
Chapter 16. Designing for Resilience, Planning for Disaster
Reliability, recoverability, timely error detection, and continuous operations are primary characteristics of any high-availability solution. Cloud Foundry, if used correctly, can become the central platform for your app development and deployment activities. As such, the resiliency of the platform is critical to your business continuity. Preparing for disaster and disruption to Cloud Foundry and the underlying stack is vital.
You can mitigate and handle failures in three key ways:
-
Design for added resiliency and high availability
-
Employ backup and restoration mechanisms
-
Repeatedly run platform verification tests
This chapter provides you with an overview of Cloud Foundry’s built-in resiliency capabilities. It then goes on to discuss how you can further expand resiliency. This chapter also provides you with an overview of some of the available techniques used for backing up and restoring Cloud Foundry.
High Availability Considerations
Resiliency and high availability go hand in hand. End users do not care how resilient your system is; they are concerned only about the availability of their app, service, or functionality. For example, when I am watching Netflix, the last thing on my mind is that Chaos Monkey can take out a vital component. I care only about watching my movie. Operators employ resiliency in technical stacks to promote HA. HA is measured from the perception of the end user. End users experience frustration, resulting in a negative perception when the service they want to access is unavailable or unreliable in some fashion. Ultimately, this is what you are guarding against.
Being HA is the degree to which a component is available to a user upon demand. At its core, HA is primarily achieved simply through the redundant setup of each component such that any single point of failure is avoided.1
Establishing HA is a concern that applies to every layer of the technology stack. For example, when using replication of components to establish HA, you should see replication at every layer of the technology stack, be it multiple Top-of-Rack (ToR) switches for network availability to a VIP underpinned by a cluster of load balancers to allow for fast failover of your VIP. Establishing replication only for a single component will typically be insufficient. HA considerations span several components, and there are different levels of HA that you can attain, because failures can occur due to a variety of reasons. For example, performance failures due to higher than expected usage can create the same havoc as the failure of a critical component or a network outage.2
The different levels of HA are captured and reasoned over through the consideration of failure boundaries. For example, the lowest level of HA might be your data center itself. You then need to consider your physical infrastructure and networking layers followed by your IaaS clusters. You need to think about HA at every single layer. Designing for HA is essential if your system is required to be continuously operational. This means that your Cloud Foundry developer environments must also be production grade if you require developers to be constantly productive. As an example, I recently worked with a large retail company that estimated that (based on employee cost per minute) that five minutes of down time could be equated to $1 million in sunk costs.
The key question to ask when making your system resilient is how much HA is actually required and at what cost. The answer to this question historically has depended on the appetite for risk coupled with the ability to recover, contrasted against additional expenses incurred through replicating components.
Understanding the failure boundaries, whether in terms of network, host, cluster, region, or process, can help shape your HA strategy as it helps you assess specific risks contrasted against the costs involved in mitigating those risks. For example, there is a high probability that an individual process or machine can fail, and therefore it is a reasonable and cost-effective approach to run more than one process or machine. Conversely, the risks of an entire data center going offline may be significantly small and the costs associated with replicating the data center versus the perceived risk may likely be too high. Understanding what can fail, the impact of those failures, and how much it would cost to mitigate those risks is an essential step in defining your HA strategy.
Within a distributed system such as Cloud Foundry, you must apply special focus to the intersection and interconnectivity of components so that every failure of an individual component can be bypassed without loss of the overall system functionality. Cloud Foundry takes a unique approach to providing HA by moving beyond just replication, although that strategy is still a key focus. Cloud Foundry, coupled with BOSH, promotes resiliency through self-healing. Self-healing is the ability to recover from app, process, and component failure through inbuilt error handling and correction.
Cloud Foundry addresses HA from the top down, beginning with app availability, and then moving through the system components to the infrastructure. This is a logical way to view HA. Generally speaking, the lower the layer affected, the higher the overall impact. Failures at the top of the stack, such as a failed process, are potentially more frequent but easier and less costly to rectify. Failures at the bottom of the stack, such as a SAN outage, are rare but can be catastrophic to the entire system and even the data center.
Data Center Availability
Before embarking on a Cloud Foundry HA strategy, there is an implicit assumption that your data center is set up correctly with an appropriate level of HA and resiliency for your hardware, storage, servers, networking, power, and so on.
Extending Cloud Foundry’s Built-In Resiliency
In the previous section, I discussed the requirement for replicating both apps and the underlying components as a mechanism for establishing HA. Cloud Foundry moves beyond the simple strategy of replication by establishing resiliency and HA on your behalf. It achieves built-in resiliency in four key ways, referred to in the Cloud Foundry community as “the four levels of HA.” An introduction to the four levels of HA were discussed in “Built-In Resilience and Fault Tolerance”. They include the following:
-
Restarting failed system processes
-
Recreating missing or unresponsive VMs
-
Dynamic deployment of new app instances if an app crashes or becomes unresponsive
-
App striping across AZs to enforce separation of the underlying infrastructure
Cloud Foundry does more of the resiliency heavy lifting for you by providing self-healing of apps, processes, and VMs. The four levels of HA provide resiliency within the boundaries of a single installation. However, if you experience wider data center failure due to underlying infrastructure issues such as a SAN outage or a load balancer VIP cluster becoming unreachable, a single Cloud Foundry deployment could become temporarily unusable.
Data center outages are extremely rare. However, if you require an additional level of resiliency to mitigate any potential data center failures, it is possible to run multiple deployments of Cloud Foundry in different data centers. Whether you run dual deployments of Cloud Foundry in active–active modes or active–passive modes, there are some important considerations of which you need to be mindful.
Resiliency Through Multiple Cloud Foundry Deployments
Consider the scenario of running two Cloud Foundry deployments across two different data centers; let’s call them West and East. This could be a preproduction instance in one data center and a production instance in the other, or two production deployments running apps and services in an active–active fashion. This configuration gives you the ability to shut down an entire Cloud Foundry deployment and still keep your production apps running in the second deployment.
Because you have two data centers, there are at least five required default domains to cover both the system components and the app domain.
Conceptually, assuming you are not yet using a pipeline, here’s what you have:
-
Developers can push myapp at “cf-west.com”.
-
Developers can push myapp at “cf-east.com”.
-
End-user clients access apps at “mycf.com” .
-
Developers and operators target the system domain
api.system.cf-west.com. -
Developers and operators target the system domain
api.system.cf-east.com.
Clearly, the number of domains can further increase with additional environments (e.g., a production and development instance in each data center).
Traffic will typically first hit a global load balancer (e.g., F5’s Global Traffic Manager [GTM]) that spans both deployments. Using the global load balancer, the end-user traffic can be balanced across both active–active environments based on, for example, geographic location or existing load in the data center. The global load balancer consults DNS and then routes the traffic to a local data center’s load balancer after it decides which data center to route the traffic to.
All domains for all the Cloud Foundry deployments must be registered as a DNS record so that the global load balancer can route traffic to the correct location. Each Cloud Foundry deployment should have all five domains defined in its certificate. This allows the local load balancer to route traffic across to a different data center if, for some rare reason, the local load balancer is unable to connect to the local Cloud Foundry deployment.
With this approach, developers who need to target a specific Cloud Foundry installation can do so by using the local data center–centric domain. Ideally though, developers should not be burdened with the need to deploy to two environments. Instead, developers should simply check in their code commit and leave the deployment responsibility to a CI/CD pipeline.
Resiliency Through Pipelines
We discussed in “Why BOSH?” the need for environmental consistency and reproducibility. This is even more pertinent when mirroring environments in two or more installations. BOSH provides environmental consistency by means of releases and stemcells, assuming that you have mirrored your deployment configuration correctly, with only instance-specific concerns such as domains, networks, and credentials unique to a specific installation.
However, neither Cloud Foundry nor BOSH will ensure that a developer will push an identical app in the same way, using the same buildpack and dependencies, to two different Cloud Foundry environments. Therefore, deploying an app to multiple production environments should not be a developer concern; it should be governed by a CI/CD pipeline such as concourse.ci. The pipeline should handle deploying the app artifact or Docker OCI image in exactly the same way to both environments, in a repeatable fashion.
Data Consistency Through Services
One of the biggest challenges with running any app layer technology in an active–active fashion across two data centers is the data layer underpinning the app. Many apps will have some requirement to persist data to a backing service such as a database. The backing data services must maintain consistency between the two data centers. This consistency concern is explained by the CAP theorem, which states that it is impossible for a distributed system to simultaneously provide consistency, availability, and partition tolerance guarantees; at any one time, a distributed system can ensure only two out of the three requirements.
Maintaining data consistency across different data centers increases the CAP theorem challenge because of increased latency when trying to propagate data changes across two separate locations. If you adopt a write-through model across your data centers, in which you return a confirmation of a successful write only after the write is completed, the end-user experience could be painfully slow. Latency is ultimately an availability issue, and any additional network latency or extra network hops will only compound this issue. If you adopt a write-behind model in which you immediately return a confirmation of a successful write and then try and propagate the change after the fact, you risk the two datastores falling out of synchronization, leaving inconsistent data.
The solution here is to use a local caching layer such as Geode or Cassandra. Using a distributed data layer that ensures eventual consistency over a wide-area network (WAN) makes it possible for you to preserve changes locally, allowing a fast response (and HA) to the end user. In write-behind mode, these technologies can then propagate the write both to a local backing database and across a WAN to another grid in your other data center. After the data update is in the second data center, the second grid can also persist the changes locally. If a conflict does occur, technologies such as Geode employ various conflict resolution algorithms to ensure that the system is eventually consistent. Although no eventually consistent system is bulletproof, they provide a solid solution to the intrinsically challenging problem of data consistency across a WAN.
HA IaaS Configuration
Establishing the correct infrastructure configuration is essential for establishing HA. As discussed in “Infrastructure Failures”, if your infrastructure is either resource constrained or misconfigured, it can have catastrophic effects on the overall health of Cloud Foundry and the apps running on it. This section briefly describes the failure boundaries for AWS, and then explores the failure boundaries for vCenter in closer detail.
AWS Failure Boundaries
When considering HA, it is important to understand the failure boundaries. For example, AWS HA failure boundaries (along with their subsequent requirements) are fairly straightforward: Cloud Foundry AZs map directly to AWS AZs. As you can see in Figure 16-1, this configuration uses a VPC with three AZs: AZ1, AZ2, and AZ3. Each AZ has a private, dedicated subnet and the Cloud Foundry components will be striped across the three AZs.

Figure 16-1. AWS Reference Architecture using three AZs to establish HA
Because AWS failure boundaries are so well defined by AZs and private, dedicated subnets that map one-to-one directly to Cloud Foundry AZs, this configuration is straighforward and does not require an in-depth analysis.
vCenter Failure Boundaries
This section explores the host configuration for a vCenter cluster. Establishing failure boundaries for on-premises IaaS is nuanced, and therefore, you are required to understand more about the underlying host configuration.
You can use vSphere HA in conjunction with the BOSH Resurrector, provided that the resurrection cadence is different. Using both capabilities can augment the HA strategy for instance groups in a powerful way. Ideally, for vCenter, a cluster should have a minimum of two hosts for resiliency, but preferably three. Even though the vSphere HA can bring back failed VMs, in a complete host failure situation, a single host ESXi cluster would render the cluster inoperable. For that reason, a minimum of two hosts per cluster (although three is preferable) ensures that you do not lose an entire AZ if a host server fails.
Therefore, sizing your infrastructure with three Cloud Foundry AZs and three hosts per cluster will result in a nine-host cluster. Some companies at this point become concerned that they are oversizing their IaaS. It is important to note that, within a cluster, you can still use the logical construct of resource pools for sharing infrastructure between different Cloud Foundry installations. For example, you can run a development installation, a production installation, and sandbox, all on the same set of clusters with isolation and AZs achieved through resource pool and cluster combinations. This nine-host cluster/resource pool configuration, supporting multiple Cloud Foundry foundations, is illustrated in Figure 16-2.

Figure 16-2. Using vSphere resource pools to allow multiple Cloud Foundry installations to use the same cluster sets
In line with the previous AWS example, Figure 16-3 presents a topology diagram for the vCenter scenario described, including a sensible networking definition.
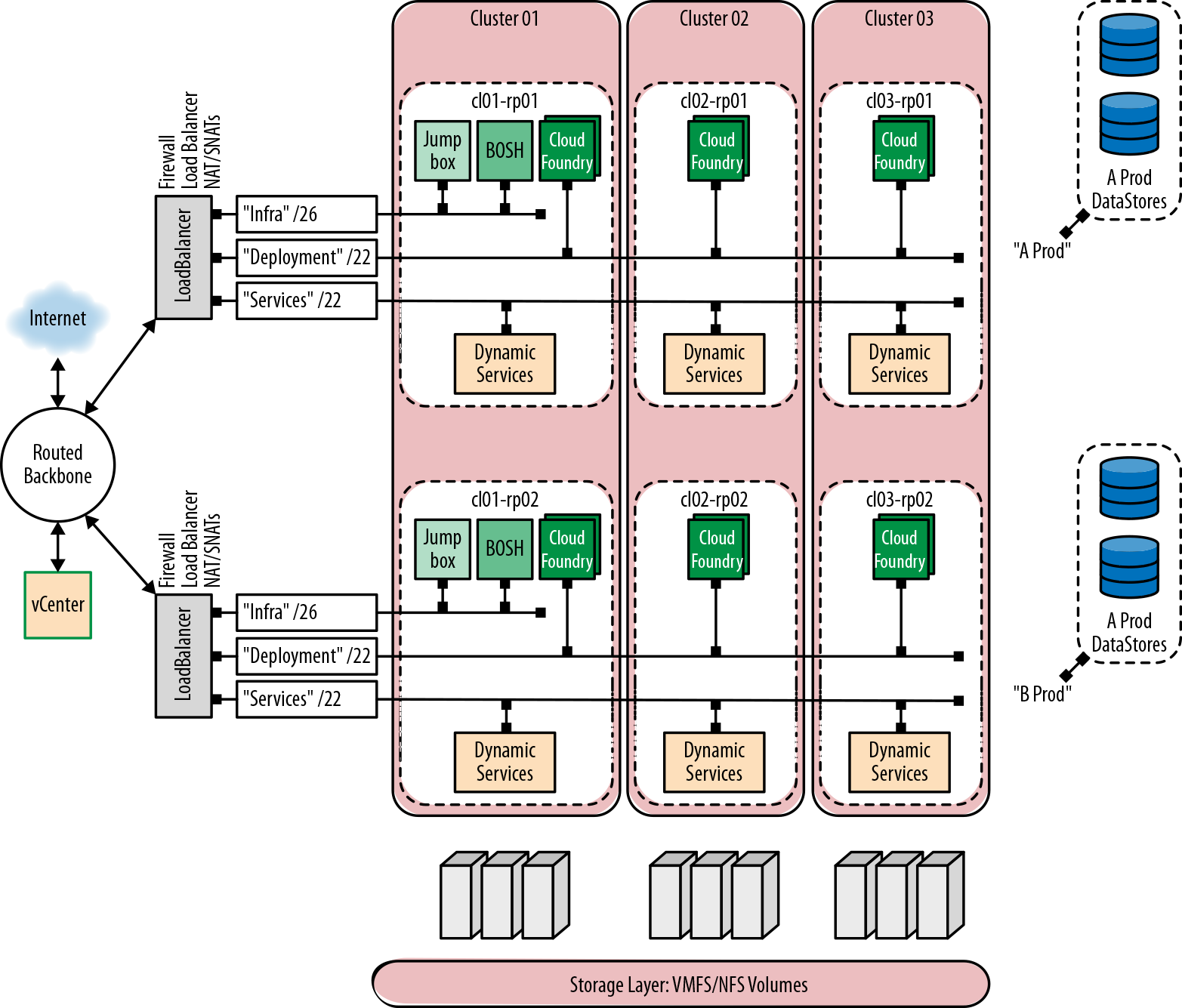
Figure 16-3. An HA Cloud Foundry architecture with two Cloud Foundry deployments spanning three vCenter clusters
When configuring your capacity for Cloud Foundry, you need to take into consideration the HA capabilities and effects of the underlying infrastructure. vSphere HA works in two ways. Primarily there is the reactive action of booting VMs that have lost a host on which to run. In addition, vSphere also employs a construct known as admission control.
Admission Control guards capacity and prevents new VMs from being powered on if it violates the capacity retention policy. This means that you can have a cluster of hosts that has plenty of spare capacity but will not boot additional VMs because Admission Control prevents you from eating into capacity you previously specified as reserved. You can disable Admission Control, but it is usually turned on. A typical configuration with both Admission Control and vSphere HA turned on often has each cluster establish one protected host. The default Admission Control policy is n + 1 host protection so that each cluster effectively loses a host’s worth of capacity. With this configuration, a nine-host environment (three clusters each with three hosts) will result in only six hosts of capacity.
Cluster Configuration
With the Admission Control and vSphere HA configuration, a two-host cluster will still establish one protected host. Therefore, this configuration yields only one host of capacity per cluster. If you are striving for a higher-utilization model, three hosts is the preferred option, provided that you have the need for total capacity.
As with other IaaS technologies, many other configurations are possible. For example, it is totally feasible to configure a three-host cluster with vSphere HA turned on and Admission Control turned off. This will provide 100 percent capacity available for VMs but if you lose an entire host, there can well be insufficient capacity to reboot the lost VMs.
The key takeaway here is that Cloud Foundry is a consolidation play (containers) on top of a consolidation play (virtualization). Do not cheat yourself at either layer. You need adequate HA and capacity at every layer (hardware, IaaS, Cloud Foundry) in order for the platform to function as desired and to protect your workload from failures at any layer.
Backup and Restore
From time to time, you might need to completely restore your environment. This could be due to any of these situations:
-
Creating a carbon copy of an existing deployment to create a brand new environment
-
Maintenance reasons such as swapping out or upgrading your networking, server, or storage layer
-
Recovering from a data center–wide malicious attack that causes a catastrophic failure
There are several projects that exist to back up and restore Cloud Foundry. Here are a couple of them:
The latter is focused on Pivotal Cloud Foundry, but, with the exception of backing up Pivotal’s Operations Manager configuration, most of the underlying principles (e.g., backing up the databases) apply to any Cloud Foundry installation.
To restore your environment, you first need to create a backup of the data layer. When thinking about Cloud Foundry from a disaster recovery perspective, you need to forget all of the moving parts—all the processes—and think about the distributed system as a set of persistent disks holding the following:
-
The CCDB
-
The UAA database
-
The BBS
-
The BOSH DB
-
The blobstore or NFS server
-
Configuration (all deployment manifests, including BOSH itself)
-
Any other app-centric persistence layer (e.g., Pivotal Cloud Foundry uses an additional App Manager database)
The persistence layer is Cloud Foundry from a disaster recovery perspective; everything else—all of the running processes—can easily be wired back in.
Cloud Foundry Availability
Backing up Cloud Foundry will suspend Cloud Controller writes for the duration of the backup. This is important because you cannot simultaneously write to a database and keep the integrity of the database backup. Suspending the Cloud Controller writes (thus effectively taking CAPI offline) will cause your foundation to become read-only for the duration of the backup. App pushes and so on will not work during this time, but your existing apps will still be running and able to accept traffic.
Restoring BOSH
Bringing back BOSH is the first step to recovering any offline Cloud Foundry environment. Therefore, it is vital that you back up the original BOSH manifest (let’s call it bosh.yml) and take regular snapshots of the BOSH DB or attached BOSH disk. With your bosh.yml, you can bring your original BOSH back, provided that you have a snapshot of the disk volume that contains the BOSH DB and blobstore, or you can use an external DB like MySQL on AWS-RDS and an external blobstore like Amazon S3. You must, however, bring BOSH back on the original IP as the BOSH worker nodes. Your BOSH-deployed machines hosting your deployments will have BOSH agents that are configured to communicate with BOSH on that original IP.
It’s best to use an external database like clustered MySQL or AWS-RDS and an external blobstore like Amazon S3. However, if you use BOSH’s internal database, there are some additional steps required to back up and restore BOSH’s internal database and blobstore.
For illustrative purposes, when using AWS, you can use the following steps to back up BOSH’s internal database and blobstore:
-
Using SSH, connect to BOSH:
$ ssh -i key vcap@boship -
Become root:
$ su -(use your VM credentials) -
Run
$ monit summaryto view all BOSH processes -
Run
$ monit stop allto cleanly stop all BOSH processes -
Take a snapshot of the BOSH persistent disk volume
Here are the steps to restore BOSH’s internal database and blobstore:
-
Using your original bosh.yml manifest, rebuild BOSH. This creates a new empty persistent disk.
-
Repeat steps 1 through 4 of the backup procedure. You will need to stop all processes before detaching the persistent disk.
-
Detach the persistent disk (deleting it).
-
Create a new volume from your disk volume snapshot, and then manually attach the new volume to the BOSH VM.
-
Start all processes again. BOSH will now have the same BOSH UUID (because it is stored in the database).
Bringing Back Cloud Foundry
After you have successfully restored BOSH, BOSH itself should successfully restore the Cloud Foundry deployment, assuming that you have used an external and reachable database and blobstore for the other components.
Validating Platform Integrity in Production
This section discusses how to validate the health and integrity of your production environment. After you have successfully deployed Cloud Foundry, you should run the smoke tests and CATS to ensure that your environment is working properly. You should also maintain a dedicated sandbox to try out any changes prior to altering any development or production environment.
Start with a Sandbox
If you run business-critical workloads on a production instance of Cloud Foundry, you should consider using a sandbox/staging environment prior to making any production platform changes. This approach gives you the ability to test any production apps in an isolated way before rolling out new platform changes (be it an infrastructure upgrade, stemcell change, Cloud Foundry release upgrade, buildpack change, or service upgrade) to production.
The sandbox environment should mirror the production environment as closely as possible. It should also contain a representation of the production apps and a mock up of the production services to ensure that you validate the health of the apps running on the platform.
Production Verification Testing
To test the behavior of your platform before making the production environment live, run the following:
-
cf-smoke-teststo ensure that core Cloud Foundry functionality is working -
cf-acceptance-teststo test Cloud Foundry behavior and component integration in more detail -
Your own custom acceptance tests against the apps and services you have written, including any established or customized configuration, ensuring established app behavior does not break
-
External monitoring against your deployed apps
An example set of app tests could include the following:
-
Use
cf pushto push the app. -
Bind the app to a service(s).
-
Start the app.
-
Target the app on a restful endpoint and validate the response.
-
Target the app on a restful endpoint to write to a given data service.
-
Target the app on a restful endpoint to read a written value.
-
Generate and log a unique string to validate app logging.
-
Stop the app.
-
Delete the app.
This set of tests should be designed to exercise the app’s core user-facing functionality, including the app’s interaction with any backing services.
Running these sorts of tests against each Cloud Foundry instance on a CI server with a metrics dashboard is the desired approach for ease of repeatability. Not only do you get volume testing for free (e.g., you can easily fill up a buildpack cache that way), you can publish the dashboard URL to both your platform consumers (namely developers) and stakeholders (namely line of business owners) alike. Linking these tests to alerting/paging systems is also better than paging people due to IaaS-level failures.
After you make the environment live, it is still important to identify any unintended behavior changes. Therefore, the ongoing periodic running of platform validation tests in production is absolutely recommended. For example, it is possible that you may uncover a problem with the underlying infrastructure that can be noticed only by running your platform validation tests in production.
Summary
This chapter provided you with a core understanding of the issues, decision points, and built-in capabilities pertaining to platform resiliency.
The key consideration in ensuring that your platform is resilient is understanding the environmental failure boundaries. When you have established those boundaries and assessed your appetite for risk versus cost, you will be in a much better position to design your Cloud Foundry topology for the desired level of HA.
After you have provisioned your Cloud Foundry environment, it is essential to make regular backups. Backup and restore is not as complex as it might first appear; however, making regular backups and, in addition, frequently testing that you can successfully restore your Cloud Foundry environment, should be a part of your ongoing disaster recovery plan.
Consuming and reacting to system events and logging information will also help establish resiliency. Using a sandbox/staging environment prior to making any production platform changes provides an additional defense against introducing instability to the platform. Finally, you should continue to run your platform tests (smoke tests, platform and app verification tests, etc.) to ensure that your environment is working properly. If you do all of this, you will be in much better shape if unforeseen issues do arise.
1 Cloud Foundry component and app redundancy is covered in “Instance group replication”.
2 HA that is achieved purely through additional redundancy can double the total cost of ownership compared to a non-HA system.