
Chapter 9. Discovering patterns with clustering
| This chapter covers |
|
It’s fascinating to analyze results found by machine learning algorithms. One of the most commonly used methods for discovering groups of related users or content is the process of clustering, which we discussed briefly in chapter 7. Clustering algorithms run in an automated manner and can create pockets or clusters of related items. Results from clustering can be leveraged to build classifiers, to build predictors, or in collaborative filtering. These unsupervised learning algorithms can provide insight into how your data is distributed.
In the last few chapters, we built a lot of infrastructure. It’s now time to have some fun and leverage this infrastructure to analyze some real-world data. In this chapter, we focus on understanding and applying some of the key clustering algorithms. K-means, hierarchical clustering, and expectation maximization (EM) are three of the most commonly used clustering algorithms.
As discussed in section 2.2.6, there are two main representations for data. The first is the low-dimension densely populated dataset; the second is the high-dimension sparsely populated dataset, which we use with text term vectors and to represent user click-through. In this chapter, we look at clustering techniques for both kinds of datasets.
We begin the chapter by creating a dataset that contains blog entries retrieved from Technorati.[1] Next, we implement the k-means clustering algorithm to cluster the blog entries. We leverage the infrastructure developed in chapter 5 to retrieve blog entries and combine it with the text-analysis toolkit we developed in chapter 8. We also demonstrate how another clustering algorithm, hierarchical clustering, can be applied to the same problem. We look at some of the other practical data, such as user clickstream analysis that can be analyzed in a similar manner. Next, we look at how WEKA can be leveraged for clustering densely populated datasets and illustrate the process using the EM algorithm. We end the chapter by looking at the clustering-related interfaces defined by JDM and develop code to cluster instances using the JDM APIs.
1 You can use any of the blog-tracking providers we discussed in chapter 5.
9.1. Clustering blog entries
In this section, we demonstrate the process of developing and applying various clustering algorithms by discovering groups of related blog entries from the blogosphere. This example will retrieve live blog entries from the blogosphere on the topic of “collective intelligence” and convert them to tag vector format, to which we apply different clustering algorithms.
Figure 9.1 illustrates the various steps involved in this example. These steps are
1. Using the APIs developed in chapter 5 to retrieve a number of current blog entries from Technorati.
2. Using the infrastructure developed in chapter 8 to convert the blog entries into a tag vector representation.
3. Developing a clustering algorithm to cluster the blog entries. Of course, we keep our infrastructure generic so that the clustering algorithms can be applied to any tag vector representation.
Figure 9.1. The various steps in our example of clustering blog entries

We begin by creating the dataset associated with the blog entries. The clustering algorithms implemented in WEKA are for finding clusters from a dense dataset. Therefore, we develop our own implementation for different clustering algorithms. We begin with implementing k-means clustering followed by hierarchical clustering algorithms.
It’s helpful to look at the set of classes that we need to build for our clustering infrastructure. We review these classes next.
9.1.1. Defining the text clustering infrastructure
The key interfaces associated with clustering are shown in figure 9.2. The classes consist of
- Clusterer: the main interface for discovering clusters. It consists of a number of clusters represented by TextCluster.
- TextCluster: represents a cluster. Each cluster has an associated TagMagnitudeVector for the center of the cluster and has a number of TextDataItem instances.
- TextDataItem: represents each text instance. A dataset consists of a number of TextDataItem instances and is created by the DataSetCreator.
- DataSetCreator: creates the dataset used for the learning process.
Figure 9.2. The interfaces associated with clustering text

Listing 9.1 contains the definition for the Clusterer interface.
Listing 9.1. The definition for the Clusterer interface
package com.alag.ci.cluster;
import java.util.List;
public interface Clusterer {
public List<TextCluster> cluster();
}
Clusterer has only one method to create the TextCluster instances:
List<TextCluster> cluster()
Listing 9.2 shows the definition of the TextCluster interface.
Listing 9.2. The definition for the TextCluster interface
package com.alag.ci.cluster;
import com.alag.ci.textanalysis.TagMagnitudeVector;
public interface TextCluster {
public void clearItems();
public TagMagnitudeVector getCenter();
public void computeCenter();
public int getClusterId() ;
public void addDataItem(TextDataItem item);
}
Each TextCluster has a unique ID associated with it. TextCluster has basic methods to add data items and to recompute its center based on the TextDataItem associated with it. The definition for the TextDataItem is shown in listing 9.3.
Listing 9.3. The definition for the TextDataItem interface
package com.alag.ci.cluster;
import com.alag.ci.textanalysis.TagMagnitudeVector;
public interface TextDataItem {
public Object getData();
public TagMagnitudeVector getTagMagnitudeVector() ;
public Integer getClusterId();
public void setClusterId(Integer clusterId);
}
Each TextDataItem consists of an underlying text data with its TagMagnitudeVector. It has basic methods to associate it with a cluster. These TextDataItem instances are created by the DataSetCreator as shown in listing 9.4.
Listing 9.4. The definition for the DataSetCreator interface
package com.alag.ci.cluster;
import java.util.List;
public interface DataSetCreator {
public List<TextDataItem> createLearningData() throws Exception ;
}
Each DataSetCreator creates a List of TextDataItem instances that’s used by the Clusterer. Next, we use the APIs we developed in chapter 5 to search the blogosphere. Let’s build the dataset that we use in our example.
9.1.2. Retrieving blog entries from Technorati
In this section, we define two classes. The first class, BlogAnalysisDataItem, represents a blog entry and implements the TextDataItem interface. The second class, BlogDataSetCreatorImpl, implements the DataSetCreator and creates the data for clustering using the retrieved blog entries.
Listing 9.5 shows the definition for BlogAnalysisDataItem. The class is basically a wrapper for a RetrievedBlogEntry and has an associated TagMagnitudeVector representation for its text.
Listing 9.5. The definition for the BlogAnalysisDataItem
package com.alag.ci.blog.cluster.impl;
import com.alag.ci.blog.search.RetrievedBlogEntry;
import com.alag.ci.cluster.TextDataItem;
import com.alag.ci.textanalysis.TagMagnitudeVector;
public class BlogAnalysisDataItem implements TextDataItem {
private RetrievedBlogEntry blogEntry = null;
private TagMagnitudeVector tagMagnitudeVector = null;
private Integer clusterId;
public BlogAnalysisDataItem(RetrievedBlogEntry blogEntry,
TagMagnitudeVector tagMagnitudeVector ) {
this.blogEntry = blogEntry;
this.tagMagnitudeVector = tagMagnitudeVector;
}
public Object getData() {
return this.getBlogEntry();
}
public RetrievedBlogEntry getBlogEntry() {
return blogEntry;
}
public TagMagnitudeVector getTagMagnitudeVector() {
return tagMagnitudeVector;
}
public double distance(TagMagnitudeVector other) {
return this.getTagMagnitudeVector().dotProduct(other);
}
public Integer getClusterId() {
return clusterId;
}
public void setClusterId(Integer clusterId) {
this.clusterId = clusterId;
}
}
Listing 9.6 shows the first part of the implementation for BlogDataSetCreatorImpl, which implements the DataSetCreator interface for blog entries.
Listing 9.6. Retrieving blog entries from Technorati

The BlogDataSetCreatorImpl uses the APIs developed in chapter 5 to retrieve blog entries from Technorati. It queries for recent blog entries that have been tagged with collective intelligence.
Listing 9.7 shows the how blog data retrieved from Technorati is converted into a List of TextDataItem objects.
Listing 9.7. Converting blog entries into a List of TextDataItem objects

The BlogDataSetCreatorImpl uses a simple implementation for estimating the frequencies associated with each of the tags:
InverseDocFreqEstimator freqEstimator = new InverseDocFreqEstimatorImpl(blogEntries.size());
The method composeTextForAnalysis() combines text from the title, name, author, and excerpt for analysis. It then uses a TextAnalyzer, which we developed in chapter 8, to create a TagMagnitudeVector representation for the text.
Listing 9.8 shows the implementation for the InverseDocFreqEstimatorImpl, which provides an estimate for the tag frequencies.
Listing 9.8. The implementation for InverseDocFreqEstimatorImpl

The inverse document frequency for a tag is estimated by computing the log of the total number of documents divided by the number of documents that the tag appears in:
Math.log(totalNumDocs/freq.doubleValue());
Note that the more rare a tag is, the higher its idf. With this background, we’re now ready to implement our first text clustering algorithm. For this we use the k-means clustering algorithm.
9.1.3. Implementing the k-means algorithms for text processing
The k-means clustering algorithm consists of the following steps:
1. For the specified number of k clusters, initialize the clusters at random. For this, we select a point from the learning dataset and assign it to a cluster. Further, we ensure that all clusters are initialized with different data points.
2. Associate each of the data items with the cluster that’s closest (most similar) to it. We use the dot product between the cluster and the data item to measure the closeness (similarity). The higher the dot product, the closer the two points.
3. Recompute the centers of the clusters using the data items associated with the cluster.
4. Continue steps 2 and 3 until there are no more changes in the association between data items and the clusters. Sometimes, some data items may oscillate between two clusters, causing the clustering algorithm to not converge. Therefore, it’s a good idea to also include a maximum number of iterations.
We develop the code for k-means in more or less the same order. Let’s first look at the implementation for representing a cluster. This is shown in listing 9.9.
Listing 9.9. The implementation for ClusterImpl

The center of the cluster is represented by a TagMagnitudeVector and is computed by adding the TagMagnitudeVector instances for the data items associated with the cluster.
Next, let’s look at listing 9.10, which contains the implementation for the k-means algorithm.
Listing 9.10. The core of the TextKMeansClustererImpl implementation

The dataset for clustering, along with the number of clusters, is specified in the constructor:
public TextKMeansClustererImpl(List<TextDataItem> textDataSet,
int numClusters)
As explained at the beginning of the section, the algorithm is fairly simple. First, the clusters are initialized at random:
this.intitializeClusters();
This is followed by reassigning the data items to the closest clusters:
reassignClusters()
and recomputing the centers of the cluster:
computeClusterCenters()
Listing 9.11 shows the code for initializing the clusters.
Listing 9.11. Initializing the clusters
private void intitializeClusters() {
this.clusters = new ArrayList<TextCluster>();
Map<Integer,Integer> usedIndexes = new HashMap<Integer,Integer>();
for (int i = 0; i < this.numClusters; i++ ) {
ClusterImpl cluster = new ClusterImpl(i);
cluster.setCenter(getDataItemAtRandom(usedIndexes).
getTagMagnitudeVector());
this.clusters.add(cluster);
}
}
private TextDataItem getDataItemAtRandom(
Map<Integer,Integer> usedIndexes) {
boolean found = false;
while (!found) {
int index = (int)Math.floor(
Math.random()*this.textDataSet.size());
if (!usedIndexes.containsKey(index)) {
usedIndexes.put(index, index);
return this.textDataSet.get(index);
}
}
return null;
}
For each of the k clusters to be initialized, a data point is selected at random. The algorithm keeps track of the points selected and ensures that the same point isn’t reselected. Listing 9.12 shows the remaining code associated with the algorithm.
Listing 9.12. Recomputing the clusters

The similarity between a cluster and a data item is computed by taking the dot product of the two TagMagnitudeVector instances:
double similarity = cluster.getCenter().dotProduct(item.getTagMagnitudeVector());
We use the following simple main program:
public static final void main(String [] args) throws Exception {
DataSetCreator bc = new BlogDataSetCreatorImpl();
List<TextDataItem> blogData = bc.createLearningData();
TextKMeansClustererImpl clusterer = new
TextKMeansClustererImpl(blogData,4);
clusterer.cluster();
}
The main program creates four clusters. Running this program yields different results, as the blog entries being created change dynamically, and different clustering runs with the same data can lead to different clusters depending on how the cluster nodes are initialized. Listing 9.13 shows a sample result from one of the clustering runs. Note that sometimes duplicate blog entries are returned from Technorati and that they fall in the same cluster.
Listing 9.13. Results from a clustering run
Id=0 Title=Viel um die Ohren Excerpt=Leider komme ich zur Zeit nicht so viel zum Bloggen, wie ich gerne würde, da ich mitten in 3 Projekt Title=Viel um die Ohren Excerpt=Leider komme ich zur Zeit nicht so viel zum Bloggen, wie ich gerne würde, da ich mitten in 3 Projekt Id=1 Title=Starchild Aug. 31: Choosing Simplicity & Creative Compassion..& Releasing "Addictions" to Suffering Excerpt=Choosing Simplicity and Creative Compassion...and Releasing "Addictions" to SufferingAn article and Title=Interesting read on web 2.0 and 3.0 Excerpt=I found these articles by Tim O'Reilly on web 2.0 and 3.0 today. Quite an interesting read and nice Id=2 Title=Corporate Social Networks Excerpt=Corporate Social Networks Filed under: Collaboration, Social-networking, collective intelligence, social-software—dorai @ 10:28 am Tags: applicatio Id=3 Title=SAP Gets Business Intelligence. What Do You Get? Excerpt=SAP Gets Business Intelligence. What Do You Get? [IMG] Posted by: Michael Goldberg in News Title=SAP Gets Business Intelligence. What Do You Get? Excerpt=SAP Gets Business Intelligence. What Do You Get? [IMG] Posted by: Michael Goldberg in News Title=Che Guevara, presente! Excerpt=Che Guevara, presente! Posted by Arroyoribera on October 7th, 2007 Forty years ago, the Argentine Title=Planet 2.0 meets the USA Excerpt= This has been a quiet blogging week due to FLACSO México's visit to the University of Minnesota. Th Title=collective intelligence excites execs Excerpt=collective intelligence excites execs zdnet.com's dion hinchcliffe provides a tremendous post cov
In this section, we looked at the implementation of the k-means clustering algorithm. K-means is one of the simplest clustering algorithms, and it gives good results.
In k-means clustering, we provide the number of clusters. There’s no theoretical solution to what is the optimal value for k. You normally try different values for k to see the effect on overall criteria, such as minimizing the overall distance between each point and its cluster mean. Let’s look at an alternative algorithm called hierarchical clustering.
9.1.4. Implementing hierarchical clustering algorithms for text processing
Hierarchical Agglomerative Clustering (HAC) algorithms begin by assigning a cluster to each item being clustered. Then they compute the similarity between the various clusters and create a new cluster by merging the two clusters that were most similar. This process of merging clusters continues until you’re left with only one cluster. This clustering algorithm is called agglomerative, since it continuously merges the clusters.
There are different versions of this algorithm based on how the similarity between two clusters is computed. The single-link method computes the distance between two clusters as the minimum distance between two points, one each of which is in each cluster. The complete-link method, on the other hand, computes the distance as the maximum of the similarities between a member of one cluster and any of the members in another cluster. The average-link method calculates the average similarity between points in the two clusters.
We demonstrate the implementation for the HAC algorithm by computing a mean for a cluster, which we do by adding the TagMagnitudeVector instances for the children. The similarity between two clusters is computed by using the dot product of the two centers.
To implement the hierarchical clustering algorithm, we need to implement four additional classes, as shown in figure 9.3. These classes are
- HierCluster: an interface for representing a hierarchical cluster
- HierClusterImpl: implements the cluster used for a hierarchical clustering algorithm
- HierDistance: an object used to represent the distance between two clusters
- HierarchialClusteringImpl: the implementation for the hierarchical clustering algorithm
Figure 9.3. The classes for implementing the hierarchical agglomerative clustering algorithm

The interface for HierCluster is shown in listing 9.14. Each instance of a HierCluster has two children clusters and a method for computing the similarity with another cluster.
Listing 9.14. The interface for HierCluster
package com.alag.ci.cluster.hiercluster;
import com.alag.ci.cluster.TextCluster;
public interface HierCluster extends TextCluster {
public HierCluster getChild1() ;
public HierCluster getChild2();
public double getSimilarity() ;
public double computeSimilarity(HierCluster o);
}
You can implement multiple variants of a hierarchical clustering algorithm by having different implementations of the computeSimilarity method. One such implementation is shown in listing 9.15, which shows the implementation for HierClusterImpl.
Listing 9.15. The implementation for HierClusterImpl

The implementation for HierClusterImpl is straightforward. Each instance of HierClusterImpl has two children and a similarity. The toString() and getBlogDetails() methods are added to display the cluster.
Next, let’s look at the implementation for the HierDistance class, which is shown in listing 9.16.
Listing 9.16. The implementation for HierDistance

We use an instance of HierDistance to represent the distance between two clusters. Note that the similarity between two clusters, A and B, is the same as the distance between cluster B and A—the similarity is order-independent. The following computation for the hashCode:
("" + c1.getClusterId()).hashCode() +
("" + c2.getClusterId()).hashCode();
ensures that two instances of HierDistance with the same two children are equivalent. containsCluster() is a utility method that will be used by the clustering algorithm to prune out links that are no longer valid.
Finally, we look at the first part of the HierarchialClusteringImpl algorithm, which is shown in listing 9.17. This part shows the implementation of the clustering algorithm in the cluster method.
Listing 9.17. The cluster method for HierarchialClusteringImpl

The clustering algorithm in HierarchialClusteringImpl is fairly simple. It first creates an initial list of clusters:
createInitialClusters();
Next it creates a new cluster from the list of available clusters. This process continues until you’re left with only one cluster:
while (allDistance.size() > 0) {
addNextCluster();
}
Let’s look at the method to create the initial set of clusters, contained in listing 9.18.
Listing 9.18. Creating the initial clusters in HierarchialClusteringImpl

Creating an initial set of clusters consists of two steps. First, we create a cluster for each data item:
createInitialSingleItemClusters();
Second, we compute the distances between each of the clusters using compute-InitialDistances(). These distances are stored in allDistances.
Next, let’s look at the code to add a new cluster to the initial set of clusters, shown in listing 9.19.
Listing 9.19. Merging the next cluster in HierarchialClusteringImpl

Adding a new cluster involves finding the HierDistance that has the highest similarity among all the distance measures. All the distances are sorted, and the best one is used for merging clusters:
Collections.sort(sortDist); HierDistance hd = sortDist.get(0);
The method pruneDistances() removes distances associated with the two clusters that have been merged, while the method addNewClusterDistances() adds the distances from the new cluster to all the other clusters that can be merged.
Listing 9.20 shows the code associated with printing the details from the hierarchical clustering algorithm.
Listing 9.20. Printing the results from HierarchialClusteringImpl
public String toString() {
StringWriter sb = new StringWriter();
sb.append("Num of clusters = " + this.idCount + "
");
sb.append(printClusterDetails(this.rootCluster,""));
return sb.toString();
}
private String printClusterDetails(
HierCluster cluster, String append) {
StringWriter sb = new StringWriter();
if (cluster != null) {
sb.append(cluster.toString());
String tab = " " + append;
if (cluster.getChild1() != null) {
sb.append("
" + tab + "C1=" +
printClusterDetails(cluster.getChild1(),tab));
}
if (cluster.getChild2() != null) {
sb.append("
" + tab + "C2="
+printClusterDetails(cluster.getChild2(),tab));
}
}
return sb.toString();
}
}
There’s nothing complicated in printing the details of the cluster that’s created. The code simply formats the results; an example is shown in listing 9.21. This listing shows the results from one of the clustering runs. Note that the titles of the blog entries are shown wherever we have a leaf cluster with a blog entry. Each cluster has a unique ID associated with it and there are a total of 10 clusters.
Listing 9.21. Sample output from hierarchical clustering applied to blog entries
Num of clusters = 19
Id=18 similarity=0.00325633040335101 C1=17 C2=9
C1=Id=17 similarity=0.02342920655844054 C1=16 C2=14
C1=Id=16 similarity=0.42247390457827866 C1=15 C2=13
C1=Id=15 similarity=0.04164026486125777 C1=10 C2=6
C1=Id=10 similarity=0.6283342717309606 C1=1 C2=0
C1=Id=1 Vote for Cool Software
C2=Id=0 Vote for Cool Software
C2=Id=6 Collective Intelligence Applied to the Patent
Process
C2=Id=13 similarity=0.8021265050360485 C1=12 C2=5
C1=Id=12 similarity=0.676456586660375 C1=11 C2=7
C1=Id=11 similarity=0.5542920709331453 C1=4 C2=8
C1=Id=4 Collective Intelligence Applied to the
Patent Process
C2=Id=8 Collective Intelligence Applied to the
Patent Process
C2=Id=7 Collective Intelligence Applied to the Patent Process
C2=Id=5 Collective Intelligence Applied to the Patent Process
C2=Id=14 similarity=0.0604642261218513 C1=2 C2=3
C1=Id=2 Wall Street meets social networking
C2=Id=3 10 Ways to Build More Collaborative Teams
C2=Id=9 Rencontres ICC'07 : on se voit là bas ?
This output was generated using the following code:
DataSetCreator bc = new BlogDataSetCreatorImpl();
List<TextDataItem> blogData = bc.createLearningData();
Clusterer clusterer = new HierarchialClusteringImpl(
blogData);
clusterer.cluster();
System.out.println(clusterer);
Hierarchical algorithms don’t scale well. If n is the number of items then the order of complexity is n2. Hierarchical algorithms, along with k-means, give good clustering results. Next, let’s look at the expectation maximization clustering algorithm.
9.1.5. Expectation maximization and other examples of clustering high-di- imension sparse data
An alternative approach to clustering is to use a model to fit the data. The clustering algorithm then tries to optimize the fit between the model and the data. Typically, for continuous attributes, the Gaussian distribution is used to model a variable. Each cluster has a mean and variance associated with it. Given another point, we can compute the probability of that point being a part of that distribution. This probability is a number between 0 and 1. The higher the probability, the higher the chance that the point belongs to the cluster.
The expectation maximization algorithm (EM) is a general-purpose framework for estimating a set of Gaussian distributions for modeling data. Unlike the k-means algorithm, the data points aren’t associated with a single cluster; the association is soft in that they’re associated with a cluster with a probability for each. Adapting the process to clustering, you can use the following clustering algorithms:
- Initialize the k clusters at random— Each cluster has a mean and variance.
- Expectation step— Compute the probability that a point belongs to the cluster.
- Maximization step— Maximize the parameters of the distribution to maximize the likelihood of the items.
The algorithm stops when the change in the likelihood of the objects after each iteration becomes small. In section 9.2, we apply the EM clustering algorithm using WEKA.
Analyzing the data corresponding to user click-through in a web application during a period of time leads to a high-dimension dataset, which is sparse. This is similar to the term vector representation for text. In this case, each document that a user can visit forms the terms, while the frequency count of visitation corresponds to the weight of the vector.
In chapter 3, we looked at user tagging. Analyzing the set of tags created by users leads to analysis similar to that done in this section. The tags created or visited by a user can be used to cluster similar users. Next, we look at clustering blog entries using WEKA.
9.2. Leveraging WEKA for clustering
Figure 7.13 in section 7.2.2 showed the classes associated with WEKA for clustering. In this section, we work through the same example of clustering blog data using the WEKA APIs.
You may recall that a dataset in WEKA is represented by the Instances class. Instances are composed of an Instance object, one for each data item. Attributes for the dataset are represented by the Attribute class. To apply the WEKA clustering algorithm, we do the following steps:
1. Convert the blog data from Technorati into an Instances representation.
2. Create an instance of the Clusterer and associate the learning data.
3. Evaluate the results of clustering.
It’s helpful to go through figure 9.4, which maps the classes that we will be using in this section.
Figure 9.4. The classes for implementing the hierarchical agglomerative clustering algorithm
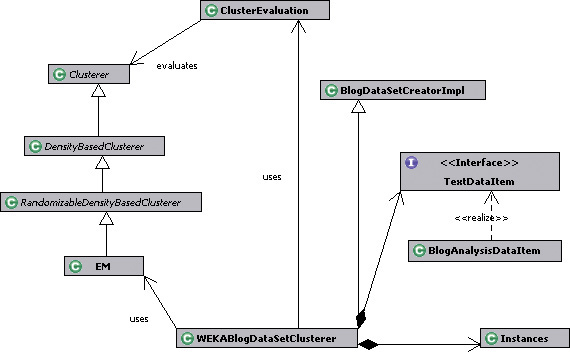
The class WEKABlogDataSetClusterer, which extends BlogDataSetCreatorImpl, is the main class that we develop in this section. It creates an instance of the dataset, of type Instances. It uses the EM class for applying the expectation maximization algorithm to the Instances class. The ClusterEvaluation class is used for evaluating the result from EM, which is an instance of the Clusterer class.
In this section, we first create the dataset for using the WEKA APIs. This will be followed by using the EM class to cluster the blog entries, and finally we evaluate the quality of the clustering model.
9.2.1. Creating the learning dataset
To create a learning dataset in WEKA, we first need to define attributes. We take a simple approach of treating each tag as an attribute. Clearly, representing text with tags leads to a high-dimensional dataset. Typically, based on your domain, you may have well over 100,000 tag instances. A common approach is to reduce the dimension space by pruning the number of tags associated with each document. In our example of classifying blog entries, for 10 blog instances, there were typically around 150 unique tags.
Listing 9.22 shows the first part of the WEKABlogDataSetClusterer class, which deals with creating an Instances dataset by retrieving live blog entries from Technorati. This class extends the BlogDataSetCreatorImpl class that we developed in the previous section.
Listing 9.22. The first part of WEKABlogDataSetClusterer

The method createLearningDataSet first gets the List of TextDataItem instances:
this.blogEntries = createLearningData();
Attribute instances are created by iterating over all the tag entries:
for (Tag tag : allTags) {
Attribute tagAttribute = new Attribute(tag.getDisplayText());
allAttributes.addElement(tagAttribute);
A new Instance is created by using the TagMagnitudeVector and iterating over all the tag instances. A tag attribute that isn’t present in the TagMagnitudeVector instance has a magnitude of 0.
It’s useful to look at listing 9.23, which shows a typical dump of the Instances class. The dump was created using the toString method for the Instances class.
Listing 9.23. An example dump of the Instances class
.............. //many more attributes @attribute zeit numeric @attribute choosing numeric @attribute da numeric @attribute um numeric @attribute sufferingan numeric @attribute gerne numeric @attribute articles numeric @attribute throu numeric @attribute years numeric @attribute advice numeric @attribute corporate numeric @data 0.159381,0.228023,0,0,0,0,0,0,0,0,0,0,0.159381,0.159381,0.159381,0.159381,0 ,0.159381,0,0,0,0.159381,0,0,0.159381,0,0,0,0,0,0.09074,0,0.09074,0,0.22802 3,0,0,0,0,0,0,0.159381,0,0,0,0,0,0,0.159381,0,0,0,0.159381,0,0.228023,0.228 023,0,0,0,0,0,0,0,0,0.228023,0.159381,0.228023,0,0,0,0,0,0.159381,0,0,0.159 381,0,0.228023,0.228023,0,0,0,0,0.09074,0,0,0,0,0,0,0,0.159381,0.09074,0,0, 0,0.159381,0,0,0.09074,0,0.159381,0,0,0,0.159381,0,0,0,0.159381,0,0.09074,0 ,0,0,0,0,0,0,0,0.228023,0,0,0 0.21483,0,0,0,0,0,0,0,0,0,0,0,0.21483,0.21483,0.21483,0.21483,0,0.21483,0,0 ,0,0.21483,0,0,0.21483,0,0,0,0,0,0.122308,0.21483,0,0,0,0,0,0,0,0,0,0,0,0,0 ,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0.21483,0,0,0,0,0.307353,0,0.21483 ,0,0,0.21483,0,0,0,0.21483,0.21483,0,0,0.122308,0,0,0,0,0,0,0,0,0.122308,0, 0,0,0.21483,0,0,0.122308,0,0.21483,0,0,0,0.21483,0,0,0,0.21483,0,0.122308,0 ,0,0,0,0,0,0,0,0,0,0,0 0,0,0,0,0,0,0,0,0,0,0,0.096607,0,0,0,0,0,0,0,0,0.18476,0,0,0.369519,0,0,0,0 ,0,0,0,0,0.073523,0.554279,0,0,0,0,0,0,0,0.129141,0.18476,0,0,0,0,0,0.12914 1,0,0,0.18476,0.387424,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0.18476,0,0, 0,0,0,0,0,0,0,0,0,0,0,0.18476,0,0,0,0.129141,0,0,0,0,0,0,0,0,0.18476,0,0,0, 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0.369519 ...................
The first part of the dump enumerates all the attributes. Each tag instance is a numeric attribute, which takes values between 0 and 1. The data associated with three blog entries is also shown in the listing. Note that the rows are sparsely populated with most of the values being zero.
9.2.2. Creating the clusterer
Now that we’ve created the dataset, let’s look at the second part of the implementation for WEKABlogDataSetClusterer, which corresponds to creating an instance of a Clusterer and clustering the dataset we just created. Listing 9.24 has the code.
Listing 9.24. The second part of WEKABlogDataSetClusterer

The clustering code is simple and consists of three steps. First, we create the learning dataset:
Instances instances = createLearningDataSet();
Next, using this Instances, we create an instance of the Clusterer. In our example, we use the expectation maximization (EM) algorithm. The class EM represents an instance of the EM algorithm. We use the no-argument constructor:
EM em = new EM();
Next, we set the parameters for the clusterer:
em.setNumClusters(-1); em.setMaxIterations(100);
When the number of clusters is set to -1, EM uses cross validation to select the number of clusters to be used. The algorithm splits the dataset into 10 instances. It assigns the number of clusters to be 1 and then performs tenfold cross validation. The log likelihood is computed for each of the 10 runs and averaged. If the log likelihood increases, then the number of clusters is increased by one and the whole process continues. The Clusterer instance clusters the dataset using the following code:
em.buildClusterer(instances);
Next, let’s look at how we can evaluate the results from clustering.
9.2.3. Evaluating the clustering results
To evaluate the results from clustering, we need to use a ClusterEvaluation instance. Listing 9.25 shows the third part of the code for WEKABlogDataSetClusterer, in which we evaluate the results from clustering.
Listing 9.25. The third part of WEKABlogDataSetClusterer

We first create an instance of ClusterEvaluation, associate it with the Clusterer instance, and then evaluate the clusterer:
ClusterEvaluation eval = new ClusterEvaluation(); eval.setClusterer(clusterer); eval.evaluateClusterer(instances);
Next, we get the association of each blog entry to a cluster instance:
double[] assignments = eval.getClusterAssignments();
Next, we use the assignments to create a list of retrieved blog entries with each of the clusters:
Map<Integer, List<RetrievedBlogEntry>>
associateInstancesWithClusters(double[] assignments)
Lastly, we print out the assignments using the method printClusterEntries. Listing 9.26 shows the results from one of the clustering runs. Note that similar posts are grouped together in the same cluster. In this instance there are four clusters.
Listing 9.26. Sample output from one of the clustering runs
.......... Clustered Instances 0 3 ( 30%) 1 2 ( 20%) 2 2 ( 20%) 3 3 ( 30%) Log likelihood: 222.25086 NumClusters=4 0.0 SAP Gets Business Intelligence. What Do You Get? [IMG] Posted by: Michael Goldberg in News SAP Gets Business Intelligence. What Do You Get? [IMG] Posted by: Michael Goldberg in News Che Guevara, presente! Posted by Arroyoribera on October 7th, 2007 Forty years ago, the Argentine 1.0 [IMG ] That's what Intel wants you to do with the launch of their new website called CoolSW. They ar [IMG ] That's what Intel wants you to do with the launch of their new website called CoolSW. They ar 2.0 We Are Smarter Than Me | Podcasts We are Smarter than Me is a great new site on collective intelli Corporate Social Networks Filed under: Collaboration, Social-networking, collective intelligence, so Choosing Simplicity and Creative Compassion...and Releasing "Addictions" to SufferingAn article and 3.0 ?[ruby][collective intelligence] "Collective Intelligence"??????ruby??????? [IMG Programming Collective Intelligence: Building Smart Web 2.0 Applicat ?[ruby][collective intelligence] "Collective Intelligence"????????????????? ? ????? del.icio.us ????
In this section, we’ve looked at applying the WEKA APIs for clustering instances. WEKA has a rich set of clustering algorithms, including SimpleKMeans, OPTICS (ordering points to identify clustering structures), EM, and DBScan.
As you must have noticed from this section, it’s fairly straightforward to apply clustering using the WEKA APIs. Lastly, before we end the chapter, let’s look at key interfaces related to clustering in the JDM APIs.
9.3. Clustering using the JDM APIs
The package javax.datamining.clustering contains interfaces for representing a clustering model, for algorithm settings associated with clustering, and for specifying the similarity matrix associated with clustering.
In this section, we briefly look at the key interfaces associated with clustering and look at code for creating a cluster using the JDM interfaces.
9.3.1. Key JDM clustering-related classes
As shown in figure 9.5, the results from a clustering run are represented by a ClusteringModel, which extends the Model interface. A ClusteringModel consists of a number of Cluster instances, which represent the metadata associated with a cluster. The Cluster interface has methods to return parent and children cluster instances (as with hierarchical clustering), statistics about the data associated with the cluster, rules associated with the cluster, and so on.
Figure 9.5. A ClusteringModel consists of a set of clusters obtained by analyzing the data.

For building a clustering model, there are two types of settings, as shown in figure 9.6. First are generic settings associated with the clustering process and represented by an instance of ClusteringSettings. Second are settings that are associated with a specific clustering algorithm. An example of such a setting is the KMeansSettings interface, which allows advanced users to specify the details of the k-means clustering algorithm.
Figure 9.6. Some of the classes associated with clustering algorithm settings and clustering settings

The interface BuildSettings has a method setAlgorithmSettings() for setting algorithm-specific settings. Let’s walk through some sample code that will make executing the clustering process through the JDM APIs clearer.
9.3.2. Clustering settings using the JDM APIs
In this section, we go through sample code to illustrate the clustering process using the JDM APIs. Our example has four steps:
1. Create the clustering settings object.
2. Create the clustering task.
3. Execute the clustering task.
4. Retrieve the clustering model.
Listing 9.27 shows the code associated with the example and the settings process.
Listing 9.27. Settings-related code for the clustering process

The example first creates an instance of ClusteringSettings and sets attributes associated with the clustering process. For this, it sets the maximum and the minimum number of clusters to be created:
clusteringSettings.setMaxNumberOfClusters(100); clusteringSettings.setMinClusterCaseCount(10);
Next, an instance of KMeansSettings is created to specify settings specific to the k-means algorithm. Here, the distance function is set to be Euclidean. The maximum number of iterations and the minimum error tolerance are also specified:
kmeansSettings.setDistanceFunction(ClusteringDistanceFunction.euclidean);
kmeansSettings.setMaxNumberOfIterations(100);
kmeansSettings.setMinErrorTolerance(0.001);
The algorithm settings are set in the ClusteringSettings instance:
clusteringSettings.setAlgorithmSettings(algorithmSettings);
Next, let’s look at creating the clustering task.
9.3.3. Creating the clustering task using the JDM APIs
To create an instance of the BuildTask for clustering we use the BuildTaskFactory as shown in Listing 9.28.
Listing 9.28. Creating the clustering task
private void createClusteringTask(Connection connection) throws
JDMException {
BuildTaskFactory buildTaskFactory = (BuildTaskFactory)
connection.getFactory("javax.datamining.task.BuildTaskFactory");
BuildTask buildTask =
buildTaskFactory.create("buildDataPhysicalDataSet",
"clusteringSettings", "clusteringModel");
connection.saveObject("clusteringBuildTask", buildTask, false);
}
The BuildTaskFactory creates an instance of the BuildTask. The create method to create a BuildTask needs the name of the dataset to be used, the name of the settings object, and the name of the model that is to be created. In our example, we will use the dataset “buildDataPhysicalDataSet”, use the setting specified in the object “clusteringSettings”, and the model that will be created from this run will be stored using the name “clusteringModel”.
9.3.4. Executing the clustering task using the JDM APIs
To execute a build task, we use the execute() method on the Connection object as shown in listing 9.29.
Listing 9.29. Executing the clustering task
private void executeClusteringTask(Connection connection)
throws JDMException {
ExecutionHandle executionHandle = connection.execute(
"clusteringBuildTask");
int timeoutInSeconds = 100;
ExecutionStatus executionStatus =
executionHandle.waitForCompletion(timeoutInSeconds);
executionStatus = executionHandle.getLatestStatus();
if (ExecutionState.success.equals(executionStatus.getState())) {
//successful state
}
}
The following code:
ExecutionStatus executionStatus = executionHandle.waitForCompletion(timeoutInSeconds);
waits for the clustering task to complete and specifies a timeout of 100 seconds. Once the task completes, it looks at execution status to see whether the task was successful.
Next, let’s look at how we can retrieve the clustering model that has been created.
9.3.5. Retrieving the clustering model using the JDM APIs
Listing 9.30 shows the code associated with retrieving a ClusteringModel using the name of the model and a Connection instance.
Listing 9.30. Retrieving the clustering model
private void retrieveClusteringModel(Connection connection)
throws JDMException {
ClusteringModel clusteringModel = (ClusteringModel)
connection.retrieveObject("clusteringModel",
NamedObject.model);
Collection<Cluster> clusters = clusteringModel.getClusters();
for (Cluster cluster: clusters) {
System.out.println(cluster.getClusterId() + " " +
cluster.getName());
}
}
}
Once a ClusteringModel is retrieved, we can get the set of Cluster instances and display information related to each of the clusters.
In this section, we’ve looked at the key interfaces associated with clustering and the JDM APIs. As you must have noticed from this chapter, using the JDM APIs to apply clustering is fairly straightforward. We’ve looked at some sample code associated with creating clustering settings, creating and executing a clustering task, and retrieving the clustering model.
9.4. Summary
Clustering is the automated process of analyzing data to discover groups of related items. Clustering the data can provide insight into the distribution of the data, and can then be used to connect items with other similar items, build predictive models, or build a recommendation engine.
Clustering text documents involves creating a term vector representation for the text. This representation typically yields a high dimension and is sparsely populated. Analyzing the clickstream for a set of users has a similar representation. Creating a dataset using the attributes of a set of items typically leads to a dense, low-dimension representation for the data.
K-means is perhaps the simplest clustering algorithm. For this algorithm, we specify the number of clusters for the data. The algorithm iteratively assigns each item to a cluster based on a similarity or a distance measure. The centers of the clusters are recomputed based on the instances assigned to them. In hierarchical clustering, the algorithm begins with assigning a cluster to each item. Next, a new cluster is created by combining two clusters that are most similar. This process continues until you’re left with only one cluster. The expectation maximization (EM) algorithm uses a probabilistic approach to cluster instances. Each item is associated with different clusters using a probabilistic distribution.
The WEKA package has a number of algorithms that can be used for clustering. The process of clustering consists of first creating an instance of Instances to represent the dataset, followed by an instance of a Clusterer, and using a ClusterEvaluation to evaluate the results.
The process of clustering using the JDM APIs involves creating a ClusterSettings instance, creating and executing a ClusteringTask, and retrieving the Clustering-Model that’s created.
Now that we have a good understanding of clustering, in the next chapter we’ll look at building predictive models.
9.5. Resources
Beil, Florian, Martin Ester, and Xiaowei Xu. “Frequent term-based text clustering.” Proceedings of the Eighth ACM SIGKDD international Conference on Knowledge Discovery and Data Mining. (Edmonton, Alberta, Canada, 2002). KDD ‘02. ACM, New York, NY. 436–442. DOI= http://doi.acm.org/10.1145/775047.775110
Böhm, Christian, Christos Faloutsos, Jia-Yu Pan, and Claudia Plant. “Robust information-theoretic clustering.” Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (Philadelphia, PA, 2006). KDD ‘06. ACM, New York, NY. 65–75. DOI= http://doi.acm.org/10.1145/1150402.1150414
“Tutorial: Clustering Large and High-Dimensional Data.” CIKM 2005. http://www.csee.umbc.edu/~nicholas/clustering/