
Chapter 4. Test Design

If you look at the three laws of test-driven development (TDD), presented in Chapter 2, “Test-Driven Development,” you could come to the conclusion that TDD is a shallow skill: Follow the three laws, and you are done. This is far from the truth. TDD is a deep skill. There are many layers to it; and they take months, if not years, to master.
In this section, we delve into just a few of those layers, ranging from various testing conundrums, such as databases and graphical user interfaces (GUIs), to the design principles that drive good test design, to patterns of testing, and to some interesting and profound theoretical possibilities.
Testing Databases
The first rule of testing databases is: Don’t test databases. You don’t need to test the database. You can assume that the database works. You’ll find out soon enough if it doesn’t.
What you really want to test are queries. Or, rather, you want to test that the commands that you send to the database are properly formed. If you write SQL directly, you are going to want to test that your SQL statements work as intended. If you use an object-relational mapping (ORM) framework, such as Hibernate, you are going to want to test that Hibernate operates the database the way you intended. If you use a NoSQL database, you are going to want to test that all your database accesses behave as you intended.
None of these tests require you to test business rules; they are only about the queries themselves. So, the second rule of testing databases is: Decouple the database from the business rules.
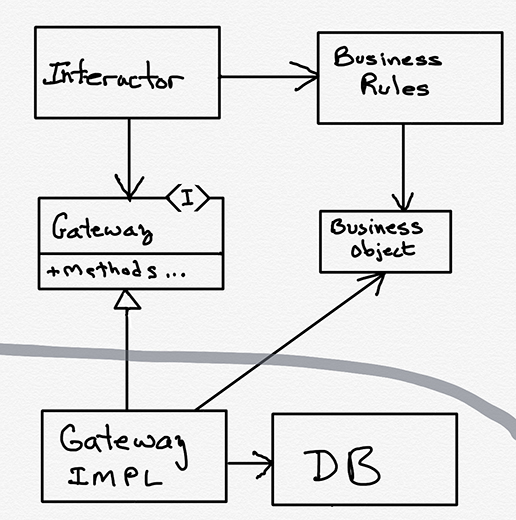
Figure 4.1 Testing the database
We decouple them by creating an interface, which I have called Gateway1 in the diagram in Figure 4.1. Within the Gateway interface, we create one method for every kind of query we wish to perform. Those methods can take arguments that modify the query. For example, in order to fetch all the Employees from the database whose hiring date was after 2001, we might call the Gateway method getEmployeesHiredAfter(2001).
1 Martin Fowler, Patterns of Enterprise Application Architecture (Addison-Wesley, 2003), 466.
Every query, update, delete, or add we want to perform in the database will have a corresponding method in a Gateway interface. There can, of course, be many Gateways, depending on how we want to partition the database.
The GatewayImpl class implements the gateway and directs the actual database to perform the functions required. If this is a SQL database, then all the SQL is created within the GatewayImpl class. If you are using ORM, the ORM framework is manipulated by the GatewayImpl class. Neither SQL nor the ORM framework nor the database API is known above the architectural boundary that separates the Gateway from the GatewayImpl.
Indeed, we don’t even want the schema of the database known above that boundary. The GatewayImpl should unpack the rows, or data elements, retrieved from the database and use that data to construct appropriate business objects to pass across the boundary to the business rules.
And now testing the database is trivial. You create a suitably simple test database, and then you call each query function of the GatewayImpl from your tests and ensure that it has the desired effect on that test database. Make sure that each query function returns a properly loaded set of business objects. Make sure that each update, add, and delete changes the database appropriately.
Do not use a production database for these tests. Create a test database with just enough rows to prove that the tests work; and then make a backup of that database. Prior to running the tests, restore that backup so that the tests are always run against the same test data.
When testing the business rules, use stubs and spies to replace the GatewayImpl classes. Do not test business rules with the real database connected. This is slow and error prone. Instead, test that your business rules and interactors manipulate the Gateway interfaces correctly.
Testing GUIs
The rules for testing GUIs are as follows:
1. Don’t test GUIs.
2. Test everything but the GUI.
3. The GUI is smaller than you think it is.
Let’s tackle the third rule first. The GUI is a lot smaller than you think it is. The GUI is just one very small element of the software that presents information on the screen. It is likely the smallest part of that software. It is the software that builds the commands that are sent to the engine that actually paints the pixels on the screen.
For a Web-based system, the GUI is the software that builds the HTML. For a desktop system, the GUI is the software that invokes the API of the graphic control software. Your job, as a software designer, is to make that GUI software as small as possible.
For example, does that software need to know how to format a date, or currency, or general numbers? No. Some other module can do that. All the GUI needs are the appropriate strings that represent the formatted dates, currencies, or numbers.
We call that other module a presenter. The presenter is responsible for formatting and arranging the data that is to appear on the screen, or in a window. The presenter does as much as possible toward that end, allowing us to make the GUI absurdly small.
So, for example, the presenter is the module that determines the state of every button and menu item. It specifies their names and whether or not they should be grayed out. If the name of a button changes based on the state of a window, it is the presenter that knows that state and changes that name. If a grid of numbers should appear on the screen, it is the presenter that creates a table of strings, all properly formatted and arranged. If there are fields that should have special colors or fonts, it is the presenter that determines those colors and fonts.
The presenter takes care of all of that detailed formatting and arrangement and produces a simple data structure full of strings and flags that the GUI can use to build the commands that get sent to the screen. And, of course, that makes the GUI very small indeed.
The data structure created by the presenter is often called a view model.

Figure 4.2 The interactor is responsible for telling the presenter what data should be presented to the screen.
In the diagram in Figure 4.2, the interactor is responsible for telling the presenter what data should be presented to the screen. This communication will be in the form of one or more data structures passed to the presenter through a set of functions. The actual presenter is shielded from the interactor by the presenter interface. This prevents the high-level interactor from depending on the implementation of the lower-level presenter.
The presenter builds the view model data structure, which the GUI then translates into the commands that control the screen.
Clearly, the interactor can be tested by using a spy for the presenter. Just as clearly, the presenter can be tested by sending it commands and inspecting the result in the view model.
The only thing that cannot be easily tested (with automated unit tests) is the GUI itself, and so we make it very small.
Of course, the GUI can still be tested; you just have to use your eyes to do it. But that turns out to be quite simple because you can simply pass a canned set of view models to the GUI and visually ensure that those view models are rendered appropriately.
There are tools that you can use to automate even that last step, but I generally advise against them. They tend to be slow and fragile. What’s more, the GUI is most likely a very volatile module. Any time someone wants to change the look and appearance of something on the screen, it is bound to affect that GUI code. Thus, writing automated tests for that last little bit is often a waste of time because that part of the code changes so frequently, and for such evanescent reasons, that the tests are seldom valid for long.
GUI Input
Testing GUI input follows the same rules: We drive the GUI to be as insignificant as possible. In the diagram in Figure 4.3, the GUI framework is the code that sits at the boundary of the system. It might be the Web container, or it might be something like Swing2 or Processing3 for controlling a desktop.
2 https://en.wikipedia.org/wiki/Swing_(Java)
The GUI framework communicates with a controller through an EventHandler interface. This makes sure that the controller has no transitive source code dependency on the GUI framework. The job of the controller is to gather the necessary events from the GUI framework into a pure data structure that I have here called the RequestModel.
Once the RequestModel is complete, the controller passes it through the InputBoundary interface to the interactor. Again, the interface is there to ensure that the source code dependencies point in an architecturally sound direction.

Figure 4.3 Testing the GUI
Testing the interactor is trivial; our tests simply create appropriate request models and hand them to the interactor. We can either check the results directly or use spies to check them. Testing the controller is also trivial—our tests simply invoke events through the event handler interface and then make sure that the controller builds the right request model.
Test Patterns
There are many different design patterns for testing, and there are several books that have documented them: XUnit Test Patterns4 by Gerard Meszaros and JUnit Recipes5 by J. B. Rainsberger and Scott Stirling, to mention just two of them.
4 Gerard Meszaros, XUnit Test Patterns: Refactoring Test Code (Addison-Wesley, 2012). and
5 J. B. Rainsberger and Scott Stirling, JUnit Recipes: Practical Methods for Programmer Testing (Manning, 2006).
It is not my intention to try to document all those patterns and recipes here. I just want to mention the three that I have found most useful over the years.
Test-Specific Subclass
This pattern is primarily used as a safety mechanism. For example, let’s say that you want to test the align method of the XRay class. However, the align method invokes the turnOn method. You probably don’t want x-rays turned on every time you run the tests.
The solution, as shown in Figure 4.4, is to create a test-specific subclass of the XRay class that overrides the turnOn method to do nothing. The test creates an instance of the SafeXRay class and then calls the assign method, without having to worry that the x-ray machine will actually be turned on.

Figure 4.4 Test-Specific-Subclass pattern
It is often helpful to make the test-specific subclass a spy so that the test can interrogate the safe object about whether the unsafe method was actually called or not.
In the example, if SafeXRay were a spy, then the turnOn method would record its invocation, and the test method in the XRayTest class could interrogate that record to ensure that turnOn was actually called.
Sometimes the Test-Specific Subclass pattern is used for convenience and throughput rather than safety. For example, you may not wish the method being tested to start a new process or perform an expensive computation.
It is not at all uncommon for the dangerous, inconvenient, or slow operations to be extracted into new methods for the express purpose of overriding them in a test-specific subclass. This is just one of the ways that tests impact the design of the code.
Self-Shunt
A variation on that theme is the Self-Shunt pattern. Because the test class is a class, it is often convenient for the test class to become the test-specific subclass, as shown in Figure 4.5.
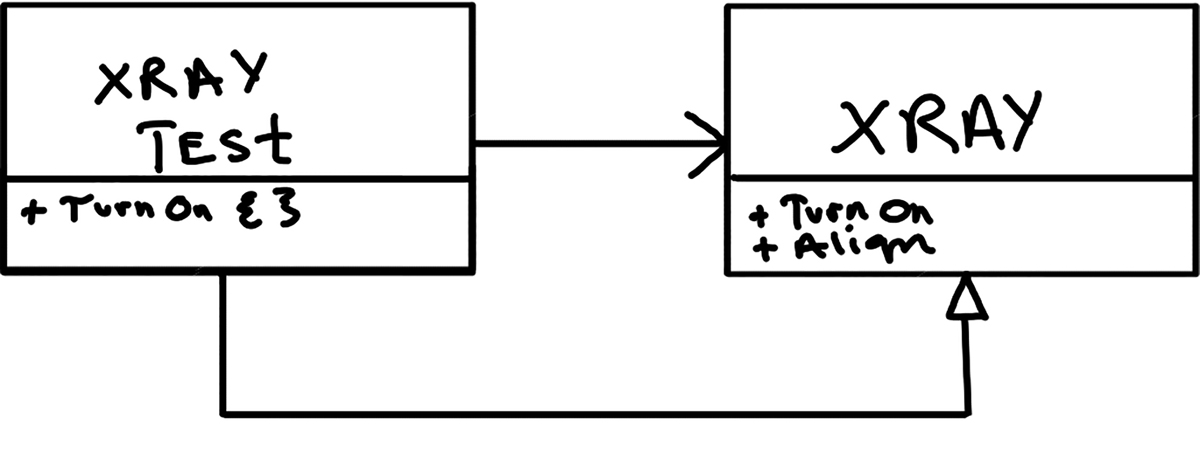
Figure 4.5 Self-Shunt pattern
In this case, it is the XRayTest class that overrides the turnOn method and can also act as the spy for that method.
I find Self-Shunt to be very convenient when I need a simple spy or a simple safety. On the other hand, the lack of a separate well-named class that specifically provides the safety or spying can be confusing for the reader, so I use this pattern judiciously.
It is important to remember, when using this pattern, that different testing frameworks construct the test classes at different times. For example, JUnit constructs a new instance of the test class for every test method invocation. NUnit, on the other hand, executes all test methods on a single instance of the test class. So, care must be taken to ensure that any spy variables are properly reset.
Humble Object
We like to think that every bit of code in the system can be tested using the three laws of TDD, but this is not entirely true. The parts of the code that communicate across a hardware boundary are perniciously difficult to test.
It is difficult, for example, to test what is displayed on the screen or what was sent out a network interface or what was sent out a parallel or serial I/O port. Without some specially designed hardware mechanisms that the tests can communicate with, such tests are impossible.
What’s more, such hardware mechanisms may well be slow and/or unreliable. Imagine, for example, a video camera staring at the screen and your test code trying desperately to determine if the image coming back from the camera is the image you sent to the screen. Or imagine a loopback network cable that connects the output port of the network adapter to the input port. Your tests would have to read the stream of data coming in on that input port and look for the specific data you sent out on the output port.
In most cases, this kind of specialized hardware is inconvenient, if not entirely impractical.
The Humble Object pattern is a compromise solution. This pattern acknowledges that there is code that cannot be practicably tested. The goal of the pattern, therefore, is to humiliate that code by making it too simple to bother testing. We saw a simple example of this earlier, in the “Testing GUIs” section, but now let’s take a deeper look.
The general strategy is shown in Figure 4.6. The code that communicates across the boundary is separated into two elements: the presenter and the Humble Object (denoted here as the HumbleView). The communication between the two is a data structure named the Presentation.

Figure 4.6 The general strategy
Let’s assume that our application (not shown) wants to display something on the screen. It sends the appropriate data to the presenter. The presenter then unpacks that data into the simplest possible form and loads it into the Presentation. The goal of this unpacking is to eliminate all but the simplest processing steps from the HumbleView. The job of the HumbleView is simply to transport the unpacked data in the Presentation across the boundary.
To make this concrete, let’s say that the application wants to put up a dialog box that has Post and Cancel buttons, a selection menu of order IDs, and a grid of dates and currency items. The data that the application sends to the presenter consists of that data grid, in the form of Date and Money objects. It also sends the list of selectable Order objects for the menu.
The presenter’s job is to turn everything into strings and flags and load them into the Presentation. The Money and Date objects are converted into locale-specific strings. The Order objects are converted into ID strings. The names of the two buttons are loaded as strings. If one or more of the buttons should be grayed out, an appropriate flag is set in the Presentation.
The end result is that the HumbleView has nothing more to do than transport those strings across the boundary along with the metadata implied by the flags. Again, the goal is to make the HumbleView too simple to need testing.
It should be clear that this strategy will work for any kind of boundary crossing, not just displays.
To demonstrate, let’s say we are coding the control software for a self-driving car. Let’s also say that the steering wheel is controlled by a stepper motor that moves the wheel one degree per step. Our software controls the stepper motor by issuing the following command:
out(0x3ff9, d);
where 0x3ff9 is the IO address of the stepper motor controller, and d is 1 for right and 0 for left.
At the high level, our self-driving AI issues commands of this form to the SteeringPresenter:
turn(RIGHT, 30, 2300);
This means that the car (not the steering wheel!) should be gradually turned 30 degrees to the right over the next 2,300ms. To accomplish this, the wheel must be turned to the right a certain number of steps, at a certain rate, and then turned back to the left at a certain rate so that, after 2,300ms, the car is heading 30 degrees to the right of its previous course.
How can we test that the steering wheel is being properly controlled by the AI? We need to humiliate the low-level steering-wheel control software. We can do this by passing it a presentation, which is an array of data structures that looks like this:
struct SteeringPresentationElement{
int steps;
bool direction;
int stepTime;
int delay;
};The low-level controller walks through the array and issues the appropriate number of steps to the stepper motor, in the specified direction, waiting stepTime milliseconds between each step and waiting delay milliseconds before moving to the next element in the array.
The SteeringPresenter has the task of translating the commands from the AI into the array of SteeringPresentationElements. In order to accomplish this, the SteeringPresenter needs to know the speed of the car and the ratio of the angle of the steering wheel to the angle of the wheels of the car.
It should be clear that the SteeringPresenter is easy to test. The test simply sends the appropriate Turn commands to the SteeringPresenter and then inspects the results in the resulting array of SteeringPresentationElements.
Finally, note the ViewInterface in the diagram. If we think of the ViewInterface, the presenter, and the Presentation as belonging together in a single component, then the HumbleView depends on that component. This is an architectural strategy for keeping the higher-level presenter from depending on the detailed implementation of the HumbleView.
Test Design
We are all familiar with the need to design our production code well. But have you ever thought about the design of your tests? Many programmers have not. Indeed, many programmers just throw tests at the code without any thought to how those tests should be designed. This always leads to problems.
The Fragile Test Problem
One of the issues that plagues programmers who are new to TDD is the problem of fragile tests. A test suite is fragile when small changes to the production code cause many tests to break. The smaller the change to the production code, and the larger the number of broken tests, the more frustrating the issue becomes. Many programmers give up on TDD during their first few months because of this issue.
Fragility is always a design problem. If you make a small change to one module that forces many changes to other modules, you have an obvious design problem. In fact, breaking many things when something small changes is the definition of poor design.
Tests need to be designed just like any other part of the system. All the rules of design that apply to production code also apply to tests. Tests are not special in that regard. They must be properly designed in order to limit their fragility.
Much early guidance about TDD ignored the design of tests. Indeed, some of that guidance recommended structures that were counter to good design and led to tests that were tightly coupled to the production code and therefore very fragile.
The One-to-One Correspondence
One common and particularly detrimental practice is to create and maintain a one-to-one correspondence between production code modules and test modules. Newcomers to TDD are often erroneously taught that for every production module or class named X, there should be a corresponding test module or class named XTest.
This, unfortunately, creates a powerful structural coupling between the production code and the test suite. That coupling leads to fragile tests. Any time the programmers want to change the module structure of the production code, they are forced to also change the module structure of the test code.
Perhaps the best way to see this structural coupling is visually (Figure 4.7).

Figure 4.7 Structural coupling
On the right side of the diagram, we see five production code modules, α, β, γ, δ, and ε. The α and ε modules stand alone, but β is coupled to γ, which is coupled to δ. On the left, we see the test modules. Note that each of the test modules is coupled to the corresponding production code module. However, because β is coupled to γ and δ, βTest may also be coupled to γ and δ.
This coupling may not be obvious. The reason that βTest is likely to have couplings to γ and δ is that β may need to be constructed with γ and δ, or the methods of β may take γ and δ as arguments.
This powerful coupling between βTest and so much of the production code means that a minor change to δ could affect βTest, γTest, and δTest. Thus, the one-to-one correspondence between the tests and production code can lead to very tight coupling and fragility.
Rule 12: Decouple the structure of your tests from the structure of the production code.
Breaking the Correspondence
To break, or avoid creating, the correspondence between tests and production code, we need to think of the test modules the way we think of all the other modules in a software system: as independent and decoupled from each other.
At first this may seem absurd. You might argue that tests must be coupled to production code, because the tests exercise the production code. The last clause is true, but the predicate is false. Exercising code does not imply strong coupling. Indeed, good designers consistently strive to break strong couplings between modules while allowing those modules to interact with and exercise each other.
How is this accomplished? By creating interface layers.

Figure 4.8 Interface layers
In the diagram in Figure 4.8, we see αTest coupled to α. Behind α we see a family of modules that support α but of which αTest is ignorant. The α module is the interface to that family. A good programmer is very careful to ensure that none of the details of the α family leak out of that interface.
As shown in the diagram in Figure 4.9, a disciplined programmer could protect αTest from the details within the α family by interposing a polymorphic interface between them. This breaks any transitive dependencies between the test module and the production code modules.

Figure 4.9 Interposing a polymorphic interface between the test and the α family
Again, this may seem absurd to the newcomer to TDD. How, you might ask, can we write tests against α5 when we cannot access that module from αTest? The answer to that question is simply that you do not need access to α5 in order to test the functionality of α5.
If α5 performs an important function for α, then that functionality must be testable through the α interface. That is not an arbitrary rule—it is a statement of mathematical certainty. If a behavior is important, it must also be visible through the interface. That visibility can be direct or indirect, but it must exist.
Perhaps an example would be beneficial to drive this point home.
The Video Store
The video store is a traditional example that demonstrates the concept of separating tests from production code quite well. Ironically, this example arose from an accident. The problem was first presented as a refactoring example in Martin Fowler’s first edition of Refactoring.6 Martin presented a rather ugly Java solution without tests and then proceeded to refactor the code into a much cleaner form.
6 Martin Fowler, Refactoring (Addison-Wesley, 1999).
In this example, we use TDD to create the program from scratch. You will learn the requirements by reading the tests as we go along.
Requirement 1: Regular movies rent, on the first day, for $1.50 and earn 1 renter point per day rented.
Red: We write a test class for the customer named CustomerTest and add the first test method.
public class CustomerTest {
@Test
public void RegularMovie_OneDay() throws Exception {
Customer c = new Customer();
c.addRental("RegularMovie", 1);
assertEquals(1.5, c.getRentalFee(), 0.001);
assertEquals(1, c.getRenterPoints());
}
}Green: We can make this pass trivially.
public class Customer {
public void addRental(String title, int days) {
}
public double getRentalFee() {
return 1.5;
}
public int getRenterPoints() {
return 1;
}
}Refactor: We can clean this up quite a bit.
public class CustomerTest {
private Customer customer;
@Before
public void setUp() throws Exception {
customer = new Customer();
}
private void assertFeeAndPoints(double fee, int points) {
assertEquals(fee, customer.getRentalFee(), 0.001);
assertEquals(points, customer.getRenterPoints());
}
@Test
public void RegularMovie_OneDay() throws Exception {
customer.addRental("RegularMovie", 1);
assertFeeAndPoints(1.5, 1);
}
}Requirement 2: The second and third days’ rentals of regular movies are free, and no points are earned for them.
Green: No change to production code.
@Test
public void RegularMovie_SecondAndThirdDayFree() throws Exception {
customer.addRental("RegularMovie", 2);
assertFeeAndPoints(1.5, 1);
customer.addRental("RegularMovie", 3);
assertFeeAndPoints(1.5, 1);
}Requirement 3: All subsequent days rent for $1.50 and earn 1 renter point.
Red: The test is simple.
@Test
public void RegularMovie_FourDays() throws Exception {
customer.addRental("RegularMovie", 4);
assertFeeAndPoints(3.0, 2);
}Green: This isn’t hard to fix.
public class Customer {
private int days;
public void addRental(String title, int days) {
this.days = days;
}
public double getRentalFee() {
double fee = 1.5;
if (days > 3)
fee += 1.5 * (days - 3);
return fee;
}
public int getRenterPoints() {
int points = 1;
if (days > 3)
points += (days - 3);
return points;
}
}Refactor: There’s a bit of duplication we can eliminate, but it causes some trouble.
public class Customer {
private int days;
public void addRental(String title, int days) {
this.days = days;
}
public int getRentalFee() {
return applyGracePeriod(150, 3);
}
public int getRenterPoints() {
return applyGracePeriod(1, 3);
}
private int applyGracePeriod(int amount, int grace) {
if (days > grace)
return amount + amount * (days - grace);
return amount;
}
}Red: We want to use applyGracePeriod for both the renter points and the fee, but the fee is a double, and the points are an int. Money should never be a double! So, we changed the fee into an int, and all the tests broke. We need to go back and fix all our tests.
public class CustomerTest {
private Customer customer;
@Before
public void setUp() throws Exception {
customer = new Customer();
}
private void assertFeeAndPoints(int fee, int points) {
assertEquals(fee, customer.getRentalFee());
assertEquals(points, customer.getRenterPoints());
}
@Test
public void RegularMovie_OneDay() throws Exception {
customer.addRental("RegularMovie", 1);
assertFeeAndPoints(150, 1);
}
@Test
public void RegularMovie_SecondAndThirdDayFree() throws Exception {
customer.addRental("RegularMovie", 2);
assertFeeAndPoints(150, 1);
customer.addRental("RegularMovie", 3);
assertFeeAndPoints(150, 1);
}
@Test
public void RegularMovie_FourDays() throws Exception {
customer.addRental("RegularMovie", 4);
assertFeeAndPoints(300, 2);
}
}Requirement 4: Children’s movies rent for $1.00 per day and earn 1 point.
Red: The first day business rule is simple:
@Test
public void ChildrensMovie_OneDay() throws Exception {
customer.addRental("ChildrensMovie", 1);
assertFeeAndPoints(100, 1);
}Green: It’s not hard to make this pass with some very ugly code.
public int getRentalFee() {
if (title.equals("RegularMovie"))
return applyGracePeriod(150, 3);
else
return 100;
}Refactor: But now we have to clean up that ugliness. There’s no way the type of the video should be coupled to the title, so let’s make a registry.
public class Customer {
private String title;
private int days;
private Map<String, VideoType> movieRegistry = new HashMap<>();
enum VideoType {REGULAR, CHILDRENS};
public Customer() {
movieRegistry.put("RegularMovie", REGULAR);
movieRegistry.put("ChildrensMovie", CHILDRENS);
}
public void addRental(String title, int days) {
this.title = title;
this.days = days;
}
public int getRentalFee() {
if (getType(title) == REGULAR)
return applyGracePeriod(150, 3);
else
return 100;
}
private VideoType getType(String title) {
return movieRegistry.get(title);
}
public int getRenterPoints() {
return applyGracePeriod(1, 3);
}
private int applyGracePeriod(int amount, int grace) {
if (days > grace)
return amount + amount * (days - grace);
return amount;
}
}That’s better, but it violates the single responsibility principle7 because the Customer class should not be responsible for initializing the registry. The registry should be initialized during early configuration of the system. Let’s separate that registry from Customer:
7 Robert C. Martin, Clean Architecture: A Craftsman’s Guide to Software Structure and Design (Addison-Wesley, 2018), 61ff.
public class VideoRegistry {
public enum VideoType {REGULAR, CHILDRENS}
private static Map<String, VideoType> videoRegistry = new HashMap<>();
public static VideoType getType(String title) {
return videoRegistry.get(title);
}
public static void addMovie(String title, VideoType type) {
videoRegistry.put(title, type);
}
}VideoRegistry is a monostate8 class, guaranteeing that there is only one instance. It is statically initialized by the test:
8 Robert C. Martin, Agile Software Development: Principles, Patterns, and Practices (Prentice Hall, 2003), 180ff.
@BeforeClass
public static void loadRegistry() {
VideoRegistry.addMovie("RegularMovie", REGULAR);
VideoRegistry.addMovie("ChildrensMovie", CHILDRENS);
}And this cleans up the Customer class a lot:
public class Customer {
private String title;
private int days;
public void addRental(String title, int days) {
this.title = title;
this.days = days;
}
public int getRentalFee() {
if (VideoRegistry.getType(title) == REGULAR)
return applyGracePeriod(150, 3);
else
return 100;
}
public int getRenterPoints() {
return applyGracePeriod(1, 3);
}
private int applyGracePeriod(int amount, int grace) {
if (days > grace)
return amount + amount * (days - grace);
return amount;
}
}Red: Note that requirement 4 said that customers earn 1 point for a children’s movie, not 1 point per day. So, the next test looks like this:
@Test
public void ChildrensMovie_FourDays() throws Exception {
customer.addRental("ChildrensMovie", 4);
assertFeeAndPoints(400, 1);
}I chose four days because of the 3 currently sitting as the second argument of the call to applyGracePeriod within the getRenterPoints method of the Customer. (Though we sometime feign naïveté while doing TDD, we do actually know what’s going on).
Green: With the registry in place, this is easily repaired.
public int getRenterPoints() {
if (VideoRegistry.getType(title) == REGULAR)
return applyGracePeriod(1, 3);
else
return 1;
}At this point, I want you to notice that there are no tests for the VideoRegistry class. Or, rather, no direct tests. VideoRegistry is, in fact, being tested indirectly because none of the passing tests would pass if VideoRegistry were not functioning properly.
Red: So far, our Customer class can handle only a single movie. Let’s make sure it can handle more than one:
@Test
public void OneRegularOneChildrens_FourDays() throws Exception {
customer.addRental("RegularMovie", 4); //$3+2p
customer.addRental("ChildrensMovie", 4); //$4+1p
assertFeeAndPoints(700, 3);
}Green: That’s just a nice little list and a couple of loops. It’s also nice to move the registry stuff into the new Rental class:
public class Customer {
private List<Rental> rentals = new ArrayList<>();
public void addRental(String title, int days) {
rentals.add(new Rental(title, days));
}
public int getRentalFee() {
int fee = 0;
for (Rental rental : rentals) {
if (rental.type == REGULAR)
fee += applyGracePeriod(150, rental.days, 3);
else
fee += rental.days * 100;
}
return fee;
}
public int getRenterPoints() {
int points = 0;
for (Rental rental : rentals) {
if (rental.type == REGULAR)
points += applyGracePeriod(1, rental.days, 3);
else
points++;
}
return points;
}
private int applyGracePeriod(int amount, int days, int grace) {
if (days > grace)
return amount + amount * (days - grace);
return amount;
}
}
public class Rental {
public String title;
public int days;
public VideoType type;
public Rental(String title, int days) {
this.title = title;
this.days = days;
type = VideoRegistry.getType(title);
}
}This actually fails the old test because Customer now sums up the two rentals:
@Test
public void RegularMovie_SecondAndThirdDayFree() throws Exception {
customer.addRental("RegularMovie", 2);
assertFeeAndPoints(150, 1);
customer.addRental("RegularMovie", 3);
assertFeeAndPoints(150, 1);
}We have to divide that test in two. That’s probably better anyway.
@Test
public void RegularMovie_SecondDayFree() throws Exception {
customer.addRental("RegularMovie", 2);
assertFeeAndPoints(150, 1);
}
@Test
public void RegularMovie_ThirdDayFree() throws Exception {
customer.addRental("RegularMovie", 3);
assertFeeAndPoints(150, 1);
}Refactor: There’s an awful lot I don’t like about the Customer class now. Those two ugly loops with the strange if statements inside them are pretty awful. We can extract a few nicer methods from those loops.
public int getRentalFee() {
int fee = 0;
for (Rental rental : rentals)
fee += feeFor(rental);
return fee;
}
private int feeFor(Rental rental) {
int fee = 0;
if (rental.getType() == REGULAR)
fee += applyGracePeriod(150, rental.getDays(), 3);
else
fee += rental.getDays() * 100;
return fee;
}
public int getRenterPoints() {
int points = 0;
for (Rental rental : rentals)
points += pointsFor(rental);
return points;
}
private int pointsFor(Rental rental) {
int points = 0;
if (rental.getType() == REGULAR)
points += applyGracePeriod(1, rental.getDays(), 3);
else
points++;
return points;
}Those two private functions seem to play more with the Rental than with the Customer. Let’s move them along with their utility function applyGracePeriod. This makes the Customer class much cleaner.
public class Customer {
private List<Rental> rentals = new ArrayList<>();
public void addRental(String title, int days) {
rentals.add(new Rental(title, days));
}
public int getRentalFee() {
int fee = 0;
for (Rental rental : rentals)
fee += rental.getFee();
return fee;
}
public int getRenterPoints() {
int points = 0;
for (Rental rental : rentals)
points += rental.getPoints();
return points;
}
}The Rental class has grown a lot and is much uglier now:
public class Rental {
private String title;
private int days;
private VideoType type;
public Rental(String title, int days) {
this.title = title;
this.days = days;
type = VideoRegistry.getType(title);
}
public String getTitle() {
return title;
}
public VideoType getType() {
return type;
}
public int getFee() {
int fee = 0;
if (getType() == REGULAR)
fee += applyGracePeriod(150, days, 3);
else
fee += getDays() * 100;
return fee;
}
public int getPoints() {
int points = 0;
if (getType() == REGULAR)
points += applyGracePeriod(1, days, 3);
else
points++;
return points;
}
private static int applyGracePeriod(int amount, int days, int grace) {
if (days > grace)
return amount + amount * (days - grace);
return amount;
}
}Those ugly if statements need to be gotten rid of. Every new type of video is going to mean another clause in those statements. Let’s head that off with some subclasses and polymorphism.
First, there’s the abstract Movie class. It’s got the applyGracePeriod utility and two abstract functions to get the fee and the points.
public abstract class Movie {
private String title;
public Movie(String title) {
this.title = title;
}
public String getTitle() {
return title;
}
public abstract int getFee(int days, Rental rental);
public abstract int getPoints(int days, Rental rental);
protected static int applyGracePeriod(int amount, int days, int grace) {
if (days > grace)
return amount + amount * (days - grace);
return amount;
}
}RegularMovie is pretty simple:
public class RegularMovie extends Movie {
public RegularMovie(String title) {
super(title);
}
public int getFee(int days, Rental rental) {
return applyGracePeriod(150, days, 3);
}
public int getPoints(int days, Rental rental) {
return applyGracePeriod(1, days, 3);
}
}ChildrensMovie is even simpler:
public class ChildrensMovie extends Movie {
public ChildrensMovie(String title) {
super(title);
}
public int getFee(int days, Rental rental) {
return days * 100;
}
public int getPoints(int days, Rental rental) {
return 1;
}
}There’s not much left of Rental—just a couple of delegator functions:
public class Rental {
private int days;
private Movie movie;
public Rental(String title, int days) {
this.days = days;
movie = VideoRegistry.getMovie(title);
}
public String getTitle() {
return movie.getTitle();
}
public int getFee() {
return movie.getFee(days, this);
}
public int getPoints() {
return movie.getPoints(days, this);
}
}The VideoRegistry class turned into a factory for Movie.
public class VideoRegistry {
public enum VideoType {REGULAR, CHILDRENS;}
private static Map<String, VideoType> videoRegistry = new HashMap<>();
public static Movie getMovie(String title) {
switch (videoRegistry.get(title)) {
case REGULAR:
return new RegularMovie(title);
case CHILDRENS:
return new ChildrensMovie(title);
}
return null;
}
public static void addMovie(String title, VideoType type) {
videoRegistry.put(title, type);
}
}And Customer? Well, it just had the wrong name all this time. It is really the RentalCalculator class. It is the class that protects our tests from the family of classes that serves it.
public class RentalCalculator {
private List<Rental> rentals = new ArrayList<>();
public void addRental(String title, int days) {
rentals.add(new Rental(title, days));
}
public int getRentalFee() {
int fee = 0;
for (Rental rental : rentals)
fee += rental.getFee();
return fee;
}
public int getRenterPoints() {
int points = 0;
for (Rental rental : rentals)
points += rental.getPoints();
return points;
}
}Now let’s look at a diagram of the result (Figure 4.10).
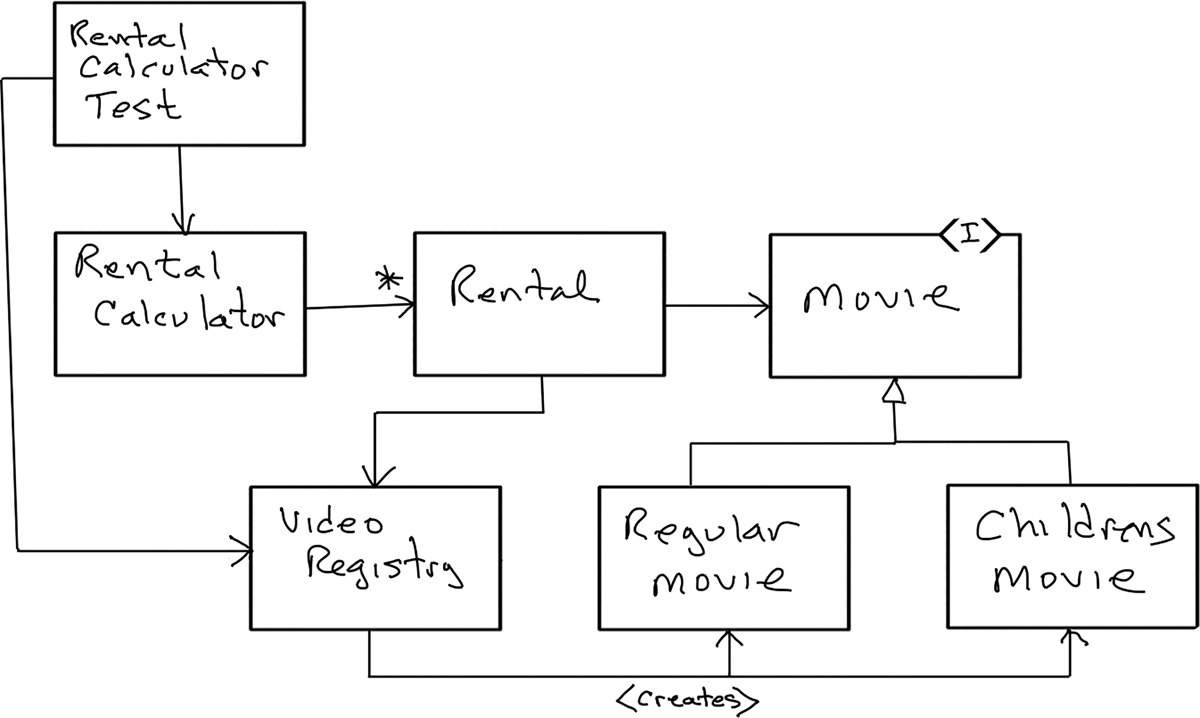
Figure 4.10 The result
As the code evolved, all those classes to the right of RentalCalculator were created by various refactorings. Yet RentalCalculatorTest knows nothing of them other than VideoRegistry, which it must initialize with test data. Moreover, no other test module exercises those classes. RentalCalculatorTest tests all those other classes indirectly. The one-to-one correspondence is broken.
This is the way that good programmers protect and decouple the structure of the production code from the structure of the tests, thereby avoiding the fragile test problem.
In large systems, of course, this pattern will repeat over and over. There will be many families of modules, each protected from the test modules that exercise them by their own particular facades or interface modules.
Some might suggest that tests that operate a family of modules through a facade are integration tests. We talk about integration tests later in this book. For now, I’ll simply point out that the purpose of integration tests is very different from the purpose of the tests shown here. These are programmer tests, tests written by programmers for programmers for the purpose of specifying behavior.
Specificity versus Generality
Tests and production code must be decoupled by yet another factor that we learned about in Chapter 2, when we studied the prime factors example. I wrote it as a mantra in that chapter. Now I’ll write it as a rule.
Rule 13: As the tests get more specific, the code gets more generic.
The family of production code modules grows as the tests grow. However, they evolve in very different directions.
As each new test case is added, the suite of tests becomes increasingly specific. However, programmers should drive the family of modules being tested in the opposite direction. That family should become increasingly general (Figure 4.11).

Figure 4.11 The suite of tests becomes more specific, while the family of modules being tested becomes more general.
This is one of the goals of the refactoring step. You saw it happening in the video store example. First a test case was added. Then some ugly production code was added to get the test to pass. That production code was not general. Often, in fact, it was deeply specific. Then, in the refactoring step, that specific code was massaged into a more general form.
This divergent evolution of the tests and the production code means that the shapes of the two will be remarkably different. The tests will grow into a linear list of constraints and specifications. The production code, on the other hand, will grow into a rich family of logic and behavior organized to address the underlying abstraction that drives the application.
This divergent style further decouples the tests from the production code, protecting the two from changes in the other.
Of course, the coupling can never be completely broken. There will be changes in one that force changes in the other. The goal is not to eliminate such changes but to minimize them. And the techniques described are effective toward that end.
Transformation Priority Premise
The previous chapters have led up to a fascinating observation. When we practice the discipline of TDD, we incrementally make the tests more specific, while we manipulate the production code to be ever more general. But how do these changes take place?
Adding a constraint to a test is a simple matter of either adding a new assertion to an existing test or adding a whole new test method to arrange, act, and then assert the new constraint. This operation is entirely additive. No existing test code is changed. New code is added.
Making the new constraint pass the tests, however, is very often not an additive process. Instead, the existing production code must be transformed to behave differently. These transformations are small changes to the existing code that alter the behavior of that code.
Then, of course, the production code is refactored in order to clean it up. These refactorings are also small changes to the production code, but in this case, they preserve the behavior.
Already you should see the correlation to the Red/Green/Refactor loop. The Red step is additive. The Green step is transformative. The Blue step is restorative.
We discuss the restorative refactorings in Chapter 5, “Refactoring.” Here, we discuss the transformations.
Transformations are small changes to the code that change behavior and simultaneously generalize the solution. The best way to explain this is with an example.
Recall the prime factors kata from Chapter 2. Early on, we saw a failing test and a degenerate implementation.
public class PrimeFactorsTest {
@Test
public void factors() throws Exception {
assertThat(factorsOf(1), is(empty()));
}
private List<Integer> factorsOf(int n) {
return null;
}
}We made the failing test pass by transforming the null into new ArrayList<>(), as follows:
private List<Integer> factorsOf(int n) {
return new ArrayList<>();
}That transformation changed the behavior of the solution but also generalized it. That null was extremely specific. ArrayList is more general than null.
The next failing test case also resulted in generalizing transformations:
assertThat(factorsOf(2), contains(2));
private List<Integer> factorsOf(int n) {
ArrayList<Integer> factors = new ArrayList<>();
if (n>1)
factors.add(2);
return factors;
}First, ArrayList was extracted to the factors variable, and then the if statement was added. Both of these transformations are generalizing. Variables are always more general than constants. However, the if statement is only partially generalizing. It is specific to the test because of the 1 and the 2, but it softens that specificity with the n>1 inequality. That inequality remained part of the general solution all the way to the end.
Armed with this knowledge, let’s look at some other transformations.
{} → Nil
This is usually the very first transformation employed at the start of a TDD session. We begin with no code at all. We write the most degenerate test we can think of. Then, to get it to compile and fail, we make the function we are testing return null,9 as we did in the prime factors kata.
9 Or the most degenerate allowed return value.
private List<Integer> factorsOf(int n) {
return null;
}This code transforms nothing into a function that returns nothing. Doing so seldom makes the failing test pass, so the next transformation usually follows immediately.
Nil → Constant
Again, we see this in the prime factors kata. The null we returned is transformed into an empty list of integers.
private List<Integer> factorsOf(int n) {
return new ArrayList<>();
}We also saw this in the bowling game kata in Chapter 2, though in that case, we skipped the {} → Nil transformation and went straight to the constant.
public int score() {
return 0;
}Constant->Variable
This transformation changes a constant into a variable. We saw this in the stack kata (Chapter 2) when we created the empty variable to hold the true value that isEmpty had been returning.
public class Stack {
private boolean empty = true;
public boolean isEmpty() {
return empty;
}
. . .
}We saw this again in prime factors when, in order to pass the case for factoring 3, we replaced the constant 2 with the argument n.
private List<Integer> factorsOf(int n) {
ArrayList<Integer> factors = new ArrayList<>();
if (n>1)
factors.add(n);
return factors;
}At this point, it should be obvious that every one of these transformations, so far, moves the code from a very specific state to a slightly more general state. Each of them is a generalization, a way to make the code handle a wider set of constraints than before.
If you think about it carefully, you’ll realize that each of these transformations widens the possibilities much more than the constraint placed on the code by the currently failing test. Thus, as these transformations are applied, one by one, the race between the constraints of the tests and the generality of the code must end in favor of the generalizations. Eventually, the production code will become so general that it will pass all future constraints within the current requirements.
But I digress.
Unconditional → Selection
This transformation adds an if statement, or the equivalent. This is not always a generalization. Programmers must take care not to make the predicate of the selection specific to the currently failing test.
We saw this transformation in the prime factors kata when we needed to factor the number 2. Note that the predicate of the if statement in that kata was not (n==2); that would have been too specific. The (n>1) inequality was an attempt to keep the if statement more general.
private List<Integer> factorsOf(int n) {
ArrayList<Integer> factors = new ArrayList<>();
if (n>1)
factors.add(2);
return factors;
}Value → List
This generalizing transformation changes a variable that holds a single value into a list of values. The list could be an array or a more complex container. We saw this transformation in the stack kata when we changed the element variable into the elements array.
public class Stack {
private int size = 0;
private int[] elements = new int[2];
public void push(int element) {
this.elements[size++] = element;
}
public int pop() {
if (size == 0)
throw new Underflow();
return elements[--size];
}
}Statement → Recursion
This generalizing transformation changes a single statement into a recursive statement, in lieu of a loop. These kinds of transformations are very common in languages that support recursion, especially those like Lisp and Logo that have no looping facilities other than recursion. The transformation changes an expression that is evaluated once into an expression that is evaluated in terms of itself. We saw this transformation in the word-wrap kata in Chapter 3, “Advanced TDD.”
private String wrap(String s, int w) {
if (w >= s.length())
return s;
else
return s.substring(0, w) + "
" + wrap(s.substring(w), w);
}Selection → Iteration
We saw this several times in the prime factors kata when we converted those if statements into while statements. This is clearly a generalization because iteration is the general form of selection, and selection is merely degenerate iteration.
private List<Integer> factorsOf(int n) {
ArrayList<Integer> factors = new ArrayList<>();
if (n > 1) {
while (n % 2 == 0) {
factors.add(2);
n /= 2;
}
}
if (n > 1)
factors.add(n);
return factors;
}Value → Mutated Value
This transformation mutates the value of a variable, usually for the purpose of accumulating partial values in a loop or incremental computation. We saw this in in several of the katas but perhaps most significantly in the sort kata in Chapter 3.
Note that the first two assignments are not mutations. The first and second values are simply initialized. It is the list.set(...) operations that are the mutations. They actually change the elements within the list.
private List<Integer> sort(List<Integer> list) {
if (list.size() > 1) {
if (list.get(0) > list.get(1)) {
int first = list.get(0);
int second = list.get(1);
list.set(0, second);
list.set(1, first);
}
}
return list;
}Example: Fibonacci
Let’s try a simple kata and keep track of the transformations. We’ll do the tried and true Fibonacci kata. Remember that fib(0) = 1, fib(1) = 1, and fib(n) = fib(n-1) + fib(n-2).
We begin, as always, with a failing test. If you are wondering why I’m using BigInteger, it is because Fibonacci numbers get big very quickly.
public class FibTest {
@Test
public void testFibs() throws Exception {
assertThat(fib(0), equalTo(BigInteger.ONE));
}
private BigInteger fib(int n) {
return null;
}
}We can make this pass by using the Nil → Constant transformation.
private BigInteger fib(int n) {
return new BigInteger("1");
}Yes, I thought the use of the String argument was odd too; but that’s the Java library for you.
The next test passes right out of the box:
@Test
public void testFibs() throws Exception {
assertThat(fib(0), equalTo(BigInteger.ONE));
assertThat(fib(1), equalTo(BigInteger.ONE));
}The next test fails:
@Test
public void testFibs() throws Exception {
assertThat(fib(0), equalTo(BigInteger.ONE));
assertThat(fib(1), equalTo(BigInteger.ONE));
assertThat(fib(2), equalTo(new BigInteger("2")));
}We can make this pass by using Unconditional → Selection:
private BigInteger fib(int n) {
if (n > 1)
return new BigInteger("2");
else
return new BigInteger("1");
}This is perilously close to being more specific than general, though it titillates me with the potential for negative arguments to the fib function.
The next test tempts us to go for the gold:
assertThat(fib(3), equalTo(new BigInteger("3")));The solution uses Statement → Recursion:
private BigInteger fib(int n) {
if (n > 1)
return fib(n-1).add(fib(n-2));
else
return new BigInteger("1");
}This is a very elegant solution. It’s also horrifically expensive in terms of time10 and memory. Going for the gold too early often comes at a cost. Is there another way we could have done that last step?
10 fib(40) == 165580141 took nine seconds to compute on my 2.3GHz MacBook Pro.
Of course there is:
private BigInteger fib(int n) {
return fib(BigInteger.ONE, BigInteger.ONE, n);
}
private BigInteger fib(BigInteger fm2, BigInteger fm1, int n) {
if (n>1)
return fib(fm1, fm1.add(fm2), n-1);
else
return fm1;
}This is a nice tail-recursive algorithm that is tolerably fast.11
11 fib(100)==573147844013817084101 in 10ms.
You might think that last transformation was just a different application of Statement → Recursion, but it wasn’t. It was actually Selection → Iteration. In fact, if the Java compiler would deign to offer us tail-call-optimization,12 it would translate almost exactly to the following code. Note the implied if->while.
12 Java, Java, wherefore art thou Java?
private BigInteger fib(int n) {
BigInteger fm2 = BigInteger.ONE;
BigInteger fm1 = BigInteger.ONE;
while (n>1) {
BigInteger f = fm1.add(fm2);
fm2 = fm1;
fm1 = f;
n--;
}
return fm1;
}I took you on that little diversion to make an important point:
Rule 14: If one transformation leads you to a suboptimal solution, try a different transformation.
This is actually the second time we have encountered a situation in which a transformation led us to a suboptimal solution and a different transformation produced much better results. The first time was back in the sort kata. In that case, it was the Value → Mutated Value transformation that led us astray and drove us to implement a bubble sort. When we replaced that transformation with Unconditional → Selection, we wound up implementing a quick sort. Here was the critical step:
private List<Integer> sort(List<Integer> list) {
if (list.size() <= 1)
return list;
else {
int first = list.get(0);
int second = list.get(1);
if (first > second)
return asList(second, first);
else
return asList(first, second);
}
}The Transformation Priority Premise
As we have seen, there are sometimes forks in the road as we are following the three laws of TDD. Each tine of a fork uses a different transformation to make the currently failing test pass. When faced with such a fork, is there a way to choose the best transformation to use? Or, to say this differently, is one transformation better than another in every case? Is there a priority to the transformations?
I believe there is. I’ll describe that priority to you in just a moment. However, I want to make it clear that this belief of mine is only a premise. I have no mathematical proof, and I am not sure that it holds in every case. What I am relatively certain of is that you are likely to wind up at better implementations if you choose the transformations in something like the following order:
• {} → Nil
• Nil → Constant
• Constant → Variable
• Unconditional → Selection
• Value → List
• Statement → Recursion
• Selection → Iteration
• Value → Mutated Value
Don’t make the mistake of thinking that the order here is natural and immune to violation. (e.g., that Constant → Variable cannot be used until Nil → Constant has been completed.) Many programmers might make a test pass by transforming Nil to a Selection of two constants without going through the Nil → Constant step.
In other words, if you are tempted to pass a test by combining two or more transformations, you may be missing one or more tests. Try to find a test that can be passed by using just one of these transformations. Then, when you find yourself at a fork in the road, first choose the tine of that fork that can be passed by using the transformation that is higher on the list.
Does this mechanism always work? Probably not, but I’ve had pretty good luck with it. And as we’ve seen, it gave us better results for both the sort and the Fibonacci algorithms.
Astute readers will have realized by now that following the transformations in the specified order will lead you to implement solutions using the functional programming style.
Conclusion
This concludes our discussion of the discipline of TDD. We’ve covered a lot of ground in the last three chapters. In this chapter, we talked about the problems and patterns of test design. From GUIs to databases, from specifications to generalities, and from transformations to priorities.
But, of course, we’re not done. There’s the fourth law to consider: refactoring. That’s the topic of the next chapter.