
The basis of Clojure's concurrency is its STM system. Basically, this extends the semantics of database transactions to the computer's memory.
For this recipe, we'll use the STM to calculate the families per housing unit from a piece of U.S. census data. We'll use future-call to perform the calculations in the thread pool and spread the execution over multiple cores. Afterwards, we'll go into more detail about how the STM works in general, and how it's applied in this particular recipe.
To prepare for this recipe, we first need to list our dependencies in the Leiningen project.clj file:
(defproject concurrent-data "0.1.0-SNAPSHOT"
:dependencies [[org.clojure/clojure "1.6.0"]
[org.clojure/data.csv "0.1.2"]])We also need to import these dependencies to our script or REPL:
(require '[clojure.java.io :as io]
'[clojure.data.csv :as csv])Finally, we need to have our data file. I downloaded one of the bulk data files from the Investigative Reporters and Editors' U.S. census site at http://census.ire.org/data/bulkdata.html. The data in this recipe will use the family census data for Virginia. I've also uploaded this data at http://www.ericrochester.com/clj-data-analysis/data/all_160_in_51.P35.csv. You can easily download it from here and save it to a directory named data. Let's bind the filename to a variable for easy access:
(def data-file "data/all_160_in_51.P35.csv")
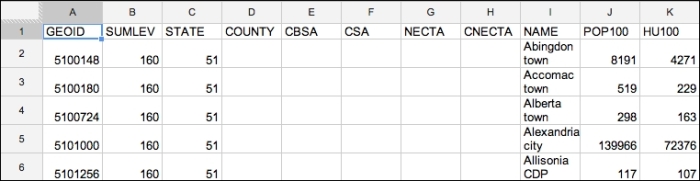
Here's the data file, opened in a spreadsheet, and showing the first few rows:
For this recipe, we'll read in the data, break it into chunks, and use separate threads to total the number of housing units and the number of families in each chunk. Each chunk will add its totals to some global references:
- We need to define two references that the STM will manipulate: one for the total of housing units and one for families:
(def total-hu (ref 0)) (def total-fams (ref 0))
- Now, we'll need a couple of utility functions to safely read a CSV file to a lazy sequence. The first is
lazy-read-csvfrom the Lazily processing very large data sets recipe in Chapter 2, Cleaning and Validating Data. We'll also define a new function,with-header, that uses the first row to create maps from the rest of the rows in the dataset:(defn with-header [coll] (let [headers (map keyword (first coll))] (map (partial zipmap headers) (next coll)))) - Next, we'll define some utility functions. One (
->int) will convert a string into an integer. Another (sum-item) will calculate the running totals for the fields we're interested in. A third function (sum-items) will calculate the sums from a collection of data maps:(defn ->int [i] (Integer. i)) (defn sum-item ([fields] (partial sum-item fields)) ([fields accum item] (mapv + accum (map ->int (map item fields))))) (defn sum-items [accum fields coll] (reduce (sum-item fields) accum coll))
- We can now define the function that will actually interact with the STM. The
update-totalsfunction takes a list of fields that contains the housing unit and family data and a collection of items. It will total the fields in the parameter with the items passed into the function and update the STM references with them:(defn update-totals [fields items] (let [mzero (mapv (constantly 0) fields) [sum-hu sum-fams] (sum-items mzero fields items)] (dosync (alter total-hu #(+ sum-hu %)) (alter total-fams #(+ sum-fams %))))) - In order to call this function with
future-call, we'll write a function to create a thunk (a function created to assist in calling another function). It will just callupdate-totalswith the parameters we give:(defn thunk-update-totals-for [fields data-chunk] (fn [] (update-totals fields data-chunk)))
- With all this in place, we can define a main function that controls the entire process and returns the ratio of families to housing units:
(defn main ([data-file] (main data-file [:HU100 :P035001] 5)) ([data-file fields chunk-count] (doall (->> (lazy-read-csv data-file) with-header (partition-all chunk-count) (map (partial thunk-update-totals-for fields)) (map future-call) (map deref))) (float (/ @total-fams @total-hu))))
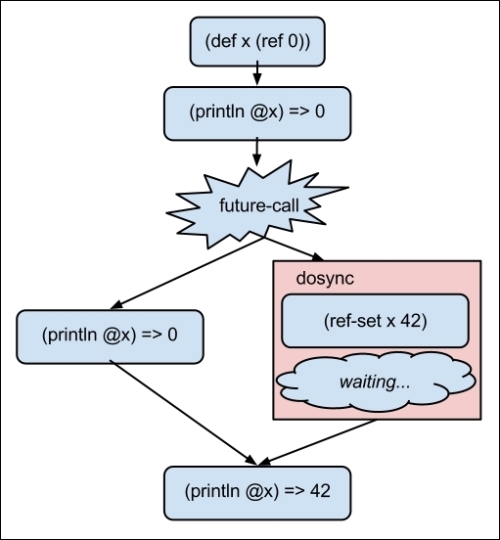
In general, the way the STM works is as follows. First, we mark memory locations to be controlled by the STM using the ref function. We can then dereference them anywhere using the deref function or the @ macro, but we can only change the values of a reference inside a dosync block. Then, when the point of execution gets to the end of a transaction, the STM performs a check. If any of the references that the transaction altered have been changed by another transaction, the current transaction fails and it's queued to be tried again. However, if none of the references have changed, then the transaction succeeds and is committed.
While we're in the transaction, those values don't appear to have changed to the code outside it. Once the transaction is committed, then any changes we make to those locations with ref-set or alter will be visible outside that block, as shown in the following diagram:
Note the following warnings:
- With the STM, we should use only Clojure's native, immutable data types. This sounds restrictive, but in practice, it isn't a big deal. Clojure has a rich and flexible collection of data types.
- We should also limit how much we try to do in each transaction. We only want to bundle together operations that truly must pass or fail as a collection. This keeps transactions from being retried too much, which can hurt performance.
The STM helps us manage complexity by allowing us to divide our processing in a way that makes the most sense to us, and then to run those processes concurrently. The STM, together with the immutable state, keeps this system simple and easy to reason about.
In this particular recipe, the first reference to the STM is in the definitions of total-hu and total-fams. Each of these is a reference, initially set to zero.
The update-totals function contains the dosync that updates the references. It uses alter, which takes the reference and a function that updates the value. Because of the dosync, if either of these values is changed in another thread that is summing another chunk of data, the call to dosync is repeated. That's why we calculate the items' totals before we enter that block.
Finally, in main, we partition the data into chunks, then package the calls to update-totals for each chunk of data into a thunk, and run it in Clojure's thread pool using future-call, calling deref on future blocks until the value is returned from the thread pool.
We wrap this process in a call to doall to make sure that all of the processing is completed. Remember that sequences are lazy by default, so without doall, the sequence started by lazy-read-csv and ending in the series of map calls would be garbage collected before any work would be done. The future-call and deref functions would never actually be called. The @ macros in the last line would return the values of these references as originally set in the def calls (both zero). The doall simply forces all of the processing to be done before we get to the last line.
As this recipe shows, Clojure provides a lot of easy concurrency without having to worry about synchronizing values, locks, monitors, semaphores, or any of the other things that make threads and concurrency difficult and painful.