
In this chapter, we'll build a brand new application from scratch while exploring the advanced features of Catalyst, DBIx::Class, and the Template Toolkit. We'll start by modeling our data and building a DBIx::Class schema. Then we'll add some extra code to the schema to abstract some more complex queries. After that we'll build a web interface to the database with just a few lines of code. Finally, we'll add some editing features to the web interface. In the course of this chapter, you will also be learning some nice ways to debug including interactive shell. In the end, you will also learn a powerful feature called chaining dispatcher that allows for a certain kind of abstraction with Controller methods.
The application we'll be building in this chapter is called ChatStat and arises from a need to track the opinions of irc.perl.org denizens. A common convention on irc.perl.org is to add ++ or -- and a quip after a word. These one-liners are usually amusing and deserve to live on after they've scrolled off the screen. So, we'll write a Catalyst application to make this data available on the Web.
Following is a glimpse of what you are going to build:
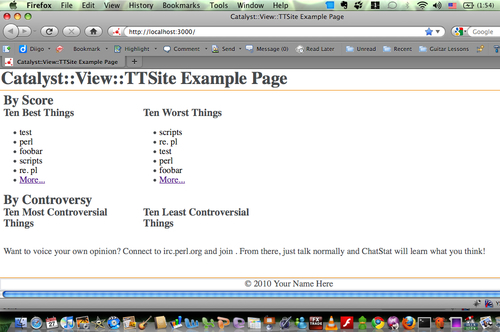
- Best/worst/most controversial and least controversial topic listing:
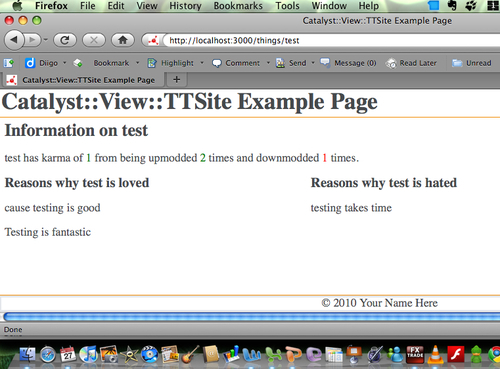
- Reasons for being loved and hated for a single item:
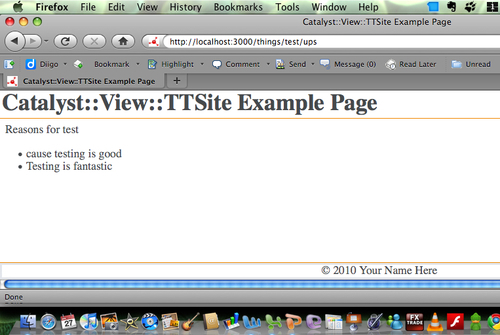
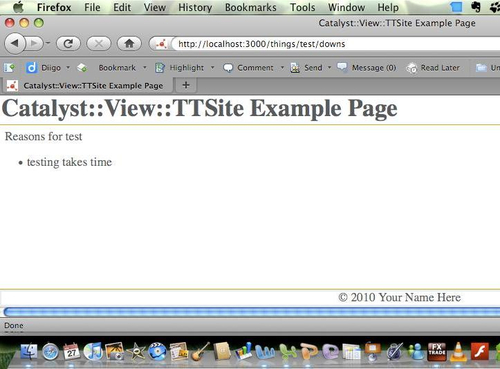
- Reasons for ups and downs (chained actions just like the previous):
Before we set up the data model, it's important to understand what data we need to keep track of. The most important piece of data to track is the actual opinions from the IRC channel. A complete opinion on IRC looks something like the following:
(on #channel) < nickname> (some thing)++ # things are good
Here we see nickname saying that he likes some thing on #channel because things are good. In our database, we'll want to store each opinion as a parsed entity consisting of columns for the channel, the nickname, the thing ("some thing" here), how many points were given (1 for "++", 0 for "+-", and -1 for "--"), the comment ("things are good"), and finally the entire message (so that we can fix up the other columns if we find our parser not working properly later).
For the sake of making queries easier to write, we'll also normalize the data. This means that there will be a things table that gives each thing a unique ID and similar tables for the nicknames and channels. This will result in an opinions table that has records like "57, 42, 89, 6, 1, 'message', and 'something++ # message". 57 is the (opinion) primary key, 42 is the nickname primary key, 89 is the thing primary key, 6 is the channel, and so on. Database management systems work best with this sort of data (as redundancy is eliminated) and it makes it easy to add metadata to the entities later. (A nickname will consist of a hostname, username, and nickname; a channel will consist of an IRC network and channel names, and so on.) Normalizing the data means that it's simple to add extra metadata later, without affecting the existing queries.
Finally, as one person (in real life) can have multiple nicknames, we'll add a person table to group related nicknames together. Each nickname will belong to one person.