
Chapter 11. Editing Unit Tests
Few code bases are bootstrapped with the practices covered in the first part of the book. They have long methods, high degrees of complexity, poor encapsulation, and little automated test coverage. We call such code bases legacy code. There’s already a great book about Working Effectively with Legacy Code[27], so I don’t intend to repeat its lessons here.
11.1 Refactoring unit tests
If you have a trustworthy automated test suite, you can apply many of the lessons from Refactoring[34]. That book discusses how to change the structure of existing code without changing its behaviour. Many of the techniques described in it are built into modern IDEs, such as renaming, extracting helper methods, moving code around, and so on. I don’t wish to spend too much time on that topic, either, because it, too, is covered in greater depth by other sources[34].
11.1.1 Changing the safety net
While Refactoring[34] explains how to change the structure of production code, given the safety net of an automated test suite, xUnit Test Patterns[66] comes with the subtitle Refactoring Test Code1.
1 Although, to be fair, it’s more a book about design patterns than about refactoring.
Test code is code you write to gather confidence that your production code works. As I’ve argued in this book, it’s easy to make mistakes when writing code. How do you know that your test code is mistake-free, then?
You don’t, but some of the practices outlined earlier improves your chances. When you use tests as a driver for your production code, you’re entering into a sort of double-entry bookkeeping[63] where the tests keep the production code in place, and the production code provides feedback about the tests.
Another mechanism that should instil trust is if you’ve been following the Red Green Refactor checklist. When you see a test fail, you know that it actually verifies something you want to verify. If you never edit the test, you can trust it to keep doing that.
What happens if you edit test code?
The more you edit test code, the less you can trust it. The backbone of refactoring, however, is a test suite:
“to refactor, the essential precondition is [...] solid tests”[34]
Formally speaking, then, you can’t refactor unit tests.
In practice, you’re going to have to edit unit test code. You should realise, however, that contrary to production code, there’s no safety net. Modify tests carefully; move deliberately.
11.1.2 Adding new test code
In test code, the safest edits you can make is to append new code. Obviously, you can add entirely new tests; that doesn’t diminish the trustworthiness of existing tests.
Clearly, adding an entirely new test class may be the most isolated edit you can make, but you can also append new test methods to an existing test class. Each test method is supposed to be independent of all other test methods, so adding a new method shouldn’t affect existing tests.
You can also append test cases to a parametrised test. If, for example, you have the test cases shown in listing 11.1, you can add another line of code, as shown in listing 11.2. That’s hardly dangerous.
[Theory] [InlineData(null, "[email protected]", "Jay Xerxes", 1)] [InlineData("not a date", "[email protected]", "Wk Hd", 8)] [InlineData("2023-11-30 20:01", null, "Thora", 19)] public async Task PostInvalidReservation(
Listing 11.1: A parametrised test method with three test cases. Listing 11.2 shows the updated code after I added a new test case. (Restaurant/b789ef1/Restaurant.RestApi.Tests/ReservationsTests.cs)
[Theory] [InlineData(null, "[email protected]", "Jay Xerxes", 1)] [InlineData("not a date", "[email protected]", "Wk Hd", 8)] [InlineData("2023-11-30 20:01", null, "Thora", 19)] [InlineData("2022-01-02 12:10", "[email protected]", "3 Beard", 0)] public async Task PostInvalidReservation(
Listing 11.2: A test method with a new test case appended, compared to listing 11.1. The line added is highlighted. (Restaurant/745dbf5/Restaurant.RestApi.Tests/ReservationsTests.cs)
You can also add assertions to existing tests. Listing 11.3 shows a single assertion in a unit test, while listing 11.4 shows the same test after I added two more assertions.
Assert.Equal(
HttpStatusCode.InternalServerError,
response.StatusCode);
Listing 11.3: A single assertion in a test method. Listing 11.4 shows the updated code after I added more assertions. (Restaurant/36f8e0f/Restaurant.RestApi.Tests/ReservationsTests.cs)
These two examples are taken from a test case that verifies what happens if you try to overbook the restaurant. In listing 11.3, the test only verifies that the HTTP response is 500 Internal Server Error2. The two new assertions verify that the HTTP response includes a clue to what might be wrong, such as the message No tables available.
2 Still a controversial design decision. See the footnote on page 101 for more details.
I often run into programmers who’ve learned that a test method may only contain a single assertion; that having multiple assertions is called Assertion Roulette. I find that too simplistic. You can view appending new assertions as a strengthening of postconditions. With the assertion in listing 11.3 any 500 Internal Server Error response would pass the test. That would include a ‘real’ error, such as a missing connection string. This could lead to false negatives, since a general error could go unnoticed.
Adding more assertions strengthens the postconditions. Any old 500 Internal Server Error will no longer do. The HTTP response must also come with content, and that content must, at least, contain the string "tables".
Assert.Equal(
HttpStatusCode.InternalServerError,
response.StatusCode);
Assert.NotNull(response.Content);
var content = await response.Content.ReadAsStringAsync();
Assert.Contains(
"tables",
content,
StringComparison.OrdinalIgnoreCase);
Listing 11.4: Verification phase after I added two more assertions, compared to listing 11.3. The lines added are highlighted. (Restaurant/0ab2792/Restaurant.RestApi.Tests/ReservationsTests.cs)
This strikes me as reminiscent of the Liskov Substitution Principle[60]. There’s many ways to express it, but in one variation, we say that subtypes may weaken preconditions and strengthen postconditions, but not the other way around. You can think of of subtyping as an ordering, and you can think of time in the same way, as illustrated by figure 11.1. Just like a subtype depends on its supertype, a point in time ‘depends’ on previous points in time. Going forward in time, you’re allowed to strengthen the postconditions of a system, just like a subtype is allowed to strengthen the postcondition of a supertype.
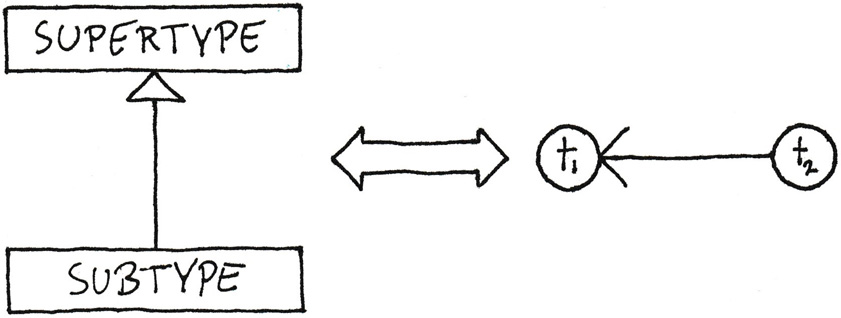
Figure 11.1: A type hierarchy forms a directed graph, as indicated by the arrow from subtype to supertype. Time, too, forms a directed graph, as indicated by the arrow from t2 to t1. Both present a way to order elements.
Think of it another way, adding new tests or assertions is fine; deleting tests or assertions would weaken the guarantees of the system. You probably don’t want that; herein lie regression bugs and breaking changes.
11.1.3 Separate refactoring of test and production code
Many code changes are ‘safe’ if you perform them correctly. Some of the refactorings described in Refactoring[34] are now included in modern IDEs. The most basic are various rename operations, such as Rename Variable and Rename Method. Others include Extract Method or Move Method.
Such refactorings tend to be ‘safe’ in the sense that you can be confident that they aren’t going to change the behaviour of the code. This also applies to test code. Use those refactorings with confidence in your production and test code alike.
Other changes are more risky3. When you perform such changes in your production code, a good test suite will alert you to any problems. If you make such changes in your test code, there’s no safety net.
3Add Parameter, for example.
Or rather, that’s not quite true...
The test code and the production code are coupled to each other, as figure 11.2 illustrates. If you introduce a bug in the production code, but didn’t change the tests, the tests may alert you to the problem. There’s no guarantee that this will happen, since you may not have any test cases that will expose the defect you just introduced, but you might be lucky. Furthermore, if the bug is a regression, you ought to already have a test of that scenario in place.

Figure 11.2: Test code and production code are coupled.
Likewise, if you edit the test code without changing the production code, a mistake may manifest as a failing test. Again, there’s no guarantee that this will happen. You could, for example, first use the Extract Method to turn a set of assertions into a helper method. This is in itself a ‘safe’ refactoring. Imagine, however, that you now go look for other occurrences of that set of assertions and replace them with a call to the new helper method. That isn’t as safe, because you could make a mistake. Perhaps you replace a small variation of the assertion set with a call to the helper method. If that variation, however, implied a stronger set of postconditions, you’ve just inadvertently weakened the tests.
While such mistakes are difficult to guard against, other mistakes will be immediately apparent. If, instead of weakening postconditions, you accidentally strengthen them too much, tests may fail. You may then inspect the failing test cases and realise that you made a mistake.
For this reason, when you need to refactor your test code, try to do it without touching the production code.
You can think of this rule as jumping from production code to test code and back to production code, as illustrated by figure 11.3.
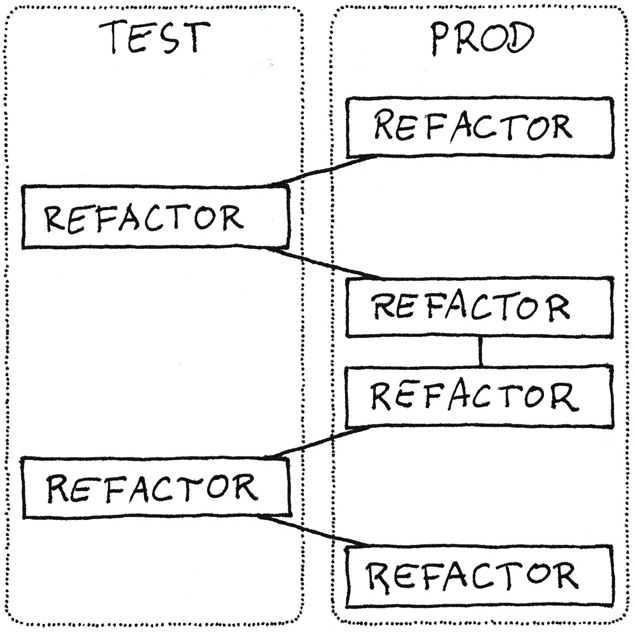
Figure 11.3: Refactor test code apart from production code. Commit each refactoring separately. It’s safer to refactor production code, so you can refactor it more often than test code. Other, safer changes, such as renaming a method, may touch both test and production code; those kinds of changes are not shown in this figure.
As an example, I was working on the restaurant code base to add email capabilities. I’d already implemented the behaviour that when you make a reservation, the system should send you a confirmation email.
Interaction with the external world is best modelled as a polymorphic type, and I favour interfaces like the one shown in listing 11.5 over base classes.
public interface IPostOffice { Task EmailReservationCreated(Reservation reservation); }
Listing 11.5: Initial iteration of the IPostOffice interface. (Restaurant/b85ab3e/Restaurant.RestApi/IPostOffice.cs)
To unit test that the system sends an email under the right circumstances, I added the Test Spy[66] shown in listing 11.6 to keep an eye on indirect output[66].
public class SpyPostOffice : Collection<Reservation>, IPostOffice { public Task EmailReservationCreated(Reservation reservation) { Add(reservation); return Task.CompletedTask; } }
Listing 11.6: Initial version of SpyPostOffice, implementing the version of IPostOffice shown in listing 11.5. (Restaurant/b85ab3e/Restaurant.RestApi.Tests/SpyPostOffice.cs)
Notice that SpyPostOffice inherits from a collection base class. This enables the implementation to Add the reservation to itself. A test can use this behaviour to verify that the system invokes the EmailReservationCreated method; that it sends an email, so to speak.
A test can create an instance of SpyPostOffice, pass it to constructors or methods that take an IPostOffice argument, exercise the System Under Test[66], and then inspect its state, as implied by listing 11.7.
Assert.Contains(expected, postOffice);
Listing 11.7: Assert that the expected reservation is in the postOffice collection. The postOffice variable is a SpyPostOffice object. (Restaurant/b85ab3e/Restaurant.RestApi.Tests/ReservationsTests.cs)
With that behaviour firmly in place, I started on a related feature. The system should also send an email when you delete a reservation. I added a new method to the IPostOffice interface, as shown in listing 11.8.
Since I’d added a new method to the IPostOffice interface, I also had to implement that method in the SpyPostOffice class. Since both the EmailReservationCreated and EmailReservationDeleted methods take a Reservation argument, I could just Add the reservation to the Test Spy[66] itself.
But as I started writing a unit test for the new behaviour, I realised that while I could write an assertion like the one in listing 11.7, I could only verify that the Test Spy[66] contained the expected reservation. I couldn’t verify how it got there; whether the spy added it via the EmailReservationCreated or the EmailReservationDeleted method.
public interface IPostOffice { Task EmailReservationCreated(Reservation reservation); Task EmailReservationDeleted(Reservation reservation); }
Listing 11.8: Second iteration of the IPostOffice interface. The highlighted line indicates the new method, compared to listing 11.5. (Restaurant/1811c8e/Restaurant.RestApi/IPostOffice.cs)
I had to improve the ‘sensitivity’ of SpyPostOffice in order to be able to do that.
I’d already embarked on a set of changes that touched the production code. The IPostOffice interface is part of the production code, and there was also a production implementation of it (called SmtpPostOffice). I was in the process of making changes to the production code, and all of a sudden, I realised that I had to refactor the test code.
This is one of the many reasons that Git is such a game changer, even for individual development. It’s an example of the manoeuvrability that it offers. I simply stashed4 my changes and independently edited the SpyPostOffice class. You can see the result in listing 11.9.
4 git stash saves your dirty files in a ‘hidden’ commit and resets the repository to HEAD. Once you’re done with whatever else you wanted to do, you can retrieve that commit with git stash pop.
I introduced a nested Observation class to keep track of both the type of interaction and the reservation itself. I also changed the base class to a collection of observations.
This broke some of my tests, because an assertion like the one shown in listing 11.7 would look for a Reservation object in a collection of Observation objects. That didn’t type-check, so I had to massage the test in place, too.
I managed to do that without touching the production code. When I was done, all tests still passed. That’s no guarantee that I didn’t make a mistake while refactoring, but at least it eliminates a category of errors5.
5 That the changes to the tests inadvertently strengthened some preconditions.
Once I had refactored the test code, I popped the stashed changed and continued where I’d left off. Listing 11.10 shows the updated SpyPostOffice.
While these changes also involved editing the test code, they were safer because they were only additions. I didn’t have to refactor existing test code.
internal class SpyPostOffice : Collection<SpyPostOffice.Observation>, IPostOffice { public Task EmailReservationCreated(Reservation reservation) { Add(new Observation(Event.Created, reservation)); return Task.CompletedTask; } internal enum Event { Created = 0 }
Listing 11.9: Refactored SpyPostOffice (fragment). The Observation class is a nested class, which isn’t shown. It just holds an Event and a Reservation. (Restaurant/b587eef/Restaurant.RestApi.Tests/SpyPostOffice.cs)
11.2 See tests fail
If you must edit both tests and production code at the same time, consider verifying the tests by making them fail deliberately, if only temporarily.
It’s surprisingly easy to write tautological assertions[104]. These are assertions that never fail, even if the production code is faulty.
Don’t trust a test that you haven’t seen fail. If you changed a test, you can temporarily change the System Under Test to make the test fail. Perhaps comment out some production code, or return a hard-coded value. Then run the test you edited and verify that with the temporary sabotage in place, the test fails.
Once more, Git offers manoeuvrability. If you have to change both tests and production code at the same time, you can stage your changes and only then sabotage the System Under Test. Once you’ve seen the test fail, you can discard the changes in your working directory and commit the staged changed.
internal class SpyPostOffice : Collection<SpyPostOffice.Observation>, IPostOffice { public Task EmailReservationCreated(Reservation reservation) { Add(new Observation(Event.Created, reservation)); return Task.CompletedTask; } public Task EmailReservationDeleted(Reservation reservation) { Add(new Observation(Event.Deleted, reservation)); return Task.CompletedTask; } internal enum Event { Created = 0, Deleted = 1 }
Listing 11.10: Updated SpyPostOffice. It now implements the version of IPostOffice shown in listing 11.8. (Restaurant/1811c8e/Restaurant.RestApi.Tests/SpyPostOffice.cs)
11.3 Conclusion
Be careful editing unit test code; there’s no safety net.
Some changes are relatively safe. Adding new tests, new assertions, or new test cases tend to be safe. Applying refactorings built into your IDE also tends to be safe.
Other changes to test code are less safe, but may still be desirable. Test code is code that you have to maintain. It’s as important that it fits in your brain as that the production code does. Sometimes, then, you should refactor test code to improve its internal structure.
You may, for example, want to address duplication by extracting helper methods. When you do that, make sure that you edit only the test code, and that you don’t touch the production code. Check such changes to test code into Git as separate commits. This doesn’t guarantee that you didn’t make mistakes in the test code, but it improves your chances.