
Chapter 9. Teamwork
When I was young, I loathed teamwork. I could usually complete school assignments faster by working by myself than in a group. I felt that other group members stole my thunder, and I resented having to argue for my way of doing things when I ‘knew’ I was right.
I don’t think that I would have much liked my younger self.
Thinking back on it, I may have self-selected into a vocation that looked promising to a person with limited interest in social interaction. I think I have that in common with quite a few other programmers.
The bad news is that as a software developer, you rarely work alone.
You work in a software development team with other programmers, product owners, managers, operations specialists, designers, etc. This is no different from the ‘real’ engineers discussed in subsection 1.3.4. They also work in teams.
A major part of being an engineer is to follow various processes. In this chapter, you’ll learn about some beneficial processes for software engineering. Use these processes to help yourself and your team mates more readily understand the code.
A word of warning: Don’t confuse process with outcome. Like checklists, following a processes improves the chance of success. The most important part of any process, however, is to understand the underlying motivation for it. When you understand why a particular process is beneficial, you know when to follow it, and when to deviate from it. In the end, it’s the outcome that matters.
Keep in mind, though, that outcomes can be positive or negative. As discussed in subsection 3.1.2, it’s impractical to measure the direct outcomes of your actions. They could have immediate positive effects now, but net negative impact over six months. For example, technical debt accrues over time.
A process works as a proxy for the actual effect you’re aiming for. It’s not a guarantee that all will go well, but it helps.
9.1 Git
Most software development organisations now use Git instead of another version control system such as CVS or Subversion. Despite its distributed nature, you typically use it with a centralised service such as GitHub, Azure DevOps Services, Stash, GitLab, etc.
Such services come with additional capabilities like work item management, statistics, or automatic backups. Managers often consider these services essential, but don’t give the actual source control features much thought.
Likewise, most software developers I’ve met think of Git as a way to integrate their code with the rest of their team’s code base. They give little thought to how they interact with it.
Used in this way, Git is almost an afterthought. That’s a wasted opportunity. Use Git tactically.
9.1.1 Commit messages
When you make a commit, you should write a commit message. For most programmers, this is an obstacle to be cleared as easily as possible. You have to write something, but while Git rejects empty commit messages, it’ll accept anything else.
People typically write what’s in the commit, and then nothing more. Examples include “FirstName Added”, “No empty saga”, or “Handle CustomerUpdated Added”1. That’s not as helpful as it could be.
1 These are real, slightly anonymised examples.
Consider the hierarchy of communication described in subsection 8.1.7. Anything you write and persist is a message to the future, for you and your team members. On the other hand, focus on communication over writing. You don’t have to spend much time explaining what changed in in a commit. The commit diff already contains that information.
Focus on communication over writing.
Believe it or not, a standard for Git commit messages exists. It’s known as the 50/72 rule, and it’s not an official standard, but rather a de-facto standard based on experience with the tool[80].
• Write a summary in the imperative, no wider than 50 characters.
• If you add more text, leave the second line blank.
• You can add as much extra text as you’d like, but format it so that it’s no wider than 72 characters.
These rules are based on how various Git features work. For example, if you want to see a list of commits, you can use git log --oneline:
$ git log --oneline 8fa3e47 (HEAD) Make /reservations URL segment lowercase fbf74ae Return IDs from database in range query 033388a Return 404 Not Found for non-guid id 0f97b34 Return 404 Not Found for absent reservation ee3c786 Read existing reservation 62f3a56 Introduce TimeOfDay struct
Such a list shows the summary line from each commit, but none of the rest of the commit message. Even if you don’t use Git from the command line, someone else might. Additionally, some graphical user interfaces that make Git more friendly actually interoperate with the Git command-line API. There’ll be less friction if you follow the 50/72 rule.
The summary serves as a headline or a chapter title. It enables you to navigate the history of the repository. Thus, it’s an exception from the rule that you don’t need to explain what changed in the commit.
Write the summary in the imperative mood. While there isn’t a strong force behind this particular rule, it’s a convention. For years, I wrote my commit messages in the past tense while following the formatting rules of the 50/72 rule, and that gave me no problems. I did it because I found it more natural to describe the work I’d just performed in the past tense, and no-one had told me about the rule about using imperative mood. Once I learned about that rule, I reluctantly changed my ways, none the worse for wear.
Usually, the imperative form is shorter than the past-tense form. For example, ‘return’ is shorter than ‘returned’. This, at least, gives you a slight advantage when you struggle to fit a summary into 50 characters.
You don’t have to write more than the summary, and often, if the commit is small and self-explanatory, that’s all I do.
The commit diff already contains information about what changed, and the code itself is the artefact that controls how the software behaves. There’s no reason to repeat that information in the commit message.
While you can find answers to questions about what and how elsewhere, a commit message is often the best place to explain why a change was made, or why it took that form. Here’s a short example:
Introduce TimeOfDay struct This makes the roles of the constructor parameters to MaitreD clearer. A large part of the TimeOfDay type was autogenerated by Visual Studio.
The message answers two questions:
• Why was the TimeOfDay type introduced?
• Why does it look like most of the code wasn’t driven by tests?
You can find many other examples of commit messages that answer why questions in the code repository that accompanies the book.
Struggling to understand the rationale behind code may be the highest-ranked problem in software development[24], so it’s important to make it clear.
9.1.2 Continuous Integration
Continuous Integration is already established in most software development organisations. Except that it isn’t.
While everyone seems to ‘know’ that Continuous Integration is a proper software engineering practice, most confuse it with having a Continuous Integration server. Such a server is a fine thing to have, but doesn’t guarantee that you do Continuous Integration.
Continuous Integration is a practice. It’s a way to work. You do what it says on the tin: you continually integrate your code with the code that your colleagues are working on.
Integration means merging, and you shouldn’t take the word continuous too literally. The point, though, is to frequently share your code with everyone else. How frequently? As a rule of thumb, at least every four hours2.
2 More frequent integration would be even better. At the limit, you could integrate every time you’ve made a change and all tests pass.
I’ve met quite a few developers who’d tell me that the reason that Git is so great is that it solves the problem of ‘merge hell’. Ironically, it doesn’t. It does, however, foster a workflow different from centralised source control system workflows.
The underlying problem with merge hell is the same as any other kind of concurrent work on a shared resource. It’s the same problem as with database transactions. You have more than one client that wishes to modify a shared resource. With source control, the resource is code rather than database rows, but the problem is the same.
You can solve this problem in a few ways. Databases have historically offered transactions as a solution. This involves taking locks on resources.
Visual SourceSafe also worked that way. As soon as you changed a bit in a file, SourceSafe would mark that file as checked out, and on-one else could edit it until it got checked in again.
Sometimes, people would go home for the day, leaving files checked out. This effectively prevented other people working at other schedules from doing anything with that file. Pessimistic locking doesn’t scale well.
Optimistic locking tends to be a more scalable tactic, as long as contention is unlikely[55]. Before you start modifying a resource, you take a snapshot3 of it. Then you edit it. When you want to save your changes, you compare the current state with the snapshot, as illustrated in figure 9.1. If you can tell that the resource didn’t change since you began modifying it, you can safely save your changes.
3 You can also use a hash or a database-generated row version.
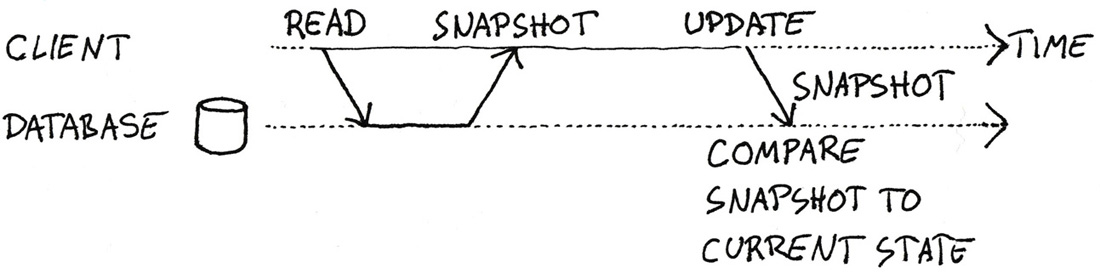
Figure 9.1: Optimistic locking. A client first reads the current version of a resource from the database. While it edits the resource, it also retains a copy of the snapshot. When it wishes to update the resource, it also sends the snapshot copy along for the ride. The database compares the snapshot with the current state of the resource. Only if the snapshot matches the current state does the update complete.
Even if the resource was edited, you may be able to merge the two changes. If a database row was edited, but different columns were changed, you could still apply your changes. If you’re editing a code file, merging is possible if your colleague changed a different part of the file than you did4.
4 There’s no guarantee that the merged result makes sense, though.
If, however, you’re both editing the same line of code at the same time, you have a merge conflict. How do you avoid that? In the same way that you do with optimistic locking. You can’t guarantee that it’ll never happen, but you can make it unlikely. The shorter the time you spend editing the code, the less likely it is that someone else made a change to the same part at the same time.
You may have heard that Continuous Integration means ‘running on trunk’. Some people seem to take that so literally that they don’t create branches in Git. Instead, they write everything on master.
The only thing you accomplish by doing that is to demonstrate that you haven’t understood what the problem is. The problem is concurrency - not the name of the Git branch on which you’re working. Unless you’re doing mob programming5 with all your colleagues, there’s always a risk that one of your co-workers is editing the same line of code that you are.
5 For details about mob programming, see subsection 9.2.2.
Decrease that risk. Make small changes, and merge as often as you can. I recommend that you integrate at least every four hours. It’s a somewhat arbitrary period; I picked it because it represents approximately half a day’s work. You shouldn’t sit on something for more than half a day before you share it with the rest of your team. Otherwise, your local Git repositories are going to diverge, and the result with be merge hell.
If you can’t complete a feature in four hours, then hide it behind a feature flag6 and integrate the code anyway[49].
6 See section 10.1 for more details.
9.1.3 Small commits
There’s much variance in programming. Sometimes, you can produce much code in four hours. At other times, half a day goes by without a single line of working code. Trying to replicate or understand a bug can take hours. Learning how to use an unfamiliar API may require days of research. Sometimes, it turns out that you’ll have to scrap the code you spent a couple of hours writing. All of that is normal.
A major benefit of Git is the manoeuvrability that it provides; that it enables you to experiment, as illustrated by figure 9.2. Try out some code. If it works, commit it. If not, reset. This works best if you make many small commits. If the last commit you made was a small one, it means that throwing it away only discards the code that you actually want to get rid of.

Figure 9.2: When you make many small commits, mistakes are cheap. You can even commit the mistakes and abandon them on side branches, if it should turn out that you need them later. The yeah branch looks promising. Once you’ve reached a good checkpoint on that branch, integrate it with master.
Git is a distributed version control system. Until you share your changes with other people or systems, the commits are only on your local hard drive. This means that you can edit your commit history before you push it.
I relish the ability to edit local Git branches before I push them. Not that I find it necessary to hide my mistakes or appear supernaturally prescient, but because it liberates me to experiment and still enables me to leave behind a coherent commit trail.
If you make coarse-grained commits, you can’t easily manipulate your code’s history. You may regret some changes you made, but when they’re bundled with unrelated edits in a single big commit, as in figure 9.3, you can’t easily undo only the changes you wish to get rid of.
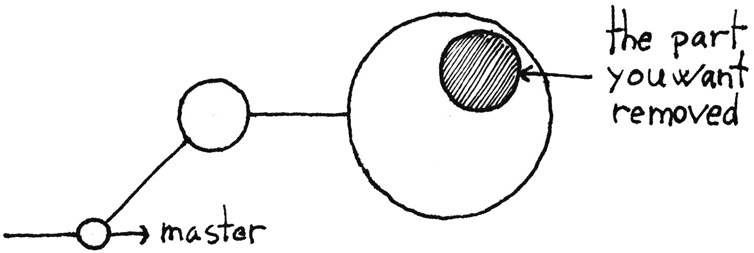
Figure 9.3: When you make coarse-grained commits, it can be hard to later undo only parts of them. Here, a commit contains some code that you’d like to undo, but it’s an integral part of that Death Star commit, which also contains code that you’d like to keep.
Your commit history should be a series of snapshots of working software. Don’t commit code that doesn’t work. On the other hand, every time your code successfully builds, then commit it. Make micro-commits[77].
• Rename a symbol; commit
• Extract a method; commit
• Inline a method; commit
• Add a test and make it pass; commit
• Add a Guard Clause; commit
• Fix the way code is formatted; commit
• Add a comment; commit
• Delete redundant code; commit
• Fix a typo; commit
In practice, you can’t make all commits small. The example Git repository that accompanies this book has lots of micro-commit examples, but you’ll also be able to find the occasional larger commit.
The more small commits you have, the easier you can change your mind.
After a couple of hours, you may have tried lots of things that you then abandoned. The result may be only a handful of small, good commits. Clean up your local branch and integrate it with master.
9.2 Collective code ownership
Is there a part of your code base where only Irina works on? What happens when she goes on vacation? What happens when she’s sick? What happens if she quits?
You can organise code ownership in multiple ways, but if a single person ‘owns’ a part of the code base, you’re vulnerable to team changes. Every owner becomes a critical resource - a single point of failure. It also makes refactoring harder. You can’t easily rename a method if one developer owns the method and another programmer owns the code that calls the method[30].
By sharing the code, you increase the bus factor. Ideally, there should be no part of the code base where only one person dares to go.
Bus factor
How many team members can be hit by a bus before development halts?
You want that number to be as high as possible. If it’s 1, it means that if only one team member is out of commission, development flounders.
Some people dislike the morbid connotation of the term, and instead prefer to ask: Can the team survive if Vera wins the lottery and quits? The notion is then named the lottery factor, but the idea is the same.
Regardless of what you call it, the point is to raise awareness that circumstances change. Team members come and go. In addition to winning the lottery, or getting hit by a bus, people get reassigned, or they simply quit their job for a myriad of reasons.
The point isn’t to actually measure any factor, but to organise work so that no single person is indispensable.
When you have more than one programmer on a team, people tend to specialise. Some developers prefer user-interface programming, while others thrive with back-end development. Collective code ownership doesn’t prohibit specialisation, but as figure 9.4 illustrates, it favours overlap of responsibilities.

Figure 9.4: Three developers (Ann, Max, and Sue) work on a code base. Ann prefers working on the left and top module (e.g. HTTP API and Domain Model). Max favours the top and right module, while Sue likes the two bottom modules best. All share a part of the code base with another team member.
I avoid user-interface development if I can, but if there’s only one other user-interface programmer on my team, I ought to take responsibility for that part of the code base as well. As soon as there’s more than one team member who handles the user interface, I may decide that it’s in good hands. This enables me to focus on parts closer to my heart.
As argued in chapter 3, the code is the only artefact that matters. Collective code ownership entails, then, that you must constantly answer the following question in the affirmative:
Does the team contain more than one person comfortable working with a particular part of the code?
In other words, at least two active maintainers of the code base should approve the changes.
You can do this in formal and informal ways, including pair programming and code reviews. The key is that any code change involves more than one person.
9.2.1 Pair programming
Pair programming[5] involves two software developers collaborating in real time on the same problem. There are several styles of pair programming[12], but they all share the feature that collaboration happens in real time.
The process includes continuous, on-the-go code reviews[12]. Code produced by a pair represents agreement on implementation details. The resulting commits already contain code that at least two persons are comfortable with. As approval processes go, it doesn’t get more informal than that.
I’ve seen teams who find this too informal. They add notes about coauthors in commit messages or when they merge the changes into master. This is entirely optional.
Pair programming can be an effective means to achieve collective code ownership.
“Consistent pairing makes sure that every line of code was touched or seen by at least 2 people. This increases the chances that any-one on the team feels comfortable changing the code almost anywhere. It also makes the codebase more consistent than it would be with single coders only.
“Pair programming alone does not guarantee you achieve collective code ownership. You need to make sure that you also rotate people through different pairs and areas of the code, to prevent knowledge silos.”[12]
It’s almost as if pair programming comes with real-time code review and informal approval process as a side effect. It’s a low-latency sort of review. Since you’re already two team members working on the code, you don’t have to wait for anyone else to later approve the changes.
Even so, not everyone likes pair programming. As a typical introvert[16], I personally find the activity exhausting. It also leaves little room for contemplation, and it requires synchronisation of schedules.
I don’t insist that all teams pair-program, but it’s hard to argue against the above benefits7. Regardless, it’s hardly practical or desirable to do it all the time[12]. You can mix pair programming with other processes in this chapter to arrive at a mix that suits your particular organisation.
7 There’s also some evidence that it’s an efficient way to work[115].
9.2.2 Mob programming
If two programmers working together on a problem is good, then three developers working together must be even better. And what about four people? Five?
If you can hijack a conference room or another space where a group of people can write code in collaboration, you can engage in mob programming8.
8 I dislike the term mob programming, since a mob, to me, is an unthinking horde. Ensemble programming[83] might be a better term.
It’s hard enough to convince management (or even your fellow developers) that pair programming is productive. The knee-jerk reaction is that two people working on the same problem must exhibit half the productivity of two people working concurrently on two separate problems. It’s even harder to convince naysayers that three or more people working on the same problem doesn’t represent a drop in productivity.
I hope that, since you’ve made it so far into the book, you’re convinced that productivity is unrelated to how fast someone types on a keyboard.
There’s likely a point of diminishing returns. Imagine trying to mob-program with 50 people. The majority would have little to contribute, or, alternatively, nothing would get done if you had to achieve group consensus.
It seems, though, that there’s a sweet spot for small groups.
Mob programming isn’t my default modus operandi, but I find it useful in certain circumstances.
I’ve used it with great success as a programming coach. In one engagement, I spent 2-3 days a week with a few other programmers, helping them apply test-driven development practices to their production code bases. After a few months of that, I went on vacation. Meanwhile those programmers kept going with test-driven development. Mob programming is great for knowledge transfer.
Since it involves more than one person collaborating on a single set of code changes, you get all the review and approval benefits from mob programming that pair programming gives you.
Try it, if possible. Use it if you like it.
9.2.3 Code review latency
As Laurent Bossavit convincingly argues, most ‘common knowledge’ in software development is more myth than reality[13]. Only a few practices have documented effects. A code review is one such practice[20].
It’s one of the most effective ways to find defects in code[65], yet most organisations don’t use them. A prevalent reason is that people feel that it slows down development.
It’s true that a code review can introduce latency into the development process. It is, however, a mistake to believe that development is more efficient if most bugs remain undetected until much later.
In most organisations I’ve helped, a piece of work (typically termed a feature) is handled by a single developer. When that programmer declares the work done, no further vetting takes place.
Various organisations have different definitions of done. Some operate with the catchphrase done done to imply that the work is only done when the feature is complete and available for use in the production system.
As you learned in subsection 3.1.2, a too myopic focus on delivering ‘value’ may overlook problems arising from pushing a rickety, erratic, spurious feature to production.
Figure 9.5 illustrates a situation where you declare a feature done. Later, a defect is found. At that time, you’re working on something else. Fixing the bug isn’t part of the plan. Your team may decide to remedy the situation, but since it’s unplanned work, it strains your capacity. Either you work overtime, or you miss the deadline on other features.

Figure 9.5: Many organisations don’t perform code reviews. When a developer declares a feature done, a long time may pass before a bug is discovered. This leads to unplanned work.
Missed deadlines encourage crunch mode: a combination of working long hours and weekends with constant firefighting. There’s never time to do things ‘right’ because there’s always a new unanticipated problem that you have to deal with. This is a vicious circle.
With code reviews you can effectively detect problems before you declare the work done. Preventing defects becomes part of the process instead of part of the problem.
The problem with typical approaches is illustrated by figure 9.6. A developer submits a piece of work for review. Then much time passes before the review takes place.

Figure 9.6: How not to do code reviews: let much time pass between completion of a feature and the review. (The smaller boxes to the right of the review indicates improvements based on the initial review, and a subsequent review of the improvements.)
Figure 9.7 illustrates an obvious solution to the problem. Reduce the wait time. Make code reviews part of the daily rhythm of the organisation.

Figure 9.7: Reduce the wait time between feature completion and code review. A review will typically spark some improvements, and a smaller review of those improvements. These activities are indicated by the smaller boxes to the right of the review.
Most people already have a routine that they follow. You should make code reviews part of that routine. You can do that on an individual level, or you can structure your team around a daily rhythm. Many teams already have a daily stand-up. Such a regularly occurring event creates an anchor around which the day revolves. Typically, lunchtime is another natural break in work.
Consider, for example, setting aside half an hour each morning, as well as half an hour after lunch9, for reviews.
9 You could also set aside half an hour before lunch, as well as before you go home for the day, but you’d be more likely to skip the activities becuase you’d be in the middle of doing something else.
Keep in mind that you should make only small sets of changes. Sets that represent less than half a day’s work. If you do that, and all team members review those small changes twice a day, the maximum wait time will be around four hours.
9.2.4 Rejecting a change set
I once helped a development organisation transition from developers working in isolated silos with little cooperation to collective code ownership. One practice I wanted to teach them was taking small steps.
Soon, I received a pull request from a remote developer I hadn’t heard from in a couple of weeks. It was massive. Thousands of lines to review, distributed over fifty files.
I didn’t review it. I immediately rejected it, on the grounds of being too big10. Then I worked with the entire team, showing them how to make small changes. I never again received a pull request of that size.
10 I had the support of management to do this. Sometimes, consultants are permitted to do things regular employees aren’t. Unfair, yes, but true.
Every time you perform a code review, saying no should be a real option. A code review is worth nothing if it’s only a rubber stamp.
I often see people submit a big change for review. A big change set represents days (or weeks) of work. Reviewing a big change set takes a long time[77]. Such a review can often drag on for days while the author tries to address your myriad concerns.
Either that, or you give up and accept the changes because you have other work to do.
Don’t do that. Reject big change sets.
Reviewers are often reluctant to reject a change set that represents days of work. This is a common problem knowns as the sunk cost fallacy[51]. True, your colleague has already spent much time making the changes, but if you think that you’ll have to waste more time maintaining a poor design, then the choice is clear. Cut your losses. The time your colleague wasted is already lost. Don’t waste more time on badly organised code.
Rejecting days or weeks of work hurts. Rejecting a few hours of work is more palatable. That’s one more reason to make small changes that represent half a day’s work.
Besides, a code review that takes more than an hour isn’t effective[20].
9.2.5 Code reviews
The most fundamental question that a code review should answer is this:
Will I be okay maintaining this?
That’s really it11. You can assume, I think, that the author will be happy to maintain his or her own code. If you’re also ready to maintain it, then you’re two persons, and you’re on the way to collective code ownership.
11 To be fair, you shouldn’t forget an even more important and basic question: Does the change address a valid concern? Sometimes, you misunderstand your assignment. I’ve done that. We all do that. It’s worth keeping that question in mind during a code review. It can be a cause to reject a change, but I don’t consider it the prime focus of a code review.
What should you look for in a code review?
The most important criterion is whether the code is readable. Does it fit in your brain?
Keep in mind that documentation (if it even exists) is typically stale, comments can be misleading, and so on. Ultimately, the only artefact you can trust is the code. The day you have to maintain it, the author may no longer be around.
Some people conduct reviews by sitting together. The author guides the reviewer through the changes. This is undesirable:
• The reviewer is unable to judge whether the code is readable on its own merits.
• The author may be able to fast-talk the reviewer into overlooking problematic practices.
Code reviews should be conducted by the reviewer reading the code at his or her own pace. The author just wrote the code, so he or she isn’t in a position to evaluate whether the code is readable. That’s the reason he or she shouldn’t be actively involved in the code reading.
While rejection should be a real option, your job as a reviewer isn’t to hurt the author or to prove your own superiority. It’s to reach an agreement on how to move forward.
Nitpicking typically isn’t helpful, so don’t worry too much about code formatting or variable names12. Consider whether the code fits in your brain. Are methods too long or too complex?
12 You can always change the formatting later, or fix a typo in a variable name. As long as a fix doesn’t constitute a breaking change, don’t let it drag out the review. On the other hand, typos in public APIs should be addressed, because fixing them would constitute breaking changes.
Cory House suggests things to look for[47]:
• Does the code work as intended?
• Is the intent clear?
• Is there needless duplication?
• Could existing code have solved this?
• Could this be simpler?
• Are the tests comprehensive and clear?
This isn’t an exhaustive list, but it gives you an idea what to look for.
The outcome of a code review typically isn’t a binary accept/reject decision. Instead, a review produces a list of suggestions that the author and the reviewer can use to engage in a dialogue. While the author should be absent from the actual code reading, friendly interpersonal interaction can help speed up the rest of the process.
You’ll typically agree on some improvements. The author goes back to implement them, and submits the new changes for a repeat review, as illustrated in figure 9.7. This is an iterative process. Subsequent reviews tend to be quicker. Soon, you reach consensus and integrate the changes.
All team members should be authors, and all team members should review other team members’ code. Being a reviewer is neither a privilege nor a burden reserved for the elect few.
Not only does that stimulate collective code ownership, but it also encourages everyone to conduct reviews in a civilised manner.
9.2.6 Pull requests
Online Git services like GitHub, Azure DevOps Services, etc. support GitHub flow13, which is a lightweight team workflow where you create branches on your local machine, but use the centralised service to handle merges.
13 Not to be confused with Git flow
When you wish to merge a branch into master, you can issue a pull request. This represents an appeal for your changes to be integrated with the master branch.
In many team settings, you typically have sufficient permissions to complete the merge yourself. Nevertheless, you should make it a team policy that someone else must review and sign off on the changes. This is just another way to perform a code review.
When you create a pull request, keep the rules for working with Git in mind. Specifically[90]:
• Make each pull request as small as possible. That’s smaller than you think.
• Do only one thing in each pull request. If you want to do multiple things, put them in separate pull requests.
• Avoid reformatting, unless that’s the only thing the pull request does.
• Make sure the code builds.
• Make sure all tests pass.
• Add tests of new behaviour.
• Write proper commit messages.
When you review a pull request, all the points about performing a code review apply. In addition, GitHub flow is an asynchronous workflow, so you’ll typically be doing the review by writing. Keep in mind that tone and intent is easily lost in writing. You may mean no harm with a particular phrasing, but the recipient may read it in a way that hurts. Be extra polite and use emojis to indicate your friendly attitude.
As a reviewer, you should take the time it takes to do a proper review. Keep in mind that if the pull request is too big, it’s better to decline it14 than rubber-stamp approve it.
14 Beginners often submit oversized pull requests because they don’t know how to split their work into smaller parts. That’s what code that fits in your brain is all about, but it’s not something that everyone knows how to do from day one. Help your colleagues with that.
If you decide to take on the review, work with the author to make improvements. Don’t just point out things you don’t like; offer concrete alternatives. Remember to cheer when you see something you like. Pull down the code and run it on your own machine[112].
9.3 Conclusion
Every team member has a few strong skills. It’s only natural that you gravitate towards the part of the code base that best suits you. If everyone does that, it may engender a sense of ownership. That’s fine as long as it remains weak code ownership[30]. This is when a piece of code has a ‘natural’ owner or main developer, but everyone is allowed to make changes to it.
You should promote collective code ownership by processes that call for more than a single person being responsible for every change to the code base. You can do this informally with pair or mob programming, or more formally with code reviews.
As subsection 1.3.4 discussed, ‘real’ engineers work in teams, and they sign off on each others’ work[40]. Having more than one pair of eyes on everything that goes on is one of the most engineering-like practices you can adopt in software development.