
As mentioned earlier, Ceph hardware selection requires meticulous planning based on your environment and storage needs. The type of hardware component, network infrastructure, and cluster design are some critical factors you should consider during the initial phase of Ceph storage planning. There is no golden rule for Ceph hardware selection as it depends on various factors such as budget, performance versus capacity, or both, fault tolerance level, and the use case.
Ceph is hardware agnostic; organizations are free to select any hardware of their choice based on budget, performance/capacity requirements, or use case. They have full control over their storage cluster and the underlying infrastructure. Also, one of the advantages of Ceph is that it supports heterogeneous hardware. You can mix hardware brands while creating your Ceph cluster infrastructure. For example, while building your Ceph cluster, you can mix hardware from different manufacturers such as HP, Dell, Supermicro, and so on, and even off-the-shelf hardware that can lead to significant cost savings.
You should keep in mind that hardware selection for Ceph is driven by the workload that you are planning to put on your storage cluster, the environment, and the features you will be using. In this recipe, we will learn some general practices for selecting hardware for your Ceph cluster.
The Ceph Monitor daemon maintains the cluster maps and does not serve any data to the client, hence it is light-weight and does not have very strict processor requirements. In most cases, an average single core server processor will do the job for the Ceph monitor. On the other hand, the Ceph MDS is a bit more resource hungry. It requires significantly higher CPU processing powers with quad core or more. For a small Ceph cluster or proof of concept environment, you can co-locate Ceph monitors with other Ceph components such as the OSD, Radosgw, or even the Ceph MDS. For a medium-to-large-scale environment, instead of being shared, Ceph Monitors should be hosted on dedicated machines.
A Ceph OSD daemon requires a fair amount of processing power as it serves data to clients. To estimate the CPU requirement for the Ceph OSD, it's important to know how many OSDs the server would be hosting. It's generally recommended that each OSD daemon should have a minimum of one CPU core-GHz. You can use the following formula to estimate the OSD CPU requirement:
((CPU sockets * CPU cores per socket * CPU clock speed in GHz) / No. Of OSD) >=1
For example, a server with a single socket, 6 core, 2.5Ghz CPU should be good enough for 12 Ceph OSDs, and each OSD will get roughly 1.25Ghz of computing power: ((1*6*2.5)/12)= 1.25.
Here are a few more examples of processors for the Ceph OSD node:
- Intel® Xeon® Processor E5-2620 v3 (2.40 GHz, 6 core)
1 * 6 * 2.40 = 14.4 implies Good for Ceph node with up to 14 OSDs
- Intel® Xeon® Processor E5-2680 v3 (2.50 GHz, 12 core)
1 * 12 * 2.50 = 30 implies Good for Ceph node with up to 30 OSDs
If you are planning to use the Ceph erasure coding feature, then it would be more beneficial to get a more powerful CPU, as erasure coding operations require more processing power.
Monitor and metadata daemons need to serve their data rapidly, hence they should have enough memory for faster processing. The rule of thumb—be to have 2 GB or more memory per-daemon instance—should be good for Ceph MDS and monitor. Ceph MDS depends a lot on data caching; as they need to serve data quickly, they require plenty of RAM. The higher the RAM for Ceph MDS, the better the performance of CephFS will be.
OSDs generally require a fair amount of physical memory. For an average workload, 1 GB of memory per-OSD-daemon instance should suffice; however, from a performance point of view, 2 GB per-OSD daemon will be a good choice and having more memory also helps during recovery and for better caching. This recommendation assumes that you are using one OSD daemon for one physical disk. If you use more than one physical disk per OSD, your memory requirements will grow as well. Generally, more physical memory is good, because during cluster recovery, memory consumption increases significantly. It's worth knowing that the OSD memory consumption will increase if you consider the RAW capacity of the underlying physical disk. So, the OSD requirement for a 6 TB disk would be more than that of a 4 TB disk. You should take this decision wisely, such that memory should not become a bottleneck in your cluster's performance.
Ceph is a distributed storage system and it relies heavily on the underlying network infrastructure. If you are planning your Ceph cluster to be reliable and performant, make sure that you have your network designed for it. It's recommended that all cluster nodes have two redundant separate networks for cluster and client traffic.
For a small proof of concept, or to test the Ceph cluster of a few nodes, 1Gbps network speed should go well. If you have a mid-to-large sized cluster, (a few tens of nodes), you should think of using 10Gbps or more bandwidth network. At the time of recovery/re-balancing, the network plays a vital role. If you have a good 10Gbps or more bandwidth network connection, your cluster will recover quickly, else it might take some time. So, from a performance point of view, a 10Gbps or more dual network will be a good option. A well-designed Ceph cluster makes use of two physically separated networks: one for the cluster network (internal network), and another for the client network (external network); both these networks should be physically separated right from the server to the network switch and everything in-between, as shown in the following diagram:

With respect to the network, another topic of debate is whether to use the Ethernet network or InfiniBand network, or more precisely a 10G network, 40G, or higher bandwidth network. It depends on several factors such as workload, size of your Ceph cluster, density and number of Ceph OSD nodes, and so on. In several deployments, I have seen customers are using both 10G and 40G networks with Ceph. In this case, their Ceph cluster ranges to several PB and a few hundreds of nodes, in which they are using the client network as 10G, and the internal cluster network as high bandwidth, low latency 40G. Nevertheless, the price of the Ethernet network is going down; based on your use case, you can decide the network type that you would like to have.
Performance and economics for the Ceph clusters both depend heavily on an effective choice of storage media. You should understand your workload and possible performance requirements before selecting storage media for your Ceph cluster. Ceph uses storage media in two ways: the OSD journal part and the OSD data part. As explained in earlier chapters, every write operation in Ceph is currently a two-step process. When an OSD receives a request to write an object, it first writes that object to the journal part of OSDs in the acting set, and sends a write acknowledgment to clients. Soon after, the journal data is synced to data partition. It's worth knowing that replication is also an important factor during write performances. The replication factor is usually a trade off between reliability, performance, and TCO. In this way, all the cluster performance revolves around the OSD journal and data partition.
If your workload is performance-centric, then it's recommended to use SSDs for journals. By using an SSD, you can achieve significant throughput improvements by reducing the access time and write latency. To use SSDs as journals, we create multiple logical partitions on each physical SSD, such that each SSD logical partition (journal) is mapped to one OSD data partition. In this case, the OSD data partition is located on a spinning disk and has its journal on the faster SSD partition. The following diagram illustrates this configuration:
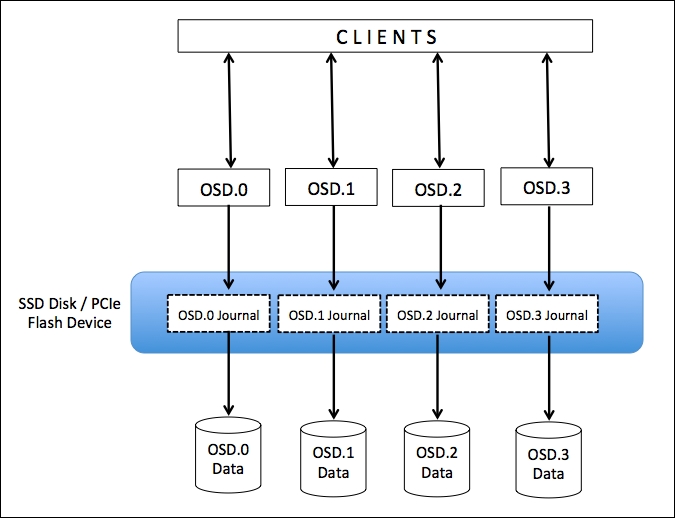
In this type of setup, you should keep in mind not to overload SSDs by storing multiple journals beyond their limits. Usually, 10 to 20GB journal sizes should be good enough for most cases, however, if you have a larger SSD, you can create a larger journal device; in this case, don't forget to increase the filestore maximum and minimum synchronization time intervals for OSD.
The two most common types of non-volatile fast storage that are used with Ceph are SATA or SAS SSDs and PCIe or NVMe SSDs. To achieve good performance out of your SATA/SAS SSDs, your SSD to OSD ratio should be 1:4, that is, one SSD shared with 4 OSD data disks. In the case of PCIe or NVMe flash devices, depending on device performance, the SSD to OSD ratio can vary from 1:12 to 1:18, that is, one flash device shared with 12 to 18 OSD data disks.
The dark side of using a single SSD for multiple journals is that if you lose your SSD hosting multiple journals, all the OSDs associated with this SSD will fail, and you might lose your data. However, you can overcome this situation by using RAID 1 for journals, but this will increase your storage cost. Also, the SSD cost per gigabyte is nearly 10 times more as compared to HDD. So, if you are building a cluster with SSDs, it will increase the cost per gigabyte for your Ceph cluster. However, if you are looking for significant performance improvements out of your Ceph cluster, it's worth investing on SSD for journals.
We have learned a lot about SSD journals and understood that they can contribute a lot to improving the write performance. However, if you are not concerned about extreme performance, and cost per TB is a deciding factor for you, then you should consider configuring the journal and data partition on the same hard disk drive. This means that out of your large spinning disk, you will allocate a few GBs for the OSD journal and use the remaining capacity of the same drive with the OSD data. This kind of setup might not be as performant as the SSD-journal-based one, but the TCO of price per TB of storage would be fairly less.
OSDs are the real workhorses that store all the data. In a production environment, you should use an enterprise, cloud, or archive class hard disk drive with your Ceph cluster. Typically, desktop class HDDs are not well suited to a production Ceph cluster. The reason being that in a Ceph cluster, several hundreds of rotating HDDs are installed in close proximity, and the combined rotational vibration can become a challenge with desktop class HDDs. This increases the disk failure rate and can hamper the overall performance. The enterprise class HDDs are purposely built to handle vibrations, and they themselves generate very little rotational vibration. Also, their MTBF is significantly higher than the desktop class HDDs.
Another thing to consider for the Ceph OSD data disk is its interface, that is, SATA or SAS. The NL-SAS HDDs have dual SAS 12GB/s ports, and they are generally more high performing than single ported 6GB/s SATA interface HDDs. Also, dual SAS ports provide redundancy and can also allow simultaneous reading and writing. Another aspect of SAS devices is that they have lower unrecoverable read errors (URE) as compared to SATA drives. The lower the URE, the fewer scrubbing errors and placement group repair operations.
The density of your Ceph OSD node is also an important factor for cluster performance, usable capacity, and TCO. Generally, it's better to have a larger number of smaller nodes than a few large capacity nodes, but this is always open for debate. You should select the density of your Ceph OSD node such that one node should be less than 10% of the total cluster size.
For example, in a 1PB Ceph cluster, you should avoid using 4 x 250 TB OSD nodes, in which each node constitutes 25% of the cluster capacity. Instead, you can have 13 x 80TB OSD nodes, in which each node size is less than 10% of the cluster capacity. However, this might increase your TCO and can affect several other factors of your cluster planning.
Ceph is a software-defined system that runs on top of a Linux-based operating system. Ceph supports most of the major Linux distributions. As of now, the valid operating system choices to run a Ceph clusters are RHEL, CentOS, Fedora, Debian, Ubuntu, OpenSuse, and SLES. For the Linux kernel version, it's recommended that you deploy Ceph on newer releases of the Linux Kernel. We also recommend deploying it on release with long-term support (LTS). At the time of writing this book, the Linux Kernel v3.16.3, or a later version, is recommended and is a good starting point. It's a good idea to keep an eye on http://docs.ceph.com/docs/master/start/os-recommendations. According to documentation, CentOS 7 and Ubuntu 14.04 are tier-1 distributions for which comprehensive functional, regression, and stress test suites are run on a continuous basis, and with no doubts, RHEL is the best choice if you are using the enterprise Red Hat Ceph Storage product.
The Ceph OSD daemon runs on top of a filesystem that can be XFS, EXT, or even Btrfs. However, selecting the right Filesystem for the Ceph OSD is a critical factor as OSD daemons rely heavily on the stability and performance of the underlying filesystem. Apart from stability and performance, filesystem also provides extended attributes (XATTRs) that Ceph OSD daemon's take advantage of. The XATTR provides internal information on the object state, snapshot, metadata, and ACL to the Ceph OSD daemon, which helps in data management.
That's why the underlying filesystem should provide sufficient capacity for XATTRs. Btrfs provides significantly larger xattr metadata, which is stored with a file. XFS has a relatively large limit (64 KB) that most deployments won't encounter, but the ext4 is too small to be usable. If you are using the ext4 filesystem for your Ceph OSD, you should always add filestore xattr use omap = true to the following setting to the [OSD] section of your ceph.conf file. The filesystem selection is quite important for a production workload, and with respect to Ceph, these filesystems differ from each other in various ways:
- XFS: Is a reliable, mature, and very stable filesystem, which is recommended for production usage in the Ceph clusters. However, XFS stands lower as compared to Btrfs. XFS has small performance issues in metadata scaling. Also, XFS is a journaling filesystem, that is, each time a client sends data to write to a Ceph cluster, it is first written to a journaling space and then to an XFS filesystem. This increases the overhead of writing the same data twice, and thus makes the XFS perform slower as compared to Btrfs, which does not use journals. However, due to its reliability and stability, XFS is the most popular and recommended filesystem for Ceph deployments.
- Btrfs: The OSD, with the Btrfs filesystem underneath, delivers the best performance as compared to XFS and the ext4 filesystem-based OSDs. One of the major advantages of using Btrfs is its support to copy-on-write and writable snapshots. With the Btrfs filesystem, Ceph uses parallel journaling, that is, Ceph writes to the OSD journal and OSD data in parallel, which is a big boost for
writeperformance. It also supports transparent compression and pervasive checksums, and it incorporates multi-device management in a filesystem. It has an attractive feature of online FSCK. However, despite these new features, Btrfs is currently not production ready, but it's a good candidate for test deployment. - Ext4: The fourth extended filesystem (Ext4) is also a journaling filesystem that is a production-ready filesystem for the Ceph OSD. However, it's not as popular as XFS. From a performance point of view, the ext4 filesystem is not on par with Btrfs.