
Chapter 5. Searching the blogosphere
| This chapter covers |
|
In early 2007, Microsoft was slated to launch its much-awaited new operating system—Vista. Perhaps tacitly acknowledging the growing power of the blogosphere—the collection of blogs on the web—and the impact it has in shaping the thoughts of others, a Microsoft employee contacted about 90 influential bloggers in late December 2006, offering them each a laptop, probably worth about $2,000, preloaded with Vista, and encouraging them to blog about their experiences with the new operating system. Leaving aside issues related to ethics and conflict of interest, public relations firms are now reaching out to bloggers, podcasters, and people who post video clips on the Internet to promote their products.
What people say about your product or application has an impact on others and affects your brand—it’s important to track what others are saying about your product or application. In this chapter, we look at how we can search the blogosphere to discover nuggets of relevant information. The infrastructure developed here to retrieve blog entries is leveraged in the remaining part of the book to build examples to illustrate various algorithms.
In the previous three chapters, we looked at how to gather information from within your application. Collective intelligence deals with using information both within and outside one’s application. In this and the next chapter, we focus on gathering relevant information from outside your application.
In section 4.2.1, we briefly looked at the elements of a blog. Searching for relevant information within blogs in your application is straightforward—index all content with a search engine and derive metadata from it. But harvesting information from the millions of blog entries not within your application is more involved. There are a large number of companies,[1] blog-tracking providers, that are in the business of tracking blogs. These companies provide APIs to query for relevant blog entries, usually using RSS (introduced in section 5.1.2) and/or proprietary APIs.
1 As of September 2008, there were more than 150 companies that tracked various kinds of RSS feeds.
This chapter shows how to search blog-tracking providers. We leverage this infrastructure again in chapter 9 to illustrate the clustering process, in chapter 10 to illustrate predictive models, in chapter 11 to illustrate a search engine, and in chapter 12 to illustrate building a recommendation engine.
In this chapter, we build a generalized framework so you can start using blog-tracking providers to search blogs. We begin with a brief introduction to the blogosphere, RSS, and blog-tracking providers. Next, we build a generalized framework for searching blogs. This is followed by building the base implementation, which takes care of most of the heavy lifting.
There are a number of blog-tracking providers. Fortunately, most of them provide an RSS API in addition to any proprietary APIs to search for blogs they’re tracking. We show how to integrate blog-tracking providers into the framework by integrating Technorati and Bloglines using their proprietary APIs, followed by integrating other providers, MSN and Blogdigger, using RSS 2.0. Other formats and providers can be integrated in a similar manner.
5.1. Introducing the blogosphere
People blog on virtually every topic, and there are literally millions of blogs in the blogosphere.[2] Further, people may blog within your application. All these blog entries contain a rich set of information, which when relevant could be valuable to users. The universe of blogs in essence is a good example of collective intelligence in action; here, the collective contributions of millions of people shape the thoughts of others.
2 As of September 2008, Technorati was tracking more than 112 million blogs.
In this section, we look at some of the benefits associated with searching the blogosphere; briefly look at RSS, a standard publishing format; and provide an overview of the different blog tracking providers.
5.1.1. Leveraging the blogosphere
In the previous chapter, I mentioned that content is the building block for applications. Many times, you have to go outside your application to get relevant content. It’s common for applications to get news feeds and then show relevant news based on the context and the user. Similarly, the growing blogosphere provides a rich set of content—the collective set of blogs that can shape the minds of others—that can be aggregated and shown when relevant. Continuing with our example, if your application were in the business of selling the latest version of an operating system, perhaps it would be useful to show users blog entries from people who’ve expressed their experiences in using the new operating system.
Finding relevant content consists of two parts: first you need to aggregate or find content, and second you need to determine whether the context is relevant. This chapter focuses on the first part. You should be able to determine the relevance of the retrieved document to an item of interest using the similarities in the term vectors for the two items. The infrastructure for this similarity computation is developed in chapter 8.
Using the framework developed in this chapter, you should be able to build a feature that periodically queries the blogosphere for relevant blog entries. This could be helpful in protecting your brand; you can automate the retrieval of relevant blog entries and extract keywords to determine either positive or negative comments about your brand. The retrieved items could also be classified for review by a human.
Next, let’s briefly look at RSS, one of the key enabling technologies for searching the blogosphere. If you’re already familiar with RSS, you can skip this section.
5.1.2. RSS: the publishing format
Chances are that there are hundreds of articles or other content that you’d like to keep track of on the Internet. This could be tracking blog entries of your favorite bloggers or following news as it unfolds. It’s virtually impossible to manually go and check for updates for each of these. Fortunately, software is pretty good at automating this repetitive task. Most sites publish their content in a standard format, RSS, that’s understood by programs such as RSS readers or aggregators, which automatically check for updates and retrieve new content when available.
RSS allows you to publish content to the Web in an XML format that’s commonly understood and also track other sites for updates using a similar format. Formats for publishing content on the Web have existed from the early days of the Internet. RSS has a rich history, and the acronym RSS stands for different things, as we’ll soon see. Given the various formats, it’s helpful to spend a few minutes understanding its history.
In March 1999, the first version of RSS[3]—RDF Site Summary—was created by Netscape. This version became known as RSS 0.9. There were two camps in the RSS community. The first camp wanted to make better use of RDF in RSS, while the other camp wanted to simplify the format and remove RDF. A few months later, in June 1999, Dan Libby produced a prototype called RSS 0.91 that simplified the format, removed all reference to RDF, and incorporated parts of an earlier syndication format created by Dave Winer, an influential blogger from Userland Software. In this version, RSS stood for Rich Site Summary. In late December 2000, Dave Winer released RSS 0.92, and then released a final version in September 2002, known as RSS 2.0. Here, RSS stands for Really Simple Syndication; RSS 2.0 is the most widely used newsfeed format. But there’s more to this story.
3 Resource Description Framework—a language for describing resources on the web
In 2003, a group of influential bloggers and XML experts got together to develop a new newsfeed format known as Atom. Almost every part of RSS 2.0 is optional, and developers can extend the specification by using namespace-qualified vocabularies. This vagueness caused issues with interoperability among different vendor implementations. The influential bloggers joined forces with the Internet Engineering Task Force (IETF) and aimed to develop a new format that was
100 percent vendor-neutral, implemented by everybody, freely extensible by anybody, and cleanly and thoroughly specified.
The Atom Wiki, June 2003. http://www.intertwingly.net/wiki/pie/RoadMap
IETF developed the Atom Publishing Format and Atom Publishing Protocol, and released Atom as an internet standard in 2005. Most blog search providers, with the exception of Blogger.com, provide results in RSS 2.0 format (see http://blogs.law.harvard.edu/tech/rss). Blogger.com provides results in the Atom format.
Listing 5.1 shows a sample of an RSS 2.0 output from Blogdigger.com. We later use this listing in section 5.6 to integrate Blogdigger. Each channel has a number of different <item>s associated with it. This XML snippet gives you a sense of the elements used in RSS 2.0, perhaps the most commonly used RSS version.
Listing 5.1. Example of RSS 2.0 from Blogdigger.com
<rss version="2.0">
<channel>
<title>Blogdigger search for collective intelligence</title>
<link>://www.blogdigger.com/search/collective+intelligence</link>
<description>Blogdigger search for collective intelligence
</description>
<ttl>60</ttl>
<image>
<url>http://www.blogdigger.com/images/blogd_logo01a.gif</url>
<title>Blogdigger search for collective intelligence</title>
<link>http://www.blogdigger.com/search?q=collective+intelligence
</link>
<width>144</width>
<height>55</height>
</image>
<item>
<title>Water - the basic system flow and missing learning ...</title>
<link>http://waterangels.blogspot.com/2006/12/water-basic-system-
flow-and-missing.html</link>
<description>When info from our various network ... ... .</description>
<pubDate>Mon, 1 Jan 2007 00:38:00 EST</pubDate>
<source url="http://waterangels.blogspot.com/atom.xml">what the ...
</source>
<author>macrae.nets</author>
</item>
</channel>
<?xml version="1.0" encoding="UTF-8"?></rss>
If you want to find out more about RSS, Manning has an excellent book on RSS and Atom, RSS and Atom in Action: Web 2.0 Building Blocks, by Dave Johnson. Chapter 12 of the book, Searching and Monitoring the Web, also presents a good overview of blog search engines.
Next, let’s look at companies that are in the business of tracking blogs and other RSS newsfeeds.
5.1.3. Blog-tracking companies
Fueled by the growth of the self-publishing phenomenon, a large number of companies track what’s being published on the Web. As of early 2008, there were more than 40 blog-search engines; some of the best are Technorati, Google, Yahoo!, MSN, Sphere, IceRocket, Bloglines, Blogdigger, DayPop, Zopto, Postami, and Read A Blog.
If you publish content, you want others to find it. This is most easily done by notifying blog-tracking providers of the change. A number of companies allow you to notify multiple blogs and feed-tracking providers. By pinging these providers, you’re notifying these services that content on your site has changed, and they then crawl your site to get the new content and publish it. By pinging these services, you decrease how long it takes before your content is published by these content-tracking providers. Ping-oat (http://www.pingoat.com/), Pingomatic (http://pingomatic.com/), Blogflux (http://pinger.blogflux.com/), Feedshark (http://feedshark.brainbliss.com/), and King Ping (http://kping.com/) are examples of services that ping multiple providers.
APIs provided by these providers typically include the ability to search for relevant blogs using search terms or tags, as well as information on who’s connecting to various blogs using either HTTP Get or HTTP Post. We discuss these kinds of APIs in sections 5.4 and 5.5.
With this background, we’re now ready to build a framework to search the blogosphere. We follow a step-by-step approach, beginning with a generalized framework, building the base classes, and then integrating various providers.
5.2. Building a framework to search the blogosphere
Given the large number of blog-tracking providers, chances are that you may want to integrate more than one of them in your application. The framework we develop in this chapter abstracts out the differences between the APIs for these different providers; thus it’s easy for your application to add new providers and not be coupled to a specific API or a single provider.
As shown in figure 5.1, there are four steps involved in searching the blogosphere:
- Create a query that’s submitted to a blog searcher.
- The blog searcher translates this query into a format that can be understood by the blog-tracking provider and sends this information to the provider using either HTTP Get or HTTP Post.
- The blog-tracking provider processes the request and sends back an XML response.
- The response is parsed by the blog searcher and a response in a standard format is sent back to the client.
Figure 5.1. Four steps in searching the blogosphere
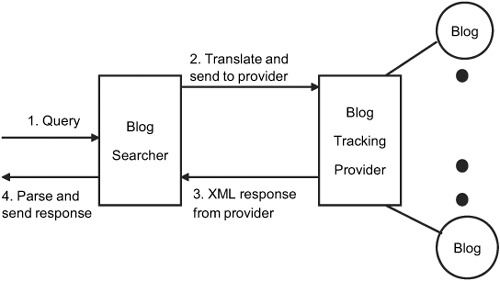
Therefore, to develop a generic framework, we need the four main interfaces that are shown in figure 5.2:
- BlogQueryParameter: captures the query made by the client
- BlogSearcher: translates and submits the query to the provider
- BlogSearchResponseHandler: used by the BlogSearcher to process the response XML
- BlogQueryResult: the canonical response to query
Figure 5.2. The generic architecture for the blog searcher

Next, let’s look at each of these main interfaces. The API is fairly generic, using generic objects as input to the methods and for the results from the query. The API should be resilient to changes as you integrate more blog-tracking providers.
5.2.1. The searcher
The BlogSearcher is the main class that coordinates the process of searching. Listing 5.2 shows the BlogSearcher interface.
Listing 5.2. BlogSearcher interface

BlogSearcher contains only one method:
public BlogQueryResult getRelevantBlogs(BlogQueryParameter param)
throws BlogSearcherException;
which takes a BlogQueryParameter, returns a BlogQueryResult, and throws a BlogSearcherException.
Next, let’s look at the input to the search: BlogQueryParameter.
5.2.2. The search parameters
Parameters for the search are encapsulated in the BlogQueryParameter interface, whose code is shown in listing 5.3.
Listing 5.3. The BlogQueryParameter interface

There are two enums: QueryType and QueryParameter. There are two types of queries that can be made—search by a query string or search by a specified tag:
enum QueryType {SEARCH,TAG};
You may want to generalize to additional search commands in your application. Similarly, the following
public enum QueryParameter {KEY, APIUSER, START_INDEX, LIMIT,
QUERY, TAG, SORTBY, LANGUAGE};
specifies the different parameters that can be set for the query. It’s nearly impossible to list all parameters (a lot of them optional) across the various blog-tracking providers. The enumerated list is the subset of features that we support in our API. Table 5.1 contains a description of the QueryParameters.
Table 5.1. Description of the QueryParameters
|
QueryParameter |
Description |
|---|---|
| KEY, APIUSER | A unique-token KEY and APIUSER name that may need to be passed to the provider. This key and name identify the caller to the provider. The provider may authenticate if the caller has privileges to make the call. This also gives the provider the capability to charge for calls made if required. |
| START_INDEX, LIMIT | There may be a large number of results available from the query. Typically, LIMIT specifies the maximum number of results returned from the START INDEX. For example, if there are 100 results, specifying START INDEX of 20 and LIMIT of 10 will return results 20–29. |
| QUERY, TAG | The query string is populated either as a QUERY or a TAG based on whether we’re interested in search queries or tag related blog entries. |
| SORTBY | Specifies how the results should be sorted, for example, by date or title. |
| LANGUAGE | Language of blog entries. |
There are two methods to retrieve the QueryParameter:
String getParameter(QueryParameter param); Collection<QueryParameter> getAllParameters();
The URL for connecting to a provider is dependent on the type of search and the provider. This can be retrieved using String getMethodUrl();. This doesn’t need to be specified by the calling client code. We’ll build implementations of QueryParameter that automatically set the URL for each provider.
Next, let’s look at how results are returned by the BlogSearcher.
5.2.3. The query results
BlogQueryResult is a container object that contains the result of the blog search query, as shown in figure 5.3. For building a generic API that will be resilient to changes over time, it’s almost always better to return a rich object such as the container BlogQueryResult rather than just a List. You can add more details to the BlogQuery-Result, perhaps by how long the query took or whether multiple blog-tracking providers were queried. Listing 5.4 shows the code for the BlogQueryResult, which consists of two methods.
Figure 5.3. The BlogQueryResult object
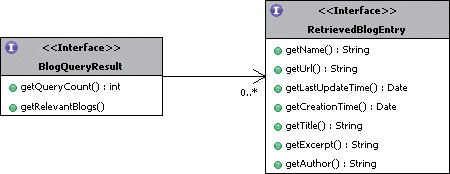
Listing 5.4. The BlogQueryResult interface

The number of results returned by the query is accessed through the following method:
int getQueryCount();
Note that this count is the total number of results, not necessarily the same as the number of blog entries retrieved in this query. The list of blog entries retrieved is
List<RetrievedBlogEntry> getRelevantBlogs();
RetrievedBlogEntry represents one retrieved blog entry, and its specification is shown in figure 5.3. The attributes of RetrievedBlogEntry are a subset of all the attributes of a blog entry (see BlogEntry in section 4.3.1) and represent common attributes that are available across different blog-tracking providers. Note that some providers may expose only a subset of these attributes in their APIs. RetrievedBlogEntry contains the name of the blog, getName(), which is different from the title of the blog entry, String getTitle();.
The BlogSearcher normally receives an XML response from the provider. This XML is handled by a BlogSearchResponseHandler, which parses the response and converts it into BlogQueryResult.
5.2.4. Handling the XML response
The response XML received from a provider is handled by BlogSearchResponse-Handler. The BlogSearchResponseHandler interface, as shown in figure 5.4, consists of a single method, getBlogQueryResult(). For parsing the XML results, it uses Xml-Token objects, corresponding to the XML tags.
Figure 5.4. BlogSearchResponseHandler and XMLToken

Listing 5.5 contains the code for the interface BlogSearchResponseHandler.
Listing 5.5. The BlogSearchResponseHandler interface

The code BlogQueryResult getBlogQueryResult(); returns the resulting result object from the parsed XML.
The SAX parsing deals with tokens, which are represented by the interface shown in figure 5.4. The XmlToken interface has only one method, String getTag();, which returns the associated XML tag.
A number of exceptions can be thrown while talking to external providers. Next, let’s look at how exceptions are handled in the framework.
5.2.5. Exception handling
All exceptions are wrapped in a common exception, BlogSearcherException, which is used for throwing exceptions throughout the package. Listing 5.6 contains the code for the BlogSearcherException, which is a checked exception, so the caller code needs to handle it.
Listing 5.6. Implementation of BlogSearcherException

The constructor BlogSearcherException nests the underlying Throwable, and the new exception is created with the original cause attached, as is typically done with chained exceptions.
So far we’ve looked at the process of searching the blogosphere and introduced interfaces for the main entities that will be used in our framework. Next, let’s implement the base classes for these interfaces. Provider-specific implementations will extend these base classes.
5.3. Implementing the base classes
We’d like most of the heavy lifting to be done by the base implementations, so as to minimize the amount of code required to integrate a new provider. Next, we implement each of the interfaces introduced in the previous section; we begin with an easy one: BlogQueryParameterImpl.
5.3.1. Implementing the search parameters
Each provider has a unique URL, and we’ll have multiple implementations of the BlogQueryParameter that will extend from the base class BlogQueryParameterImpl.
BlogQueryParameterImpl is an abstract class, whose implementation is shown in listing 5.7.
Listing 5.7. Implementation of BlogQueryParameterImpl

BlogQueryParameterImpl uses the following to store the QueryParameters:
private Map<QueryParameter,String> params = null;
It also has a variable QueryType to store the type of query being made and methodUrl to store the provider URL. The rest of the code consists of get methods for the three attributes. The constructor BlogQueryParameterImpl sets the queryType and the methodUrl. There are no set methods for these two attributes—the derived classes will pass these two attributes to the constructor.
Next, let’s look at implementing the result objects.
5.3.2. Implementing the result objects
As shown in figure 5.5, BlogQueryResultImpl implements BlogQueryResult. NullBlogQueryResultImpl extends BlogQueryResultImpl and represents the case when there are no results found for a blog query.
Figure 5.5. Two implementations for BlogQueryResult

The implementation of BlogQueryResultImpl is straightforward. It consists of two attributes. The first stores the List of retrieved blog entries:
private List<RetrievedBlogEntry> results = null;
The other stores the query count:
private Integer queryCount = null;
NullBlogQueryResultImpl extends BlogQueryResultImpl and has a constructor that sets the results List to an empty Collections.EMPTY_LIST:
public NullBlogQueryResultImpl() {
super();
this.setResults(Collections.EMPTY_LIST);
}
The method getRelevantBlogs returns a List of RetrievedBlogEntry objects, which is implemented by RetrievedBlogEntryImpl. RetrievedBlogEntryImpl is a JavaBean object with seven attributes to implement the interface RetrievedBlog-Entry. There are standard get and set methods and a toString method to print out the attributes.
So far we’ve implemented the classes for representing the query and the results. Next, let’s look at the implementation of the BlogSearcher, which is responsible for coordinating the search.
5.3.3. Implementing the searcher
Implementations of BlogSearcher are responsible for converting the input query from the client into a format that the blog-tracking provider can understand and then processing the XML response back from the provider. Figure 5.6 shows the base implementation for the BlogSearcher. Note that there is only one public method that needs to be implemented:
public BlogQueryResult getRelevantBlogs(BlogQueryParameter param)
throws BlogSearcherException {
Figure 5.6. Base implementation for BlogSearcher
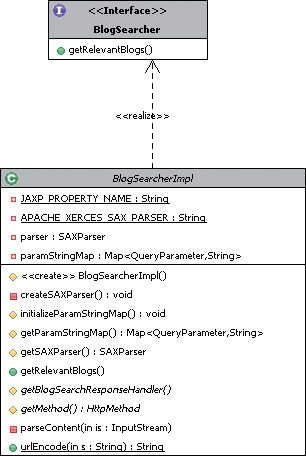
We use SAX[4] parsing to process the XML returned by the provider. We use JAXP[5]—a small layer on top of SAX—to plug in parsers from different vendors without changing the basic code. We use the Apache Xerces-J[6] parser. SAX parsing consists of creating a content handler and invoking the parser with the content handler.
Communication with blog-tracking providers occurs using the Hypertext Transfer Protocol (HTTP). The java.net class provides basic functionality for accessing resources via HTTP. However, the Apache Jakarta Commons HttpClient[7] package provides an easy way to use the HTTP protocol. This open source project follows the Apache Source License and provides flexibility for source and binary reuse.
Note
You can download the HttpClient library from http://jakarta.apache.org/commons/httpclient/downloads.html. Don’t forget to also download the dependent jar files: commons-codec.jar and commons-logging.jar.
Listing 5.8 contains the first half of the code for BlogSearcherImpl. This half deals with creating the SAX parser.
Listing 5.8. First half of BlogSearcherImpl—SAX parser

The system property javax.xml.parsers.SAXParserFactory needs to be set to specify which instance of the SAX parser is to be used. This is set to org.apache.xerces.jaxp.SAXParserFactoryImpl in our case. The constructor creates an instance of the SAX parser:
protected BlogSearcherImpl() throws BlogSearcherException {
createSAXParser();
For this, it first creates a SAXParserFactory:
SAXParserFactory factory = SAXParserFactory.newInstance();
And through the factory, it creates an instance of the parser:
this.parser = factory.newSAXParser();
The attribute paramStringMap stores a Map of QueryParameters and their values.
Next, let’s look at listing 5.9, which deals with submitting an HTTP request and handling the XML response.
Listing 5.9. Second half of BlogSearcherImpl—HTTP and parsing response

Initially, the result BlogQueryResult is initialized to a null implementation, in case of no response back from the provider:
BlogQueryResult result = new NullBlogQueryResultImpl();
The code first creates an instance of the HttpClient:
HttpClient client = new HttpClient();
Next, it creates an instance of HttpMethod, either Get or Post:
HttpMethod method = getMethod(param);
The getMethod() method is abstract and will be implemented by the inheriting classes. The method is executed on the client and a status code is returned, which can be used to determine if the request was successful.
There are two kinds of exceptions that can be thrown:
- HttpException— Represents a logical error.
- IOException— Represents a transport error. This is likely to be an I/O error.
The following code sets the default recovery procedure to recover when a plain IOException is thrown:
method.getParams().setParameter(HttpMethodParams.RETRY_HANDLER,
new DefaultHttpMethodRetryHandler(3, false));
HttpClient will retry the request three times, provided the request was never fully submitted to the blog-tracking provider.
Next, the response back from the provider is read in as a stream:
InputStream is = method.getResponseBodyAsStream(); result = parseContent(is);
The parseContent() method gets the appropriate response handler to parse the response.
Parameters for get methods need to be URL-encoded—for example, collective intelligence gets converted to collective+intelligence. The following code
public static String urlEncode(String s)
is available for inheriting classes to encode the parameters using UTF-8 encoding, which is the recommended encoding scheme.
In this section, we developed the base class for coordinating the search. The last class to be implemented is the base class for handling the XML response.
5.3.4. Parsing XML response
An implementation of the BlogSearchResponseHandler is responsible for parsing the XML response from the provider and creating a BlogQueryResult. BlogSearchResponseHandlerImpl is the base class that other instances extend. This base class does most of the heavy lifting for writing a specific implementation of BlogSearchResponse-Handler. Figure 5.7 shows the methods in BlogSearchResponseHandlerImpl. Default-Handler[8] is the base class for SAX event handlers and contains default implementations for the callbacks.
8http://java.sun.com/j2se/1.4.2/docs/api/org/xml/sax/helpers/DefaultHandler.html
Figure 5.7. The base class for SAX parsing handlers

For consistency across the different parsers, we use Java 1.5’s Enum[9] capabilities. Each XML file has different tokens for the returning values. Each of the XML tokens that we’re interested in is enumerated in an Enum that implements the XMLToken interface. This abstraction helps factor a lot of the XML processing out to the base class.
9http://java.sun.com/j2se/1.5.0/docs/guide/language/enums.html
Typically, the retrieved response from the providers contains date strings; for example, the last updated time for the blog entry or the date the blog entry was created. Unfortunately, different providers use different formats for the date string.
“Mon, 01 Jan 2007 04:20:38 GMT” and “24 Dec 06 01:44:00 UTC” are examples of date formats that are returned from providers—refer to table 5.2 for a more complete list. A DateFormat object is used to parse the String into a Date object.
Table 5.2. The different date formats returned by the different providers
|
Date format |
Example |
Blog-tracking providers |
|---|---|---|
| yyyy-MM-dd HH:mm:ss | 2008-01-10 11:25:56 | Technorati—tag search |
| EEE, dd MMM yy HH:mm:ss zzz | Mon, 01 Jan 2007 04:20:38 GMT | Bloglines |
| yyyy-MM-dd HH:mm:ss zzz | 2007-01-10 19:21:49 GMT | Technorati—query search |
| dd MMM yy HH:mm:ss zzz | 24 Dec 06 01:44:00 UTC | RSS feed, MSN, Blogdigger |
With that overview, let’s look at listing 5.10, which has the first part of the code for BlogSearchResponseHandlerImpl. This listing shows the constructor along with the attributes for the class.
Listing 5.10. Constructor and attributes for BlogSearchResponseHandlerImpl

private BlogQueryResultImpl result = null; private List<RetrievedBlogEntry> entries = null; private RetrievedBlogEntryImpl item = null;
store the resulting BlogQueryResult, the List of RetrievedBlogEntry objects, and the current RetrievedBlogEntry being processed.tagMap contains the list of tokens we’re interested in. Each subclass implements the abstract getXMLTokens() method to return an array of tokens we’re interested in. The subclasses also implement another abstract method, isBlogEntryToken(), which specifies which XML token creates a new entry in the result object.
Next, let’s look at listing 5.11, which contains the parsing-related methods.
Listing 5.11. Parsing-related code for BlogSearchResponseHandlerImpl

In SAX parsing, startElement and endElement are the methods that get called at the start and end of an element. The startElement method takes four parameters. The first is the namespaceURI, which is left empty if there is no namespace. The second is localName (without prefix), or an empty String if namespace processing isn’t being performed—both the namespaceURI and localName are empty strings for our sample XML. The third is the fully qualified element name; for example, weblog or name. The fourth parameter lists any attributes attached to the element. The endElement takes only the first three parameters, since end tags aren’t permitted any attributes.
The following code
public void startElement(String namespaceURI, String localName,
String qName, Attributes atts) throws SAXException {
checks to see if a new instance of an item is available and resets the charString. The method characters() gets called by the SAX parser to report each chunk of character data. This method may be called multiple times for an element; the charString takes care of concatenating the String of characters together.
The utility method getParsedDate() contains logic to select the right date parser and convert the String to a Date object.
That takes care of all the base implementations in our framework. Now, let’s look at how this framework will be extended to integrate the different blog-tracking providers.
5.3.5. Extending the framework
Figure 5.8 gives an overview of the classes that we build. Basically, for each integration, we extend the three classes: BlogSearcherImpl for blog searching, BlogSearchResponseHandlerImpl for handling the XML response, and BlogQueryParameterImpl for configuring the search parameters.
Figure 5.8. The interfaces and their implementing classes

Figure 5.9 shows the classes that will extend BlogQueryParameterImpl to configure the URL that the instance of BlogSearcher will access.
Figure 5.9. The classes extending BlogQueryParameterImpl

So far we’ve implemented the base classes for our framework. Now let’s integrate various blog-tracking providers. We begin with integrating Technorati, who tracks the largest number of blogs—more than 112.8 million blogs as of September 2008. I selected Technorati and Bloglines for their popularity, as well as to illustrate how to integrate a custom API.
5.4. Integrating Technorati
In early December 2006, Jeremy Caplan of Time magazine profiled Technorati, calling it the “Searchlight for the Blogosphere.” In his words:
If Google is the Web’s reference library, Technorati is becoming its coffeehouse, where people go to find out what’s being said and by whom. Rather than send you to Madonna’s web site if you punch her name into its search box, Technorati tells you the latest buzz about her career—and her adoption saga.
Technorati provides an API[10] that allows developers to
- Search for blog postings that use specified keywords or are tagged with those keywords. Furthermore, you can find out which blogs link to a particular URL.
- Get the list of top tags that have been indexed by Technorati.
- Get detailed information about a blog, such as its available feeds and how many other blogs link to it.
- Get information about a Technorati member.
In this section, we look at how to use our framework to search for relevant blogs using the two APIs provided, search and tag. Using this approach, you should be able to extend the framework to query Technorati for other functionality.
To access Technorati’s API, you first need to sign up for the Technorati developer program and agree to the terms of service. Technorati’s API returns results in its own proprietary XML as well as common feed formats such as RSS. In this section, we extend our framework to use Technorati’s custom API, which provides a richer set of information than the RSS feed. Once you sign up for the service, you’ll get a unique API key from Technorati, which you can see at the Technorati API information page.
5.4.1. Technorati search API overview
Using the Technorati API, you can search for blog entries using either the search query or the tag query. The query parameters and response XML are similar in both cases. Technorati uses a RESTful interface for their API, where you can send either a Post or a Get. Let’s look at the details for both these queries.
Technorati Search Query
The search API allows you to search for blog entries that contain the given search string. This gives the same result as entering a search string into Technorati’s search box. We need to send either a Get or a Post to
http://api.technorati.com/search?key=[apikey]&query=[words]
with mandatory parameters key and query, and the following optional parameters:
- format: Output format, either XML or RSS, with XML being the default.
- language: Two-character language code to retrieve results specific in that language. For example, en for English. This feature is in beta and may not work for all languages.
- start: This parameter, along with the next one (limit), is useful for retrieving paginated results. If the limit is set to 20, its default value, and start is set to 0, the API will return entries from 0 to 20. Similarly, if you set start to 40+1, you’ll get the third set of results from 41 to 60.
- limit: The number of values returned, which should be between 0 and 100. There are two more optional parameters: authority, to filter results to those from blogs with at least the Technorati Authority specified, and claim, to include user information with each link. We ignore these parameters, as they aren’t supported by other providers. If you’d like to add them to the API, you need to extend the enums in QueryParameters and modify the TechnoratiBlogSearcherImpl to take these into account.
Listing 5.12 shows the response XML for the search request, with elements that we’re interested in shown in bold.
Listing 5.12. Technorati response XML for search query
<?xml version="1.0" encoding="utf-8"?>
<!-- generator="Technorati API version 1.0 /search" -->
<!DOCTYPE tapi PUBLIC "-//Technorati, Inc.//DTD TAPI 0.02//EN"
"http://api.technorati.com/dtd/tapi-002.xml">
<tapi version="1.0">
<document>
<result>
<query>[query string]</query>
<querycount>[number of matches]</querycount>
<querytime>[duration of query]</querytime>
<rankingstart>[value of start parameter]</rankingstart>
</result>
<item>
<weblog>
<author>
<firstname></firstname>
<lastname></lastname>
<username>[username]</username>
<description></description>
<bio></bio>
<thumbnailpicture></thumbnailpicture>
</author>
<name>[name of blog containing match]</name>
<url>[blog URL]</url>
<rssurl>[blog RSS URL]</rssurl>
<atomurl>[blog Atom URL]</atomurl>
<inboundblogs>[inbound blogs]</inboundblogs>
<inboundlinks>[inbound links]</inboundlinks>
<lastupdate>[date blog last updated]</lastupdate>
</weblog>
<title>[title of entry]</title>
<excerpt>[blurb from entry with search term highlighted]</excerpt>
<created>[date entry was created]</created>
<permalink>[URL of blog entry]</permalink>
</item>
...
</document>
</tapi>
The element querycount gives the total number of responses. firstname and lastname correspond to the first and last name of the author—these are combined together. name, url, title, excerpt, and created correspond to elements in the RetrievedBlogEntry.
Technorati Tag Query
The tag query returns a list of blog entries that have the given tag associated with them. The API consists of sending either a Get or a Post to http://api.technorati.com/tag?key=[apikey]&tag=[tag] with the mandatory parameters key and tag, along with additional optional parameters. format, limit, and start are the same parameters as described for the search query. There are two other optional parameters:
- excerptsize: The number of word characters to include in the post excerpt. We use the default 100 word characters.
- topexcerptsize: The number of word characters to include in the first post excerpt. We use the default 150 word characters.
The XML response is similar to that for the search query.
5.4.2. Implementing classes for integrating Technorati
There are four classes that we need to implement:
- TechnoratiSearchBlogQueryParameterImpl: a search-related query parameter
- TechnoratiTagBlogQueryParameterImpl: a tag-related query parameter
- TechnoratiBlogSearcherImpl: an instance of BlogSearcher that coordinates the search
- TechnoratiResponseHandler: to handle the XML response
Let’s begin by looking at the two implementations for the QueryParameters.
Technorati Query Parameters
TechnoratiSearchBlogQueryParameterImpl implements the QueryParameter for the search query as shown in listing 5.13.
Listing 5.13. TechnoratiSearchBlogQueryParameterImpl

The constructor simply sets the query type to search and the URL for the query. Note that the client code simply needs to create an instance, such as
BlogQueryParameter tbqp = new TechnoratiSearchBlogQueryParameterImpl();
without having to worry about the URL or kind of search.
Similarly, TechnoratiTagBlogQueryParameterImpl sets the query type to tag-related search and sets the URL for the tag search:
private static final String TECHNORATI_TAG_API_URL =
"http://api.technorati.com/tag";
TechnoratiBlogSearcherImpl
Listing 5.14 contains the code for TechnoratiBlogSearcherImpl, the Technorati-related blog searcher. Remember there are two abstract method that this extending class needs to implement. Further, since both Get and Post can be used, we develop methods for both.
Listing 5.14. TechnoratiBlogSearcherImpl

The method initializeParamStringMap() sets the strings for the various query parameters to those expected by Technorati. These parameters are set in the Post method and the Get method to compose the URL.
Note
You can use either Get or Post within our framework, and most of the work is done by the base class that TechnoratiBlogSearcherImpl extends. However, some providers support only HTTP GET.
Lastly, we need to look at TechnoratiResponseHandler, which handles the response and is shown in listing 5.15. Note that most of the implementation deals with implementing the three abstract methods that were specified in the base class BlogSearchResponseHandlerImpl: getXMLTokens(), isBlogEntryToken(), and characters().
Listing 5.15. TechnoratiResponseHandler

The TechnoratiXmlToken contains a list of XML tokens that we’re interested in; this list is returned to the base class by the getXMLToken() method.
New blog entries are created whenever TechnoratiXmlToken.ITEM token is encountered, as shown by the implementation of the isBlogEntryToken() method:
protected boolean isBlogEntryToken(XmlToken t) {
return (TechnoratiXmlToken.ITEM.compareTo(
(TechnoratiXmlToken)t) == 0);
}
Lastly, in the characters() method, appropriate fields in RetrievedBlogEntryImpl and BlogQueryResultImpl are populated.
That’s all that’s required to integrate Technorati into our framework. Next, let’s look at how to call this API. Listing 5.16 shows the output from a unit test that calls this API.
Listing 5.16. Output from Technorati search for “collective intelligence”

This output was generated using the unit test in listing 5.17.
Listing 5.17. Unit test to call Technorati search

Searching Technorati using our framework consists of three steps. First, we create an instance of TechnoratiBlogSearcherImpl:
BlogSearcher bs = new TechnoratiBlogSearcherImpl();
Second, we create an instance of TechnoratiSearchBlogQueryParameterImpl and set the query parameters. In this case, we’re searching for English blog entries containing the keyword collective intelligence:
BlogQueryParameter searchQueryParam = new
TechnoratiSearchBlogQueryParameterImpl();
Third, we perform the search:
BlogQueryResult searchResult =bs.getRelevantBlogs(searchQueryParam);
Doing a tag-based search is similar, except you’ll create an instance of TechnoratiTagBlogQueryParameterImpl:
BlogQueryParameter tagQueryParam = new
TechnoratiTagBlogQueryParameterImpl();
and set the parameter:
tagQueryParam.setParameter(QueryParameter.TAG,
"collective intelligence");
With this example, you should have a sense of how easy it is to integrate new blog providers and invoke them to get relevant blogs. In the next section, we integrate another blog-tracking provider, Bloglines, using their custom API. This demonstrates how to handle responses that return information in attributes.
5.5. Integrating Bloglines
Time featured Bloglines as one of its 50 coolest websites in 2004.[11] Bloglines is a free online service that allows people to search, subscribe, share, and create new feeds, blogs, and rich content. The site indexes “tens of millions of live Internet content feeds, including articles, blogs, images, and audio,” and allows people to create personalized news pages. Based in San Francisco, Bloglines is a fully owned subsidiary of IAC/InterActiveCorp.
In this section, we look at how to integrate Bloglines into our framework to search for relevant blogs. Let’s begin by briefly looking at their API.
5.5.1. Bloglines search API overview
In addition to the blog search API, Bloglines provides three other APIs. These are
- Notifier— For counting unread items in a Bloglines account
- Sync— For accessing subscription lists and unread blog items
- Blogroll— For incorporating subscription lists into other sites
We concentrate on the search API in this section, but you should be able to use the concepts developed in this chapter to access the other APIs.
Bloglines Search API
The search API requires a username and key to be submitted in the request for user authentication. You need to register with Bloglines to retrieve your key. You can find your key once you’re logged in under the Developers tab under My Account.
The search API supports Get calls with four required parameters:
- format=publicapi: specifies that the search page return a publicapi query result in XML
- apiuser: the username or email address from the user’s Bloglines account
- apikey: the API key generated on the Developer Tools tab under Profile Options
- q: the URL-encoded search query terms
Here is an example URL call:
http://www.bloglines.com/search?format=publicapi&apiuser=myusername &apikey=275938797F98797FA9879AF&q=collective+intelligence
Listing 5.18 contains a sample response with the tokens that we’re interested in shown in bold.
Listing 5.18. Example response from Bloglines search

Note that the total number of items retrieved is listed in the attributes for resultset with the name found, and the date of the blog entry is an attribute for the element result.
5.5.2. Implementing classes for integrating Bloglines
To integrate Bloglines, we need to create three classes: BlogLineSearchBlogQueryParameterImpl for the query parameters, BlogLinesBlogSearcherImpl for searching, and BlogLinesResponseHandler for handling the XML response.
BlogLineSearchBlogQueryParameterImpl is similar to the TechnoratiSearchBlogQueryParameterImpl class shown in listing 5.13, except that the URL passed in is http://www.bloglines.com/search. The constructor BlogLineSearchBlogQueryParameterImpl() also sets the query type to search.
Next, let’s look at the implementation of the BlogLinesBlogSearcherImpl, which carries out the search.
Implementing BlogLinesBlogSearcherImpl
BlogLinesBlogSearcherImpl is responsible for carrying out the search, and simply needs to implement the two abstract methods in the base class:
protected abstract BlogSearchResponseHandler getBlogSearchResponseHandler(); protected abstract HttpMethod getMethod(BlogQueryParameter param);
The implementation for BlogLinesBlogSearcherImpl is shown in listing 5.19.
Listing 5.19. Implementation of BlogLinesBlogSearcherImpl

The method getMethod() takes three parameters: APIUSER, KEY, and a QUERY set in a BlogQueryParameter to compose the URL.
Lastly, we need to create a handler, BlogSearchResponseHandler, to handle the XML response.
Implementing BlogLinesResponseHandler
BlogLinesResponseHandler is responsible for parsing the XML returned from Blog-lines and converting it to a BlogQueryResult object. Listing 5.20 contains the code for BlogLinesResponseHandler.
Listing 5.20. BlogSearchResponseHandler

The enum BlogLinesXmlToken keeps a list of tokens that we’re interested in. New blog entries are created by the tag RESULT, which leads to the implementation of the abstract isBlogEntryToken() method:
protected boolean isBlogEntryToken(XmlToken t) {
return (BlogLinesXmlToken.RESULT.compareTo(
(BlogLinesXmlToken)t) == 0);
}
The date of the blog entry and the number of items are extracted from the attributes in the method startElement(), while the other attributes are set in the method characters().
That takes care of all the classes we need to implement to integrate Bloglines. The process of calling Bloglines is similar to that for Technorati. There are three steps involved in executing the search.
First, we need to create an instance of the BlogSearcher:
BlogSearcher bs = new BlogLinesBlogSearcherImpl();
Second, we need to set the parameters: login-name, key, and the search query:
BlogQueryParameter searchQueryParam = new BlogLineSearchBlogQueryParameterImpl(); searchQueryParam.setParameter( QueryParameter.APIUSER, "[login-name]"); searchQueryParam.setParameter(QueryParameter.KEY, "[key]"); searchQueryParam.setParameter( QueryParameter.QUERY, "collective intelligence");
Third, we need to execute the search:
BlogQueryResult searchResult = bs.getRelevantBlogs(searchQueryParam);
The output from this query is similar to the one for Technorati.
So far, we’ve demonstrated how two different blog-tracking providers, Technorati and Bloglines, can be integrated using their proprietary APIs. Most blog-tracking providers provide an RSS 2.0 XML response. Though this RSS response may not be as rich in content as a provider’s proprietary API, it can still be useful for integrating providers.
5.6. Integrating providers using RSS
In section 5.1.2, we briefly reviewed RSS and its history. Most providers support the RSS 2.0 format for responding to a search query. A typical RSS 2.0 XML response was shown in listing 5.1. The total number of results isn’t available in this XML response.
Adding a new provider consists of adding three new classes:
- An instance of the QueryParameter
- An instance of the BlogSearcher that implements getMethod()
- An instance of BlogSearchResponseHandler that handles the XML parsing
In this section, we develop each of these classes in a generic manner.
5.6.1. Generalizing the query parameters
Rather than creating a specific instance of these classes for each provider, let’s generalize the approach. Table 5.3 shows the URL used to query MSN and Blogdigger.
Table 5.3. Query URLs for some blog-tracking providers
|
Provider |
URL |
|---|---|
| MSN | http://search.msn.com/results.aspx?q=collective+intelligence&format=rss&first=1&count=2 |
| Blogdigger | http://www.blogdigger.com/rss.jsp?sortby=date&q=collective+intelligence&si=1&pp=2 |
You can decompose the query URL into five elements, as shown in table 5.4. These elements are
- URL— The provider URL for the query
- First element— The term used to specify the index of the first element
- Number items— The term used to specify the number of items
- Sort— The term used to specify the sort element
- Format type— The term used to specify the format used
Table 5.4. Decomposing the query parameters across providers
|
Provider |
URL |
First element |
Number items |
Sort |
Format type |
|---|---|---|---|---|---|
| MSN | http://search.msn.com/results.aspx | first | count | format | |
| Blogdigger | http://www.blogdigger.com/rss.jsp | si | pp | sortby |
RSSFeedBlogQueryParameterImpl, whose code is shown in listing 5.21, encapsulates the parameters shown in table 5.4.
Listing 5.21. RSSFeedBlogQueryParameterImpl

The enum RSSProviderURL has an enumerated type for each of the providers that specifies the values for the various parameters. Now we can use this to develop a generic instance of the blog searcher.
5.6.2. Generalizing the blog searcher
Most of the heavy lifting required to implement RSSFeedBlogQueryParameterImpl has already been done in the base class, as shown in listing 5.22.
Listing 5.22. RSSFeedBlogQueryParameterImpl

RSSFeedBlogQueryParameterImpl needs to implement the abstract method get-Method(). This method uses the parameters specified in RSSFeedBlogQueryParameterImpl to create the appropriate query URL.
The last thing we need to implement is the handler to parse the XML, which is in RSS 2.0 format.
5.6.3. Building the RSS 2.0 XML parser
Listing 5.23 shows the implementation for RSSFeedResponseHandler, which is the handle for parsing the RSS 2.0 XML response.
Listing 5.23. RSSFeedResponseHandler

There are six tokens that are handled:
ITEM("item"), TITLE("title"), AUTHOR("author"), LINK("link"),
DESCRIPTION("description"), PUBDATE("pubDate");
Appropriate elements of the items are also set.
A typical result using the RSS feed is shown in listing 5.24. Note that the total number of blog entries isn’t returned.
Listing 5.24. Output from Blogdigger query for “collective intelligence”

The code was generated using the test shown in listing 5.25, which is similar to listing 5.17.
Listing 5.25. Output from Blogdigger query for “collective intelligence”

You can add other providers by decomposing the query URL into the five parameters specified in table 5.4 and adding an enum value to RSSFeedBlogQueryParameterImpl.RSSProviderURL.
In this section, we’ve shown how blog-tracking providers can be added using RSS. The approach is generic and can be extended to add other blog-tracking providers. Once you have the URL to the blog, you can download the text of the blog entry, analyze it to generate its term vector, and compute its similarity to items of interest.
5.7. Summary
It’s helpful to search the blogosphere to obtain relevant information and to monitor what’s being said about your product and application. There are a number of blog-tracking providers, companies that track what’s being said in the blogosphere. RSS is an XML specification that’s widely used for content changes. Most blog-tracking providers provide an RSS-based API to query.
In this chapter, we’ve developed a generic framework for searching the blogosphere by integrating blog-tracking providers. Searching the blogosphere involves four steps: creating the search query, sending it to a blog-tracking provider in a format the provider can understand, parsing the response from the provider, and lastly, converting it to a standard result format. We’ve demonstrated this process by adding four providers, two using proprietary APIs and the rest using RSS.
In the next chapter, we continue with our theme of collecting relevant information from outside your application by looking at web crawling.
5.8. Resources
Apache commons.feedparser. http://jakarta.apache.org/commons/sandbox/feedparser/
“Argos.” https://argos.dev.java.net/
“Argos: Simple Java Search Engine Wrapper API.” techno.blog(“Dion”). April, 2005. http://almaer.com/blog/argos-simple-java-search-engine-wrapper-api
Atom. http://atomenabled.org/
Atom Publishing Format and Protocol (atompub). http://www.ietf.org/html.charters/atompub-charter.html
Blog Search Engine. http://www.blogsearchengine.com/
Blogdigger. http://www.blogdigger.com/rss.jsp
Blogger Data API. http://code.google.com/apis/blogger/gdata.html
Bloglines API Documentation. http://www.bloglines.com/services/api/
BlogPulse API FAQ. http://www.blogpulse.com/about.html#showcase_3
Brown, Larry, and Marty Hall. XML Processing with Java. 2002. Prentice Hill. http://www.phptr.com/articles/article.asp?p=26351&seqNum=4&rl=1
Caplan, Jeremy. “Searchlight for the Blogosphere.” Time. Dec. 3, 2006. http://www.time.com/time/globalbusiness/article/0,9171,1565540,00.html
DateFormat and SimpleDateFormat Examples. http://javatechniques.com/public/java/docs/basics/dateformat-examples.html
Dmoz open directory. http://dmoz.org/Computers/Internet/On_the_Web/Weblogs/Search_Engines/
Fagan Finder, Blogs and RSS Search Engines. http://www.faganfinder.com/blogs/
Full list of ping services to go. http://www.onlinemoneytip.com/blogging/rss-ping-list/
Google Blog Search. http://www.google.com/help/about_blogsearch.html
HttpClient Tutorial. http://jakarta.apache.org/commons/httpclient/tutorial.html
Icerocket.com. http://www.icerocket.com/
Jakarta Commons HttpClient. http://hc.apache.org/httpclient-3.x/
“Java API for XML Processing (JAXP) Sources.” Sun Microsystems Inc. https://jaxp-sources.dev.java.net/
Johnson, Dave. RSS and Atom in Action. 2006. Manning Publications.
MSN Live Search. http://search.msn.com/results.aspx
RSS, Wikipedia. http://en.wikipedia.org/wiki/RSS_%28file_format%29
RSS 2.0 Specification. RSS Advisory Board. http://www.rssboard.org/rss-specification
RSS 2.0 Specification. http://blogs.law.harvard.edu/tech/rss
RSS Tutorial for Content Publishers and Webmasters. http://www.mnot.net/rss/tutorial/
Sayer, Robert. “Atom: The Standard in Syndication.” IEEE Internet Computing, vol. 9, no. 2, 2005, pp. 71-75.
SAX API Javadoc. http://www.saxproject.org/apidoc/overview-summary.html
SimpleDateFormat. http://java.sun.com/j2se/1.4.2/docs/api/java/text/SimpleDateFormat.html
Tailrank. http://tailrank.com/code.php
Technorati API Documentation. http://www.technorati.com/developers/api/
“Time’s 50 Best Websites.”
Time. http://www.time.com/time/techtime/200406/news.html
UrlEncoder. http://java.sun.com/j2se/1.4.2/docs/api/java/net/URLEncoder.html
Winer, Dave. “RSS History.” April, 2004. http://blogs.law.harvard.edu/tech/rssVersionHistory
“Xerces2 Java Parser Readme.” Apache XML. http://xerces.apache.org/xerces2-j/