
Benchmarking can be an important part of the data analysis process. Especially when faced with very large datasets that need to be processed in multiple ways, choosing algorithms that will finish in a reasonable amount of time is important. Benchmarking gives us an empirical basis on which to make these decisions.
For some of the recipes in this chapter, we've used the Criterium library (https://github.com/hugoduncan/criterium). Why will we want to go to the trouble of using an entire library just to see how fast our code is?
Generally, when we want to benchmark our code, we often start by using something similar to the time macro. This means:
- Get the start time.
- Execute the code.
- Get the end time.
If you've done this often, you will realize that this has a number of problems, especially for benchmarking small functions that execute quickly. The times are often inconsistent, and they can be dependent on a number of factors that are external to your program, such as the memory or disk cache. Using this benchmarking method often ends up being an exercise in frustration.
Fortunately, Criterium takes care of all of this. It makes sure that the caches are warmed up, runs your code multiple times, and presents a statistical look at the execution times.
This presents more information than just a single raw time. It also presents a lot of other useful information, such as how much time is spent in garbage collection.
For this recipe, we'll take the functions that we created to do the Monte Carlo pi estimates in the Using type hints recipe, and compare the timings we get with the time macro against those we get from Criterium.
To use Criterium, we just need to add it to the list of dependencies in our project.clj file:
(defproject parallel-data ""0.1.0""
:dependencies [[org.clojure/clojure ""1.6.0""]
[criterium ""0.4.3""]])We need to use it in our script or REPL:
(use 'criterium.core)
We'll also need the code the benchmark, which means the mc-pi and mc-pi-hint functions from the Using type hints recipe along with their dependencies.
First, let's look at the results of running the time macro several times on each function. Here's how we do it once:
user=> (time (mc-pi 1000000)) ""Elapsed time: 1304.007 msecs"" 3.14148
The following chart shows the results of all five calls on each:
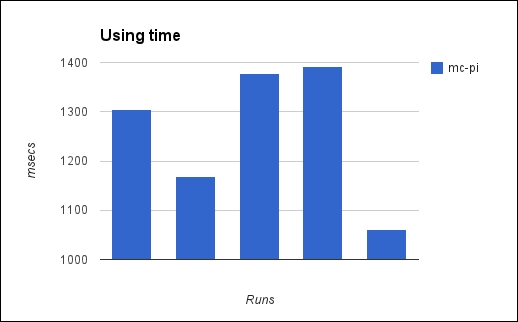
You can see that the results are all over the map. It's difficult to say how to synthesize these results without losing some information that might be important.
For comparison, here are the results with Criterium:
user=> (bench (mc-pi 1000000))
WARNING: Final GC required 1.6577782102371632 % of runtime
Evaluation count : 120 in 60 samples of 2 calls.
Execution time mean : 1.059337 sec
Execution time std-deviation : 61.159841 ms
Execution time lower quantile : 963.110499 ms ( 2.5%)
Execution time upper quantile : 1.132513 sec (97.5%)
Overhead used : 1.788607 ns
Found 1 outliers in 60 samples (1.6667 %)
low-severe 1 (1.6667 %)
Variance from outliers : 43.4179 % Variance is moderately inflated by outliersThe results are immediately clear (without having to type them into a spreadsheet, which I did to create the chart), and there's a lot more information given.
So, how does Criterium help us? First, it runs the code several times, and just throws away the results. This means that we don't have to worry about initial inconsistencies while the JVM, memory cache, and disk cache get settled.
Second, it runs the code a lot more than five times. Quick benchmarking runs it six times. Standard benchmarking runs it sixty times. This gives us a lot more data and a lot more confidence in our interpretation.
Third, it provides us with a lot more information about the runs. With time, we have to eyeball the results and go with our gut instinct for what all those numbers mean. If we want to be more precise, we can retype all of the numbers into a spreadsheet and generate some statistics. Criterium does that for us. It also analyzes the results to tell us whether some outliers are throwing off the statistics. For instance, in the results mentioned previously, we can see that there was one low outlier.
Criterium gives us a much better basis on which to make decisions about how best to optimize our code and improve its performance.
We've really just touched the surface of the functionality that Criterium provides and the functions it exports. For more information about this fantastic library, see the documentation at https://github.com/hugoduncan/criterium.