
The default data protection mechanism in Ceph is replication. It's proven and is one of the most popular methods of data protection. However, the downside of replication is that it requires double the amount of storage space to provide redundancy. For instance, if you were planning to build a storage solution with 1 PB of usable capacity with a replication factor of three, you would require 3 PB of raw storage capacity for 1 PB of usable capacity, that is, 200% or more. In this way, with the replication mechanism, cost per gigabyte of storage system increases significantly. For a small cluster, you might ignore the replication overhead, but for large environments, it becomes significant.
Since the Firefly release of Ceph, it has introduced another method for data protection known as erasure coding. This method of data protection is absolutely different from the replication method. It guarantees data protection by dividing each object into smaller chunks known as data chunks, encoding them with coding chunks, and finally storing all these chunks across the different failure zones of a Ceph cluster. The concept of erasure coding revolves around the equation n = k + m. This is explained next:
- k: This is the number of chunks the original object is divided into; it is also known as data chunks.
- m: This is the extra code added to the original data chunks to provide data protection; it is also known as coding chunks. For ease of understanding, you can consider it as the reliability level.
- n: This is the total number of chunks created after the erasure coding process.
Based on the preceding equation, every object in an erasure-coded Ceph pool will be stored as k+m chunks, and each chunk is stored in a unique OSD with an acting set. In this way, all the chunks of an object are spread across the entire Ceph cluster, providing a higher degree of reliability. Now, let's discuss some useful terms with respect to erasure coding:
- Recovery: At the time of recovery, we will require any k chunks out of n chunks to recover the data
- Reliability level: With erasure coding, Ceph can tolerate failure up to m chunks
- Encoding Rate (r): This can be calculated using the formula, r = k / n, where r is less than 1
- Storage required: This is calculated using the formula 1/r
To understand these terms better, let's consider an example. A Ceph pool is created with five OSDs based on erasure code (3, 2) rule. Every object that is stored inside this pool will be divided into sets of data and coding chunks as given by this formula: n = k + m.
Consider 5 = 3 + 2, then n = 5, k = 3 and m = 2. So, every object will be divided into three data chunks, and two extra erasure coded chunks will be added to it, making a total of five chunks that will be stored and distributed on five OSDs of an erasure-coded pool in a Ceph cluster. In an event of failure, to construct the original file, we need (k chunks), three chunks out of (n chunks), and five chunks to recover it. Thus, we can sustain the failure of any (m) two OSDs as the data can be recovered using three OSDs.
- Encoding rate (r) = 3 / 5 = 0.6 < 1
- Storage required = 1/r = 1 / 0.6 = 1.6 times of original file.
Let's suppose that there is a data file of size 1 GB. To store this file in a Ceph cluster on an erasure coded (3, 5) pool, you will need 1.6 GB of storage space, which will provide to you file storage with the sustainability of two OSD failures.
In contrast to the replication method, if the same file is stored on a replicated pool, then in order to sustain the failure of two OSDs, Ceph will need a pool of the replica size 3, which eventually requires 3 GB of storage space to reliably store 1 GB of the file. In this way, you can reduce storage costs by approximately 40 percent by using the erasure coding feature of Ceph and getting the same reliability as with replication:
Erasure-coded pools require less storage space compared to replicated pools, however, this storage saving comes at the cost of performance because the erasure coding process divides every object into multiple smaller data chunks, and few newer coding chunks are mixed with these data chunks. Finally, all these chunks are stored across the different failure zones of a Ceph cluster. This entire mechanism requires a bit more computational power from the OSD nodes. Moreover, at the time of recovery, decoding the data chunks also requires a lot of computing. So, you might find the erasure coding mechanism of storing data somewhat slower than the replication mechanism. Erasure coding is mainly use-case dependent, and you can get the most out of erasure coding based on your data storage requirements.
Ceph gives us options to choose the erasure code plugin while creating the erasure code profile. One can create multiple erasure code profiles, with different plugins each time. Ceph supports the following plugins for erasure coding:
- Jerasure erasure code plugin: The Jerasure plugin is the most generic and flexible plugin. It is also the default for Ceph erasure coded pools. The Jerasure plugin encapsulates the Jerasure library. Jerasure uses the Reed Solomon Code technique. The following diagram illustrates Jerasure code
(3, 2). As explained, data is first divided into three data chunks, and an additional two coded chunks are added, and they finally get stored in the unique failure zone of the Ceph cluster:
With the Jerasure plugin, when an erasure-coded object is stored on multiple OSDs, recovering from the loss of one OSD requires reading from all the others. For instance, if Jerasure is configured with k=3 and m=2, losing one OSD requires reading from all the five OSDs to repair, which is not very efficient during recovery.
- Locally repairable erasure code plugin: Since Jerasure erasure code (Reed Solomon) was not recovery efficient, it was improved by the local parity method, and the new method is known as Locally Repairable erasure Code (LRC). The Locally Repairable erasure code plugin creates local parity chunks that are able to recover using less OSD, which makes it recovery-efficient.
To understand this better, let's assume that LRC is configured with k=8, m=4, and l=4 (locality), it will create an additional parity chunk for every four OSDs. When a single OSD is lost, it can be recovered with only four OSDs instead of eleven, which is the case with Jerasure.
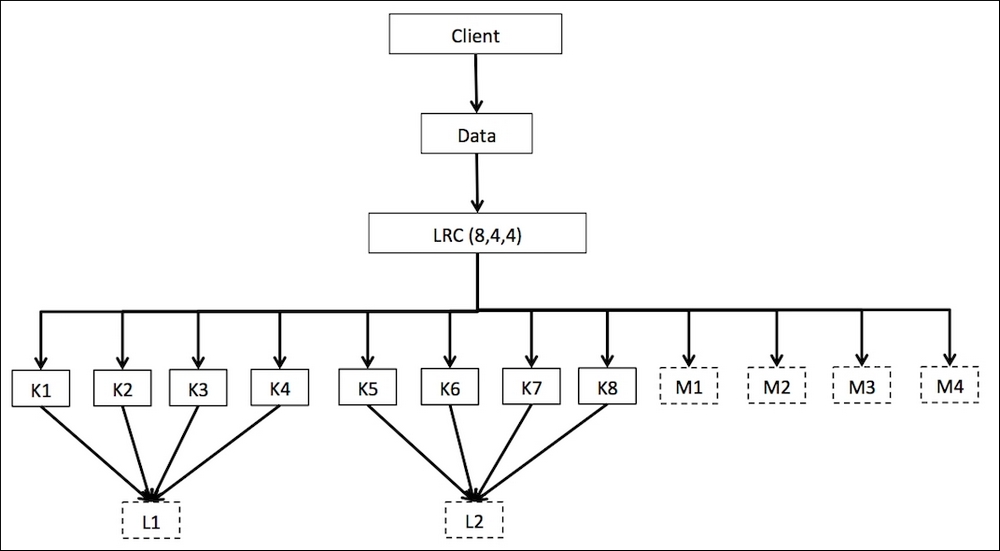
Locally Repairable Codes are designed to lower the bandwidth when recovering from the loss of a single OSD. As illustrated previously, a local parity chunk (L) is generated for every four data chunks (K). When K3 is lost, instead of recovering from all [(K+M)-K3] chunks, that is, 11 chunks, with Locally Repairable Code, it's enough to recover from the K1, K2, K4, and L1 chunks.
- Shingled erasure code plugin: The locally repairable codes are optimized for single OSD failure. For multiple OSD failure, the recovery overhead is large with LRC because it has to use global parity (M) for recovery. Let's reconsider the previous scenario and assume that multiple data chunks, K3 and K4, are lost. To recover the lost chunks using LRC, it needs to recover from K1, K2, L1 (the local parity chunk), and M1 (the global parity chunk). Thus, LRC involves overhead with multi disk failure.
To address this problem, SHEC (Shingled Erasure Code) has been introduced. The SHEC plugin encapsulates multiple SHEC libraries and allows Ceph to recover data more efficiently than Jerasure and Locally Repairable Codes. The goal of the SHEC method is to efficiently handle multiple disk failure. Under this method, the calculation range for local parities has been shifted, and parity the overlap with each other (like shingles on a roof) to keep enough durability.
Let's understand this by example, SHEC (10,6,5) where K=10 (data chunks), m=6 (parity chunks), l=5 (calculation range). In this case, the diagrammatic representation of SHEC looks as follows:

Recovery efficiency is one of the biggest features of SHEC. It minimizes the amount of data read from the disk during recovery. If chunks K6 and K9 are lost, SHEC will use the M3 and M4 parity chunks, and the K5, K7, K8, and K10 data chunks for recovery. The same has been illustrated in the following diagram:

For multi disk failure, SHEC is expected to recover more efficiently than other methods. SHEC's recovery time was 18.6% faster than the Solomon code in case of a double disk failure.
ISA-I erasure code plugin: The Intelligent Storage Acceleration (ISA) plugin encapsulates the ISA library. ISA-I was optimized for Intel platforms using some platform-specific instructions, and thus runs only on Intel architecture. ISA can be used in either of the two forms of Reed Solomon, that is, Vandermonde or Cauchy.