
Pointers
Pointers have long been a source of trouble for beginners and experts alike. It takes a while for beginners to get used to pointers, and they are a fertile source of bugs in even professionals' programs. The pointer is an animal that is never entirely tamed, and it should be treated with respect. Pointers are no longer as crucial in basic C++ programming as they were in C, which is why I've delayed talking about them until this chapter. Indeed, Java deliberately eliminated pointers because they are potentially unsafe, although they are still there, disguised as references.
Pointers as References
You can think of memory as a large array of bytes, up to 4GB in length on a 32-bit machine. The address of a variable is the index into that array. You can define a pointer value as being an address. To find the address of a variable, you use the address-of operator (&), which we previously saw used in reference declarations (in “Reference Types”). Pointer values are traditionally expressed in hexadecimal (that is, base 16, not base 10), but you can typecast a pointer into an integer if you want to see the value in decimal, as in the following example, which also shows the addresses of two adjacent variables i1 and i2:
;> &i; (int*) 72CD30 ;> (int) &i; (int&) 7523632 ;> int i1=1,i2=2; ;> &i1; &i2; (int*) 72CD54 (int*) 72CD58
Notice in this example that the address of i2 is 4 bytes ahead of the address of i1. But don't depend on facts like this! These pointer values will not be the same on your machine. Generally, you should not use the actual values of these addresses. They will change as a program changes and will probably be different if the program is rebuilt on another platform.
A pointer is a variable that contains a pointer value. That is, it is a reserved area of memory, 4 bytes in size on most machines, that contains the address of some other variable. You declare and access pointers by using the dereference operator (*). The following example shows how. Figure 5.2 shows how i1, i2, and pi are laid out in memory for this particular example.
Figure 5.2. The pointer variable pi contains the address of the integer variable i1, which contains 1.
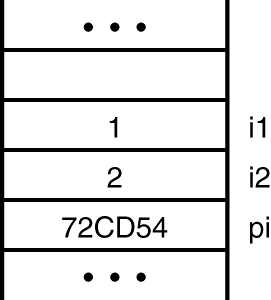
;> int i1 = 1, i2 = 2; ;> int *pi = &i1; ;> *pi; (int) 1 ;> *pi = 10; (int) 10 ;> int& ri = i1; ;> int *p2 = pi; ;> *p2; (int) 10
The result of dereferencing a pointer (*pi, in this case) is the value contained in the original variable i1. *pi is written exactly as iterator expressions such as *lpi (see “Iterators” in Chapter 3); a pointer is a special kind of iterator. *pi acts as an alias for i1, in the same way that the reference ri is an alias for i1. Both *pi and i1 refer to the same memory. You can have as many pointers as you like referring to the original variable. References are in fact a restricted kind of pointer, and they automatically dereference themselves (that is, you don't need *).
CAUTION
More than one pointer can be declared at once, but each new pointer must be preceded by *, as in the following example:
;> int *p3, *p4, p5; ;> p5 = &i1; CON 52: cannot convert from 'int*' to 'int'
This code declares p3 and p4 to have type int * but declares p5 to have type int. p5 is just a plain integer, and trying to put a pointer value into it results in an error. If you are used to a more relaxed language, C++'s insistence on types matching can become irritating. However, it prevents you from writing foolish or badly behaved code.
You can use any C++ type as the base type of a pointer. It is important to note that C++ will not let you automatically convert one pointer type to another. If you force the conversion by using a typecast, you are likely to get garbage. This is similar to what happens with passing arrays to functions; a double variable is 8 bytes and is organized very differently from a 4-byte integer. There is no translation involved with pointer assignments, such as when a double value is translated to an integer value. In the following example, a pointer to int is copied into a pointer to double, and the result of dereferencing that pointer is displayed. The bit pattern representing the integer 10 is some arbitrary (and very small) floating-point number.
;> int i = 10; ;> int *pi = &i; ;> double *pd; ;> pd = pi; // not allowed! CON 55: cannot convert from 'int*' to 'double*' ;> pd = (double *) pi; // force it! (double*) 72CD58 ;> *pd; (double&) 1.67896e-306
Using pointers with structures is probably the most common use of pointers. Note that just as with iterators, the clumsy (*ppt).x can be written as ppt->x, as in the following example:
;> Point pt = make_point(500,200); ;> Point *ppt = &pt; ;> (*ppt).x; (int) 500 ;> ppt->x; (int) 500
Some operating system functions use structures. For instance, the standard C header time.h contains the tm struct, which includes all you need to know about the time, and allows the time functions to pass back a large amount of information, as in the following example:
struct tm {
int tm_sec; /* seconds after the minute - [0,59] */
int tm_min; /* minutes after the hour - [0,59] */
int tm_hour; /* hours since midnight - [0,23] */
int tm_mday; /* day of the month - [1,31] */
int tm_mon; /* months since January - [0,11] */
int tm_year; /* years since 1900 */
int tm_wday; /* days since Sunday - [0,6] */
int tm_yday; /* days since January 1 - [0,365] */
int tm_isdst; /* daylight savings time flag */
};
The following function today() uses tm to generate a Date structure for today's date:
Date today() {
time_t t;
time(&t);
tm *ts = localtime(&t);
Date dd;
dd.year = ts->tm_year + 1900; // years since 1900...
dd.month = ts->tm_mon + 1; // it goes 0-11...
dd.day = ts->tm_mday;
return dd;
}
In this example, the type time_t is a typedef for a long integer; the time() function returns the number of seconds since midnight January 1, 1970 (which is when UNIX started counting time). localtime() returns a pointer to a tm struct, which you can transfer to the Date structure. The time functions in this example are a little eccentric, and there are things to watch out for (for example, the month field goes from 0 to 11). It is a good idea to keep this kind of unexpected behaviour wrapped up safely in a function so that you do not have to keep remembering to add 1900 to tm_year. One advantage of using a struct to return information from a function is that you need refer to only what you need, and you can ignore the rest.
Structures can themselves contain pointers. For instance, here is an Account structure that keeps information about money outstanding:
Struct Account {
Double amount;
Person *debtor;
Date when_due;
};
Why would you keep a pointer to a structure? Consider that any given Person object probably has a number of accounts (Account object), and Person is a rather large struct. So keeping one Person object shared among several Account objects would save memory and disk space. But the most important reason is that you keep one (and only one) Person object and thus there is no redundant information floating around. Sooner or later, the person's contact details change, and if you didn't share one object, you would have to go through every structure in the system that contains that Person object and update the details. (Some government departments seem to work like this.)
Pointers can also be used to pass variables by reference:
;> void update_value(int *p) { *p = 0; } ;> update_value(&i1); ;> i1; (int) i1 = 0
C, which does not have reference variables, uses pointers to pass structures by reference. Notice that you have to explicitly extract the address of the argument you want to pass by reference, using &. Many C++ programmers prefer this style because it shows that the argument of update_value() is going to be modified. With references, there is no way you can tell just by looking at the function call whether the argument is going to be modified or not.
What Pointers Refer To
The big difference between references and pointers (apart from needing to say *p to extract values from pointers) is that each reference is bound to one (and only one) variable. Pointers can be made to point to new variables, and they can also be made to point to anything, which makes them powerful and also potentially full of problems. Consider the following example. You can put an arbitrary number 648 into a pointer, although you will need an (int *) typecast to remove the error message. But usually any attempt to dereference such a bogus pointer results in a access violation message. In other words, 648 is considered an illegal address. Because local variables are not initialized automatically, you also need to watch out for uninitialized pointers.
;> int pi = 648; CON 42: cannot convert from 'const int' to 'int*' ;> pi = (int *)648; (int*) 288 ;> *pi; access violation <temp> (1)
By now I hope you're getting worried every time you see a typecast. Sometimes they are necessary, but too many typecasts usually spells trouble. You might wonder why this arbitrary value 648 was considered a bad pointer. Surely if you have 64MB of system memory, you can address everything from 0 to about 64×1024×1024 = 67,108,864, right? But modern operating systems don't work like that; each program (or process) gets its own 4GB address space, and only isolated sections of that total range are actually valid memory. System memory is virtual, with chunks of memory (called pages) being swapped to and from disk continuously. So you actually have about 100MB of virtual memory available if you have 64MB of random access memory (RAM), but it's much slower to access the disk than to access RAM. As you load more and more programs, your system grinds to a halt because it is constantly trying to page to disk. The separate address space for each process means that a program can't destroy another program's data; the pointer value 0x77DE230 (say) will have different meanings for different programs.
In Windows 9x, the upper 2GB is shared among all programs and is used for dynamic link libraries and the operating system. So your program can still overwrite system memory. This is a major reason Windows NT is more reliable than Windows 9x
In C++, you can have pointers to pointers. Remember that a pointer is basically a variable, so it has an address or pointer value, which you can store in another variable of a suitable type. Again, the style of declaration is meant to resemble how the pointer will be used; to dereference int** ppi (read as “pointer to pointer to int”), you would use *ppi. In the following code, I have ppi, which points to pi, which points to i1. *ppi will be the value of the pointer pi (that is, the address of i1). **ppi will be the value of i1.
;> int *pi = &i1; ;> int **ppi = π ;> *ppi; (int*) 72CD54 ;> **ppi; (int) 10 ;> void *pv = &i1; ;> double f; ;> pv = &f; // (double *) will convert directly to (void *) (void*) 72CE2C ;> *pv; // this will be an error!
There are two things to remember about void pointers: Any pointer will happily convert to a void pointer, and you cannot dereference a void pointer because the system does not know what the pointer's base type is.
The NULL Pointer
The NULL pointer is usually simply defined to be 0, which is an exception among integers; it matches any pointer type without typecasting. Trying to access memory at logical address zero always results in an access violation on machines that have memory protection. UnderC recognizes this as a special problem, but most compilers do not distinguish this case in their runtime errors. With the GNU compiler, a program will say something like “A has caused an error in A.EXE. A will now close” and give some helpful advice about restarting your computer if problems persist. (This is ultimately why I went to the trouble of creating UnderC: I spent years being frustrated with weird runtime errors and slow compilers!) Here you see UnderC's more friendly runtime error:
;> pi = NULL; (int*) 0 ;> *pi; NULL pointer <temp> (1)
Java programmers are likely to regard this as yet more proof that C++ is not to be trusted. With C++, you should always check to see whether a pointer is NULL because many programs use this value to indicate a special state.
Writing Structures to Binary Files
Up to now you have only written plain ASCII text to files. You can inspect such files with a text editor such as Notepad, and they contain no unprintable characters. The main difference between binary files and ASCII text files is that binary files can use all 256 ASCII characters, whereas text files tend to keep to a subset of the lower 127 characters.
The other difference between these types of files has to do with human stubbornness; when Microsoft developed DOS, it decided that the ends of lines of text should be indicated with two characters, a carriage return (cr) and a linefeed (lf). The UNIX people just used newline, which is written like in C character strings. (Mac people just use carriage return, so everyone is different.) When you write the string "this is a line " to a text file, " " must be translated into " "; the opposite translatation must occur when you read in a line.
Accessing a file in binary mode involves no filtering or translation. Streams default to text mode, so a special constant is needed when you open a file using ofstream. Here is a small function that writes a few integers directly to a file:
void binarr(int arr[], int n) {
ofstream out("arr.bin",ios::binary);
out.write((char *) arr, n*sizeof(int));
}
;> int a[] = { 1,2,3,4};
;> binarr(a,4);
You use another of the ios constants (ios::binary) to indicate that any character written out to this file should not be translated. An integer might include a byte with the value of (that is, hex 0x0A or decimal 10), and you don't want write() inserting an extra . UNIX programmers should particularly be aware of this potential problem with Windows.
The write() method takes two arguments: a pointer to char and the total size (in bytes) of the data to be written. Usually, you have to put in a typecast to force the type to be (char *); if it were (void *), then any pointer would freely convert. If you now look at the created arr.bin file, you'll see that it is exactly 16 bytes (4 integers of 4 bytes each.) You can use a utility such as DOS DEBUG to look at the first few bytes of the file:
c:ucwexampleschap5> debug arr.bin -d 0100,010f 1AC2:0100 01 00 00 00 02 00 00 00-03 00 00 00 04 00 00 00 -q c:ucwexampleschap5
Sure enough, 1, 2, 3, and 4 each take up 4 bytes. Notice that the least significant part of each number (that is, the low byte) appears first. Because the most significant part is at the end, this is called big-endian, which is how Intel processors arrange bytes. (Little-endian, on the other hand, is how Motorola processors arrange the bytes, with the least significant part at the end; you use little-endian when you write down numbers: 45,233.)
I mention big-endian and little-endian now to raise a warning: Binary files are not fully portable across different platforms. Consider someone trying to read the four integers in arr.bin on a non-Intel machine. A Macintosh would be confused by the byte ordering, because it has a little-endian processor. A Silicon Graphics workstation is a 64-bit machine (making sizeof(int) equal to 8), so the integers in the file would be the wrong size. In recent years, therefore, there has been a move toward ASCII data standards, such as Hypertext Markup Language and rich text format.
So what are the advantages of binary files?
They are usually more compact and are definitely more efficient than ASCII files. The four integers in the last example were transferred without any translation. To write out four integers as text, they must be converted into decimal representation.
They are more secure than text files. Users strongly believe that any ASCII files are for them to edit, and they will then blame you when the application no longer works.
They are particularly good at accurate storage of floating-point numbers.
It is easy to write a structure directly into a binary file (as we will see.)
Most importantly, you have true random access to the file. That is, you can move to any arbitrary point in the file, given the offset in bytes (this is often called 'seeking') The text translation involved in text files makes such access unreliable.
NOTE
There are some things you cannot write to disk very easily. It is meaningless to write a pointer out directly because it will not have any meaning if you read it in again. A pointer refers to a specific address, which is kindly (and temporarily) allocated to you by the operating system. Besides, copying the pointer does not copy the data! Not only pointers are affected by this restriction; if you look under the hood, you will see that standard strings are basically structures that contain pointers. So structures such as Person, which contains strings, are unsuitable for direct binary input/output.
Allocating Memory with new and delete
So far you've used two methods for allocating memory to variables. The first method is through a global or static declaration, where the compiler reserves space when it is generating the code. (Note that static allocation in UnderC is limited to about 1MB.) The second method is by using local variables (called automatic allocation), which has the advantage that the memory is used only within the function call. The third kind of memory allocation is dynamic: At any point, a program asks for a block of memory from the heap, which is the pool of free system memory. The heap is only limited by the amount of memory available on your system. This allocation is achieved by using the new operator:
;> int *p = new int; ;> *p = 2; (int) 2
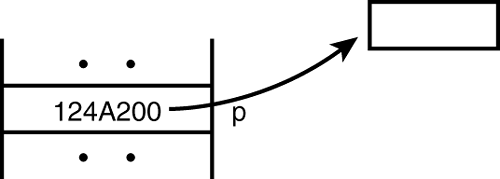
Earlier in this chapter, we spoke of pointers referring to other variables; that is, a pointer is another way of accessing a variable. Some people speak of dynamically allocated pointers as being nameless variables, which are accessible only through the pointer. Figure 5.3 shows this situation; the pointer value is outside the block of statically allocated memory.
A marvelous thing about dynamic memory is that you can give it back to the system by using delete. When you are finished with a pointer, you should give the block of memory back. After you delete the pointer, that memory no longer belongs to you, and the pointer is called a dangling pointer. It is like a phone number after the service has been disconnected. By deleting a block, you are giving permission to the system to do anything it likes with the block, including giving it to some other part of the program. Accessing dangling pointers can cause problems that are particularly hard to trap. Here is how you use delete to give memory back to the system:
;> int *p = new int; // ask for a 4 byte block ;> *p = 2; (int) 2 ;> delete p; // give the block back ;> *p; // p is no longer valid (int) 9773312
It is useful to write functions that create pointers to objects and guarantee that the resulting object is properly initialized. This function guarantees that the name fields of a Person are properly set:
Person *new_person(string fname, string lname)
{
Person *pp = new Person;
pp->first_name = fname;
pp->last_name = lname;
return pp;
}
It is possible for a struct to contain a pointer to an object of the same type. Obviously, you can't have a member that is the same struct (because the system doesn't know how big the struct is until it's defined), but a member can be another pointer because all pointers are the same size.
Imagine that the struct Person discussed earlier in this chapter has an extra field, parent, of type Person *. You can set up a chain of Person objects (as long as parent is initialized to NULL):
;> Person *fred = new_person("Fred","Jones"); ;> fred->parent = new_person("Jim","Jones"); ;> fred->parent->parent = new_person("Joshua","Jones"); ;> for(Person *p = fred; p != NULL; p = p->parent) cout << p->first_name << endl; Fred Jim Joshua
The parent field being NULL at the end is an example of a NULL pointer that is used to indicate some condition—in this case, the end of Fred's ancestors. The for loop may seem unfamiliar, but remember that the second section (p != NULL) is tested before the output statement, and the third section (p = p->parent) executes after the output statement, moving you to the next parent in the chain. This curious arrangement is called a linked list, and in fact it is how the standard list is implemented. Figure 5.4 shows how these Person objects are linked to each other (with the name fields indicated as pointers to emphasize that the names are not stored inside the struct). But you would rarely have to write such code since std::list already implements a linked list. It would in fact be better to use list<Person> in this case.
Figure 5.4. The pointer fred points to a chain, or list, of Person objects.

NOTE
You may be wondering why pointers are so important, given that they seem to be a major cause of program bugs. The primary use of pointers is to access dynamic blocks of memory. You have been using them for this purpose without realizing it, because the standard containers do this all the time. Modern C++ practice prefers to keep pointers hidden within trusted library code, precisely because they can be such trouble. It is best to wrap up a pointer tangle in an easily used package.