
Chapter 6. Diego
Diego is the container runtime architecture for Cloud Foundry. It is responsible for managing the scheduling, orchestration, and running of containerized workloads. Essentially, it is the heart of Cloud Foundry, running your applications and one-off tasks in containers, hosted on Windows and Linux backends. Most Cloud Foundry users (e.g., developers) do not interact with Diego directly. Developers interact only with Cloud Foundry’s API, known as CAPI. However, comprehending the Diego container runtime is essential for Platform Operators because, as an operator, you are required to interact with Diego for key considerations such as resilience requirements and application troubleshooting. Understanding Diego is essential for understanding how workloads are deployed, run, and managed. This understanding also provides you with an appreciation of the principles underpinning container orchestration.
This chapter explores Diego’s concepts and components. It explains the purpose of each Diego service, including how the services interrelate as state changes throughout the system.
Implementation Changes
It is important to understand the fundamental concepts of the Diego system. The specific technical implementation is less consequential because it is subject to change over time. What Diego does is more important than how it does it.
Why Diego?
Residing at the core of Cloud Foundry, Diego handles the scheduling, running, and monitoring of tasks and long-running processes (applications) that reside inside managed containers. Diego extends the traditional notion of running applications to scheduling and running two types of processes:
- Task
-
A process that is guaranteed to be run at most once, with a finite duration. A Task might be an app-based script or a Cloud Foundry “job”; for example, a staging request to build an application droplet.
- Long-running process (LRP)
-
An LRP runs continuously and may have multiple instances. Cloud Foundry dictates to Diego the desired number of instances for each LRP, encapsulated as DesiredLRPs. All of these desired instances are run and represented as actual LRPs known as ActualLRPs. Diego attempts to keep the correct number of ActualLRPs running in the face of any network partitions, crashes, or other failures. ActualLRPs only terminate due to intervention, either by crashing or being stopped or killed. A typical example of an ActualLRP is an instance of an application running on Cloud Foundry.
Cloud Foundry is no longer solely about the application as a unit of work. The addition of running one-off tasks in isolation opens up the platform to a much broader set of workloads; for example, running Bash scripts or Cron-like jobs to process a one-off piece of data. Applications can also spawn and run tasks for isolated computation. Tasks can also be used for local environmental adjustments to ensure that applications adhere to service-level agreements (SLAs).
The required scope for what Cloud Foundry can run is ever increasing as more workloads migrate to the platform. Tasks and LRPs, along with the new TCPRouter (discussed in “The TCPRouter”), have opened up the platform to accommodate a much broader set of workloads. In addition to traditional web-based applications, you can now consider Cloud Foundry for the following:
-
Internet of Things (IoT) applications such as aggregating and processing device data
-
Batch applications
-
Applications with application tasks
-
Computational numerical modeling
-
Reactive streaming applications
-
TCP-based applications
By design, Diego is agnostic to preexisting Cloud Foundry components such as the Cloud Controller. This separation of concerns is compelling. Being agnostic to both client interaction and runtime implementation has allowed for diverse workloads with composable backends. For example, Diego has generalized the way container image formats are handled; Diego’s container management API is Garden.
Through Garden, Diego can now support any container image format that the Garden API supports. Diego still supports the original droplet plus a stack combination but can now accommodate other image formats; for example, OCI-compatible images such as Docker or Rocket. In addition, Diego has added support for running containers on any Garden-based container technology, including Linux and Windows-based container backends that implement the Garden API. Figure 6-1 illustrates Diego’s ability to support multiple application artifacts and container image formats.

Figure 6-1. Developer interaction, cf pushing different application artifacts to Cloud Foundry
A Brief Overview of How Diego Works
Container scheduling and orchestration is a complex topic. Diego comprises several components, and each component comprises one or more microservices. Before getting into detail about these components and services, it is worth taking a moment to introduce the end-to-end flow of the Diego component interactions. At this point, I will begin to introduce specific component names for readability. The individual component responsibilities will be explained in detail in “Diego Components”.
At its core, Diego executes a scheduler. Scheduling is a method by which work, specified by some means, is assigned to resources that attempt to undertake and complete that work.
A Tip on Scheduling
Schedulers are responsible for using resources in such a way so as to allow multiple users to share system resources effectively while maintaining a targeted quality of service. Scheduling is an intrinsic part of the execution model of a distributed system. Scheduling makes it possible to have distributed multitasking spread over different nodes, with a centralized component responsible for processing. Within OSs, this processing unit is referred to as a CPU. Within Cloud Foundry, Diego acts as a centralized processing unit for all scheduling requirements.
Diego clients—in our case, the Cloud Controller (via a bridge component known as the CC-Bridge)—submit, update, and retrieve Tasks and LRPs to the BBS. The BBS service is responsible for Diego’s central data store and API. Communication from the Cloud Controller to the BBS is via a remote procedure call (RPC)–style API implemented though Google protocol buffers.
The scheduler within Diego is governed by Diego’s Brain component. The Brain’s orchestration function, known as the Auctioneer service, retrieves information from the BBS and optimally distributes Tasks and LRPs to the cluster of Diego Cell machines (typically VMs). The Auctioneer distributes its work via an auction process that queries Cells for their capacity to handle the work and then sends work to the Cells. After the Auctioneer assigns work to a Cell, the Cell’s Executor process creates a Garden container and executes the work encoded in the Task/LRP. This work is encoded as a generic, platform-independent recipe of composable actions (described in “Composable Actions”). Composable actions are the actual actions that run within a container; for example, a RunAction that runs a process in the container, or a DownloadAction that fetches and extracts an archive into the container. To assist in setting up the environment for the process running within the container, Application Life-Cycle Binaries (e.g., Buildpacks) are downloaded from a file server that is responsible for providing static assets.
Application Life-Cycle Binaries
Staging is the process that takes an application and composes a executable binary known as a droplet. Staging is discussed further in “Staging”. The process of staging and running an application is complex and filled with OS and container implementation-specific requirements. These implementation-specific concerns have been encapsulated in a collection of binaries known collectively as the Application Life-Cycle. The Tasks and LRPs produced by the CC-Bridge download the Application Life-Cycle Binaries from a blobstore (in Cloud Foundry’s case, the Cloud Controller blobstore). These Application Life-Cycle Binaries are helper binaries used to stage, start, and health-check Cloud Foundry applications. You can read more about Application Life-Cycle Binaries in “Application Life-Cycle Binaries”.
Diego ensures that the actual LRP (ActualLRP) state matches the desired LRP (DesiredLRP) state through interaction with its client (the CC-Bridge). Specific services on the CC-Bridge are responsible for keeping the Cloud Controller and Diego synchronized, ensuring domain freshness.1
The BBS also provides a real-time representation of the state of the Diego cluster (including all DesiredLRPs, running ActualLRP instances, and in-flight Tasks). The Brain’s Converger periodically analyzes snapshots of this representation and corrects discrepancies, ensuring that Diego is eventually consistent. This is a clear example of Diego using a closed feedback loop to ensure that its view of the world is accurate. Self-healing is the first essential feature of resiliency; a closed feedback loop ensures that eventual consistency continues to match the ever-changing desired state.
Diego sends real-time streaming logs for Tasks/LRPs to the Loggregator system. Diego also registers its running LRP instances with the GoRouter via the Route-Emitter, ensuring external web traffic can be routed to the correct container.
Essential Diego Concepts
Before exploring Diego’s architecture and component interaction, you need to be aware of two fundamental Diego concepts:
-
Action abstraction
-
Composable actions
As work flows through the distributed system, Diego components describe their actions using different levels of abstraction. Diego can define different abstractions because the architecture is not bound by a single entity; for example, a single monolithic component with a static data schema. Rather, Diego consists of distributed components that each host one or more microservices. Although microservices architecture is no panacea, if designed correctly for appropriate use cases, microservices offer significant advantages by decoupling complex interactions. Diego’s microservices have been composed with a defined boundary and are scoped to a specific component. Furthermore, Diego establishes well-defined communication flows between its component services. This is vital for a well designed system.
Action Abstraction
Because each microservice is scoped to a specific Diego component, each service is free to express its work using its own abstraction. This design is incredibly powerful because bounded abstractions offer an unprecedented degree of flexibility. Abstraction levels move from course high-level abstractions to fine-grained implementations as work moves through the system. For example, work can begin its journey at the Cloud Controller as an app, but ultimately all work ends up as a scheduled process running within a created container. This low-level implementation of a scheduled process is too specific to be hardwired into every Diego component. If it were hardwired throughout, the distributed system would become incredibly complex for end users and brittle to ongoing change. The abstraction boundaries provides two key benefits:
Plug-and-play offers the freedom to replace key parts of the system when required, without refactoring the core services. A great example of this is a pluggable container implementation. Processes can be run via a Docker image, a droplet plus a stack, or in a Windows container. The required container implementation (both image format and container backend) can be plugged into Diego as required without refactoring the other components.
Moreover, clients of Diego have high-level concerns. Clients should not need to be concerned with underlying implementation details such as how containers (or, more specifically, process isolation) are created in order to run their applications. Clients operate at a much higher level of abstraction, imperatively requesting “run my application.” They are not required to care about any of the underlying implementation details. This is one of the core benefits of utilizing a platform to drive application velocity. The more of the undifferentiated heavy lifting you allow the platform to undertake, the faster your business code will progress.
Composable Actions
At the highest level of abstraction, the work performed by a Task or LRP is expressed in terms of composable actions, exposed via Diego’s public API. As described earlier, composable actions are the actual actions that run within a container; for example, a RunAction that runs a process in the container, or a DownloadAction that fetches and extracts an archive into the container.
Conceptually each composable action implements a specific instruction. A set of composable actions can then be used to describe an explicit imperative action, such as “stage my application” or “run my application.”2 Composable actions are, by and large, hidden from Cloud Foundry users. Cloud Foundry users generally interact only with the Cloud Controller. The Cloud Controller (via the CC-Bridge) then interacts with Diego through Diego’s composable actions. However, even though as a Platform Operator you do not interact with composable actions directly, it is essential that you understand the available composable actions when it comes to debugging Cloud Foundry. For example, the UploadAction might fail due to misconfigured blobstore credentials, or a TimeoutAction might fail due to a network partition.
Composable actions include the following:
-
RunAction runs a process in the container.
-
DownloadAction fetches an archive (.tgz or .zip) and extracts it into the container.
-
UploadAction uploads a single file, in the container, to a URL via POST.
-
ParallelAction runs multiple actions in parallel.
-
CodependentAction runs multiple actions in parallel and will terminate all codependent actions after any single action exits.
-
SerialAction runs multiple actions in order.
-
EmitProgressAction wraps another action and logs messages when the wrapped action begins and ends.
-
TimeoutAction fails if the wrapped action does not exit within a time interval.
-
TryAction runs the wrapped action but ignores errors generated by the wrapped action.
Because composable actions are a high-level Diego abstraction, they describe generic activity, not how the activity is actually achieved. For example, the UploadAction describes uploading a single file to a URL; it does not specify that the URL should be the Cloud Controller’s blobstore. Diego, as a generic execution environment, does not care about the URL; Cloud Foundry, as a client of Diego, is the entity responsible for defining that concern. This concept ties back to the action abstraction discussed previously, allowing Diego to remain as an independently deployable subsystem, free from specific end-user concerns.
So, how do composable actions relate to the aforementioned Cloud Foundry Tasks and LRPs? Consider the steps involved when the Cloud Controller issues a run command for an already staged application. To bridge the two abstractions, there is a Cloud Foundry-to-Diego bridge component known as the Cloud Controller Bridge (CC-Bridge). This essential function is discussed at length in “The CC-Bridge”. For now, it is sufficient to know that the CC-Bridge knows how to take the various resources (e.g., a droplet, metadata ,and blobstore location) that the Cloud Controller provides, coupled with a desired application message. Then, using these composable actions, the CC-Bridge directs Diego to build a sequence of composable actions to run the droplet within the container, injecting the necessary information provided by the Cloud Controller. For example, the specific composable action sequence for a run command will be:
-
DownLoadAction to download the droplet from the CC blobstore into a specified location inside the container.
-
DownLoadAction to download the set of static plugin (AppLifeCycle) binaries from a file server into a specified location within the container.
-
RunAction to run the start command in the container, with the correct parameters. RunAction ensures that the container runs the code from the droplet using the helper (AppLifeCycle) binaries that correctly instantiate the container environment.
Applications are broken into a set of Tasks such as “stage an app” and “run an app.” All Diego Tasks will finally result in a tree of composable actions to be run within a container.
Layered Architecture
Diego is comprised of a number of microservices residing on several components. Diego is best explained by initially referring to the diagram in Figure 6-2.

Figure 6-2. Diego components
We can group the components broadly, as follows:
-
A Cloud Foundry layer of user-facing components (components with which you, as a platform user, will directly interact)
-
The Diego Container Runtime layer (components with which the core Cloud Foundry components interact)
Each Diego component is a single deployable BOSH machine (known as an instance group) that can have any number of machine instances. Although there can be multiple instances of each instance group to allow for HA and horizontal scaling, some instance groups require a global lock to ensure that only one instance is allowed to make decisions.
We will begin exploring Diego by looking at the user-facing Cloud Foundry components that act as a client to Diego, and then move on to the specific Diego components and services.
Interacting with Diego
Cloud Foundry users do not interact with Diego directly; they interact with the Cloud Foundry user-facing components, which then interact with Diego on the user’s behalf. Here are the Cloud Foundry user-facing components that work in conjunction with Diego:
-
CAPI components: the Cloud Foundry API (Cloud Controller and the CC-Bridge)
-
The logging system defined by the Loggregator and Metron agents
-
Routing (GoRouter, TCPRouter, and the Route-Emitter)
Collectively, these Cloud Foundry components are responsible for the following:
-
Application policy
-
Uploading application artifacts, droplets, and metadata to a blobstore
-
Traffic routing and handling application traffic
-
Logging
-
User management including end-user interaction via the Cloud Foundry API commands4
Diego seamlessly hooks into these different Cloud Foundry components to run applications and tasks, route traffic to your applications, and allow the retrieval of required logs. With the exception of the CC-Bridge, these components were discussed at length in Chapter 3.
CAPI
Diego Tasks and LRPs are submitted to Diego via a Diego client. In Cloud Foundry’s case, the Diego client is the CAPI, exposed by the Cloud Controller. Cloud Foundry users interact with the Cloud Controller through the CAPI. The Cloud Controller then interacts with Diego’s BBS via the CC-Bridge, a Cloud Foundry-to-Diego translation layer. This interaction is depicted in Figure 6-3.

Figure 6-3. API interaction from the platform user through to Diego
The Cloud Controller provides REST API endpoints for Cloud Foundry users to interact with Cloud Foundry for commands including the following:
-
Pushing, staging, running, and updating
-
Pushing and running discrete one-off tasks
-
Creating users, Orgs, Spaces, Routes, Domains and Services, and so on
-
Retrieving application logs
The Cloud Controller (discussed in “The Cloud Controller”) is concerned with imperatively dictating policy to Diego, stating “this is what the user desires; Diego, make it so!”; for example, “run two instances of this application.” Diego is responsible for orchestrating and executing the required workload. It deals with orchestration through a more autonomous subsystem at the backend. For example, Diego deals with the orchestration of the Cells used to fulfill a workload request through an auction process governed by the Auctioneer.
This design means that the Cloud Controller is not coupled to the execution machines (now known as Cells) that run your workload. The Cloud Controller does not talk to Diego directly; instead, it talks only to the translation component, the CC-Bridge, which translates the Cloud Controller’s app-specific messages to the more generic Diego language of Tasks and LRPs. The CC-Bridge is discussed in-depth in “The CC-Bridge”. As just discussed, this abstraction allows the Cloud Foundry user to think in terms of apps and tasks, while allowing each Diego service to express its work in a meaningful abstraction that makes sense to that service.
Staging Workflow
To better understand the Cloud Controller interaction with Diego, we will explore what happens during a staging request. Exploring staging introduces you to two Diego components:
-
The BBS: Diego’s database that exposes the Diego API.
-
Cells: the execution machines responsible for running applications in containers.
These two components are discussed at length later in this chapter. Understanding the staging process provides you with a clear picture of how Cloud Foundry interprets the $ cf push and translates it into a running ActualLRP instance. Figure 6-4 provides an overview of the process.

Figure 6-4. Interaction between Cloud Foundry’s Cloud Controller components and Diego, while staging and running an application
The numbered list that follows corresponds to the callout numbers in Figure 6-4 and provides an explanation of each stage:
-
A developer/Platform Operator uses the Cloud Foundry command-line tool to issue a
cf pushcommand. -
The Cloud Foundry command-line tool instructs the Cloud Controller to create a record for the application and sends over the application metadata (e.g., the app name, number of instances, and the required buildpack, if specified).
-
The Cloud Controller stores the application metadata in the CCDB.
-
The Cloud Foundry command-line tool uploads the application files (such as a .jar file) to the Cloud Controller.
-
The Cloud Controller stores the raw application files in the Cloud Controller blobstore.
-
The Cloud Foundry command-line tool issues an app start command (unless a
no-startargument was specified). -
Because the app has not already been staged, the Cloud Controller, through the CC-Bridge, instructs Diego to stage the application.
-
Diego, through an auction process, chooses a Cell for staging and sends the staging task to the Cell.
-
The staging Cell downloads the required life-cycle binaries that are hosted on the Diego file server, and then uses the instructions in the buildpack to run the staging task in order to stage the application.
-
The staging Cell streams the output of the staging process (to loggregator) so that the developer can troubleshoot application staging problems.
-
The staging Cell packages the resulting staged application into a tarball (.tar file) called a droplet and uploads it to the Cloud Controller blobstore.
-
Diego reports to the Cloud Controller that staging is complete. In addition, it returns metadata about the application back to the CCDB.
-
The Cloud Controller (via CC-Bridge) issues a run AI command to Diego to run the staged application.
-
Diego, through an auction process, chooses a Cell to run an LRP instance as an ActualLRP.
-
The running Cell downloads the application droplet directly from the Cloud Controller blobstore (the ActualLRP has a Cloud Controller URL for the asset).
-
The running Cell downloads the Application Life-Cycle Binaries hosted by the Diego file server and uses these binaries to create an appropriate container and then starts the ActualLRP instance.
-
Diego reports the status of the application to the Cloud Controller, which periodically receives the count of running instances and any crash events.
-
The Loggregator log/metric stream goes straight from the Cell to the Loggregator system (not via the CC-Bridge). The application logs can then be obtained from the Loggregator through the CF CLI.
Diego Staging
The preceding steps explore only staging and running an app from Cloud Foundry’s perspective. The steps gloss over the interaction of the internal Diego services. After exploring the remaining Diego components and services, we will explore staging an LRP from Diego’s perspective. Analyzing staging provides a concise way of detailing how each service interacts, and therefore it is important for you to understand.
The CC-Bridge
The CC-Bridge (Figure 6-5) is a special component comprised of four microservices. It is a translation layer designed to interact both with the Cloud Controller and Diego’s API, which is exposed by Diego’s BBS. The BBS is discussed shortly in “The BBS”.

Figure 6-5. The CC-Bridge
The components on the CC-Bridge are essential for establishing domain freshness. Domain freshness means two things:
-
The actual state reflects the desired state.
-
The desired state is always understood.
Domain freshness is established through a combination of self-healing and closed feedback loops.
The Future of the CC-Bridge Component
For now, you can think of the CC-Bridge as a translation layer that converts the Cloud Controller’s domain-specific requests into Diego’s generic Tasks and LRPs. Eventually, Cloud Foundry’s Cloud Controller might be modified to communicate directly with the BBS, making the CC-Bridge redundant. Either way, the function of the four services that currently reside on the CC-Bridge will still be required no matter where they reside.
CC-Bridge services translate the Cloud Controller’s domain-specific requests of stage and run applications into Diego’s generic language of LRP and Tasks. In other words, Diego does not explicitly know about applications or staging tasks; instead, it just knows about a Task or LRP that it has been requested to execute. The CC-Bridge services include the following:
- Stager
-
The Stager handles staging requests.
- CC-Uploader
-
A file server to serve static assets to the Cloud Controller’s blobstore.
- Nsync
-
This service is responsible for handling domain freshness from the Cloud Controller to Diego.
- TPS
-
This service is responsible for handling domain freshness from Diego to the Cloud Controller.
Stager
The Stager handles staging requests from the Cloud Controller. It translates these requests into generic Tasks and submits the Tasks to Diego’s BBS. The Stager also instructs the Cells (via BBS Task auctions) to inject the platform-specific Application Life-Cycle Binary into the Cell to perform the actual staging process. Application Life-Cycle Binaries provide the logic to build, run, and health-check the application. (You can read more about them in “Application Life-Cycle Binaries”.) After a task is completed (successfully or otherwise), the Stager sends a response to the Cloud Controller.
CC-Uploader
The CC-Uploader acts as a file server to serve static assets such as droplets and build artifacts to the Cloud Controller’s blobstore. It mediates staging uploads from the Cell to the Cloud Controller, translating a simple generic HTTP POST request into the complex correctly formed multipart-form upload request that is required by the Cloud Controller. Droplet uploads to the CC-Uploader are asynchronous, with the CC-Uploader polling the Cloud Controller until the asynchronous UploadAction is completed.
Nsync and TPS
Nsync and TPS are the two components responsible for handling domain freshness, matching desired and actual state between Diego and the Cloud Controller. They are effectively two sides of the same coin:
-
The Nsync primarily retrieves information from the Cloud Controller. It is the component responsible for constructing the DesiredLRP that corresponds with the application request originating from the Cloud Controller.
-
The TPS primarily provides feedback information from Diego to the Cloud Controller.
Both components react to events via their listener process, and will periodically check state validity via their respective bulker/watcher processes.
Figure 6-6 shows the high-level component interaction between the Cloud Controller, Diego’s Nsync, and Converger components right through to the Cell. The figure also illustrates the convergence from a DesiredLRP stored in the BBS to an ActualLRP running on a Cell.
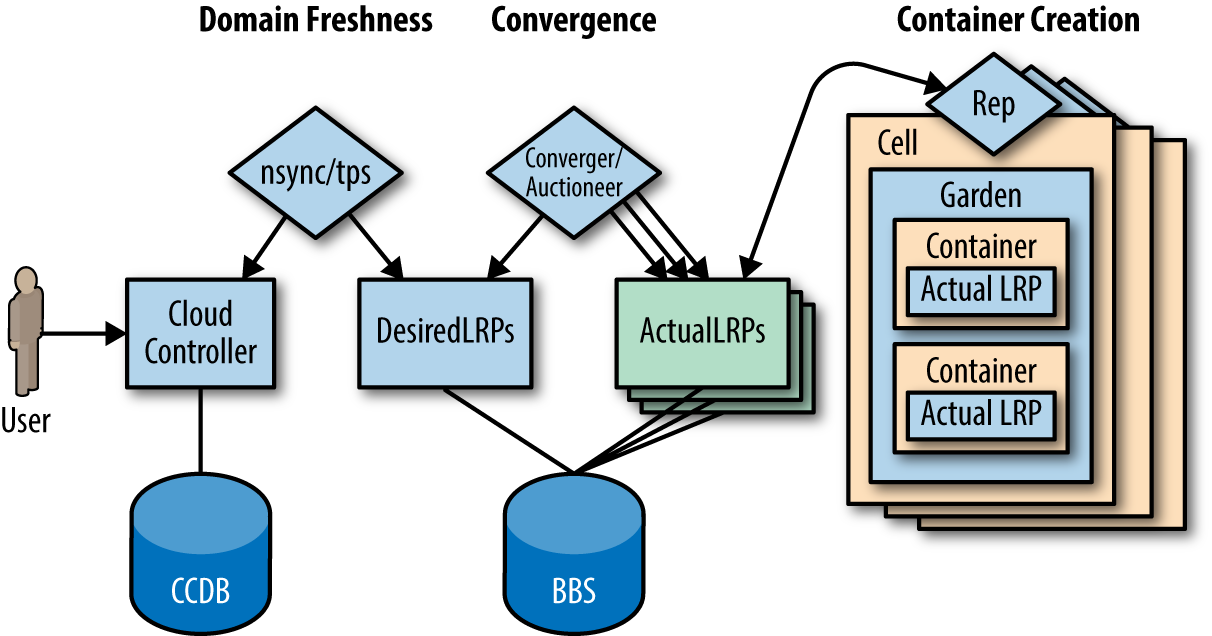
Figure 6-6. High-level process interaction involving domain freshness, convergence, and ActualLRP placement into a Cell’s container
The Nsync is responsible for keeping Diego “in sync” with the Cloud Controller. It splits its responsibilities between two independent processes: a bulker and a listener. Let’s look at each of them:
- Nsync-Listener
-
The Nsync-Listener is a service that responds to DesiredLRP requests from the Cloud Controller. It actively listens for desired app requests and, upon receiving a request, either creates or updates the DesiredLRP via a record in the BBS database. This is the initial mechanism for dictating desired state from the Cloud Controller to Diego’s BBS.
- Nsync-Bulker
-
The Nsync-Bulker is focused on maintaining the system’s desired state, periodically polling the Cloud Controller and Diego’s BBS for all DesiredLRPs to ensure that the DesiredLRP state known to Diego is up to date. This component provides a closed feedback loop, ensuring that any change of desired state from the Cloud Controller is reflected on to Diego.
The process status reporter (TPS) is responsible for reporting Diego’s status; it is Diego’s “hall monitor.” It splits its responsibilities between two independent processes: listener and watcher submodules. Here’s what each one does:
- TPS-Listener
-
The TPS-Listener provides the Cloud Controller with information about currently running ActualLRP instances. It responds to the Cloud Foundry CLI requests for
cf appsandcf app <may-app-name>. - TPS-Watcher
-
The TPS-Watcher monitors ActualLRP activity for crashes and reports them to the Cloud Controller.
Logging and Traffic Routing
To conclude our review of the Cloud Foundry layer of user-facing components, let look at logging.
Diego uses support for streaming logs from applications to Cloud Foundry’s Loggregator system and provides support for routing traffic to applications via the routing subsystem. With the combined subsystems—Diego, Loggregator, and the routing subsystem—we have everything we need to do the following:
-
Run any number of applications as a single user
-
Route traffic to the LRPs
-
Stream logs from the LRPs
The Loggregator aggregates and continually streams log and event data. Diego uses the Loggregator’s Metron agent to provide real-time streaming of logs for all Tasks and LRPs in addition to the streaming of logs and metrics for all Diego components. The routing system routes incoming application traffic to ActualLRPs running within Garden containers on Diego Cells. (The Loggregator and routing subsystem were discussed in Chapter 3.)
Diego Components
At the time of writing, there are four core Diego component machines:
-
BBS (Database)
-
Cell
-
Brain
-
Access (an external component)
The functionality provided by these components is broken up into a number of microservices running on their respective component machines.
The BBS
The BBS manages Diego’s database by maintaining an up-to-date cache of the state of the Diego cluster including a picture-in-time of all DesiredLRPs, running ActualLRP instances, and in-flight Tasks. Figure 6-7 provides an overview of the CC–Bridge-to-BBS interaction.
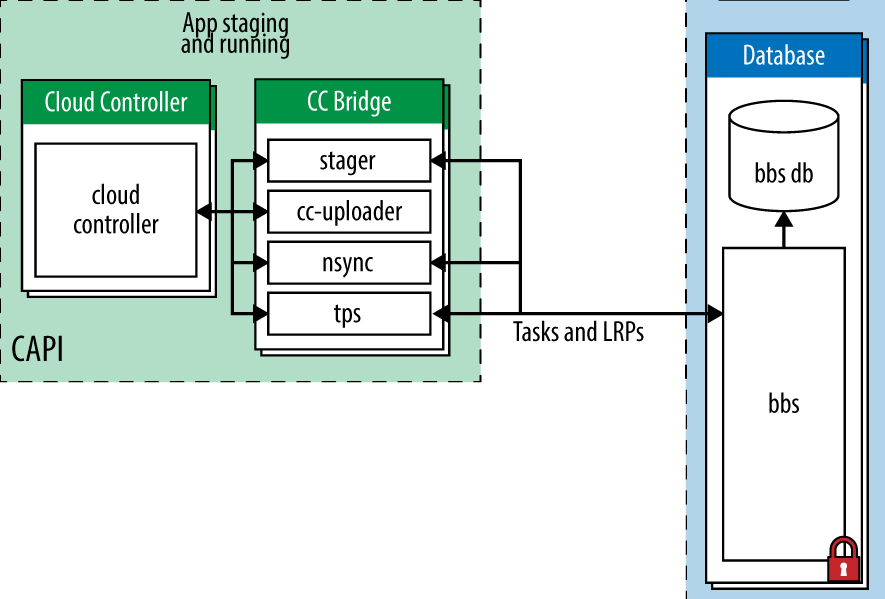
Figure 6-7. The BBS interaction with the Cloud Controller via the CC-Bridge
The BBS provides Diego’s internal components and external clients with a consistent API to carry out the following:
-
Query and update the system’s shared state (the state machine)
-
Trigger operations that execute the placement of Tasks and LRPs
-
View the datastore underpinning the state machine
For example, certain operations will cause effects. Consider creating a new LRP in the system. To achieve this, the CC-Bridge communicates to the BBS API endpoints. These endpoints will save any required state in the BBS database. If you specify a DesiredLRP with N instances, the BBS will automatically trigger the required actions for creating N ActualLRPs. This is the starting point of the state machine. Because understanding the state machine is important for debugging the platform, we cover it in more detail in “The Diego State Machine and Workload Life Cycles”.
Communication to the BBS is achieved through Google protocol buffers (protobufs).
Protocol Buffers
Protocol buffers (protobufs) provide an efficient way to marshal and unmarshal data. They are a language-neutral, platform-neutral, extensible mechanism for serializing structured data, similar in concept to eXtensible Markup Language (XML) but smaller, faster, and much less verbose.
The Diego API
The BBS provides an RPC-style API for core Diego components (Cell reps and Brain) and any external clients (SSH proxy, CC-Bridge, Route-Emitter). The BBS endpoint can be accessed only by Diego clients that reside on the same “private” network; it is not publicly routable. Diego uses dynamic service discovery between its internal components. Diego clients (the CC-Bridge) will look up the active IP address of the BBS using internal service discovery. Here are the main reasons why the Diego endpoint is not accessible via an external public route through the GoRouter:
-
Clients are required to use TLS for communication with the BBS. The GoRouter is currently not capable of establishing or passing through a TLS connection to the backend.
-
Clients are required to use mutual TLS authentication. To talk to the BBS, the client must present a certificate signed by a CA that both the client and BBS recognize.
The BBS encapsulates access to the backing database and manages data migrations, encoding, and encryption. The BBS imperatively directs Diego’s Brain to state “here is a task with a payload, find a Cell to run it.” Diego clients such as the CC-Bridge, the Brain, and the Cell all communicate with the BBS. The Brain and the Cell are both described in detail later in this chapter.
For visibility into the BBS, you can use a tool called Veritas.
The Converger process
The Converger is a process responsible for keeping work eventually consistent.
Eventual Consistency
Eventual consistency is a consistency model used for maintaining the integrity of stateful data in a distributed system. To achieve high availability, a distributed system might have several “copies” of the data-backing store. Eventual consistency informally guarantees that, if no new updates are made to a given item of data, eventually all requests for that item will result in the most recently updated value being returned. To learn more about HA, see “High Availability Considerations”.
The Converger is a process that currently resides on the Brain instance group. It is important to discuss now, because it operates on the BBS periodically and takes actions to ensure that Diego attains eventual consistency. Should the Cell fail catastrophically, the Converger will automatically move the missing instances to other Cells. The Converger maintains a lock in the BBS to ensure that only one Converger performs convergence. This is primarily for performance considerations because convergence should be idempotent.
The Converger uses the converge methods in the runtime-schema/BBS to ensure eventual consistency and fault tolerance for Tasks and LRPs. When converging LRPs, the Converger identifies which actions need to take place to bring the DesiredLRP state and ActualLRP state into accord. Two actions are possible:
-
If an instance is missing, a start auction is sent.
-
If an extra instance is identified, a stop message is sent to the Cell hosting the additional instance.
In addition, the Converger watches for any potentially missed messages. For example, if a Task has been in the PENDING state for too long, it is possible that the request to hold an auction for the Task never made it to the Auctioneer. In this case, the Converger is responsible for resending the auction message. Periodically the Converger sends aggregate metrics about DesiredLRPs, ActualLRPs, and Tasks to the Loggregator.
Resilience with RAFT
Whatever the technology used to back the BBS (etcd, Consul, clustered MySQL), it is likely to be multinode to remove any single point of failure. If the backing technology is based on the Raft consensus algorithm, you should always ensure that you have an odd number of instances (three at a minimum) to maintain a quorum.
Diego Cell Components
Cells are where applications run. The term application is a high-level construct; Cells are concerned with running desired Tasks and LRPs. Cells are comprised of a number of subcomponents (Rep/Executor/Garden; see Figure 6-8) that deal with running and maintaining Tasks and LRPs. One Cell typically equates to a single VM, as governed by the CPI in use. You can scale-out Cells both for load and resilience concerns.

Figure 6-8. The Cell processes gradient from the Rep to the Executor through to Garden and its containers
There is a specificity gradient across the Rep, Executor, and Garden. The Rep is concerned with Tasks and LRPs, and knows the details about their life cycles. The Executor knows nothing about Tasks and LRPs but merely knows how to manage a collection of containers and run the composable actions in these containers. Garden, in turn, knows nothing about actions and simply provides a concrete implementation of a platform-specific containerization technology that can run arbitrary commands in containers.
Rep
The Rep is the Cell’s API endpoint. It represents the Cell and mediates all communication between the BBS and Brain—the Rep is the only Cell component that communicates with the BBS. This single point of communication is important to understand; by using the Rep for all communication back to the Brain and BBS, the other Cell components can remain implementation independent. The Rep is also free to be reused across different types of Cells. The Rep is not concerned with specific container implementations; it knows only that the Brain wants something run. This means that specific container technology implementations can be updated or swapped out and replaced at will, without forcing additional changes within the wider distributed system. The power of this plug-and-play ability should not be underestimated. It is an essential capability for upgrading the system with zero-downtime deployments.
Specifically, the Rep does the following (see also Figure 6-9):
-
Participates in the Brain’s Auctioneer auctions to bid for Tasks and LRPs. It bids for work based on criteria such as its capacity to handle work, and then subsequently tries to accept what is assigned.
-
Schedules Tasks and LRPs by asking its in-process Executor to create a container to run generic action recipes in the newly created container.
-
Repeatedly maintains the presence of the Cell in the BBS. Should the Cell fail catastrophically, the BBS will invoke the Brain’s Converger to automatically move the missing instances to another Cell with availability.
-
Ensures that the set of Tasks and ActualLRPs stored in the BBS are synchronized with the active containers that are present and running on the Cell, thus completing the essential feedback loop between the Cell and the BBS.

Figure 6-9. The BBS, auction, and Cell feedback loop
The Cell Rep is responsible for getting the status of a container periodically from Garden via its in-process Executor and reporting that status to the BBS database. There is only one Rep running on every Diego Cell.
Executor
The Executor is a logical process inside the Rep. Its remit is “Let me run that for you.”5 The Executor still resides in a separate repository, but it is not a separate job; it is part of the Rep.
The Executor does not know about the Task versus LRP distinction. It is primarily responsible for implementing the generic Executor “composable actions,” as discussed in “Composable Actions”. Essentially, all of the translation between the Rep and Garden is encapsulated by the Executor: the Executor is a gateway adapter from the Rep to the Garden interface. The Rep deals with simplistic specifications (execute this tree of composable actions), and the Executor is in charge of actually interacting with Garden to, for example, make the ActualLRP via the life cycle objects. Additionally, the Executor streams Stdout and Stderr to the Metron-agent running on the Cell. These log streams are then forwarded to the Loggregator.
Garden
Cloud Foundry’s container implementation, Garden, is separated into the API implementation and the actual container implementation. This separation between API and actual containers is similar to how Docker Engine has both an API and a container implementation based on runC.
Garden is a container API. It provides a platform-independent client server to manage Garden-compatible containers such as runC. It is backend agnostic, defining an interface to be implemented by container-runners (e.g., Garden-Linux, Garden-Windows, libcontainer, runC). The backend could be anything as long as it understands requests through the Garden API and is able to translate those requests into actions.
Container Users
By default, all applications run as the vcap user within the container. This user can be changed with a runAction, the composable action responsible for running a process in the container. This composable action allows you to specify, among other settings, the user. This means Diego’s internal composable actions allow processes to run as any arbitrary user in the container. That said, the only users that really make sense are distinguished unprivileged users known as vcap and root. These two users are provided in the cflinuxfs2 rootfs. For Buildpack-based apps, Cloud Foundry always specifies the user to be vcap.
Chapter 8 looks at Garden in greater detail.
The Diego Brain
We have already discussed the Brain’s Converger process. The Brain (Figure 6-10) is also responsible for running the Auctioneer process. Auctioning is the key component of Diego’s scheduling capability. There are two components in Diego that participate in auctions:
- The Auctioneer
-
Responsible for holding auctions whenever a Task or LRP needs to be scheduled
- The Cell’s Rep
-
Represents a Cell in the auction by making bids for work and, if picked as the winner, running the Task or LRP

Figure 6-10. The Cell–Brain interaction
Horizontal Scaling for Controlling Instance Groups
Each core component (known in BOSH parlance as an instance group) is deployed on a dedicated machine or VM. There can be multiple instances of each instance group, allowing for HA and horizontal scaling.
Some instance groups, such as the Auctioneer, are essentially stateless. However, it is still important that only one instance is actively making decisions. Diego allows for lots of potential running instances in order to establish HA, but only one Auctioneer can be in charge at any one period in time. Within a specific instance group, the instance that is defined as “in charge” is specified by a global lock. Finding out which specific instance is in charge is accomplished through an internal service discovery mechanism.
When holding an auction, the Auctioneer communicates with the Cell Reps via HTTP. The auction process decides where Tasks and ActualLRP instances are run (remember that a client can dictate that one LRP requires several ActualLRP instances for availability). The Auctioneer maintains a lock in the BBS such that only one Auctioneer may handle auctions at any given time. The BBS determines which Auctioneer is active from a lock record (effectively the active Auctioneer holding the lock). When the BBS is at a point at which it wants to assign a payload to a Cell for execution, the BBS directs the Brain’s Auctioneer by requesting, “here is a task with a payload, find a Cell to run it.” The Auctioneer asks all of the Reps what they are currently running and what their current capacity is. Reps proactively bid for work and the Auctioneer uses the Reps’ responses to make a placement decision.
Scheduling Algorithms
At the core of Diego is a distributed scheduling algorithm designed to orchestrate where work should reside. This distribution algorithm is based on several factors such as existing Cell content and app size. Other open source schedulers exist, such as Apache Mesos or Google’s Kubernetes. Diego is optimized specifically for application and task workloads. The supply–demand relationship for Diego differs from the likes of Mesos. For Mesos, all worker Cells report, "I am available to take N pieces of work" and Mesos decides where the work goes. In Diego, an Auctioneer says, "I have N pieces of work, who wants them?" Diego’s worker Cells then join an auction, and the winning Cell of each auctioned-off piece of work gets that piece of work. Mesos’ approach is supply driven, or a “reverse-auction,” and Diego’s approach is demand driven.
A classic optimization problem in distributed systems is that there is a small lag between the time the system realizes it is required to make a decision (e.g., task placement) and the time when it takes action on that decision. During this lag the input criteria that the original decision was based upon might have changed. The system needs to take account of this to optimize its work-placement decisions.
Consequently, there are currently two auction actions for LRPs: LRPStartAuction and LRPStopAuction. Let’s look at each:
- LRPStartAuctions
-
These occur when LRPs need to be assigned somewhere to run. Essentially, one of Diego’s Auctioneers is saying, “We need another instance of this app. Who wants it?”
- LRPStopAuctions
-
These occur when there are too many LRPs instances running for a particular application. In this case, the Auctioneer is saying, “We have too many instances of this app at index X. Who wants to remove one?"
The Cell that wins the auction either starts or stops the requested LRP.
The Access VM
The access VM contains the file server and the SSH proxy services.
The SSH proxy
Diego supports SSH access to ActualLRP instances. This feature provides direct access to the application for tasks such as viewing application logs or inspecting the state of the container filesystem. The SSH proxy is a stateless routing tier. The primary purpose of the SSH proxy is to broker connections between SSH clients and SSH servers running within containers. The SSH proxy is a lightweight SSH daemon that supports the following:
-
Command execution
-
Secure file copy via SCP
-
Secure file transfer via SFTP
-
Local port forwarding
-
Interactive shells, providing a simple and scalable way to access containers associated with ActualLRPs
The SSH proxy hosts the user-accessible SSH endpoint so that Cloud Foundry users can gain SSH access to containers running ActualLRPs. The SSH proxy is responsible for the following:
-
SSH authentication
-
Policy enforcement
-
Access controls
After a user successfully authenticates with the proxy, the proxy attempts to locate the target container, creating the SSH session with a daemon running within the container. It effectively creates a “man-in-the-middle” connection with the client, bridging two SSH sessions:
-
A session from the client to the SSH proxy
-
A session from the SSH proxy to the container
After both sessions have been established, the proxy will manage the communication between the user’s SSH client and the container’s SSH daemon.
The daemon is self-contained and has no dependencies on the container root filesystem. It is focused on delivering basic access to ActualLRPs running in containers and is intended to run as an unprivileged process; interactive shells and commands will run as the daemon user. The daemon supports only one authorized key and is not intended to support multiple users. The daemon is available on Diego’s file server. As part of the application life cycle bundle, Cloud Foundry’s LRPs will include a downloadAction to acquire the binary and then a runAction to start it.
The Diego State Machine and Workload Life Cycles
Diego’s semantics provide clients with the ability to state, “Here is my workload: I want Diego to keep it running forever. I don’t care how.” Diego ensures this request becomes a reality. If for some reason an ActualLRP crashes, Diego will reconcile desired and actual state back to parity. These life cycle concerns are captured by Diego’s state machine. It is important that you understand the state machine should you need to debug the system. For example, if you notice many of your ActualLRPs remain in UNCLAIMED state, it is highly likely that your Cells have reached capacity and require additional resources.
An understanding of the state machine (see Figure 6-11) and how it relates to the app and task life cycles is essential for understanding where to begin with debugging a specific symptom.

Figure 6-11. Diego’s state machine
The responsibility for state belongs, collectively, to several components. The partition of ownership within the distributed system is dependent on the task or LRP (app) life cycle.
The Application Life Cycle
The application life cycle is as follows:
-
When a client expresses the desire to run an application, the request results in Diego’s Nsync process creating an ActualLRP record.
-
An ActualLRP has a state field (a process globally unique identifier [GUID] with an index) recorded in the BBS. The ActualLRP begins its life in an UNCLAIMED state, resulting in the BBS passing it over to the Auctioneer process.
-
Work collectively is batched up and then distributed by the Auctioneer. When the Auctioneer has a batch of work that requires allocating, it looks up all the running Cells through service discovery and individually asks each Cell (Rep) for a current snapshot of its state, including how much capacity the Cell has to receive extra work. Auction activity is centrally controlled. It is like a team leader assigning tasks to team members based on their desire for the work and their capacity to perform it. The batch of work is broken up and distributed appropriately across the Cells.
-
An auction is performed and the ActualLRP is placed on a Cell. The Cell’s Rep immediately transfers the ActualLRP state to CLAIMED. If placement is successful, the LRP is now RUNNING and the Rep now owns this record. If the ActualLRP cannot be placed (if a Cell is told to do work but cannot run that work for some reason), it reenters the auction process in an UNCLAIMED state. The Cell rejects the work and the Auctioneer can retry the work later.
-
The Cell’s response on whether it has the capacity to do the work should not block actually starting the work. Therefore, the “perform” request from the Auctioneer instructs the Cell to try to undertake the work. The Cell then attempts to reserve capacity within the Executor’s state management, identifying the extra resource required for the work.
-
The Cell quickly reports success or failure back to the Auctioneer. Upon success, the Cell then reserves this resource (as quickly as possible) so as not to advertise reserved resources during future auctions. The Executor is now aware that it has the responsibility for the reserved work and reports this back to the Rep, which knows the specifics of the Diego state machine for Tasks and LRPs.
-
Based on the current state that the Executor is reporting to the Rep, the Rep is then going to make decisions about how to progress workloads through their life cycles. In general, if anything is in reserved state, the Rep states to the Executor: "start running that workload.” At that point, the Executor takes the container specification and creates a container in Garden.
-
The Auctioneer is responsible for the placement of workloads across the entire cluster of Cells. The Converger is responsible for making sure the desired and actual workloads are reconciled across the entire cluster of Cells. If the ActualLRP crashes, it is placed in a CRASHED state and the Rep moves the state ownership back to the BBS because the ActualLRP is no longer running. When the Rep undertakes its own local convergence cycle, trying to converge the actual running states in its Garden containers with its representation within the BBS, the Rep will discover the ActualLRP CRASHED state. The Rep then looks for the residual state that might still reside from its management of that ActualLRP. Even if the container itself is gone, the Executor might still have the container represented in a virtual state. The virtual state’s “COMPLETED” state information might provide a clue as to why the ActualLRP died (e.g., it may have been placed in failure mode). The Rep then reports to the BBS that the ActualLRP has crashed. The BBS will attempt three consecutive restarts and then the restart policy will begin to back off exponentially, attempting subsequent restarts after a delayed period.
-
The Brain’s Converger runs periodically looking for “CRASHED” ActualLRPs. Based on the number of times it has crashed (which is also retained in the BBS), the Converger will pass the LRP back to the Auctioneer to resume the ActualLRP. The Converger deals with the mass of unclaimed LRPs, moving them to ActualLRPs “CLAIMED” and “RUNNING”. The Converger maps the state (held in the BBS) on to the desired LRPs. If the BBS desires five instances but the Rep only reports on four records, the Converger will make the fifth record in the BBS to kickstart the placement.
-
There is a spectrum of responsibilities that extends from the Converger to the BBS. Convergence requires a persistence-level convergence, including the required cleanup process. There is also a business-model convergence in which we can strip away any persistence artifacts and deal with the concepts we are managing—and Diego ensures that the models of these concepts are in harmony. The persistence layer always happens in the BBS, but it is triggered by the Converger running a convergence loop.
Task Life Cycle
Tasks in Diego also undergo a life cycle. This life cycle is encoded in the Task’s state as follows:
- PENDING
-
When a task is first created, it enters the PENDING state.
- CLAIMED
-
When successfully allocated to a Diego Cell, the Task enters the CLAIMED state and the Task’s Cell_id is populated.
- RUNNING
-
The Task enters the RUNNING state when the Cell begins to create the container and run the defined Task action.
- COMPLETED
-
Upon Task completion, the Cell annotates the TaskResponse (failed, failure_reason, result), and the Task enters the COMPLETED state.
Upon Task completion, it is up to the consumer of Diego to acknowledge and resolve the completed Task, either via a completion callback or by deleting the Task. To discover if a Task is completed, the Diego consumer must either register a completion_callback_url or periodically poll the API to fetch the Task in question. When the Task is being resolved, it first enters the RESOLVING state and is ultimately removed from Diego. Diego will automatically reap Tasks that remain unresolved after two minutes.
Additional Components and Concepts
In addition to its core components, Diego also makes use of the following:
-
The Route-Emitter
-
Consul
-
Application Life-Cycle Binaries
The Route-Emitter
The Route-Emitter is responsible for registering and unregistering the ActualLRPs routes with the GoRouter. It monitors DesiredLRP state and ActualLRP state via the information stored in the BBS. When a change is detected, the Route-Emitter emits route registration/unregistration messages to the router. It also periodically emits the entire routing table to the GoRouter. You can read more about routing in Chapter 7.
Consul
Consul is a highly available and distributed service discovery and key-value store. Diego uses it currently for two reasons:
-
It provides dynamic service registration and load balancing via internal DNS resolution.
-
It provides a consistent key-value store for maintenance of distributed locks and component presence. For example, the active Auctioneer holds a distributed lock to ensure that other Auctioneers do not compete for work. The Cells Rep maintains a global presence in Consul so that Consul can maintain a correct view of the world. The Converger also maintains a global lock in Consul.
To provide DNS, Consul uses a cluster of services. For services that require DNS resolution, a Consul agent is co-located with the hosting Diego component. The consul-agent job adds 127.0.0.1 as the first entry in the nameserver list. The consul-agent that is co-located on the Diego component VM serves DNS for consul-registered services on 127.0.0.1:53. When Consul tries to resolve an entry, the Consul domain checks 127.0.0.1 first. This reduces the number of component hops involved in DNS resolution. Consul allows for effective intercomponent communication.
Other services that expect external DNS resolution also need a reference to the external DNS server to be present in /etc/resolv.conf.
Like all RAFT stores, if Consul loses quorum, it may require manual intervention. Therefore, a three-Consul-node cluster is required, preferably spanning three AZs. If you restart a node, when it comes back up, it will begin talking to its peers and replay the RAFT log to get up to date and synchronized with all the database history. It is imperative to ensure that a node is fully back up and has rejoined the cluster prior to taking a second node down; otherwise, when the second node goes offline, you might lose quorum. BOSH deploys Consul via a rolling upgrade to ensure that each node is fully available prior to bringing up the next.
Application Life-Cycle Binaries
Diego aims to be platform agnostic. All platform-specific concerns are delegated to two types of components:
-
the Garden backend
-
the Application Life-Cycle Binaries
The process of staging and running an application is complex. These concerns are encapsulated in a set of binaries known collectively as the Application Life-Cycle Binaries. There are different Application Life-Cycle Binaries depending on the container image (see also Figure 6-12):
-
Buildpack-Application Life Cycle implements a traditional buildpack-based life cycle.
-
Docker-Application Life Cycle implements a Docker-based OCI-compatible life cycle.
-
Windows-Application Life Cycle implements a life cycle for .NET applications on Windows.

Figure 6-12. The Application Life-Cycle Binaries
Each of the aforementioned Application Life Cycles provides a set of binaries that manage a specific application type. For the Buildpack-Application Life Cycle, there are three binaries:
-
The Builder stages a Cloud Foundry application. The CC-Bridge runs the Builder as a Task on every staging request. The Builder performs static analysis on the application code and performs any required preprocessing before the application is first run.
-
The Launcher runs a Cloud Foundry application. The CC-Bridge sets the Launcher as the Action on the app’s DesiredLRP. The Launcher executes the user’s start command with the correct system context (working directory, environment variables, etc.).
-
The Healthcheck performs a status check of the running ActualLRP from within the container. The CC-Bridge sets the Healthcheck as the Monitor action on the app’s DesiredLRP.
The Stager Task produced by the CC-Bridge downloads the appropriate Application Life-Cycle Binaries and runs them to invoke life cycle scripts such as stage, start, and health-check in the ActualLRP.
This is a pluggable module for running OS-specific components. Because the life cycle is OS specific, the OS is an explicitly specified field required by the LRP. For example, the current Linux setting references the cflinuxfs2 rootfs. In addition to the rootfs, the only other OS-specific component that is explicitly specified is the backend container type.
In addition to the Linux life cycle, Diego also supports a Windows life cycle and a Docker life cycle. The Docker life cycle (to understand how to stage a Docker image) is based on metadata from the Cloud Controller, based on what type of app we want to run. As part of the information for “stage these app bits,” there will be some indication of what branching the Stager is required to undertake. The binaries have tried to ensure that, as much as possible, these specifications are shared.
Putting It All Together
We discussed what happens when staging an application in “Staging Workflow”. Specifically, we discussed the following interactions:
-
The CLI and the Cloud Controller
-
The Cloud Controller and CC-Bridge
-
The CC-Bridge and Diego, including Diego Cells
Up to this point, we have glossed over the interaction of the internal Diego components. This section discusses the interaction between the Diego components during staging LRPs. This section assumes you are staging an app using the buildpack Application Life-Cycle Binaries as opposed to pushing a prebuilt OCI-compatible image.
Staging takes application artifacts and buildpacks and produces a binary droplet artifact coupled with metadata. This metadata can be anything from hosts and route information to the detected buildpack and the default start command. Essentially, any information that comes out of the entire buildpack compilation and release process can be encapsulated via the buildpack’s metadata.
Note
The internals of Diego know nothing about buildpacks. The Cloud Controller, via the Application Life-Cycle Binaries, provides all the required buildpacks to run in a container. The Cloud Controller can be conservative on what it downloads; if you specify a buildpack (e.g., the JBP), only that buildpack will be downloaded. If no buildpack is specified, the Cloud Controller will download all buildpacks. Additionally, individual Cells can cache buildpacks so that they do not need to be repeatedly downloaded from the Cloud Controller. Chapter 9 looks at buildpacks in greater detail.
The steps for staging are as follows:
-
The staging process begins with a
cf pushrequest from the Cloud Foundry CLI to the Cloud Controller (CAPI). Diego’s role in the process occurs when the Cloud Controller instructs Diego (via the CC-Bridge) to stage the application. All Tasks and LRPs are submitted to the CC-Bridge via Cloud Foundry’s Cloud Controller. The Cloud Controller begins the staging process by sending a “stage app bits” request as a task. -
The CC-Bridge’s Stager picks up and handles the “stage app bits” request. The Stager constructs a staging message and forwards it to the BBS. Thus, the Stager represents a transformation function.
-
The first step of the BBS is to store the task information. When the task request is stored in the BBS, the BBS is responsible for validating it. At this stage the task request is only stored; no execution of the task has taken place.
-
Diego is now at a point at which it wants to assign a payload (the Task) to a Cell that is best suited to run it. The BBS determines which of the Brain’s Auctioneers is active by looking for the Auctioneer that currently holds the lock record. The BBS communicates to the Auctioneer, directing it to find a Cell to run the Task.
-
The Auctioneer optimally distributes Tasks and LRPs to the cluster of Diego Cells via an auction involving the Cell Reps. The Auctioneer asks all of the Reps what they are currently running. It uses the Reps’ responses to make a placement decision. After it selects a Cell, it directs the chosen Cell to run the desired Task. You can configure it so that this auction is done every time you push an application; however, you can also batch auctions for performance to reduce the auction overhead.
There is additional scope for sharding this auction process by AZ. It is inappropriate to cache the auction results because state is changing all the time; for example, a task might complete or an ActualLRP might crash. To look up which Cells are registered (via their Reps), the Auctioneer communicates with the BBS to get the shared system state. Reps report to BBS directly to inform BBS of their current state. When the Auctioneer is aware of the available Reps, it contacts all Reps directly.
-
The chosen Rep is assigned the Task. After a Task/LRP is assigned to a Cell, that Cell will try to allocate containers based on its internal accounting. Inside the Rep, there is a gateway to Garden (the Executor). (We introduced Garden in “Garden” and it is discussed further in Chapter 8.) The Rep runs Tasks/ActualLRPs by asking its in-process Executor to create a container to run generic action recipes. The Executor creates a Garden container and executes the work encoded in the Task/ActualLRP. This work is encoded as a generic, platform-independent recipe of composable actions (we discussed these in “Composable Actions”). If the Cell cannot perform the Task, it responds to the Auctioneer, announcing that it was unable to run the requested work. Payloads that are distributed are a batch of Tasks rather than one Task per request. This approach reduces chatter and allows the Cell to attempt all requested tasks and report back any Task it was unable to accomplish.
-
The staging Cell uses the instructions in the buildpack and the staging task to stage the application. It obtains the buildpack through the buildpack Application Life-Cycle Binaries via the file server.
-
Assuming that the task completes successfully, the staging task will result in a droplet, and Garden reports that the container has completed all processes. This information bubbles up through the Rep and the Task is now marked as being in a completed state. When a Task is completed it can call back to the BBS using the callback in the Task request. The callback URL then calls back to the Stager so that the Stager knows that the task is complete (Stagers are stateless, so the callback will return to any Stager). The callback is the process responsible for uploading the metadata from Cell to Stager, and the Stager passes the metadata back to the Cloud Controller.
-
The Cloud Controller also provides information as to where to upload the droplet. The Cell that was responsible for staging the droplet can asynchronously upload the droplet back to the Cloud Controller blobstore. The droplet goes back to the Cloud Controller blobstore via the Cell’s Executor. The Executor uploads the droplet to the file server. The file server asynchronously uploads the blobstore to the Cloud Controller’s blobstore, regularly polling to find out when the upload has been completed.
-
Additionally the staging Cell streams the output of the staging process so that the developer can troubleshoot application staging problems. After this staging process has completed successfully, the Cloud Controller subsequently issues a “run application droplet command” to Diego to run the staged application.
From a developer’s perspective, you issue a command to Cloud Foundry and Cloud Foundry will run your app. However, as discussed at the beginning of this chapter, as work flows through the distributed system, Diego components describe their actions using different levels of abstraction. Internal interactions between the Cloud Controller and Diego’s internal components are abstracted away from the developer. They are, however, important for an operator to understand in order to troubleshoot any issues.
Summary
Diego is a distributed system that allows you to run and scale N number of applications and tasks in containers across a number of Cells. Here are Diego’s major characteristics and attributes:
-
It is responsible for running and monitoring OCI-compatible images, standalone applications, and tasks deployed to Cloud Foundry.
-
It is responsible for container scheduling and orchestration.
-
It is agnostic to both client interaction and runtime implementation.
-
It ensures applications remain running by reconciling desired state with actual state through establishing eventual consistency, self-healing, and closed feedback loops.
-
It has a generic execution environment made up of composable actions, and a composable backend to allow the support of multiple different Windows- and Linux-based workloads.
When you step back and consider the inherent challenges with any distributed system, the solutions to the consistency and orchestration challenges provided by Diego are extremely elegant. Diego has been designed to make the container runtime subsystem of Cloud Foundry modular and generic. As with all distributed systems, Diego is complex. There are many moving parts and the communication flows between them are not trivial. Complexity is fine, however, if it is well defined within bounded contexts. The Cloud Foundry team has gone to great lengths to design explicit boundaries for the Diego services and their interaction flows. Each service is free to express its work using its own abstraction, and ultimately this allows for a modular composable plug-and-play system that is easy both to use and operate.
1 These services, along with the concept of domain freshness, are discussed further in “The CC-Bridge”.
2 The available actions are documented in the Cloud Foundry BBS Release on GitHub.
3 You can find more information on Diego online, including the Diego BOSH release repository.
4 User management is primarily handled by the User Access and Authentication, which does not directly interact with Diego but still remains an essential piece of the Cloud Foundry ecosystem.
5 A conceptual adaption from the earlier container technology LMCTFY, which stands for Let Me Contain That For You.