
1
Introduction to Cognitive Computing
Vamsidhar Enireddy*, Sagar Imambi† and C. Karthikeyan‡
Department of Computer Science and Engineering, Koneru Lakshmaiah Education Foundation, Guntur, India
Abstract
Cognitive computing is an interdisciplinary subject that brings under its umbrella several techniques such as Machine learning, big data analytics, artificial intelligence, analytics, natural language processing, and probability and statistics to gather information and understand it using different senses and learning from their experience. Cognitive computing helps humans in taking the right decisions at a right time helping the people to grow in their respective fields. In this chapter, we are going to discuss cognitive computing and the elements involved in it. Further, we will learn about the components and hypothesis generation and scoring of it.
Keywords: Artificial intelligence, cognition, cognitive computing, corpus, intuitive thinking, hypothesis generation, machine learning
1.1 Introduction: Definition of Cognition, Cognitive Computing
The term Cognition is defined as “The procedure or the method of acquiring information and understanding through experience, thought and the senses” [1]. It envelops numerous parts of procedures and intellectual functions, for example, development of information, thinking, reasoning, attention, decision making, evaluating the decisions, problem-solving, computing techniques, judging and assessing, critical thinking, conception, and creation of language. This process produces new information using existing information. A large number of fields especially psychology, neuroscience, biology, philosophy, psychiatry, linguistics, logic, education, anesthesia, and computer science view and analyze the cognitive processes with a diverse perspective contained by dissimilar contexts [2].
The word cognition dates to the 15th century, derived from a Latin word where it meant “thinking and awareness” [3]. The term comes from cognitio which means “examination, learning or knowledge”, derived from the verb cognosco, a compound of con (‘with’), and gnōscō (‘know’). The latter half, gnōscō, itself is a cognate of a Greek verb, gi(g)nόsko (γι(γ)νώσκω, ‘I know,’ or ‘perceive’) [4, 5].
Aristotle is probably the first person who has shown interest to study the working of the mind and its effect on his experience. Memory, mental imagery, observation, and awareness are the major areas of cognition, hence Aristotle also showed keen interest in their study. He set incredible significance on guaranteeing that his examinations depended on exact proof, that is, logical data that is assembled through perception and principled experimentation [6]. Two centuries later, the basis for current ideas of comprehension was laid during the Enlightenment by scholars, like, John Locke and Dugald Stewart who tried to build up a model of the psyche in which thoughts were obtained, recalled, and controlled [7].
As Derived from the Stanford Encyclopedia of Philosophy the Cognitive science can be defined as “Cognitive science is the interdisciplinary study of mind and intelligence, embracing philosophy, psychology, artificial intelligence, neuroscience, linguistics, and anthropology.”
The approach for cognitive computing depends on understanding the way how the human brain can process the information. The main theme or idea of a cognitive system is that it must able to serve as an associate for the human’s rather than simply imitating the capabilities of the human brain.
1.2 Defining and Understanding Cognitive Computing
Cognitive computing can be defined as hardware and software to learn so that they need not be reprogrammed and automate the cognitive tasks [11]. This technology brings under its cover many different technologies such as Artificial Intelligence, Machine Learning, Advanced Analytics, Natural Language Processing, Big Data Analytics, and Distributed Computing. The impact of this technology can be seen in health care, business, decision making, private lives, and many more.
Two disciplines are brought together with cognitive computing
- Cognitive Science
- Computer Science.
The term cognitive science refers to the science of mind and the other is a computational approach where the theory is put into practice.
The ultimate objective of cognitive computing is that it must able to replicate the human thinking ability in a computer model. Using technologies like machine learning, natural language processing, advanced analytics, data mining, and statistics had made these things possible where the working of the human brain can be mimicked [8].
From a long back, we can construct the computers which perform the calculations at a high speed, also able to develop supercomputers which can do calculations in a fraction of second, but they are not able to perform the tasks as humans do like the reasoning, understanding and recognizing the objects and images.
Cognitive researchers discover the mental capability of humans through an examination of the aspects like memory, emotion, reasoning, perception, and language [12]. Figure 1.1 shows the Human centered cognitive cycle. On analysis, the human being’s cognitive process can be divided into two stages. One is the humans use their sensory organs to perceive the information about their surrounding environment and become aware of it, in this manner humans gather the input from the outside environment. The second stage is that this information is carried by the nerves to the brain for processing and the process of storing, analyzing, and learning takes place [13].
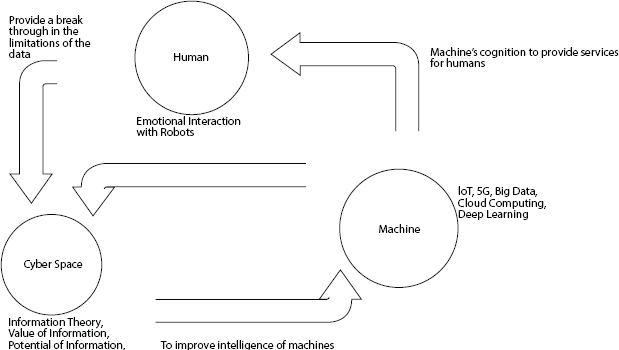
Figure 1.1 Human-centered cognitive cycle.
Many researchers and scientists from many years had tried to develop the systems that can mimic the human thoughts and process, but it is relatively complex to transform the intricacy of thinking of humans and actions into systems. Human beings have a lot of influence on them such as perception, culture, sentiment, lifestyle, and implicit beliefs about their surrounding environment. Cognition is the basic framework that not only leverages the way we imagine but also the way we behave and the way we make decisions. To understand this let us consider some examples that we see around us. Why there are different recommendations and approaches between the treatments for the same disease with different doctors? Why do people with the same background born and brought up in the same family have different views and opinions about the world?
Dr. Daniel Kahneman is a Nobel Prize winner in economic sciences in 2002 had paved a way for the cognitive computing approach. He had made a lot of research in the area of psychology of judgment and decision making [11]. The approach is divided into two systems: 1. Intuitive thinking and 2. Controlled andrulecentric thinking.
System 1: Intuitive thinking
In this system, reasoning occurs in the human brain naturally. The conclusions are drawn using our instincts. In System 1 human thinking begins the moment they are born. Humans learn to notice and recognize the things and their relationship by themselves. To illustrate this we consider some examples for better understanding. The children correlate their parent’s voices with safety. People correlate strident sound with danger. At the same time, we can see that children with a harsh mother are not going to have a similar experience with the voice of the mother as the child with a good mother. Humans learn more things over time and continue assimilating their thoughts into their mode of working in the world. The chess grandmaster can play the game with their mind anticipating their opponent’s move and also they can play the game entirely in their mind without any need to touch the chessboard. The surrounding environment plays a major role in a person’s behavior, it affects their emotions and attitudes. A person brought up in treacherous surroundings, have a different attitude about the people compared to a person brought up in healthy surroundings. In System1 using the perception, we gather the data about the world and connect the events. In the cognitive computing point of view, this System 1 had taught the way how we gather information from the surroundings helps us to conclude. Figure 1.2 shows collaboration between the Intuitive thinking and analysis.
System 2: Controlled and rulecentric thinking.
In this process, the reasoning is based on an additional premeditated process. This conclusion is made by taking into consideration both observations and test assumptions, rather than simply what is understood. In this type of system the thinking process to get a postulation, it uses a simulation model and observes the results of that particular statement. To do this a lot of data is required and a model is built to test the perceptions made by System 1. Consider the treatment of cancer patients in which a large number of ways and drugs are available to treat the patients. The cancer drugs not only kill the cancer cells but also kill the healthy cells, making the patient feel the side effects of it. When a drug company comes with any novel drug it tests on animals, records its results, and then it is tested on humans. After a long verification of the data checking the side effects of the drug on the other parts of the body, the government permits to release the drug into the market where it takes a long time from research to availability of that drug. In System 1 when a drug can destroy the cancer cells it determines it can be put onto the market. It is completely biased. System 2 will not conclude as of System 1, it collects the data from various sources, refines it, and then it comes to a conclusion. Although this process is slow it is important to study all the things before jumping to a conclusion. One of the most complex problems is predicting the outcomes as many factors can affect the outcomes. So, it is very important to merge the spontaneous thinking with the computational models.

Figure 1.2 Intuitive thinking and analysis [11].
The cognitive system is based on three important principles
- Learn
- Model
- Hypothesis generation.
- Learn: The cognitive framework must be able to learn. The framework use information to make inductions about an area, a theme, an individual, or an issue dependent on preparing and perceptions from all assortments, volumes, and speed of information.
- Model: To learn, the framework it requires to make a model or portrayal of a domain which incorporates interior and conceivably exterior information and presumptions that direct what realizing calculations are utilized. Understanding the setting of how the information fits into the model is critical to a cognitive framework.
- Generate hypotheses: A cognitive framework expects that there will be several solutions or answers to a question. The most fitting answer depends on the information itself. In this way, an intellectual framework is probabilistic. A theory is an up-and-comer clarification for a portion of the information previously comprehended. A cognitive framework utilizes the information to prepare, test, or score speculation.
1.3 Cognitive Computing Evolution and Importance
The basis for cognitive computing is artificial intelligence. Artificial Intelligence has roots back at least 300 years ago, but in the last 50 years, there is much research and improvement in this field which has impacted the development of cognitive computing. The combined work of the mathematicians and scientists in converting the working of a brain into a model such that it mimics the working of the brain, but it has taken a long time to make them work and think like a human brain. During WW-II England has achieved victory due to the decoding of the messages of the opponent and this is achieved by the great work of Alan Turing who worked on the cryptography. Later Turing worked on machine learning and published a paper “Computing Machinery and Intelligence” in which he put up a question “Can machines think”, he greatly believed that machines can think and also throw away the argument that the machines cannot think as they do not have any emotions like the human beings. In the later years, he came up with the famous Turing test to prove that machines can think as human beings do. From ten many scientists had contributed to the development of artificial intelligence and can be termed as modern artificial intelligence. The cognitive computing is still evolving. Figure 1.3 shows how the evolution of Cognitive Computing had taken place over the years.
The main focus of cognitive computing is on processing methods, here the data that is to be processed need not be big. The most important thing in understanding the working of the brain is how a brain can decode the image and it is well known that 20% of the brain working function is allocated for the vision and the working of the brain in the image processing is highly efficient. The brain can do things with limited data and even the limited memory is not affecting the cognition of image information. Cognitive science helps to develop the algorithms required for cognitive computing, making the machines to function like a human brain to some degree of extending [14]. The only way to build up the computers to compute as a human brain is to understand and cognize the things and surroundings in the perspective of how a human brain thinks. The cognitive computing is very much important and critical to building up the cognition of a machine and thereby making it to understand the requirements of humans [15]. There is a necessity to make the machines think like humans and they must be able to make decisions and have some intelligence as of humans, of course, a lot of improvement is to be made in this field. With the help of the present techniques, it is possible to make machines think like humans, as they involve reasoning, understanding complicated emotions. Cognitive computing had made tremendous progress and also exceeded the conventional machine learning. Internet of Things is one technology that had made very good progress and helping the people in many ways and now IoT is embedded with cognitive computing developing a smarter Internet of Things systems assisting the humans in many ways like providing vital suggestions and helping in the decision making [16].
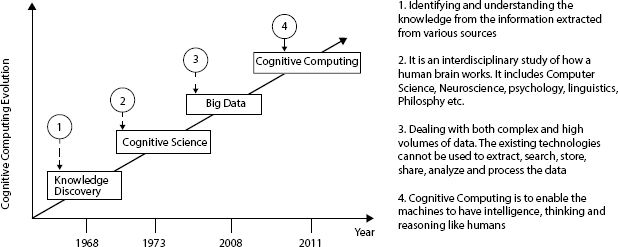
Figure 1.3 Showing the evolution of Cognitive Computing [13].
In today’s world with a lot of sensors around a lot of data is being generated all the time in many forms. The evolution of cognitive computing is to make a sense in this multifaceted world with this large volume of data. The older technologies have been developed to make sense with the structured data and machines, software is also developed to deal with such type of data and gathering information from the structured data. The growth of social site and apps have impacted the growth in the unstructured and semi-structured data and these older technologies are no more a way to handle these types of data and the cognitive computing helps in gathering the information from all types of data Unstructured, Semi-structured, and Structured data. Without the handling of these different types of data, a lot of information can be missed and the cognitive computing is going to help the humans to collaborate with the machines so that a maximum gain can be extracted from them. In the past also we have seen the technology had transformed the industries and also the human way of living from the last decades. Transactional processing had started in the 1950s had brought a lot of transformation in government operations and also in business transactions, giving a lot of efficient ways to deal with the operations. During that time the data was limited and major data is structured data and tools are developed to handle this type of data and many mining tools are developed to extract the information from that data. A large amount of data cannot be handled by the traditional tools and methods, so we need a mixture of traditional methods with traditional technical models with the innovations to solve the niggling problems.
1.4 Difference Between Cognitive Computing and Artificial Intelligence
Although it was stated that the foundation for cognitive computing is artificial intelligence there is a lot of difference between the two.
The basic use of artificial intelligence is to solve the problem by implementing the best algorithm, but cognitive computing is entirely different from artificial intelligence as cognitive computing adds the reasoning, intelligence to the machine and also analyzes different factors to solve the problem.
Artificial Intelligence mimics the human intelligence in machines. This process comprises making the machines learn constantly with the changing data, making sense of the information, and taking decisions including the self-corrections whenever needed.
Human beings use the senses to gather information about the surrounding environment and process that information using the brain to know about the environment. In this context, we can define that artificial intelligence can also include replicating the human senses such as hearing, smelling, touching, seeing, and tasting. It also includes simulating the learning process and this is made possible in the machines using machine learning and deep learning. Last but not least is human responses achieved through the robotics [18].
The cognitive computing is used to understand and simulate the reasoning and human behavior. Cognitive Computing assists humans to take better decisions in their respective fields. Their applications are fraud detection, face and emotion detection, sentiment analysis, risk analysis, and speech recognition [17].
The main focus of cognitive computing includes
- To solve complex problems by mimicking human behavior and reasoning.
- Trying to replicate the humans in solving the problems
- Assists the human in taking decisions and do not replace humans at all.
Artificial Intelligence focus includes
- To solve complex problems it augments human thinking, it tries to provide accurate results.
- It tries to find new methods to solve problems which can potentially be superior to humans
- The main intent of AI is to solve the problem utilizing the best algorithm and not simply mimicking the human brain.
- The human role is minimized in taking the decisions and artificial intelligence takes over the responsibility.
The main advantage that needs to be highlighted is that Cognitive Computing does not pose any threat to humans. Cognitive computing helps in assisting human beings in taking better decisions in their tasks, endowing human beings with high precision in analyzing the things, same time having everything under their control. In the case of the health care system, cognitive computing assists the specialists in the diagnosis of the disease using the data and advanced analytics, by which it helps to take quality decisions by the doctors [10]. In Figure 1.4 we can see the growth of Cognitive Computing in various continents. In Figure 1.5 we can see the growth of revenue in the various locations of the world.

Figure 1.4 Global cognitive market [17].

Figure 1.5 Global cognitive market revenue, by geography [17].
1.5 The Elements of a Cognitive System
Several different elements constitute the cognitive system, starting from hardware and operational prototypes to modern machine learning algorithms and applications. Figure 1.6 gives a general design for building a cognitive system.
1.5.1 Infrastructure and Deployment Modalities
The system needs to meet the demands of the industries as they continuously grow and the infrastructure should be flexible to carry on the applications required for the industry. A large amount of data is required to be processed and managed; this data consists of both public and private data. Cloud infrastructure services are required and constant support should be given, providing a highly parallel and distributed computing environment.

Figure 1.6 The general design of a cognitive system [11].
1.5.2 Data Access, Metadata, and Management Services
Data is the most important point where cognitive computing revolves around, so the data collection, accession, and maintaining it must have a very important role. A lot of essential services are required for adding the data and also using it. To ingest the data utmost care should be taken to check the source from which the data is originated. As a result, there is a requirement that data should be classified based on the origin of data, as it is required to check the data source was trusted or not. The most important thing to learn here is that the data is not static as it is required to update the data from the sources and upload it into the systems. The corpus is the one that holds the data and it relies on various internal and external sources. As a large data is available, a check should be done on data sources, data should be verified, cleaned, and check for accuracy so that it can be added into the corpus. This is a mammoth task as it requires a lot of management services to prepare the data.
1.5.3 The Corpus, Taxonomies, and Data Catalogs
Firmly connected with the information access and the other executive layer are the corpus and data analytics administrations. A corpus is the information base of ingested information and is utilized to oversee classified information. The information required to build up the area for the framework is incorporated in the corpus. Different types of information are ingested into the framework. In numerous cognitive frameworks, this information will principally be text-based (records, patient data, course books, client reports, and such). Other cognitive frameworks incorporate numerous types of unstructured and semi-structured information, (for example, recordings, pictures, sensors, and sounds). What’s more, the corpus may incorporate ontologies that characterize explicit elements and their connections. Ontologies are regularly evolved by industry gatherings to arrange industry-specific components, for example, standard synthetic mixes, machine parts, or clinical maladies and medicines. In a cognitive framework, it is frequently important to utilize a subset of an industry-based ontology to incorporate just the information that relates to the focal point of the cognitive framework. A taxonomy works inseparably with ontologies. It also provides a background contained by the ontology.
1.5.4 Data Analytics Services
These are the methods used to increase the comprehension of the information ingested and managed inside the corpus. Ordinarily, clients can take a bit of leeway of structured, unstructured, and semi-structured information that has been ingested and start to utilize modern calculations to anticipate results, find designs, or decide the next best activities. These administrations don’t live in separation. They constantly get to new information from the information get to layer and pull information from the corpus. Various propelled calculations are applied to build up the model for the cognitive framework.
1.5.5 Constant Machine Learning
Machine learning is a strategy that gives the ability to the information to learn without being unequivocally modified. Cognitive frameworks are dynamic. These models are ceaselessly refreshed dependent on new information, examination, and associations. This procedure has two key components: Hypothesis generation and Hypothesis evaluation.
A distinctive cognitive framework utilizes machine learning calculations to construct a framework for responding to questions or conveying insight. The structure requires helping the following characteristics:
- Access, administer, and evaluate information in the setting.
- Engender and score different hypotheses dependent on the framework’s aggregated information. The framework may produce various potential arrangements to each difficult it illuminates and convey answers and bits of knowledge with related certainty levels.
- The framework persistently refreshes the model dependent on client associations and new information. A cognitive framework gets more astute after some time in a robotized way.
1.5.6 Components of a Cognitive System
The framework has an interior store of information (the corpus) and also communicates with the exterior surroundings to catch extra information, to possibly refresh external frameworks. Cognitive frameworks may utilize NLP to get text, yet additionally need another handling, profound learning capacities, and instruments to apprehend images, voice, recordings, and position. These handling capacities give a path to the cognitive framework to comprehend information in setting and understand a specific domain area. The cognitive framework creates hypotheses and furnishes elective answers or bits of knowledge with related certainty levels. Also, a cognitive framework should be able to do deep learning that is explicit to branches of knowledge and businesses. The existing pattern of a cognitive framework is an iterative procedure. The iterative procedure requires the amalgamation of best practices of the humans and also training the system with the available data.
1.5.7 Building the Corpus
Corpus can be defined as a machine-readable portrayal of the total record of a specific area or theme. Specialists in an assortment of fields utilize a corpus or corpora for undertakings, for example, semantic investigation to contemplate composing styles or even to decide the credibility of a specific work.
The information that is to be added into the corpus is of different types of Structured, Unstructured, and Semi-structured data. It is here what makes the difference with the normal database. The structured data is the data which have a structured format like rows and column format. The semi-structured data is like the raw data which includes XML, Jason, etc. The unstructured data includes the images, videos, log, etc. All these types of data are included in the corpus. Another problem we face is that the data needs to be updated from time to time. All the information that is to be added into the corpus must be verified carefully before ingesting into it.
In this application, the corpus symbolizes the body of information the framework can use to address questions, find new examples or connections, and convey new bits of knowledge. Before the framework is propelled, in any case, a base corpus must be made and the information ingested. The substance of this base corpus obliges the sorts of issues that can be tackled, and the association of information inside the corpus significantly affects the proficiency of the framework. In this manner, the domain area for the cognitive framework has to be chosen and then the necessary information sources can be collected for building the corpus. A large of issues will arise in building the corpus.
What kinds of issues would you like to resolve? If the corpus is as well barely characterized, you may pass up new and unforeseen insights.
If information is cut from outside resources before ingesting it into a corpus, they will not be utilized in the scoring of hypotheses, which is the foundation of machine learning.
Corpus needs to incorporate the correct blend of applicable information assets that can empower the cognitive framework to convey exact reactions in normal time. When building up a cognitive framework, it’s a smart thought to decide in favor of social occasion more information or information because no one can tell when the disclosure of an unforeseen affiliation will lead to significant new information.
Accorded the significance set on obtaining the correct blend of information sources, several inquiries must be tended to right off the bat in the planning stage for this framework:
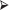 Which interior and exterior information sources are required for the particular domain regions and issues to be unraveled? Will exterior information sources be ingested in entire or to some extent?
Which interior and exterior information sources are required for the particular domain regions and issues to be unraveled? Will exterior information sources be ingested in entire or to some extent?- How would you be able to streamline the association of information for effective exploration and examination?
- How would you be able to coordinate information over various corpora?
- How would you be able to guarantee that the corpus is extended to fill in information gaps in your base corpus? How might you figure out which information sources need to be refreshed and at what recurrence?
The most critical point is that the decision of which sources to remember for the underlying corpus. Sources running from clinical diaries to Wikipedia may now be proficiently imported in groundwork for the dispatch of the cognitive framework. It is also important that the unstructured data has to be ingested from the recordings, pictures, voice, and sensors. These sources are ingested at the information get to layer (refer figure). Other information sources may likewise incorporate subject-specific organized databases, ontologies, scientific classifications, furthermore, indexes.
On the off chance that the cognitive computing application expects access to exceptionally organized information made by or put away in different frameworks, for example, open or exclusive databases, another structure thought is the amount of that information to import at first. It is additionally essential to decide if to refresh or invigorate the information intermittently, consistently, or in light of a solicitation from the framework when it perceives that more information can assist it with giving better answers.
During the plan period of an intellectual framework, a key thought is whether to build a taxonomy or ontology if none as of now exists for the specific domain. These types of structures not only streamline the activity of the framework, but they also make them more productive. In any case, if the designers are accountable for guaranteeing that an ontology and taxonomy is absolute and fully updated, it might be progressively viable to have the framework constantly assess connections between space components rather than have the originators incorporate that with a hard-coded structure. The performance of the hypothesis generation and scoring solely depend on the data structures that have been chosen in the framework. It is in this manner prudent to demonstrate or reenact regular outstanding tasks at hand during the planning stage before focusing on explicit structures. An information catalog, which incorporates metadata, for example, semantic data or pointers, might be utilized to deal with the basic information all the more productively. The list is, as a deliberation, progressively smaller what’s more, for the most part, quicker to control than a lot bigger database it speaks to. In the models and outlines, when alluding to corpora, it ought to be noted that these can be coordinated into a solitary corpus while doing so will help disentangle the rationale of the framework or improves execution. Much like a framework can be characterized as an assortment of littler incorporated frameworks, totaling information from an assortment of corpora brings about a solitary new corpus. Looking after isolated corpora is ordinarily accomplished for execution reasons, much like normalizing tables in a database to encourage inquiries, instead of endeavoring to join tables into a solitary, progressively complex structure.
1.5.8 Corpus Administration Governing and Protection Factors
Information sources and the development of that information are progressively turning out to be intensely managed, especially for by and by recognizable data. Some broad issues of information approach for assurance, security, and consistency are regular to all applications, however, cognitive computing applications be trained and infer new information or information that may likewise be dependent upon a developing collection of state, government, furthermore, global enactment.
At the point when the underlying corpus is created, almost certainly, a ton of information will be imported utilizing extract–transform–load (ETL) apparatuses. These devices may have risk management, security, and administrative highlights to enable the client to make preparations for information abuse or give direction when sources are known to contain sensitive information. The accessibility of the said instruments doesn’t clear the developers from a duty to guarantee that the information and metadata are consistent with material rules and guidelines. Ensured information might be ingested (for instance, individual identifiers) or produced (for instance, clinical findings) when the corpus is refreshed by the cognitive computing framework. Anticipating great corpus the executive sought to incorporate an arrangement to screen applicable strategies that sway information in the corpus. The information gets to layer instruments depicted in the following area must be joined by or implant consistence strategies and techniques to guarantee that imported and determining information and metadata stay consistent. That incorporates the thought of different sending modalities, for example, distributed computing, which may disperse information across geopolitical limits.
1.6 Ingesting Data Into Cognitive System
In contrast to numerous customary frameworks, the information that is added into the corpus is always dynamic, which means that the information should be always updated. There is a need to fabricate a base of information that sufficiently characterizes your domain space and also start filling this information base with information you anticipate to be significant. As you build up the model in the cognitive framework, you refine the corpus. Along these lines, you will consistently add to the information sources, change those information sources, and refine and purge those sources dependent on the model improvement and consistent learning.
1.6.1 Leveraging Interior and Exterior Data Sources
Most associations as of now oversee immense volumes of organized information from their value-based frameworks and business applications, and unstructured information, for example, the text contained in structures or notes and conceivably pictures from archives or then again corporate video sources. Albeit a few firms are composing applications to screen outer sources, for example, news and online life channels, numerous IT associations are not yet well prepared to use these sources and incorporate them with interior information sources. Most subjective registering frameworks will be created for areas that require continuous access to coordinated information from outside the association.
The person figures out how to recognize the correct sources to sustain his statements or his decision, he is normally based on social media, news channels, newspapers, and also on different web resources. Similarly, the cognitive application for the most part needs to get to an assortment of efficient sources to keep updated on the topic on which the cognitive domain operates. Likewise, similar to experts who must adjust the news or information from these exterior sources in opposition to their understanding, a cognitive framework must figure out how to gauge the external proof and create trust in the source and also on the content after some time. For instance, one can find an article related to medicine in a famous magazine, which can be a good source of information but if this article is contrary to an article published in a peer-reviewed journal, then the cognitive system must able to gauge the contradicting positions. The data that has to be ingested into the corpus must be verified carefully. In the above example, we may find that all the information sources that might be helpful ought to be thought of and conceivably ingested. On the other hand, this doesn’t imply that all sources will be of equivalent worth.
Consider the case of the healthcare in which we can see that an average person meets several doctors or specialists for any health issue. A large number of records will be generated each time he meets the doctors, so Electronic Medical Records (EMRs) help to place all the records in one place and also help to refer them whenever required and doctors can map easily on verifying these records. This helps the specialist to find the association between the blends of side effects and disorders or infections that would be missed if a specialist or scientist approached uniquely to the records from their training or establishment. This cannot be done manually by a person as he may miss or forget to carry all the records with him while meeting the doctor.
A communications organization using the cognitive approach wants to improve its performance to capture or improve their market share. The cognitive system can foresee ant failures in the machine by calculating the inner variables, for example, traffic and traditional patterns; they also calculate the external components, for example, extreme climate threats that are probably going to cause over-burdens and also substantial damage.
1.6.2 Data Access and Feature Extraction
In the diagram data access level has portrayed the principle interface connecting the cognitive system and the external world. Any information that is needed has to be imported from outer sources has to go through the procedures inside this layer. All types of structured, semi-structured, and unstructured data are required for the cognitive application is collected from different resources, and this information is arranged for processing using the machine learning algorithms. To put an analogy to the human way of learning is that it represents the senses. There are two tasks that the feature extraction layer needs to complete. One is identifying the significant information and the second is to extract the information so that it can be processed by the machine learning algorithms. Consider for instance with image processing application where the image representation is in pixels and it does not completely represent an object in the image. We need to represent the things in a meaningful manner as in the case of the medical images, where a dog or dog scan is not useful to the veterinary doctor until the essential structure is captured, identified, and represented. Using Natural Language Processing the meaning in the unstructured text can be identified. The corpus is dynamic hence the data is added or removed from it constantly by using the hypotheses score.
1.7 Analytics Services
The term Analytics alludes to an assortment of procedures used to discover and provide details regarding fundamental qualities or associations inside a dataset. These techniques are very helpful in guiding us by providing knowledge about data so that a good decision can be taken based on the insights. Algorithms such as regression analysis are most widely used to find the solutions. In cognitive systems, a wide scope of sophisticated analytics is accessible for descriptive, predictive, and prescriptive tasks in many commercial library packages in the statistical software. In further to support the cognitive systems tasks a large number of supporting tools are available. In the present time analytics role in the market has changed a lot. Table 1.1 gives us a view of the analytics role that many organizations are experiencing. These analytics helps to learn and understand things from the past and thereby predict future outcomes. Most of the data collected from the past are utilized by business analytics and data scientists to come up with a good prediction. The main important thing in these days is that the technology is growing and it is meeting all levels of the people in the whole world and world has itself become a small global village due to the information technology, so the organizations should learn that they are many dynamic changes in the behavior and taste of the people. Using the advanced analytics it is necessary to build better predictive models so that for any small change in the trade environment these models can react to them.
Figure 1.7 gives a brief look at how analytics and artificial intelligence technologies are converged. In the competitive world, operational changes and planning should be done at a quick rate to survive in the market. A decision should be taken fast and it can happen when the tools used for the prediction can give us a result in no time otherwise it may become a disaster for the company if it takes decisions a late as the competitor can overtake the market within no time. Many big and reliable companies have lost the market for taking late decisions it has happened in the past and can happen in the future also. For instance, consider a client relationship application in which the customer calls the executive for some reason, and in this interaction, with the customer, the executive must clear the doubts of the client and satisfy him by deciding in a short time. This helps the organization to retain the customer and helps to add more clients to them when the service provided to them is done in no time. The problem is that there is a large amount of data available and to process it also is difficult. As the data contains structured, semi-structured, and unstructured a large number of analytical models are need to be incorporated so that the prediction can be improved.
Table 1.1 Different types of analytics and their examples [11].
| S. no. | Analytics type | Description | Examples |
|---|---|---|---|
| 1 | Descriptive Analytics | Realize what transpires when using analytic procedures on past and present data. | Which item styles are selling better this quarter as analyzed to last quarter? Which districts are displaying the most elevated/least development? What components are affecting development in various areas? |
| 2 | Predictive Analytics | Comprehend what may happen when utilizing statistical predictive modeling capabilities, that includes both data mining and AI. Predictive models use past and current data to forecast forthcoming outcomes. Models search for patterns, clusters of behavior, and events. Models recognize outliers. | What are the forecasts for next quarter’s sales by items and territory? How does this affect unprocessed acquisitions, human resources and inventory Management? |
| 3 | Prescriptive Analytics | Use to create a framework for deciding what to do or not do in the future. The “prescient” component ought to be tended to in prescriptive examination to help recognize the overall outcomes of your activities. Utilize an iterative procedure so that your model can gain from the relationship among activities and results | What is the best blend of items for every locale? In What Way the consumers in each zone respond to marketing promotions and deals? What type of the offer ought to be made to each client to fabricate dependability and increment deals? |
| 4 | Machine Learning and Cognitive Computing | A coordinated effort among people and machines to take care of complicated issues. Incorporate and evaluate different sources of data to anticipate results. Need relies upon the issues you are attempting to understand. Improve adequacy of critical thinking and decrease blunders in predicting outcomes. |
In What Manner the city environment is secure? Are there any cautions from the immense the measure of data spilling from checking gadgets (video, sound, and detecting gadgets for smoke or harmful gases)? Which blend of drugs will furnish the best result for a particular cancer patient based on precise attributes of the tumor and genetic sequencing? |
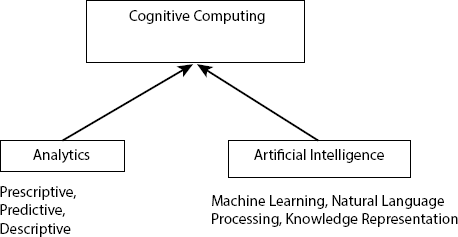
Figure 1.7 Figure showing the convergence of technologies.
1.8 Machine Learning
Machine learning is the logical control that rose out of the general field of Artificial Intelligence. It is an interdisciplinary field where insights and information speculations are applied to discover the connections among the information and to build up programs by adapting consequently without human intercession. This procedure looks like the human learning process. Analysts are as yet attempting to make machines smart and act like people. This learning procedure begins with accessible information. Information assumes an essential job in the machine learning process. ML is also being utilized for information examination, such as identifying regularities in the information by fittingly managing incomplete information and the transformation of constant information.
Machine learning is multidisciplinary and is a subset of AI. However, it additionally consolidates the methods from statistics, control hypothesis, Cognitive Science as shown in Figure 1.8. The subsequent explanation is the exponential development of both accessible information and computer processing power. The order of AI additionally joins other information investigation disciplines like data mining, probability and statistics, computational complexity theory, Neurobiology, philosophy, and Information theory.

Figure 1.8 Machine learning.
Cognitive computing models use machine learning techniques dependent on inferential insights to identify or find designs that direct their behavioral patterns. Picking the fundamental learning way to deal with model recognition versus disclosure of examples ought to be founded on the available information and nature of the issues to be unraveled. AI regularly utilizes inferential insights (the reason for prescient, instead of precise examination) methods.
One of the more important uses of AI is to mechanize the procurement of information bases utilized by supposed master frameworks, which plans to imitate the dynamic procedure of human aptitude in a field. Be that as it may, the extent of its application has been developing.
The significant methodologies incorporate utilizing neural systems, case-based learning, hereditary calculations, rule enlistment, and analytical learning. While in the past they were applied autonomously, as of late these ideal models or models are being utilized in a crossbreed design, shutting the limits among them and empowering the improvement of increasingly compelling models. The blend of analytical techniques can guarantee compelling and repeatable and reliable outcomes, a necessary part for practical use in standard business and industry arrangements.
1.9 Machine Learning Process
1.9.1 Data Collection
- The quantity and quality of data decide how our model performs. The gathered data is represented in a format which is further used in training
- We can also get preprocessed data from Kaggle, UCI, or from any other public datasets.
1.9.2 Data Preparation
Data preparation of machine learning process includes
- Arranging information and set it up for preparing.
- The cleaning process includes removing duplicate copies, handling mistakes, managing missing qualities, standardization, information type changes, and so on.
- Randomizing information, which eradicates the impacts of the specific samples wherein we gathered or potentially, in any case, arranged our information.
- Transforming information to identify pertinent connections between factors or class labels and characteristics (predisposition alert!), or perform other exploratory examination.
- Splitting data set into training and test data sets for learning and validating process.
1.9.3 Choosing a Model
Choosing the model is crucial in the machine learning process as the different algorithms are suitable for different tasks. Choosing an appropriate algorithm is a very important task.
1.9.4 Training the Model
- The goal of training is to learn from data and use it to predict unseen data. For example in Linear, the regression algorithm would need to learn values for m (or W) and b (x is input, y is output)
- In each iteration of the process, the model trains and improves its efficiency.
1.9.5 Evaluate the Model
Model evaluation is done by a metric or combination of metrics and measures the performance of the model. The performance of the model is tested against previously unknown data. This unknown data may be from the real world and used to measure the performance and helps in tuning the model. Generally, the train and the split ratio is 80/20 or 70/30 depending on the data availability.
1.9.6 Parameter Tuning
This progression alludes to hyperparameter tuning, which is a “fine art” instead of a science. Tune the model boundaries for improved execution. Straightforward model hyperparameters may include the number of preparing steps, learning rate, no of epochs, and so forth.
1.9.7 Make Predictions
Utilizing further (test set) information which has, until this point, been retained from the model (and for which class names are known), are utilized to test the model; a superior estimate of how the model will act in reality.
1.10 Machine Learning Techniques
Machine learning comes in many different zests, depending on the algorithm and its objectives. The learning techniques are broadly classified into 3 types, Supervised learning, unsupervised, and reinforcement learning. Machine learning can be applied by specific learning strategies, such as:
1.10.1 Supervised Learning
It is a machine learning task of inferring function from labeled data. The model relies on pre-labeled data that contains the correct label for each input as shown in Figure 1.9. A supervised algorithm analyses the training example and produce an inferred function that can be used for mapping new examples. It is like learning with a teacher. The training data set is considered as a teacher. The teacher gives good examples for the student to memorize, and guide the student to derive general rules from these specific examples.
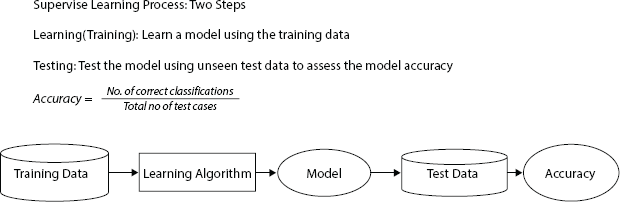
Figure 1.9 Supervised model.
In the Supervised learning technique, an algorithm learns from historical data and the related target labels which may consist of numeric values or string, as classes. And the trained model predicts the correct label when given with new examples.
The supervised approach is generally similar to human learning under the supervision of a teacher. There is a need to distinguish between regression problems, whose target is a numeric value, and classification problems, whose target is a qualitative variable, such as a class or a tag. A regression task determines the average prices of houses in the Boston area, and a classification task distinguishes between kinds of iris flowers based on their sepal and petal measures. A supervised strategy maps the data inputs and models them against desired outputs.
The supervised learning technique can be further divided into regression and classification problems.
- Classification: In the classification problem, the output variable is a category, such as “red” or “blue” or “disease” and “no disease”. Classification emails into ‘spam’ or ‘not spam’ is another example.
- Regression: In the regression problem, the output variable is a real value, such as “price” or “weight” or “sales”.
Some famous examples of supervised machine learning algorithms are:
SVM, Bayes, KNN, Random forest, Neural networks, Linear regression, Decision tree, etc.
1.10.2 Unsupervised Learning
An unsupervised strategy used to map the inputs and model them to find new trends. Derivative ones that combine these for a semi-supervised approach and others are also be used. Unsupervised learning is another form of machine learning algorithm which was applied to extract inferences from the large number of datasets consisting of input data without labeled responses.
Unsupervised learning happens when a calculation gains from plain models with no related reaction, leaving for the calculation to decide the information designs all alone. This sort of calculation will, in general, rebuild the information into something different, such as new highlights that may speak to a class or another arrangement of uncorrelated qualities. They are accommodating in giving people bits of knowledge into the significance of information and new valuable contributions to administered machine learning techniques.
The most widely recognized unsupervised learning technique is cluster analysis, which is utilized for exploratory information investigation to discover hidden examples or gathering in the information. It is like learning without a teacher. The machine learns through observation and finds structures in data.
Clustering and Association rule the two techniques that come under unsupervised learning.
Hierarchical clustering, K mean clustering, Markov models.
As a part of learning, it takes after the strategies people use to make sense of those specific articles or occasions are from a similar class, for example, by watching the level of similitude between objects. Some suggestion frameworks that find on the web through promoting robotization depend on this sort of learning.
This opens the entryway onto a huge number of utilizations for which AI can be utilized, in numerous territories, to depict, endorse, and find what is happening inside enormous volumes of assorted information.
1.10.3 Reinforcement Learning
Reinforcement Learning involves the mechanism of reward and punishment for the process of learning. In this type of learning, the objective is to maximize the reward and minimize the punishment. In Reinforcement Learning Errors help you learn because they have a penalty added (cost, loss of time, regret, pain, and so on).
Ex. when computers learn to play video games by themselves.

Figure 1.10 Reinforcement learning.
Reinforcement learning is connected to the applications for which the algorithm must make decisions and where the decisions held consequences. In the human world, it is similar to learning by trial and error. In cognitive computing, reinforcement learning is mostly used where numerous variables in the model are difficult to represent and the model has to do a sequence of tasks. For example Self-driving cars.
In reinforcement learning, we have an agent that acts in the environment as shown in Figure 1.10. The agent can take action and this action can impact the environment. In a particular stage, the agent takes an action and the environment goes to a new state and gives some reward to the agent, that reward may be positive can be a negative reward or penalty or can be nothing at that particular time step. But the agent is continually acting in this world.
The model finds a relation between the reward and the sequence of tasks, which lead to getting a reward.
1.10.4 The Significant Challenges in Machine Learning
- Identifying good hypothesis space
- Optimization of accuracy on unknown data
- Insufficient Training Data.
It takes a great deal of information for most Machine Learning calculations to work appropriately. For underlying issues, regularly need a vast number of models, and for complex issues, for example, picture or discourse recognition you may require a great many models.
- Representation of Training Data
It is critical, to sum up, the preparation of information on the new cases. By utilizing a non-representative preparing set, we prepared a model that is probably not going to make precise forecasts, particularly for poor and rich nations. It is essential to utilize a preparation set that is illustrative of the cases you need to generalize to. This is frequently harder than it sounds: if the example is excessively small, you will have inspecting clamor. However, even extremely enormous examples can be non-representative of the testing technique is defective. This is called sample data bias.
- Quality of Data
If the preparation of information is loaded with mistakes, exceptions, and clamor it will make it harder for the framework to distinguish the basic examples, so your framework is less inclined to perform well. It is regularly definitely justified even despite the push to invest energy tidying up your preparation information. In all actuality, most information researchers spend a noteworthy piece of their time doing only that. For instance: If a few occurrences are exceptions, it might help to just dispose of them or attempt to fix the blunders physically. If a few examples are feeling the loss of a couple of highlights (e.g., 5% of your clients did not determine their age), you should choose whether you need to overlook this characteristic altogether, disregard these occasions, fill in the missing qualities (e.g., with the middle age), or train one model with the component and one model without it, etc.
- Unimportant Features
The machine learning framework might be fit for learning if the preparation information contains enough significant features and not very many unimportant ones. Now days Feature engineering, became very necessary for developing any type of model. Feature engineering process includes choosing the most helpful features to prepare on among existing highlights, consolidating existing highlights to deliver an increasingly valuable one (as we saw prior, dimensionality decrease calculations can help) and then creating new features by social event new information.
- Overfitting
Overfitting implies that the model performs well on the preparation information, yet it doesn’t sum up well. Overfitting happens when the model is excessively mind boggling comparative with the sum and din of the preparation information.
The potential arrangements to overcome the overfitting problem are
- To improve the model by choosing one with fewer boundaries (e.g., a straight model instead of a severe extent polynomial model), by lessening the number of characteristics in the preparation of data.
- To assemble all the more preparing information
- To lessen the commotion in the preparation information (e.g., fix information blunders and evacuate anomalies)
- Constraining a model to make it more straightforward and decrease the danger of overfitting is called regularization.
1.11 Hypothesis Space
A hypothesis is an idea or a guess which needs to be evaluated. The hypothesis may have two values i.e. true or false. For example, “All hibiscus have the same number of petals”, is a general hypothesis. In this example, a hypothesis is a testable declaration dependent on proof that clarifies a few watched marvel or connection between components inside a universe or specific space. At the point when a researcher details speculation as a response to an inquiry, it is finished in a manner that permits it to be tested. The theory needs to anticipate a predicted result. The ability to explain the hypothesis phenomenon is increased by experimenting the hypothesis testing. The hypothesis may be compared with the logic theory. For example, “If x is true then y” is a logical statement, here x became our hypothesis and y became the target output.
Hypothesis space is the set of all the possible hypotheses. The machine learning algorithm finds the best or optimal possible hypothesis which maps the target function for the given inputs. The three main variables to be considered while choosing a hypothesis space are the total size of hypothesis space and randomness either stochastic or deterministic. The hypothesis is rejected or supported only after analyzing the data and find the evidence for the hypothesis. Based on data the confidence level of the hypothesis is determined.
In terms of machine learning, the hypothesis may be a model that approximates the target function and which performs mappings of inputs to outputs. But in cognitive computing, it is termed as logical inference. The available data for supporting the hypothesis may not always structured. In real-world applications, the data is mostly unstructured. Figure 1.11 shows an upright pattern of hypothesis generation and scoring. Understanding and traversing through the unstructured information requires a new computing technology which is called cognitive computing. The intellectual frameworks can create different hypotheses dependent on the condition of information in the corpus at a given time. When all the hypotheses are generated then they can be assessed and scored. In the below fig of, IBM’s Watson derives the responses questions and score each response. Here 100 autonomous hypothesis might be produced for a question after parsing the question and extracting the features of the question. Each generated hypothesis might be scored using the pieces of evidence.

Figure 1.11 Hypotheses generation IBM Watson.
1.11.1 Hypothesis Generation
The hypothesis must be generalized and should map for the unseen cases also. The experiments are developed to test the general unseen case. There are two key ways a hypothesis might be produced in cognitive computing systems. The first is because of an express inquiry from the user, for example, “What may cause my fever and diarrhea?” The system generates all the possible explanations, like flu, COVID where we can see these symptoms. Sometimes the given data is not sufficient and might require some additional input and based on that the system refines the explanations. It might perceive that there are such a large number of answers to be valuable and solicitation more data from the client to refine the arrangement of likely causes.
This way to deal with hypothesis generation is applied where the objective of the model is to recognize the relations between the causes and its effects ex. Medical conditions and diseases. Normally, this kind of psychological framework will be prepared with a broad arrangement of inquiry/ answer sets. The model is trained using the available question and answer sets and generates candidate hypotheses.
The second sort of hypothesis generations doesn’t rely upon a client inquiring. Rather, the system continually searches for atypical information patterns that may demonstrate threats or openings. In this method, hypotheses are generated by identifying a new pattern. For example to detect unauthorized bank transactions the system generated those fraudulent transaction patterns, which became the hypothesis space. Then the cognitive computing model has to find the evidence to support or reject the hypothesis. The hypothesis space is mostly based on assumptions.
The two kinds of hypothesis generation methods produce at least one theory given an occasion, however in the primary case, the event is a client question, and in the second it is driven by similar pattern data.
1.11.2 Hypotheses Score
The next step is to evaluate or score these hypotheses based on the evidence in the corpus, and then update the corpus and report the findings to the user or another external system. Now, you have perceived how hypotheses are generated and next comes scoring the hypothesis scoring. In the scoring process, the hypothesis is compared with the available data and check whether there is evidence or not. Scoring or assessing a hypothesis is a procedure of applying measurable strategies to the hypothesis evidence sets to dole out a certain level to the theory and find the confidence level to each hypothesis. This confidence level weight might be updated based on the available training data. The threshold score is used to eliminate the unnecessary hypothesis. On the off chance that none of the hypothesis scores over the threshold the system may need more input which may lead to updating the candidate hypothesis. This information may be represented in a matrix format and several tools are available to manipulate these matrices. The scoring process is continued until the machine learns the concept.
1.12 Developing a Cognitive Computing Application
Cognitive computing is evolving at a good pace and in the next decade, a large number of applications can be built using this technology.
The organizations of different sectors are in the premature stages in developing the cognitive applications; its applications are from healthcare to production industries to governments, making a decision using the huge variety and volumes of data. There are some issues to be noted in the process of building the application [11].
- A good decision can be taken if large volumes of data can be analyzed
- There will be a change in decisions dynamically with the frequently varying data, obtaining data from the latest sources and also from the other forms of data
- There should be a transfer of knowledge by the domain experts to the junior trainees through the training and mentoring process.
- In the process of decision making a large amount of data is analyzed, several options and solutions to a problem are obtained.
To develop the cognitive application the first step is to define the objective, which requires understanding the types of problems the application can solve. It also has to consider the different types of users using the application. The most important thing is that it also has to take care of the types of issues the user is interested in and also what they are looking for and need to know. The next step is to define the domain, it is important because we need to identify and also assess the different data sources that match to build the application. Defining the domain helps to identify the subject experts.
In training the cognitive application the domain helps in identifying the subject experts that will be useful in training the cognitive application. Table 1.2 gives the examples of the Cognitive application domains.
Characterizing Questions and Exploring Insights
The cognitive applications that are developed in the early stages for customer engagement can be divided into two types:
- Discovery and Exploration
- Using sophisticated question and response mechanisms to
- respond to inquiries as part of continuous exchange with the client.
The cognitive framework can build a relationship between questions, answers, and information to enable the client to better grasp the topic at a more profound level. The inquiries clients will pose can be set in two general classifications (Table 1.3):
- Question–Response pairs: The responses to the inquiries can be unearthed in an information resource. There might be clashing responses inside the information resources, and the framework will break down the choices to furnish various reactions with related certainty levels.
- Anticipatory analytics: The client takes part in an exchange with the cognitive application. The client may pose a few inquiries however not all the inquiries. The subjective application will utilize prescient models to envision the client’s next inquiry or arrangement of inquiries.
Table 1.2 Examples of cognitive application domains [11].
| S. no. | Domain | Data requirements to be selected | Subject experts |
|---|---|---|---|
| 1 | Medical | Electronic medical health records, International classification of diseases (ICD) Codes, Research journals | Experienced specialists, doctors, and specialists. |
| 2 | Airplane Manufacturing and Maintenance | List of complete parts, spare parts inventory and maintenance records of each plane | Skilled and qualified technicians, preservation staff, and trained and experienced pilots. These personsare capable of anticipating the failures and fix them |
| 3 | Trade | Client and product information | Skilled and qualified Salespersons |
Table 1.3 Question–response pairs for different types of users.
| S. no. | Question | Answer |
|---|---|---|
| 1 | Health Consumer: What Did You Say about a morcellator | A morcellator is a tool that consists of a spinning blade that is utilized to destroy a fibroid through an opening on a female’s stomach. The power and speed of the tool may make cell particles from the fibroid become scattered in the stomach. |
| 2 | Gynecologist: What are the consequences and advantages of utilizing a morcellator for careful treatment of fibroids? | Consequences incorporate likely spread of an occult uterine sarcoma. Advantages incorporate little incisions for the patient, lowblood loss, and faster healing and recovery. |
Along with the things we discussed above the following requirements are also needed to build the application
- Creating and Refining the Corpora
- Preparing the Data
- Ingesting the Data
- Refining and Expanding the Corpora
- Governance of Data
- Training and Testing
To understand the way to build a cognitive application here we discuss with the health care application.
1.13 Building a Health Care Application
To develop a cognitive health care application, the system has to incorporate differing associations, where each association commits to growth, funding, service provision, products, and procedures. The listing shows the various group of people required for the system.
- Patients
- Health care Practitioners
- Pharmaceutical Companies
- Players
- Governance bodies
- Data service providers.
1.13.1 Healthcare Ecosystem Constituents
The Healthcare environment as shown in Figure 1.12 incorporates the information utilized by various constituents and these are:

Figure 1.12 Healthcare ecosystem.
- Patients: With family backgrounds and research behaviors, people participation in the health care ecosystem creates individually identifiable results Information, which may be anonymously aggregated, if allowed; direct treatment of people with identical qualities.
- Providers: Information covers a wide scope of unstructured and organized sources. A few models incorporate patient clinical records (EMR, specialists’ office notes, and lab information), information from sensors and clinical gadgets, consumption records from the emergency clinic, clinical course readings, diary articles, clinical exploration examines administrative reports, charging information, and operational cost information.
- Pharmaceutical organizations: Data to help research in pharmacy, taking up the clinical trials, testing the drug, and verifying the side effects, competitive information, and prescriptions provided by the clinical suppliers.
- Payers: Data incorporates charging information and use audit information.
- Administrative agencies: Regulating the information.
- Data service providers: Taxonomies and ontologies of healthcare terminology, Usage of prescription drugs, and adequacy information providing software to analyze.
1.13.2 Beginning With a Cognitive Healthcare Application
In the previous stages, cognitive healthcare application is based on the cognitive platform. To build up an application you have to start by characterizing your objective clients and afterward train the cognitive framework to address the issues of your client base. The following questions are important to note to develop the application. Define your general branch of knowledge for your application? List out the requirements of the clients and their expectations of the application and also find out the knowledge levels of the clients on this subject?
1.13.3 Characterize the Questions Asked by the Clients
This can be started by collecting the sorts of inquiries that will be posted by a delegate gathering of clients. On collecting this information an information base can be constructed to respond to the inquiries and train the framework successfully. Although you might be enticed to start by looking into information resources, as a result, you can fabricate your insight base or corpus for your framework, best practices demonstrate that you have to make a stride back and characterize your general application technique. The problem to start with corpus is it is likely to aim to the inquiries to sources that have been already assembled. If you start with the corpus, you may discover you can’t address the issues of your end clients when you move to an operational state.
These underlying inquiries need to speak to the different kinds of clients that always question the application. What would clients like to ask and by what means will they ask inquiries?
While building the application we need to consider whether it is a consumer-based application utilized by an all-inclusive community of clients, or are you building up a framework that is destined to be utilized by technicians? The future performance of the application depends on gathering the right questions. A large number of these questions and answers pairs should be collected and used in the system as machine learning algorithms are used to train it. We need at least 1,000 to 2,000 question– answer pairs to kick start the procedure. The subject expert’s help should be taken and the questions are posed by the clients using their voice to the system.
1.13.4 Creating a Corpus and Ingesting the Content
The corpus gives the base of information utilized by the psychological application to respond to questions and give reactions to inquiries. All the reports the cognitive application needs to access will be remembered for the corpus. The Q–A sets you have made assistance to drive the way toward gathering the content. By starting with the inquiries, you have a superior thought of the substance that will be required to fabricate the corpus. List the contents required to answer the questions precisely? All the resources required for answering the questions are needed to be identified and should be added to the corpus. For instance, these resources include research articles, medical textbooks, pharmaceutical research data, ontologies, taxonomies, health dictionaries, clinical studies, and patients’ records.
1.13.5 Training the System
To train the system the key point is analyzing the question and answer pairs. Even though it is significant for delegate clients to produce inquiries, specialists need to produce the appropriate responses and settle the inquiry/answer sets. The inquiries should be predictable with the degree of information on the end client. In any case, the specialists need to guarantee that the appropriate responses are exactly what’s more, following the substance in the corpus. Table 1.4 gives you an example that covers some questions or inquires. The system learns from the questions.
Table 1.4 Sample questions to train the application [11].
| S. no. | Question |
|---|---|
| 1 | What is the difference between whole and skim milk? |
| 2 | Is low-fat milk unique with whole milk? |
| 3 | Which is better skim milk or whole milk? |
1.13.6 Applying Cognition to Develop Health and Wellness
The main challenging task is that these applications don’t generally give the customized reactions and motivating forces that their individuals need to change conduct and optimize the results. The compensation of helping people to shed weight, increment work out, eat a well-balanced diet, quit smoking, and make sound decisions generally is immense.
Medicinal services payers, governments, and associations all get an advantage if communities are healthy and people able to manage recently analyzed conditions. These conditions are premature death, Diabetics, High blood pressure, Heart disease, stroke, high cholesterol, hypertension, sleep apnea, Asthma, Osteoarthritis, Gall bladder disease, and certain types of cancer. Discovering approaches to improve the associations and correspondence of people and the medicinal services is a need for various developing organizations.
1.13.7 Welltok
It has developed a proficient healthcare concierge—CaféWell—that keeps in touch with the clients and updates their relevant health information by processing a vast amount of medical data. This is a health tool used by insurance providers to provide relevant information to their customers to improve their health. This application is smart in answering the queries of the clients and it gathers the information from various sources and offers customized heath proposals to their clients to improve their health (Figure 1.13), (Table 1.5).
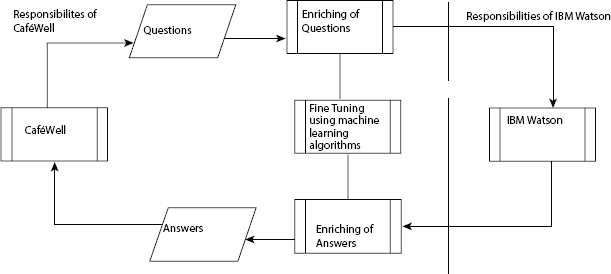
Figure 1.13 Welltok training architecture [11].
Table 1.5 Sample of Welltok question/answer pairs [11].
| S. no. | Question | Answer |
|---|---|---|
| 1 | What are some way of life changes that I ought to make on the off chance if I have high blood pressure? | Way of life changes is similarly as significant as taking prescriptions. Lessening your weight by only 10 pounds might be sufficient to bring down your blood pressure. Shedding weight can assist with upgrading the impacts of high blood pressure prescription and may likewise decrease other risk factors, such as diabetes and high bad cholesterol |
| How can you decide about the calories burned by the body? | Basal Metabolic Rate (BMR) is calculated using the Harris–Benedict equation. This equation use3 variables: weight, height, and age to calculate the total energy expenditure by multiplying BMR by an activity factor. Equation For Men: BMR = 88.362 + (13.397 × weight in kg) + (4.799 × height in cm) – (5.677 × age in years) |
|
| Do my dietary needs differ all through life? | Dietary needs change all through life. From early stages through adulthood, great nourishment is fundamental to growth and development, and to keeping up wellbeing in the later years. | |
| For what reason should I read the labels on packaged foods? Particularly on a low-sodium diet, you have to take a gander at the food name to constrain sodium admission. |
Almost all of the packaged foods have a list of ingredients and their nutrition. In the United States, Food and Drug Administration (FDA) look over the nutrition fact of a processed food using the food label. The reason for this is to assist the buyers with making fast, informed food decisions that add to a healthy diet. Particularly on a low-sodium diet, you have to take a gander at the food name to constrain sodium intake. |
|
| I have a grain hypersensitivity, what food would it be advisable for me to stay away from? What sort of food are considered grains? |
Any food produced using wheat, rice, oats, cornmeal, grain, or another oat grain is a grain item. Bread, pasta, cereal, breakfast oats, tortillas, and cornmeal are instances of grain items. There are entire grains, containing the grain piece, also, refined grains, which have been processed to evacuate bran and germ. There are numerous advantages to an eating routine wealthy in grains. |
1.13.8 CaféWell Concierge in Action
The intention of this is to assist the people in understanding their health position and guide them with the customized methods to accomplish good health and also encouraging them by giving rewards to them on meeting their goals. Suppose that a person went to a doctor for a diagnosis of diabetics and taken some tests after the examination. After receiving the results doctor advises losing your weight, by changing the diet and also asks to increase the physical activity. On the other hand, your job makes you travel a lot and also making you take the diet in the outside restaurants. You also don’t have enough time to increase physical activity by spending some time at the gym. Now the question arises what I have to do now? With the increase in technology and the availability of information on the internet, a search can be made on the diabetics. A lot of information, methods, and applications are found on the net and it leads to confusion and also makes us scary. The main important point to note here is a need for personalized support and it can be made possible with the help of the cognitive application because it can provide a better insight with the personal information making it customized to the needs of the person rather than going in a generalized method.
Using IBM Watson’s cognitive capability CafeWell Concierge (Figure 1.14) built a health application with a lot of support for the people who use it. Using the tracking devices helps to reduce your weight, reminds you to take pills on time, customize your diet based on the BMI, gives information about the restaurants around you with the food choices and also other community support. The main advantage of this is that it will give a tailored and constant support to the user.

Figure 1.14 Content acquisition.
1.14 Advantages of Cognitive Computing
There is a revolution in the automation process in every organization and the pace has increased these days. The organizations have realized that if they do not do it they will be lost in the competition. Cognitive computing helps organizations to take decisions by their executives as it can analyze a large volume of all types of data.
Cognitive computing has a host of benefits including the following:
Precise Data Analysis
These systems are highly productive in analyzing a situation efficiently as they can gather and analyze a large volume of data. In the event we take the instance of the health care industry, these cognitive systems play an important role in assisting the doctors and making things easy for deciding so that life can be saved in time. The cognitive systems gather and dissect the information from different resources for example past clinical reports, past information from the clinical organizations, medical journals, and diagnostic tools that assist the doctors in giving a suggestion based on an information-based treatment that benefits the patients and also the doctors. One important point to know here is that cognitive computing is not going to replace the doctors, but assist them to take decisions faster.
Leaner & More Efficient Business Processes
In real-time the cognitive computing can access the large volume of data and analyze it thereby it can find new business opportunities and also can deal with the basic procedure is driven issues progressively. With the help of IBM Watson, the system can simplify the lengthy process, decrease the risk factors, and guides to take the right path with the varying conditions.
Enhanced Client Interaction
The cognitive computing can assist humans while interacting with clients to provide a better answer to the question posed by him. It can be utilized to automate the client interaction process and provide a better service to the clients. This technology can provide a solution to the client without the need for interaction with the staff. It can provide better relevant information to the customer so that it increases client satisfaction, improve the client experience, and considerably more betrothed with the organization.
1.15 Features of Cognitive Computing
The motivation behind cognitive computing is the making of processing structures that can take care of confusing issues without consistent human intercession. To execute these functions in business and across the board applications, Cognitive Computing consortium has suggested the features as Adaptive, Interactive, Iterative and stateful, and Contextual.
Adaptive: It is the initial step for building a cognitive application. The system should learn to adapt from the surroundings as humans do. It should be dynamic and always well prepared to gather information, learning the objectives, and updating the requirements and goals. This type of system cannot be designed for a single assignment.
Interactive: In human beings, the brain controls the body by connecting with different and gathering information using the senses. In the same manner, the cognitive application should be able to interact with different elements such as processors, gadgets, databases, users, and cloud services. It should make use of various technologies like natural language processing, machine learning, advanced analytics, deep learning probability and statistics, and big data analytics. For interaction with the users, it uses chatbots.
Iterative and stateful: The framework must be able to recall the past interactions in a procedure and return the information whenever necessary. It ought to have the option to characterize the issue by posing inquiries or finding an extra source. This element needs a cautious utilization of the information quality and approval procedures to guarantee that the framework is constantly furnished with enough data and that the information sources it works on to convey solid and state-of-the-art input.
Contextual: They should comprehend, distinguish, and extract relevant components, for example, implications, suitable domains, position, time, guidelines, client’s profile, procedure, errand, and objective. They may draw on various wellsprings of data, including both organized and unstructured computerized data, just as tactile sources of information.
1.16 Limitations of Cognitive Computing
Limited Analysis of Risk
The cognitive applications fail flat when examining the unstructured data. There will be a risk with the unstructured data as it incorporates politics, finance, culture, economy, and public. For instance, there is a prescient model that finds an area for oil investigation even though a lot of people objecting it. Yet, if the nation is experiencing a complete change in the government, then human intervention is required as the cognitive system should also consider this and it cannot be done on its own [9].
Rigorous Training Process
These systems require a lot of training initially to comprehend the procedure and improve, but to do this a lot of data is required at the initial stage itself. The adoption is slow because of this lengthy process of collecting the data and training the system. One fine example of this is the training of IBM Watson by WellPoint’s financial management. When the user uses the Watson the text has to be inspected on each medical policy by the company engineers. The medical staff like the nurses has to upload the data regarding the cases until the cognitive system understands the specific medical situation. Also, the mind-boggling and costly procedure of utilizing cognitive frameworks aggravates it even.
More Knowledge Enlargement Instead of Artificial Intelligence
The extent of present cognitive innovation is constrained to commitment and choice. Most of these systems are best as assistants which are increasingly similar to knowledge growth and not as popular as the artificial intelligence applications. It supplements human reasoning and examination however relies upon people to take the final decision. Chatbots and smart assistants becoming popular these days are some fine examples. As opposed to a big business wide selection, such particular activities are a viable path for organizations to begin utilizing cognitive models. In the process of automation, the subsequent step in processing is cognitive computing and it has become popular in every field. The cognitive computing will set standards for the systems to arrive at the degree of the human brain. In the case of innovation, dynamic changes, a significant level of uncertainty it is difficult to apply in these circumstances. The multifaceted nature of the issue develops with the number of information sources. It is trying to total, coordinate, and break down such unstructured information. A complex cognitive arrangement ought to have numerous innovations that exist together to give profound area bits of knowledge.
The enterprises looking to adopt cognitive solutions should start with a specific business segment. These segments should have strong business rules to guide the algorithms, and large volumes of data to train the machines. In the cognitive system more technological advancements should be included so that they can take care of changing real-time data, past data, and also the different types of data (Unstructured, structured, and semi-structured). It will be better if the Kafka, Elasticsearch NoSQL, Hadoop, Spark, etc. become a part of the cognitive systems so that they handle the data problems easily. Any enterprise having a protocol, business domain and huge volumes of company data can adopt these cognitive systems as they are useful in training the system.
Issues With Cognitive Computing: Challenges for a Better Future
Each innovation faces a few issues at some stage in its lifecycle. Technology has a lot of potentials to make an impact on the lives of people, but humans are resisting this innovative technology owing to fear of transform. Individuals are thinking of a few cognitive computing detriments tossing huge difficulties in the way towards more noteworthy implementation, which are given below:
Security
At the point when computerized gadgets oversee basic data, the subject of security naturally comes into the image. With the ability to deal with a lot of information and break down the equivalent, psychological figuring has a critical test concerning information security and encryption. With an ever-increasing number of associated gadgets coming into the scene, cognitive processing should consider the issues identified with security penetrate by building up a full-confirmation security plan that likewise has a system to apprehensive actions to encourage integrity.
Adoption
The greatest obstacle in the way of accomplishment for any innovation is adopting it voluntarily. To make this technology effectively, it is fundamental to build up a future vision of how innovation will improve procedures and organizations. Through a coordinated effort between different partners, for example, innovation engineers, ventures, government, and people, the reception procedure can be smoothed out. Simultaneously, it is basic to have an information protection system that will additionally help the selection of technology.
Change Management
People are resistant to change because of their natural human behavior & as cognitive computing have the power to learn like humans, people are fearful that machines would replace humans someday. This has gone on to impact the growth prospects to a high level. Change the board is another pivotal test for cognitive computing need to overcome for survival. Individuals are impervious to change in light of their normal human conduct and as the technology can be trained like people, individuals are frightful that machines would supplant people sometime in the not so distant future. This has proceeded to affect the development possibilities to a significant level. The technology can work in synchronization with the people and can help them in taking the wise decision sat the right time.
Extensive Advancement Cycles
Probably the best test is the time to put resources into the improvement of situation-based applications through the cognitive approach. It is at present being created as a universal arrangement—this implies the arrangement can’t be executed over different industry fragments without development groups and a lot of time to develop the application.
Extensive advancement cycles make it harder for small organizations to create cognitive capacities all alone. With time, as the improvement lifecycles will in general abbreviate, this technology will gain a greater stage in the future.
1.17 Conclusion
Cognitive computing is a subject which helps to make better decisions by humans. It involves machine learning, big data analytics, and advanced analytics to make better decisions. It builds a corpus to keep all the data in it and also it updates it all the time. It takes data from the different sources and also it can read the structured, unstructured, and semi-structured data models. Cognitive computing does not make any disturbances in the hiring market since it cannot replace humans but it helps and assists them to do better in their fields.
References
1. Cognition, Lexico, Oxford University Press and Dictionary.com, https://www.lexico.com/definition/cognition. Retrieved 6 May 2020.
2. Von Eckardt, B., What is cognitive science?, pp. 45–72, MIT Press, Princeton, MA, 1996.
3. Revlin, R., Cognition: Theory and Practice. Worth Publishers, 2012. https://books.google.co.in/books?id=tuCBGepl2VMC
4. Liddell, H.G. and Scott, R., γιγνσκω, A Greek-English Lexicon, revised by H.S. Jones and R. McKenzie, Clarendon Press.—via Perseus Project, Oxford, 1940, Retrieved 6 May 2020.
5. Stefano, F. and Bianchini, F., On The Historical Dynamics Of Cognitive Science: A View From The Periphery, in: The Search for a Theory of Cognition: Early Mechanisms and New Ideas, p. XIV, Rodopi, Amsterdam, 2011.
6. Matlin, M., Cognition, p. 4, John Wiley & Sons, Inc., Hoboken, NJ, 2009.
7. Eddy, M.D., The Cognitive Unity of Calvinist Pedagogy in Enlightenment Scotland, in: Reformed Churches Working Unity in Diversity: Global Historical, Theological, and Ethical Perspectives, Á. Kovács (Ed.), pp. 46–60, l’Harmattan, Budapest, 2016.
8. Marr, B., What Everyone Should Know About Cognitive Computing https://www.forbes.com/sites/bernardmarr/2016/03/23/what-everyone-should-know-about-cognitive-computing/?sh=30f75db65088, 2016, March 23.
9. https://marutitech.com/cognitive-computing-features-scope-limitations/.
10. Mukadia, M. What is Cognitive Computing? How are Enterprises benefitting from Cognitive Technology? Towardsdatascience.Com. https://towardsdatascience.com/what-is-cognitive-computing-how-are-enterprises-benefitting-from-cognitive-technology-6441d0c9067b, 2019.
11. Hurwitz, J. S., Kaufman, M., Bowles, A., Cognitive Computing and Big Data Analytics. John Wiley & Sons, 2015, https://www.wiley.com/en-us/Cognitive+Computing.
12. Mundt, C., Why We Feel: The Science of Human Emotions. Am. J. Psychiatry, 157, 1185–1186, 2000. https://doi.org/10.1176/appi.ajp.157.7.1185.
13. Chen, M., Herrera, F., Hwang, K., Cognitive Computing: Architecture, Technologies, and Intelligent Applications. IEEE Access, 6, 19774–19783, 2018.
14. Appel, A.P., Candello, H., Gandour, F.L., Cognitive computing: Where big data is driving us, in: Handbook of Big Data Technologies, pp. 807–850, 2017.
15. Chen, M., Tian, Y., Fortino, G., Zhang, J., Humar, I., Cognitive Internet of vehicles. Elsevier Comput. Commun., 120, 58–70, 2018. https://doi.org/10.1016/j.comcom.2018.02.006
16. Hwang, K. and Chen, M., Big-Data Analytics for Cloud, IoT, and Cognitive Learning, Wiley, London, U.K, 2017.
18. https://towardsdatascience.com/ai-and-cognitive-computing-fc701b4fbae7.
*Corresponding author: [email protected]
†Corresponding author: [email protected]
‡Corresponding author: [email protected]