
CHAPTER 11
File I/O and Data Manipulation
Chapter Objectives
By the end of the chapter, readers will be able to:
![]() Explain the characteristics of data files and report files.
Explain the characteristics of data files and report files.
![]() Discuss the advantages associated with writing and reading data to various forms of storage mediums.
Discuss the advantages associated with writing and reading data to various forms of storage mediums.
![]() Apply predefined stream classes ifstream and ofstream to create stream variables.
Apply predefined stream classes ifstream and ofstream to create stream variables.
![]() Discuss the purpose of the file position marker (FPM).
Discuss the purpose of the file position marker (FPM).
![]() Explain the options available for opening files, checking for successfully opening files, and closing files.
Explain the options available for opening files, checking for successfully opening files, and closing files.
![]() Demonstrate programmatically reading and writing data to files.
Demonstrate programmatically reading and writing data to files.
![]() Understand the basic concepts associated with sorting and searching.
Understand the basic concepts associated with sorting and searching.
In the last chapter, we discussed how to create and manipulate arrays. Unfortunately, filling those arrays involved a lot of typing at the keyboard every time our programs were run. In this chapter, the concepts of data files and the statements necessary to read from and write to these text files are introduced. This will allow us to store the information in a file and access it as needed without retyping the data. As you will quickly see, the use of data files will make debugging and testing your code easier and will provide yet another powerful tool to use in writing your programs.
11.1 Data Files
There is a difference between a report and a data file. A report is always generated by a computer program for human consumption and usually includes title information, column headings, and other formatting. In essence, we have been creating reports throughout the book, but now instead of just being displayed on the screen, they will be written to a file for storage. This storage can be on any device accessible by your computer. This includes the hard drive, network drives, and even USB flash drives.
A data file must be written with data only and created following a consistent layout for each record in the file. A data file will generally be used as input for our programs. Because of their ease of use, the tendency is to write, and read, space-delimited files. An example of a space-delimited file is shown in Figure 11.1.1.
Although these do work in a wide variety of situations, if your data includes multiword strings, space-delimited data files won't work. Another common format for data files is a comma-delimited layout, in which all strings are enclosed in quotation marks. An example of a comma-delimited file is shown in Figure 11.1.2.

Figure 11.1.1 Space-delimited file

Figure 11.1.2 Comma-delimited file
As shown in Figure 11.1.2, all fields must be represented, even if the value is an empty string or zero. Also notice that the format of the file is consistent for each record. To write a program that reads this file, you will need to know the organization of the record as well as what each field represents.
The data files represented in this chapter are text files. To create the initial data file, it is a simple matter to use your favorite text editor, such as Notepad, vi, or Visual Studio. In fact, for simplicity we suggest you use your IDE for creating the data file as well as viewing your output or report file. It is best to use the filename extension of .txt for all of your text files. This is not a necessity but is a common practice. Not all data files will be text files, however; some will be binary. We will discuss binary data files later in the text.
Section 11.1 Exercises
Please respond to each of the following questions.
1. The purpose of generating reports is to provide:
a. data for our program
b. data in a human-readable format
c. electronic digital output
d. a storage format
2. Indicate whether each of the following statements is true or false.
a. Within this chapter we will be creating our input, data files, as regular text files.
b. A report file is used for input, and a data file is used for output.
c. Data files must be produced following a consistent layout for individual records contained within the file.
d. Data files often use either a space or a comma to separate or delimit the individual fields within a record.
Up to this point, you have been using cout and cin so much that you probably don't even give their functionality a second thought. The good news is, much of what you have learned about cout and cin applies to reading and writing files. The cout and cin statements are predefined stream objects that are tied to stdin (keyboard) and stdout (screen). Unfortunately, there aren't any predefined streams associated with files. Therefore, we will have to make our own file streams.
There are two predefined stream classes from which we can make our own stream objects. For the purpose of this chapter, think of a class as a very powerful data type. Classes are extremely useful tools we will get to learn more about in later chapters. The related term, object, refers to a variable that was created from a class.
![]()
Remember: The stream classes are predefined, not primitive, data types.
The two stream classes we will use are ifstream and ofstream. Both of these classes are found in the <fstream> header file.
![]()
Remember: The ifstream class stands for input file stream and ofstream stands for output file stream.
The ifstream class allows us to create an object that provides the functionality to read from a file. The ofstream class allows us to create objects so that we can write to files. Example 11.2.1 demonstrates how to use these classes and shows the necessary #include and using statements.


As demonstrated in Example 11.2.1, it is important to remember that these objects, fin and fout, are just variables. Many students use fin and fout exclusively as counterparts to cin and cout. This is not necessary or desirable. Like any other variable name, stream objects should be descriptive of their purpose.
Another form of declaring stream objects allows us to pass the name of the file to the object during its declaration. In Example 11.2.2, we use both a string literal and a constant to represent our filenames.

One last option available allows us to create a file stream object specifying that data will be appended to an existing file. Therefore, any new information will be added to the end of the file. This technique is shown in Example 11.2.3.

In Example 11.2.3, the declaration of the report stream object includes the ios::app parameter, which allows us to append data to an existing file. Also notice that the string literal representing the complete path and filename uses the ‘\’ escape sequence, which is only required with string literals to represent a single backslash.
Be aware that if you supply a filename in the declaration of any stream object, that file will be opened, or at least an attempt will be made to open that file. More information on opening files will be discussed in the next section.
Section 11.2 Exercises
Please respond to each of the following questions.
1. When using the two stream classes, ifstream and ofstream, we need to include the header file ___________________.
![]()
2. Which of the following methods illustrate how we can pass the name of our file to the object at the time it is being declared?

d. that is not possible
3. Indicate whether each of the following statements is true or false.
a. It is possible to open a file in append mode, thus allowing additional data to be added to the end of an existing file.
b. Both the ifstream and the ofstream classes allow us to create objects so that we can write data to the files.
c. The ifstream and ofstream classes are predefined data types.
d. When using a string literal to represent the complete path and filename, use the ‘\’ escape sequence.
e. Stream variables must be named fin, for input files, and fout, for output files.
Before manipulating the information stored in a file, we need to open it from within our program. As discussed in the last section, if we supply a filename during the declaration of a stream object, an attempt to open that file will be made. This attempt may fail for various reasons, such as if the name is misspelled or the path is incorrect.
There is another method of opening a file that utilizes a member function available through the use of stream objects. The syntax is as follows:
stream.open ( filename );
Just like with the report shown in Example 11.2.3, you can open a file in append mode by passing the ios::app flag to the .open member function. The three modes in which you can open a file are read, write, and append. The read mode is accomplished by using the ifstream class. The other two modes are accomplished using the ofstream class. Example 11.3.1 demonstrates these methods of opening a file.
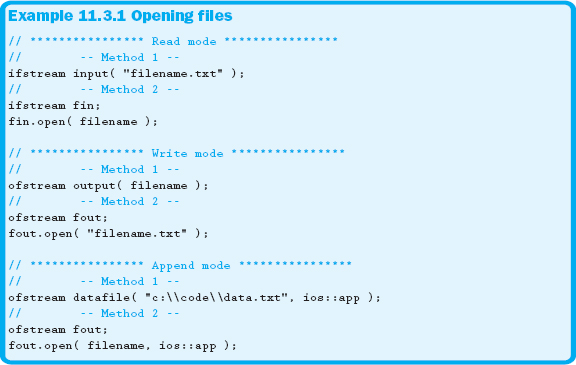
When a file is opened, the current position is indicated by something we call a file position marker (FPM). When the file is opened in read and write mode, the FPM is placed at the beginning of the file. If the file is opened in append mode, the FPM is placed at the end of the file.
![]()
Remember: Our term, “file position marker (FPM),” is often referred to by other names, such as file pointer or cursor. Regardless of what you call it, the functionality remains the same.
Be aware that opening a file in write mode destroys any existing information in that file. Be absolutely certain you are referencing the correct file. A former student of ours made the mistake of opening her source code file in write mode from within her program. This caused more than a little grief when she learned she needed to rewrite her entire program.
Both write and append modes will attempt to create the file if the one specified doesn't exist. The opening process would still fail if the file could not be created. Many things could cause the file not to be created, such as specifying an incorrect directory, not having write permissions to that location, or the drive not being ready, maybe due to a pen drive not being plugged in. Opening a file in read mode will immediately fail if the file doesn't exist, and the file will not be created under any circumstance.
Section 11.3 Exercises
Please respond to each of the following questions.
1. What are the three different modes for opening a file?
a. in, out, erase
b. in, mod, out
c. read, write, add
d. read, write, append
2. The current position within a file is noted by the file pointer, or something we call the
a. file indicator (FI)
b. pointer
c. file position marker (FPM)
d. file locator
3. If you try to open a file in read mode that does not exist, what happens?
a. The request fails and the file will not be created.
b. The file is created.
c. The file is created but you cannot read from it.
d. The file will be created but only on an external drive or device.
4. Explain why it is so important to be very careful when opening a file that already exists in write mode.
11.4 Checking for Successful Opening
If your request to open a file is denied, the program will continue executing unless an attempt is made to access the file. At this point your program will crash. For this reason, you always need to check to determine if the file-open request is granted.
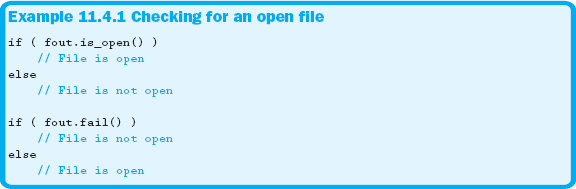
There are two member functions associated with file stream objects that check to see if the files are open. The .fail function returns true if the file did not open and returns false if it did. The .is_open member function returns the opposite values of .fail: true if open, false if not. Example 11.4.1 demonstrates the use of these functions.
![]()
Remember: Always check the file to see if it was opened before trying to access it.
Section 11.4 Exercises
Please respond to each of the following questions.
1. After attempting to open a file, always make it a point to _______________.
a. read the data it contains
b. write your new data to it as soon as possible
c. release it when done
d. make sure the file opened successfully
2. Which of the following member functions check to make sure the file is open?

3. While not our preferred option, the ___________ method can also be used to see if a file is open.

11.5 Closing Files
If you open a file, make sure you close it. However, only attempt to close the file when you are sure that the file was open. Closing a file informs the operating system that you are finished with that resource. Example 11.5.1 shows how to use the .close member function to close a file if it was open.

Section 11.5 Learn by Doing Exercise
1. Create a text file in your IDE. Place the text, “Sample text.” in the file. Save the file in a new directory on your hard drive, called Sample, as Sample.txt.
Write a program that opens the file in read mode. If the file is opened correctly, display the text, “File opened!” to the screen. Otherwise, print, “File was not opened!”. Don't forget to close the file if it was opened successfully. Compile and run your program.
Now modify the program so that you open the same file in append mode. Again, compile and rerun the program. Open the data file from within your IDE and verify that the contents are still correct.
Lastly, open the same file in write mode. Compile and rerun the program. Open the data file from within your IDE to see if the contents of the file still exist.
11.6 Writing to Files
Now that we understand the opening and closing of files, we can start to use files to store data or other information. Fortunately, an ofstream object allows us to use all of the same functionality as cout to write to a file. Example 11.6.1 illustrates how to generate a report that is written to a file.

Example 11.6.1 uses some familiar formatting commands presented in Chapter 5. Notice that the report stream object is passed to the function PrintHeader. Anytime a stream object is passed, it must be passed by reference to avoid crashing your program. It may not be intuitive, but inserting into or extracting information from the stream changes the state of the stream. Therefore, always pass these stream objects by reference. The function declaration of PrintHeader is shown in Example 11.6.2.
Section 11.6 Exercises
Please respond to each of the following questions.
1. If you open a file, you need to make sure you _______________ it.
a. read
b. write
c. append
d. close
2. What object allows us to write data to a file?
a. instream
b. ofstream
c. outstreamer
d. consolestream
3. Always make it a point to pass stream objects to functions by _________________.
a. value
b. constant
c. pointer
d. reference
Assume the following:
ofstream out( “filename.txt” );
4. Write the necessary statements to do the following:
a. Check to make sure the file is open; if not, display a message to the console
b. Write your first name and last name, separated by a space, into the file
c. Close the file
11.7 Reading from Files
As discussed earlier, an ofstream object can be used to write to a file, but we must use an ifstream object to read from a file. An ifstream object can be used exactly like cin, including the .getline member function.
It is unlikely that we would know how much data exists in any given data file. Therefore, we typically want to read every piece of data until the end of the file has been reached. In every file there is an end-of-file (EOF) marker placed at the end. Although a simple concept, it is important to realize that the marker is automatically placed by the operating system immediately after the last piece of information. Example 11.7.1 shows how to read from a data file until the EOF marker has been reached.

In Example 11.7.1, the .eof member function returns true if the EOF marker has been read, false if not. Therefore, we want to continue to read as long as the EOF marker has not been encountered.
The ReadData function returns the number of records read from the file. This value would be used to inform other functions in our program how many records are stored in our arrays. Also, we implemented a priming read to ensure that we read the correct number of records, as discussed in Chapter 8. The priming read in our example ensures that if the file exists but is empty, the number of records returned from the function would remain zero.
File access is fairly slow, especially if you are using an older floppy drive. Therefore, we suggest you keep the number of file accesses to a bare minimum. Since the data is stored in memory, it will always be faster to access this data than the data in the file.
Section 11.7 Exercises
Please respond to each of the following questions.
1. What object allows us to read data from a file?
a. mystream
b. ofstream
c. ifstream
d. consstream
2. What does EOF represent?
a. educational opportunity fund
b. end of format
c. end of file
d. end of fun
3. When using stream objects, we use a(n) _______________ object when writing to files and a(n) ______________ object for reading files.
a. fout / fin
b. ofstream / ifstream
c. outfile / infile
d. in / out
4. How long do we continue to try to read an input file?
a. until the EOF marker is encountered
b. until a compiler warning is received
c. until a complete record is processed
d. until an exception is thrown
Assume the following:
![]()
5. Write the necessary statements to do the following:
a. Check to make sure the file is open
b. Read and display all the information contained within the space-delimited file; include a priming read and assume that each record in the file contains the following three fields: lname, id, and age
c. Close the file when you have processed all the records
6. Indicate whether each of the following statements is true or false.
a. It is faster to read data from a storage device, like a floppy disk or a USB drive, than accessing data directly from RAM.
b. The exact number of records contained within a data file is usually not known ahead of time.
c. A data file will usually only be completely read once during the execution of an individual application.
d. When reading data from an input file, it is imperative to count the number of records processed.
e. The EOF marker is automatically placed at the end of a text file.
11.8 Searching
Now that we have the capability to easily store large amounts of data in memory, one of the more common capabilities required of any program is the ability to search for a specific piece of information. For example, if a program holds information on employees, the capability of finding a single employee's information would be a necessity.
The easiest method is to start at the first record, comparing a value from within our arrays to a user-specified target. If the value matches the target record, process the information; otherwise, move to the next record. If the search examines all records without finding a match, obviously the record didn't exist, and appropriate action should be taken. A simple error message displayed to the screen might suffice.
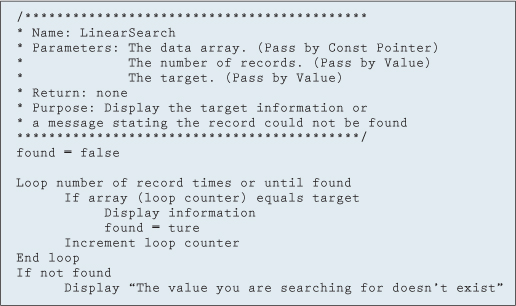
Figure 11.8.1 Linear search algorithm
This method is called a linear or sequential search. Although simple to understand and implement, let's see how efficient it is. In the best-case scenario, the record is found after the first comparison. The worst case would be if the desired record did not exist in our arrays. The average number of iterations would be n/2, where n is the number of elements in the array. Figure 11.8.1 shows an algorithm for a linear search.
Another method is called a binary search and is, on average, much more efficient. The one requirement for a binary search to work is that the data must be ordered by the key value. In other words, if we are searching by an employee's last name, the data must be arranged (i.e., sorted) in order by the last name field. In this case, the last name becomes our key value. Sorting will be covered in the next section.
The premise behind the binary search is to logically cut the array in half. Then a comparison is made to see which half the target would be located in, and it too is logically cut in half. This process continues until the target is located. Although much more complicated, this algorithm requires many less iterations on average. The number of iterations for a binary search to find its target is roughly the number of times we can divide the array in half, or 1 + log2n. Table 11.8.1 evaluates the number of iterations for the linear and binary search, dependent on the number of elements.
As you can see in Table 11.8.1, the number of comparisons required of a binary search is much less than that of a linear search. An algorithm for a binary search is shown in Figure 11.8.2.
Notice that the last two lines in Figure 11.8.2 handle the situation in which the item to be found doesn't exist in the array. If the loop terminates and the variable found is still false, the element was not found and an appropriate message will be displayed. We only show the pseudocode for the searches discussed in this section because the best way to fully understand these search algorithms is for you to implement them.
Table 11.8.1 Linear versus binary searches
| Worst Case Number of Iterations | |||
| Number of Elements | Linear Search | Binary Search | |
| 100 | 100 | 8 | |
| 1000 | 1000 | 11 | |
| 10,000 | 10,000 | 15 | |
| 100,000 | 100,000 | 18 | |
| 1,000,000 | 1,000,000 | 21 | |

Figure 11.8.2 Binary search algorithm
Section 11.8 Exercises
Please respond to each of the following questions.
1. To do a binary search, the data we are searching must have the following characteristics:
a. Be in order
b. Contain at least three or more characters
c. Be in all uppercase
d. Be used only on alphabetic characters
2. Doing a search that starts with the first record in our list and compares each successive record's key until either a match is found or we have reached the end of the list is called a _____________________ search.
a. selection
b. binary
c. linear (or sequential)
d. object
3. Indicate whether each of the following statements is true or false.
a. On the average, a linear or sequential search would be faster than a binary search.
b. A binary search requires that the list be in order.
c. A sequential search requires that the list be in order.
d. Cutting a list of values in half as we search for a specific target value is the basic idea behind the linear search.
e. You can search a list for either numeric or alphabetic characters.
11.9 Sorting
There are many sorting algorithms, ranging from the simple to the extremely complicated. As you might suspect, the simple algorithms are usually the least efficient. Although the focus of this text is not on sorting algorithms, being able to sort your information is a valuable skill to have in your toolbox. In this section, we present one of the slowest but easiest algorithms to implement: the bubble sort.
Just as a bubble floats to the surface of a pond, the bubble sort “bubbles” the largest element to the end of the array. Once one element is in place, the process restarts at the beginning of the array to bubble the next largest value to its place within the array. Each pass consists of comparing two elements, and if the first element is greater than the second, the elements are swapped. This continues until the end of the array is encountered. Figure 11.9.1 shows how the first pass would place the largest element at the end of the array.
As you can see from Figure 11.9.1, the largest element is now at the end of the array. All we need to do is repeat the process four more times and the array will be sorted. The bubble-sort algorithm is shown in Figure 11.9.2.
While the algorithm shown in Figure 11.9.2 works correctly, we can make the bubble-sort algorithm a little more efficient by making a couple of observations. First of all, each pass places one more element in the correct location. Therefore, we don't need to compare the element just placed in the correct position in any future passes. This means that each pass now requires one less comparison. The change to the algorithm is displayed in blue in Figure 11.9.3.
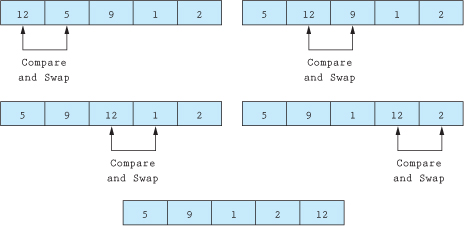
Figure 11.9.1 First pass of the bubble sort

Figure 11.9.2 Bubble-sort algorithm
Another thing to notice is that even if the array is sorted, the process continues. We can use the concept of a flag to stop the processing once we are guaranteed that the array is in order. If we make a complete pass without having to swap an element, we know that the array is ordered. Therefore, if after the first pass we can determine that the array is already sorted, all unnecessary future passes would be circumvented. This change to the algorithm is often called a flagged bubble sort and is shown in Figure 11.9.4.
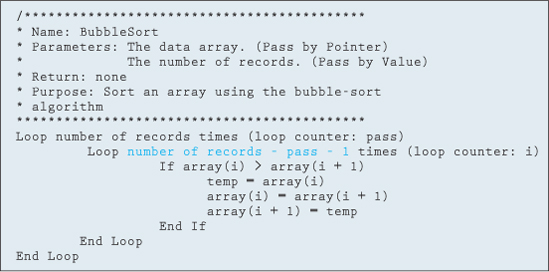
Figure 11.9.3 Bubble-sort algorithm, more efficient approach
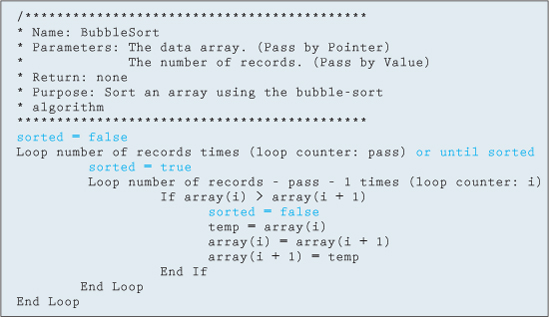
Figure 11.9.4 Flagged bubble sort
Figure 11.9.4 shows the use of the sorted variable as a flag to help determine when the array is ordered. As you can see, with very minor changes we can greatly increase the performance and efficiency of the bubble sort.
Section 11.9 Exercises
Please respond to each of the following questions.
1. Which popular sorting method floats the largest element in an array to the end?
a. merge sort
b. selection sort
c. heap sort
d. bubble sort
2. Indicate whether each of the following statements is true or false.
a. To potentially improve the efficiency of the bubble-sort method, the use of a flag was introduced to act as a signal when the array is in the desired order and no additional comparisons need to be made.
b. There are a number of popular sort methods available.
c. The bubble sort is not very efficient.
d. The bubble sort basically involves comparing each item in the array or list with the item next to it and, if needed, swapping them.
Section 11.9 Learn by Doing Exercise
1. Using Examples 10.6.3 and 10.6.4 as a guide, write a function that finds the median of the list of values.
11.10 Problem Solving Applied
In this section we make the final addition to the problem associated with the class management program discussed in the past few chapters. The fundamental aspects of the project are the same as they have been in the past, but now we will use external files for reading and writing data and reports. Once the program has read the data from an external file into a series of parallel arrays, we process it and write the results to a report file instead of the console. If you need a bit of a refresher on the overall project, please refer to Section 8.6, Section 9.10, and Section 10.12 for the problem specifications.
As was done in the previous chapter, we continue to incorporate the use of the I → P → O model to help guide us in the design associated with the required updates for our program. As you will quickly see, both the Input and the Output components of the model lend themselves well to reading and writing data from external sources or files.
Using file streams along with arrays from the last chapter will really help make your job easier in the long run. From a design and programming point of view, the fact that we are now employing external streams versus the console provides only a few additional concerns.
As in the past, main continues to act as the driver for the overall program. As needed, calls are made to deal with each of the three main components of the I → P → O model. In relation to the input phase, we now acquire and read our data from an external storage device. Because the device is a separate entity of the computer, there are additional conditions that could arise, which we will need to be concerned with from a programming perspective. For example, the device could be full or not in a ready state when we attempt to read the input data. Likewise, where in the past the output phase directed the related output information to the console, we must now concern ourselves with some potential issues, such as a device that's not ready. Fortunately, the ability to use and validate these different forms of input and output streams is relatively easy when we write the actual code.
One final point you need to remember in terms of file streams versus the keyboard or console for I/O is that the role of the programmer is in no way reduced or diminished. For example, it is imperative that you always check to make sure that all records are read from the input file and that all records or information is written to any output-related devices or files. Missing the last, or first, record in the input file has no doubt caused many students and professionals a great deal of embarrassment, humiliation, and frustration. Please make it a point to always double-check both your inputs and outputs.
Figure 11.10.1 shows the structure chart used in the previous chapter with only two small modifications. The label for InputData has now been changed to ReadData, reflecting the fact that the data will be coming from a file stream versus the keyboard. Likewise, the previous output components called Print have been replaced by the word Generate to help avoid any potential confusion.
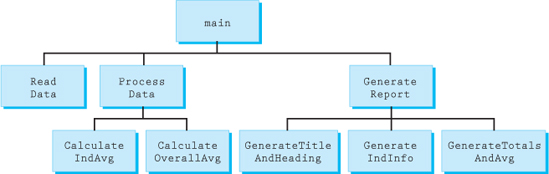
Figure 11.10.1 Structure chart
Now that the minor updates to the structure chart have been made, we can show the corresponding rough draft of the pseudocode, with only limited changes relating specifically to input and output activities.
Design:
Pseudocode



It is now time to double-check your pseudocode. Make any needed corrections or additions. Once you have proven that your algorithm works, the next step requires translating the pseudocode into C++ source code.
After you have created your Visual Studio Project and written the source code, be sure to add both the input and the output files to your project. This will save time in validating and examining the data and the associated results without ever having to leave the IDE.
11.11 C—The Differences
As we learned in Chapter 5, C accomplishes keyboard and console I/O in a totally different manner from C++, and the same goes for file I/O—no stream classes or objects are used. However, just as cin and cout were similar to the way we read and write files in C++, printf and scanf are very closely related to the way we read and write text files in C.
11.11.1 File Pointer
Instead of file streams, C uses something commonly called a file pointer—a variable that holds the address of a FILE structure. This pointer is what we will use to access the file once it has been opened. A structure is another data type similar to what we saw with classes. We will have much more to say about structures in Chapter 13. Example 11.11.1 demonstrates how to declare a file pointer.

Notice that a file pointer can be used to access both input and output files. To use the FILE structure, you need to include <stdio.h>, the same header file we used for printf and scanf.
11.11.2 Opening Files
Since FILE pointers are used for both reading and writing, C provides six modes that can be specified when opening a file. Three of these modes are listed and explained in Table 11.11.1. The other modes will be discussed in Chapter 17.
Table 11.11.1 File modes
| Mode | Explanation |
| r | Read mode. Open fails if file doesn't exist. |
| w | Write mode. Will create file if possible. Existing data is destroyed. |
| a | Append mode. Opens the file so data can be appended. Will create file. |
The fopen function opens a file in the specified mode and then returns the file pointer used to access the file. The basic fopen syntax follows:
<file-pointer> = fopen ( <filename>, <mode> );
The <filename> and <mode> are either cStrings or string literals. The <mode> is usually a string literal specifying one of the three modes in Table 11.11.1. Example 11.11.2 shows how to use the fopen function.

Even though Example 11.11.2 opens a file for reading, other modes are accomplished in the same way.
11.11.3 Checking for a Successful Open
The fopen function returns either an address, if the file was opened correctly, or NULL, if the file opening failed. As a result, all you need to do is check to see if the file pointer is NULL, as shown in Example 11.11.3.


Just as in C++, always check to see if the file was successfully opened before trying to access it.
11.11.4 Closing Files
There are a couple of ways to close files in C. The first method uses the fclose function. This is the preferred method, but you can also use the fcloseall function. The fclose function prototype follows:
int fclose ( FILE * fptr );
The fclose function returns a 0 if the file was closed. Be careful, though; if the file pointer is NULL when the fclose function is executed, your program will crash. Therefore, ensure that you only attempt to close a file if it was opened successfully.
The fcloseall function closes all files except for stdin, stdout, and stderr. The function prototype for fcloseall follows:
int fcloseall ( );
The fcloseall function returns an integer representing the number of files that were successfully closed. Example 11.11.4 demonstrates how to use these functions.

The reason fclose is preferred over fcloseall is that it is more precise. It forces you to specify the exact file to close, guaranteeing that you will not accidentally close something you shouldn't.
11.11.5 Writing to a File
Wouldn't it be nice if we could use printf to write to a file? Well, we can't—but we can use fprintf. The only difference between the two functions is that the first parameter in a call to fprintf is a file pointer. Everything else is exactly the same. Example 11.11.5 shows how to write to a file. Notice that even the output formatting used with printf remains the same for fprintf.

You might suspect that since there is a function called fprintf, there probably is a function called fscanf. You are absolutely correct! Except for the file pointer, the syntax is exactly the same as for scanf. You can also read until the end of the file by using the feof function. Both of these functions are shown in Example 11.11.6.

Now you should be able to perform file input and output routines using either C++ or C.
Over the past few years, the cost-associated with various external storage devices, such as pen drives and hard drives, have continued to drop dramatically. This chapter examined the value and use of these types of external devices for holding files made up of both input data and reports.
Since you have already been exposed to the use of streams via cin and cout, much of the material associated with getting information from a stream or sending information into a stream hopefully made sense rather quickly. Early on we showed how to associate a file located on an external device to an object or variable within a program. Once it was decided what to call a particular file, we established in what mode we wanted to open the file. The available modes presented included opening a file for reading, writing, or appending. Because there may indeed be a problem with locating a file, we illustrated how important it is that a check always be made to indicate that a file was successfully opened. Once the file is known to be open, we were ready to read or write data to the external device. Once access to the file is no longer needed, we discussed the need to close the file and release the resource back to the operating system.
The final two sections of the chapter introduced the concepts of sorting and searching data. Sorting involves placing the data contained within our arrays into an established order, while searching provides the facility to locate a specific key from within a list of data. While a thorough discussion of these two topics is beyond the scope of this text, this brief overview introduced two powerful activities often associated with handling or manipulating data.
11.13 Debugging Exercise
Download the following file from this book's website and run the program following the instructions noted in the code.
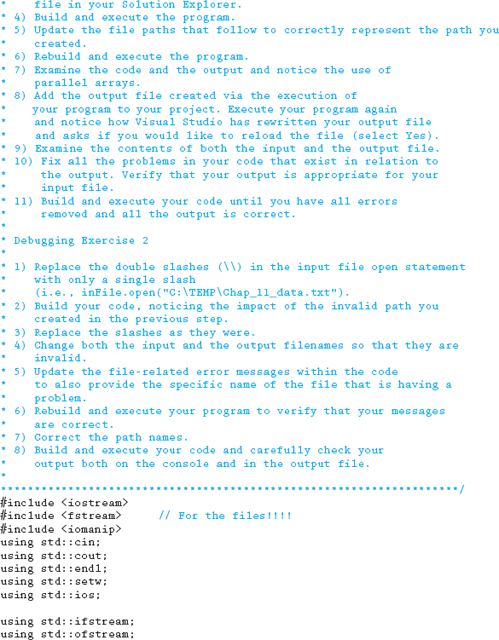


11.14 Programming Exercises
The following programming exercises are to be developed using all phases of the development method. Be sure to make use of good programming practices and style, such as constants, whitespace, indentation, naming conventions, and commenting. Make sure all input prompts are clear and descriptive and that your output is well formatted and looks professional.
1. For this exercise, read from a file a person's name, Social Security number, and wage; the number of hours worked in a week; and his or her status. For full-time employees, $5.00 is deducted from wages for union fees. A person is full time if he or she has an F as the status. Time and a half is paid for any time worked over 40 hours in a week. For the output, you must display the person's name, Social Security number, wage, number of hours, straight time pay, overtime pay, employee status, and net pay. Make sure the output is formatted into rows and columns and includes the appropriate titles and column headings.
Data: Use the following information as data for your data file:
John Smith 123-09-8765 9.00 46 F
Molly Brown 432-89-7654 9.50 40 F
Tim Wheeler 239-34-3458 11.25 83 F
Keil Wader 762-84-6543 6.50 35 P
Trish Dish 798-65-9844 7.52 40 P
Anthony Lei 934-43-9843 9.50 56 F
Kevin Ashes 765-94-7343 4.50 30 P
Cheryl Prince 983-54-9000 4.65 45 F
Kim Cares 343-11-2222 10.00 52 F
Dave Cockroach 356-98-1236 5.75 48 F
Will Kusick 232-45-2322 15.00 45 P
2. For this exercise, you will write a program to perform two main tasks. The first task simply asks the user to enter the name of a data file containing a list of 10 integers, each separated by a space or a line feed. After you have made sure that the file opened successfully and the data loaded into an array, display the smallest and the largest integer to the console. Once the smallest and largest integers have been printed, sort the entire list in ascending order and display each of the elements in the sorted list. Please use the following integers to test your program: 120 234 33 2021 44 23 530 567 340 501.
3. For this project, your supervisor wants you to write a program that starts by asking the user to enter the name of a text file that contains a number of sentences or lines. For each line you read, display a line number followed by a space and the line of text from the file. At the end of each line, display the number of characters in the line.
4. This program involves developing a menu-driven database application. You need to accept as input from a file a person's first name, last name, phone number, and birth date. This program will be menu driven with the following options:
1. Find a person's information
2. Add a person to the database
3. Edit a person's information
4. Display all records to the screen
5. Quit
![]() Option 1 allows the user to enter a name, after which the program will search for and display the person's information. Use the binary-search algorithm discussed in this chapter.
Option 1 allows the user to enter a name, after which the program will search for and display the person's information. Use the binary-search algorithm discussed in this chapter.
![]() Option 2 allows the user to add a person to the database.
Option 2 allows the user to add a person to the database.
![]() Option 3 allows the user to change any information related to a specific individual. Be aware that if the user changes the last name of the person, the arrays will need to be resorted.
Option 3 allows the user to change any information related to a specific individual. Be aware that if the user changes the last name of the person, the arrays will need to be resorted.
![]() Option 4 displays to the screen all of the records sorted by last name in the database.
Option 4 displays to the screen all of the records sorted by last name in the database.
![]() Option 5 will end the program.
Option 5 will end the program.
The data will be read from the file only once, and will only update the file after the person has chosen Option 5 from the menu. All other modifications to the data are performed on the arrays storing the information. Create your own data file using realistic personal data to exercise all of the options in the program.
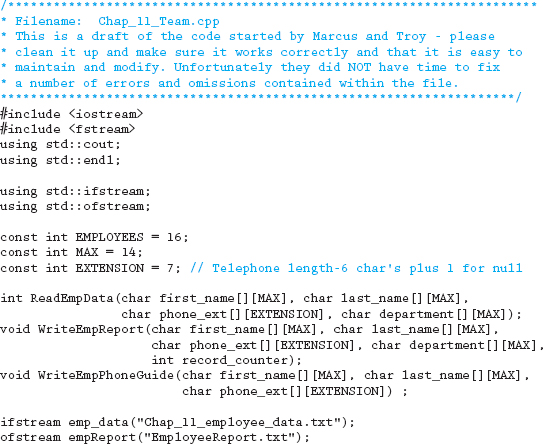
11.15 Team Programming Exercise
Do you remember Marcus, the developer turned manager we introduced a few chapters back? Well Marcus recently started another relatively short project but unfortunately didn't have the time to finish it. He asked Troy to complete it, but regrettably Troy was only able to spend a little time on the code before he too was called away to work on another project. As luck would have it, you have been asked to work through the code and get it functioning, even though it is in a pretty rough state.
Basically the program is to read from an external data file the first name, last name, extension number, and department for each of the employees of a small company. Once all the information has been placed into a series of arrays, the program should generate two separate output files. The first file, Employee Report, should be nicely formatted and contain the employee's name (i.e., last name, first name), extension number, and department. The second file, Telephone Guide, should contain only the name (first name followed by last name) and the extension number. Include titles and column headings for both reports.
Following is some additional information provided by Marcus and Troy:
1. The company has approximately 10 employees.
2. The name fields and the department field are limited to 15 characters.
3. There was some confusion on the naming convention to use within the source code. Make sure all your variables and constants are consistently named.
4. Either copy the input file from the website or create your own input file called Chap_11_employee_data.txt with the following data:
Alexis Blough 1-1921 CEO
Bill Pay 1-7711 Accounting
Willy Makit 4-1595 Sales
Marie Murray 1-4986 MIS
Cal Caldwellowinski 5-0911 MIS
Jamie Johanasola 5-9999 Marketing
5. Do not make the scope of the file streams global. Pass them to the appropriate function as needed.
6. Fix any of the “small” problems Marcus and Troy indicated were still in the source code—and make sure you close all the files.
7. Have fun and make sure you deal with all the necessary records and components being asked for.
8. Clean up Troy's code so that it follows a consistent style.


11.16 Answers to Chapter Exercises
Section 11.1
1. b. data in a human-readable format
2. a. true
b. false
c. true
d. true
Section 11.2
1. c. <fstream>
2. c. ifstream input( “filename.txt” );
3. a. true
b. false
c. true
d. true
e. false
Section 11.3
1. d. read, write, append
2. c. file position marker (FPM)
3. a. The request fails and the file will not be created.
4. You need to be careful because if the file does exist and you open it in write mode, you will be overwriting (i.e., destroying) any data previously contained within the file.
Section 11.4
1. d. make sure the file opened successfully
2. c. .is_open
3. b. .fail
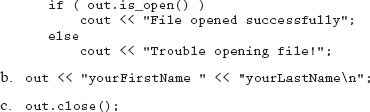
Section 11.6
1. d. close
2. b. ofstream
3. d. reference
4. a.
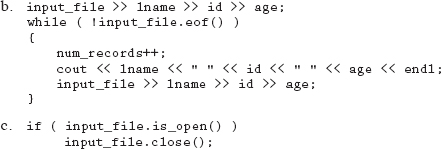
Section 11.7
1. c. ifstream
2. c. end of file
3. b. ofstream / ifstream
4. a. until the EOF marker is encountered
5. a.
6. a. false
b. true
c. true
d. true
e. true
Section 11.8
1. a. Be in order
2. c. linear (or sequential)
3. a. false
b. true
c. false
d. false
e. true
Section 11.9
1. d. bubble sort
2. a. true
b. true
c. true
d. true