
Chapter 12. Vulnerability and Risk Assessment
This chapter covers the following subjects:
![]() Conducting Risk Assessments: This section covers risk management and assessment. It discusses the differences between qualitative and quantitative risk and describes the methodologies of an important part of risk management—vulnerability management. Also covered are various ways to assess vulnerabilities and how to perform penetration tests.
Conducting Risk Assessments: This section covers risk management and assessment. It discusses the differences between qualitative and quantitative risk and describes the methodologies of an important part of risk management—vulnerability management. Also covered are various ways to assess vulnerabilities and how to perform penetration tests.
![]() Assessing Vulnerability with Security Tools: In this section, you learn how to use common network security tools to measure the vulnerability of your computer systems and network devices. These tools include network mappers, vulnerability scanners, protocol analyzers, packet sniffers, and password crackers.
Assessing Vulnerability with Security Tools: In this section, you learn how to use common network security tools to measure the vulnerability of your computer systems and network devices. These tools include network mappers, vulnerability scanners, protocol analyzers, packet sniffers, and password crackers.
Let’s take it to the next level and talk some serious security. As people, we’re all vulnerable to something. They say that you need to “manage your own healthcare”—our computers are no different. The potential health of your computers and network is based on vulnerabilities. One of the most important tasks of a security administrator is to find vulnerabilities and either remove them or secure them as much as possible—within acceptable parameters. Vulnerabilities are weaknesses in your computer network design and individual host configuration. Vulnerabilities, such as open ports, unnecessary services, weak passwords, systems that aren’t updated, lack of policy, and so on, are invitations to threats such as malicious attacks. Of course, your computer network can be vulnerable to other types of threats as well, such as environmental or natural threats, but these are covered in more depth in Chapter 16, “Redundancy and Disaster Recovery,” and Chapter 18, “Policies and Procedures.”
Vulnerability assessment is just part of overall risk management. Risk includes computer vulnerabilities, potential dangers, possible hardware and software failure, man hours wasted, and of course, monetary loss. Having a computer network is inherently a risky business, so we need to conduct risk assessments to define what an organization’s risks are and how to reduce those risks.
Foundation Topics
Conducting Risk Assessments
When dealing with computer security, a risk is the possibility of a malicious attack or other threat causing damage or downtime to a computer system. Generally, this is done by exploiting vulnerabilities in a computer system or network. The more vulnerability—the more risk. Smart organizations are extremely interested in managing vulnerabilities, and thereby managing risk. Risk management can be defined as the identification, assessment, and prioritization of risks, and the mitigating and monitoring of those risks. Specifically, when talking about computer hardware and software, risk management is also known as information assurance (IA). The two common models of IA include the well-known CIA triad (which we covered in Chapter 1, “Introduction to Security”), and the DoD “Five Pillars of IA,” which comprise the concepts of the CIA triad (confidentiality, integrity, and availability) but also include authentication and non-repudiation.
Organizations usually employ one of the four following general strategies when managing a particular risk:
![]() Transfer the risk to another organization or third party.
Transfer the risk to another organization or third party.
![]() Avoid the risk.
Avoid the risk.
![]() Reduce the risk.
Reduce the risk.
![]() Accept some or all of the consequences of a risk.
Accept some or all of the consequences of a risk.
It is possible to transfer some risk to a third party. An example of risk transference (also known as risk sharing) would be an organization that purchases insurance for a group of servers in a data center. The organization still takes on the risk of losing data in the case of server failure, theft, and disaster, but transfers the risk of losing the money those servers are worth in case they are lost.
Some organizations opt to avoid risk. Risk avoidance usually entails not carrying out a proposed plan because the risk factor is too great. An example of risk avoidance: If a high-profile organization decided not to implement a new and controversial website based on its belief that too many attackers would attempt to exploit it.
However, the most common goal of risk management is to reduce all risk to a level acceptable to the organization. It is impossible to eliminate all risk, but it should be mitigated as much as possible within reason. Usually, budgeting and IT resources dictate the level of risk reduction, and what kind of deterrents can be put in place. For example, installing antivirus/firewall software on every client computer is common; most companies do this. However, installing a high-end, hardware-based firewall at every computer is not common; although this method would probably make for a secure network, the amount of money and administration needed to implement that solution would make it unacceptable.
This leads to risk acceptance, also known as risk retention. Most organizations are willing to accept a certain amount of risk. Sometimes, vulnerabilities that would otherwise be mitigated by the implementation of expensive solutions are instead dealt with when and if they are exploited. IT budgeting and resource management are big factors when it comes to these risk management decisions.
After the risk transference, risk avoidance, and risk reduction techniques have been implemented, an organization is left with a certain amount of residual risk—the risk left over after a detailed security plan and disaster recovery plan have been implemented. There is always risk, as a company cannot possibly foresee every future event, nor can it secure against every single threat. Senior management as a collective whole is ultimately responsible for deciding how much residual risk there will be in a company’s infrastructure, and how much risk there will be to the company’s data. Often, no one person will be in charge of this, but it will be decided on as a group.
There are many different types of risks to computers and computer networks. Of course, before you can decide what to do about particular risks, you need to assess what those risks are.
Risk assessment is the attempt to determine the amount of threats or hazards that could possibly occur in a given amount of time to your computers and networks. When you assess risks, they are often recognized threats—but risk assessment can also take into account new types of threats that might occur. When risk has been assessed, it can be mitigated up until the point in which the organization will accept any additional risk. Generally, risk assessments follow a particular order, for example:
Step 1. Identify the organization’s assets.
Step 2. Identify vulnerabilities.
Step 3. Identify threats and threat likelihood.
Step 4. Identify potential monetary impact.
The fourth step is also known as impact assessment. This is when you determine the potential monetary costs related to a threat. See the section “Vulnerability Management” later in this chapter for more on information on Steps 2 and 3, including how to mitigate potential threats.
An excellent tool to create during your risk assessment is a risk register, also known as a risk log, which helps to track issues and address problems as they occur. After the initial risk assessment, a security administrator will continue to use and refer to the risk register. This can be a great tool for just about any organization but can be of more value to certain types of organizations, such as manufacturers that utilize a supply chain. In this case, the organization would want to implement a specialized type of risk management called supply chain risk management (SCRM). This is when the organization collaborates with suppliers and distributors to analyze and reduce risk.
The two most common risk assessment methods are qualitative and quantitative. Let’s discuss these now.
Qualitative Risk Assessment
Qualitative risk assessment is an assessment that assigns numeric values to the probability of a risk and the impact it can have on the system or network. Unlike its counterpart, quantitative risk assessment, it does not assign monetary values to assets or possible losses. It is the easier, quicker, and cheaper way to assess risk but cannot assign asset value or give a total for possible monetary loss.
With this method, ranges can be assigned, for example, 1 to 10 or 1 to 100. The higher the number, the higher the probability of risk, or the greater the impact on the system. As a basic example, a computer without antivirus software that is connected to the Internet will most likely have a high probability of risk; it will also most likely have a great impact on the system. We could assign the number 99 as the probability of risk. We are not sure exactly when it will happen but are 99% sure that it will happen at some point. Next, we could assign the number 90 out of 100 as the impact of the risk. This number implies a heavy impact; probably either the system has crashed or has been rendered unusable at some point. There is a 10% chance that the system will remain usable, but it is unlikely. Finally, we multiply the two numbers together to find out the qualitative risk: 99 × 90 = 8910. That’s 8910 out of a possible 10,000, which is a high level of risk. Risk mitigation is when a risk is reduced or eliminated altogether. The way to mitigate risk in this example would be to install antivirus software and verify that it is configured to auto-update. By assigning these types of qualitative values to various risks, we can make comparisons from one risk to another and get a better idea of what needs to be mitigated and what doesn’t.
The main issue with this type of risk assessment is that it is difficult to place an exact value on many types of risks. The type of qualitative system varies from organization to organization, even from person to person; it is a common source of debate as well. This makes qualitative risk assessments more descriptive than truly measurable. However, by relying on group surveys, company history, and personal experience, you can get a basic idea of the risk involved.
Quantitative Risk Assessment
Quantitative risk assessment measures risk by using exact monetary values. It attempts to give an expected yearly loss in dollars for any given risk. It also defines asset values to servers, routers, and other network equipment.
Three values are used when making quantitative risk calculations:
![]() Single loss expectancy (SLE): The loss of value in dollars based on a single incident.
Single loss expectancy (SLE): The loss of value in dollars based on a single incident.
![]() Annualized rate of occurrence (ARO): The number of times per year that the specific incident occurs.
Annualized rate of occurrence (ARO): The number of times per year that the specific incident occurs.
![]() Annualized loss expectancy (ALE): The total loss in dollars per year due to a specific incident. The incident might happen once or more than once; either way, this number is the total loss in dollars for that particular type of incident. It is computed with the following calculation:
Annualized loss expectancy (ALE): The total loss in dollars per year due to a specific incident. The incident might happen once or more than once; either way, this number is the total loss in dollars for that particular type of incident. It is computed with the following calculation:
SLE × ARO = ALE
So, for example, suppose we wanted to find out how much an e-commerce web server’s downtime would cost the company per year. We would need some additional information such as the average web server downtime in minutes and the number of times this occurs per year. We also would need to know the average sale amount in dollars and how many sales are made per minute on this e-commerce web server. This information can be deduced by using accounting reports and by further security analysis of the web server, which we discuss later. For now, let’s just say that over the past year our web server failed 7 times. The average downtime for each failure was 45 minutes. That equals a total of 315 minutes of downtime per year, close to 99.9% uptime. (The more years we can measure, the better our estimate will be.) Now let’s say that this web server processes an average of 10 orders per minute with average revenue of $35. That means that $350 of revenue comes in per minute. As we mentioned, a single downtime averages 45 minutes, corresponding to a $15,750 loss per occurrence. So, the SLE is $15,750. Ouch! Some salespeople are going to be unhappy with your 99.9% uptime! But we’re not done. We want to know the annualized loss expectancy (ALE). This can be calculated by multiplying the SLE ($15,750) by the annualized rate of occurrence (ARO). We said that the web server failed 7 times last year, so the SLE × ARO would be $15,750 × 7, which equals $110,250 (the ALE). This is shown in Table 12-1.
Table 12-1 Example of Quantitative Risk Assessment
| SLE | ARO | ALE |
| $15,750 | 7 | $110,250 |
| Revenue lost due to each web server failure | Total web server failures over the past year | Total loss due to web server failure per year |
Whoa! Apparently, we need to increase the uptime of our e-commerce web server! Many organizations demand 99.99% or even 99.999% uptime; 99.999% uptime means that the server will only have 5 minutes of downtime over the entire course of the year. Of course, to accomplish this we first need to scrutinize our server to see precisely why it fails so often. What exactly are the vulnerabilities of the web server? Which ones were exploited? Which threats exploited those vulnerabilities? By exploring the server’s logs, configurations, and policies, and by using security tools, we can discern exactly why this happens so often. However, this analysis should be done carefully because the server does so much business for the company. We continue this example and show the specific tools you can use in the section “Assessing Vulnerability with Security Tools.”
It isn’t possible to assign a specific ALE to incidents that will happen in the future, so new technologies should be monitored carefully. Any failures should be documented thoroughly. For example, a spreadsheet could be maintained that contains the various technologies your organization uses, their failure history, their SLE, ARO, and ALE, and mitigation techniques that you have employed, and when they were implemented.
Although it’s impossible to predict the future accurately, it can be quantified on an average basis using concepts such as mean time between failures (MTBF). This term deals with reliability. It defines the average number of failures per million hours of operation for a product in question. This is based on historical baselines among various customers that use the product. It can be very helpful when making quantitative assessments.
Note
Another way of describing MTBF is called failure in time (FIT), which is the number of failures per billion hours of operation.
There are two other terms you should know that are related to MTBF: mean time to repair (MTTR), which is the time needed to repair a failed device; and mean time to failure (MTTF), which is a basic measure of reliability for devices that cannot be repaired. All three of these concepts should also be considered when creating a disaster recovery (DR) plan, which we will discuss more in Chapter 16.
So, we can’t specifically foretell the future, but by using qualitative and quantitative risk assessment methods we can get a feel for what is likely to happen (more so with the latter option), and prepare accordingly. Table 12-2 summarizes the risk assessment types discussed in this chapter.
Table 12-2 Summary of Risk Assessment Types
| Risk Assessment Type | Description | Key Points |
| Qualitative risk assessment | Assigns numeric values to the probability of a risk, and the impact it can have on the system or network. | Numbers are arbitrary. Examples: 1–10 or 1–100. |
| Quantitative risk assessment | Measures risk by using exact monetary values. It attempts to give an expected yearly loss in dollars for any given risk. | Values are specific monetary amounts. SLE × ARO = ALE MTBF can be used for additional data. |
Note
Most organizations within the medical, pharmaceutical, and banking industries make use of quantitative risk assessments—they need to have specific monetary numbers to measure risk. Taking this one step further, many banking institutions adhere to the recommendations within the Basel I, II, and III accords. These recommended standards describe how much capital a bank should put aside to aid with financial and operational risks if they occur.
Security Analysis Methodologies
To assess risk properly, we must analyze the security of our computers, servers, and network devices. But before making an analysis, the computer, server, or other device should be backed up accordingly. This might require a backup of files, a complete image backup, or a backup of firmware. It all depends on the device in question. When this is done, an analysis can be made. Hosts should be analyzed to discern whether a firewall is in place, what type of configuration is used (or worse if the device is using a default configuration), what anti-malware software is installed, if any, and what updates have been made. A list of vulnerabilities should be developed, and a security person should watch for threats that could exploit these vulnerabilities; they might occur naturally, might be perpetuated by malicious persons using a variety of attack and threat vectors, or might be due to user error.
Security analysis can be done in one of two ways: actively or passively.
Active security analysis is when actual hands-on tests are run on the system in question. These tests might require a device to be taken off the network for a short time, or might cause a loss in productivity. Active scanning is used to find out if ports are open on a specific device, or to find out what IP addresses are in use on the network. A backup of the systems to be analyzed should be accomplished before the scan takes place. Active scanning (also known as intrusive scanning) can be detrimental to systems or the entire network, especially if you are dealing with a mission-critical network that requires close to 100% uptime. In some cases, you can pull systems off the network or run your test during off-hours. But in other cases, you must rely on passive security analysis.
Passive security analysis is when servers, devices, and networks are not affected by your analyses, scans, and other tests. It could be as simple as using documentation only to test the security of a system. For example, if an organization’s network documentation shows computers, switches, servers, and routers, but no firewall, you have found a vulnerability to the network (a rather large one). Passive security analysis might be required in real-time, mission-critical networks or if you are conducting computer forensics analysis, but even if you are performing a passive security analysis, a backup of the system is normal procedure. Passive security analysis is also known as non-intrusive or non-invasive analysis.
One example of the difference between active and passive is fingerprinting, which is when a security person (or attacker) scans hosts to find out what ports are open, ultimately helping the person to distinguish the operating system used by the computer. It is also known as OS fingerprinting or TCP/IP fingerprinting. Active fingerprinting is when a direct connection is made to the computer starting with ICMP requests. This type of test could cause the system to respond slowly to other requests from legitimate computers. Passive fingerprinting is when the scanning host sniffs the network by chance, classifying hosts as the scanning host observes its traffic on the occasion that it occurs. This method is less common in port scanners but can help to reduce stress on the system being scanned.
Security analysis can also be categorized as either passive reconnaissance or active reconnaissance. If an attacker or white hat is performing passive reconnaissance, that person is attempting to gain information about a target system without engaging the system. For example, a basic port scan of a system, without any further action, can be considered passive reconnaissance. However, if the attacker or white hat then uses that information to exploit vulnerabilities associated with those ports, then it is known as active reconnaissance, and is a method used when performing penetration tests. (We’ll further discuss penetration testing later in this chapter.)
Security Controls
Before we get into managing vulnerabilities, I’d like to revisit the concept of security controls. In Chapter 1 we discussed three basic security controls that are often used to develop a security plan: physical, technical, and administrative. However, there are additional categorical controls as described by the NIST. In short, the three can be described as the following:
![]() Management controls: These are techniques and concerns addressed by an organization’s management (managers and executives). Generally, these controls focus on decisions and the management of risk. They also concentrate on procedures, policies, legal and regulatory, the software development life cycle (SDLC), the computer security life cycle, information assurance, and vulnerability management/scanning. In short, these controls focus on how the security of your data and systems is managed.
Management controls: These are techniques and concerns addressed by an organization’s management (managers and executives). Generally, these controls focus on decisions and the management of risk. They also concentrate on procedures, policies, legal and regulatory, the software development life cycle (SDLC), the computer security life cycle, information assurance, and vulnerability management/scanning. In short, these controls focus on how the security of your data and systems is managed.
![]() Operational controls: These are the controls executed by people. They are designed to increase individual and group system security. They include user awareness and training, fault tolerance and disaster recovery plans, incident handling, computer support, baseline configuration development, and environmental security. The people who carry out the specific requirements of these controls must have technical expertise and understand how to implement what management desires of them.
Operational controls: These are the controls executed by people. They are designed to increase individual and group system security. They include user awareness and training, fault tolerance and disaster recovery plans, incident handling, computer support, baseline configuration development, and environmental security. The people who carry out the specific requirements of these controls must have technical expertise and understand how to implement what management desires of them.
![]() Technical controls: These are the logical controls executed by the computer system. Technical controls include authentication, access control, auditing, and cryptography. The configuration and workings of firewalls, session locks, RADIUS servers, or RAID 5 arrays would be within this category, as well as concepts such as least privilege implementation.
Technical controls: These are the logical controls executed by the computer system. Technical controls include authentication, access control, auditing, and cryptography. The configuration and workings of firewalls, session locks, RADIUS servers, or RAID 5 arrays would be within this category, as well as concepts such as least privilege implementation.
Once again, the previous controls are categorical. For the Security+ exam you should focus on these definitive security controls:
![]() Preventive controls: These controls are employed before the event and are designed to prevent an incident. Examples include biometric systems designed to keep unauthorized persons out, NIPSs to prevent malicious activity, and RAID 1 to prevent loss of data. These are also sometimes referred to as deterrent controls.
Preventive controls: These controls are employed before the event and are designed to prevent an incident. Examples include biometric systems designed to keep unauthorized persons out, NIPSs to prevent malicious activity, and RAID 1 to prevent loss of data. These are also sometimes referred to as deterrent controls.
![]() Detective controls: These controls are used during an event and can find out whether malicious activity is occurring or has occurred. Examples include CCTV/video surveillance, alarms, NIDSs, and auditing.
Detective controls: These controls are used during an event and can find out whether malicious activity is occurring or has occurred. Examples include CCTV/video surveillance, alarms, NIDSs, and auditing.
![]() Corrective controls: These controls are used after an event. They limit the extent of damage and help the company recover from damage quickly. Tape backup, hot sites, and other fault tolerance and disaster recovery methods are also included here. These are sometimes referred to as compensating controls.
Corrective controls: These controls are used after an event. They limit the extent of damage and help the company recover from damage quickly. Tape backup, hot sites, and other fault tolerance and disaster recovery methods are also included here. These are sometimes referred to as compensating controls.
Compensating controls, also known as alternative controls, are mechanisms put in place to satisfy security requirements that are either impractical or too difficult to implement. For example, instead of using expensive hardware-based encryption modules, an organization might opt to use network access control (NAC), data loss prevention (DLP), and other security methods. Or, on the personnel side, instead of implementing segregation of duties, an organization might opt to do additional logging and auditing. (See Chapter 18 for more information on segregation of duties.) Approach compensating controls with great caution. They do not give the same level of security as their replaced counterparts.
And, of course, many security concepts can be placed in the category of physical as well as other categories listed previously. For example, a locking door would be an example of a physical control as well as a preventive control.
When you see technologies, policies, and procedures in the future, attempt to place them within their proper control category. Semantics will vary from one organization to the next, but as long as you can categorize security features in a general fashion such as the ones previously listed, you should be able to define and understand just about any organization’s security controls.
Vulnerability Management
Vulnerability management is the practice of finding and mitigating software vulnerabilities in computers and networks. It consists of analyzing network documentation, testing computers and networks with a variety of security tools, mitigating vulnerabilities, and periodically monitoring for effects and changes. Vulnerability management can be broken down into five steps:
Step 1. Define the desired state of security: An organization might have written policies defining the desired state of security, or you as the security administrator might have to create those policies. These policies include access control rules, device configurations, network configurations, network documentation, and so on.
Step 2. Create baselines: After the desired state of security is defined, baselines should be taken to assess the current security state of computers, servers, network devices, and the network in general. These baselines are known as vulnerability assessments. The baselines should find as many vulnerabilities as possible utilizing vulnerability scans and other scanning and auditing methods. These baselines will be known as premitigation baselines and should be saved for later comparison.
Step 3. Prioritize vulnerabilities: Which vulnerabilities should take precedence? For example, the e-commerce web server we talked about earlier should definitely have a higher priority than a single client computer that does not have antivirus software installed. Prioritize all the vulnerabilities; this creates a list of items that need to be mitigated in order.
Step 4. Mitigate vulnerabilities: Go through the prioritized list and mitigate as many of the vulnerabilities as possible. This depends on the level of acceptable risk your organization allows. Mitigation techniques might include secure code review, and a review of system and application architecture and system design.
Step 5. Monitor the environment: When you finish mitigation, monitor the environment and compare the results to the original baseline. Use the new results as the post-mitigation baseline to be compared against future analyses. (Consider tools that can perform automated baseline reporting.) Because new vulnerabilities are always being discovered, and because company policies may change over time, you should periodically monitor the environment and compare your results to the post-mitigation baseline. Do this anytime policies change or the environment changes. Be careful to monitor for false positives—when a test reports a vulnerability as present when in fact there is none—they can be real time-wasters. If possible, use templates, scripts, and built-in system functionality to automate your monitoring efforts and employ continuous monitoring and configuration validation. All of these things will help to reduce risk.
This five-step process has helped me when managing vulnerabilities for customers. It should be noted again that some organizations already have a defined policy for their desired security level. You might come into a company as an employee or consultant who needs to work within the company’s existing mindset. In other cases, an organization won’t have a policy defined; it might not even know what type of security it needs. Just don’t jump the gun and assume that you need to complete Step 1 from scratch.
The most important parts of vulnerability management are the finding and mitigating of vulnerabilities. Actual tools used to conduct vulnerability assessments include network mappers, port scanners, and other vulnerability scanners, ping scanners, protocol analyzers (also called network sniffers), and password crackers. Vulnerability assessments might discover confidential data or sensitive data that is not properly protected, open ports, weak passwords, default configurations, prior attacks, system failures, and so on. Vulnerability assessments or vulnerability scanning can be taken to the next level by administering a penetration test.
Penetration Testing
Penetration testing is a method of evaluating the security of a system by simulating one or more attacks on that system. One of the differences between regular vulnerability scanning and penetration testing is that vulnerability scanning may be passive or active, whereas penetration testing will be active. Generally, vulnerability scans will not exploit found threats, but penetration testing will definitely exploit those threats. Another difference is that vulnerability scanning will seek out all vulnerabilities and weaknesses within an organization. But penetration tests are designed to determine the impact of a particular threat against an organization. For each individual threat, a different penetration test will be planned.
A penetration test—pen test for short—can be done blind, as in black-box testing, where the tester has little or no knowledge of the computer, infrastructure, or environment that is being tested. This simulates an attack from a person who is unfamiliar with the system. White-box testing is the converse, where the tester is provided with complete knowledge of the computer, user credentials, infrastructure, or environment to be tested. And gray-box testing is when the tester is given limited inside knowledge of the system or network. Generally, penetration testing is performed on servers or network devices that face the Internet publicly. This would be an example of external security testing—when a test is conducted from outside the organization’s security perimeter.
One common pen test technique is the pivot. Once an attacker or tester has gained access to a system with an initial exploit, the pivot allows for movement to other systems in the network. Pivoting might occur through the same exploit used to compromise the first system; a second exploit; or information discovered when accessing a previous system—also known as pillaging. Pivoting can be prevented through the use of host-based IDS and IPS, secure coding, network-based solutions such as unified threat management (UTM), and, of course, good solid network and system planning.
Another technique is that of persistence. As the name implies, an attacker/tester will attempt to reconnect at a later date using a backdoor, privilege escalation, and cryptographic keys. Whatever the method, it would have to endure reboots of the target system. Consider developing systems that are non-persistent by using a master image, and then utilizing snapshots, reverting to known states, rolling back to known good configurations, and using live boot media.
Another exploit is the race condition. This is a difficult exploit to perform because it takes advantage of the small window of time between when a service is used and its corresponding security control is executed in an application or OS, or when temporary files are created. It can be defined as anomalous behavior due to a dependence on timing of events. Race conditions are also known as time-of-check (TOC) or time-of-use (TOU) attacks. Imagine that you are tasked with changing the permissions to a folder, or changing the rights in an ACL. If you remove all of the permissions and apply new permissions, then there will be a short period of time where the resource (and system) might be vulnerable. This depends on the system used, how it defaults, and how well you have planned your security architecture. That was a basic example, but the race condition is more common within the programming of an application. This exploit can be prevented by proper secure coding of applications, and planning of the system and network architecture.
Following are a couple methodologies for accomplishing penetration testing:
![]() The Open Source Security Testing Methodology Manual (OSSTMM): This manual and corresponding methodology define the proper way to conduct security testing. It adheres to the scientific method. The manual is freely obtained from ISECOM.
The Open Source Security Testing Methodology Manual (OSSTMM): This manual and corresponding methodology define the proper way to conduct security testing. It adheres to the scientific method. The manual is freely obtained from ISECOM.
![]() NIST penetration testing: This is discussed in the document SP800-115. This document and methodology is less thorough than the OSSTMM; however, many organizations find it satisfactory because it comes from a department of the U.S. government. At times, it refers to the OSSTMM instead of going into more detail.
NIST penetration testing: This is discussed in the document SP800-115. This document and methodology is less thorough than the OSSTMM; however, many organizations find it satisfactory because it comes from a department of the U.S. government. At times, it refers to the OSSTMM instead of going into more detail.
Note
Penetration testing can become even more intrusive (active) when it is associated with DLL injection testing. This is when dynamic link libraries are forced to run within currently used memory space, influencing the behavior of programs in a way the creator did not intend or anticipate.
OVAL
The Open Vulnerability and Assessment Language (OVAL) is a standard designed to regulate the transfer of secure public information across networks and the Internet utilizing any security tools and services available at the time. It is an international standard but is funded by the U.S. Department of Homeland Security. A worldwide OVAL community contributes to the standard, storing OVAL content in several locations, such as the MITRE Corporation (http://oval.mitre.org/). OVAL can be defined in two parts: the OVAL Language and the OVAL Interpreter.
![]() OVAL Language: Three different XML schemas have been developed that act as the framework of OVAL:
OVAL Language: Three different XML schemas have been developed that act as the framework of OVAL:
1. System testing information
2. System state analysis
3. Assessment results reporting
OVAL is not a language like C++ but is an XML schema that defines and describes the XML documents to be created for use with OVAL.
![]() OVAL Interpreter: A reference developed to ensure that the correct syntax is used by comparing it to OVAL schemas and definitions. Several downloads are associated with the OVAL Interpreter and help files and forums that enable security people to check their work for accuracy.
OVAL Interpreter: A reference developed to ensure that the correct syntax is used by comparing it to OVAL schemas and definitions. Several downloads are associated with the OVAL Interpreter and help files and forums that enable security people to check their work for accuracy.
OVAL has several uses, one of which is as a tool to standardize security advisory distributions. Software vendors need to publish vulnerabilities in a standard, machine-readable format. By including an authoring tool, definitions repository, and definition evaluator, OVAL enables users to regulate their security advisories. Other uses for OVAL include vulnerability assessment, patch management, auditing, threat indicators, and so on.
Some of the entities that use OVAL include Hewlett-Packard, Red Hat Inc., CA Inc., and the U.S. Army CERDEC (Communications-Electronics Research, Development and Engineering Center).
Additional Vulnerabilities
Table 12-3 shows a list of general vulnerabilities that you should watch for and basic prevention methods. We’ll discuss some of the security tools that you can use to assess vulnerabilities and prevent exploits in the following section.
Table 12-3 General Vulnerabilities and Basic Prevention Methods
| Vulnerability | Prevention Methods |
| Improper input handling Improper error handling Memory vulnerabilities |
Secure coding, SDLC (see Chapter 5) |
| Default configuration Design weaknesses Resource exhaustion Improperly configured accounts |
Harden systems (see Chapter 4) Proper network design (see Chapter 6) Properly configure and audit permissions (see Chapter 11) |
| System sprawl End-of-life systems Vulnerable business processes |
Proper network auditing (see Chapter 6 and Chapter 13) SDLC (see Chapter 5) Implement secure policies (Chapter 18) |
| Weak ciphers Improper certificates |
Upgrade encryption (see Chapter 14 and Chapter 9) Review certificates, use a CRL (see Chapter 15) |
| New threats Zero-day attacks |
Keep abreast of latest CVEs and CWEs (see Chapter 6 and Chapter 5) Plan for unknowns (see Chapter 7) |
| Untrained users | Educate users about social engineering methods (see Chapter 17) Educate users about malware and attacks (see Chapter 2 and Chapter 7) |
Assessing Vulnerability with Security Tools
Until now, we have talked about processes, methodologies, and concepts. But without actual security tools, testing, analyzing, and assessing cannot be accomplished. This section delves into the security assessment tools you might use in the field today, and shows how to interpret the results that you receive from those tools.
Computers and networks are naturally vulnerable. Whether it is an operating system or an appliance installed out-of-the-box, they are inherently insecure. Vulnerabilities could come in the form of backdoors or open ports. They could also be caused after installation due to poor design.
To understand what can be affected, security administrators should possess thorough computer and network documentation, and if they don’t already, they should develop it themselves. Tools such as Microsoft Visio and network mapping tools can help to create proper network documentation. Then, tools such as vulnerability scanners, protocol analyzers, and password crackers should be used to assess the level of vulnerability on a computer network. When vulnerabilities are found, they should be eliminated or reduced as much as possible. Finally, scanning tools should be used again to prove that the vulnerabilities to the computer network have been removed.
You will find that most of the tools described in this section are used by security administrators and hackers alike. The former group uses the tools to find vulnerabilities and mitigate risk. The latter group uses the tools to exploit those vulnerabilities. However, remember that not all hackers are malevolent. Some are just curious, but they can cause just as much damage and downtime as a malicious hacker.
Network Mapping
Network documentation is an important part of defining the desired state of security. To develop adequate detailed network documentation, network mapping software should be used with network diagramming software. Network mapping is the study of physical and logical connectivity of networks. One example of automated network mapping software is the Network Topology Mapper by SolarWinds. This product can map elements on layers 1 through 3 of the OSI model, giving you a thorough representation of what is on the network. This type of network scan is not for the “weak of bandwidth.” It should be attempted only during off-hours (if there is such a thing nowadays), if possible; otherwise, when the network is at its lowest point of usage. Most network mapping programs show routers, layer 3 switches, client computers, servers, and virtual machines. You can usually export the mapped contents directly to Microsoft Visio, a handy time-saver.
Plenty of other free and pay versions of network mapping software are available. A quick Internet search displays a list. Try out different programs, get to know them, and decide what works best for your infrastructure.
Wireless networks can be surveyed in a similar fashion. Applications such as Air-Magnet can map out the wireless clients on your network, and apps such as NetStumbler can locate the available WAPs. Both can output the information as you want to aid in your network documentation efforts.
When you are working on your network documentation, certain areas of the network probably need to be filled in manually. Some devices are tough to scan, and you have to rely on your eyes and other network administrators’ knowledge to get a clear picture of the network. Network documentation can be written out or developed with a network diagramming program, such as Microsoft Visio. (A free trial is available at Microsoft’s Office website.) Visio can make all kinds of diagrams and flowcharts that can be real time-savers and helpful planning tools for network administrators and security people. An example of a network diagram is shown in Figure 12-1. This network diagram was created by mapping a now-defunct network with network mapping software, exporting those results to Visio, and then making some tweaks to the diagram manually. Names and IP addresses (among other things) were changed to protect the innocent. This documentation helped to discover a few weaknesses such as the lack of firewalling and other DMZ issues such as the lack of CIDR notation on the DMZ IP network. Just the act of documenting revealed some other issues with some of the servers on the DMZ, making it much easier to mitigate risk. When the risks were mitigated, the resulting final network documentation acted as a foundation for later security analysis and comparison to future baselines.
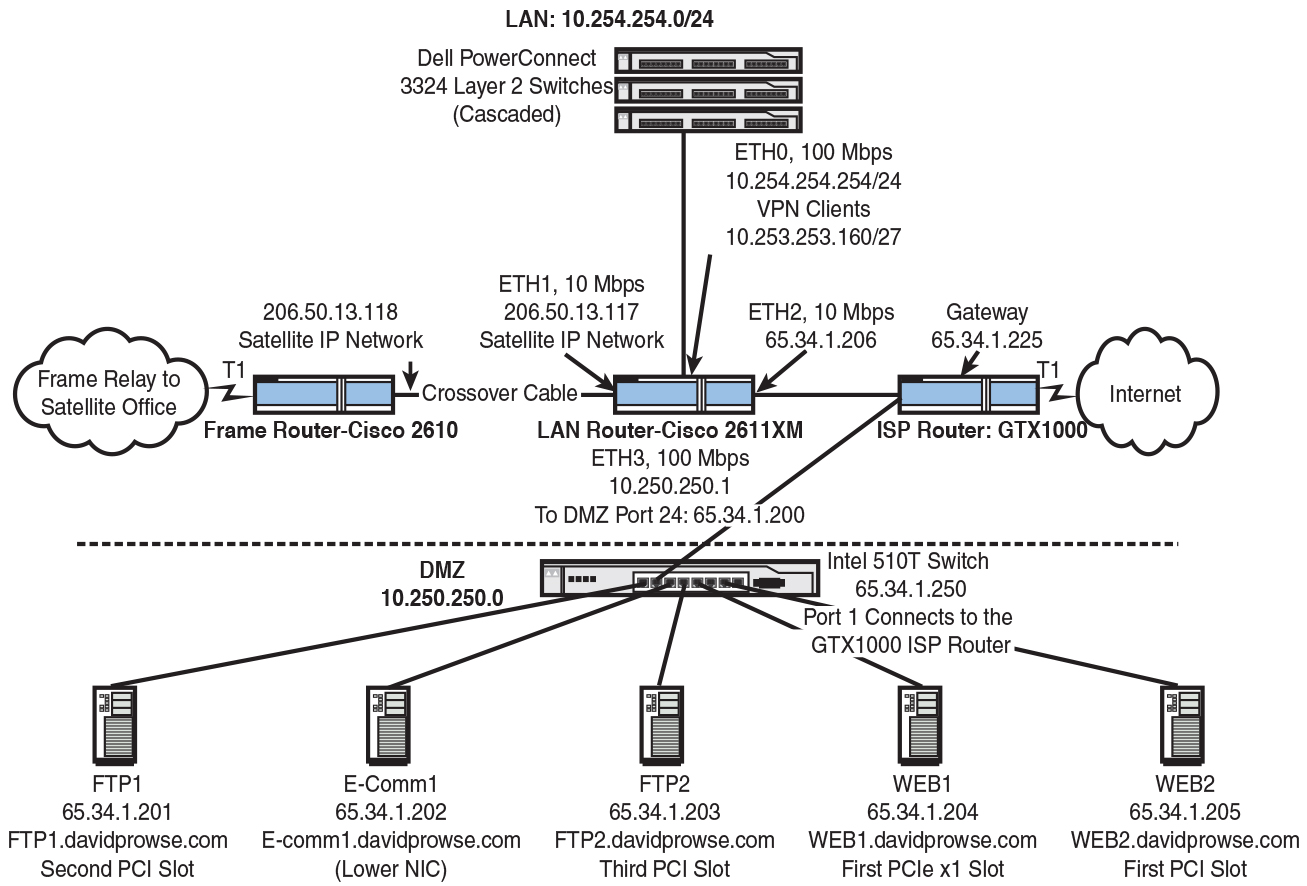
At times, you might be tempted to put passwords into a network diagram—don’t do it! If there are too many passwords to memorize, and you need to keep passwords stored somewhere, the best way is to write them on a piece of paper and lock that paper in a fireproof, non-removable safe, perhaps offsite. The people (admins) who know the combination to the safe should be limited. Don’t keep passwords on any computers!
You might also want to keep a list of IP addresses, computer names, and so on. This can be done on paper, within Excel or Access, or can be developed within your network mapping program and exported as you want. I find that Excel works great because I can sort different categories by the column header.
To summarize, network mapping can help in several of the vulnerability assessment phases. Be sure to use network mapping programs and document your network thoroughly. It can aid you when baselining and analyzing your networks and systems.
Vulnerability Scanning
Vulnerability scanning is a technique that identifies threats on your network, but does not exploit them. When you are ready to assess the level of vulnerability on the network, it is wise to use a general vulnerability scanner and a port scanner (or two). By scanning all the systems on the network, you determine the attack surface of those systems, and you can gain much insight as to the risks that you need to mitigate, and malicious activity that might already be going on underneath your nose. One such vulnerability scanner is called Nessus. This is one of many exploitation framework tools, but it is a very commonly deployed tool used to perform vulnerability, configuration, and compliance assessments. The tool can use a lot of resources, so it is wise to try to perform scans off-hours.
Sometimes, a full-blown vulnerability scanner isn’t necessary (or within budget). There will be times when you simply want to scan ports or run other basic tests. As previously discussed in Chapter 7, an example of a good port scanner is Nmap. Although this tool has other functionality in addition to port scanning, it is probably best known for its port scanning capability. Figure 12-2 shows an example of a port scan with Nmap. This shows a scan (using the -sS parameter) to a computer that runs Kerberos (port 88), DNS (port 53), and web services (port 80), among other things. By using a port scanner like this one, you are taking a fingerprint of the operating system. The port scanner tells you what inbound ports are open on the remote computer and what services are running. From this, you can discern much more information, for example, what operating system the computer is running, what applications, and so on. In the example in Figure 12-2, you can gather that the scanned computer is a Microsoft domain controller running additional services. So, this is an example of OS fingerprinting.
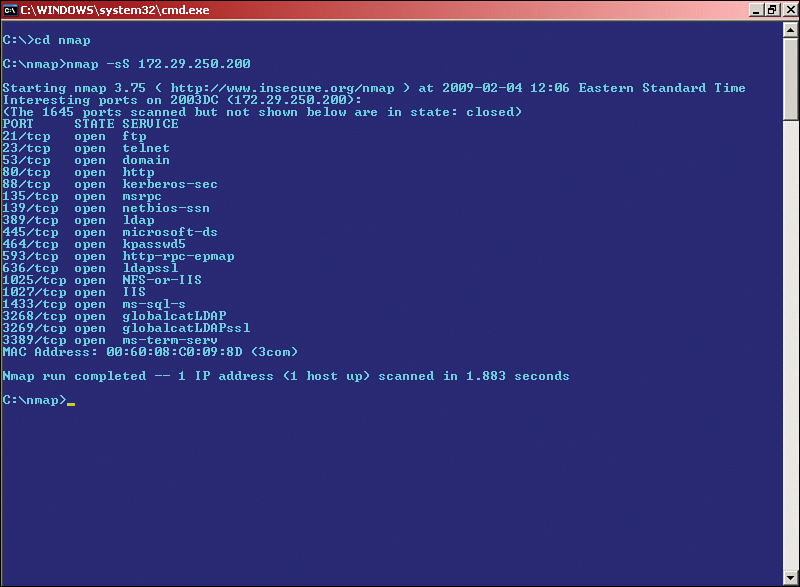
Open ports should be examined. You should be fully aware of the services or processes that use those ports. If services are unnecessary, they should be stopped and disabled. For example, if this computer was indeed a domain controller but wasn’t supposed to be a DNS server, the DNS service (port 53) should be stopped. Otherwise, the DNS port could act as a vulnerability of the server. Afterward, the computer should be rescanned to ensure that the risk has been mitigated.
Nonessential services are often not configured, monitored, or secured by the network administra283tor. It is imperative that network administrators scan for non-essential services and close any corresponding ports. Even though services may be nonessential, that doesn’t necessarily mean that they are not in use, maliciously or otherwise.
Another excellent tool is netcat (and Ncat), which is generally used in Linux/Unix platforms. It can be used for port scanning, port listening, transferring files, opening raw connections, and as a backdoor into systems. As discussed in Chapter 10, “Physical Security and Authentication Models, another tool that can be used to display the ports in use is the netstat command. Examples include the netstat, netstat -a, netstat -n, and netstat -an commands. However, this is only for the local computer, but it does show the ports used by the remote computer for the sessions that the local computer is running.
Note
There are other basic port scanners you can use, such as Angry IP Scanner (and plenty of other free port scanners on the Internet). Some of these tools can be used as ping scanners, sending out ICMP echoes to find the IP addresses within a particular network segment.
Tools such as Nmap and Nessus are also known as network enumerators. Enumeration refers to a complete listing of items (such as port numbers); network enumerators extract information from servers including network shares, services running, groups of users, and so on. It is this additional extraction of information (enumerating) that sets them apart from a basic network mapping tool. This type of enumeration is also referred to as banner grabbing. Banner grabbing is a technique used to find out information about web servers, FTP servers, and mail servers. For example, it might be used by a network administrator to take inventory of systems and services running on servers. Or, it could be used by an attacker to grab information such as HTTP headers, which can tell the attacker what type of server is running, its version number, and so on. Examples of banner-grabbing applications include Netcat and Telnet. Aside from the security administrator (and perhaps auditors), no one should be running banner-grabbing tools, or network enumeration tools in general. A good security admin will attempt to sniff out any unpermitted usage of these tools.
Network Sniffing
For all intents and purposes, the terms protocol analyzer, packet sniffer, and network sniffer all mean the same thing. “Sniffing” the network is when you use a tool to find and investigate other computers on the network; the term is often used when capturing packets for later analysis. Protocol analyzers can tell you much more about the traffic that is coming and going to and from a host than a vulnerability scanner or port scanner might. In reality, the program captures Ethernet frames of information directly from the network adapter and displays the packets inside those frames within a capture window. Each packet is encapsulated inside a frame.
One common example of a protocol analyzer is Wireshark, which is a free download that can run on a variety of platforms. By default, it captures packets on the local computer that it was installed on. Figure 12-3 shows an example of a packet capture. This capture is centered on frame number 10, which encapsulates an ICMP packet. This particular packet is a ping request sent from the local computer (10.254.254.205) to the remote host (10.254.254.1). Although my local computer can definitely send out pings, it is unknown whether 10.254.254.1 should be replying to those pings. Perhaps there is a desired policy that states that this device (which is actually a router) should not reply to pings. As we learned in Chapter 7, “Networking Protocols and Threats,” an ICMP reply can be a vulnerability. Now, if we look at frame 11 we see it shows an echo reply from 10.254.254.1—not what we want. So, to mitigate this risk and remove the vulnerability, we would turn off ICMP echo replies on the router.
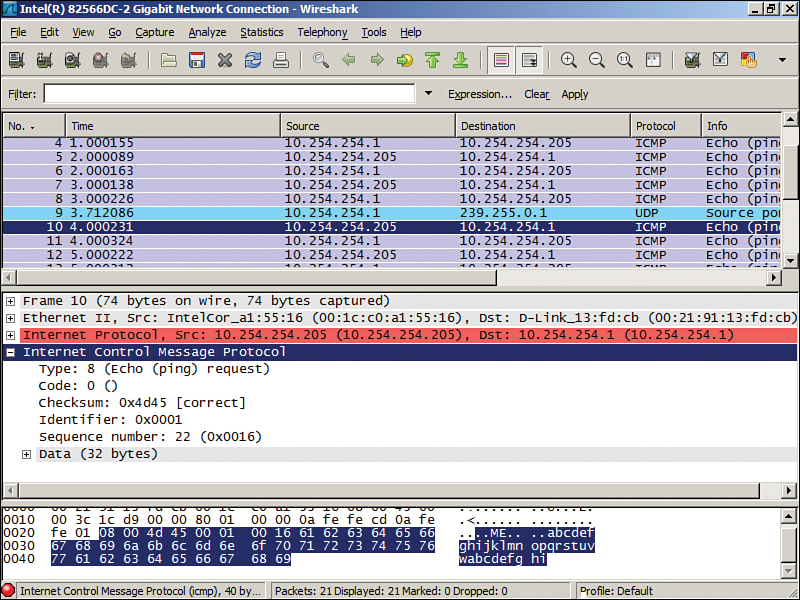
This is just one example of many that we could show with this program. I’ve used this program to find, among other things, unauthorized FTP, gaming, and P2P traffic! You’d be surprised how often network admins and even regular old users set up these types of servers. It uses up valuable bandwidth and resources, so you can imagine that an organization would want these removed. Not only that, but they can be vulnerabilities as well. By running these services, a person opens up the computer system to a whole new set of threats. By removing these unauthorized servers, we are reducing risk. I know—I’m such a buzzkill. But really now, work is work, and play is play; that’s how companies are going to look at it.
On the other side of things, malicious users will utilize a protocol analyzer to capture passwords and other confidential information. We discuss software-based protocol analyzers more in Chapter 13, “Monitoring and Auditing.”
There are plenty of other software-based packet sniffers available on the Internet, but Wireshark is the industry standard. Also, hardware-based devices can analyze your networks and hosts; for example, Fluke Networks offers a variety of network testers. These handheld computers often have a built-in GUI-based system that can be used to monitor ports, troubleshoot authentication issues, identify network resources and IP addresses, and lots more. The name Fluke is used by some techs even if they use a handheld device by a different vendor; the brand is that well-known.
Password Analysis
Well, we’ve mapped the network, documented it, scanned for vulnerabilities, scanned ports, and analyzed packets. But wait, let’s not forget about passwords. We’ve mentioned more than once in this book that weak passwords are the bane of today’s operating systems and networks. This could be because no policy for passwords was defined, and people naturally gravitate toward weaker, easier-to-remember passwords. Or it could be that a policy was defined but is not complex enough, or is out of date. Whatever the reason, it would be wise to scan computers and other devices for weak passwords with a password cracker, which uses comparative analysis to break passwords and systematically guesses until it cracks the password. And of course, a variety of password-cracking programs can help with this. For Windows computers, there is the well-documented Cain & Abel password recovery tool. This program has a bit of a learning curve but is quite powerful. It can be used to crack all kinds of different passwords on the local system or on remote devices and computers. It sniffs out other hosts on the network the way a protocol analyzer would. This is an excellent tool to find out whether weak passwords are on the network, or to help if users forget their passwords (when password resets are not possible). Figure 12-4 shows an example of Cain & Abel. You can see hashed passwords (encrypted) that the program has discovered for various accounts on a test computer. From these hashes, the program can attempt to crack the password and deliver the original plaintext version of the password.

We talk more about hashes and hashing algorithms in Chapter 14, “Encryption and Hashing Concepts.”
Cain & Abel is a free download, and many other tools are available for various platforms; some free, some not, including ophcrack, John the Ripper, THC-Hydra, Aircrack-ng (used to crack WPA preshared keys), and RainbowCrack. Some of these tools have additional functionality but are known best as password/passphrase-cracking tools, although they can be used by security administrators in a legitimate sense as password recovery programs.
The following list shows the various password-cracking methods. Password recovery (or cracking) can be done in several different ways:
![]() Guessing: Weak passwords can be guessed by a smart person, especially if the person has knowledge of the user he is trying to exploit. Blank passwords are all too common. And then there are common passwords such as password, admin, secret, love, and many more. If a guessing attacker knew the person and some of the person’s details, he might attempt the person’s username as the password, or someone the person knows, date of birth, and so on. Reversing letters or adding a 1 to the end of a password are other common methods. Although guessing is not as much of a technical method as the following three options, it reveals many passwords every day all over the world.
Guessing: Weak passwords can be guessed by a smart person, especially if the person has knowledge of the user he is trying to exploit. Blank passwords are all too common. And then there are common passwords such as password, admin, secret, love, and many more. If a guessing attacker knew the person and some of the person’s details, he might attempt the person’s username as the password, or someone the person knows, date of birth, and so on. Reversing letters or adding a 1 to the end of a password are other common methods. Although guessing is not as much of a technical method as the following three options, it reveals many passwords every day all over the world.
![]() Dictionary attack: Uses a prearranged list of likely words, trying each of them one at a time. It can be used for cracking passwords, passphrases, and keys. It works best with weak passwords and when targeting multiple systems. The power of the dictionary attack depends on the strength of the dictionary used by the password-cracking program.
Dictionary attack: Uses a prearranged list of likely words, trying each of them one at a time. It can be used for cracking passwords, passphrases, and keys. It works best with weak passwords and when targeting multiple systems. The power of the dictionary attack depends on the strength of the dictionary used by the password-cracking program.
![]() Brute-force attack: When every possible password instance is attempted. This is often a last resort due to the amount of CPU resources it might require. It works best on shorter passwords but can theoretically break any password given enough time and CPU power. For example, a four-character, lowercase password with no numbers or symbols could be cracked quickly. But a ten-character, complex password would take much longer; some computers will fail to complete the process. Also, you must consider whether the attack is online or offline. Online means that a connection has been made to the host, giving the password-cracking program only a short window to break the password. Offline means that there is no connection and that the password-cracking computer knows the target host’s password hash and hashing algorithm, giving the cracking computer more (or unlimited) time to make the attempt. Some password-cracking programs are considered hybrids and make use of dictionary attacks (for passwords with actual words in them) and brute-force attacks (for complex passwords).
Brute-force attack: When every possible password instance is attempted. This is often a last resort due to the amount of CPU resources it might require. It works best on shorter passwords but can theoretically break any password given enough time and CPU power. For example, a four-character, lowercase password with no numbers or symbols could be cracked quickly. But a ten-character, complex password would take much longer; some computers will fail to complete the process. Also, you must consider whether the attack is online or offline. Online means that a connection has been made to the host, giving the password-cracking program only a short window to break the password. Offline means that there is no connection and that the password-cracking computer knows the target host’s password hash and hashing algorithm, giving the cracking computer more (or unlimited) time to make the attempt. Some password-cracking programs are considered hybrids and make use of dictionary attacks (for passwords with actual words in them) and brute-force attacks (for complex passwords).
Note
Some attackers will utilize software that can perform hybrid attacks that consist of successive dictionary and brute-force attacks.
![]() Cryptanalysis attack: Uses a considerable set of precalculated encrypted passwords located in a lookup table. These tables are known as rainbow tables, and the type of password attack is also known as precomputation, where all words in the dictionary (or a specific set of possible passwords) are hashed and stored. This is done in an attempt to recover passwords quicker. It is used with the ophcrack and RainbowCrack applications. This attack can be defeated by implementing salting, which is the randomization of the hashing process.
Cryptanalysis attack: Uses a considerable set of precalculated encrypted passwords located in a lookup table. These tables are known as rainbow tables, and the type of password attack is also known as precomputation, where all words in the dictionary (or a specific set of possible passwords) are hashed and stored. This is done in an attempt to recover passwords quicker. It is used with the ophcrack and RainbowCrack applications. This attack can be defeated by implementing salting, which is the randomization of the hashing process.
Knowledgeable attackers understand where password information is stored. In Windows, it is stored in an encrypted binary format within the SAM hive. In Linux, the data used to verify passwords was historically stored in the /etc/passwd file, but in newer Linux systems the passwd file only shows an X, and the real password information is stored in another file, perhaps /etc/shadow, or elsewhere in an encrypted format.
Aside from using password-cracking programs, passwords can be obtained through viruses and Trojans, wiretapping, keystroke logging, network sniffing, phishing, shoulder surfing, and dumpster diving. Yikes! It should go without mentioning that protecting passwords is just as important as creating complex passwords and configuring complex password policies that are also periodically monitored and updated. Remember that password policies created on a Windows Server do not have jurisdiction where other vendors’ devices are concerned, such as Cisco routers and firewalls or Check Point security devices. These need to be checked individually or by scanning particular network segments.
We could talk about password cracking for days because there are so many types of hashes, hashing algorithms, and password-cracking tools and ways to crack the passwords. But for the Security+ exam, a basic understanding of password cracking is enough.
Chapter Review Activities
Use the features in this section to study and review the topics in this chapter.
Chapter Summary
It’s a fact: As people, we are vulnerable to all kinds of medical conditions, injuries, maladies, and so on. However, the typical human being tends to find an equilibrium with himself or herself...and with nature. By this I mean that a person tends to automatically prevent medical problems from happening, and performs a certain level of self-healing when many problems do occur. We are intuitive. We drink water before we become dehydrated. We sleep before we become overtired. Most of the time, we automatically defend ourselves from germs and viruses, because we have consciously (and unconsciously) focused on preventative maintenance for our bodies and minds.
In a way, this philosophy can also be applied to technology. Your organization’s technology environment—in all of its parts—can be treated as a sort of entity; similar to the bond a captain might have with a seagoing vessel. When this synergy happens, a person spends more productive time working on preventing problems, and as a result, spends less time fixing issues that occurred due to a compromise simply because compromises end up happening less frequently. Just as the captain will inspect the hull of a ship with a keen set of eyes, you must constantly inspect all parts of your technology for current and potential vulnerabilities. As Benjamin Franklin said, “An ounce of prevention is worth a pound of cure.” It’s a cliché, yet so necessary to revisit from time to time.
There are a great many terms, acronyms, and definitions when it comes to security analysis, but it all boils down to vulnerabilities, and how to prevent threats from exploiting them—that is, minimizing risk. You must plan ahead; not just for current attacks and CVEs, but also for what is on the horizon. Time must be spent considering what will happen to an installed device or computer in a year, or five years. That time will be here before you know it!
Define the risk, as it appears now, and as it will appear in the future. Reduce as much risk as possible, so that all but the most unlikely threats will be prevented. It’s that prevention that is the key. Of all the security controls, prevention is the most important. One excellent way to be sure that you are doing your best to prevent problems is to use a vulnerability management process. This leaves nothing to chance. Another masterful way to manage vulnerabilities is to utilize automation. You can’t clone yourself (yet), but you can clone your administrations. The size of your IT environment and the level of automation you employ should be proportionate.
Penetration testing, vulnerability scanning, port scanning, network sniffing, and password analysis are all just methods to be used within your risk and vulnerability assessments. You might use some methodologies, and not others, and you might perform assessments in an active or passive manner. That will depend on the particulars of your network and the level of criticality of your IT environment. And you may use different methods than the ones listed in this chapter, or develop new ones in the future. The list is in no way finite. The crucial point is to realize that you are taking the consolidated information you glean and using it to define the real risk to your organization in an intuitive way.
So, think of your IT infrastructure as a sort of living, breathing entity: One that relies on you as much as you rely on it.
Review Key Topics
Review the most important topics in the chapter, noted with the Key Topic icon in the outer margin of the page. Table 12-4 lists a reference of these key topics and the page number on which each is found.
Table 12-4 Key Topics for Chapter 12
| Key Topic Element | Description | Page Number |
| Table 12-1 | Example of quantitative risk assessment | 273 |
| Table 12-2 | Summary of risk assessment types | 274 |
| Bulleted list | Preventive, detective, and corrective security controls | 276 |
| Step list | Five steps of vulnerability management | 276 |
| Figure 12-2 | Port scan with Nmap | 282 |
| Figure 12-3 | Packet capture with Wireshark | 284 |
| Figure 12-4 | Password cracking with Cain & Abel | 285 |
| Bulleted list | Password-cracking methods | 285 |
Define Key Terms
Define the following key terms from this chapter, and check your answers in the glossary:
mean time between failures (MTBF)
Open Vulnerability and Assessment Language (OVAL)
Complete the Real-World Scenarios
Complete the Real-World Scenarios found on the companion website (www.pearsonitcertification.com/title/9780134846057). You will find a PDF containing the scenario and questions, and also supporting videos and simulations.
Review Questions
Answer the following review questions. Check your answers in Appendix A, “Answers to the Review Questions.”
1. Which type of vulnerability assessments software can check for weak passwords on the network?
A. Wireshark
B. Antivirus software
C. Performance Monitor
D. A password cracker
2. Which of the following has schemas written in XML?
A. OVAL
B. 3DES
C. WPA
D. PAP
3. Russ is using only documentation to test the security of a system. What type of testing methodology is this known as?
A. Active security analysis
B. Passive security analysis
C. Hybrid security analysis
D. Hands-on security analysis
4. Of the following, which is the best way for a person to find out what security holes exist on the network?
A. Run a port scan.
B. Use a network sniffer.
C. Perform a vulnerability assessment.
D. Use an IDS solution.
5. After using Nmap to do a port scan of your server, you find that several ports are open. Which of the following should you do next?
A. Leave the ports open and monitor them for malicious attacks.
B. Run the port scan again.
C. Close all ports.
D. Examine the services and/or processes that use those ports.
6. Which of the following is a vulnerability assessment tool?
A. John the Ripper
B. Aircrack-ng
C. Nessus
D. Cain & Abel
7. You are a consultant for an IT company. Your boss asks you to determine the topology of the network. What is the best device to use in this circumstance?
A. Network mapper
B. Protocol analyzer
C. Port scanner
D. Vulnerability scanner
8. Which of the following can enable you to find all the open ports on an entire network?
A. Protocol analyzer
B. Network scanner
C. Firewall
D. Performance monitor
9. What can attackers accomplish using malicious port scanning?
A. “Fingerprint” of the operating system
B. Topology of the network
C. All the computer names on the network
D. All the usernames and passwords
10. Many companies send passwords via clear text. Which of the following can view these passwords?
A. Rainbow table
B. Port scanner
C. John the Ripper
D. Protocol analyzer
11. Which of the following persons is ultimately in charge of deciding how much residual risk there will be?
A. Chief security officer
B. Security administrator
C. Senior management
D. Disaster recovery plan coordinator
12. To show risk from a monetary standpoint, which of the following should risk assessments be based upon?
A. Survey of loss, potential threats, and asset value
B. Quantitative measurement of risk, impact, and asset value
C. Complete measurement of all threats
D. Qualitative measurement of risk and impact
13. The main objective of risk management in an organization is to reduce risk to a level _____________. (Fill in the blank.)
A. the organization will mitigate
B. where the ARO equals the SLE
C. the organization will accept
D. where the ALE is lower than the SLE
14. Why would a security administrator use a vulnerability scanner? (Select the best answer.)
A. To identify remote access policies
B. To analyze protocols
C. To map the network
D. To find open ports on a server
15. An example of a program that does comparative analysis is what?
A. Protocol analyzer
B. Password cracker
C. Port scanner
D. Event Viewer
16. Why do attackers often target nonessential services? (Select the two best answers.)
A. Often they are not configured correctly.
B. They are not monitored as often.
D. They are not monitored by an IDS.
17. Which of the following tools uses ICMP as its main underlying protocol?
A. Ping scanner
B. Port scanner
C. Image scanner
D. Barcode scanner
18. Which command would display the following output?
Active Connections Proto Local Address Foreign Address State TCP WorkstationA:1395 8.15.228.165:http ESTABLISHED
A. Ping
B. Ipconfig
C. Nbtstat
D. Netstat
19. Which of the following is used when performing a quantitative risk analysis?
A. Asset value
B. Surveys
C. Focus groups
D. Best practices
20. You have been tasked with running a penetration test on a server. You have been given limited knowledge about the inner workings of the server. What kind of test will you be performing?
A. White-box
B. Gray-box
C. Black-box
D. Passive vulnerability scan
21. Which of the following is a technical control?
A. Disaster recovery plan
B. Baseline configuration development
C. Least privilege implementation
D. Categorization of system security
22. Which of the following is a detective security control?
A. Bollards
B. Firewall
C. Tape backup
23. Which of the following would you make use of when performing a qualitative risk analysis?
A. Judgment
B. Asset value
C. Threat frequency
D. SLE
24. What is the best action to take when you conduct a corporate vulnerability assessment?
A. Document your scan results for the change control board.
B. Examine vulnerability data with a network sniffer.
C. Update systems.
D. Organize data based on severity and asset value.
25. You are implementing a new enterprise database server. After you evaluate the product with various vulnerability scans you determine that the product is not a threat in of itself but it has the potential to introduce new vulnerabilities to your network. Which assessment should you now take into consideration while you continue to evaluate the database server?
A. Risk assessment
B. Code assessment
C. Vulnerability assessment
D. Threat assessment
26. Why should penetration testing only be done during controlled conditions?
A. Because vulnerability scanners can cause network flooding.
B. Because penetration testing actively tests security controls and can cause system instability.
C. Because white-box penetration testing cannot find zero-day attacks.
D. Because penetration testing passively tests security controls and can cause system instability.
27. You are attempting to prevent unauthorized access to the desktop computers on your network. You decide to have the computers’ operating systems lock after 5 minutes of inactivity. What type of security control is this?
A. Detective
B. Operational
C. Management
D. Technical
28. Which of the following methods can be used by a security administrator to recover a user’s forgotten password from a password-protected file?
A. Brute-force
B. Packet sniffing
C. Social engineering
29. A security admin is running a security analysis where information about a target system is gained without engaging or exploiting the system. Which of the following describes this type of analysis? (Select the best answer.)
A. Banner grabbing
B. ALE assessment
C. Active reconnaissance
D. Passive reconnaissance