. It is both peer-to-peer and machine-to-machine. And it is applicable to people, companies, and autonomous entities. For instance, the term Web 3.0 is used by Ethereum in a different context than that suggested by Berners-Lee. It is proposed as the separation of content from the presentation by removing the need to have servers at all. Stephan Tual, formerly Ethereum’s CCO, defines that what makes Ethereum different from Web 2.0 is that “there are no web-servers, and therefore no middleman to take commissions, steal your data or offer it to the NSA, and of course nothing to DDoS.” The transformation to blockchain distributed application (dapp) will happen over a period of years. The technology is currently unable to handle high-speed transactions for reasons discussed in later chapters.
Distributed Storage Systems
One of the fundamental open challenges for Web 3.0 is effective data storage. The socio-economic value and scale of information increases day by day, and Web 3.0 developers have been working to identify ways to ensure not only that digitally stored data endures but also that it is readily available, reliable, secure, and consistent. In recent years, the massive generation of data coupled with frequent storage failures has increased the popularity of distributed storage systems, which allow data to be replicated in different, geographically dispersed, storage devices. Due to the dissemination of data in multiple hosts, one of the major problems that distributed storage systems face is maintaining the consistency of data when they are accessed concurrently by multiple operations.
InterPlanetary File System
The InterPlanetary File System (IPFS) is a distributed file system that resulted from the evolution of prior peer-to-peer systems, including DHTs, BitTorrent, Git, and SFS. The contribution of IPFS is simplifying, evolving, and connecting proven techniques into a single cohesive system, greater than the sum of its parts (see https://ipfs.io/). IPFS presents a new platform for writing and deploying applications, and a new system for distributing and versioning large data. IPFS could even evolve the Web itself. IPFS is peer-to-peer; no nodes are privileged. IPFS nodes store IPFS objects in local storage. Described by Viktor Tron as “the Lego kit for the third web,” IPFS is a new system for storing data on a large number of computers. It is transport layer agnostic, meaning that it can communicate through TCP, μTP, UDT, QUIC, TOR, and even Bluetooth. Instead of a central server, a peer-to-peer network is used to establish connections. IPFS implements a distributed hash table (DHT) that provides a lookup service similar to a hash table: (key, value) pairs are stored in a DHT, and any participating node can efficiently retrieve the value associated with a given key. Responsibility for maintaining the mapping from keys to values is distributed among the nodes in such a way that a change in the set of participants causes a minimal amount of disruption. This allows a DHT to scale to extremely large numbers of nodes and to handle continual node arrivals, departures, and failures.
IPFS Nodes
Nodes connect to each other and transfer objects. These objects represent files and other data structures. The IPFS protocol is divided into a stack of subprotocols responsible for different functionalities:
• Identities: Manage node identity generation and verification.
• Network: Manages connections to other peers, uses various underlying network protocols.
• Routing: Maintains information to locate specific peers and objects. Responds to both local and remote queries. Defaults to a DHT but is swappable.
• Exchange: A novel block exchange protocol (BitSwap) that governs efficient block distribution. Modeled as a market, weakly incentivizes data replication.
• Objects: A Merkle DAG of content-addressed immutable objects with links. Used to represent arbitrary data structures, such as file hierarchies and communications systems.
• Files: Versioned file system hierarchy inspired by Git.
• Naming: A self-certifying mutable name system.
• Applications can run over the Internet and leverage the principles and features of IPFS to create a web of Merkle links connecting data (objects and blocks) for business applications.
These subsystems are not independent; they are integrated and leverage-blended properties. However, it is useful to describe them separately, building the protocol stack from the bottom up.
Public key cryptography is built into the node addressing system, and content addressing is used to index content. Both node and content addresses are stored in a decentralized naming system called IPNS. Nodes in the peer-to-peer network each hold private keys and release public keys, just like in Bitcoin or Ethereum. Node addresses are derived through hashing their public keys. This allows connection verification through message signing. Their public keys can be used to encrypt data before it is transferred, preventing interception and theft. Solutions to today’s security issues are built into this addressing system. There is no need for a trusted central certificate issuer to provide connection verification tools, and all connections can easily be encrypted by default.
IPFS Content Addressing
A content address is derived by hashing a piece of content. That content address is then hashed again to derive a key name (see Figure 3-2). The key name is associated with a human readable name in IPNS (the IPFS address registry). Today, if a file is moved, all links to that file need to be updated if they are to resolve. Because IPFS addresses are derived from the content they refer to, if the content still exists anywhere on the network, links will always resolve. This removes any need for duplication of content, except for the purposes of greater persistence security or for scaling up serving capabilities. So how do we grow a decentralized storage system to replace the current model? We need a way to incentivize the storage and serving of content. Filecoin is one prospective solution being developed by Protocol Labs. Swarm is another being developed by the Ethereum foundation. Both projects make use of IPFS technology but have different philosophies on how to incentivize participation.

FIGURE 3-2 Distributed hash table with content address derived by hashing content
So, as mentioned, IPFS creates a P2P swarm that allows the exchange of IPFS objects. The totality of IPFS objects forms a cryptographically authenticated data structure known as a Merkle DAG, and this data structure can be used to model many other data structures. We will introduce IPFS objects and the Merkle DAG and give examples of structures that can be modeled using IPFS.
IPFS Objects
An IPFS object is a data structure with two fields:
• Data: A blob of unstructured binary data of size less than or equal to 256 kB.
• Links: An array of link structures. These are links to other IPFS objects.
A link structure has three data fields:
• Name: The name of the link
• Hash: The hash of the linked IPFS object
• Size: The cumulative size of the linked IPFS object, including following its links
The Size field is mainly used for optimizing the P2P networking, and we’re going to mostly ignore it here, since conceptually it’s not needed for the logical structure.
IPFS objects are normally referred to by their Base58 encoded hash. All hashes begin with “Qm”. This is because the hash is a multihash, meaning that the hash itself specifies the hash function and length of the hash in the first two bytes of the multihash. The data and named links give the collection of IPFS objects the structure of a Merkle directed acyclic graph (DAG) to signify that this is a cryptographically authenticated data structure that, as we noted above, uses cryptographic hashes to address content. Visualize an IPFS object by a graph with data in the node and the links being directed graph edges to other IPFS objects, where the name of the link is a label on the graph edge. Various data structures can be represented by IPFS objects, for example, a file system. IPFS can easily represent a file system consisting of files and directories.
IPFS Small Files
A small file—one whose length is less than or equal to 256 kB—is represented by an IPFS object with data being the file contents (plus a small header and footer) and no links (that is, the links array is empty). Note that the file name is not part of the IPFS object, so two files with different names and the same content will have the same IPFS object representation and hence the same hash.
• Add a small file to IPFS using the command ipfs add; see https://ipfs.io/docs/commands/ for all commands.
• View the file contents of the above IPFS object using ipfs cat.
IPFS Large Files
A large file—one whose length is greater than 256 kB—is represented by a list of links to file chunks that are less than or equal to 256 kB, and only minimal data specifying that this object represents a large file. The links to the file chunks have empty strings as names.
ipfs add ucny_dir/bigfile.js
IPFS Directory Structures
A directory is represented by a list of links to IPFS objects representing files or other directories. The names of the links are the names of the files and directories.
IPFS Versioned File Systems
IPFS can represent the data structures used by Git to allow for versioned file systems. The Git commit objects are described in the Git Book. The main properties of the commit object are that it has (like any good source control tool) one or more links with names parent0, parent1, etc., pointing to previous commits, and one link with a name object (this is called tree in Git) that points to the file system structure referenced by that commit.
IPFS Blockchains
So now for the most important use case for IPFS. A blockchain has a natural DAG structure in that past blocks are always linked by their hash from later ones. More advanced blockchains like the Ethereum blockchain also have an associated state database which has a tree structure that also can be emulated using IPFS objects.
As we saw in Chapter 1, in a simplistic model of a blockchain each block contains the following data:
• A list of transaction objects
• A link to the previous block
• The hash of a state tree/database
This blockchain can then be modeled in IPFS as shown in Figure 3-3.

FIGURE 3-3 Blockchain model
Swarm
Swarm is a distributed storage platform and content distribution service, a native base layer service of the Ethereum web3 stack. The primary objective of Swarm is to provide a decentralized and redundant store of Ethereum’s public record, in particular to store and distribute distributed application code (dapp) and data as well as blockchain data. Swarm and IPFS both offer comprehensive solutions for efficient decentralized storage layers for the next-generation Internet. Both high-level goals and the technology used are very similar. As a result both are well suited for replacing the data layer of the current Web 2.0. They both serve as storage layers for the Web 3.0 vision with all the required properties of distributed document storage:
• Low-latency retrieval
• Efficient auto-scaling (content caching)
• Reliable, fault-tolerant operation, resistant to node disconnections, intermittent availability
• Zero downtime
• Censorship resistant
• Potentially permanent versioned archive of content
Swarm’s core storage component is an immutable content addressed chunk store rather than a generic distributed hash, i.e., DHT. As previously shown in Figure 3-2, IPFS uses DHT. IPFS and Swarm use different network communications layers and peer management protocols. Swarm has deep integration with the Ethereum blockchain, and the incentive system benefits from both smart contracts as well as the semi-stable peer pool, while Filecoin uses proof of retrievability as part of mining. The consequences of these choices are far reaching. So to continue, from the end user’s perspective, Swarm is not that different from Web 2.0, except that uploads are not to a specific server. The objective is to create a peer-to-peer storage and serving solution that has the mentioned attributes such as denial-of-service resistant, zero downtime, fault tolerant, and censorship resistant as well as self-sustaining due to a built-in incentive system that uses peer-to-peer accounting and allows trading resources for payment. Swarm is designed to deeply integrate with the devp2p multiprotocol network layer of Ethereum as well as with the Ethereum blockchain for domain name resolution, service payments, and content availability insurance.
Two major features of Swarm that set it apart from other decentralized distributed storage solutions like IPFS are “upload and disappear” and the incentive system. The former refers to the fact that Swarm does not only serve content, it also provides a cloud storage service. Unlike in related systems, you do not only publish the fact that you host content, but there is a genuine sense that you can just upload stuff to Swarm and potentially disappear (drop off as a node, disconnect, or just operate without storage entirely) right away. Swarm aspires to be the generic storage and delivery service catering for all use cases ranging from serving low-latency real-time interactive web applications as well as acting as guaranteed persistent storage for rarely used content. The incentive system makes sure that participating nodes following their rational self-interest nonetheless converge on an emergent Swarm behavior that is beneficial for the entire system as well as economically self-sustaining. In particular, it allows nodes in the network to pool their bandwidth and storage resources in the most efficient way to collectively provide services.
The planned features of Swarm include integrity protection, random access (range queries), URL-based addressing, manifest-based routing on virtual hosts, domain name resolution via Ethereum Name Service, encryption support, plausible deniability, bandwidth and storage incentives, associated metadata, on-demand download of Ethereum blockchain state/receipts/contract-storage, auto-scaling by popularity (elastic cloud), auto-syncing, client side configurable redundancy/availability. A swarm-based Internet needs to provide solutions for web3 use cases with decentralized infrastructure, so broadly speaking, it is a project toward the ambitious goal of building the third web in the ethersphere.
Swarm was conceived of as a storage protocol tailored for interoperation with the Ethereum smart contract ecosystem. Like Filecoin, it will piggyback on Ethereum’s consensus process in order to provide a decentralized alternative to our existing client/server infrastructure. Incentivizing persistent storage is a challenge, however. The downside of a node deleting data and losing some income is potentially much less significant than a user losing his or her valuable data. Swarm takes the approach of rewarding nodes for serving content. Because more often requested content is more profitable to store than rarely requested content, rewarding nodes only for recall would incentivize the trashing of rarely accessed data. Failure to store every last piece of a large data set can result in the entire set being rendered useless, so in these cases a solution must exist to balance this downside asymmetry.
Using content recall as the base reward mechanism and distributing content randomly among nodes, weighted for location, puts Swarm in a good place to start solving the persistence problem:
• Nodes offering “promissory” storage, or storage with a promise of persistence, must first post a security deposit covering the time for which they are offering storage.
• If data is lost during this period, the bond is forfeited.
• The smart contract infrastructure of Ethereum automates this whole process, making the “upload and forget” experience seamless.
Storj
Storj is a protocol that creates a distributed network for the formation and execution of storage contracts between peers. The Storj protocol enables peers on the network to negotiate contracts, transfer data, verify the integrity and availability of remote data, retrieve data, and pay other nodes. Each peer is an autonomous agent, capable of performing these actions without significant human interaction. In Storj, files are stored as encrypted shards. Sharding is a type of database partitioning that separates very large databases into smaller, faster, more easily managed parts called data shards. The word shard means a small part of a whole. So a shard is a portion of an encrypted file to be stored on this network. Sharding has a number of advantages to security, privacy, performance, and availability. Files should be encrypted client-side before being sharded. The reference implementation uses AES256-CTR, but convergent encryption or any other desirable system could be implemented. This protects the content of the data from the storage provider, or farmer, housing the data. The data owner retains complete control over the encryption key and thus over access to the data. The data owner may separately secure knowledge of how a file is sharded and where in the network the shards are located. As the set of shards in the network grows, it becomes exponentially more difficult to locate any given shard set without prior knowledge of their locations. This implies that security of the file is proportional to the square of the size of the network. Shard size is a negotiable contract parameter. To preserve privacy, it is recommended that shard sizes be standardized as a byte multiple, such as 8 or 32 MB. Smaller files may be filled with zeroes or random data.
Storj uses hash chains or Merkle trees, as they are sometimes called, to verify the contents of a file after it has been broken up into blocks or “leaves” off a master or root hash (see Figure 3-4).

FIGURE 3-4 Storj service sharding and data transfer
Standardized sizes dissuade side-channel attempts to determine the content of a given shard and can mask the flow of shards through the network. Sharding large files such as video content and distributing the shards across nodes reduces the impact of content delivery on any given node. Bandwidth demands are distributed more evenly across the network. In addition, the end user can take advantage of parallel transfer, similar to BitTorrent or other peer-to-peer networks. Because peers generally rely on separate hardware and infrastructure, data failure is not correlated. This implies that creating redundant mirrors of shards, or applying a parity scheme across the set of shards, is an extremely effective method of securing availability. Availability is proportional to the number of nodes storing the data. So, to summarize Storj:
• Files are encrypted.
• Encrypted files are split into shards, or multiple files are combined to form a shard.
• Audit preprocessing is performed for each shard.
• Shards may be transmitted to the network.
Decentralized storage services like Storj will most certainly evolve. They provide a peer-to-peer network that would “rent” unused capacity from a computer’s hard drive as part of a cloud service to store files from other users. They will meet the Web 3.0 challenge to provide effective, available, reliable, secure, and consistent data storage.
Distributed Computation
Distributed computing is the science that studies and seeks to evolve the distributed systems model. In this growing paradigm, components located on networked computers/nodes communicate and coordinate their actions. These components interact with each other to achieve a common goal. As early as 1977, computer scientists like Gérard Le Lann described how networked distributed computing components could “solve user problems more satisfactorily … than centralized servers.” (https://www.rocq.inria.fr/novaltis/publications/IFIP%20Congress%201977.pdf)
These days we are on the threshold of yet another revolutionary paradigm shift of supercomputers. As we have seen, blockchain technology allows developers to consider yet again reducing the price of high-performance computing services and making supercomputers—that is, networked computers—more accessible. A new model for decentralized clouds is a classic example of shared economy: the idea is about gathering users in a global peer-to-peer network where every machine acts as a provider of computation services by offering a part of its idling capacities. This distributed systems model promises a breakthrough for the industry coupled with profit for each user. Most of us do not even use half of our computers’ capacities. By connecting these idle capacities to a network, users will be able to make money with their unused computing resources. Those who lease computing resources will also gain advantages in decentralized services. First, the service will be less expensive. Decentralized cloud platforms are free markets where demand and supply form competitive prices. Such services will be able to compete with the likes of Microsoft, Google, IBM, or Amazon, which in turn are likely to make relevant services cheaper. Additionally, decentralized structures have no single center to be attacked, so they are more reliable by default. Other advantages include higher probability of finding a node geographically close to the end user, which would also accelerate work with big data. It also may ensure power savings as distributed clouds use the unused capacities of subscribed users. So, the significant characteristics of distributed systems are:
• Resource sharing
• Openness
• Concurrency
• Scalability
• Fault tolerance
• Transparency
Golem
As we have been discussing, a supercomputer is a computer that performs at or near the currently highest operational rate for computers. The first supercomputers that were not networked emerged in the 1960s. They were unique monolith devices extremely powerful for their time and equally expensive. These supercomputers were used for scientific and engineering applications that handled large databases or performed a great amount of computation. Popular among supercomputers are traditional processors, interconnected and installed in given locations with the task of solving specific data problems. Examples of the top supercomputers in the world include:
• Jaguar, located at the Department of Energy’s Oak Ridge Leadership Computing Facility in Tennessee (https://www.olcf.ornl.gov/).
• Nebulae, located at the National Supercomputing Centre in Shenzhen, China.
• Kraken, situated at the National Institute for Computational Sciences (NICS). The NICS is a partnership with the University of Tennessee and Oak Ridge National Lab.
(www.datacenterknowledge.com/the-top-five-supercomputers-illustrated/)
With the emergence of decentralized technology, the design and installation of supercomputers appear to have shifted gears. Some engineers describe the decentralized supercomputer as “fog computing,” where the fog exists in the singular. Fog computing can solve some of the most challenging tasks of humanity by joining the powers of personal computers, laptops, and even smartphones. Scientific calculations of any difficulty can be performed quite fast due to the opportunities fog computing provides. Solutions offered by decentralized supercomputers include the generous availability of processing power, uninterrupted uptime, and economic incentives.
Golem is touted as the first truly decentralized supercomputer, creating a global market for computing power. Combined with flexible tools to aid developers in securely distributing and monetizing their software, Golem hopes to change the way computer tasks are organized and executed. By powering decentralized microservices and asynchronous task execution, Golem is set to become a key building block for future Internet service providers and software development. By substantially lowering the price of computations, complex applications such as CGI rendering, scientific calculation, and machine learning become more accessible to everyone. Golem connects computers in a peer-to-peer network, enabling both application owners and individual users (“requestors”) to rent resources of other users’ (“providers”) machines. These resources can be used to complete tasks requiring any amount of computation time and capacity. Today, such resources are supplied by centralized cloud providers which are constrained by closed networks, proprietary payment systems, and hard-coded provisioning operations. Core to Golem’s built-in feature set is a dedicated Ethereum-based transaction system, which enables direct payments between requestors, providers, and software developers. The function of Golem as the backbone of a decentralized market for computing power can be considered both Infrastructure-as-a-Service (IaaS) as well as Platform-as-a-Service (PaaS). However, Golem’s true potential may be adding dedicated software integrations to the equation. Any interested party is free to create and deploy software to the Golem network by publishing it to the application registry. Together with the transaction framework, developers can also extend and customize the payment mechanism, resulting in unique mechanisms for monetizing software. GNT (Golem Network Tokens) are Ethereum-based tokens used to fuel the Golem platform. The Golem supercomputers run when the user pays GNT tokens. These tokens are given to people who have rented out their extra computing power on the Golem network. GNT’s coin supply is fixed, which means as the project becomes more popular, the price of GNT will likely increase (see Figure 3-5).

FIGURE 3-5 Golem network
Zennet
Comparable to the Golem project is Zennet (zennet.sc), According to its founder, software engineer Ohad Asor, Zennet is a distributed supercomputing project that will use blockchain technology to remove the central administrators from the problem. Computation power is traded on Zennet’s open market platform. Anyone can rent computation power and use it to run arbitrary tasks. Anyone can monetize their hardware by offering unused computation power for sale. Zennet allows “publishers” (those who need computation power) to run arbitrary computational tasks. Computation power is supplied by “providers” for a negotiated fee. A free-market infrastructure brings publishers and providers together. Publishers can hire many computers and run whatever they want on them safely, thanks to cutting-edge virtualization technology. Payment is continuous and frictionless, thanks to Blockchain technology. The network is 100 percent distributed and decentralized: there is no central entity of any kind, just like Bitcoin. All software will be open source. Publishers pay providers directly; there is no middleman. Accordingly, there are no payable commissions, except for regular transaction fees that are being paid to Xencoin miners. It is a totally free market: all participants are free to pay or charge by any rate they want. There are no restrictions. Hence, projects like Zennet put additional focus on customizability. Zennet allows advanced participants to control all parameters and conditions of their nodes in a versatile way. On the other hand, simplicity and automation are made possible by making the client software implement automatic risk-reward considerations by default.
Decentralized Communications
The decentralized communications model enables natively interoperable communications services that can trustfully use peer-to-peer connections without having to use central authorities or services. A wide range of distributed applications require confidential communication between users. The messages exchanged between the users and the identity of group members should not be visible to external observers. Classical approaches to confidential group communication rely upon centralized servers, which limit scalability and represent single points of failure. The use of confidential communication between a group of distributed entities is at the core of many applications. Examples include private chat rooms in social networks, information-sharing systems guaranteeing freedom of speech, control-flow and admission-control for pay-per view live streaming, distributed content indexes that should not be made public to prevent attacks, etc. The confidentiality of the messages exchanged between the members of a private group is typically achieved using encrypted channels that prevent malevolent parties from spying on the exchanged content. However, content encryption alone is insufficient for many of the applications mentioned above, which also require that the composition of the group remain secret—that is, one should not be able to determine whether a node belongs to a group. The existence of the group itself can also be hidden from unauthorized parties.
Computer networks typically use centralized solutions for supporting private group communication, such as by relying on dedicated servers. Virtual private networks (VPNs) allow nodes to create private communication channels with encrypted traffic. Group communication can leverage VPNs, for instance, as part of a multisite company infrastructure, with all communications between sites being routed through some VPN gateways. In large-scale dynamic settings, where sizable populations of nodes are interconnected in self-organizing and often loosely structured overlays, the use of VPN-based solutions is inadequate for implementing private group communications. The problem is that VPN gateways act as single points of failure. For this reason, they forfeit one of the major benefits of decentralized systems: their robustness to targeted attacks such as denial-of-service attacks. As soon as the attackers know the gateway, it is straightforward to disrupt communications within the private group by concentrating the attacks on the gateway. Further disadvantages of solutions based on VPNs or dedicated servers include their scalability to large numbers of users, their price, and their operating costs.
We should point out that these approaches do not keep the membership of private groups hidden from malevolent nodes; only the content of exchanged messages is protected. The process of hiding the communication partners, and hence the identity of the members of the group, must be provided by anonymizing systems such as The Onion Router (TOR). These systems rely on a set of dedicated servers that conceal the source of the message from the destination, typically using onion routing mechanisms. Here again, the cost of provisioning such a system with sufficiently many dedicated servers can be a hindrance in large-scale self-organizing networks. These observations make the case for a fully decentralized, autonomous, and self-organizing service to support confidential communications within groups of nodes in large-scale systems. Unlike existing approaches, this service should let private groups be created by ordinary nodes and emerge within the network, without relying on dedicated and trusted third-party servers. At the same time, it must hide communications between the members of a private group from the other nodes (content privacy), as well as keep the group memberships secret to external observers (membership privacy). This latter point is especially important, as it is impossible for an attacker to focus an attack on the members of a group without being able to determine their identity.
Existing Decentralized Communications
Bitmessage (bitmessage.org) is a peer-to-peer communications protocol used to send encrypted messages to another person or to many subscribers. It is decentralized and trustless, meaning that you need not inherently trust any entities such as root certificate authorities. It uses strong authentication, which means that the sender of a message cannot be spoofed, and it aims to hide “non-content” data, like the sender and receiver of messages, from passive eavesdroppers such as those running warrantless wiretapping programs. Bitmessage works by encrypting all the incoming and outgoing messages using public-key cryptography so that only the receiver of the message is capable of decrypting it. In order to achieve anonymity, Bitmessage replicates all the messages inside its own anonymous P2P network, therefore mixing all the encrypted messages of a given user with all the encrypted messages of all other users of the network, thus making it difficult to track which particular computer is the actual originator of the message and which computer is the recipient of the message.
Telehash (telehash.org) is a peer-to-peer data distribution and communications protocol that is designed to be decentralized and secure. The protocol is licensed under the Creative Commons public domain. Telehash is like BitTorrent Sync in that it allows users of the software to share data securely without any central server authority. There are implementations in C, Python, Ruby, Erlang, JavaScript, Go, and Objective-C. Similar in approach to BitTorrent, it routes to the recipient given its hash. Telehash uses DHT to do deterministic routing, therefore it may not be secure against simple statistical packet-analysis attacks.
Whisper
Whisper is fully decentralized middleware that supports confidential communications within groups of nodes in large-scale systems. (See “Whisper: Middleware for Confidential Communication in Large-Scale Networks” by Valerio Schiavoni, Etienne Rivière, and Pascal Felber.) Whisper builds upon a peer sampling service that takes into account network limitations such as network address translation (NAT) and firewalls. Whisper is a part of the Ethereum P2P protocol suite that allows for messaging between users via the same network on which the blockchain runs.
Some dapp use cases include:
• Dapps that need to publish small amounts of information to each other and have the publication last some substantial amount of time. For example, a currency exchange dapp may use it to record an offer to sell some currency at a particular rate on an exchange. In this case, it may last anywhere between tens of minutes to days. The offer wouldn’t be binding, merely a hint to get a potential deal started.
• Dapps that need to signal to each other in order to ultimately collaborate on a transaction. For example, a currency exchange dapp may use it to coordinate an offer prior to creating transactions on the exchange.
• Dapps that need to provide non-real-time hinting or general communication between each other.
• Dapps that need to provide dark communication to two correspondents that know nothing of each other but a hash. This could be a dapp for a whistleblower to communicate to a known journalist exchange some small amount of verifiable material and arrange between themselves for some other protocol to handle the bulk transfer.
The Whisper architecture (see Figure 3-6) is a combination of layers. The Whisper communication layer (WCL) operates on top of the NAT-aware peer sampling services (PSS). It allows confidential communication between peers by protecting both exchanged content and relationship anonymity. This is still true even when relays should be employed for bypassing NAT limitations.
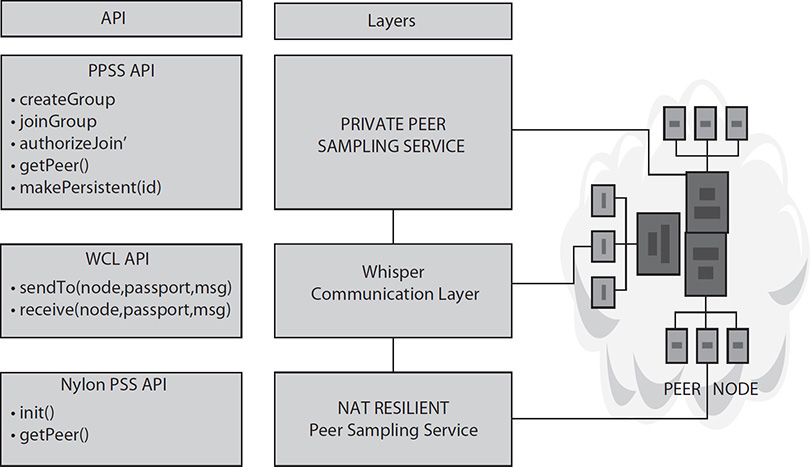
FIGURE 3-6 Whisper architecture layers
The private peer sampling service (PPSS) operates on top of the WCL. It provides the services of a PSS: it acts as a provider of a private view of live peers for the applications operating in the private group. It leverages the WCL to guarantee that communications with any node in the private view will remain strictly confidential. The PPSS also deals with group management and membership authentication, and ensures that confidential connections between peers can be maintained even when the destination node no longer belongs to the view of the source node. Whisper targets large-scale, Internet-wide networked systems in which a large majority of nodes reside behind NAT devices or firewalls. The Whisper algorithms exploit peer sampling as an underlying approach for organizing nodes in the network in a fully decentralized and autonomous manner. Whisper considers malevolent nodes that spy upon other nodes in the system, but that follow the protocol specification and do not exhibit other byzantine behavior.
Whisper implements confidentiality in two ways: it protects the content of messages exchanged between the members of a group, and it keeps the group memberships secret to external observers. Using multi-hop paths allows these guarantees to hold even if attackers can observe the link between two nodes or be used as content relays for NAT bypassing. Whisper supports the creation of confidential communication routes without the need for a trusted third party. It additionally provides membership management and overlay maintenance among private groups of nodes communicating in a confidential manner. Evaluation of Whisper in real-world settings indicates that the price of confidentiality remains reasonable in terms of network load and processing costs.
Summary
In this chapter, we introduced some of the components of the Web 3.0 architecture, including distributed networking and storage that are happening now and promise solutions that could save the global economy trillions annually. The Web today needs a new security model and an architecture designed around contemporary use cases. The technology stack is just beginning to emerge (see Figure 3-7). It includes Swarm, IPFS, Storj, Golem, and Whisper, just to mention a few of a growing number of components that represent the most ambitious solutions to this problem.

FIGURE 3-7 Web 3.0 technology stack
As the global infrastructure adapts to the new demands we are putting on it, unforeseen opportunities will open before us. New tools will change not only the way we work and use web conveniences but also the way we organize ourselves in groups. We are living in an interesting time in history, where the Web begins to bring more knowledge and action capacity to its users, resulting in considerable changes in several aspects of daily life. This new Web is moving fast toward a more dynamic environment, where the democratization of the capacity of action and knowledge can speed up business in almost all areas. Imagine a future with hundreds of real decentralized applications—for example, one in charge of registering land titles and mortgages and handling local taxes, and another more general application in charge of managing the supply chain of registered tenants and their monthly lease payments as well as mortgage and expense payments. One could easily link information from properties registered in the first application with tenants and their use of the properties registered in the second application. All this in an easy way, using the whole stack of semantic web technology and—something that is not possible to date—ensuring that all data is 100 percent true, guaranteed by the smart contracts. The real questions we must ask are: How will the world of Web 3.0 differ from the world of Web 2.0? How will this technology penetrate beyond the cultures that created it? One thing is for sure: the blockchain will be at the center of this new world.