
Chapter 3
Security Architecture and Engineering
This chapter covers the following topics:
Engineering Processes Using Secure Design Principles: Concepts discussed include the ISO/IEC 15288:2015 and NIST SP 800-160 systems engineering standards, objects and subjects, closed versus open systems, threat modeling, least privilege, defense in depth, secure defaults, fail securely, separation of duties (SoD), keep it simple, Zero Trust, Privacy by design, Trust but verify, and shared responsibility.
Security Model Concepts: Concepts discussed include confidentiality, integrity, and availability; security modes; security model types; security models; system architecture steps; ISO/IEC 42010:2011; computing platforms; security services; and system components.
System Security Evaluation Models: Concepts discussed include TCSEC, ITSEC, Common Criteria, security implementation standards, and controls and countermeasures.
Certification and Accreditation: Concepts discussed include certification, accreditation, and the phases of accreditation.
Control Selection Based on Systems Security Requirements: Concepts discussed include selecting controls for systems based on security requirements.
Security Capabilities of Information Systems: Concepts discussed include memory protection, virtualization, Trusted Platform Module, interfaces, fault tolerance, policy mechanisms, and encryption/decryption.
Security Architecture Maintenance: Concepts discussed include maintaining security architecture.
Vulnerabilities of Security Architectures, Designs, and Solution Elements: Concepts discussed include client-based systems, server-based systems, database systems, cryptographic systems, industrial control systems, cloud-based systems, large-scale parallel data systems, distributed systems, Internet of Things, microservices, containerization, serverless, high-performance computing (HPC) systems, edge computing systems, and virtualized systems.
Vulnerabilities in Web-Based Systems: Concepts discussed include maintenance hooks, time-of-check/time-of-use attacks, web-based attacks, XML, SAML, and OWASP.
Vulnerabilities in Mobile Systems: Concepts discussed include the vulnerabilities encountered when using mobile systems, such as device security, application security, and mobile device concerns.
Vulnerabilities in Embedded Systems: Concepts discussed include the issues that are currently being seen with the advent of machine-to-machine communication and the Internet of Things.
Cryptographic Solutions: Topics discussed include cryptographic concepts, cryptography history, cryptosystem features, cryptographic mathematics, and cryptographic life cycle.
Cryptographic Types: Concepts discussed include running key and concealment ciphers, substitution ciphers, transposition ciphers, symmetric algorithms, asymmetric algorithms, hybrid ciphers, elliptic curves, and quantum cryptography.
Symmetric Algorithms: Algorithms discussed include Digital Encryption Standard and Triple Data Encryption Standard, Advanced Encryption Standard, IDEA, Skipjack, Blowfish, Twofish, RC4/RC5/RC6/RC7, and CAST.
Asymmetric Algorithms: Algorithms discussed include Diffie-Hellman, RSA, El Gamal, ECC, Knapsack, and zero-knowledge proof.
Public Key Infrastructure and Digital Certificates: Concepts discussed include CAs and RAs, certificates, certificate life cycle, CRLs, OCSP, PKI steps, and cross-certification.
Key Management Practices: Concepts discussed include the key management practices that organizations should understand, including symmetric key management and asymmetric key management.
Message Integrity: Concepts discussed include hashing, one-way hash, message authentication code, and salting.
Digital Signatures and Non-repudiation: This section covers the use of digital signatures, including DSS and non-repudiation.
Applied Cryptography: This section covers link encryption, end-to-end encryption, email security, and Internet security.
Cryptanalytic Attacks: Attacks discussed include ciphertext-only attack, known plaintext attack, chosen plaintext attack, chosen ciphertext attack, social engineering, brute force, differential cryptanalysis, linear cryptanalysis, algebraic attack, frequency analysis, birthday attack, dictionary attack, replay attack, analytic attack, statistical attack, factoring attack, reverse engineering, meet-in-the-middle attack, ransomware attack, side-channel attack, implementation attacks, fault injection, timing attack, pass-the-hash attack, and Kerberos exploitation.
Digital Rights Management: This section explains digital rights management, including document, music, movie, video game, and e-book DRM.
Site and Facility Design: Concepts discussed include a layered defense model, CPTED, physical security plan, and facility selection issues.
Site and Facility Security Controls: Controls discussed include doors, locks, biometrics, glass entries, visitor control, wiring closets/intermediate distribution facilities, restricted and work areas (secure data center, restricted work area, server room, media storage facilities, and evidence storage), environmental security and issues, and equipment security.
The Security Architecture and Engineering domain addresses a broad array of topics including security engineering processes, security models, security controls, assessing and mitigating vulnerabilities, cryptography, and site and facility security controls. Out of 100 percent of the exam, this domain carries an average weight of 13 percent, which ties with two other domains for the third highest weight.
Security architecture and engineering are mainly concerned with the design, implementation, monitoring, and securing of information security assets. These assets include computers, equipment, networks, and applications. Within this area, a security professional must understand security models, system vulnerabilities, cryptography, and physical security. But simply understanding security architecture and engineering is not enough. A security professional must also know how to implement security architecture engineering to ensure that assets are protected. Organizations must understand what they need to secure, why they need to secure it, and how it will be secured.
Foundation Topics
Engineering Processes Using Secure Design Principles
Systems engineering is an approach for the design, realization, technical management, operations, and retirement of a system. In general, a system is a collection of elements that together produce results not obtainable by the individual elements alone. In IT specifically, a system may involve single or multiple computers or devices working together to achieve a particular result. For example, an online ordering system may involve a web server, an e-commerce server, and a database server. However, these systems alone cannot provide adequate security to online transactions. An organization may need to include routers, firewalls, and other security mechanisms to ensure that security is integrated into the total design solutions.
Organizations must implement and manage systems engineering processes using secure design principles. Systems engineering is usually modeled based on a life cycle. Chapter 1, “Security and Risk Management,” discusses groups that establish standards, including International Organization for Standardization (ISO)/International Electrotechnical Commission (IEC) and the National Institute of Standards and Technology (NIST). These groups both have established standards for systems engineering: ISO/IEC 15288:2015 and NIST Special Publication (SP) 800-160, which supersedes NIST SP 800-27.
ISO/IEC 15288:2015 establishes four categories of processes:

Agreement processes: This category includes acquisition and supply.
Organizational project-enabling processes: This category includes life cycle model management, infrastructure management, portfolio management, human resource management, quality management, and knowledge management.
Technical management processes: This category includes project planning, project assessment and control, decision management, risk management, configuration management, information management, measurement, and quality assurance.
Technical processes: This category includes business or mission analysis, stakeholder needs and requirements definition, system requirements definition, architecture definition, design definition, system analysis, implementation, integration, verification, transition, validation, operation, maintenance, and disposal.
The systems life cycle stages of this standard include concept, development, production, utilization, support, and retirement. While this standard defines system life cycle processes, it does not by itself address security during systems engineering.
NIST SP 800-160 is based on ISO/IEC 15288:2015 and discussed in Chapter 1.
To understand engineering using secure design principles, organizations must understand the difference between objects and subjects and closed versus open systems.
Objects and Subjects
Objects are resources that a user or process wants to access, and subjects are the users or processes requesting access. If the resource is requesting access, it is a subject. If a resource is being accessed, it is an object. Many resources can be both objects and subjects.
Let’s look at an example. Suppose Jim, a user, wants to access an application. In this case, Jim is a subject, and the application is an object. If the application Jim uses needs to access a database, then the application is the subject, and the database is the object.
Closed Versus Open Systems
A closed system is a proprietary system that is designed to work with a limited range of other systems. Open systems conform to industry standards and can work with systems that support the same standard. When an organization is integrating these systems, closed systems are harder to integrate, whereas open systems are much easier to integrate.
Threat Modeling
Threat modeling is the process of identifying potential threats and determining possible mitigations and countermeasures, if any, for the threats. The process can provide an organization with an attacker’s profile, likely attack vectors, targeted asset, and an analysis of the controls or defenses that should be implemented for the identified threats.
Least Privilege
The principle of least privilege is important in the design of systems. Least privilege means that users are granted access only to the information and resources that are minimally necessary for them to do their jobs. If the principle of least privilege is strictly enforced across an organization and the appropriate procedures are in place, privilege creep, wherein user privileges accumulate over time, will be prevented so that systems are as secure as possible.
When designing operating system processes, security professionals should ensure that system processes run in user mode when possible. When a process executes in privileged mode, the potential for vulnerabilities greatly increases. If a process needs access to privileged services, it is best to use an application programming interface (API) to ask for supervisory-mode services.
Related to the principle of least privilege, the principle of least functionality is that systems and devices should be configured to provide only essential or minimally required capabilities and specifically prohibit or restrict the use of functions, ports, protocols, and services.
Defense in Depth
Communications security management and techniques are designed to prevent, detect, and correct errors so that the CIA of transactions over networks might be maintained. Most computer attacks result in a violation of one of the security properties: confidentiality, integrity, or availability. A defense-in-depth approach refers to deploying layers of protection. For example, even when you are deploying firewalls, access control lists (ACLs) should still be applied to resources to help prevent access to sensitive data in case the firewall is breached.
Secure Defaults
Secure defaults, also referred to as secure by default, is a term used to describe a condition wherein an application’s or device’s default settings are set to the most secure settings possible. If the application or device is reset, these secure defaults should be maintained. Security professionals should keep in mind that the most secure settings are not often the most user-friendly settings.
If a technology follows secure defaults principles, the technology will have embedded, built-in cybersecurity principles. Depending on the technology, device, or application, best practices in secure defaults should include password prompts, history, length and strength, the closing of unused ports or services, encryption, and remote access disablement.
Fail Securely
To understand the concept of fail securely, security professionals must understand two related terms: fail safe and fail secure. Most often these terms are used in conjunction with physical controls, particularly door locks.
A product that is fail safe is unlocked when power is removed. Personnel therefore can enter or leave the area. A product that is fail secure is locked when power is removed. In this case, personnel can leave the area, but they must use a key to enter the area. These terms refer to the status of the secure side of the door. Most products provide free egress or exit whether they are fail safe or fail secure.
Fail-safe products should never be used for areas of high security. Simply cutting the power would give a threat actor access to the security area. Security professionals should ensure that public or general areas use fail-safe products, whereas secure areas, such as data centers, use fail-secure products.
Separation of Duties (SoD)
Separation of duties (SoD) is an internal personnel control that distributes the tasks and associated privileges for a security process among multiple personnel. It is most often associated with an organization’s financial accounting policies whereby controls are put into place for issuing checks. The person inputting the payment information is usually a separate person than the one who signs or otherwise authorizes the checks after printing. In addition, organizations often implement policies whereby checks above a certain amount require two signatures.
SoD, as it relates to security, has two primary objectives: (1) to prevent conflict of interest, fraud, abuse, or errors and (2) to detect control failures, including breaches, data theft, and circumvention of security controls.
SoD restricts the power or influence held by any one person. It also ensures that personnel do not have conflicting responsibilities and are not responsible for reporting on themselves or their superiors. For example, in an IT department, the person who creates the user accounts can only do so with the proper request made by a department head or asset owner, and the person who assigns the appropriate permissions can only do so with the proper request made by the data or asset owner.
Keep It Simple
Keep it simple, also referred to as keep it simple, stupid (KISS), is a design principle that states a design and/or system should be as simple as possible and avoid unneeded complexity. Simplicity guarantees the greatest levels of user acceptance and interaction.
Security professionals should ensure that organizations focus on implementing simple controls to provide security for confidentiality, integrity, and availability. To offset the need for controls to be simple, organizations should deploy a layered security model.
Zero Trust
Zero trust is a security model based on the principle of maintaining strict access controls and not trusting anyone or anything by default. Zero trust requires strict identity verification for every person and device trying to access resources on a private network, regardless of whether they are sitting within or outside of the network perimeter.
In a zero trust environment, each access request is fully identified, authenticated, authorized, and encrypted before granting access. A zero trust environment is built upon five fundamental elements:
The person or device is always assumed to be hostile.
External and internal threats exist at all times.
Location is not sufficient for deciding trust in a person or device.
Every device, user, and communication is identified, authenticated, and authorized.
Policies must be dynamic and calculated from as many sources of data as possible.
To fully implement zero trust, organizations must deploy multifactor authentication (MFA), the principle of least privilege, and endpoint validation.
Privacy by Design
Privacy by design is a term that implies data protection through technology design. Behind this is the thought that data protection in data processing procedures is best adhered to when it is already integrated in the technology at creation. It is a concept in the General Data Protection Regulation (GDPR).
In new systems, security professionals should implement privacy by design by emphasizing privacy and security throughout the design process. Privacy should be integrated into a system from day one. Security professionals should implement privacy by design in an existing system by deconstructing and analyzing the system. This is more difficult and time-consuming. A privacy audit should be performed on the existing system to examine how privacy has been embedded into the system, identify weak-points, and create new user-friendly solutions.
Trust but Verify
Trust but verify is a principle that is used when communicating entities trust each other but verify that such trust should be provided through the verification of an established relationship. When implementing trust but verify, security professionals should ensure their organizations
Use multiple asset inventory tools for verification and validation.
Use vulnerability management scanning tools to verify patching and hardening settings.
Use account reviews to verify that the principle of least privilege is enforced.
Use penetration tests and security posture testing in production environments.
Document supporting artifacts and evidence for audits and reviews.
Using a trust but verify approach ensures that checks and balances are implemented and that the appropriate controls are deployed to meet the expectations of the organization.
Shared Responsibility
Shared responsibility is a principle that requires that each user is accountable for different aspects of security and all must work together to ensure full coverage. All personnel within an organization must be aware of their responsibilities regarding security. During annual security and awareness training, personnel should be given scenarios wherein they see when and how to report security issues they may encounter.
All organizations should implement a security issues reporting portal so that it becomes part of organizational culture. This portal should include a feature that allows personnel to anonymously report security issues or violations that they observe to the appropriate management. Personnel can choose to remain anonymous or to disclose their identity.
Security Model Concepts
Security measures must have a defined goal to ensure that the measure is successful. All measures are designed to provide one of a core set of protections. In the following sections, the three fundamental principles of security are discussed. Also, an approach to delivering these goals is covered. In addition, these sections cover the security modes, security model types, security models, and system architecture. Finally, it covers ISO/IEC 42010:2011, computing platforms, security services, and system components.
Confidentiality, Integrity, and Availability
The essential security principles of confidentiality, integrity, and availability are referred to as the CIA triad. Confidentiality is provided if the data cannot be read either through access controls and encryption for data as it exists on a hard drive or through encryption as the data is in transit. With respect to information security, confidentiality is the opposite of disclosure.
Integrity is provided if you can be assured that the data has not changed in any way. This is typically provided with a hashing algorithm or a checksum of some kind. Both methods create a number that is sent along with the data. When the data gets to the destination, this number can be used to determine whether even a single bit has changed in the data by calculating the hash value from the data that was received. This approach helps to protect data against undetected corruption.
Some additional integrity goals are to
Prevent unauthorized users from making modifications.
Maintain internal and external consistency.
Prevent authorized users from making improper modifications.
Availability describes what percentage of the time the resource or the data is available. This is usually measured as a percentage of “up” time, with 99.9 percent up time representing more availability than 99 percent up time. Making sure that the data is accessible when and where it is needed is a prime goal of security.
Confinement
Confinement is a term used to describe isolating processes or machines/subsystems in a larger system. When a process is confined, the process is only allowed to read from and write to certain memory locations and resources. Confinement is usually carried out using the operating system, through a confinement service, or using a hypervisor.
Bounds
On a system, processes run at an assigned authority level, which defines what the process can do. Two common authority levels are user and kernel. The bounds of a process set limits on the memory addresses and resources the process can access. The bounds logically segment memory areas for each process to use. Highly secure systems will physically bound the processes, meaning that the processes run in memory areas that are physically separated from each other. Logically bounded memory is cheaper than but not as secure as physically bounded memory.
Isolation
A process runs in isolation when it is confined using bounds. Process isolation ensures that any actions taken by the process will only affect the memory and resources used by the isolated process. Isolation prevents other processes, applications, or resources from accessing the memory or resources of another.
Security Modes
A mandatory access control (MAC) system operates in different security modes at various times, based on variables such as sensitivity of data, the clearance level of the user, and the actions users are authorized to take. The following sections provide descriptions of these modes.
Dedicated Security Mode
A system is operating in dedicated security mode if it employs a single classification level. In this system, all users can access all data, but they must sign a nondisclosure agreement (NDA) and be formally approved for access on a need-to-know basis.
System High Security Mode
In a system operating in system high security mode, all users have the same security clearance (as in the dedicated security model), but they do not all possess a need-to-know clearance for all the information in the system. Consequently, although users might have clearance to access an object, they still might be restricted if they do not have need-to-know clearance pertaining to the object.
Compartmented Security Mode
In the compartmented security mode system, all users must possess the highest security clearance (as in both dedicated and system high security), but they must also have valid need-to-know clearance, a signed NDA, and formal approval for all information to which they have access. The objective is to ensure that the minimum number of people possible have access to information at each level or compartment.
Multilevel Security Mode
When a system allows two or more classification levels of information to be processed at the same time, it is said to be operating in multilevel security mode. Users must have a signed NDA for all the information in the system and will have access to subsets based on their clearance level, need-to-know, and formal access approval. These systems involve the highest risk because information is processed at more than one level of security, even when all system users do not have appropriate clearances or a need to know for all information processed by the system. This is also sometimes called controlled security mode. Table 3-1 compares the four security modes and their requirements.
Table 3-1 Security Modes Summary
| Signed NDA | Proper Clearance | Formal Approval | Valid Need to Know |
Dedicated | All information | All information | All information | All information |
System high | All information | All information | All information | Some information |
Compartmented | All information | All information | Some information | Some information |
Multilevel | All information | Some information | Some information | Some information |
Assurance and Trust
Whereas a trust level describes the protections that can be expected from a system, assurance refers to the level of confidence that the protections will operate as planned. Typically, higher levels of assurance are achieved by dedicating more scrutiny to security in the design process. The section “System Security Evaluation Models,” later in this chapter, discusses various methods of rating systems for trust levels and assurance.
Security Model Types
A security model describes the theory of security that is designed into a system from the outset. Formal models have been developed to approach the design of the security operations of a system. In the real world, the use of formal models is often skipped because it delays the design process somewhat (although the cost might be a lesser system). This section discusses some basic model types along with some formal models derived from the various approaches available.
A security model maps the desires of the security policy makers to the rules that a computer system must follow. Different model types exhibit various approaches to achieving this goal. The specific models that are contained in the section “Security Models” incorporate various combinations of these model types.
State Machine Models
The state of a system is its posture at any specific point in time. Activities that occur in the process of the system operating alter the state of the system. After the security professional examines every possible state the system could be in and ensures that the system maintains the proper security relationship between objects and subjects in each state, the system is said to be secure. The Bell-LaPadula model discussed in the later section “Security Models” is an example of a state machine model.
Multilevel Lattice Models
The lattice-based access control model or multilevel lattice model was developed mainly to deal with confidentiality issues and focuses itself mainly on information flow. Each security subject is assigned a security label that defines the upper and lower bounds of the subject’s access to the system. Controls are then applied to all objects by organizing them into levels or lattices. Objects are containers of information in some format. These pairs of elements (object and subject) are assigned a least upper bound of values and a greatest lower bound of values that define what can be done by that subject with that object.
A subject’s label (remember a subject can be a person, but it can also be a process) defines what level someone can access and what actions can be performed at that level. With the lattice-based access control model, a security label is also called a security class. This model associates every resource and every user of a resource with one of an ordered set of classes. The lattice-based model aims at protecting against illegal information flow among the entities.
Matrix-Based Models
A matrix-based model organizes tables of subjects and objects indicating what actions individual subjects can take upon individual objects. This concept is found in other model types as well, such as the lattice model discussed in the previous section. Access control to objects is often implemented as a control matrix. It is a straightforward approach that defines access rights to subjects for objects. The two most common implementations of this concept are ACLs and capabilities. In its table structure, a row would indicate the access one subject has to an array of objects. Therefore, a row could be seen as a capability list for a specific subject. It consists of the following parts:
A list of objects
A list of subjects
A function that returns an object’s type
The matrix itself, with the objects making the columns and the subjects making the rows
Noninterference Models
In multilevel security models, the concept of noninterference prescribes those actions that take place at a higher security level but do not affect or influence those that occur at a lower security level. Because this model is less concerned with the flow of information and more concerned with a subject’s knowledge of the state of the system at a point in time, it concentrates on preventing the actions that take place at one level from altering the state presented.
One of the attack types that this conceptual model is meant to prevent is interference, which occurs when someone has access to information at one level that allows them to infer information about another level.
Information Flow Models
Any of the models discussed in the next section that attempt to prevent the flow of information from one entity to another that violates or negates the security policy is called an information flow model. In the information flow model, what relates two versions of the same object is called the flow. A flow is a type of dependency that relates two versions of the same object, and thus the transformation of one state of that object into another, at successive points in time. In a multilevel security (MLS) system, a one-way information flow device called a pump prevents the flow of information from a lower level of security classification or sensitivity to a higher level.
For example, the Bell-LaPadula model (discussed in the section “Security Models”) concerns itself with the flow of information in the following three cases:
When a subject alters an object
When a subject accesses an object
When a subject observes an object
The prevention of illegal information flow among the entities is the aim of an information flow model.
Take-Grant Model
A system in the Take-Grant model is represented as a directed graph, called a protection graph. The subjects and objects of the computer system are the vertices, and the access rights of subjects to objects are represented by arcs. Although the Take-Grant model uses standard access rights like read and write, the Take-Grant model includes two additional access rights:
Take (t) is the right to take any access rights from the subject.
Grant (g) is the right to assign its access rights to any subject.
Figure 3-1 shows a graph of the Take-Grant model’s Take and Grant access rights.
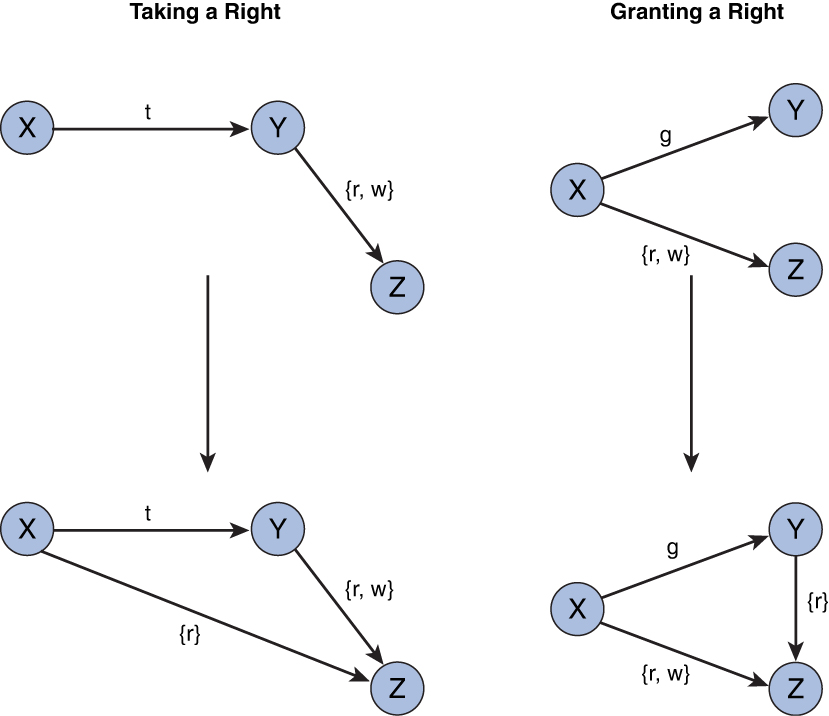
Figure 3-1 Take-Grant Model’s Example of Take and Grant
Security Models
A number of formal models incorporating the concepts discussed in the previous section have been developed and used to guide the security design of systems. The following sections discuss some of the more widely used or important security models, including the following:
Bell-LaPadula model
Biba model
Clark-Wilson integrity model
Lipner model
Brewer-Nash (Chinese Wall) model
Graham-Denning model
Harrison-Ruzzo-Ullman model
Goguen-Meseguer model
Sutherland model
Bell-LaPadula Model
The Bell-LaPadula model was the first mathematical model of a multilevel system that used both the concepts of a state machine and those of controlling information flow. It formalizes the U.S. DoD multilevel security policy. It is a state machine model capturing confidentiality aspects of access control. Any movement of information from a higher level to a lower level in the system must be performed by a trusted subject.
Bell-LaPadula, known as “no read up and no write down,” incorporates three basic rules with respect to the flow of information in a system:
The simple security rule: A subject cannot read data located at a higher security level than that possessed by the subject (also called no read up).
The star (*)-property rule: A subject cannot write to a lower level than that possessed by the subject (also called no write down or the confinement rule).
The strong star property rule: A subject can perform both read and write functions only at the same level granted to the subject.
The *-property rule is depicted in Figure 3-2.
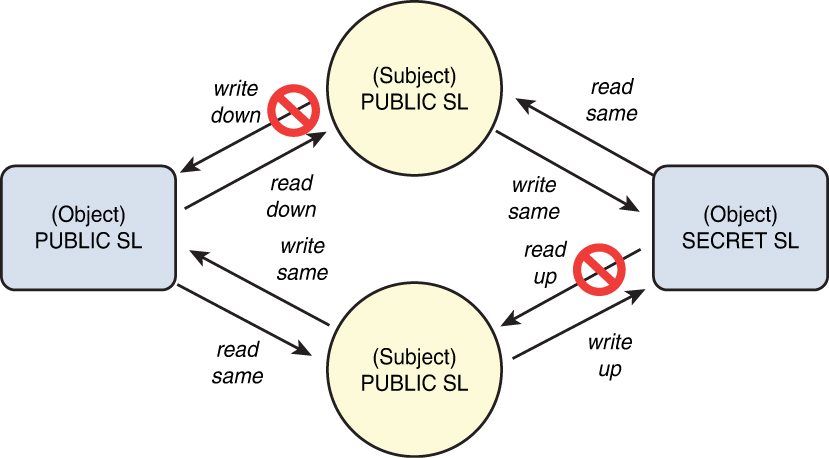
Figure 3-2 The *-Property Rule
The main concern of the Bell-LaPadula security model and its use of these rules is confidentiality. Although its basic model is a MAC system, another property rule called the discretionary security property (ds-property) makes a mixture of mandatory and discretionary controls possible. This property allows a subject to pass along permissions at its own discretion. In the discretionary portion of the model, access permissions are defined through an access control matrix using a process called authorization, and security policies prevent information flowing downward from a high security level to a low security level.
The Bell-LaPadula security model does have limitations. Among those are
It contains no provision or policy for changing data access control. Therefore, it works well only with access systems that are static in nature.
It does not address what are called covert channels. A low-level subject can sometimes detect the existence of a high-level object when it is denied access. Sometimes it is not enough to hide the content of an object; also their existence might have to be hidden.
Its main contribution at the expense of other concepts is confidentiality.
This security policy model was the basis for the Orange Book, discussed in the later section “TCSEC.”
Biba Model
The Biba model came after the Bell-LaPadula model and shares many characteristics with that model. These two models are the most well-known of the models discussed here. It is also a state machine model that uses a series of lattices or security levels, but the Biba model concerns itself more with the integrity of information rather than the confidentiality of that information. It does this by relying on a data classification system to prevent unauthorized modification of data. Subjects are assigned classes according to their trustworthiness; objects are assigned integrity labels according to the harm that would be done if the data were modified improperly.
Like the Bell-LaPadula model, the Biba model applies a series of properties or axioms to guide the protection of integrity. Its effect is that data must not flow from a receptacle of given integrity to a receptacle of higher integrity:
Integrity axiom: Subjects cannot write to a higher integrity level than that to which they have access (no write up).
Simple integrity axiom: Subjects cannot read to a lower integrity level than that to which they have access (no read down).
Invocation property: Subjects cannot invoke (request service of) higher integrity.
Clark-Wilson Integrity Model
Developed after the Biba model, the Clark-Wilson integrity model also concerns itself with data integrity. The model describes a series of elements that are used to control the integrity of data as listed here:
User: An active user’s agent
Transformation procedure (TP): An abstract operation, such as read, write, and modify, implemented through programming
Constrained data item (CDI): An item that can be manipulated only through a TP
Unconstrained data item (UDI): An item that can be manipulated by a user via read and write operations
Integrity verification procedure (IVP): A check of the consistency of data with the real world
This model enforces these elements by allowing data to be altered only through programs and not directly by users. Rather than employing a lattice structure, it uses a three-part relationship of subject/program/object known as a triple. It also sets as its goal the concepts of separation of duties and well-formed transactions:
Separation of duties: This concept ensures that certain operations require additional verification or that all personnel do their part.
Well-formed transaction: This concept ensures that all values are checked before and after the transaction by carrying out particular operations to complete the change of data from one state to another.
To ensure that integrity is attained and preserved, the Clark-Wilson model asserts, integrity-monitoring and integrity-preserving rules are needed. Integrity-monitoring rules are called certification rules, and integrity-preserving rules are called enforcement rules.
Lipner Model
The Lipner model is an implementation that combines elements of the Bell-LaPadula model and the Biba model. The first way of implementing integrity with the Lipner model uses Bell-LaPadula and assigns subjects to one of two sensitivity levels—system manager and anyone else—and to one of four job categories. Objects are assigned specific levels and categories. Categories become the most significant integrity (such as access control) mechanism. The second implementation uses both Bell-LaPadula and Biba. This method prevents unauthorized users from modifying data and prevents authorized users from making improper data modifications. The implementations also share characteristics with the Clark-Wilson model in that it separates objects into data and programs.
Brewer-Nash (Chinese Wall) Model
The Brewer-Nash (Chinese Wall) model introduced the concept of allowing access controls to change dynamically based on a user’s previous actions. One of its goals is to do this while protecting against conflicts of interest. This model is also based on an information flow model. Implementation involves grouping data sets into discrete classes, each class representing a different conflict of interest. Isolating data sets within a class provides the capability to keep one department’s data separate from another in an integrated database.
Graham-Denning Model
The Graham-Denning model addresses an issue ignored by the Bell-LaPadula (with the exception of the ds-property) and Biba models. It deals with the delegate and transfer rights. It focuses on issues such as
Securely creating and deleting objects and subjects
Securely providing or transferring access rights
Harrison-Ruzzo-Ullman Model
The Harrison-Ruzzo-Ullman model also deals with access rights. It restricts the set of operations that can be performed on an object to a finite set to ensure integrity. It is used by software engineers to prevent unforeseen vulnerabilities from being introduced by overly complex operations.
Goguen-Meseguer Model
Although not as well known as Biba and other integrity models, the Goguen-Meseguer model is the foundation of the noninterference model. With this model, the list of objects that a subject can access is predetermined. Subjects can then perform these predetermined actions only against the predetermined objects. Subjects are unable to interfere with each other’s activities.
Sutherland Model
The Sutherland model focuses on preventing interference in support of integrity. Based on the state machine and information flow models, this model defines a set of system states, initial states, and state transitions. Using these predetermined secure states, the Sutherland model maintains integrity and prohibits interference.
System Architecture Steps
Various models and frameworks discussed in this chapter might differ in the exact steps toward developing a system architecture but do follow a basic pattern. The main steps include
Design phase: In this phase system requirements are gathered and the manner in which the requirements will be met is mapped out using modeling techniques that usually graphically depict the components that satisfy each requirement and the interrelationships of these components. At this phase many of the frameworks and security models discussed later in this chapter are used to help meet the architectural goals.
Development phase: In this phase hardware and software components are assigned to individual teams for development. At this phase the work done in the first phase can help to ensure these independent teams are working toward components that will fit together to satisfy requirements.
Maintenance phase: In this phase the system and security architecture are evaluated to ensure that the system operates properly and that security of the systems is maintained. The system and security should be periodically reviewed and tested.
Retirement phase: In this phase the system is retired from use in the live environment. Security professionals must ensure that the organization follows proper disposal procedures and ensure that data cannot be obtained from disposed assets.
ISO/IEC 42010:2011
ISO/IEC 42010:2011 uses specific terminology when discussing architectural frameworks. The following is a review of some of the most important terms:
Architecture: The organization of the system, including its components and their interrelationships, along with the principles that guide its design and evolution
Architectural description (AD): The set of documents that convey the architecture in a formal manner
Stakeholder: Individuals, teams, and departments, including groups outside the organization with interests or concerns to consider
View: The representation of the system from the perspective of a stakeholder or a set of stakeholders
Viewpoint: A template used to develop individual views that establish the audience, techniques, and assumptions made
Computing Platforms
A computing platform is composed of the hardware and software components that allow software to run. This typically includes the physical components, the operating systems, and the programming languages used. From a physical and logical perspective, a number of possible frameworks or platforms are in use. The following sections discuss some of the most common.
Mainframe/Thin Clients
When a mainframe/thin client platform is used, a client/server architecture exists. The server holds the application and performs all the processing. The client software runs on the user machines and simply sends requests for operations and displays the results. When a true thin client is used, very little exists on the user machine other than the software that connects to the server and renders the result.
Distributed Systems
The distributed platform also uses a client/server architecture, but the division of labor between the server portion and the client portion of the solution might not be quite as one-sided as you would find in a mainframe/thin client scenario. In many cases multiple locations or systems in the network might be part of the solution. Also, sensitive data may be more likely to be located on the user’s machine, and therefore the users play a bigger role in protecting it with best practices.
Another characteristic of a distributed environment is multiple processing locations that can provide alternatives for computing in the event a site becomes unavailable.
Data is stored at multiple, geographically separate locations. Users can access the data stored at any location with the users’ distance from those resources transparent to the user.
Distributed systems can introduce security weaknesses into the network that must be considered. The following are some examples:
Desktop systems can contain sensitive information that might be at risk of being exposed.
Users might generally lack security awareness.
Modems present a vulnerability to dial-in attacks.
Lack of proper backup might exist.
Middleware
In a distributed environment, middleware is software that ties the client and server software together. It is neither a part of the operating system nor a part of the server software. It is the code that lies between the operating system and applications on each side of a distributed computing system in a network. It might be generic enough to operate between several types of client/server systems of a particular type.
Embedded Systems
An embedded system is a piece of software built into a larger piece of software that is in charge of performing some specific function on behalf of the larger system. The embedded part of the solution might address specific hardware communications and might require drivers to talk between the larger system and some specific hardware.
Mobile Computing
Mobile code is instructions passed across the network and executed on a remote system. An example of mobile code is Java and ActiveX code downloaded into a web browser from the World Wide Web. Any introduction of code from one system to another is a security concern but is required in some situations. An active content module that attempts to monopolize and exploit system resources is called a hostile applet. The main objective of the Java Security Model (JSM) is to protect the user from hostile, network mobile code. It does this by placing the code in a sandbox, which restricts its operations.
Virtual Computing
Virtual environments are increasingly being used as the computing platform for solutions. Most of the same security issues that must be mitigated in the physical environment must also be addressed in the virtual network.
In a virtual environment, instances of an operating system are called virtual machines (VMs). A host system can contain many VMs. Software called a hypervisor manages the distribution of resources (CPU, memory, and disk) to the VMs. Figure 3-3 shows the relationship between the host machine, its physical resources, the resident VMs, and the virtual resources assigned to them.
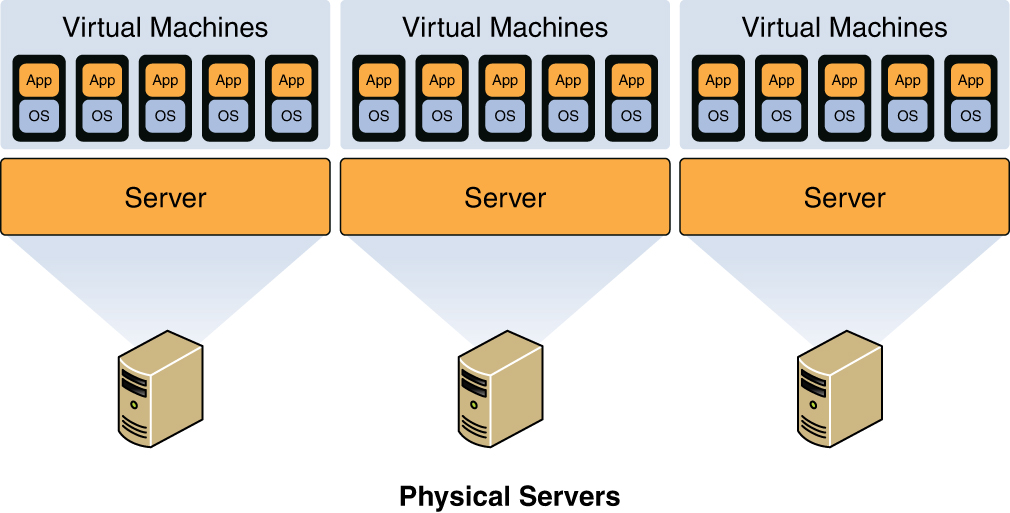
Figure 3-3 Virtualization
Security Services
The process of creating system architecture also includes design of the security that will be provided. These services can be classified into several categories depending on the protections they are designed to provide. The following sections briefly examine and compare types of security services.
Boundary Control Services
These services are responsible for placing various components in security zones and maintaining boundary control among them. Generally, this task is accomplished by indicating components and services as trusted or not trusted. As an example, memory space insulated from other running processes in a multiprocessing system is part of a protection boundary.
Access Control Services
In Chapter 5, you will learn about various methods of access control and how they can be deployed. An appropriate method should be deployed to control access to sensitive material and to give users the minimum required access they need to do their jobs.
Integrity Services
As you might recall, integrity implies that data has not been changed. When integrity services are present, they ensure that data moving through the operating system or application can be verified to not have been damaged or corrupted in the transfer.
Cryptography Services
If the system is capable of scrambling or encrypting information in transit, it is said to provide cryptography services. In some cases this service is not natively provided by a system and if desired must be provided in some other fashion, but if the capability is present, it is valuable, especially in instances where systems are distributed and talk across the network.
Auditing and Monitoring Services
If the system has a method of tracking the activities of the users and of the operations of the system processes, it is said to provide auditing and monitoring services. Although our focus here is on security, the value of this service goes beyond security because it also allows for monitoring what the system itself is actually doing.
System Components
When discussing the way security is provided in an architecture, having a basic grasp of the components in computing equipment is helpful. The following sections discuss those components and some of the functions they provide.
CPU
The central processing unit (CPU), also called the processor, is the hardware in the system that executes all the instructions in the code. The CPU is the heart of a computer or IT systems. It has its own set of instructions for its internal operation, and those instructions define its architecture. The software that runs on the system must be compatible with this architecture, which really means the CPU and the software can communicate.
When more than one processor is present and available, the system becomes capable of multiprocessing. This capability allows the computer to execute multiple instructions in parallel. It can be done with separate physical processors or with a single processor with multiple cores. When multiple cores are used, each core operates as a separate CPU.
CPUs have their own memory, and the CPU is able to access this memory faster than any other memory location. It also typically has cache memory where the most recently executed instructions are kept in case they are needed again. When a CPU gets an instruction from memory, the process is called fetching.
An arithmetic logic unit (ALU) in the CPU performs the actual execution of the instructions. The control unit acts as the system manager while instructions from applications and operating systems are executed. CPU registers contain the instruction set information and data to be executed and include general registers, special registers, and a program counter register.
CPUs can work in user mode or privileged mode, which is also referred to as kernel or supervisor mode. When applications are communicating with the CPU, it is in user mode. If an instruction that is sent to the CPU is marked to be performed in privileged mode, it must be a trusted operating system process and is given functionality not available in user mode.
The CPU is connected to an address bus. Memory and I/O devices recognize this address bus. These devices can then communicate with the CPU, read requested data, and send it to the data bus.
When microcomputers were first developed, the instruction fetch time was much longer than the instruction execution time because of the relatively slow speed of memory access. This situation led to the design of the Complex Instruction Set Computer (CISC) CPU. In this arrangement, the set of instructions was reduced (while made more complex) to help mitigate the relatively slow memory access.
After memory access was improved to the point where not much difference existed in memory access times and processor execution times, the Reduced Instruction Set Computer (RISC) architecture was introduced. The objective of the RISC architecture was to reduce the number of cycles required to execute an instruction, which was accomplished by making the instructions less complex.
Multitasking and Multiprocessing
Multitasking is the process of carrying out more than one task at a time. Multitasking can be done in two different ways. When the computer has a single processor with one core, it is not really doing multiple tasks at once. It is dividing its CPU cycles between tasks at such a high rate of speed that it appears to be doing multiple tasks at once. However, when a computer has more than one processor or has a processor with multiple cores, then it is capable of actually performing two tasks at the same time. It can do this in two different ways:
Symmetric mode: In this mode the processors or cores are handed work on a round-robin basis, thread by thread.
Asymmetric mode: In this mode a processor is dedicated to a specific process or application; when work needs done for that process, it always is done by the same processor. Figure 3-4 shows the relationship between these two modes.

Figure 3-4 Types of Multiprocessing
Preemptive multitasking means that task switches can be initiated directly out of interrupt handlers. With cooperative (nonpreemptive) multitasking, a task switch is only performed when a task calls the kernel and allows the kernel a chance to perform a task switch.
Multithreading
Multithreading allows multiple tasks to be performed within a single process. A thread is a self-contained sequence of instruction that can execute in parallel with other threads that are part of the same process. Multithreading is often used in applications to reduce overhead and increase efficiency. An example of multithreading is having multiple Microsoft Excel spreadsheets open at the same time. In this situation, the computer does not run multiple instances of Microsoft Excel. Each spreadsheet is treated as a single thread within the single Microsoft Excel process with the software managing which thread is being accessed.
Single-State Versus Multistate Systems
Single-state systems manage information at different levels using policy mechanisms approved by security administrators. These systems handle one security level at a time. Multistate systems manage multiple security levels at the same time using the protection mechanisms described in the next section. Multistate systems are uncommon because they are so expensive to implement.
Process States
Process states are the different modes in which a process may run. A process can operate in one of several states:
Ready: The process is ready to start processing when needed.
Waiting: The process is ready for execution but is waiting for access to an object.
Running: The process is being executed until the process is finished, the time expires, or the process is blocked or aborted.
Supervisory: The process is performing an action that requires higher privileges.
Stopped: The process is finished or terminated.
Memory and Storage
A computing system needs somewhere to store information, both on a long-term basis and a short-term basis. There are two types of storage locations: memory, for temporary storage needs, and long-term storage media. Information can be accessed much faster from memory than from long-term storage, which is why the most recently used instructions or information is typically kept in cache memory for a short period of time, which ensures the second and subsequent accesses will be faster than returning to long-term memory.
Computers can have both random-access memory (RAM) and read-only memory (ROM). RAM is volatile, meaning the information must continually be refreshed and will be lost if the system shuts down. Table 3-2 contains some types of RAM used in laptops and desktops.
Table 3-2 Memory Types
Desktop Memory | Description |
SDRAM—synchronous dynamic random-access memory | Synchronizes itself with the CPU’s bus. |
DDR SDRAM—double data rate synchronous dynamic random-access memory | Supports data transfers on both edges of each clock cycle (the rising and falling edges), effectively doubling the memory chip’s data throughput. |
DDR2 SDRAM—double data rate two (2) synchronous dynamic random-access memory | Transfers 64 bits of data twice every clock cycle and is not compatible with current DDR SDRAM memory slots. |
DDR3-SDRAM—double data rate three (3) synchronous dynamic random-access memory | Offers reduced power consumption, a doubled pre-fetch buffer, and more bandwidth because of its increased clock rate. Allows for DIMMs of up to 16 GB in capacity. |
DDR4-SDRAM—double data rate four (4) synchronous dynamic random-access memory | Includes higher module density and lower voltage requirements. Theoretically allows for DIMMs of up to 512 GB in capacity. |
Laptop Memory | Description |
SODIMM—small outline DIMM | Differs from desktop RAM in physical size and pin configuration. A full-size DIMM has 100, 168, 184, 240, or 288 pins and is usually 4.5 to 5 inches in length. In contrast, a SODIMM has 72, 100, 144, 200, 204, or 260 pins and is smaller—2.5 to 3 inches. |
ROM, on the other hand, is not volatile and also cannot be overwritten without executing a series of operations that depend on the type of ROM. It usually contains low-level instructions of some sort that make the device on which it is installed operational. Some examples of ROM are
Flash memory: A type of electrically programmable ROM
Programmable logic device (PLD): An integrated circuit with connections or internal logic gates that can be changed through a programming process
Field-programmable gate array (FPGA): A type of PLD that is programmed by blowing fuse connections on the chip or using an antifuse that makes a connection when a high voltage is applied to the junction
Firmware: A type of ROM where a program or low-level instructions are installed
Memory directly addressable by the CPU, which is for the storage of instructions and data that are associated with the program being executed, is called primary memory. Regardless of which type of memory in which the information is located, in most cases the CPU must get involved in fetching the information on behalf of other components. If a component has the ability to access memory directly without the help of the CPU, it is called direct memory access (DMA).
Some additional terms you should be familiar with in regard to memory include the following:
Associative memory: The type of memory that searches for a specific data value in memory rather than using a specific memory address.
Implied addressing: The type of memory addressing that refers to registers usually contained inside the CPU.
Absolute addressing: The type of memory addressing that addresses the entire primary memory space. The CPU uses the physical memory addresses that are called absolute addresses.
Cache: A relatively small amount (when compared to primary memory) of very high speed RAM that holds the instructions and data from primary memory and that has a high probability of being accessed during the currently executing portion of a program.
Indirect addressing: The type of memory addressing where the address location that is specified in the program instruction contains the address of the final desired location.
Logical address: The address at which a memory cell or storage element appears to reside from the perspective of an executing application program.
Relative address: The address that specifies its location by indicating its distance from another address.
Virtual memory: A location on the hard drive used temporarily for storage when memory space is low.
Memory leak: A failure that occurs when a computer program incorrectly manages memory allocations, which can exhaust available system memory as an application runs.
Secondary memory: Magnetic, optical, or flash-based media or other storage devices that contain data that must first be read by the operating system and stored into memory. This memory is less expensive than primary memory.
Volatile memory: Memory that is emptied when the device shuts down or when an application cleans up.
Nonvolatile memory: Long-term persistent storage that remains even when the device shuts down.
Random Versus Sequential Access
Random access devices read data immediately from any point on the drive. Sequential access devices read data as it is stored on the drive in the order in which it is stored. RAM, magnetic hard drives, and USB flash drives are random access devices, while magnetic tapes are sequential access devices.
Input/Output Devices
Input/output (I/O) devices are used to send and receive information to the system. Examples are the keyboard, mouse, displays, and printers. The operating system controls the interaction between the I/O devices and the system. In cases where the I/O device requires the CPU to perform some action, it may signal the CPU with a message called an interrupt. Not all devices require an interrupt to communicate with the CPU.
Input/Output Structures
Some computer activities are general I/O operations that require manual configuration of devices. The I/O structures used by those activities utilize memory-mapped I/O, interrupt requests (IRQs), and direct memory access (DMA).
With memory-mapped I/O, the CPU manages access to a series of mapped memory addresses or locations. Using these memory-mapped locations, the user actually obtains input from the corresponding device. The input is copied to those memory locations when the device signals that it is ready. When the user writes to the memory-mapped locations, the output to the device is copied from the memory location to the device when the CPU indicates that the output is ready. When memory-mapped I/O is used, a single device or piece of hardware should map to a specific memory address. That address should be used by no other device or hardware. The operating system manages access to mapped-memory locations.
An IRQ assigns specific signal lines to a device through an interrupt controller. IRQs are mapped to specific CPU-addressed memory locations. When a device wants to communicate, it sends a signal to the CPU through its assigned IRQ. Older devices must have exclusive use of an IRQ, while newer plug-and-play (PnP) devices can share an IRQ. Older computers had IRQs 0–15, while newer computers have IRQs 0–23. If an IRQ conflict occurs, none of the devices sharing the IRQ will be available. The operating system manages access to IRQs.
DMA access uses a channel with two signal lines, one of which is the DMA request (DMQ) line and the other of which is the DMA acknowledgment (DACK) line. This I/O structure type allows devices to work directly with memory without waiting on the CPU. The CPU simply authorizes the access and then lets the device communicate with memory directly. A DACK signal is used to release the memory location back to the CPU. DMA is much faster than the other two methods. The operating system manages DMA assignments.
Firmware
Firmware is software that is stored on an EPROM or EEPROM chip within a device. While updates to firmware may become necessary, they are infrequent. Firmware can exist as the basic input/output system (BIOS) on a computer or device firmware.
BIOS/UEFI
A computer’s BIOS contains the basic instruction that a computer needs to boot and load the operating system from a drive. The process of updating the BIOS with the latest software is referred to as flashing the BIOS. Security professionals should ensure that any BIOS updates are obtained from the BIOS vendor and have not been tampered with in any way.
The traditional BIOS has been replaced with the Unified Extensible Firmware Interface (UEFI). UEFI maintains support for legacy BIOS devices but is considered a more advanced interface than traditional BIOS. BIOS uses the master boot record (MBR) to save information about the hard drive data, while UEFI uses the GUID partition table (GPT). BIOS partitions were a maximum of 4 partitions, each being only 2 terabytes (TB). UEFI allows up to 128 partitions, with the total disk limit being 9.4 zettabytes (ZB) or 9.4 billion terabytes. UEFI is also faster and more secure than traditional BIOS. UEFI Secure Boot requires boot loaders to have a digital signature.
UEFI is an open standard interface layer between the firmware and the operating system that requires firmware updates to be digitally signed. Security professionals should understand the following points regarding UEFI:
It was designed as a replacement for traditional PC BIOS.
Additional functionality includes support for Secure Boot, network authentication, and universal graphics drivers.
It protects against BIOS malware attacks including rootkits.
Secure Boot requires that all boot loader components (e.g., OS kernel, drivers) attest to their identity (digital signature) and the attestation is compared to the trusted list.
When a computer is manufactured, a list of keys that identify trusted hardware, firmware, and operating system loader code (and in some instances, known malware) is embedded in the UEFI.
It ensures the integrity and security of the firmware.
It prevents malicious files from being loaded.
Can be disabled for backward compatibility.
Device Firmware
Hardware devices, such as routers and printers, require some processing power to complete their tasks. This firmware is contained in the firmware chips located within the devices. Like with computers, this firmware is often installed on EEPROM to allow it to be updated. Again, security professionals should ensure that updates are obtained only from the device vendor and that the updates have not been changed in any manner, including modified by a third party.
Operating Systems
The operating system is the software that enables a human to interact with the hardware that comprises the computer. Without the operating system, the computer would be useless. Operating systems perform a number of noteworthy and interesting functions as part of the interfacing between the human and the hardware. In this section, we look at some of these activities.
A thread is an individual unit of an application for a specific process. A process is a set of threads that are part of the same larger application. An application’s instructions are not considered processes until they have been loaded into memory where all instructions must first be copied to be processed by the CPU. A process can be in a running state, ready state, or blocked state. When a process is blocked, it is simply waiting for data to be transmitted to it, usually through user data entry. A group of processes that share access to the same resources is called a protection domain.
CPUs can be categorized according to the way in which they handle processes. A superscalar computer architecture is characterized by a processor that enables concurrent execution of multiple instructions in the same pipeline stage. A processor in which a single instruction specifies more than one concurrent operation is called a Very Long Instruction Word (VLIW) processor. A pipelined processor overlaps the steps of different instructions, whereas a scalar processor executes one instruction at a time, consequently increasing pipelining.
From a security perspective, processes are placed in a ring structure according to the concept of least privilege, meaning they are only allowed to access resources and components required to perform the task. A common visualization of this structure is shown in Figure 3-5.
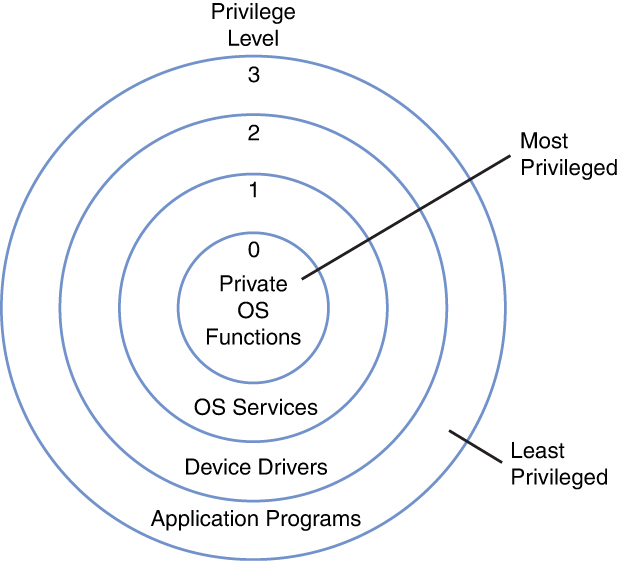
Figure 3-5 Ring Structure
When a computer system processes I/O instructions, it is operating in supervisor mode. The termination of selected, noncritical processing when a hardware or software failure occurs and is detected is referred to as a fail soft state. It is in a fail safe state if the system automatically leaves system processes and components in a secure state when a failure occurs or is detected in the system.
Memory Management
Because all information goes to memory before it can be processed, secure management of memory is critical. Memory space insulated from other running processes in a multiprocessing system is part of a protection domain.
System Security Evaluation Models
In an attempt to bring order to the unexpected security threats that happen, several evaluation models have been created to assess and rate the security of these products. An assurance level examination attempts to examine the security-related components of a system and assign a level of confidence that the system can provide a particular level of security. In the following sections, we discuss organizations that have created such evaluation systems.
TCSEC
The Trusted Computer System Evaluation Criteria (TCSEC) was developed by the National Computer Security Center (NCSC) for the U.S. DoD to evaluate products. NCSC has issued a series of books focusing on both computer systems and the networks in which they operate. They address confidentiality, but not integrity. In 2005, TCSEC was replaced by the Common Criteria, discussed later in the chapter. However, security professionals still need to understand TCSEC because of its effect on security practices today and because some of its terminology is still in use.
With TCSEC, functionality and assurance are evaluated separately and form a basis for assessing the effectiveness of security controls built into automatic data-processing system products. For example, the concept of least privilege is derived from TCSEC. In the following sections, we discuss those books and the ratings they derive.
Rainbow Series
The original publication created by the TCSEC was the Orange Book, but as time went by, other books were also created that focused on additional aspects of the security of computer systems. Collectively, this set of more than 20 books is now referred to as the Rainbow Series, alluding to the fact that each book is a different color. For example, the Green Book focuses solely on password management. Next, we cover the most important books: the Red Book, Orange Book, and Green Book.
Red Book
The Trusted Network Interpretation (TNI) extends the evaluation classes of the TCSEC (DOD 5200.28-STD) to trusted network systems and components in the Red Book. So where the Orange Book focuses on security for a single system, the Red Book addresses network security.
Orange Book
The Orange Book is a collection of criteria based on the Bell-LaPadula model that is used to grade or rate the security offered by a computer system product. Covert channel analysis, trusted facility management, and trusted recoveries are concepts discussed in this book.
The goals of this system can be divided into two categories, operational assurance requirements and life cycle assurance requirements, the details of which are defined next.
The operational assurance requirements specified in the Orange Book are as follows:
System architecture
System integrity
Covert channel analysis
Trusted facility management
Trusted recovery
The life cycle assurance requirements specified in the Orange Book are as follows:
Security testing
Design specification and testing
Configuration management
Trusted distribution
TCSEC uses a classification system that assigns an alphabetic letter and a number to describe systems’ security effectiveness. The assigned letter refers to a security assurance level or division as A, B, C, D, and the number refers to gradients within that security assurance level or class. Each division and class incorporates all the required elements of the ones below it.
In order of least secure to most secure, the four classes and their constituent divisions and requirements are as follows:
D—Minimal Protection
Reserved for systems that have been evaluated but that fail to meet the requirements for a higher division.
C—Discretionary Protection
C1—Discretionary Security Protection
– Requires identification and authentication.
– Requires separation of users and data.
– Uses discretionary access control (DAC) capable of enforcing access limitations on an individual or group basis.
– Requires system documentation and user manuals.
C2—Controlled Access Protection
– Uses a more finely grained DAC.
– Provides individual accountability through login procedures.
– Requires protected audit trails.
– Invokes object reuse theory.
– Requires resource isolation.
B—Mandatory Protection
B1—Labeled Security Protection
– Uses an informal statement of the security policy.
– Requires data sensitivity or classification labels.
– Uses MAC over selected subjects and objects.
– Capable of label exportation.
– Requires removal or mitigation of discovered flaws.
– Uses design specifications and verification.
B2—Structured Protection
– Requires a clearly defined and formally documented security policy.
– Uses DAC and MAC enforcement extended to all subjects and objects.
– Analyzes and prevents covert storage channels for occurrence and bandwidth.
– Structures elements into protection-critical and non-protection-critical categories.
– Enables more comprehensive testing and review through design and implementation.
– Strengthens authentication mechanisms.
– Provides trusted facility management with administrator and operator segregation.
– Imposes strict configuration management controls.
B3—Security Domains
– Satisfies reference monitor requirements.
– Excludes code not essential to security policy enforcement.
– Minimizes complexity through significant systems engineering.
– Defines the security administrator role.
– Requires an audit of security-relevant events.
– Automatically detects and responds to imminent intrusion detection, including personnel notification.
– Requires trusted system recovery procedures.
– Analyzes and prevents covert timing channels for occurrence and bandwidth.
– An example of such a system is the XTS-300, a precursor to the XTS-400.
A—Verified Protection
A1—Verified Design
– Provides higher assurance than B3, but is functionally identical to B3.
– Uses formal design and verification techniques, including a formal top-level specification.
– Requires that formal techniques are used to prove the equivalence between the Trusted Computer Base (TCB) specifications and the security policy model.
– Provides formal management and distribution procedures.
– An example of such a system is Honeywell’s Secure Communications Processor (SCOMP), a precursor to the XTS-400.
Green Book
The Green Book provides guidance on password creation and management. It includes single sign-on (SSO) responsibilities, user responsibilities, authentication mechanisms, and password protection. The following major features are advocated in this guideline:
Users should be able to change their own passwords.
Passwords should be machine-generated rather than user-created.
Certain audit reports (e.g., date and time of last login) should be provided by the system directly to the user.
ITSEC
TCSEC addresses confidentiality only and bundles functionality and assurance. In contrast to TCSEC, the Information Technology Security Evaluation Criteria (ITSEC) addresses integrity and availability as well as confidentiality. Another difference is that the ITSEC was mainly a set of guidelines used in Europe, whereas the TCSEC was relied on more in the United States.
ITSEC has a rating system in many ways similar to that of TCSEC. ITSEC has 10 classes, F1 to F10, to evaluate the functional requirements and 7 TCSEC classes, E0 to E6, to evaluate the assurance requirements.
Security functional requirements include the following:
F00: Identification and authentication
F01: Audit
F02: Resource utilization
F03: Trusted paths/channels
F04: User data protection
F05: Security management
F06: Product access
F07: Communications
F08: Privacy
F09: Protection of the product’s security functions
F10: Cryptographic support
Security assurance requirements include the following:
E00: Guidance documents and manuals
E01: Configuration management
E02: Vulnerability assessment
E03: Delivery and operation
E04: Life cycle support
E05: Assurance maintenance
E06: Development
E07: Testing
The TCSEC and ITSEC systems can be mapped to one another, but the ITSEC provides a number of ratings that have no corresponding concept in the TCSEC ratings. Table 3-3 shows a mapping of the two systems.
Table 3-3 Mapping of ITSEC and TCSEC
ITSEC | TCSEC |
E0 | D |
F1+E1 | C1 |
F2+E2 | C2 |
F3+E3 | B1 |
F4+E4 | B2 |
F5+E5 | B3 |
F6+E6 | A1 |
F6 | Systems that provide high integrity |
F7 | Systems that provide high availability |
F8 | Systems that provide high data integrity during communication |
F9 | Systems that provide high confidentiality (using cryptography) |
F10 | Networks with high demands on confidentiality and integrity |
The ITSEC has been largely replaced by Common Criteria, discussed in the next section.
Common Criteria
In 1990 the ISO identified the need for a standardized rating system that could be used globally. The Common Criteria (CC) for Information Technology Security Evaluation was the result of a cooperative effort to establish this system. This system uses Evaluation Assurance Levels (EALs) to rate systems, with each EAL representing a successively higher level of security testing and design in a system. The resulting rating represents the potential the system has to provide security. It assumes that the customer will properly configure all available security solutions, so it is required that the vendor always provide proper documentation to allow the customer to fully achieve the rating. ISO/IEC 15408-1:2009 is the ISO version of the CC.
The CC represents requirements for IT security of a product or system in two categories: functionality and assurance. This means that the rating should describe what the system does (functionality), and the degree of certainty the raters have that the functionality can be provided (assurance).
The CC has seven assurance levels, which range from EAL1 (lowest), where functionality testing takes place, through EAL7 (highest), where thorough testing is performed and the system design is verified.
The assurance designators used in the CC are as follows:
EAL1: Functionally tested
EAL2: Structurally tested
EAL3: Methodically tested and checked
EAL4: Methodically designed, tested, and reviewed
EAL5: Semi-formally designed and tested
EAL6: Semi-formally verified design and tested
EAL7: Formally verified design and tested
The CC uses a concept called a protection profile during the evaluation process. The protection profile describes a set of security requirements or goals along with functional assumptions about the environment. Therefore, if someone identified a security need not currently addressed by any products, that person could write a protection profile that describes the need and the solution and all issues that could go wrong during the development of the system. This would be used to guide the development of a new product. A protection profile contains the following elements:
Descriptive elements: The name of the profile and a description of the security problem that is to be solved.
Rationale: Justification of the profile and a more detailed description of the real-world problem to be solved. The environment, usage assumptions, and threats are given along with security policy guidance that can be supported by products and systems that conform to this profile.
Functional requirements: Establishment of a protection boundary, meaning the threats or compromises that are within this boundary to be countered. The product or system must enforce the boundary.
Development assurance requirements: Identification of the specific requirements that the product or system must meet during the development phases, from design to implementation.
Evaluation assurance requirements: Establishment of the type and intensity of the evaluation.
The result of following this process will be a security target. This is the vendor’s explanation of what the product brings to the table from a security standpoint. Intermediate groupings of security requirements developed along the way to a security target are called packages.
While it is important to understand the EAL levels of the CC, the CC has been redesigned. Common Criteria Version 3.1, Revision 5, uses the term Target of Evaluation (TOE). A TOE is defined as a set of software, firmware, and/or hardware possibly accompanied by guidance. The TOE consists of a specific version and a specific representation of the TOE. For example, the Windows 10 Enterprise OS is a specific version, and its configuration on a computer based on the organization’s security policies is the specific representation.
The CC includes two types of evaluations: Security Target (ST)/TOE evaluation and Protection Profile (PP) evaluation. In an ST evaluation, the sufficiency of the TOE and the operational environment are determined. In a TOE evaluation, the correctness of the TOE is determined. The PP evaluation is a document, typically created by a user or user community, which identifies security requirements for a class of security devices relevant to that user for a particular purpose.
The Common Criteria has categorized PPs into 14 categories:
Access control devices and systems
Biometric systems and devices
Boundary protection devices and systems
Data protection
Databases
ICs, smart cards, and smart card–related devices and systems
Key management systems
Mobility
Multifunction devices
Network and network-related devices and systems
Operating systems
Other devices and systems
Products for digital signatures
Trusted computing
Protection profiles are assigned an EAL after analysis by a member organization in the Common Criteria Recognition Arrangement (CCRA). For more information on the latest Common Criteria implementation, go to www.commoncriteriaportal.org/. Click the Protection Profiles tab to see the available PPs.
Security Implementation Standards
It is important for a security professional to understand security implementation standards that have been published by international bodies. In addition, security professionals should examine standards in the industry that apply to their organizations and align the practices in their organization to these implementation standards. These standards include ISO/IEC 27001 and 27002 and PCI DSS.
ISO/IEC 27001
ISO/IEC 27001:2018 is the latest version of the 27001 standard and is one of the most popular standards by which organizations obtain certification for information security. It provides guidance on how to ensure that an organization’s information security management system (ISMS) is properly built, administered, and maintained. It includes the following components:
ISMS scope
Information security policy
Risk assessment process and its results
Risk treatment process and its decisions
Information security objectives
Information security personnel competence
ISMS-related documents that are necessary
Operational planning and control documents
Information security monitoring and measurement evidence
ISMS internal audit program and its results
Top management ISMS review evidence
Identified nonconformities evidence and corrective actions
When an organization decides to obtain ISO/IEC 27001 certification, a project manager should be selected to ensure that all the components are properly completed.
To implement ISO/IEC 27001:2018, the selected project manager should complete the following steps:
Obtain management support.
Determine whether to use consultants or to complete the implementation in-house, and if the latter, purchase the 27001 standard, write the project plan, define the stakeholders, and organize the project kickoff.
Identify the requirements.
Define the ISMS scope, information security policy, and information security objectives.
Develop document control, internal audit, and corrective action procedures.
Perform risk assessment and risk treatment.
Develop a statement of applicability and risk treatment plan and accept all residual risks.
Implement controls defined in the risk treatment plan and maintain implementation records.
Develop and implement security training and awareness programs.
Implement the ISMS, maintain policies and procedures, and perform corrective actions.
Maintain and monitor the ISMS.
Perform an internal audit and write an audit report.
Perform management review and maintain management review records.
Select a certification body and complete certification.
Maintain records for surveillance visits.
ISO/IEC 27002
ISO/IEC 27002:2013 is the latest version of the 27002 standard and provides a code of practice for information security management.
It includes the following 14 content areas:
Information security policy
Organization of information security
Human resources security
Asset management
Access control
Cryptography
Physical and environmental security
Operations security
Communications security
Information systems acquisition, development, and maintenance
Supplier relationships
Information security incident management
Information security aspects of business continuity
Compliance
Payment Card Industry Data Security Standard (PCI DSS)
Payment Card Industry Data Security Standard (PCI DSS) Version 3.2 is for merchants and other entities involved in payment card processing. Compliance with the PCI DSS helps to alleviate vulnerabilities and protect cardholder data. There are three ongoing steps for adhering to PCI DSS:
Assess: Identify all locations of cardholder data, take an inventory of your IT assets and business processes for payment card processing, and analyze them for vulnerabilities that could expose cardholder data.
Repair: Fix identified vulnerabilities, securely remove any unnecessary cardholder data storage, and implement secure business processes.
Report: Document assessment and remediation details, and submit compliance reports to the acquiring bank and card brands or other requesting entity.
PCI DSS applies to all entities that store, process, and/or transmit cardholder data. It covers technical and operational system components included in or connected to cardholder data. If an organization accepts or processes payment cards, then PCI DSS applies to that organization. If there is a breach or possibility of breach (even without harming cardholders in anyway) for an entity that follows PCI-DSS, the entity should immediately be reported to customers.
For more information on PCI-DSS, you can download the PCI-DSS Quick Reference Guide at https://www.pcisecuritystandards.org/documents/PCI_DSS-QRG-v3_2_1.pdf.
Controls and Countermeasures
After an organization implements a system security evaluation model and security implementation standard, the organization must ensure that the appropriate controls and countermeasures are implemented, based on the most recent vulnerability and risk assessments performed by security professionals. Understanding the different categories and types of access controls is vital to ensure that an organization implements a comprehensive security program. Information security should always be something that the organization assesses and pursues.
Certification and Accreditation
Although the terms are used as synonyms in casual conversation, accreditation and certification are two different concepts in the context of assurance levels and ratings, although they are closely related. Certification evaluates the security features of system components, whereas accreditation occurs when the adequacy of a system’s overall security is assessed by an approval authority as to the system’s purpose.
The National Information Assurance Certification and Accreditation Process (NIACAP) provides a standard set of activities, general tasks, and a management structure to certify and accredit systems that will maintain the information assurance and security posture of a system or site.
The accreditation process developed by NIACAP has four phases:
Phase 1: Definition
Phase 2: Verification
Phase 3: Validation
Phase 4: Post Accreditation
NIACAP defines the following three types of accreditation:
Type accreditation evaluates an application or system that is distributed to a number of different locations.
System accreditation evaluates an application or support system.
Site accreditation evaluates the application or system at a specific self-contained location.
Control Selection Based on Systems Security Requirements
Although controls should be selected based on systems security evaluation models, they also need to be selected based on the systems security requirements. Security controls include the management, operational, and technical countermeasures used within an organizational information system to protect the CIA of the system and its information.
Selecting and implementing the appropriate security controls for an information system are important tasks that can have major implications on the operations and assets of an organization. According to the NIST Risk Management Framework, organizations are required to adequately mitigate risk arising from use of information and information systems in the execution of missions and business functions. A significant challenge for organizations is to determine the appropriate set of security controls that, if implemented and determined to be effective, would most cost-effectively mitigate risk while complying with the security requirements defined by applicable federal laws, directives, policies, standards, or regulations.
The security control selection process includes, as appropriate:
Choosing a set of baseline security controls
Tailoring the baseline security controls by applying scoping, parameterization, and compensating control guidance
Supplementing the tailored baseline security controls, if necessary, with additional controls or control enhancements to address unique organizational needs based on a risk assessment and local conditions, including environment of operation, organization-specific security requirements, specific threat information, cost-benefit analysis, or special circumstances
Specifying minimum assurance requirements
The information system owner and information security architect are responsible for selecting the security controls for the information system and documenting the controls in the security plan.
Security Capabilities of Information Systems
Organizations must understand the security capabilities of any information systems that they implement. The following sections discuss memory protection, Trusted Platform Module, interfaces, and fault tolerance.
Memory Protection
In an information system, memory and storage are the most important resources. Damaged or corrupt data in memory can cause the system to stop functioning. Data in memory can be disclosed and therefore must be protected. Memory does not isolate running processes and threads from data. Security professionals must use processor states, layering, process isolation, abstraction, hardware segmentation, and data hiding to help keep data isolated.
Most processors support two processor states: supervisor state (or kernel mode) and problem state (or user mode). In supervisor state, the highest privilege level on the system is used so that the processor can access all the system hardware and data. In problem state, the processor limits access to system hardware and data. Processes running in supervisor state are isolated from the processes that are not running in that state; supervisor-state processes should be limited to only core operating system functions.
A security professional can use layering to organize programming into separate functions that interact in a hierarchical manner. In most cases, each layer has access only to the layers directly above and below it. Ring protection is the most common implementation of layering, with the inner ring (ring 0) being the most privileged ring and the outer ring (ring 3) being the lowest privileged. The OS kernel usually runs on ring 0, and user applications usually run on ring 3.
A security professional can isolate processes by providing memory address spaces for each process. Other processes are unable to access address spaces allotted to another process. Naming distinctions and virtual mapping are used as part of process isolation.
Hardware segmentation works like process isolation. It prevents access to information that belongs to a higher security level. However, hardware segmentation enforces the policies using physical hardware controls rather than the operating system’s logical process isolation. Hardware segmentation is rare and is usually restructured to governmental use, although some organizations may choose to use this method to protect private or confidential data.
Data hiding prevents data at one security level from being seen by processes operating at other security levels.
Trusted Platform Module
Trusted Platform Module (TPM) is a security chip installed on computer motherboards that is responsible for managing symmetric and asymmetric keys, hashes, and digital certificates. This chip provides service to protect passwords, encrypt drives, and manage digital rights, making it much harder for attackers to gain access to the computers that have a TPM-chip enabled.
Two particularly popular uses of TPM are binding and sealing. Binding actually “binds” the hard drive through encryption to a particular computer. Because the decryption key is stored in the TPM chip, the hard drive’s contents are available only when connected to the original computer. But keep in mind that all the contents are at risk if the TPM chip fails and a backup of the key does not exist.
Sealing, on the other hand, “seals” the system state to a particular hardware and software configuration. This technology prevents attacks from making any changes to the system. However, it can also make installing a new piece of hardware or a new operating system much harder. The system can only boot after the TPM verifies system integrity by comparing the original computed hash value of the system’s configuration to the hash value of its configuration at boot time.
The TPM consists of both static memory and dynamic memory that is used to retain the important information when the computer is turned off.
The memory used in a TPM chip is as follows:
Endorsement Key (EK): Persistent memory installed by the manufacturer that contains a public/private key pair
Storage Root Key (SRK): Persistent memory that secures the keys stored in the TPM
Attestation Identity Key (AIK): Dynamic memory that ensures the integrity of the EK
Platform Configuration Register (PCR) hashes: Dynamic memory that stores data hashes for the sealing function
Storage keys: Dynamic memory that contains the keys used to encrypt the computer’s storage, including hard drives, USB flash drives, and so on
Interfaces
An interface is a mechanism that a user employs to access a system, an application, a device, or another entity. Most users assume that the interfaces they use are secure. Organizations are responsible for ensuring that secure interfaces are implemented across the network. If an entity has multiple user interfaces—such as a graphical user interface, a command-line interface, and a remote access interface—all these interfaces should require secure authentication. It is a security professional’s job to understand the difference between secure and insecure interfaces and to ensure that insecure interfaces are replaced with secure interfaces.
Fault Tolerance
Fault tolerance allows a system to continue operating properly in the event that components within the system fail. For example, providing fault tolerance for a hard drive system involves using fault-tolerant drives and fault-tolerant drive adapters. However, the cost of any fault tolerance must be weighed against the cost of the redundant device or hardware. If security capabilities of information systems are not fault tolerant, attackers may be able to access systems if the security mechanisms fail. Organizations should weigh the cost of deploying a fault-tolerant system against the cost of any attack against the system being secured. It may not be vital to provide a fault-tolerant security mechanism to protect data that is classified as public, but it is very important to provide a fault-tolerant security mechanism to protect confidential data.
Policy Mechanisms
Organizations can implement different policy mechanisms to increase the security of information systems. The policy mechanisms include separation of privilege and accountability.
Separation of Privilege
The principle of separation of privilege is tied to the principle of least privilege. Separation of privilege requires that security professionals implement different permissions for each type of privileged operation. This principle ensures that the principle of least privilege is applied to administrative-level users. Very few administrative-level users need full administrative-level access to all systems. Separation of privilege ensures that administrative-level access is only granted to users for only those resources or privileges that the user needs to perform.
For example, credit card service representatives on the phone cannot grant additional credit. However, they can view the credit limit or take your financial details and send a credit limit request application to their managers for processing.
Accountability
Accountability ensures that users are held accountable for the actions that they take. However, accountability relies heavily on the system’s ability to monitor activity. Accountability is usually provided using auditing functions. When auditing is enabled, it is also important to ensure that the auditing logs are preserved and cannot be edited. Finally, keep in mind that accounting also relies heavily on the authorization and authentication systems. Organizations cannot track user activities if the users are not individually authenticated and authorized.
Encryption/Decryption
Information systems use encryption and decryption to provide confidentiality of data. Encryption is the process of translating plain text data (plaintext) into unreadable data (ciphertext), and decryption is the process of translating ciphertext back into plaintext. Encryption and decryption are covered later in this chapter in the “Cryptography” section.
Security Architecture Maintenance
Unfortunately, after a product has been evaluated, certified, and accredited, the story is not over. The product typically evolves over time as updates and patches are developed to either address new security issues that arise or to add functionality or fix bugs that surface occasionally. When these changes occur, as ongoing maintenance, the security architecture must be maintained.
Ideally, solutions should undergo additional evaluations, certification, and accreditation as these changes occur, but in many cases the pressures of the real world prevent this time-consuming step. This situation is unfortunate because as developers fix and patch things, they often drift further and further from the original security design as they attempt to put out time-sensitive fires. In addition, developers may assume the fixes conform to the security guidelines or standards and may not verify. Unless disgruntled, a coder will not purposefully drift from security guidelines or standards, new or old.
Maturity modeling becomes important at this point. Most maturity models are based on the Software Engineer Institute’s CMMI, which is discussed in Chapter 1. It has five levels: Initial, Managed, Defined, Quantitatively Managed, and Optimizing.
The U.S. Department of Defense (DoD) Software Engineering Institute’s (SEI’s) Capability Maturity Model (CMM) ranks organizations against industry best practices and international guidelines. It includes six rating levels, numbered from zero to five: nonexistent, initial, repeatable, defined, managed, and optimized. The nonexistent level does not correspond to any CMMI level, but all the other levels do.
Vulnerabilities of Security Architectures, Designs, and Solution Elements
Organizations must assess and mitigate the vulnerabilities of security architectures, designs, and solution elements. Insecure systems are exposed to many common vulnerabilities and threats. The following sections discuss the vulnerabilities of client-based systems, server-based systems, database systems, cryptographic systems, industrial control systems, cloud-based systems, large-scale parallel data systems, distributed systems, and the Internet of Things.
Client-Based Systems
In most networks, client systems are the most widely used because they are the systems that users most rely on to access resources. Client systems range from desktop systems to laptops to mobile devices of all types. This section focuses mainly on the vulnerabilities of desktops and laptops.
Because client systems are so prolific, new attacks against these systems seem to crop up every day. Security practitioners must ensure that they know which client systems attach to the network so they can ensure that the appropriate controls are implemented to protect them.
Traditional client-side threats usually target web browsers, browser plug-ins, and email clients. But threats also exploit the applications and operating systems that are deployed. Client systems also tend to have exposed services deployed that are not needed. Often client systems are exposed to hostile servers. Added to these issues is the fact that most normal users are not security savvy and often inadvertently cause security issues on client systems.
Security architecture for client systems should include policies and controls that cover the following areas:
Deploying only licensed, supported operating systems. These operating systems should be regularly updated with all vendor patches, security updates, and service packs as they are released.
Deploying anti-malware and antivirus software on every client system. Updates to this software should also be configured as automatic to ensure that the most recently detected vulnerabilities are covered.
Deploying a firewall with a well-configured access control list (ACL) and host-based intrusion detection system on the client systems.
Using drive encryption such as BitLocker to protect the data on the hard drives.
Issuing user accounts with the minimum permissions the users require to do their jobs. Users who need administrative access should have both an administrative account and a regular account and should use the administrative account only when performing administrative duties.
Testing all updates and patches, including those to both the operating systems and applications, prior to deployment at the client level.
An applet is a small application that performs a specific task. It runs within a dedicated widget engine or a larger program, often as a plug-in. Java applets and ActiveX applets are examples. Malicious applets are often deployed by attackers and appear to come from legitimate sources. These applets can then be used to compromise a client system. A security professional should ensure that clients download applets only from valid vendors. In addition, a security professional should ensure that any application that includes applets is kept up to date with the latest patches.
A client system contains several types of local caches. The DNS cache holds the results of DNS queries on the Internet and is the cache that is most often attacked. Attackers may attempt to poison the DNS cache with false IP addresses for valid domains. They do this by sending a malicious DNS reply to an affected system. As with many other issues, you should ensure that the operating system and all applications are kept up to date. In addition, users should be trained to never click unverified or unknown links in email or on websites. They are not always pointing to the site shown in the visible link. The link may show a valid website, while the underlaying link may point to a malicious site.
Server-Based Systems
In some cases an attack can focus on the operations of the server operating system itself rather than the web applications running on top of it. Later, we look at the way in which these attacks are implemented, focusing mainly on the issue of data flow manipulation.
Data Flow Control
Software attacks often subvert the intended data flow of a vulnerable program. For example, attackers exploit buffer overflows and format string vulnerabilities to write data to unintended locations. The ultimate aim is either to read data from prohibited locations or write data to memory locations for the purpose of executing malicious commands, crashing the system, or making malicious changes to the system. The proper mitigation for these types of attacks is proper input validation and data flow controls that are built into the system.
With respect to databases in particular, a data flow architecture is one that delivers the instruction tokens to the execution units and returns the data tokens to the content-addressable memory (CAM). (CAM is hardware memory, not the same as RAM.) In contrast to the conventional architecture, data tokens are not permanently stored in memory; rather, they are transient messages that exist only when in transit to the instruction storage. This makes them less likely to be compromised.
Database Systems
In many ways, a database is the Holy Grail for the attacker. It is typically where sensitive information resides. When considering database security, you need to understand the following terms: inference, aggregation, contamination, and data mining warehouse.
Inference
Inference occurs when someone has access to information at one level that allows them to infer information about another level. The main mitigation technique for inference is polyinstantiation, which is the development of a detailed version of an object from another object using different values in the new object. It prevents low-level database users from inferring the existence of higher level data.
Aggregation
Aggregation is defined as assembling or compiling units of information at one sensitivity level and having the resultant totality of data being of a higher sensitivity level than the individual components. So you might think of aggregation as a different way of achieving the same goal as inference, which is to learn information about data on a level to which you do not have access.
Contamination
Contamination is the intermingling or mixing of data of one sensitivity or need-to-know level with that of another. Proper implementation of security levels is the best defense against these problems.
Data Mining Warehouse
A data warehouse is a repository of information from heterogeneous databases. It allows for multiple sources of data to not only be stored in one place but to be organized in such a way that redundancy of data is reduced (called data normalizing), and more sophisticated data mining tools are used to manipulate the data to discover relationships that may not have been apparent before. Along with the benefits they provide, they also offer more security challenges.
The following control steps should be performed in data warehousing applications:
Monitor summary tables for regular use.
Monitor the data purging plan.
Reconcile data moved between the operations environment and data warehouse.
Cryptographic Systems
By design, cryptographic systems are responsible for encrypting data to prevent data disclosure. Security professionals must ensure that their organization’s software and IT systems are using the latest version of a cryptographic algorithm, if possible. Once a compromise of a cryptographic algorithm is known, that algorithm should no longer be used.
Industrial Control Systems
Industrial control systems (ICSs) is a general term that encompasses several types of control systems used in industrial production. The most widespread is supervisory control and data acquisition (SCADA). SCADA is a system operating with coded signals over communication channels so as to provide control of remote equipment.
ICS includes the following components:
Sensors: Sensors typically have digital or analog I/O and are not in a form that can be easily communicated over long distances.
Remote terminal units (RTUs): RTUs connect to the sensors and convert sensor data to digital data, including telemetry hardware.
Programmable logic controllers (PLCs): PLCs connect to the sensors and convert sensor data to digital data; they do not include telemetry hardware.
Telemetry system: Such a system connects RTUs and PLCs to control centers and the enterprise and are generally used over short distances.
Human interface: Such an interface presents data to the operator.
ICSs should be securely segregated from other networks as a security layer. The Stuxnet virus hit the SCADA used for the control and monitoring of industrial processes. SCADA components are considered privileged targets for cyberattacks. Through the use of cybertools, it is possible to destroy an industrial process. This was the idea used on the attack on the nuclear plant in Natanz in order to interfere with the Iranian nuclear program.
Considering the criticality of the systems, physical access to SCADA-based systems must be strictly controlled. Systems that integrate IT security with physical access controls like badging systems and video surveillance should be deployed. In addition, the solution should be integrated with existing information security tools such as log management and IPS/IDS. A helpful publication by NIST, SP 800-82, provides recommendations on ICS security. Issues with these emerging systems include
Required changes to the system may void the warranty.
Products may be rushed to market, with security an afterthought.
The return on investment may take decades.
There is insufficient regulation regarding these systems.
NIST SP 800-82, Rev. 2 provides a guide to ICS security.
According to this publication, the major security objectives for an ICS implementation should include the following:
Restricting logical access to the ICS network and network activity
Restricting physical access to the ICS network and devices
Protecting individual ICS components from exploitation
Restricting unauthorized modification of data
Detecting security events and incidents
Maintaining functionality during adverse conditions
Restoring the system after an incident
In a typical ICS, this means a defense-in-depth strategy that includes the following:
Develop security policies, procedures, training, and educational material that applies specifically to the ICS.
Address security throughout the life cycle of the ICS.
Implement a network topology for the ICS that has multiple layers, with the most critical communications occurring in the most secure and reliable layer.
Provide logical separation between the corporate and ICS networks.
Employ a DMZ network architecture.
Ensure that critical components are redundant and are on redundant networks.
Design critical systems for graceful degradation (fault tolerant) to prevent catastrophic cascading events.
Disable unused ports and services on ICS devices after testing to assure this will not impact ICS operation.
Restrict physical access to the ICS network and devices.
Restrict ICS user privileges to only those that are required to perform each person’s job.
Use separate authentication mechanisms and credentials for users of the ICS network and the corporate network.
Use modern technology, such as smart cards, for Personal Identity Verification (PIV).
Implement security controls such as intrusion detection software, antivirus software, and file integrity checking software, where technically feasible, to prevent, deter, detect, and mitigate the introduction, exposure, and propagation of malicious software to, within, and from the ICS.
Apply security techniques such as encryption and/or cryptographic hashes to ICS data storage and communications where determined appropriate.
Expeditiously deploy security patches after testing all patches under field conditions on a test system if possible, before installation on the ICS.
Track and monitor audit trails on critical areas of the ICS.
Employ reliable and secure network protocols and services where feasible.
When designing security solutions for ICS devices, security professionals should include the following considerations: timeliness and performance requirements, availability requirements, risk management requirements, physical effects, system operation, resource constraints, communications, change management, managed support, component lifetime, and component location.
ICS implementations use a variety of protocols and services, including
Modbus: A master/slave protocol that uses port 50
BACnet2: A master/slave protocol that uses port 47808
LonWorks/LonTalk3: A peer-to-peer protocol that uses port 1679
DNP3: A master/slave protocol that uses port 19999 when using Transport Layer Security (TLS) and port 20000 when not using TLS
They can also use IEEE 802.1X, Zigbee, and Bluetooth for communication.
The basic process for developing an ICS security program includes the following:
Develop a business case for security.
Build and train a cross-functional team.
Define charter and scope.
Define specific ICS policies and procedures.
Implement an ICS Security Risk Management Framework.
Define and inventory ICS assets.
Develop a security plan for ICS systems.
Perform a risk assessment.
Define the mitigation controls.
Provide training and raise security awareness for ICS staff.
The ICS security architecture should include network segregation and segmentation, boundary protection, firewalls, a logically separated control network, and dual network interface cards (NICs) and should focus mainly on suitable isolation between control networks and corporate networks.
Security professionals should also understand that many ISC/SCADA systems use weak authentication and outdated operating systems. The inability to patch these systems (and even the lack of available patches) means that the vendor is usually not proactively addressing any identified or newly found security issues. Finally, many of these systems allow unauthorized remote access, thereby making it easy for an attacker to breach the system with little effort.
Cloud-Based Systems
Cloud computing is the centralization of data, software, or the computing environment itself in a web environment that can be accessed from anywhere and anytime. An organization can create a cloud environment, or it can pay a vendor to provide this service. A private cloud is considered more secure than a public cloud. Using a public cloud introduces all sorts of security concerns. How do you know your data is kept separate from other customers? How do you know your data is safe? Outsourcing the security of their data makes many organizations uncomfortable.
Cloud computing is all the rage these days, and it comes in many forms. The basic idea of cloud computing is to make resources available in a web-based data center so the resources can be accessed from anywhere. A company can pay another company to host and manage the cloud environment, or a company can host the environment. Before a cloud deployment model is chosen, the organization must determine the needs of the organization and the security requirements for any data that will be stored in the cloud.
There is a trade-off when a decision must be made between the two architectures. A solution deployed on organizational resources provides the most control over the safety of your data but also requires the staff and the knowledge to deploy, manage, and secure the solution. A cloud solution deployed on a provider’s resources puts your data’s safety in the hands of a third party, but that party is often more capable and knowledgeable about protecting data in this environment and managing the cloud environment.
Cloud storage locates the data on a central server, but the key difference is that the data is accessible from anywhere and, in many cases, from a variety of device types.
Moreover, cloud solutions typically provide fault tolerance.
NIST SP 800-145 gives definitions for cloud deployments that IT professionals should understand. Security professionals should be familiar with four cloud deployments:
Private cloud: This is a solution owned and managed by one company solely for that company’s use. This type of cloud provides the most control and security but also requires the biggest investment in both hardware and expertise.
Public cloud: This is a solution provided by a third party. It offloads the details to that third party but gives up some control and can introduce security issues. Typically, you are a tenant sharing space with others, and in many cases you don’t know where your data is being kept physically.
Hybrid cloud: This is some combination of private and public. For example, perhaps you only use the facilities of the provider but still manage the data yourself.
Community cloud: This is a solution owned and managed by a group of organizations that create the cloud for a common purpose, perhaps to address a common concern such as regularity compliance.
When a public solution is selected, various levels of service can be purchased. Some of these levels include
Infrastructure as a Service (IaaS): Involves the vendor providing the hardware platform or data center and the company installing and managing its own operating systems and application systems. The vendor simply provides access to the data center and maintains that access.
Platform as a Service (PaaS): Involves the vendor providing the hardware platform or data center and the software running on the platform. This includes the operating systems and infrastructure software. The company is still involved in managing the system.
Software as a Service (SaaS): Involves the vendor providing the entire solution. This includes the operating system, infrastructure software, and the application. It might provide you with an email system, for example, whereby the vendor hosts and manages everything for you.
Figure 3-6 shows the relationships of these services to one another.
Figure 3-6 Cloud Computing
NIST SP 800-144 gives guidelines on security and privacy in public cloud computing. This publication defines two types of cloud computing service contracts: predefined non-negotiable agreements and negotiated agreements. Non-negotiable agreements are in many ways the basis for the economies of scale enjoyed by public cloud computing. The terms of service are prescribed completely by the cloud provider. They are typically not written with attention to federal privacy and security requirements. Furthermore, with some offerings, the provider can make modifications to the terms of service unilaterally (e.g., by posting an updated version online) without giving any direct notification to the cloud consumer.
Negotiated service agreements are more like traditional outsourcing contracts for information technology services. They are often used to address an organization’s concerns about security and privacy policy, procedures, and technical controls, such as the vetting of employees, data ownership and exit rights, breach notification, isolation of tenant applications, data encryption and segregation, tracking and reporting service effectiveness, compliance with laws and regulations, and the use of validated products meeting national or international standards.
Critical data and applications may require an agency to undertake a negotiated service agreement. Because points of negotiation can negatively affect the service agreement, a negotiated service agreement is normally less cost effective. The outcome of a negotiation is also dependent on the size of the organization and the influence it can exert. Regardless of the type of service agreement, obtaining adequate legal and technical advice is recommended to ensure that the terms of service adequately meet the needs of the organization.
Potential areas of improvement where organizations may derive security and privacy benefits from transitioning to a public cloud computing environment include the following:
Staff specialization
Platform strength
Resource availability
Backup and recovery
Mobile endpoints
Data concentration
Some of the more fundamental concerns when transitioning to a public cloud include the following:
System complexity
Shared multitenant environment
Internet-facing
Loss of control
Table 3-4 provides a list of security and privacy issues and recommendations for public cloud deployments from NIST SP 800-144.
Table 3-4 NIST SP 800-144 Cloud Security and Privacy Issues and Recommendations
Areas | Recommendations |
Governance | Extend organizational practices pertaining to the policies, procedures, and standards used for application development and service provisioning in the cloud, as well as the design, implementation, testing, use, and monitoring of deployed or engaged services. Put in place audit mechanisms and tools to ensure organizational practices are followed throughout the system life cycle. |
Compliance | Understand the various types of laws and regulations that impose security and privacy obligations on the organization and potentially impact cloud computing initiatives, particularly those involving data location, privacy and security controls, records management, and electronic discovery requirements. Review and assess the cloud provider’s offerings with respect to the organizational requirements to be met and ensure that the contract terms adequately meet the requirements. Ensure that the cloud provider’s electronic discovery capabilities and processes do not compromise the privacy or security of data and applications. |
Trust | Ensure that service arrangements have sufficient means to allow visibility into the security and privacy controls and processes employed by the cloud provider, and their performance over time. Establish clear, exclusive ownership rights over data. Institute a risk management program that is flexible enough to adapt to the constantly evolving and shifting risk landscape for the life cycle of the system. Continuously monitor the security state of the information system to support ongoing risk management decisions. |
Architecture | Understand the underlying technologies that the cloud provider uses to provision services, including the implications that the technical controls involved have on the security and privacy of the system, over the full system life cycle and across all system components. |
Identity and Access Management | Ensure that adequate safeguards are in place to secure authentication, authorization, and other identity and access management functions, and are suitable for the organization. |
Software Isolation | Understand virtualization and other logical isolation techniques that the cloud provider employs in its multitenant software architecture, and assess the risks involved for the organization. |
Data Protection | Evaluate the suitability of the cloud provider’s data management solutions for the organizational data concerned and the ability to control access to data, to secure data while at rest, in transit, and in use, and to sanitize data. Take into consideration the risk of collating organizational data with that of other organizations whose threat profiles are high or whose data collectively represent significant concentrated value. Fully understand and weigh the risks involved in cryptographic key management with the facilities available in the cloud environment and the processes established by the cloud provider. |
Availability | Understand the contract provisions and procedures for availability, data backup and recovery, and disaster recovery, and ensure that they meet the organization’s continuity and contingency planning requirements. Ensure that during an intermediate or prolonged disruption or a serious disaster, critical operations can be immediately resumed, and that all operations can be eventually reinstituted in a timely and organized manner. |
Incident Response | Understand the contract provisions and procedures for incident response and ensure that they meet the requirements of the organization. Ensure that the cloud provider has a transparent response process in place and sufficient mechanisms to share information during and after an incident. Ensure that the organization can respond to incidents in a coordinated fashion with the cloud provider in accordance with their respective roles and responsibilities for the computing environment. |
Another NIST publication, NIST SP 800-146, gives a cloud computing synopsis and recommendations.
NIST SP 800-146 lists the following benefits of SaaS deployments:
Very modest software tool footprint
Efficient use of software licenses
Centralized management and data
Platform responsibilities managed by providers
Savings in up-front costs
NIST SP 800-146 lists the following issues and concerns of SaaS deployments:
Browser-based risks and risk remediation
Network dependence
Lack of portability between SaaS clouds
Isolation vs. efficiency (security vs. cost trade-offs)
NIST SP 800-146 gives a single benefit of PaaS deployments:
Facilitated scalable application development and deployment
The issues and concerns of PaaS deployments are as follows:
Lack of portability between PaaS clouds
Event-based processor scheduling
Security engineering of PaaS applications
NIST SP 800-146 lists the following benefits of IaaS deployments:
Full control of the computing resource through administrative access to VMs
Flexible, efficient renting of computing hardware
Portability and interoperability with legacy applications
The issues and concerns of IaaS deployments are as follows:
Compatibility with legacy security vulnerabilities
Virtual machine sprawl
Verifying authenticity of an IaaS cloud provider website
Robustness of VM-level isolation
Features for dynamic network configuration for providing isolation
Data erase practices
Large-Scale Parallel Data Systems
Most large-scale parallel data systems have been designed to handle scientific and industrial problems, such as air traffic control, ballistic missile defense, satellite-collected image analysis, missile guidance, and weather forecasting. They require enormous processing power. Because data in these systems is being analyzed so quickly, it is often difficult to detect and prevent an attempted intrusion. These types of systems must find a way to split the queries across multiple parallel nodes so the queries can be processed in parallel.
Because these parallel data systems often span multiple organizations, security professionals must consider the areas of trust, privacy, and general security any time their organizations operate within large-scale parallel data systems. Trust-related issues such as the following need to be considered in trusted networks:
Key verification
Trust-based denial-of-service (DoS) attack mitigation
Data leakage detection
Privacy-related issues that need to be considered include the following:
Remote authentication
Decentralized access control
Traffic masking
Large-scale dataset cryptography
Other general security issues that need to be considered include inconsistent user credentials and authorization and data sharing issues related to using cryptography.
Distributed Systems
Distributed systems are discussed in the “Computing Platforms” section earlier in this chapter.
Grid Computing
Grid computing is the process of harnessing the CPU power of multiple physical machines to perform a job. In some cases, individual systems might be allowed to leave and rejoin the grid. Although the advantage of additional processing power is great, there has to be concern for the security of data that could be present on machines that are entering and leaving the grid without proper authentication and authorization. Therefore, grid computing is not necessarily a safe implementation when secrecy of the data is a key issue.
Peer-to-Peer Computing
Any client/server solution in which any platform/system may act as a client or server or both is called peer-to-peer computing. A widely used example of this is instant messaging (IM). These implementations present security issues that do not present themselves in a standard client/server arrangement. In many cases these systems operate outside the normal control of the network administrators.
This situation can present problems such as the following:
Viruses, worms, and Trojan horses can be transmitted through this entry point to the network.
In many cases, lack of strong authentication allows for account spoofing.
Buffer overflow attacks and attacks using malformed packets can sometimes be successful.
If these systems must be tolerated in the environment, security professionals should follow these guidelines:
Security policies should address the proper use of these applications.
All systems should have a firewall and antivirus products installed.
Configure firewalls to block unwanted IM traffic.
If possible, allow only products that provide encryption.
Internet of Things
The Internet of Things (IoT) refers to a system of interrelated computing devices, mechanical and digital machines, and objects that are provided with unique identifiers and the ability to transfer data over a network without requiring human-to-human or human-to-computer interaction. The IoT has presented attackers with a new medium through which to carry out an attack. Often the developers of the IoT devices add the IoT functionality without thoroughly considering the security implications of such functionality or without building in any security controls to protect the IoT devices.
IoT Examples
IoT deployments include a wide variety of devices but are broadly categorized into five groups:
Smart home: Includes products that are used in the home. They range from personal assistance devices, such as Amazon’s Alexa, to HVAC components, such as the Nest Thermostat. The goals of these devices are home management and automation.
Wearables: Includes products that are worn by users. They range from watches, such as the Apple Watch, to personal fitness devices, like the Fitbit.
Smart cities: Includes devices that help resolve traffic congestion issues and reduce noise, crime, and pollution. They include smart energy, smart transportation, smart data, smart infrastructure, and smart mobility.
Connected cars: Includes vehicles that have Internet access and data-sharing capabilities. They include GPS devices, OnStar, and AT&T-connected cars.
Business automation: Includes devices that automate HVAC, lighting, access control, and fire detection for organizations.
Methods of Securing IoT Devices
Security professionals must understand the different methods of securing IoT devices. The following are some recommendations:
Secure and centralize the access logs of IoT devices.
Use encrypted protocols to secure communication.
Create secure password policies.
Implement restrictive network communications policies, and set up virtual LANs.
Regularly update device firmware based on vendor recommendations.
When selecting IoT devices, particularly those that are implemented at the organizational level, security professionals need to look into the following:
Does the vendor design explicitly for privacy and security?
Does the vendor have a bug bounty program and vulnerability reporting system?
Does the device have default or manual overrides or special functions for disconnected operations?
NIST Framework for Cyber-Physical Systems
Cyber-physical systems (CPS) are smart systems that include engineered interacting networks of physical and computational components. These highly interconnected and integrated systems provide new functionalities to improve quality of life and enable technological advances in critical areas, such as personalized healthcare, emergency response, traffic flow management, smart manufacturing, defense and homeland security, and energy supply and use. In addition to CPS, there are many words and phrases (Industrial Internet, IoT, machine-to-machine [M2M], smart cities, and others) that describe similar or related systems and concepts. There is significant overlap between these concepts, in particular CPS and IoT, such that CPS and IoT are sometimes used interchangeably; therefore, the approach described in NIST’s CPS Framework should be considered to be equally applicable to IoT.
The CPS Framework includes domains, aspects, and facets, as shown in Figure 3-7.
Figure 3-7 NIST CPS Framework (Image Courtesy of NIST)
Domains represent the different application areas of CPS and include all those listed in Table 3-5. This list is expected to expand as new CPS and IoT devices are launched.
Table 3-5 CPS Domains
Domains | |
Advertising | Entertainment/sports |
Aerospace | Environmental monitoring |
Agriculture | Financial services |
Buildings | Healthcare |
Cities | Infrastructure (communications, power, water) |
Communities | Leisure |
Consumer | Manufacturing |
Defense | Science |
Disaster resilience | Social networks |
Education | Supply chain/retail |
Emergency response | Transportation |
Energy | Weather |
Table 3-6 describes the three facets of CPS.
Table 3-6 CPS Facets
Facet | Description |
Conceptualization | What things should be and what things are supposed to do: the set of activities that produce a model of a CPS (includes functional decomposition, requirements, and logical models). |
Realization | How things should be made and operate: the set of activities that produce, deploy, and operate a CPS (includes engineering trade-offs and detailed designs in the critical path to the creation of a CPS instance). |
Assurance | How to achieve a desired level of confidence that things will work the way they should: the set of activities that provide confidence that a CPS performs as specified (includes claims, evidence, and argumentation). |
Table 3-7 lists the different aspects of the CPS Framework.
Table 3-7 CPS Framework Aspects
Aspect | Description |
Functional | Concerns about function including sensing, actuation, control, communications, physicality, and so on. |
Business | Concerns about enterprise, time to market, environment, regulation, cost, and so on. |
Human | Concerns about human interaction with and as part of a CPS. |
Trustworthiness | Concerns about trustworthiness of CPS including security, privacy, safety, reliability, and resilience. |
Timing | Concerns about time and frequency in CPS, including the generation and transport of time and frequency signals, timestamping, managing latency, timing composability, and so on. |
Data | Concerns about data interoperability including fusion, metadata, type, identity, and so on. |
Boundaries | Concerns related to demarcations of topological, functional, organizational, or other forms of interactions. |
Composition | Concerns related to the ability to compute selected properties of a component assembly from the properties of its components. Compositionality requires components that are composable: they do not change their properties in an assembly. Timing composability is particularly difficult. |
Life cycle | Concerns about the life cycle of CPS including its components. |
To learn more about the CPS Framework and other IoT initiatives from NIST, go to https://www.nist.gov/itl/applied-cybersecurity/nist-cybersecurity-iot-program/related-initiatives-nist.
Microservices
Microservices is a term for an application design technique whereby developers design highly scalable, flexible applications by decomposing the application into discrete services that implement specific business functions. These services, often referred to as “loosely coupled,” can then be built, deployed, and scaled independently.
Microservices are based on container technology. Security professionals should ensure that security is deployed at the container level. Containers are based on baseline images, which may contain vulnerabilities. Organizations should perform regular scans of container images to ensure the images do not contain security issues. To protect containers at runtime, organizations should adopt the principle of least privilege.
Microservices should also be secured by creating one entry point, which all clients and systems access, and which can easily be secured. This entry point is called an API gateway. The API gateway performs authentication and authorization, and filters requests to sensitive resources.
Using microservices, each service is a separate, isolated application section. Programmers should be able to implement, maintain, modify, extend, and update microservices without affecting other microservices. Isolation should also be performed at other layers of the infrastructure, such as the database.
Containerization
Containerization is the use of containers to isolate and maintain an application. All resources that the application requires to run are placed inside that container. When an application is contained, you can pick it up and move it around regardless of the host operating system if a virtualization host is deployed.
Organizations can run software without worrying about operating systems or dependencies. Because an operating system runs underneath the containerization platform, developers do not have to build a production environment with the right settings and libraries. These are built into the container. Containers are not dependent on the underlying OS and are more portable than virtual machines.
Container isolation provides security benefits. However, isolation does not make a container safe by default. If attackers can find a container escape flaw, this flaw can be used to gain access to sensitive data in other containers. Also, container platforms often do not take advantage of network segmentation. Without network segmentation, an attacker can more easily cross from one compromised container to other vulnerable ones on the same network.
Because containers are portable and easy to set up, attackers can create their own malware-laden containers and upload them to public resources. Before running containers, security professionals should understand the source and assess the container’s security to ensure it is trustworthy and not opening the organization’s network for attackers.
Security professionals must update and securely configure the host OS, harden the containerization layers and any orchestration software, and configure accounts based on the principles of least privilege. Otherwise, attackers will focus on insecurely configured containerization layers. In addition, security professionals should ensure protections are in place for all sensitive information, such as credentials, API keys, and tokens at every level: the containerization platform, orchestration platforms, and the individual containers.
Serverless Systems
Serverless is a term used for a model wherein applications rely on managed services that do away with the need to manage, patch, and secure infrastructure and virtual machines. This is most commonly seen deployed in the cloud. Serverless systems have many vulnerabilities of which security professionals must be aware.
Any misconfigurations can act as an entry point for attacks against serverless architectures. With many independent functions and services, security professionals should ensure that the principle of least privilege is followed for all user accounts. In addition, the privileges of functions should be properly configured because privilege escalation is considered a potential security threat.
Injection flaws in applications are one of the most common security risks. They include untrusted inputs in application calls, cloud storage event triggers, NoSQL databases, and code changes.
Monitoring and logging in serverless systems must be properly configured as if these systems were physical systems. In addition, any third-party dependencies must be documented and the security of them verified.
Because debugging services are often limited to the capabilities of the developers, developers should implement verbose error messages and enable the debugging mode. But these should be disabled when the application is moved to production because they may reveal information about serverless functions and the logic used.
High-Performance Computing Systems
High-Performance Computing (HPC) systems process data and perform complex calculations at high speeds. One of the best-known types of HPC solutions is the supercomputer. Another example of an HPC is a cluster.
By definition, clusters are closely-coupled machines that are centrally administered and share common resources, such as storage. Security professionals should secure these internal distributed resources against unauthorized access, while at the same time allowing easy access by legitimate users.
When a user executes a job on HPC systems, it is often difficult to differentiate legitimate versus illegitimate use unless there are obvious malicious process signatures. In addition, security must be coordinated across different node platforms and different specialized function nodes in an HPC system. Tools to automate security management need to be aware of the similarities and differences present among HPS system resources.
The security of the resources in an HPC system is dependent on the integrity of all nodes. A single compromised node represents a dramatic risk increase to the rest of the nodes due to the fact that many nodes share identical configurations.
Edge Computing Systems
Edge computing systems are part of a distributed computing topology that brings computation and data storage closer to the devices where it’s being gathered, primarily on the edge of the network perimeter, rather than relying on a central location far away. Edge computing devices are often small, lacking built-in security, and without automatic updates. They are often an easy entry point into the network, which can then be used to access main systems.
Security professionals should ensure that edge computing systems are protected against digital and physical attacks. Employing security by design is basic to securing edge computing systems. Poorly configured and poorly secured edge computing systems provide attackers more opportunities to disrupt operations or to gain access to the broader enterprise network. If the edge computing systems interact with the service provider edge, organizations should examine the service provider’s security processes, service-level agreements (SLAs) and architecture alignment. Employing zero trust will ensure that untrusted devices will be more easily detectable. Finally, organizations should ensure that any open-source code is assessed for security vulnerabilities.
Virtualized Systems
Today physical servers are increasingly being consolidated as virtual servers on the same physical box. Virtual networks using virtual switches even exist in the physical devices that host these virtual servers. These virtual network systems and their traffic can be segregated in all the same ways as in a physical network using subnets, VLANs, and of course, virtual firewalls. Virtual firewalls are software that has been specifically written to operate in the virtual environment. Increasingly, virtualization vendors such as VMware are making part of their code available to security vendors to create firewalls (and antivirus products) that integrate closely with the product.
Keep in mind that in any virtual environment each virtual server that is hosted on the physical server must be configured with its own security mechanisms. These mechanisms include antivirus and anti-malware software and all the latest service packs and security updates for all the software hosted on the virtual machine. Also, remember that all the virtual servers share the resources of the physical device.
Vulnerabilities in Web-Based Systems
Despite all efforts to design a secure web architecture, attacks to a web-based system still occur and still succeed. In the following sections, we examine some of the more common types of attacks, including maintenance hooks, time-of-check/time-of-use attacks, and web-based attacks. We also explore XML and SAML vulnerabilities and OWASP, a resource dedicated to defending against web-based attacks.
Maintenance Hooks
From the perspective of software development, a maintenance hook is a set of instructions built into the code that allows someone who knows about the so-called backdoor to use the instructions to connect to view and edit the code without using the normal access controls. In many cases, maintenance hooks are placed in an application to make it easier for the vendor to load patches, fix bugs, and/or otherwise provide software support to the customer. In other cases, maintenance hooks can be used in testing and tracking the activities of the product and not removed when the application is deployed.
Regardless of how the maintenance hooks got into the code, they can present a major security issue if they become known to hackers who can use them to access the system. Countermeasures on the part of the customer to mitigate the danger are
Use a host-based IDS to record any attempts to access the system using one of these hooks.
Encrypt all sensitive information contained in the system.
Implement auditing to supplement the IDS.
The best solution is for the vendor to remove all maintenance hooks before the product goes into production. Code reviews should be performed to identify and remove these hooks.
Time-of-Check/Time-of-Use Attacks
Time-of-check/time-of-use attacks attempt to take advantage of the sequence of events that occur as the system completes common tasks. It relies on knowledge of the dependencies present when a specific series of events occur in multiprocessing systems. By attempting to insert themselves between events and introduce changes, hackers can gain control of the result.
A term often used as a synonym for a time-of-check/time-of-use attack is race condition, which is actually a different attack. In this attack, hackers insert themselves between instructions, introduce changes, and alter the order of execution of the instructions, thereby altering the outcome.
Countermeasures to these attacks are to make critical sets of instructions atomic. This means that they either execute in order and in entirety, or the changes they make are rolled back or prevented. It is also best for the system to lock access to certain items it will use or touch when carrying out these sets of instructions.
Web-Based Attacks
Attacks upon information security infrastructures have continued to evolve steadily over time, and the latest attacks use largely more sophisticated web application–based attacks. These attacks have proven more difficult to defend with traditional approaches using perimeter firewalls.
XML
Extensible Markup Language (XML) is the most widely used web language now and has come under some criticism. The method currently used to sign data to verify its authenticity has been described as inadequate by some, and the other criticisms have been directed at the architecture of XML security in general. Next, we discuss an extension of this language that attempts to address some of these concerns.
SAML
Security Assertion Markup Language (SAML) is an XML-based open standard data format for exchanging authentication and authorization data between parties, in particular between an identity provider and a service provider. SAML allows the user to have a portable identity for authentication and authorization on the Internet. The major issue on which it focuses is called the web browser single sign-on (SSO) problem.
SSO is the ability to authenticate once to access multiple sets of data. SSO at the Internet level is usually accomplished with cookies, but extending the concept beyond the Internet has resulted in many propriety approaches that are not interoperable. SAML’s goal is to create a standard for this process.
OWASP
The Open Web Application Security Project (OWASP) is an open-source application security project. This group creates guidelines, testing procedures, and tools to assist with web security. They are also known for maintaining a top-10 list of web application security risks. Information on OWASP can be obtained from www.owasp.org.
Vulnerabilities in Mobile Systems
As mobile devices have become more popular, security issues related to those devices have increased. Security professionals face unique challenges due to the increasing use of mobile devices combined with the fact that many of these devices connect using public networks with little or no security.
Educating users on the risks related to mobile devices and ensuring that they implement appropriate security measures can help protect against threats involved with these devices. Some of the guidelines that should be provided to mobile device users include implementing a device-locking PIN, using device encryption, implementing GPS location services, and implementing remote wiping. Also, users should be cautioned about downloading apps without ensuring that they are coming from a reputable source. In recent years, mobile device management (MDM) and mobile application management (MAM) systems have become popular in enterprises. These systems are implemented to ensure that an organization can control mobile device settings, applications, and other parameters when those devices are attached to the enterprise.
The threats presented by the introduction of personal mobile devices (smartphones and tablets) to an organization’s network include
Insecure web browsing
Insecure Wi-Fi connectivity
Lost or stolen devices holding company data
Corrupt application downloads and installations
Missing security patches
Constant upgrading of personal devices
Use of location services
While the most common types of corporate information stored on personal devices are corporate emails and company contact information, it is alarming to note that almost half of these devices also contain customer data, network login credentials, and corporate data accessed through business applications.
The main issues regarding mobile systems are device security, application security, and mobile device concerns. Also, we cover NIST SP 800-164, which provides guidelines for mobile devices.
Device Security
Device security involves the physical security of the mobile device. In the event that a device is lost or stolen, users also need the capability to remotely track and lock the device. Some of the recommendations for device security include
Locking your phone with a password or fingerprint detection
Encrypting your data
Setting up remote wipe
Backing up phone, credit card, pictures, and other personal data
Avoiding jail-breaking your iPhone or rooting your Android
Updating the operating system as updates are available
Being aware of social engineering scams
Using public Wi-Fi with added caution
Application Security
Although device security is important for mobile devices, application security is just as important. Users should download approved apps only from the vendor application stores. Some of the recommendations for application security include
Avoiding third-party apps
Being aware of social engineering scams
Downloading reputable and proven-to-work anti-malware for your mobile device
Mobile Device Concerns
To address these issues and to meet the rising demand to bring and use personal devices, many organizations have created bring-your-own-device (BYOD) policies. In supporting a BYOD initiative, a security professional should consider that careless users are a greater threat than hackers. Not only are users less than diligent in maintaining security updates and patches on devices, but they also buy new devices as often as they change clothes. These factors make it difficult to maintain control over the security of the networks in which these devices are allowed to operate.
Other initiatives today include company-owned, business only (COBO), company-owned, personally enabled (COPE), and choose-your-own-device (CYOD) deployments. No matter which deployment an organization uses, security professionals must ensure that the risks of each model are understood and that the appropriate policies are in place to protect company data and assets. Security professionals are responsible for ensuring that management understands these risks and implements the appropriate tools to control access to the enterprise.
Centralized mobile device management tools are a fast-growing solution. Some of these tools leverage the messaging server’s management capabilities, and others are third-party tools that can manage multiple brands of devices. Systems Manager by Cisco is one example that integrates with the Cisco Meraki cloud services. Another example for iOS devices is the Apple Configurator. One of the challenges with implementing such a system is that not all personal devices may support native encryption and/or the management process.
Typically, centralized mobile device management tools handle company-issued and personal mobile devices differently. For organization-issued devices, a client application typically manages the configuration and security of the entire device. If a personal device is allowed through a BYOD initiative, the application typically manages the configuration and security of itself and its data only. The application and its data are sandboxed from the other applications and data. The result is that the organization’s data and the user’s data are protected if the device is stolen.
Regardless of whether a centralized mobile device management tool is in use, a BYOD policy should include the following in the organization’s security policy:
Identify the allowed uses of personal devices on the corporate network.
Create a list of allowed applications on the devices and design a method of preventing the installation of applications not on the list (for example, software restriction policies).
Ensure that high levels of management are on board and supportive.
Train and regularly remind users to follow the new policies.
In the process of deploying and supporting a mobile solution, follow these guidelines:
Ensure that the selected solution supports applying security controls remotely.
Ensure that the selected vendor has a good track record of publicizing and correcting security flaws.
Make the deployment of an MDM tool a top priority.
In the absence of an MDM system, design a process to ensure that all devices are kept up to date on security patches.
Update the policy as technology and behaviors change.
Require all employees to agree to allow remote wiping of any stolen or lost devices.
Strictly forbid rooted (Android) or jail-broken (iOS) devices from accessing the network.
If possible, choose a product that supports:
Encrypting the solid state drive (SSD) and nonvolatile RAM
Requiring a PIN to access the device
Locking the device when a specific number of incorrect PINs are attempted
As with many of the other security issues discussed in this book, user education is key. A security professional must ensure that users understand the importance of mobile device security.
If an organization does not implement an MDM or MAM solution, the mobile device security policy should include, at minimum, the following policies:
Implement anti-malware/antivirus software on all mobile devices.
Use only secure communications.
Use strong authentication.
Require a PIN or some other login mechanism with each use of the device after a certain idle period (no more than 10 minutes of inactivity).
Limit third-party software.
Implement GPS and other location services.
Enable remote locking and remote wiping features.
Never leave the device unattended.
Immediately report any missing or stolen device.
Disable all unnecessary options, applications, and services, including Bluetooth.
Regularly back up data.
Install all updates from the device manufacturer.
NIST SP 800-164
NIST SP 800-164 is a draft Special Publication that gives guidelines on hardware-rooted security in mobile devices. It defines three required security components for mobile devices: Roots of Trust (RoTs), an application programming interface (API) to expose the RoTs to the platform, and a Policy Enforcement Engine (PEnE).
Roots of Trust are the foundation of assurance of the trustworthiness of a mobile device. RoTs must always behave in an expected manner because their misbehavior cannot be detected. Hardware RoTs are preferred over software RoTs due to their immutability, smaller attack surfaces, and more reliable behavior. They can provide a higher degree of assurance that they can be relied upon to perform their trusted function or functions. Software RoTs could provide the benefit of quick deployment to different platforms. To support device integrity, isolation, and protected storage, devices should implement the following RoTs:
Root of Trust for Storage (RTS)
Root of Trust for Verification (RTV)
Root of Trust for Integrity (RTI)
Root of Trust for Reporting (RTR)
Root of Trust for Measurement (RTM)
The RoTs need to be exposed by the operating system to applications through an open API. This exposure will provide application developers a set of security services and capabilities they can use to secure their applications and protect the data they process. By providing an abstracted layer of security services and capabilities, these APIs can reduce the burden on application developers to implement low-level security features, and instead allow them to reuse trusted components provided in the RoTs and the OS. The APIs should be standardized within a given mobile platform and, to the extent possible, across platforms. Applications can use the APIs, and the associated RoTs, to request device integrity reports, protect data through encryption services provided by the RTS, and store and retrieve authentication credentials and other sensitive data.
The PEnE enforces policies on the device with the help of other device components and enables the processing, maintenance, and management of policies on both the device and in the information owners’ environments. The PEnE provides information owners with the ability to express the control they require over their information. The PEnE needs to be trusted to implement the information owner’s requirements correctly and to prevent one information owner’s requirements from adversely affecting another’s. To perform key functions, the PEnE needs to be able to query the device’s configuration and state.
Mobile devices should implement the following three mobile security capabilities to address the challenges with mobile device security:
Device integrity: Device integrity is the absence of corruption in the hardware, firmware, and software of a device. A mobile device can provide evidence that it has maintained device integrity if its software, firmware, and hardware configurations can be shown to be in a state that is trusted by a relying party.
Isolation: Isolation prevents unintended interaction between applications and information contexts on the same device.
Protected storage: Protected storage preserves the confidentiality and integrity of data on the device while at rest, while in use (in the event an unauthorized application attempts to access an item in protected storage), and upon revocation of access.
Vulnerabilities in Embedded Systems
An embedded system is a computer system with a dedicated function within a larger system, often with real-time computing constraints. It is embedded as part of the device, often including hardware and mechanical parts. Embedded systems control many devices in common use today and include systems embedded in cars, HVAC systems, security alarms, and even lighting systems. Machine-to-machine (M2M) communication, the Internet of Things (IoT), and remotely controlled industrial systems have increased the number of connected devices and simultaneously made these devices targets.
Because embedded systems are usually placed within another device without input from a security professional, security is not even built into the device. So while allowing the device to communicate over the Internet with a diagnostic system provides a great service to the consumer, oftentimes the manufacturer has not considered that a hacker can then reverse communication and take over the device with the embedded system. As of this writing, reports have surfaced of individuals being able to take control of vehicles using their embedded systems. Manufacturers have released patches that address such issues, but not all vehicle owners have applied or even know about the patches.
As M2M and IoT increase in popularity, security professionals can expect to see a rise in incidents like this. A security professional is expected to understand the vulnerabilities these systems present and how to put controls in place to reduce an organization’s risk.
Cryptographic Solutions
While security architecture and engineering involves securing all the devices that an organization implements, it is not just enough to secure the devices. Organizations must also secure the data as it resides on the devices and as it is transmitted over the network. Cryptography involves using algorithms to protect data. The following sections discuss cryptography concepts, cryptography history, cryptosystem features, cryptographic mathematics, and cryptographic life cycle.
Cryptography Concepts
A security professional should understand many terms and concepts related to cryptography.
These terms are often used when discussing cryptography:
Encryption: The process of converting data from plaintext to ciphertext. Also referred to as enciphering.
Decryption: The process of converting data from ciphertext to plaintext. Also referred to as deciphering.
Key: A parameter that controls the transformation of plaintext into ciphertext or vice versa. Determining the original plaintext data without the key is impossible. Keys can be both public and private. Also referred to as a cryptovariable.
Synchronous: When encryption or decryption occurs immediately.
Asynchronous: When encryption or decryption requests are processed from a queue. This method utilizes hardware and multiple processors in the process.
Symmetric: An encryption method whereby a single private key both encrypts and decrypts the data. Also referred to as private or secret key encryption.
Asymmetric: An encryption method whereby a key pair, one private key and one public key, performs encryption and decryption. One key performs the encryption, whereas the other key performs the decryption. Also referred to as public key encryption.
Digital signature: A method of providing sender authentication and message integrity. The message acts as an input to a hash function, and the sender’s private key encrypts the hash value. The receiver can perform a hash computation on the received message to determine the validity of the message.
Hash: A one-way function that reduces a message to a hash value. A comparison of the sender’s hash value to the receiver’s hash value determines message integrity. If the resultant hash values are different, then the message has been altered in some way, provided that both the sender and receiver used the same hash function.
Digital certificate: An electronic document that identifies the certificate holder.
Plaintext: A message in its original format. Also referred to as cleartext.
Ciphertext: An altered form of a message that is unreadable without knowing the key and the encryption system used. Also referred to as a cryptogram.
Cryptosystem: The entire cryptographic process, including the algorithm, key, and key management functions. The security of a cryptosystem is measured by the size of the keyspace and available computational power.
Cryptanalysis: The science of decrypting ciphertext without prior knowledge of the key or cryptosystem used. The purpose of cryptanalysis is to forge coded signals or messages that will be accepted as authentic signals or messages.
Key clustering: The grouping that occurs when different encryption keys generate the same ciphertext from the same plaintext message.
Keyspace: All the possible key values when using a particular algorithm or other security measure. A 40-bit key would have 240 possible values, whereas a 128-bit key would have 2128 possible values.
Collision: An event that occurs when a hash function produces the same hash value on different messages.
Algorithm: A mathematical function that encrypts and decrypts data. Also referred to as a cipher.
Cryptology: The science that studies encrypted communication and data.
Encoding: The process of changing data into another form using code.
Decoding: The process of changing an encoded message back into its original format.
Transposition: The process of shuffling or reordering the plaintext to hide the original message. Also referred to as permutation. For example, AEEGMSS is a transposed version of MESSAGE.
Substitution: The process of exchanging one byte in a message for another. For example, ABCCDEB is a substituted version of MESSAGE.
Confusion: The process of changing a key value during each round of encryption. Confusion is often carried out by substitution. Confusion conceals a statistical connection between the plaintext and ciphertext. Claude Shannon first discussed confusion.
Diffusion: The process of changing the location of the plaintext within the ciphertext. Diffusion is often carried out using transposition. Claude Shannon first introduced diffusion.
Avalanche effect: The condition where any change in the key or plaintext, no matter how minor, will significantly change the ciphertext. Horst Feistel first introduced avalanche effect.
Work factor or work function: The amount of time and resources that would be needed to break the encryption.
Trapdoor: A secret mechanism that allows the implementation of the reverse function in a one-way function.
One-way function: A mathematical function that can be more easily performed in one direction than in the other.
Cryptography History
Cryptography has its roots in ancient civilizations. Although early cryptography solutions were simplistic in nature, they were able to provide leaders with a means of hiding messages from enemies.
In their earliest forms, most cryptographic methods implemented some sort of substitution cipher, where each character in the alphabet was replaced with another. A mono-alphabetic substitution cipher uses only one alphabet, and a polyalphabetic substitution cipher uses multiple alphabets. As with all other cryptography methods, the early substitution ciphers had to be replaced by more complex methods.
The Spartans created the scytale cipher, which used a sheet of papyrus wrapped around a wooden rod. The encrypted message had to be wrapped around a rod of the correct size to be deciphered, as shown in Figure 3-8.
Figure 3-8 Scytale Cipher
Other notable advances in cryptography history include the following:
Caesar cipher
Vigenere cipher
Kerckhoff’s principle
World War II Enigma
Lucifer by IBM
Julius Caesar and the Caesar Cipher
Julius Caesar developed a mono-alphabetic cipher that shifts the letters of the alphabet three places. Although this technique is very simplistic, variations of it were very easy to develop because the key (the number of locations that the alphabet shifted) can be changed. Because it was so simple, it is easy to reverse engineer and led to the development of polyalphabetic ciphers.
An example of a Caesar cipher–encrypted message is shown in Figure 3-9. In this example, the letters of the alphabet are applied to a three-letter substitution shift, meaning the letters were shifted by three letters. As you can see, the standard English alphabet is listed first. Underneath it, the substitution letters are listed.

Figure 3-9 Caesar Cipher
Vigenere Cipher
In the sixteenth century, Blaise de Vigenere of France developed one of the first polyalphabetic substitution ciphers, today known as the Vigenere cipher. Although it is based on the Caesar cipher, the Vigenere cipher is considerably more complicated because it uses 27 shifted alphabets (see the Vigenere table in Figure 3-10). To encrypt a message, you must know the security key and use it in conjunction with the plaintext message to determine the ciphertext.
Figure 3-10 Vigenere Table
As an example of a message on which the Vigenere cipher is applied, let’s use the security key PEARSON and the plaintext message of MEETING IN CONFERENCE ROOM. The first letter in the plaintext message is M, and the first letter in the key is P. We should locate the letter M across the headings for the columns. We follow that column down until it intersects with the row that starts with the letter P, resulting in the letter B. The second letter of the plaintext message is E, and the second letter in the key is E. Using the same method, we obtain the letter I. We continue in this same manner until we run out of key letters, and then we start over with the key, which would result in the second letter I in the plaintext message working with the letter P of the key.
So applying this technique to the entire message, the MEETING IN CONFERENCE ROOM plaintext message converts to BIEKABT XR CFFTRGINTW FBDQ ciphertext message.
Kerckhoffs’s Principle
In the nineteenth century, Auguste Kerckhoffs developed six design principles for the military use of ciphers. The six principles are as follows:
The system must be practically, if not mathematically, indecipherable.
It must not be required to be secret, and it must be able to fall into the hands of the enemy without inconvenience.
Its key must be communicable and retainable without the help of written notes, and changeable or modifiable at the will of the correspondents.
It must be applicable to telegraphic correspondence.
It must be portable, and its usage and function must not require the concourse of several people.
Finally, given the circumstances that command its application, the system needs to be easy to use, requiring neither mental strain nor the knowledge of a long series of rules to observe.
In Kerckhoffs’s principle, remember that the key is secret, and the algorithm is known.
World War II Enigma
During World War II, most of the major military powers developed encryption machines. The most famous of the machines used during the war was the Enigma machine, developed by Germany. The Enigma machine consisted of rotors and a plug board.
To convert a plaintext message to ciphertext, the machine operator would first configure its initial settings. Then the operator would type each letter of the original plaintext message into the machine one at a time. The machine would display a different letter for each letter entered. After the operator wrote down the ciphertext letter, the operator would advance the rotors to the new setting. So with each letter entered, the operator had to change the machine setting. The key of this process was the initial machine setting and the series of increments used to advance the rotor, both of which had to be known by the receiver to properly convert the ciphertext back to plaintext.
As complicated as the system was, a group of Polish cryptographers were able to break the code, thereby being credited with shortening World War II by two years.
Lucifer by IBM
The Lucifer project, developed by IBM, developed complex mathematical equations. These equations later were used by the U.S. National Security Agency in the development of the U.S. Digital Encryption Standard (DES), which is still used today in some form. Lucifer used a Feistel cipher, an iterated block cipher that encrypts the plaintext by breaking the block into two halves. The cipher then applies a round of transformation to one of the halves using a subkey. The output of this transformation is Exclusive ORed (XORed) with the other block half. Finally, the two halves are swapped to complete the round.
Cryptosystem Features
A cryptosystem consists of software, protocols, algorithms, and keys. The strength of any cryptosystem comes from the algorithm and the length and secrecy of the key. For example, one method of making a cryptographic key more resistant to exhaustive attacks is to increase the key length. If the cryptosystem uses a weak key, it facilitates attacks against the algorithm.
While a cryptosystem supports the three core principles of the CIA triad, cryptosystems directly provide authentication, confidentiality, integrity, authorization, and non-repudiation. The availability tenet of the CIA triad is supported by cryptosystems, meaning that implementing cryptography will help to ensure that an organization’s data remains available. However, cryptography does not directly ensure data availability although it can be used to protect the data.
Authentication
Cryptosystems provide authentication by being able to determine the sender’s identity and validity. Digital signatures verify the sender’s identity. Protecting the key ensures that only valid users can properly encrypt and decrypt the message.
Confidentiality
Cryptosystems provide confidentiality by altering the original data in such a way as to ensure that the data cannot be read except by the valid recipient. Without the proper key, unauthorized users are unable to read the message.
Integrity
Cryptosystems provide integrity by allowing valid recipients to verify that data has not been altered. Hash functions do not prevent data alteration but provide a means to determine whether data alteration has occurred.
Authorization
Cryptosystems provide authorization by providing the key to valid users after those users prove their identity through authentication. The key given to a user will allow the user to access a resource.
Non-repudiation
Non-repudiation in cryptosystems provides proof of the origin of data, thereby preventing senders from denying that they sent a message and supporting data integrity. Public key cryptography and digital signatures provide non-repudiation.
NIST SP 800-175A and B
NIST SP 800-175A and B are two Special Publications that provide guidelines for using cryptographic standards in the federal government. SP 800-175A lists all the directives, mandates, and policies that affect the selection of cryptographic standards for the federal government, while SP 800-175B discusses the cryptographic standards that are available and how they should be used.
NIST SP 800-175A lists the following laws as affecting cryptographic standards:
Federal Information Security Management Act (FISMA)
Health Information Technology for Economic and Clinical Health (HITECH) Act
Federal Information Systems Modernization Act of 2014
Cybersecurity Enhancement Act of 2014
The executive actions and the Office of Management and Budget (OMB) circulars and memorandums that affect U.S. government systems cryptography standards are also listed in NIST SP 800-175A. It also gives the definitions for the following policies:
Information management policy: Specifies what information is to be collected or created, and how it is to be managed
Information security policy: Supports and enforces portions of the organization’s information management policy by specifying in more detail what information is to be protected from anticipated threats and how that protection is to be attained
Key management policy: Includes descriptions of the authorization and protection objectives and constraints that apply to the generation, distribution, accounting, storage, use, recovery, and destruction of cryptographic keying material, and the cryptographic services to be provided
Finally, NIST SP 800-175A lists the Risk Management Framework steps from NIST SP 800-37 that affect cryptography selection: categorization of information and information systems and selection of security controls.
NIST SP 800-175B covers the following cryptographic algorithms:
Cryptographic hash functions
Symmetric key algorithms
Asymmetric key algorithms
It also discusses algorithm security strength, algorithm lifetime, and key management.
Security professionals who need help in selecting the appropriate cryptographic algorithms should refer to these SPs.
Cryptographic Mathematics
All cryptographic algorithms involve the use of mathematics. The fundamental mathematical concepts for cryptography are discussed in the following sections.
Boolean
The rules used for the bits and bytes that form a computer are established by Boolean mathematics. In a Boolean system, the values of each circuit are either true or false, usually denoted by 1 and 0, respectively.
Logical Operations (And, Or, Not, Exclusive Or)
When you are dealing with Boolean mathematics, four basic logical operators are used: AND, OR, NOT, and EXCLUSIVE OR. The AND, OR, and EXCLUSIVE OR operators take in two values and output one value. The NOT operator takes in one value and outputs one value.
An AND operation, also referred to as conjunction, checks to see whether two values are both true. Table 3-8 shows the result of an AND operation.
Table 3-8 AND Operation Results
X Value | Y Value | AND Operation Result |
0 | 0 | 0 |
0 | 1 | 0 |
1 | 0 | 0 |
1 | 1 | 1 |
An OR operation, also referred to as disjunction, checks to see whether at least one of the values is true. Table 3-9 shows the result of an OR operation.
Table 3-9 OR Operation Results
X Value | Y Value | OR Operation Result |
0 | 0 | 0 |
0 | 1 | 1 |
1 | 0 | 1 |
1 | 1 | 1 |
A NOT operation, also referred to as negation, reverses the value of a variable. Table 3-10 shows the result of a NOT operation.
Table 3-10 NOT Operation Results
X Value | NOT Operation Result |
0 | 1 |
1 | 0 |
An EXCLUSIVE OR operation, also referred to as XOR, returns a true value when only one of the input values is true. If both values are true or both values are false, the output is always false. Table 3-11 shows the result of an XOR operation.
Table 3-11 XOR Operation Results
X Value | Y Value | XOR Operation Result |
0 | 0 | 0 |
0 | 1 | 1 |
1 | 0 | 1 |
1 | 1 | 0 |
Modulo Function
Used in cryptography, a modulo function is the value that is left over/remainder after a division operation is performed. For example, 32 divided by 8 would have a remainder of 0 because 8 goes into 32 an even number of times (4); modulo in this case is 0. The number 10 divided by 3 would have a remainder of 1 because 10 divided by 3 equals 3 with a remainder of 1. Therefore, modulo of 10 divided by 3 is 1.
One-Way Function
A one-way function produces output values for each possible combination of inputs. This makes it impossible to retrieve the input values of a one-way function. Public key algorithms are based on one-way functions. The inputs used are prime numbers. For example, suppose an input contains only prime numbers with three digits. The output or result of those three prime numbers could be determined using a good calculator. However, if someone obtains the result of 19,786,001, it would be hard to determine which three three-digit prime numbers were used. (By the way, 101, 227, and 863 are the three prime numbers used.)
Nonce
A nonce is a random number that is used only once and acts as a placeholder variable in functions. When the function is actually executed, the nonce is replaced with a random number generated at the time of processing. A common example of a nonce is an initialization vector (IV). IVs are values that are used to create a unique ciphertext every time the same message is encrypted using the same key.
Split Knowledge
Split knowledge is the term used when information or privilege is divided between multiple users or entities so that no single user has sufficient privileges to compromise security. An example of split knowledge in cryptography is key escrow. With key escrow, the key is held by a third party to ensure that the key could be retrieved if the issuing party ceases to exist or has a catastrophic event.
Cryptographic Life Cycle
When considering implementing cryptography or encryption techniques in an organization, security professionals must fully analyze the needs of the organization. Each technique has strengths and weaknesses. In addition, they each have specific purposes. Analyzing the needs of the organization will ensure that you identify the best algorithm to implement.
Professional organizations manage algorithms to ensure that they provide the protection needed. It is essential that security professionals research the algorithms they implement and understand any announcements from the governing organization regarding updates, retirements, or replacements to the implemented algorithms. The life cycle of any cryptographic algorithm involves implementation, maintenance, and retirement or replacement. Security professionals who fail to obtain up-to-date information regarding the algorithms implemented might find the organization’s reputation and their own personal reputation damaged as the result of this negligence.
Key Management
Key management in cryptography is essential to ensure that the cryptography provides confidentiality, integrity, and authentication. If a key is compromised, it can have serious consequences throughout an organization.
Key management involves the entire process of ensuring that keys are protected during creation, distribution, transmission, storage, and disposal. As part of this process, keys must also be destroyed properly. When you consider the vast number of networks over which the key is transmitted and the different types of systems on which a key is stored, the enormity of this issue really comes to light.
As the most demanding and critical aspect of cryptography, it is important that security professionals understand key management principles.
Keys should always be stored in ciphertext when stored on a noncryptographic device. Key distribution, storage, and maintenance should be automatic by integrating the processes into the application.
Because keys can be lost, backup copies should be made and stored in a secure location. A designated individual should have control of the backup copies with other designated individuals serving as emergency backups. The key recovery process should also require more than one operator to ensure that only valid key recovery requests are completed. In some cases, keys are even broken into parts and deposited with trusted agents, who provide their part of the key to a central authority when authorized to do so. Although other methods of distributing parts of a key are used, all the solutions involve the use of trustee agents entrusted with part of the key and a central authority tasked with assembling the key from its parts. Also, key recovery personnel should span across the entire organization and not just be members of the IT department.
Organizations should also limit the number of keys that are used. The more keys that you have, the more keys you must worry about and ensure are protected. Although a valid reason for issuing a key should never be ignored, limiting the number of keys issued and used reduces the potential damage.
When designing the key management process, security professionals should consider how to do the following:
Securely store and transmit the keys.
Use random keys.
Issue keys of sufficient length to ensure protection.
Properly destroy keys when no longer needed.
Back up the keys to ensure that they can be recovered.
Algorithm Selection
When selecting an algorithm, organizations need to understand the data that needs protecting and the organizational environment, including any regulations and standards with which they must comply. Organizations should answer the following questions when selecting the algorithm to use:
What is the encryption timeframe? Use encryption that can survive a brute-force attack at least long enough that the data is no longer important to keep secret.
What data types need to be encrypted? Data at rest, data in use, and data in motion need different types of encryption for protection.
What system restrictions exist? Considerations include budget, operating system restrictions, infrastructure restrictions, and so on.
Who will be exchanging the encrypted data? Legacy systems may cause restrictions on the encryption that can be used when data is exchanged.
Cryptographic Types
Algorithms that are used in computer systems implement complex mathematical formulas when converting plaintext to ciphertext. The two main components to any encryption system are the key and the algorithm. In some encryption systems, the two communicating parties use the same key. In other encryption systems, the two communicating parties use different keys in the process, but the keys are related.
In the following sections, we discuss the following:
Running key and concealment ciphers
Substitution ciphers
Transposition ciphers
Symmetric algorithms
Asymmetric algorithms
Hybrid ciphers
Running Key and Concealment Ciphers
Running key ciphers and concealment ciphers are considered classical methods of producing ciphertext. The running key cipher uses a physical component, usually a book, to provide the polyalphabetic characters. An indicator block must be included somewhere within the text so that the receiver knows where in the book the originator started. Therefore, the two parties must agree upon which book to use and where the indicator block will be included in the cipher message. Running key ciphers are also referred to as key ciphers and running ciphers.
A concealment cipher, also referred to as a null cipher, occurs when plaintext is interspersed somewhere within other written material. The two parties must agree on the key value, which defines which letters are part of the actual message. For example, every third letter or the first letter of each word is part of the real message. A concealment cipher belongs in the steganography realm.
Substitution Ciphers
A substitution cipher uses a key to substitute characters or character blocks with different characters or character blocks. The Caesar cipher and Vigenere cipher are two of the earliest forms of substitution ciphers.
Another example of a substitution cipher is a modulo 26 substitution cipher. With this cipher, the 26 letters of the alphabet are numbered in order starting at zero. The sender takes the original message and determines the number of each letter in the original message. Then the letter values for the keys are added to the original letter values. The value result is then converted back to text.
Figure 3-11 shows an example of a modulo 26 substitution cipher encryption. With this example, the original message is PEARSON, and the key is KEY. The ciphertext message is ZIYBSMX.

Figure 3-11 Modulo 26 Substitution Cipher Example
Substitution ciphers explained here include the following:
One-time pads
Steganography
One-Time Pads
A one-time pad, invented by Gilbert Vernam, is the most secure encryption scheme that can be used. If it’s used properly, an attacker cannot break a one-time pad. A one-time pad works like a running cipher in that the key value is added to the value of the letters. However, a one-time pad uses a key that is the same length as the plaintext message, whereas the running cipher uses a smaller key that is repeatedly applied to the plaintext message.
Figure 3-12 shows an example of a one-time pad encryption. With this example, the original message is PEARSON, and the key is JOHNSON. The ciphertext message is YSHEKCA.
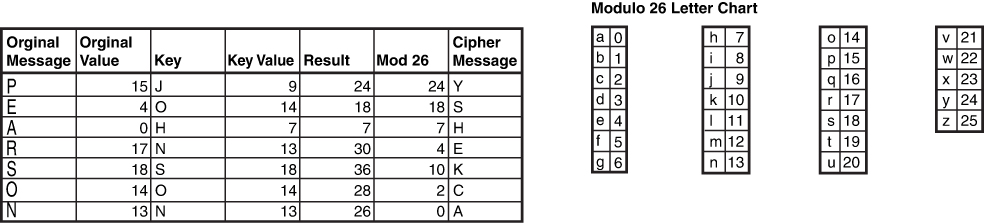
Figure 3-12 One-Time Pad Example
To ensure that the one-time pad is secure, the following conditions must exist:
Must be used only one time
Must be as long as (or longer than) the message
Must consist of random values
Must be securely distributed
Must be protected at its source and destination
Although the earlier example uses a one-time pad in a modulo 26 scheme, one-time pads can also be used at the bit level. When the bit level is used, the message is converted into binary, and an XOR operation occurs two bits at a time. The bits from the original message are combined with the key values to obtain the encrypted message. When you combine the values, the result is 0 if both values are the same and 1 if both values are different. An example of an XOR operation is as follows:
Original message 0 1 1 0 1 1 0 0
Key 1 1 0 1 1 1 0 0
Cipher message 1 0 1 1 0 0 0 0
Steganography
Steganography occurs when a message is hidden inside another object, such as a picture, audio file, video file, or a document. In steganography, it is crucial that only those who are expecting the message know that the message exists.
A concealment cipher, discussed earlier, is one method of steganography. Another method of steganography is digital watermarking, which is a logo or trademark that is embedded in documents, pictures, or other objects. The watermarks deter people from using the materials in an unauthorized manner.
Transposition Ciphers
A transposition cipher scrambles the letters of the original message in a different order. The key determines the positions to which the letters are moved.
Figure 3-13 shows an example of a simple transposition cipher. With this example, the original message is PEARSON EDUCATION, and the key is 4231 2314. The ciphertext message is REAP ONSE AUCD IOTN. So you take the first four letters of the plaintext message (PEAR) and use the first four numbers (4231) as the key for transposition. In the new ciphertext, the letters would be REAP. Then you take the next four letters of the plaintext message (SONE) and use the next four numbers (2314) as the key for transposition. In the new ciphertext, the letters would be ONSE. Then you take the next four letters of the original message and apply the first four numbers of the key because you do not have any more numbers in the key. Continue this pattern until complete.

Figure 3-13 Transposition Example
Symmetric Algorithms
Symmetric algorithms use a private or secret key that must remain secret between the two parties. Each party pair requires a separate private key. Therefore, a single user would need a unique secret key for every user with whom they communicate.
Consider an example where there are 10 unique users. Each user needs a separate private key to communicate with the other users. To calculate the number of keys that would be needed in this example, you would use the following formula:
# of users × (# of users – 1) / 2
Using this example, you would calculate 10 × (10 – 1) / 2, or 45 needed keys.
With symmetric algorithms, the encryption key must remain secure. To obtain the secret key, the users must find a secure out-of-band method for communicating the secret key, including courier or direct physical contact between the users.
A special type of symmetric key called a session key encrypts messages between two users during one communication session.
Symmetric algorithms can be referred to as single-key, secret-key, private-key, or shared-key cryptography.
Symmetric systems provide confidentiality but not authentication or non-repudiation. If both users use the same key, determining where the message originated is impossible.
Symmetric algorithms include DES, AES, IDEA, Skipjack, Blowfish, Twofish, RC4/RC5/RC6/RC7, and CAST. All these algorithms are discussed later in this chapter.
Table 3-12 lists the strengths and weaknesses of symmetric algorithms.
Table 3-12 Symmetric Algorithm Strengths and Weaknesses
Strengths | Weaknesses |
1,000 to 10,000 times faster than asymmetric algorithms | Remembering or maintaining the number of unique keys needed can cause key management issues. |
Hard to break | Secure key distribution is critical. |
Cheaper to implement than asymmetric | Key compromise occurs if one party is compromised, thereby allowing impersonation. |
The two broad types of symmetric algorithms are stream-based ciphers and block ciphers. Initialization vectors (IVs) are an important part of block ciphers. These three components are discussed next.
Stream-Based Ciphers
Stream-based ciphers perform encryption on a bit-by-bit basis and use keystream generators. The keystream generators create a bit stream that is XORed with the plaintext bits. The result of this XOR operation is the ciphertext.
A synchronous stream-based cipher depends only on the key, and an asynchronous stream cipher depends on the key and plaintext. The key ensures that the bit stream that is XORed to the plaintext is random.
An example of a stream-based cipher is RC4, which is discussed later in this chapter.
Advantages of stream-based ciphers include the following:
Generally have lower error propagation because encryption occurs on each bit
Generally used more in hardware implementation
Use the same key for encryption and decryption
Generally cheaper to implement than block ciphers
Employ only confusion concept
Block Ciphers
Block ciphers perform encryption by breaking the message into fixed-length units, called blocks. A message of 1,024 bits could be divided into 16 blocks of 64 bits each. Each of those 16 blocks is processed by the algorithm formulas, resulting in a single block of ciphertext.
Examples of block ciphers include IDEA, Blowfish, RC5, and RC6, which are discussed later in this chapter.
Advantages of block ciphers include the following:
Implementation is easier than stream-based cipher implementation.
Generally less susceptible to security issues.
Generally used more in software implementations.
Block ciphers employ both confusion and diffusion. Block ciphers often use different modes: ECB, CBC, CFB, and CTR. These modes are discussed in detail later in this chapter.
Initialization Vectors (IVs)
The modes mentioned earlier use IVs to ensure that patterns are not produced during encryption. These IVs provide this service by using random values with the algorithms. Without using IVs, a repeated phrase within a plaintext message could result in the same ciphertext. Attackers, when they obtain IVs, can possibly use these patterns to break the encryption.
Asymmetric Algorithms
Asymmetric algorithms use both a public key and a private or secret key. The public key is known by all parties, and the private key is known only by its owner. One of these keys encrypts the message, and the other decrypts the message.
In asymmetric cryptography, determining a user’s private key is virtually impossible even if the public key is known, although both keys are mathematically related. However, if a user’s private key is discovered, the encryption system can be compromised.
Asymmetric algorithms can be referred to as dual-key or public key cryptography.
Asymmetric systems provide confidentiality, integrity, authentication, and non-repudiation. Because both users have one unique key that is part of the process, determining where the message originated is possible.
If confidentiality is the primary concern for an organization, a message should be encrypted with the receiver’s public key, which is referred to as the secure message format. If authentication is the primary concern for an organization, a message should be encrypted with the sender’s private key, which is referred to as the open message format. When the open message format is used, the message can be decrypted by anyone with the sender’s public key.
Asymmetric algorithms include Diffie-Hellman, RSA, El Gamal, ECC, Knapsack, DSA, and zero-knowledge proof. All of these algorithms are discussed later in this chapter.
Table 3-13 lists the strengths and weaknesses of asymmetric algorithms.
Table 3-13 Asymmetric Algorithm Strengths and Weaknesses
Strengths | Weaknesses |
Key distribution is easier and more manageable than with symmetric algorithms. | More expensive to implement than symmetric algorithms. |
Key management is easier because the same public key is used by all parties. | 1,000 to 10,000 times slower than symmetric algorithms. |
Hybrid Ciphers
Because both symmetric and asymmetric algorithms have weaknesses, solutions have been developed that use both types of algorithms in a hybrid cipher. By using both algorithm types, the cipher provides confidentiality, authentication, and non-repudiation.
The process for hybrid encryption is as follows:
The symmetric algorithm provides the keys used for encryption.
The symmetric keys are then passed to the asymmetric algorithm, which encrypts the symmetric keys and automatically distributes them.
The message is then encrypted with the symmetric key.
Both the message and the key are sent to the receiver.
The receiver decrypts the symmetric key and uses the symmetric key to decrypt the message.
An organization should use hybrid encryption if the parties do not have a shared secret key and large quantities of sensitive data must be transmitted.
Elliptic Curves
Elliptic curves are public key algorithms that use mathematical functions to create faster, smaller, and more efficient cryptographic keys based on the elliptic curve theory. The algebraic structure of the elliptic curves over infinite fields provides a more difficult to break mechanism.
Quantum Cryptography
Quantum cryptography, also called quantum encryption, uses quantum mechanics principles to encrypt messages. Quantum’s multiple states, coupled with its “no change theory,” are used as part of the process. Quantum cryptography requires a quantum computer, which has the immense computing power to encrypt and decrypt data. A quantum computer could quickly crack current public key (asymmetric) cryptography.
Longer keys are a good defense against quantum computers breaking public key cryptography. Another good defense is to use symmetric encryption for the messages themselves and then use asymmetric encryption just for the keys.
Symmetric Algorithms
Symmetric algorithms were explained earlier in this chapter. In the following sections, we discuss some of the most popular symmetric algorithms. Some of these might no longer be commonly used because there are more secure alternatives.
Security professionals should be familiar with the following symmetric algorithms:
DES/3DES
AES
IDEA
Skipjack
Blowfish
Twofish
RC4/RC5/RC6/RC7
CAST
DES and 3DES
Digital Encryption Standard (DES) is a symmetric encryption system created by the U.S. National Security Agency (NSA) but based on the 128-bit Lucifer algorithm by IBM. Originally, the algorithm was named Data Encryption Algorithm (DEA), and the DES acronym was used to refer to the standard. But in today’s world, DES is the more common term for both.
DES uses a 64-bit key, 8 bits of which are used for parity. Therefore, the effective key length for DES is 56 bits. DES divides the message into 64-bit blocks. Sixteen rounds of transposition and substitution are performed on each block, resulting in a 64-bit block of ciphertext.
DES has mostly been replaced by 3DES and AES (which is discussed later).
DES-X is a variant of DES that uses multiple 64-bit keys in addition to the 56-bit DES key. The first 64-bit key is XORed to the plaintext, which is then encrypted with DES. The second 64-bit key is XORed to the resulting cipher.
Double-DES, a DES version that uses a 112-bit key length, is no longer used. After it was released, a security attack occurred that reduced Double-DES security to the same level as DES.
DES Modes
DES comes in the following five modes:
In ECB, 64-bit blocks of data are processed by the algorithm using the key. The ciphertext produced can be padded to ensure that the result is a 64-bit block. If an encryption error occurs, only one block of the message is affected. ECB operations run in parallel, making it a fast method.
Although ECB is the easiest and fastest mode to use, it has security issues because every 64-bit block is encrypted with the same key. If an attacker discovers the key, all the blocks of data can be read. If an attacker discovers both versions of the 64-bit block (plaintext and ciphertext), the key can be determined. For these reasons, the mode should not be used when encrypting a large amount of data because patterns would emerge.
ECB is a good choice if an organization needs encryption for its databases because ECB works well with the encryption of short messages. Figure 3-14 shows the ECB encryption process.
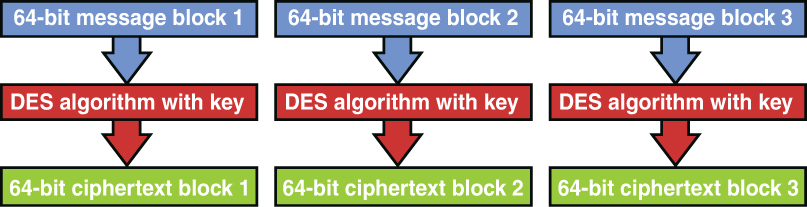
Figure 3-14 ECB Mode of DES
In CBC, each 64-bit block is chained together because each resultant 64-bit ciphertext block is applied to the next block. So plaintext message block 1 is processed by the algorithm using an IV (discussed earlier in this chapter). The resultant ciphertext message block 1 is XORed with plaintext message block 2, resulting in ciphertext message 2. This process continues until the message is complete.
Unlike ECB, CBC encrypts large files without having any patterns within the resulting ciphertext. If a unique IV is used with each message encryption, the resultant ciphertext will be different every time, even in cases where the same plaintext message is used. Figure 3-15 shows the CBC encryption process.
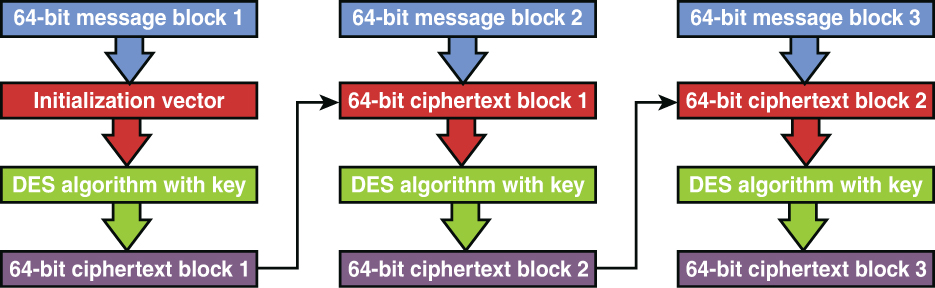
Figure 3-15 CBC Mode of DES
Whereas CBC and ECB require 64-bit blocks, CFB works with 8-bit (or smaller) blocks and uses a combination of stream ciphering and block ciphering. Like CBC, the first 8-bit block of the plaintext message is XORed by the algorithm using a keystream, which is the result of an IV and the key. The resultant ciphertext message is applied to the next plaintext message block. Figure 3-16 shows the CFB encryption process.
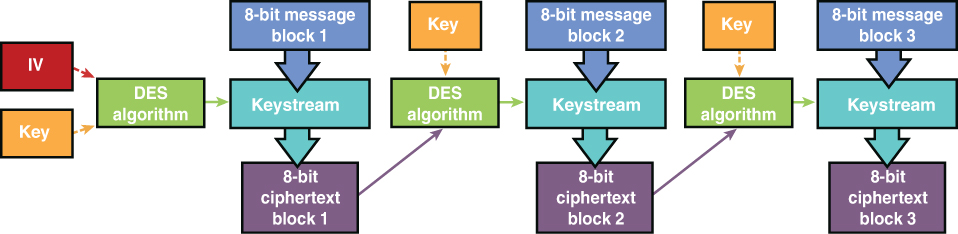
Figure 3-16 CFB Mode of DES
The size of the ciphertext block must be the same size as the plaintext block. The method that CFB uses can have issues if any ciphertext result has errors because those errors will affect any future block encryption. For this reason, CFB should not be used to encrypt data that can be affected by this problem, particularly video or voice signals. This problem led to the need for DES OFB mode.
Similar to CFB, OFB works with 8-bit (or smaller) blocks and uses a combination of stream ciphering and block ciphering. However, OFB uses the previous keystream with the key to create the next keystream. Figure 3-17 shows the OFB encryption process.
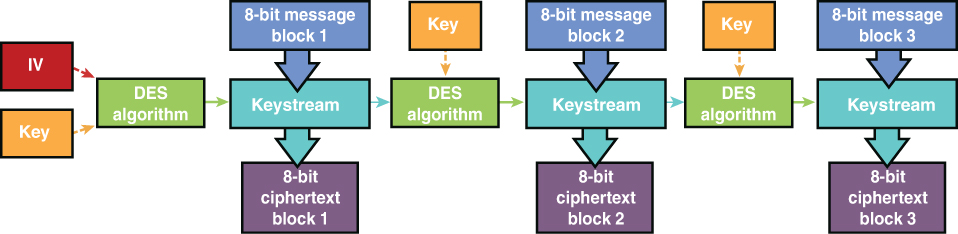
Figure 3-17 OFB Mode of DES
With OFB, the size of the keystream value must be the same size as the plaintext block. Because of the way in which OFB is implemented, OFB is less susceptible to the error type that CFB has.
CTR mode is similar to OFB mode. The main difference is that CTR mode uses an incrementing IV counter to ensure that each block is encrypted with a unique keystream. Also, the ciphertext is not chaining into the encryption process. Because this chaining does not occur, CTR performance is much better than the other modes. Figure 3-18 shows the CTR encryption process.
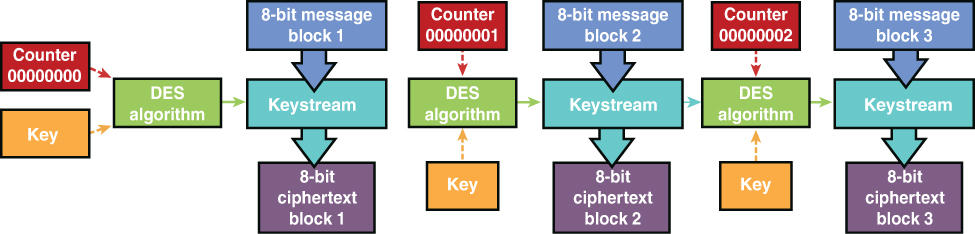
Figure 3-18 CTR Mode of DES
3DES and Modes
Because of the need to quickly replace DES, Triple DES (3DES), a version of DES that increases security by using three 56-bit keys, was developed. Although 3DES is resistant to attacks, it is up to three times slower than DES. 3DES did serve as a temporary replacement to DES. However, NIST has actually designated the Advanced Encryption Standard (AES) as the replacement for DES. Even though 3DES was an improvement over DES, modern applications should not use 3DES.
3DES comes in the following four modes:
3DES-EEE3: Each block of data is encrypted three times, each time with a different key.
3DES-EDE3: Each block of data is encrypted with the first key, decrypted with the second key, and encrypted with the third key.
3DES-EEE2: Each block of data is encrypted with the first key, encrypted with the second key, and finally encrypted again with the first key.
3DES-EDE2: Each block of data is encrypted with the first key, decrypted with the second key, and finally encrypted again with the first key.
AES
Advanced Encryption Standard (AES) is the replacement algorithm for DES. When NIST decided a new standard was needed because DES had been cracked, NIST was presented with five industry options:
IBM’s MARS
RSA Laboratories’ RC6
Anderson, Biham, and Knudsen’s Serpent
Counterpane Systems’ Twofish
Daemen and Rijmen’s Rijndael
Of these choices, NIST selected Rijndael. So although AES is considered the standard, the algorithm that is used in the AES standard is the Rijndael algorithm. The AES and Rijndael terms are often used interchangeably.
The three block sizes that are used in the Rijndael algorithm are 128, 192, and 256 bits. A 128-bit key with a 128-bit block size undergoes 10 transformation rounds. A 192-bit key with a 192-bit block size undergoes 12 transformation rounds. Finally, a 256-bit key with a 256-bit block size undergoes 14 transformation rounds.
Rijndael employs transformations composed of three layers: the nonlinear layer, key addition layer, and linear-maxing layer. The Rijndael design is very simple, and its code is compact, which allows it to be used on a variety of platforms. It is the required algorithm for sensitive but unclassified U.S. government data.
IDEA
International Data Encryption Algorithm (IDEA) is a block cipher that uses 64-bit blocks. Each 64-bit block is divided into 16 smaller blocks. IDEA uses a 128-bit key and performs eight rounds of transformations on each of the 16 smaller blocks.
IDEA is faster and harder to break than DES. However, IDEA is not as widely used as DES or AES because it was patented, and licensing fees had to be paid to IDEA’s owner, a Swiss company named Ascom. However, the patent expired in 2012. IDEA is used in PGP, which is discussed later in this chapter.
Skipjack
Skipjack is a block-cipher, symmetric algorithm developed by the U.S. NSA. It uses an 80-bit key to encrypt 64-bit blocks. This is the algorithm that is used in the Clipper chip. Algorithm details are classified.
Blowfish
Blowfish is a block cipher that uses 64-bit data blocks using anywhere from 32- to 448-bit encryption keys. Blowfish performs 16 rounds of transformation. Initially developed with the intention of serving as a replacement to DES, Blowfish is one of the few algorithms that are not patented.
Twofish
Twofish is a version of Blowfish that uses 128-bit data blocks using 128-, 192-, and 256-bit keys. It uses 16 rounds of transformation. Like Blowfish, Twofish is not patented.
RC4/RC5/RC6/RC7
A total of seven RC algorithms have been developed by Ron Rivest. RC1 was never published, RC2 was a 64-bit block cipher, and RC3 was broken before release. So the main RC implementations that a security professional needs to understand are RC4, RC5, RC6, and RC7.
RC4, also called ARC4, is one of the most popular stream ciphers. It is used in SSL and WEP (both of which are discussed in more detail in Chapter 4, “Communication and Network Security”). RC4 uses a variable key size of 40 to 2,048 bits and up to 256 rounds of transformation.
RC5 is a block cipher that uses a key size of up to 2,048 bits and up to 255 rounds of transformation. Block sizes supported are 32, 64, or 128 bits. Because of all the possible variables in RC5, the industry often uses an RC5=w/r/b designation, where w is the block size, r is the number of rounds, and b is the number of 8-bit bytes in the key. For example, RC5-64/16/16 denotes a 64-bit word (or 128-bit data blocks), 16 rounds of transformation, and a 16-byte (128-bit) key.
RC6 is a block cipher based on RC5, and it uses the same key size, rounds, and block size. RC6 was originally developed as an AES solution, but lost the contest to Rijndael. RC6 is faster than RC5.
RC7 is a block cipher based on RC6. Although it uses the same key size and rounds, it has a block size of 256 bits. In addition, it uses six working registers instead of four. As a result, it is much faster than RC6.
CAST
CAST, invented by Carlisle Adams and Stafford Tavares, has two versions: CAST-128 and CAST-256. CAST-128 is a block cipher that uses a 40- to 128-bit key that will perform 12 or 16 rounds of transformation on 64-bit blocks. CAST-256 is a block cipher that uses a 128-, 160-, 192-, 224-, or 256-bit key that will perform 48 rounds of transformation on 128-bit blocks.
Table 3-14 lists the key facts about each symmetric algorithm.
Table 3-14 Symmetric Algorithms Key Facts
Algorithm Name | Block or Stream Cipher? | Key Size | Number of Rounds | Block Size |
DES | Block | 64 bits (effective length 56 bits) | 16 | 64 bits |
3DES | Block | 56, 112, or 168 bits | 48 | 64 bits |
AES | Block | 128, 192, or 256 bits | 10, 12, or 14 (depending on block/key size) | 128, 192, or 256 bits |
IDEA | Block | 128 bits | 8 | 64 bits |
Skipjack | Block | 80 bits | 32 | 64 bits |
Blowfish | Block | 32–448 bits | 16 | 64 bits |
Twofish | Block | 128, 192, or 256 bits | 16 | 128 bits |
RC4 | Stream | 40–2,048 bits | Up to 256 | N/A |
RC5 | Block | Up to 2,048 | Up to 255 | 32, 64, or 128 bits |
RC6 | Block | Up to 2,048 | Up to 255 | 32, 64, or 128 bits |
RC7 | Block | Up to 2,048 | Up to 255 | 256 bits |
CAST-128 | Block | Up to 128 | 12–16 | 64 bits |
CAST-256 | Block | 128–256 bits | 48 | 128 bits |
Asymmetric Algorithms
Asymmetric algorithms were explained earlier in this chapter. In the following sections, we discuss some of the most popular asymmetric algorithms. Some of them might no longer be commonly used because more secure alternatives are available.
Security professionals should be familiar with the following symmetric algorithms:
Diffie-Hellman
RSA
El Gamal
ECC
Knapsack
Zero-knowledge proof
Diffie-Hellman
Diffie-Hellman is an asymmetric key agreement algorithm created by Whitfield Diffie and Martin Hellman. Diffie-Hellman is responsible for the key agreement process. The key agreement process includes the following steps:
John and Sally need to communicate over an encrypted channel and decide to use Diffie-Hellman.
John generates a private and public key, and Sally generates a private and a public key.
John and Sally share their public keys with each other.
An application on John’s computer takes John’s private key and Sally’s public key and applies the Diffie-Hellman algorithm, and an application on Sally’s computer takes Sally’s private key and John’s public key and applies the Diffie-Hellman algorithm.
Through this application, the same shared value is created for John and Sally, which in turn creates the same symmetric key on each system using the asymmetric key agreement algorithm.
Through this process, Diffie-Hellman provides secure key distribution, but not confidentiality, authentication, or non-repudiation. The key to this algorithm is dealing with discrete logarithms. Diffie-Hellman is susceptible to man-in-the-middle (or on-path) attacks unless an organization implements digital signatures or digital certificates for authentication at the beginning of the Diffie-Hellman process.
RSA
RSA is the most popular asymmetric algorithm and was invented by Ron Rivest, Adi Shamir, and Leonard Adleman. RSA can provide key exchange, encryption, and digital signatures. The strength of the RSA algorithm is the difficulty of finding the prime factors of very large numbers. RSA uses a 1,024- to 4,096-bit key and performs one round of transformation.
RSA-768 and RSA-704 have been factored. If factorization of the prime numbers used by an RSA implementation occurs, then the implementation is considered breakable and should not be used. RSA-2048 is the largest RSA number. RSA-4096 is also available and has not been broken either. While RSA-4096 is considered stronger, organizations may be unable to deploy RSA-4096 because an application may limit them to 2048.
As a key exchange protocol, RSA encrypts a DES or an AES symmetric key for secure distribution. RSA uses a one-way function to provide encryption/decryption and digital signature verification/generation. The public key works with the one-way function to perform encryption and digital signature verification. The private key works with the one-way function to perform decryption and signature generation.
In RSA, the one-way function is a trapdoor. The private key knows the one-way function. The private key is capable of determining the original prime numbers. Finally, the private key knows how to use the one-way function to decrypt the encrypted message.
Attackers can use Number Field Sieve (NFS), a factoring algorithm, to attack RSA.
El Gamal
El Gamal is an asymmetric key algorithm based on the Diffie-Hellman algorithm. Like Diffie-Hellman, El Gamal deals with discrete logarithms. However, whereas Diffie-Hellman can be used only for key agreement, El Gamal can provide key exchange, encryption, and digital signatures.
With El Gamal, any key size can be used. However, a larger key size negatively affects performance. Because El Gamal is the slowest asymmetric algorithm, using a key size of 1,024 bits or less would be wise.
ECC
Elliptic Curve Cryptosystem (ECC) provides secure key distribution, encryption, and digital signatures. The elliptic curve’s size defines the difficulty of the problem.
Although ECC can use a key of any size, it can use a much smaller key than RSA or any other asymmetric algorithm and still provide comparable security. Therefore, the primary benefit promised by ECC is a smaller key size, reducing storage and transmission requirements. ECC is more efficient and provides better security than RSA keys of the same size.
Figure 3-19 shows an elliptic curve example with the elliptic curve equation.
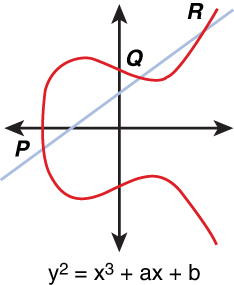
Figure 3-19 Elliptic Curve Example with Equation
Knapsack
Knapsack is a series of asymmetric algorithms that provide encryption and digital signatures. This algorithm family is no longer used due to security issues.
Zero-Knowledge Proof
A zero-knowledge proof is a technique used to ensure that only the minimum needed information is disclosed without giving all the details. An example of this technique occurs when one user encrypts data with a private key and the receiver decrypts with the originator’s public key. The originator has not given the private key to the receiver. But the originator is proving that they have their private key simply because the receiver can read the message.
Public Key Infrastructure and Digital Certificates
A public key infrastructure (PKI) includes systems, software, and communication protocols that distribute, manage, and control public key cryptography. A PKI publishes digital certificates. Because a PKI establishes trust within an environment, a PKI can certify that a public key is tied to an entity and verify that a public key is valid. Public keys are published through digital certificates.
The X.509 standard is a framework that enables authentication between networks and over the Internet. A PKI includes timestamping and certificate revocation to ensure that certificates are managed properly. A PKI provides confidentiality, message integrity, authentication, and non-repudiation.
The structure of a PKI includes certification authorities, certificates, registration authorities, certificate revocation lists, cross-certification, and the Online Certificate Status Protocol (OCSP). In the following sections, we discuss these PKI components as well as a few other PKI concepts.
Certificate Authority and Registration Authority
Any participant that requests a certificate must first go through the registration authority (RA), which verifies the requestor’s identity and registers the requestor. After the identity is verified, the RA passes the request to the certificate authority (CA).
A CA is the entity that creates and signs digital certificates, maintains the certificates, and revokes them when necessary. Every entity that wants to participate in the PKI must contact the CA and request a digital certificate. The CA is the ultimate authority for the authenticity for every participant in the PKI and signs each digital certificate. The certificate binds the identity of the participant to the public key.
There are different types of CAs. Some existing organizations provide a PKI as a payable service to companies that need them. An example is Symantec. Some organizations implement their own private CAs so that the organization can control all aspects of the PKI process. If an organization is large enough, it might need to provide a structure of CAs, with the root CA being the highest in the hierarchy.
Because more than one entity is often involved in the PKI certification process, certification path validation allows the participants to check the legitimacy of the certificates in the certification path.
Certificates
A digital certificate provides an entity, usually a user, with the credentials to prove its identity and associates that identity with a public key. At a minimum, a digital certificate must provide the serial number, the issuer, the subject (owner), and the public key.
An X.509 certificate complies with the X.509 standard. An X.509 certificate contains the following fields:
Version
Serial Number
Algorithm ID
Issuer
Validity
Subject
Subject Public Key Info
Public Key Algorithm
Subject Public Key
Issuer Unique Identifier (optional)
Subject Unique Identifier (optional)
Extensions (optional)
Symantec first introduced the following digital certificate classes:
Class 1: For individuals; used to protect email. These certificates get saved by web browsers.
Class 2: For organizations that must provide proof of identity.
Class 3: For servers and software signing in which independent verification and identity and authority checking are done by the issuing CA.
Certificate Life Cycle
Security professionals should understand the certificate life cycle. According to Microsoft, the certificate life cycle includes the following events:
CAs are installed, and the CA certificates are issued.
Certificates are issued by CAs to entities.
Certificates are revoked (as necessary), renewed, or allowed to expire.
The CAs’ certificates are renewed before they expire, are revoked, or retired.
NIST Interagency Report (NISTIR) 7924, titled “Reference Certificate Policy,” identifies a baseline set of security controls and practices to support the secure issuance of certificates. This report is in its second draft and can be found at https://csrc.nist.gov/CSRC/media/Publications/nistir/7924/draft/documents/nistir_7924_2nd_draft.pdf.
According to NISTIR 7924, the certificate application process must provide sufficient information to
Establish the applicant’s authorization (by the employing or sponsoring organization) to obtain a certificate.
Establish and record the identity of the applicant.
Obtain the applicant’s public key and verify the applicant’s possession of the private key for each certificate required.
Verify any role or authorization information requested for inclusion in the certificate.
In this document, the steps of the certificate process are as follows:
Certificate application
Certificate application processing
Certificate issuance
Certificate acceptance
Key pair and certificate usage
Certificate renewal
Certificate re-key
Certificate modification
Certificate revocation and suspension
End of subscription
Key escrow and recovery
These steps may be performed in any order that is convenient for the CA and applicants that does not compromise security, but all must be completed before certificate issuance.
For the CISSP exam, you should know the four main steps that involve how a certificate is issued to an entity: enrollment, verification, revocation, and renewal and modification.
Enrollment
Enrollment is the process of requesting a certificate from the CA. According to NISTIR 7924, a certificate application shall be submitted to the CA by the subscriber, an authorized organizational representative (AOR), or an RA on behalf of the subscriber. Multiple certificate requests from one RA or AOR may be submitted as a batch.
When a subscriber is enrolled, all communications among PKI authorities supporting the certificate application and issuance process will be authenticated and protected from modification; any electronic transmission of shared secrets and personally identifiable information will be protected. Communications may be electronic or out-of-band. Where electronic communications are used, cryptographic mechanisms commensurate with the strength of the public/private key pair will be used. Out-of-band communications will protect the confidentiality and integrity of the data.
Verification
Verification is the process whereby an application verifies that a certificate is valid. Applications use two types of verification methods to check the validity of a digital certificate: certificate revocation lists (CRLs) and Online Certificate Status Protocol (OCSP), both of which are discussed in the sections that follow.
To issue a certificate, the CA must verify that the identity and authorization of the applicant have been verified. If this information cannot be verified, upon receiving the request, the CAs/RAs will
Verify the identity of the requester.
Verify the authority of the requester and the integrity of the information in the certificate request.
Build and sign a certificate if all certificate requirements have been met (in the case of an RA, have the CA sign the certificate).
Make the certificate available to the subscriber after confirming that the subscriber has formally acknowledged their obligations.
The certificate request may already contain a to-be-signed certificate built by either the RA or the subscriber. This certificate will not be signed until all verifications and modifications, if any, have been completed to the CA’s satisfaction. All authorization and other attribute information received from a prospective subscriber will be verified before inclusion in a certificate. Failure to object to the certificate or its contents will constitute acceptance of the certificate.
Revocation
Revocation is the process whereby a certificate is revoked. CAs operating under NISTIR 7924 will make public a description of how to obtain revocation information for the certificates they publish, and an explanation of the consequences of using dated revocation information. This information will be given to subscribers during certificate request or issuance, and will be readily available to any potential relying party. Revocation requests must be authenticated.
A certificate will be revoked when the binding between the subject and the subject’s public key defined within the certificate is no longer considered valid. When this situation occurs, the associated certificate will be revoked and placed on the CRL and/or added to the OCSP responder. (Both CRL and OCSP are explained in the following sections.) Revoked certificates will be included on all new publications of the certificate status information until the certificates expire.
CAs should revoke certificates as quickly as practical upon receipt of a proper revocation request and by the requested revocation time.
Renewal and Modification
Any certificate may be renewed if the public key has not reached the end of its validity period, the associated private key has not been revoked or compromised, and the Subscriber name and attributes are unchanged. In addition, the validity period of the certificate must not exceed the remaining lifetime of the private key.
CA certificates and OCSP responder certificates may be renewed as long as the aggregated lifetime of the public key does not exceed the certificate lifetime. The CA may renew previously issued certificates during recovery from CA key compromise without subject request or approval as long as the CA is confident of the accuracy of information to be included in the certificates.
A CA may perform certificate modification for a subscriber whose characteristics have changed (e.g., name change due to marriage). If the subscriber name has changed, the subscriber will undergo the initial registration process.
Certificate Revocation List
A certificate revocation list (CRL) is a list of digital certificates that a CA has irreversibly revoked. To find out whether a digital certificate has been revoked, the browser must either check the CRL or receive the CRL values pushed out from the CA. This process can become quite daunting when you consider that the CRL contains every certificate that has ever been revoked.
One concept to keep in mind is the revocation request grace period. This period is the maximum amount of time between when the revocation request is received by the CA and when the revocation actually occurs. A shorter revocation period provides better security but often results in a higher implementation cost.
OCSP
Online Certificate Status Protocol (OCSP) is an Internet protocol that obtains the revocation status of an X.509 digital certificate. OCSP is an alternative to the standard CRL that is used by many PKIs. OCSP automatically validates the certificates and reports back the status of the digital certificate by accessing the CRL on the CA.
PKI Steps
The steps involved in requesting a digital certificate are as follows:
A user requests a digital certificate, and the RA receives the request.
The RA requests identifying information from the requestor.
After the required information is received, the RA forwards the certificate request to the CA.
The CA creates a digital certificate for the requestor. The requestor’s public key and identity information are included as part of the certificate.
The user receives the certificate.
After the user has a certificate, that user is considered a trusted entity and is ready to communicate with other trusted entities. The process for communication between entities is as follows:
User 1 requests User 2’s public key from the certificate repository.
The repository sends User 2’s digital certificate to User 1.
User 1 verifies the certificate and extracts User 2’s public key.
User 1 encrypts the session key with User 2’s public key and sends the encrypted session key and User 1’s certificate to User 2.
User 2 receives User 1’s certificate and verifies the certificate with a trusted CA.
After this certificate exchange and verification process occurs, the two entities are able to communicate using encryption.
Cross-Certification
Cross-certification establishes trust relationships between CAs so that the participating CAs can rely on the other participants’ digital certificates and public keys. It enables users to validate each other’s certificates when they are actually certified under different certification hierarchies. A CA for one organization can validate digital certificates from another organization’s CA when a cross-certification trust relationship exists.
Key Management Practices
A discussion of cryptography would be incomplete without coverage of key management practices. NIST SP 800-57 contains recommendations for key management in three parts:
Part 1: This publication covers general recommendations for key management.
Part 2: This publication covers the best practices for a key management organization.
Part 3: This publication covers the application-specific key management guidance.
Security professionals should at least understand the key management principles in Part 1 of SP 800-57 Revision 1. If security professionals are involved in organizations that provide key management services to other organizations, understanding Part 2 is a necessity. Part 3 is needed when an organization implements applications that use keys. In this section, we cover the recommendations in Part 1.
Part 1 defines the different types of keys. The keys are identified according to their classification as public, private, or symmetric keys, as well as according to their use. For public and private key agreement keys, status as static or ephemeral keys is also specified.
In general, a single key is used for only one purpose (e.g., encryption, integrity, authentication, key wrapping, random bit generation, or digital signatures). A cryptoperiod is the time span during which a specific key is authorized for use by legitimate entities, or the time that the keys for a given system will remain in effect. Among the factors affecting the length of a cryptoperiod are
The cryptographic strength (e.g., the algorithm, key length, block size, and mode of operation)
The embodiment of the mechanisms (e.g., a FIPS 140 Level 4 implementation or a software implementation on a personal computer)
The operating environment (e.g., a secure limited-access facility, open office environment, or publicly accessible terminal)
The volume of information flow or the number of transactions
The security life of the data
The security function (e.g., data encryption, digital signature, key derivation, or key protection)
The rekeying method (e.g., keyboard entry, rekeying using a key loading device where humans have no direct access to key information, or remote rekeying within a PKI)
The key update or key-derivation process
The number of nodes in a network that share a common key
The number of copies of a key and the distribution of those copies
Personnel turnover (e.g., CA system personnel)
The threat to the information from adversaries (e.g., from whom the information is protected and their perceived technical capabilities and financial resources to mount an attack)
The threat to the information from new and disruptive technologies (e.g., quantum computers)
A key is used differently, depending on its state in the key’s life cycle. Key states are defined from a system point of view, as opposed to the point of view of a single cryptographic module. The states that an operational or backed-up key may assume are as follows:
Pre-activation state: The key has been generated but has not been authorized for use. In this state, the key may be used to perform only proof-of-possession or key confirmation.
Active state: The key may be used to cryptographically protect information (e.g., encrypt plaintext or generate a digital signature), to cryptographically process previously protected information (e.g., decrypt ciphertext or verify a digital signature), or both. When a key is active, it may be designated for protection only, processing only, or both protection and processing, depending on its type.
Suspended state: The use of a key or key pair may be suspended for several possible reasons; in the case of asymmetric key pairs, both the public and private keys are suspended at the same time. One reason for a suspension might be a possible key compromise, and the suspension has been issued to allow time to investigate the situation. Another reason might be that the entity that owns a digital signature key pair is not available (e.g., is on an extended leave of absence); signatures purportedly signed during the suspension time would be invalid. A suspended key or key pair may be restored to an active state at a later time or may be deactivated or destroyed, or may transition to the compromised state.
Deactivated state: Keys in the deactivated state are not used to apply cryptographic protection, but in some cases, they may be used to process cryptographically protected information. If a key has been revoked (for reasons other than a compromise), then the key may continue to be used for processing. Note that keys retrieved from an archive can be considered to be in the deactivated state unless they are compromised.
Compromised state: Generally, keys are compromised when they are released to or determined by an unauthorized entity. A compromised key shall not be used to apply cryptographic protection to information. However, in some cases, a compromised key or a public key that corresponds to a compromised private key of a key pair may be used to process cryptographically protected information. For example, a signature may be verified to determine the integrity of signed data if its signature has been physically protected since a time before the compromise occurred. This processing shall be done only under very highly controlled conditions, where the users of the information are fully aware of the possible consequences.
Destroyed state: The key has been destroyed as specified in the destroyed phase, discussed shortly. Even though the key no longer exists when in this state, certain key metadata (e.g., key state transition history, key name, type, cryptoperiod) may be retained.
The cryptographic key management life cycle can be divided into the following four phases:
Pre-operational phase: The keying material is not yet available for normal cryptographic operations. Keys may not yet be generated or are in the pre-activation state. System or enterprise attributes are also established during this phase. During this phase, the following functions occur:
User registration
System initialization
User initialization
Key establishment
Key registration
Operational phase: The keying material is available and in normal use. Keys are in the active or suspended state. Keys in the active state may be designated as protect only, process only, or protect and process; keys in the suspended state can be used for processing only. During this phase, the following functions occur:
Normal operational storage
Continuity of operations
Key change
Key derivation
Post-operational phase: The keying material is no longer in normal use, but access to the keying material is possible, and the keying material may be used for processing only in certain circumstances. Keys are in the deactivated or compromised states. Keys in the post-operational phase may be in an archive when not processing data. During this phase the following functions occur:
Archive storage and key recovery
Entity (user or device) deregistration
Key deregistration
Key destruction
Key revocation
Destroyed phase: Keys are no longer available. Records of their existence may or may not have been deleted. Keys are in the destroyed states. Although the keys themselves are destroyed, the key metadata (e.g., key name, type, cryptoperiod, usage period) may be retained.
Systems that process valuable information require controls in order to protect the information from unauthorized disclosure and modification. Cryptographic systems that contain keys and other cryptographic information are especially critical. Security professionals should work to ensure that the protection of keying material provides accountability, audit, and survivability.
Accountability involves the identification of entities and the work they perform (via logs) that have access to, or control of, cryptographic keys throughout their life cycles. Accountability can be an effective tool to help prevent key compromises and to reduce the impact of compromises when they are detected. Although it is preferred that no humans be able to view keys, as a minimum, the key management system should account for all individuals who are able to view plaintext cryptographic keys. In addition, more sophisticated key management systems may account for all individuals authorized to access or control any cryptographic keys, whether in plaintext or ciphertext form.
Two types of audits should be performed on key management systems:
Security: The security plan and the procedures that are developed to support the plan should be periodically audited to ensure that they continue to support the key management policy.
Protective: The protective mechanisms employed should be periodically reassessed with respect to the level of security they currently provide and are expected to provide in the future. They should also be assessed to determine whether the mechanisms correctly and effectively support the appropriate policies. New technology developments and attacks should be considered as part of a protective audit.
Key management survivability entails backing up or archiving copies of all keys used. Key backup and recovery procedures must be established to ensure that keys are not lost. System redundancy and contingency planning should also be properly assessed to ensure that all the systems involved in key management are fault tolerant.
Message Integrity
Integrity is one of the three basic tenets of security. Message integrity ensures that a message has not been altered by using parity bits, cyclic redundancy checks (CRCs), or checksums.
The parity bit method adds an extra bit to the data. The parity bit simply indicates the number of 1s in a digital bit stream. Parity is either odd or even parity. The parity bit is set before the data is transmitted. When the data arrives, the parity bit is checked against the other data. If the parity bit doesn’t match the data sent, then an error is sent to the originator.
The CRC method uses polynomial division to determine the CRC value for a file. The CRC value is usually 16 or 32 bits long. Because CRC is very accurate, the CRC value will not match up if a single bit is incorrect.
The checksum method adds up the bytes of data being sent and then transmits that number to be checked later using the same method. The source adds up the values of the bytes and sends the data and its checksum. The receiving end receives the information, adds up the bytes in the same way the source did, and gets the checksum. The receiver then compares their checksum with the source’s checksum. If the values match, message integrity is intact. If the values do not match, the data should be re-sent or replaced. Checksums are also referred to as hash sums because they typically use hash functions for the computation.
Message integrity is provided by hash functions and message authentication code.
Hashing
Hash functions were explained earlier in this chapter. In the following sections, we discuss some of the most popular hash functions. Some of them might no longer be commonly used because more secure alternatives are available.
Security professionals should be familiar with the following hash functions:
One-way hash
MD2/MD4/MD5/MD6
SHA/SHA-2/SHA-3
HAVAL
RIPEMD-160
Tiger
One-Way Hash
A hash function takes a message of variable length and produces a fixed-length hash value. Hash values, also referred to as message digests, are calculated using the original message. If the receiver calculates a hash value that is the same, then the original message is intact. If the receiver calculates a hash value that is different, then the original message has been altered.
Using a given function H, the following equation must be true to ensure that the original message, M1, has not been altered or replaced with a new message, M2:
H(M1) < > H(M2)
For a one-way hash to be effective, creating two different messages with the same hash value must be mathematically impossible. Given a hash value, discovering the original message from which the hash value was obtained must be mathematically impossible. A one-way hash algorithm is collision free if it provides protection against creating the same hash value from different messages.
Unlike symmetric and asymmetric algorithms, the hashing algorithm is publicly known. Hash functions are always performed in one direction. Using it in reverse is unnecessary.
However, one-way hash functions do have limitations. If an attacker intercepts a message that contains a hash value, the attacker can alter the original message to create a second invalid message with a new hash value. If the attacker then sends the second invalid message to the intended recipient, the intended recipient will have no way of knowing that they received an incorrect message. When the receiver performs a hash value calculation, the invalid message will look valid because the invalid message was appended with the attacker’s new hash value, not the original message’s hash value. To prevent this from occurring, the sender should use message authentication code (MAC).
Encrypting the hash function with a symmetric key algorithm generates a keyed MAC. The symmetric key does not encrypt the original message. It is used only to protect the hash value.
Figure 3-20 illustrates the basic steps of a hash function.

Figure 3-20 Hash Function Process
MD2/MD4/MD5/MD6
The MD2 message digest algorithm produces a 128-bit hash value. It performs 18 rounds of computations. Although MD2 is still in use today, it is much slower than MD4, MD5, and MD6.
The MD4 algorithm also produces a 128-bit hash value. However, it performs only three rounds of computations. Although MD4 is faster than MD2, its use has significantly declined because attacks against it have been so successful.
Like the other MD algorithms, the MD5 algorithm produces a 128-bit hash value. It performs four rounds of computations. It was originally created because of the issues with MD4, and it is more complex than MD4. However, MD5 is not collision free. For this reason, it should not be used for SSL certificates or digital signatures. The U.S. government requires the usage of SHA-2 instead of MD5. However, in commercial usage, many software vendors publish the MD5 hash value when they release software patches so customers can verify the software’s integrity after download.
The MD6 algorithm produces a variable hash value, performing a variable number of computations. Although it was originally introduced as a candidate for SHA-3, it was withdrawn because of early issues the algorithm had with differential attacks. MD6 has since been re-released with this issue fixed. However, that release was too late to be accepted as the NIST SHA-3 standard.
SHA/SHA-2/SHA-3
Secure Hash Algorithm (SHA) is a family of four algorithms published by the U.S. NIST. SHA-0, originally referred to as simply SHA because there were no other “family members,” produces a 160-bit hash value after performing 80 rounds of computations on 512-bit blocks. SHA-0 was never very popular because collisions were discovered.
Like SHA-0, SHA-1 produces a 160-bit hash value after performing 80 rounds of computations on 512-bit blocks. SHA-1 corrected the flaw in SHA-0 that made it susceptible to attacks.
SHA-2 is actually a family of hash functions, each of which provides different functional limits. The SHA-2 family is as follows:
SHA-224: Produces a 224-bit hash value after performing 64 rounds of computations on 512-bit blocks.
SHA-256: Produces a 256-bit hash value after performing 64 rounds of computations on 512-bit blocks.
SHA-384: Produces a 384-bit hash value after performing 80 rounds of computations on 1,024-bit blocks.
SHA-512: Produces a 512-bit hash value after performing 80 rounds of computations on 1,024-bit blocks.
SHA-512/224: Produces a 224-bit hash value after performing 80 rounds of computations on 1,024-bit blocks. The 512 designation here indicates the internal state size.
SHA-512/256: Produces a 256-bit hash value after performing 80 rounds of computations on 1,024-bit blocks. Once again, the 512 designation indicates the internal state size.
SHA-3, like SHA-2, is a family of hash functions. SHA-2 has not yet been broken. The hash value sizes for SHA-3 range from 224 to 512 bits. The block sizes range from 576 to 1,152 bits. SHA-3 performs 120 rounds of computations, by default.
Keep in mind that SHA-1 and SHA-2 are still widely used today. SHA-3 was not developed because of some security flaw with the two previous standards but was instead proposed as an alternative hash function to the others.
HAVAL
HAVAL is a one-way function that produces variable-length hash values, including 128 bits, 160 bits, 192 bits, 224 bits, and 256 bits, and uses 1,024-bit blocks. The number of rounds of computations can be three, four, or five. Collision issues have been discovered if producing a 128-bit hash value with three rounds of computations.
RIPEMD-160
Although several variations of the RIPEMD hash function exist, security professionals should only worry about RIPEMD-160 for exam purposes. RIPEMD-160 produces a 160-bit hash value after performing 160 rounds of computations on 512-bit blocks.
Tiger
Tiger is a hash function that produces 128-, 160-, or 192-bit hash values after performing 24 rounds of computations on 512-bit blocks, with the most popular version being the one that produces 192-bit hash values. Unlike MD5, RIPEMD, SHA-0, and SHA-1, Tiger is not built on the MD4 architecture.
Message Authentication Code
MAC was explained earlier in this chapter. Here, we discuss the three types of MACs with which security professionals should be familiar:
HMAC
CBC-MAC
CMAC
HMAC
A hash MAC (HMAC) is a keyed-hash MAC that involves a hash function with symmetric key. HMAC provides data integrity and authentication. Any of the previously listed hash functions can be used with HMAC, with the HMAC name being appended with the hash function name, as in HMAC-SHA-1. The strength of HMAC depends on the strength of the hash function, including the hash value size and the key size.
HMAC’s hash value output size will be the same as the underlying hash function. HMAC can help to reduce the collision rate of the hash function.
The basic steps of an HMAC process are as follows:
The sender and receiver agree on which symmetric key to use.
The sender joins the symmetric key to the message.
The sender applies a hash algorithm to the message and obtains a hash value.
The sender adds a hash value to the original message, and the sender sends the new message to the receiver.
The receiver receives the message and joins the symmetric key to the message.
The receiver applies the hash algorithm to the message and obtains a hash value.
If the hash values are the same, the message has not been altered. If the hash values are different, the message has been altered.
CBC-MAC
Cipher Block Chaining MAC (CBC-MAC) is a block-cipher MAC that operates in CBC mode. CBC-MAC provides data integrity and authentication.
The basic steps of a CBC-MAC process are as follows:
The sender and receiver agree on which symmetric block cipher to use.
The sender encrypts the message with the symmetric block cipher in CBC mode. The last block is the MAC.
The sender adds the MAC to the original message, and the sender sends the new message to the receiver.
The receiver receives the message and encrypts the message with the symmetric block cipher in CBC mode.
The receiver obtains the MAC and compares it to the sender’s MAC.
If the values are the same, the message has not been altered. If the values are different, the message has been altered.
CMAC
Cipher-Based MAC (CMAC) operates in the same manner as CBC-MAC but with much better mathematical functions. CMAC addresses some security issues with CBC-MAC and is approved to work with AES and 3DES.
Salting
Lookup tables and rainbow tables work because each password is hashed exactly the same way. If two users have the same password, they have the same hashed password if random hashes are not used. To prevent attack, security professionals should ensure that each hash is randomized. Then, when the same password is hashed twice, the hashes are not the same.
Salting means randomly adding data to a one-way function that “hashes” a password or passphrase. The primary function of salting is to defend against dictionary attacks versus a list of password hashes and against precomputed rainbow table attacks.
A security professional should randomize the hashes by appending or prepending a random string, called a salt, to the password before hashing. To check whether a password is correct, the attacker needs to know the value of the salt added. The salt usually can be stored in the user account database, or another secure location, along with the hash, or as part of the hash string itself.
Attackers do not know in advance what the salt will be, so they cannot precompute a lookup table or rainbow table. If each user’s password is hashed with a different salt, a reverse lookup table attack doesn’t work either.
If salts are used, security professionals must ensure that they are not reused and are not too short. A new random salt must be generated each time an administrator creates a user account or a user changes their password. A good rule of thumb is to use a salt that is the same size as the output of the hash function. For example, the output of SHA-256 is 256 bits (32 bytes), so the salt should be at least 32 random bytes.
Salts should be generated using a cryptographically secure pseudo-random number generator (CSPRNG). As the name suggests, a CSPRNG is designed to provide a high level of randomness and is completely unpredictable.
Digital Signatures and Non-repudiation
A digital signature is a hash value encrypted with the sender’s private key. A digital signature provides authentication, non-repudiation, and integrity. A blind signature is a form of digital signature where the contents of the message are masked before it is signed.
Public key cryptography, which is discussed later, is used to create digital signatures. Users register their public keys with a CA, which distributes a certificate containing the user’s public key and the CA’s digital signature. The digital signature is computed by the user’s public key and validity period being combined with the certificate issuer and digital signature algorithm identifier.
When considering cryptography, keep the following facts in mind:
Encryption provides confidentiality.
Hashing provides integrity.
Digital signatures provide authentication, non-repudiation, and integrity.
DSS
The Digital Signature Standard (DSS) is a federal digital security standard that governs the Digital Security Algorithm (DSA). DSA generates a message digest of 160 bits. The U.S. federal government requires the use of DSA, RSA (discussed earlier in this chapter), or Elliptic Curve DSA (ECDSA) and SHA for digital signatures. DSA is slower than RSA and provides only digital signatures. RSA provides digital signatures, encryption, and secure symmetric key distribution.
Non-repudiation
Non-repudiation occurs when a sender is provided with proof of delivery to a receiver, and a receiver is provided with proof of the sender’s identity. If non-repudiation is implemented correctly, the sender cannot later deny having sent the information.
In addition to digital signatures, non-repudiation is also used in digital contracts and email. Email non-repudiation involves methods such as email tracking.
Applied Cryptography
Encryption can provide different protection based on which level of communication is being used. The two types of encryption communication levels are link encryption and end-to-end encryption. In addition, cryptography is used for email and Internet security. These topics are discussed in detail in the “Communications Cryptography” section in Chapter 4.
Link Encryption Versus End-to-End Encryption
Link encryption encrypts all the data that is transmitted over a link. End-to-end encryption encrypts less of the packet information than link encryption.
Email Security
Email security methods include the PGP, MIME, and S/MIME email standards that are popular in today’s world.
Internet Security
Internet security includes remote access; SSL/TLS; HTTP, HTTPS, and S-HTTP; SET; cookies; SSH; and IPsec and ISAKMP.
Cryptanalytic Attacks
Cryptography attacks are categorized as either passive or active attacks. A passive attack is usually implemented just to discover information and is much harder to detect because it is usually carried out by eavesdropping or packet sniffing. Active attacks involve an attacker actually carrying out steps, like message alteration or file modification. Cryptography is usually attacked by exploiting the key, algorithm, execution, data, or people. But most of these attacks are attempting to discover the key used.
Cryptography attacks that are discussed include the following:
Ciphertext-only attack
Known plaintext attack
Chosen plaintext attack
Chosen ciphertext attack
Social engineering
Brute force
Differential cryptanalysis
Linear cryptanalysis
Algebraic attack
Frequency analysis
Birthday attack
Dictionary attack
Replay attack
Analytic attack
Statistical attack
Factoring attack
Reverse engineering
Meet-in-the-middle attack
Ransomware attack
Side-channel attack
Implementation attack
Fault injection
Timing attack
Pass-the-hash attack
Ciphertext-Only Attack
In a ciphertext-only attack, an attacker uses several encrypted messages (ciphertext) to figure out the key used in the encryption process. Although it is a very common type of attack, it is usually not successful because so little is known about the encryption used.
Known Plaintext Attack
In a known plaintext attack, an attacker uses various plaintext and ciphertext versions of a message or more messages to discover the key used. This type of attack implements reverse engineering, frequency analysis, or brute force to determine the key so that all messages can be deciphered.
Chosen Plaintext Attack
In a chosen plaintext attack, an attacker chooses the plaintext to get encrypted to obtain the ciphertext. The attacker sends a message hoping that the user will forward that message as ciphertext to another user. The attacker captures the ciphertext version of the message and tries to determine the key by comparing the plaintext version that was originated with the captured ciphertext version. Once again, key discovery is the goal of this attack.
Chosen Ciphertext Attack
A chosen ciphertext attack is the opposite of a chosen plaintext attack. In a chosen ciphertext attack, an attacker chooses the ciphertext to be decrypted to obtain the plaintext. This attack is more difficult because control of the system that implements the algorithm is needed.
Social Engineering
Social engineering attacks against cryptographic algorithms do not differ greatly from social engineering attacks against any other security area. Attackers attempt to trick users into giving the attacker the cryptographic key used. Common social engineering methods include intimidation, enticement, or inducement.
Brute Force
As with a brute-force attack against passwords, a brute-force attack executed against a cryptographic algorithm uses all possible keys until a key is discovered that successfully decrypts the ciphertext. This attack requires considerable time and processing power and is very difficult to complete.
Differential Cryptanalysis
Differential cryptanalysis measures the execution times and power required by the cryptographic device. The measurements help to detect the key and algorithm used.
Linear Cryptanalysis
Linear cryptanalysis is a known plaintext attack that uses linear approximation, which describes the behavior of the block cipher. An attacker is more successful with this type of attack when more plaintext and matching ciphertext messages are obtained.
Algebraic Attack
Algebraic attacks rely on the algebra used by cryptographic algorithms. If an attacker exploits known vulnerabilities of the algebra used, looking for those vulnerabilities can help the attacker to determine the key and algorithm used.
Frequency Analysis
Frequency analysis is an attack that relies on the fact that substitution and transposition ciphers will result in repeated patterns in ciphertext. Recognizing the patterns of 8 bits and counting them can allow an attacker to use reverse substitution to obtain the plaintext message.
Frequency analysis usually involves the creation of a chart that lists all the letters of the alphabet alongside the number of times that letter occurs. So if the letter Q in the frequency lists has the highest value, a good possibility exists that this letter is actually E in the plaintext message because E is the most used letter in the English language. The ciphertext letter is then replaced in the ciphertext with the plaintext letter.
Today’s algorithms are considered too complex to be susceptible to this type of attack.
Birthday Attack
A birthday attack uses the premise that finding two messages that result in the same hash value is easier than matching a message and its hash value. Most hash algorithms can resist simple birthday attacks.
Dictionary Attack
Similar to a brute-force attack, a dictionary attack uses all the words in a dictionary until a key is discovered that successfully decrypts the ciphertext. This attack requires considerable time and processing power and is very difficult to complete. It also requires a comprehensive dictionary of words.
Replay Attack
In a replay attack, an attacker sends the same data repeatedly in an attempt to trick the receiving device. This data is most commonly authentication information. The best countermeasures against this type of attack are timestamps and sequence numbers.
Analytic Attack
In analytic attacks, attackers use known structural weaknesses or flaws to determine the algorithm used. If a particular weakness or flaw can be exploited, then the possibility of a particular algorithm being used is more likely.
Statistical Attack
Whereas analytic attacks look for structural weaknesses or flaws, statistical attacks use known statistical weaknesses of an algorithm to aid in the attack.
Factoring Attack
A factoring attack is carried out against the RSA algorithm by using the solutions of factoring large numbers.
Reverse Engineering
One of the most popular cryptographic attacks, reverse engineering occurs when an attacker purchases a particular cryptographic product to attempt to reverse engineer the product to discover any information about the cryptographic algorithm used, whether the information is the key or the algorithm itself.
Meet-in-the-Middle Attack
In a meet-in-the middle attack, an attacker tries to break the algorithm by encrypting from one end and decrypting from the other to determine the mathematical problem used.
Ransomware Attack
In a ransomware attack, a user accidentally installs a program that allows an attacker to encrypt files or folders on the user’s computer. To obtain access to the files and folders that are encrypted, the victim must pay a fine to obtain access to their data. Two of the more recent variants of this type of attack are the CryptoLocker, which targeted Windows computers and infected email attachments using a Trojan, and WannaCry, which also targeted Windows computers and demanded payment in Bitcoin.
Side-Channel Attack
In a side-channel attack, information from the implementation of a computer system is obtained, rather than exploiting a weakness in the algorithm itself. Areas that are exploited include the computer’s cache, timing, acoustics, and data remanence. It usually involves monitoring communication within the different components of the computer to determine the secret key.
Implementation Attack
An implementation attack, a specific type of side-channel attack, exploits implementation weaknesses in algorithms, focusing on software code, errors, and other flaws. This type of attack can be carried out in a physical or logical manner. Physical attacks target physical leakage of a device, meaning the attacker attempts to obtain the data from the hard drive or the hard drive itself. Logical attacks try to observe some parameters of the algorithm.
Fault Injection
Fault injection attacks, which are a type of side-channel attack, are carried out on crypto-devices. A single fault injected during encryption can reveal the cipher's secret key. Fault injection attacks on crypto-devices include power supply voltage variations, clock signal irregularity injections, electro-magnetics disturbances, overheating, and light exposure.
Timing Attack
A timing attack is a type of side-channel attack wherein an attacker attempts to compromise an algorithm by analyzing the time taken to encrypt or decrypt data. Timing attacks are easier to carry out if the attacker knows hardware implementation details and the cryptographic system used.
Pass-the-Hash Attack
A pass-the-hash attack allows an attacker to authenticate to a remote server or service by using the underlying hash of a user’s password, instead of the plaintext password itself. This attack requires that an attacker steal the password’s hash, rather than the plaintext password, and use it for authentication.
Digital Rights Management
Digital rights management (DRM) is covered in Chapter 1. For security architecture and engineering, security professionals must ensure that organizations employ DRM policies and procedures to protect intellectual property, including documents, music, movies, video games, and e-books.
Today’s DRM implementations include the following:
Directories:
Lightweight Directory Access Protocol (LDAP)
Active Directory (AD)
Custom
Permissions:
Open
Print
Modify
Clipboard
Additional controls:
Expiration (absolute, relative, immediate revocation)
Version control
Change policy on existing documents
Watermarking
Online/offline
Auditing
Ad hoc and structured processes:
User initiated on desktop
Mapped to system
Built into workflow process
Document DRM
Organizations implement DRM to protect confidential or sensitive documents and data. Commercial DRM products allow organizations to protect documents and include the capability to restrict and audit access to documents. Some of the permissions that can be restricted using DRM products include reading and modifying a file, removing and adding watermarks, downloading and saving a file, printing a file, or even taking screenshots. If a DRM product is implemented, the organization should ensure that the administrator is properly trained and that policies are in place to ensure that rights are appropriately granted and revoked.
Music DRM
DRM has been used in the music industry for some time now. Subscription-based music services, such as Napster, use DRM to revoke a user’s access to downloaded music after their subscription expires. Although technology companies have petitioned the music industry to allow them to sell music without DRMs, the industry has been reluctant to do so.
Movie DRM
Although the movie industry has used a variety of DRM schemes over the years, two main technologies are used for the mass distribution of media:
Content Scrambling System (CSS): Uses encryption to enforce playback and region restrictions on DVDs. This system can be broken using Linux’s DeCSS tool.
Advanced Access Content System (AACS): Protects Blu-ray and HD DVD content. Hackers have been able to obtain the encryption keys to this system.
This industry continues to make advances to prevent hackers from creating unencrypted copies of copyrighted material.
Video Game DRM
Most video game DRM implementations rely on proprietary consoles that use Internet connections to verify video game licenses. Most consoles today verify the license upon installation and allow unrestricted use from that point. However, to obtain updates, the license will again be verified prior to download and installation of the update.
E-book DRM
E-book DRM is considered to be the most successful DRM deployment. Both Amazon’s Kindle and Barnes and Noble’s Nook devices implement DRM to protect electronic forms of books. Both of these companies have released mobile apps that function like the physical e-book devices.
Today’s implementation uses a decryption key that is installed on the device. This means that the e-books cannot be easily copied between e-book devices or applications. Adobe created the Adobe Digital Experience Protection Technology (ADEPT) that is used by most e-book readers except Amazon’s Kindle. With ADEPT, AES is used to encrypt the media content, and RSA encrypts the AES key.
Site and Facility Design
For many forward-thinking organizations, physical security considerations begin during physical site selection and design, such as a building and location. These companies have learned that building in security is easier than patching the security after the fact. In the following sections, we cover physical site selection and site building practices that can lead to increased physical security.
Layered Defense Model
All physical security should be based in a layered defense model. In such a model, reliance should not be based on any single physical security concept but on the use of multiple approaches that support one another. The theory is that if one tier of defense (say, for example, perimeter security) fails, another layer will serve as a backup (such as locks on the server room door). Layering the concepts discussed in this chapter can strengthen the overall physical security.
CPTED
Crime Prevention Through Environmental Design (CPTED) refers to designing a facility from the ground up to support security. It is actually a broad concept that can be applied to any project (housing developments, office buildings, and retail establishments). It addresses the building entrance, landscaping, and interior design. It aims to create behavioral effects that reduce crime. The three main strategies that guide CPTED are covered here.
Natural Access Control
The natural access control concept applies to the entrances of the facility. It encompasses the placement of the doors, lights, fences, and even landscaping. It aims to satisfy security goals in the least obtrusive and aesthetically appealing manner. A single object can be designed in many cases to fulfill multiple security objectives.
For example, many buildings have bollards or large posts in the front of the buildings with lights on them. These objects serve a number of purposes. They protect the building entrance from vehicular traffic being driven into it. The lights also brighten the entrance to discourage crime, and can help show a clear way to the entrance.
Natural access control also encourages the idea of creating security zones in the building. These areas can be labeled, and then card systems can be used to prevent access to more sensitive areas. This concept also encourages a minimization of entry points and a tight control over those entry points. It also encourages designing and designating a separate entrance for suppliers that is not accessible or highly visible to the public eye.
Natural Surveillance
Natural surveillance is the use of physical environmental features to promote visibility of all areas and thus discourage crime in those areas. The idea is to encourage the flow of people such that the largest possible percentage of the building is always populated, because people in an area discourage crime. It also attempts to maximize the visibility of all areas.
Natural Territorials Reinforcement
The goal of natural territorials reinforcement is to create a feeling of community in the area. It attempts to extend the sense of ownership to the employees. It also attempts to make potential offenders feel that their activities are at risk of being discovered. This is often implemented in the form of walls, fences, landscaping, and lighting design.
Physical Security Plan
Another important aspect of site and facility design is the proper convergence between the physical layout and the physical security plan. Achieving all the goals of CPTED may not be always possible, and in cases where gaps exist, the physical security plan should include policies and/or procedures designed to close any gaps. The plan should address the following issues.
Deter Criminal Activity
Both the layout and supporting policies should deter criminal activity. For example, as many areas as possible should be open and clearly seen. There should be a minimum of isolated and darkened areas. Signage that indicates cameras or onsite monitoring and the presence of guards can also serve as deterrents.
Delay Intruders
Another beneficial characteristic of the physical security plan is to add impediments to entry, such as locks, fences, and barriers. Any procedures that slow, deter, and monitor the entry of people into the facility can also help. The more delay intruders encounter, the less likely they are to choose the facility and the more likely they are to be caught.
Detect Intruders
Systems and procedures should be in place that allow for criminal activity to be detected. Motion sensors, cameras, and the like are all forms of intruder detection. Logging all visitors could also be a form of deterrence.
Assess Situation
The plan should identify specific personnel and actions to be taken when an event occurs. Compiling a list of incident types that indicate an acceptable response, response time, and contact names might be beneficial. Written plans developed ahead of time provide a much more effective and consistent response.
Respond to Intrusions and Disruptions
The plan should also attempt to anticipate and develop appropriate responses to intruders and to common disruptions (power outages, utility problems, and so on). Although anticipating every potential event is impossible, creating a list covering possible intrusions and disruptions should be doable. Scripted responses can then be developed to ensure a consistent and predictable response to these events from all personnel.
Facility Selection Issues
When an organization moves to a new facility or enlarges an existing one, it is a great opportunity to include physical security issues in the site selection process or in the expansion plan. Next, we look at some critical items to consider if this opportunity presents itself.
Visibility
The amount of visibility desired depends on the organization and the processes being carried out at the facility. In some cases having high visibility of the location to help promote the brand or for the convenience of customers is beneficial. In other cases a lower profile is desired when sensitive operations are taking place. When this is the case, the likelihood of eavesdropping from outside the facility through windows should be considered. Considering common areas is also important. If possible, these areas should not be isolated or darkened. Place them in visible areas with lighting to discourage crime. Such areas includes hallways, parking lots, and other shared spaces.
Surrounding Area and External Entities
Considering the environment in which the facility is located is also important. What type of neighborhood is it? Is it an area that has a high crime rate, or is it isolated? Isolation can be good, but it also invites crime that might go undetected for a longer period of time. Also consider the distance to law enforcement, medical facilities, and fire stations. Finally, consider the nature of the operations of the surrounding businesses. Do they pose any sort of threat to your operations?
Accessibility
The ease with which employees and officers can access the facility is a consideration. What are the traffic conditions that the employees will encounter? If this is a new facility replacing an old one, is it inconvenient for the bulk of the employees? Do you risk losing employees over the commute? Is this location convenient to transportation options, such as train stations and airports? If lots of travel is required of your employees, accessibility could be important. If you often host employees from other locations on a temporary basis or host business partners, are safe accommodations nearby?
Construction
The materials used to construct a facility are another critical issue. But the issues to consider here do not stop at simply the makeup of the walls and ceilings, although that is crucial. The support systems built into the building are also important and include the following:
Walls
Doors
Ceilings
Windows
Flooring
HVAC
Power source
Utilities
Fire detection and suppression
Some special considerations include the following:
All walls must have a two-hour minimum fire-resistant rating.
Doors must resist forcible entry.
Location and type of fire suppression systems should be known.
Flooring in server rooms and wiring closets should be raised to help mitigate flooding damage.
Backup and alternate power sources should exist.
Separate AC units must be dedicated, and air quality/humidity should be controlled for data centers and computer rooms.
Internal Compartments
In many areas of a facility, partitions are used to separate work areas. These partitions, although appearing to be walls, are not full walls in that they do not extend all the way to the ceiling. When this construction approach is combined with a drop ceiling, also common in many buildings, an opportunity exists for someone to gain access to an adjoining room through the drop ceiling. All rooms that need to be secured, such as server rooms and wiring closets, should not have these types of walls.
Computer and Equipment Rooms
While we are on the subject of rooms that contain equipment to which physical access should be controlled, such as those that contain sensitive servers and crucial network gear, computer and equipment rooms should be locked at all times and secured and fitted with the following safeguards:
Locate computer and equipment rooms in the center of the building, when possible.
Computer and equipment rooms should have a single access door or point of entry.
Avoid the top floors of buildings for computer and equipment rooms.
Install and frequently test fire detection and suppression systems.
Install raised flooring.
Install separate power supplies for computer and equipment rooms when possible.
Use only solid doors.
Site and Facility Security Controls
Although perimeter security is important, security within the building is also important as prescribed in the concentric circle model. The following sections cover issues affecting the interior of the facility.
Doors
A variety of door types and door materials can be used in buildings. They can either be hollow, which are used inside the building, or solid, typically used at the edge of the building and in places where additional security is required. Some door types with which a security professional should be familiar and prepared to select for protection are
Vault doors: Leading into walk-in safes or security rooms
Personnel doors: Used by humans to enter the facility
Industrial doors: Large doors that allow access to larger vehicles
Vehicle access doors: Doors to parking building or lots
Bullet-resistant doors: Doors designed to withstand firearms
Door Lock Types
Door locks can either be mechanical or electronic. Electric locks or cipher locks use a key pad that requires the correct code to open the lock. These locks are programmable, and organizations that use them should change the password frequently. Another type of door security system is a proximity authentication device, with which a programmable card is used to deliver an access code to the device either by swiping the card or in some cases just being in the vicinity of the reader. These devices typically contain the following Electronic Access Control (EAC) components:
An electromagnetic lock
A credential reader
A closed-door sensor
Turnstiles and Mantraps
Two special types of physical access control devices, turnstiles and mantraps, also require mention. Although you might be familiar with a turnstile, which can be opened by scanning or swiping an access card, a mantrap is an unusual system with which you might not be familiar.
A mantrap is a series of two doors with a small room between them. The user is authenticated at the first door and then allowed into the room. At that point, additional verification occurs (such as a guard visually identifying the person), and then the person is allowed through the second door. These doors are typically used only in very high security situations. Mantraps also typically require that the first door is closed prior to enabling the second door to open. Figure 3-21 shows a mantrap design.
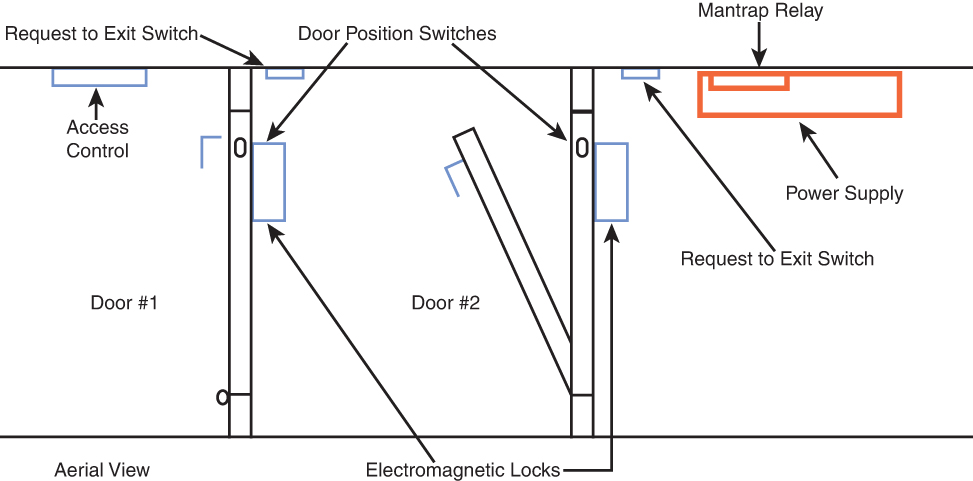
Figure 3-21 Mantrap
Locks
Locks are also used in places other than doors, such as protecting cabinets and securing devices. Types of mechanical locks with which you should be familiar are
Warded locks: These have a spring-loaded bolt with a notch in it. The lock has wards or metal projections inside the lock with which the key will match and enable opening the lock. A warded lock design is shown in Figure 3-22.
Figure 3-22 Warded Lock
Tumbler locks: These have more moving parts than the warded locks, and the key raises the lock metal piece to the correct height. A tumbler lock design is shown in Figure 3-23.
Figure 3-23 Tumbler Lock
Combination locks: These require rotating the lock in a pattern that, if correct, lines up the tumblers, opening the lock. A combination lock design is shown in Figure 3-24.
Figure 3-24 Combination Lock
In the case of device locks, laptops are the main item that must be protected because they are so easy to steal. Laptops should never be left in the open without being secured to something solid with a cable lock. These are vinyl-coated steel cables that connect to the laptop and then lock around a hard-to-move object, such as a table or desk leg.
Biometrics
The most expensive physical access control to deploy is a biometric device. Biometric devices rely on human interaction and are covered extensively in Chapter 5.
Type of Glass Used for Entrances
Glass entryways, which have become common in many facilities, include windows, glass doors, and glass walls. The proper glass must be selected for the situation. A security professional should be familiar with the following types of glass:
Standard glass: Used in residential areas and is easily broken
Tempered glass: Created by heating the glass, which gives it extra strength
Acrylic glass: Made of polycarbonate acrylic; is much stronger than regular glass but produces toxic fumes when burned
Laminated glass: Made of two sheets of glass with a plastic film between, which makes breaking it more difficult
In areas where regular glass must be used but security is a concern, glass that is embedded with wire to reduce the likelihood of breaking and entering can be used. An even stronger option is to supplement the windows with steel bars.
Visitor Control
Some system of identifying visitors and controlling their access to the facility must be in place. The best system is to have a human present to require all visitors to sign in before entering. If that option is unfeasible, another option is to provide an entry point at which visitors are presented with a locked door and a phone that can be used to call and request access. Either of these methods helps to prevent unauthorized persons from simply entering the building and going where they please.
Another best practice with regard to visitors is to have personnel always accompany a contractor or visitor to their destination to help ensure they are not going where they shouldn’t. In low security situations, this practice might not be necessary but is recommended in high security areas. Finally, log all visitors.
Wiring Closets/Intermediate Distribution Facilities
Lock any areas where equipment is stored, and control access to them. Having a strict inventory of all equipment so theft can be discovered is also important. For data centers and server rooms, the bar is raised even higher. There is more on this topic later.
Restricted and Work Areas
Some system should be in place to separate areas by security. Some specific places where additional security measures might be required are discussed here. Most of these measures apply to both visitors and employees. Following the least privilege policies and prohibiting some employees from certain areas might be beneficial.
Secure Data Center
Data centers must be physically secured with lock systems and should not have drop ceilings. The following are some additional considerations for rooms that contain lots of expensive equipment:
They should not be located on top floors or in basements.
An off switch should be located near the door for easy access.
Separate HVAC for these rooms is recommended.
Environmental monitoring should be deployed to be alert to temperature or humidity problems.
Floors should be raised to help prevent water damage.
All systems should have a UPS with the entire room connected to a generator.
Restricted Work Area
The facility might have areas that must be restricted to only the workers involved, even from other employees. In these cases, physical access systems must be deployed using smart cards, proximity readers, keypads, or any of the other physical access mechanisms described in this book.
Server Room
Some smaller companies implement a server room instead of a secure data center. The physical security controls needed for a server room are similar to those deployed in a secure data center or restricted work area.
Media Storage Facilities
A media storage facility is a building or a secured area within a building where media is stored. Because media can come in a variety of forms, organizations must determine which storage media they will use before selecting a media storage facility. If only tape or optical media is being stored, it might suffice to just install a fireproof safe in an organization’s existing data center and to store a backup copy at a remote location. However, in some cases, a much larger solution is necessary because of the amount of data that is being protected. If a separate media storage facility is needed, then the organization must ensure that the facility provides the appropriate physical security to protect the media stored there and the organization follows the storage/backup/recovery policies.
Evidence Storage
If an organization has collected evidence that is crucial to an investigation, the organization must ensure that the evidence is protected from being accessed by unauthorized users. Only personnel involved in the investigation should have access to evidence that is stored. Evidence should be stored in a locked room, and access to the evidence should be logged. When required, evidence should be turned over to law enforcement at the appropriate time. If backup copies of digital evidence are retained during the investigation, the backup copies should also be in a secure storage area with limited personnel access.
Environmental Security and Issues
Although most considerations concerning security revolve around preventing mischief, preventing damage to data and equipment from environmental conditions is also the responsibility of the security team because it addresses the availability part of the CIA triad. In the following sections, we cover some of the most important considerations.
Fire Protection
Fire protection has a longer history than many of the topics discussed in this book, and although the traditional considerations concerning preventing fires and fire damage still hold true, the presence of sensitive computing equipment requires different approaches to detection and prevention, which we discuss next.
Fire Detection
Several options are available for fire detection.
Security professionals should be familiar with the following basic types of fire detection systems:
Smoke-activated sensor: Operates using a photoelectric device to detect variations in light caused by smoke particles.
Heat-activated sensor (also called heat-sensing sensor): Operates by detecting temperature changes. These systems can either alert when a predefined temperature is met or alert when the rate of rise is a certain value.
Flame-actuated sensor: Operates by “looking at” the protected area with optical devices. They generally react faster to a fire than nonoptical devices do.
Fire Suppression
Although fire extinguishers (covered in Chapter 1) are a manual form of fire suppression, other more automated systems also exist.
Security professionals should be familiar with the following sprinkler system types:
Wet pipe extinguisher: This system uses water contained in pipes to extinguish the fire. In some areas, the water might freeze and burst the pipes, causing damage. These extinguishers are also not recommended for rooms where equipment will be damaged by the water.
Dry pipe extinguisher: In this system, the water is not held in the pipes but in a holding tank. The pipes hold pressurized air, which is reduced when fire is detected, allowing the water to enter the pipe and the sprinklers. This structure minimizes the chance of an accidental discharge.
Preaction extinguisher: This system operates like a dry pipe system except that the sprinkler head holds a thermal-fusible link that must be melted before the water is released. This is currently the recommended system for a computer room.
Deluge extinguisher: This system allows large amounts of water to be released into the room, which obviously makes this not a good choice where computing equipment will be located.
At one time, fire suppression systems used Halon gas, which works well by suppressing combustion through a chemical reaction. However, these systems are no longer used because they have been found to damage the ozone layer.
Current EPA-approved replacements for Halon include
Water
Argon
NAF-S-III
Another fire suppression system that can be used in computer rooms that will not damage computers and is safe for humans is FM-200.
Power Supply
The power supply is the lifeblood of the enterprise, its IT systems, and all of its equipment. Here, we look at common power issues and some of the prevention mechanisms and mitigation techniques that will allow the company to continue to operate when power problems arise.
Types of Outages
When discussing power issues, security professionals should be familiar with the following terms:
Surge: A prolonged high voltage
Brownout: A prolonged drop in power that is below normal voltage
Fault: A momentary power outage
Blackout: A prolonged power outage
Sag: A momentary reduction in the level of power
However, possible power problems go beyond partial or total loss of power. Power lines can introduce noise and interfere with communications in the network. In any case where large electric motors or sources of certain types of light, such as fluorescent lighting, are present, shielded cabling should be used to help prevent radio frequency interference (RFI) and electromagnetic interference (EMI).
Preventive Measures
Procedures to prevent static electricity from damaging components should be observed. Some precautions to take are
Use antistatic sprays.
Maintain proper humidity levels.
Use antistatic mats and wrist bands.
To protect against dirty power (sags and surges) and both partial and total power outages, the following devices can be deployed:
Power conditioners: Go between the wall outlet and the device and smooth out the fluctuations of power delivered to the device, protecting against sags and surges.
Uninterruptible power supplies (UPSs): Go between the wall outlet and the device and use a battery to provide power if the source from the wall is lost. UPSs also exist that can provide power to a server room.
HVAC
Heating, ventilation, and air conditioning systems are not just in place for the comfort of the employees. The massive amounts of computing equipment deployed by most enterprises are even more dependent on these systems than humans. Without the proper environmental conditions, computing equipment won’t complain; it will just stop working. Computing equipment and infrastructure devices, like routers and switches, must be protected from the following conditions:
Heat: Excessive heat causes reboots and crashes.
Humidity: Humidity causes corrosion problems with connections.
Low humidity: Dry conditions encourage static electricity, which can damage equipment.
With respect to temperature, some important facts to know are
At 100 degrees Fahrenheit, damage starts occurring to magnetic media.
At 175 degrees Fahrenheit, damage starts occurring to computers and peripherals.
At 350 degrees Fahrenheit, damage starts occurring to paper products.
In summary, the conditions need to be perfect for these devices. It is for this reason that AC units should be dedicated to the information processing facilities and on a separate power source than the other HVAC systems.
Water Leakage and Flooding
As much as computing systems dislike heat, they dislike water even more. It also can cause extensive damage to flooring, walls, and the facility foundation. Water detectors should be placed under raised floors and over dropped ceilings so that leaks in the ceiling and water under the floors are detected before they cause a problem.
Speaking of raised floors, in areas such as wiring closets, data centers, and server rooms, all floors should be raised to provide additional margin for error in the case of rising water.
Environmental Alarms
An error that causes a system to be vulnerable because of the environment in which it is installed is called an environmental error. Considering the various challenges presented by the environmental demands placed on the facility by the computing equipment and the costs of failing to address these needs, it behooves the enterprise to have some system that alerts when environmental conditions are less than desirable. An alert system such as a hygrometer, which monitors humidity, should be in place in areas where sensitive equipment resides. The system should also monitor temperature. These types of controls are considered physical controls.
Equipment Physical Security
The physical security of the equipment is stressed throughout this book. Here, we discuss corporate procedures concerning equipment and media and the use of safes and vaults for protecting other valuable physical assets. IT systems are not the only physical assets.
Corporate Procedures
Physical security of equipment and media should be designed into the security policies and procedures of the company. These procedures should address the issues covered in the sections that follow.
Tamper Protection
Unauthorized persons should not be able to access and change the configuration of any devices. Ensuring device safety means taking additional measures, such as the ones in the following sections, to prevent such access. Tampering includes defacing, damaging, or changing the configuration of a device. Applications should use integrity verification programs to look for evidence of data tampering, errors, and omissions.
Data Encryption
Encrypting sensitive data stored on devices can help to prevent the exposure of data in the event of a theft or in the event of inappropriate access of the device. Cryptography and encryption concepts are covered extensively earlier in this chapter.
Inventory
Recognizing when items are stolen is impossible if no item count or inventory system exists. All equipment should be inventoried, and all relevant information about each device should be maintained and kept up to date. Maintain this information both electronically and in hard copy.
Physical Protection of Security Devices
Security devices, such as firewalls, NAT devices, and intrusion detection and prevention systems, should receive the most attention because they relate to physical and logical security.
Beyond these devices, devices that can be easily stolen, such as laptops, tablets, and smartphones, should be locked away. If locking devices away is not practical, then lock these types of devices to a stationary object. A good example is the cable locks used with laptops.
Tracking Devices
When the technology is available, small devices can be tracked to help mitigate loss of both devices and their data, as previously covered. Most smartphones now include tracking software that allows you to locate these devices after they have been stolen or lost by using either cell tower tracking or GPS. Deploy this technology when available and affordable.
Another useful feature available on these same types of devices is a remote wipe feature. This feature allows sending a signal to a stolen device instructing it to wipe out the data contained on the device. Finally, these devices typically also come with the ability to remotely lock the device when misplaced.
Portable Media Procedures
As previously covered, strict control of the use of portable media devices can help prevent sensitive information from leaving the network. These devices include CDs, DVDs, flash drives, thumb drives, and external hard drives. Although written rules should be in effect about the use of these devices, using security policies to prevent the copying of data to these media types is also possible. Allowing the copying of data to these drive types as long as the data is encrypted is also possible. If the operating system allows administrators to prevent the use of these drives or require encryption, administrators should ensure that such functions are enabled.
Safes, Vaults, and Locking
With respect to protecting physical assets such as laptops, smartphones, tablets, and so on, nothing beats physically locking the devices away. In cases where it is possible to do so, lockable cabinets are a good solution for storing these devices. In addition to selecting the proper locks (locks are discussed earlier in this chapter), all equipment should be inventoried, and a system devised for maintaining these counts as the devices come and go.
Some items require even more protection than a locked cabinet. Keep important legal documents and any other items of extreme value in a safe or a vault for the added protection these items require. Fireproof safes and vaults can provide protection for contents even during a fire.
Exam Preparation Tasks
As mentioned in the section “About the CISSP Cert Guide, Fourth Edition” in the Introduction, you have a couple of choices for exam preparation: the exercises here, Chapter 9, “Final Preparation,” and the exam simulation questions in the Pearson Test Prep practice test software.
Review All Key Topics
Review the most important topics in this chapter, noted with the Key Topics icon in the outer margin of the page. Table 3-15 lists a reference of these key topics and the page numbers on which each is found.
Table 3-15 Key Topics for Chapter 3
Key Topic Element | Description | Page Number |
List | ISO/IEC 15288:2015 categories of processes | 214 |
Security Modes Summary | 222 | |
List | Bell-LaPadula rules | 226 |
List | Biba axioms | 228 |
List | Clark-Wilson elements | 228 |
List | TCSEC classification system | 246 |
Mapping of ITSEC and TCSEC | 249 | |
List | Common Criteria assurance levels | 250 |
List | ISO/IEC 27001:2018 steps | 253 |
List | NIACAP phases | 256 |
List | Security control selection process | 257 |
List | TPM chip memory | 259 |
List | Industrial control systems components | 265 |
List | NIST SP 800-82, Rev. 2 ICS security objectives | 266 |
List | ICS security program steps | 267 |
List | NIST SP 800-145 cloud deployments | 269 |
List | Cloud levels | 269 |
NIST SP 800-144 Cloud Security and Privacy Issues and Recommendations | 272 | |
List | NIST SP 800-146 benefits of SaaS | 273 |
List | NIST SP 800-146 issues and concerns of SaaS | 273 |
List | NIST SP 800-146 benefit of PaaS | 274 |
List | NIST SP 800-146 issues and concerns of PaaS | 274 |
List | NIST SP 800-146 benefits of IaaS | 274 |
List | NIST SP 800-146 issues and concerns of IaaS | 274 |
NIST CPS Framework | 278 | |
List | Cryptography concepts | 292 |
List | Key management process elements | 304 |
Symmetric Algorithm Strengths and Weaknesses | 309 | |
List | Advantages of stream-based ciphers | 309 |
List | Advantages of block ciphers | 310 |
Asymmetric Algorithm Strengths and Weaknesses | 311 | |
List | DES modes | 313 |
List | 3DES modes | 316 |
Symmetric Algorithms Key Facts | 319 | |
List | PKI steps | 327 |
List | Basic steps of an HMAC process | 338 |
List | Basic steps of a CBC-MAC process | 338 |
List | Basic types of fire detection systems | 359 |
List | Sprinkler system types | 359 |
List | Power issue terms | 360 |
Complete the Tables and Lists from Memory
Print a copy of Appendix A, “Memory Tables,” or at least the section from this chapter, and complete the tables and lists from memory. Appendix B, “Memory Tables Answer Key,” includes completed tables and lists to check your work.
Define Key Terms
Define the following key terms from this chapter and check your answers in the glossary:
Brewer-Nash (Chinese Wall) model
certificate revocation list (CRL)
Cipher Block Chaining MAC (CBC-MAC)
Crime Prevention Through Environmental Design (CPTED)
Digital Encryption Standard (DES)
Digital Signature Standard (DSS)
Extensible Markup Language (XML)
field-programmable gate array (FPGA)
Information Technology Security Evaluation Criteria (ITSEC)
Infrastructure as a Service (IaaS)
International Data Encryption Algorithm (IDEA)
mono-alphabetic substitution cipher
natural territorials reinforcement
Online Certificate Status Protocol (OCSP)
Open Web Application Security Project (OWASP)
Payment Card Industry Data Security Standard (PCI DSS)
polyalphabetic substitution cipher
proximity authentication device
Security Assertion Markup Language (SAML)
time-of-check/time-of-use attack
Trusted Computer System Evaluation Criteria (TCSEC)
Answer Review Questions
1. Which of the following is provided if data cannot be read?
Integrity
Confidentiality
Availability
Defense in depth
2. In a distributed environment, which of the following is software that ties the client and server software together?
Embedded system
Mobile code
Virtual computing
Middleware
3. Which of the following is composed of the components (hardware, firmware, and/or software) that are expected to enforce the security policy of the system?
Security perimeter
Reference monitor
Trusted Computer Base (TCB)
Security kernel
4. Which process converts plaintext into ciphertext?
Hashing
Decryption
Encryption
Digital signature
5. Which type of cipher is the Caesar cipher?
Polyalphabetic substitution
Mono-alphabetic substitution
Polyalphabetic transposition
Mono-alphabetic transposition
6. Which of the following is the most secure encryption scheme?
Concealment cipher
Symmetric algorithm
One-time pad
Asymmetric algorithm
7. Which 3DES implementation encrypts each block of data three times, each time with a different key?
3DES-EDE3
3DES-EEE3
3DES-EDE2
3DES-EEE2
8. Which of the following is NOT a hash function?
ECC
MD6
SHA-2
RIPEMD-160
9. Which of the following is an example of a preventive control?
A door lock system on a server room
An electric fence surrounding a facility
Armed guards outside a facility
Parking lot cameras
10. Which of the following is NOT one of the three main strategies that guide CPTED?
Natural access control
Natural surveillance reinforcement
Natural territorials reinforcement
Natural surveillance
11. What occurs when different encryption keys generate the same ciphertext from the same plaintext message?
Key clustering
Cryptanalysis
Keyspace
Confusion
12. Which encryption system uses a private or secret key that must remain secret between the two parties?
Running key cipher
Concealment cipher
Asymmetric algorithm
Symmetric algorithm
13. Which of the following is an asymmetric algorithm?
IDEA
Twofish
RC6
RSA
14. Which PKI component contains a list of all the certificates that have been revoked?
CA
RA
CRL
OCSP
15. Which attack executed against a cryptographic algorithm uses all possible keys until a key is discovered that successfully decrypts the ciphertext?
Frequency analysis
Reverse engineering
Ciphertext-only attack
Brute force
16. In ISO/IEC 15288:2015, which process category includes acquisition and supply?
Technical management processes
Technical processes
Agreement processes
Organizational project-enabling processes
17. Which statement is true of dedicated security mode?
It employs a single classification level.
All users have the same security clearance, but they do not all possess a need-to-know clearance for all the information in the system.
All users must possess the highest security clearance, but they must also have valid need-to-know clearance, a signed NDA, and formal approval for all information to which they have access.
Systems allow two or more classification levels of information to be processed at the same time.
18. What is the first step in ISO/IEC 27001:2013?
Identify the requirements.
Perform risk assessment and risk treatment.
Maintain and monitor the ISMS.
Obtain management support.
19. Which two states are supported by most processors in a computer system?
Supervisor state and problem state
Supervisor state and kernel state
Problem state and user state
Supervisor state and elevated state
20. When supporting a BYOD initiative, from which group do you probably have most to fear?
Hacktivists
Careless users
Software vendors
Mobile device vendors
21. Which term applies to embedded devices that bring with them security concerns because engineers that design these devices do not always worry about security?
BYOD
NDA
IoT
ITSEC
22. Which option best describes the primary concern of NIST SP 800-57?
Asymmetric encryption
Symmetric encryption
Message integrity
Key management
23. Which of the following key types requires only integrity security protection?
Public signature verification key
Private signature key
Symmetric authentication key
Private authentication key
24. What is the final phase of the cryptographic key management life cycle, according to NIST SP 800-57?
Operational phase
Destroyed phase
Pre-operational phase
Post-operational phase
Answers and Explanations
1. b. Confidentiality is provided if the data cannot be read. It can be provided either through access controls and encryption for data as it exists on a hard drive or through encryption as the data is in transit.
2. d. In a distributed environment, middleware is software that ties the client and server software together. It is neither a part of the operating system nor a part of the server software. It is the code that lies between the operating system and applications on each side of a distributed computing system in a network.
3. c. The Trusted Computer Base (TCB) is composed of the components (hardware, firmware, and/or software) that are trusted to enforce the security policy of the system and that if compromised jeopardize the security properties of the entire system.
4. c. Encryption converts plaintext into ciphertext. Hashing reduces a message to a hash value. Decryption converts ciphertext into plaintext. A digital signature is an object that provides sender authentication and message integrity by including a digital signature with the original message.
5. b. The Caesar cipher is a mono-alphabetic substitution cipher. The Vigenere substitution is a polyalphabetic substitution.
6. c. A one-time pad is the most secure encryption scheme because it is used only once.
7. b. The 3DES-EEE3 implementation encrypts each block of data three times, each time with a different key. The 3DES-EDE3 implementation encrypts each block of data with the first key, decrypts each block with the second key, and encrypts each block with the third key. The 3DES-EDE2 implementation encrypts each block of data with the first key, decrypts each block with the second key, and then encrypts each block with the first key. The 3DES-EEE2 implementation encrypts each block of data with the first key, encrypts each block with the second key, and then encrypts each block with the third key.
8. a. Elliptic Curve Cryptosystem (ECC) is NOT a hash function. It is an asymmetric algorithm. All the other options are hash functions.
9. a. An electric fence surrounding a facility is designed to prevent access to the building by those who should not have any access (an external threat), whereas a door lock system on the server room that requires a swipe of the employee card is designed to prevent access by those who are already in the building (an internal threat).
10. b. The three strategies are natural access control, natural territorials reinforcement, and natural surveillance.
11. a. Key clustering occurs when different encryption keys generate the same ciphertext from the same plaintext message. Cryptanalysis is the science of decrypting ciphertext without prior knowledge of the key or cryptosystem used. A keyspace is all the possible key values when using a particular algorithm or other security measure. Confusion is the process of changing a key value during each round of encryption.
12. d. A symmetric algorithm uses a private or secret key that must remain secret between the two parties. A running key cipher uses a physical component, usually a book, to provide the polyalphabetic characters. A concealment cipher occurs when plaintext is interspersed somewhere within other written material. An asymmetric algorithm uses both a public key and a private or secret key.
13. d. RSA is an asymmetric algorithm. All the other algorithms are symmetric algorithms.
14. c. A certificate revocation list (CRL) contains a list of all the certificates that have been revoked. A certificate authority (CA) is the entity that creates and signs digital certificates, maintains the certificates, and revokes them when necessary. A registration authority (RA) verifies the requestor’s identity, registers the requestor, and passes the request to the CA. Online Certificate Status Protocol (OCSP) is an Internet protocol that obtains the revocation status of an X.509 digital certificate.
15. d. A brute-force attack executed against a cryptographic algorithm uses all possible keys until a key is discovered that successfully decrypts the ciphertext. A frequency analysis attack relies on the fact that substitution and transposition ciphers will result in repeated patterns in ciphertext. A reverse engineering attack occurs when an attacker purchases a particular cryptographic product to attempt to reverse engineer the product to discover confidential information about the cryptographic algorithm used. A ciphertext-only attack uses several encrypted messages (ciphertext) to figure out the key used in the encryption process.
16. c. ISO/IEC 15288:2015 establishes four categories of processes:
Agreement processes, including acquisition and supply
Organizational project-enabling processes, including infrastructure management, quality management, and knowledge management
Technical management processes, including project planning, risk management, configuration management, and quality assurance
Technical processes, including system requirements definition, system analysis, implementation, integration, operation, maintenance, and disposal
17. a. Dedicated security mode employs a single classification level.
18. d. The first step in ISO/IEC 27001:2013 is to obtain management support.
19. a. Two processor states are supported by most processors: supervisor state (or kernel mode) and problem state (or user mode).
20. b. As a security professional, when supporting a BYOD initiative, you should take into consideration that you probably have more to fear from the carelessness of the users than you do from hackers.
21. c. Internet of Things (IoT) is the term used for embedded devices and their security concerns because engineers that design these devices do not always worry about security.
22. d. Key management is the primary concern of NIST SP 800-57.
23. a. Public signature verification keys require only integrity security protection.
24. b. The destroyed phase is the final phase of the cryptographic key management life cycle, according to NIST SP 800-57.