
CHAPTER 12
Security Best Practices
In this chapter, you will learn about
• Cloud security engineering
• Security governance and strategy
• Vulnerability management
• Incident response
Cloud services make it easier for companies to adopt software, systems, and services. However, it can be easy to implement a cloud system that functions well but secures very little. Some practical steps can be taken to better secure systems and data in the cloud.
Cloud security engineering includes important information on how to protect cloud systems. Cloud security engineering involves host and guest computer hardening and layering security to provide multiple overlapping controls that an attacker would need to break through to get to systems and data. Additionally, systems should be designed so that users and services have only the privileges they need to function, in what is known as least privilege. Cloud security engineers must also divide elements of tasks among multiple people to minimize the risk of corruption. Lastly, cloud security engineering seeks to automate security tasks.
Security governance is the set of activities and guidelines an organization uses to manage technologies, assets, and employees. Security governance ensures that the right activities are performed and that those activities accomplish the security goals of the organization. This is performed through security policies that set organizational expectations and procedures that define how tasks will be performed. Established industry standards and regulations can be used to craft the right mix of technologies and policies to meet regulatory requirements or established best practices.
Organizations also need to perform vulnerability scanning and penetration testing. These functions together form the basis for vulnerability management. Vulnerability management is the process of identifying possible vulnerabilities and enacting controls to mitigate those threats that are probable.
Cloud Security Engineering
Cloud security engineering is the practice of protecting the usability, reliability, integrity, and safety of cloud data and infrastructure and the users utilizing cloud systems. As it does in many other areas, security in cloud computing has similarities to traditional computing models. If deployed without evaluating security, cloud systems may deliver against their functional requirements, but they will likely have many gaps that could lead to a compromised system.
As part of any cloud deployment, attention needs to be paid to specific security requirements so that the resources that are supposed to have access to data and software in the cloud system are the only resources that can read, write, or change it. This section provides coverage of the following practices and principles employed in cloud security engineering:
• Implementing layered security
• Protecting against availability attacks
• Least privilege
• Separation of duties
• Security automation
Implementing Layered Security
To protect network resources from threats, secure network design employs multiple overlapping controls to prevent unwanted access to protected cloud resources. Some layered security components include demilitarized zones, ACLs, and intrusion detection and prevention systems.
A demilitarized zone (DMZ) is a separate network that is layered in between an internal network and an external network to house resources that need to be accessed by both while preventing direct access from the outside network to the inside network. ACLs define the traffic that is allowed to traverse a network segment. Lastly, intrusion detection systems can detect anomalous network behavior and send alerts to system administrators to take action, while intrusion prevention systems can detect anomalies and take specific actions to remediate threats.
The real strength of demilitarized zones, ACLs, and intrusion detection and prevention systems (covered in Chapter 11) is that they can all be used together, creating a layered security system for the greatest possible security.
Consider an attacker trying to get to a cloud database. The attacker would need to first get through the firewall. A DMZ, along with appropriately configured ACLs, between networks would require the attacker to compromise a machine in the DMZ and then pivot from that machine to another machine in the internal network. However, networks with an IDS/IPS might detect this activity, notify administrators, and block the attacker from making the connection. In this way, these technologies work together to provide a layered solution to protect the cloud database.
Protecting Against Availability Attacks
Attacks on availability are those designed to take a system down so that users, such as customers or employees, cannot use it. Some availability attacks are used to cause a system to restart so that weaknesses in the system’s startup routines can be exploited to inject code, start in a maintenance mode and reset passwords, or take other malicious actions.
Distributed Denial of Service
A distributed denial of service (DDoS) attack targets a single system simultaneously from multiple compromised systems. DDoS was introduced in Chapter 11 under the discussion on firewalls and cloud access security brokers (CASBs), but there are other protections against DDoS.
DDoS attacks are distributed because they use thousands or millions of machines that could be spread worldwide. Such an attack denies services or disrupts availability by overwhelming the system so that it cannot respond to legitimate connection requests. The distributed nature of these attacks makes it difficult for administrators to block malicious traffic based on its origination point and to distinguish approved traffic from attacking traffic. DDoS can quickly overwhelm network resources. However, large cloud systems can offer protection to cloud consumers.
Cloud DDoS protection solutions, such as those from Amazon, Microsoft, Verisign, or Cloudflare, not only protect cloud consumers from attack and loss of availability of resources but also protect against excessive usage charges, since many cloud providers charge for how much data is sent and received. Cloud providers offering services such as CASB, also introduced in Chapter 11, can screen out some traffic. They also have the bandwidth to soak up most DDoS traffic without becoming overwhelmed. There have been some high-profile DDoS attacks that caused a disruption, such as those committed with the Internet of Things (IoT) devices that took down large clouds. However, most DDoS attacks cannot commit resources at that scale.
Ping of Death
Ping of death (PoD) attacks send malformed ICMP packets with the intent of crashing systems that cannot process them and consequently shut down. Most modern cloud firewall packages, such as AWS Shield, DigitalOcean, and Zscaler, can actively detect these packets and discard them before they cause damage.
Ping Flood Attacks
Ping flood attacks are similar to DDoS attacks in that they attempt to overwhelm a system with more traffic than it can handle. In this variety, the attack is usually attempted by a single system, making the attack easier to identify and block. Defense strategies for ping floods are the same as those for DDoS, including cloud DDoS protection.
Least Privilege
Another essential security concept is the principle of least privilege. Employees should be granted only the minimum permissions necessary to do their job. No more, no less. Incorporating the principle of least privilege limits the potential misuse and risk of accidental mishandling or viewing of sensitive information by unauthorized people.
Separation of Duties
Separation of duties, also known as segregation of duties, divides the responsibilities required to perform a sensitive task among two or more people so that one person, acting alone, cannot compromise the system. The separation of duties needs to be carefully planned and implemented. If implemented correctly, it can act as an internal control to help reduce potential damage caused by the actions of a single administrator.
By limiting permissions and influence over key parts of the cloud environment, no one individual can knowingly or unknowingly exercise complete power over the system. For example, in an e-commerce organization with multiple layers of security comprised in a series of cloud solutions, separation of duties would ensure that a single person would not be responsible for every layer of that security, such as provisioning accounts, implementing ACLs, and configuring logging and alerting for the various cloud services and their integrations. Therefore, if that person were to become disgruntled, they would not have the ability to compromise the entire system or the data it contains; they would only have the ability to access their layer of the security model.

EXAM TIP Separation of duties is the process of segregating tasks among two or more people. It prevents fraud because one person cannot compromise a system without colluding with others. Separation of duties is also called segregation of duties.
Security Automation
The last part of cloud security engineering is to automate security tasks. Security tasks must be performed at regular intervals, and they must be performed correctly each time. Additionally, it can be quite a job to secure many systems, and organizational security departments are supporting more systems and cloud services than ever before.
Security automation helps in both these areas. Automation ensures that tasks are performed the same way every time and performed precisely on schedule. Furthermore, automation frees up valuable security resources so that they can focus on other tasks. Automation uses scripting, scheduled tasks, and automation tools to perform routine tasks so that IT staff can spend more time solving real problems and proactively looking for ways to make things better and even more efficient.
This section discusses different security activities that can be automated to save time and standardize. They include the following:
• Disabling inactive accounts
• Eliminating outdated firewall rules
• Cleaning up outdated security settings
• Maintaining ACLs for target objects
Disabling Inactive Accounts
You can automate the disabling of inactive accounts. Use this quite sparingly because disabling an account will mean that the user cannot log in anymore. Choose to disable rather than remove an account because once you remove an account, creating it again is somewhat tricky. If you create another account with the same name, it will still have a different security identifier and will not really be the same account. That is why it is best to disable accounts first, and then at some later point, you can remove the account. Disabling it is also important if you need to take action on that account in the future, such as decrypting EFS encrypted files, viewing profile settings, or logging onto that person’s e-mail. These are things that might need to be done for a terminated employee if that employee is under investigation; if the account were deleted, they would still be possible, but a bit more complicated.
The following PowerShell command disables all accounts that have not been logged into for over 30 days. Of course, if you were in Europe, some people take a holiday for longer than 30 days, but you can always enable the account when they return.
Search-ADAccount -AccountInactive -TimeSpan ([timespan]30d) -UsersOnly | Set-
ADUser -Enabled $false
Eliminating Outdated Firewall Rules
It is possible through the course of adding and removing programs or changing server roles that the Windows Firewall rules for a VM could become out of date. It can be challenging to automate the analysis of the rules and remove outdated rules, so the best course of action is to remove all rules and reassign rules based on the current roles.
As mentioned many times in this book, it is imperative to document. Document the firewall rules that you put in place for VMs and organize the rules by role. For example, you would have one set of standard rules for database servers, web servers, file servers, domain controllers, certificate servers, VPN servers, FTP servers, DHCP servers, and a separate role for each type of application server.
Each of the firewall rules for a defined role can be scripted. Here is an example configuration for a VM with the database role running Microsoft SQL Server 2016 with Analysis Services. This script allows remote management and communication over SQL Server ports. The last commands turn the firewall on, just in case it is not already on.

Now, with the role descriptions and the scripts in hand, you can clear the configurations from a set of servers whose rules you believe are outdated, and then you can reapply the company standard firewall rules for that role. Here is the command to clear the rules from the server. Essentially, this command resets the Windows Firewall to its default out-of-the-box settings.
netsh advfirewall reset
Please note that the firewall configuration formerly used just the netsh command, but this command was deprecated. The new command is netsh advfirewall.
Firewalls are covered in more detail in the “Network Security” section of Chapter 11.
Cleaning Up Outdated Security Settings
VMware vSphere can be made much more secure by turning off some features for VMs. The first feature to disable is host guest file system (HGFS) file transfers. HGFS transfers files into the operating system of the VM directly from the host, and a hacker or malware could potentially misuse this feature to download malware onto a guest or to exfiltrate data from the guest. Script these commands for each VM:
keyword = isolation.tools.hgfsServerSet.disable
keyval = TRUE
The next feature to disable is the ability to copy and paste data between the remote console and the VM. This is disabled by default, but if someone turned it on, you could disable it again. Enabling copy and paste can allow for sensitive content to accidentally be placed on another machine. Script these commands for each VM:
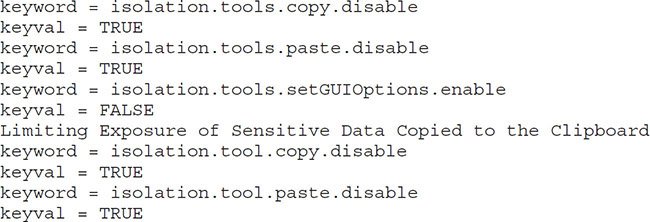
The third item to disable is the ability for a user to disconnect VMware devices from the VM. When this is turned on, administrative users on the VM can run commands to disconnect devices such as network adapters, hard disk drives, and optical drives. Script these commands for each VM:

The fourth item to disable is the ability of processes running in the VM to send configuration messages to the hypervisor. Processes on the VM that modify configuration settings can potentially damage the VM or cause it to be unstable. Script these commands for each VM:
keyword = isolation.tools.setinfo.disable
keyval = TRUE
Maintaining ACLs for Target Objects
You can script setting access control lists for objects by using the cacls command. ACL scripting can be useful if you want to change permissions for many files and folders. Here is the command to give a group called DevOps full control to the D: drive and all subfolders:
CACLS D: /E /T /C /G "DevOps":F
Security Governance and Strategy
Attackers keep coming up with innovative attacks, so the line for security best practices continues to move. A variety of government agencies and standards bodies publish security best practices and standards, such as the ISO/IEC 27001 or NIST SP 800-53. These can give an organization some guidance on security governance practices and valuable security strategies. Still, each organization needs to determine for itself what is appropriate for its security based on its specific operations.
Implementing a practice just because it is listed in a standard might improve security, but it might not improve it as much as something else. Budgets are tight, so it is crucial to choose the security controls that will give your organization the best protection for your budget. This section covers best practices for governance and strategy. This text has organized these best practices into the following sections:
• Developing company security policies
• Account management policies
• Documenting security procedures
• Assessment and auditing
• Leveraging established industry standards and regulations
• Applying platform-specific security standards
• Data classification
• Keeping employees and tools up to date
• Roles and responsibilities
Developing Company Security Policies
Security policies set the organizational expectations for certain functional security areas. Policies should be defined based on what the organization is committed to doing, not on what it might do. Once a policy is put in place, others will expect the company to adhere to it. Policies usually come with sanctions for those who do not follow the policy, such as oral or written warnings, coaching, suspensions from work, or termination.
Security policies often use the terms personally identifiable information (PII) and protected health information (PHI). PII is information that represents the identity of a person, such as name, phone number, address, e-mail address, Social Security number, and date of birth. PHI is similar to PII in the context of patient identity but is used in HIPAA compliance and other similar areas. The term PII is common in security policies of many types of organizations, whereas PHI is common in the security policies of healthcare organizations. Both terms are used in security policies to designate information that must not be disclosed to anyone who is not authorized to access it.
Some common security policies include the following:
• Acceptable use policy States how organizational assets are to be used. This policy covers the use of corporate equipment such as computers, laptops, phones, and office equipment. More importantly, it covers which cloud and other Internet services employees can use, acceptable norms for e-mail, and use of social networking.
• Audit policy Specifies how often audits occur, the differences between internal and external audits, who should handle audits, how they are reported on, and the level of access granted to auditors. Both internal and external audits would cover internal systems and cloud systems used by the company. The audit policy also covers how audit findings and exceptions are to be handled.
• Backup policy Covers how the organization will back up the data that it has. This includes both data on-premise and in the cloud. The backup policy usually includes who is responsible for backing up data, how often backups will take place, the data types that will be backed up, and the recovery time objective (RTO) and recovery point objective (RPO) for each data type.
• BYOD policy Specifies how employee-owned devices are to be used within the company and how they can be used if they access company cloud services and data.
• Cloud services policy Defines which cloud services are acceptable for organizational use, how cloud services are evaluated, who is authorized to purchase cloud services, and how employees suggest or recommend cloud services to the review committee.
• Data destruction policy Outlines how the organization will handle the disposal of equipment that houses data, such as computers, servers, and hard drives. It should specify how that data will be wiped or destroyed, what evidence will be retained on the disposal or destruction, and who is authorized to dispose of assets. This includes not only digital data but physical documents as well, so these documents must be shredded when the policy requires it.
• Data retention policy Specifies how long data of various types will be kept on organizational systems or cloud systems the organization utilizes. For example, the data retention policy may specify that e-mail on Office 365 will be retained for two years, financial documents on SAP S/4HANA will be kept for seven years, and other data will be retained for one year.
• Encryption policy Specifies what should be encrypted in the organization and in cloud systems used by the organization, how encryption systems are evaluated, which cryptographic algorithms are acceptable, how cryptographic keys are managed, and how keys are disposed of.
• Mobile device policy Specifies which types of mobile devices can be used for organizational purposes, which person or role authorizes mobile devices, how those devices are to be protected, where they can be used, which cloud services can be accessed by mobile devices, how they are encrypted, and how organizational data will be removed from mobile devices when they are retired or when employees leave.
• Privacy policy Includes what information the organization considers private; how the organization will handle that information; the purposes and uses of that information; and how that information will be collected, destroyed, or returned.
• Remote access policy Specifies which types of remote access are acceptable, how remote access will take place, how employees are authorized for remote access, auditing of remote access, and how remote access is revoked.
There are hundreds of other policies that can be defined for more granular things. However, the best practice is to keep the number of policies to the minimum necessary so that employees can easily find the organization’s expectations regarding a particular subject.
Some organizations choose to bundle policies together into a handbook or a comprehensive security policy. Compliance requirements may specify which policies an organization needs to have and the minimum standards for those policies. Be aware of which compliance requirements your organization falls under so that you can make sure your policies are in accordance with those requirements.
Account Management Policies
Account management policies establish expectations on how accounts and their associated credentials will be managed. Some simpler policies will be called a password policy. These policies deal only with the password elements of the account management policy and are often used when granularity on password requirements is needed.
EXAM TIP Account management policies and password policies should apply to organizational systems and cloud systems that house organizational data.
Account management policies stipulate how long passwords need to be and how often they should be changed. They also specify who should be issued an account and how accounts are issued to users. This includes which approvals are necessary for provisioning an account. There may be rare cases where a password can be shared, and account management policies will specify these circumstances, if any. These policies also establish requirements for how and when temporary passwords are issued and the process for how and when passwords can be reset.
Two other sections in the account management policy require a bit more attention. They include the lockout policy and password complexity rules. These are covered next in their own sections.
Lockout Policy
A lockout is the automatic disabling of an account due to some potentially malicious action. The most common reason for a lockout is too many incorrect password attempts. Lockout policy can be specified on a per-resource basis or a per-domain basis. When single sign-on (SSO) is used, a single lockout policy also applies.
When a user’s password is entered incorrectly too often, either by the user or by an unauthorized person, the system will disable the user’s account for a predefined period. In some cases, the account is disabled until an administrator unlocks it. Another system can be configured to lock out the account for a set amount of time that increases each time the account is subsequently locked out until a point when an administrator is required to unlock the account again.
You may wish to notify on account lockouts. For example, suppose you have a cloud-based application. In that case, you may want to send users an e-mail when they enter their password incorrectly too many times. This way, if someone else tries to log on as the user, the authorized user will become aware of the attempt and report that it was not authorized. Systems can be configured to automatically notify users when their account is locked out. Otherwise, users will find out their account is locked out when they are unable to log in.
Password Complexity Rules
Stealing or cracking passwords is one of the most common ways that attackers infiltrate a network and break into systems. People generally choose weak passwords because passwords are hard to remember. Most people try to create a password using information that is easy for them to remember, and the easiest thing to remember is something you already know, such as your address, phone number, children’s names, or workplace. But this is also information that can be learned about you easily, so it is a poor choice for a password.
Password complexity has to do with how hard a password would be to break with brute force techniques, where the attacker tries all possible combinations of a password until they get the right one. If you look at just numbers, there are four combinations in a two-character password, while there are eight combinations in a three-character password.
Numbers alone are the easiest to break because there are only ten combinations for each digit (0–9). When you add letters into the mix, this creates more possibilities for the brute force attack to factor in. Special characters such as @#$%^&*&() expand that scope even further. The best passwords are ones that you can remember. However, they should be unrelated to anything someone would be able to figure out about you and to any security questions you may have answered. Passwords should contain a mix of numbers, uppercase and lowercase letters, and special characters.
For those with multiple-language keyboards and application support, a password that combines multiple character systems such as Chinese or Russian can make it even harder to crack.
Security practitioners have for decades tried to find a balance between password complexity and usability. On the one hand, stronger passwords are harder to guess and more difficult to brute force crack. However, these more complex passwords are harder to remember. This can lead users to circumvent best practices by writing passwords down.
Similarly, frequent change intervals can cause users to construct passwords that follow specific patterns such as Fire$ale4Dec in December, Fire$ale4Jan in January, and so forth. Since users have so many passwords to remember, some use the same password in many places and change them all at the same time. However, when a data breach occurs in one location, the usernames and passwords are often put in a database that attackers use to determine other likely passwords. In this example, the attacker might breach the database at the end of December, but then the user changes their passwords. An attacker reviewing the database in April would likely try Fire$ale4Apr and gain access to the system if the user continued with their pattern.
NIST has recognized these weaknesses in their special publication 800-63B. Here are some of the new guidelines. First, increase the maximum password length to at least 64 characters. Along with this, NIST recommends that password fields allow spaces and other printable characters in passwords. These two changes allow users to create longer but more natural passwords.
NIST has also relaxed some of the complexity rules and recommends that companies require just one uppercase, number, or symbol—not all three—and that passwords be kept longer with less frequent change intervals.
NIST also adds some requirements. They recommend that two-factor authentication be used, and they exclude SMS as a valid two-factor authentication method because of the ability for others to potentially obtain the unencrypted SMS authentication data. They also require that passwords be measured for how common and easy to guess they are. Authentication systems should restrict users from creating passwords that contain simple dictionary words, common phrases, or easily guessed information.
Documenting Security Procedures
Security policies specify the company’s expectations and provide general guidelines for what to do, but they do not get into the specifics. This is where security procedures step in. Security procedures outline the individual steps required to complete a task. Furthermore, security procedures ensure that those who follow the procedures will do the following:
• Perform the task consistently.
• Take a predictable amount of time to perform the task.
• Require the same resources each time the task is performed.
Assessment and Auditing
A network assessment is an objective review of an organization’s network infrastructure regarding current functionality and security capabilities. The environment is evaluated holistically against industry best practices and its ability to meet the organization’s requirements. Once all the assessment information has been documented, it is stored as a baseline for future audits to be performed against.
Complete audits must be scheduled regularly to make certain that the configurations of all network resources are not changed to increase the risk to the environment or the organization.
Internal Audits
Internal audit teams validate that security controls are implemented correctly and that security systems are functioning as expected. Companies operate today in an environment of rapid change, and this increased frequency of change can result in an increase in mistakes leading to security issues. Internal audits can help catch these issues before they are exploited.
For example, the technologies enable administrators to move VMs between hosts with no downtime and minimal administrative effort. Because of this, some cloud environments have become extremely volatile. A side effect of that volatility is that the security posture of a guest on one cloud may not be retained when it has been migrated to a different yet compatible cloud. The audit team would have a specification of what the security posture should look like, and they would use that to determine if the machine met the requirements after being moved to the new cloud.
A change management system can help identify changes in an environment, but initial baseline assessments and subsequent periodic audits are still necessary. Such evaluations make it possible for administrators to correlate performance logs on affected systems with change logs, so they can identify configuration errors that may be causing problems. Change management will be covered in more detail in Chapter 14.
Utilizing Third-Party Audits
When assessing or auditing a network, it is best practice to use a third-party product or service provider. Using external resources is preferable to using internal resources. The latter often have both preconceived biases and preexisting knowledge about the network and security configuration.
Familiarity with the environment can produce unsuccessful audits because the internal resources already have an assumption about the systems they are evaluating. Those assumptions result in either incomplete or incorrect information. A set of eyes from an outside source not only eliminates the familiar as a potential hurdle but also allows for a different (and in many cases, broader or more experienced) set of skills to be utilized in the evaluation.
The results of an unbiased third-party audit are more likely to hold up under scrutiny. Many regulations and standards stipulate third-party audits.
Risk Register
A risk register is a document that tracks the risks that have been identified along with their likelihood. Some companies use risk management tools to maintain the risk register, but you can track risks in a spreadsheet too. A risk register contains the list of risks, a description of the risk, the impact the risk would have on the business if actualized, and the likelihood of the risk. The risk register might also prioritize the risks and assign a risk owner.
Risks are given a risk value. This value is a combination of the likelihood and impact, where risk = likelihood * impact. To make things simple, risk managers assign a number value to each and then multiply them together to get the risk value. These values can then be assigned a priority of low, medium, high, or critical.
Figure 12-1 shows a risk heat map. A risk heat map is a visualization of a risk’s impact and likelihood values. The colors indicate which risks would be low, medium, high, or critical, based on the multiplication of the two rankings. In the diagram, green is low, yellow is medium, orange is high, and red is critical.
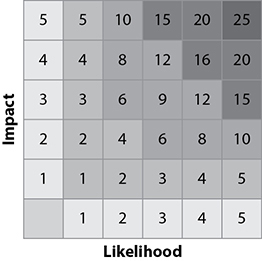
Figure 12-1 Computing the risk value
As risks are analyzed by business owners, they will make a determination on how to handle the risk. Some risks are too unlikely or have very little impact and the company may choose to accept them. Others might require action to remediate the risk. Still other risks can be transferred by purchasing insurance or utilizing a cloud service to perform the function that pertains to the risk. The last option is to avoid the risk by ceasing the function that produces the risk.
Risk registers may document mitigating controls that reduce the risk. If mitigating controls are mentioned, the register will then show what the residual risk is after the mitigating control is factored in. A sample risk register is shown in Tables 12-1 and 12-2.

Table 12-1 Risk Register Risk Documentation

Table 12-2 Risk Register Showing Risk Ratings and Management Decisions
Leveraging Established Industry Standards and Regulations
As cloud computing has become ubiquitous, various standards for best practice deployments of cloud computing infrastructures have been developed. Standards have been established to improve the quality of IT organizations. Some examples of standards include the Information Technology Infrastructure Library (ITIL) and the Microsoft Operations Framework (MOF).
Regulations specify security requirements for business systems and clouds. Noncompliance with regulations can lead to fines or the inability to do business in that industry or in the current capacity. Some regulations include the Payment Card Industry Data Security Standard (PCI DSS), the Sarbanes-Oxley Act (SOX), and the Health Insurance Portability and Accountability Act (HIPAA). Regulatory compliance is more expensive for IT organizations than adhering to a set of standards or best practices. Regulatory compliance requires not only for the organization to build solutions according to the regulatory requirements but also to demonstrate compliance to auditors. The tools and labor required to generate the necessary proof can be costly.
In addition to adopting published best practices, organizations can implement one of the many tools available to raise alerts when a deviation from these compliance frameworks is identified.
Applying Platform-Specific Security Standards
Many vendors have released their own security standards or device configuration guides. It is a good idea to follow the recommendations from these vendors. After all, Cisco created Cisco switches, so who better to recommend how to configure them? Seek out the configuration guides for the equipment you have and audit your device against those security guidelines.
Some vendors release multiple guidelines that are customized for different needs. For example, you may want to harden web application servers, so you look to your web hosting provider for guidance. However, they might offer different guidelines on configuring the server for HIPAA, PCI DSS, NIST, or their general security best practice or hardening guide. Which one you choose depends on which compliance areas you need to adhere to.
Data Classification
Data classification is the practice of sorting data into discrete categories that help define the access levels and type of protection required for that data set. These categories are then used to determine the disaster recovery mechanisms, cloud technologies needed to store the data, and the placement of that data onto physically or logically separated storage resources.
Data classification can be divided into four steps that can be performed by teams within an organization. The first step is to identify the present data within the organization. Next, the data should be grouped into areas with similar sensitivity and availability needs. The third step is to define classifications for each unique sensitivity and availability requirement. The last step is to determine how the data will be handled in each category.
Here are some of the different types of data that an organization would classify into categories such as public, trade secret, work product, financial data, customer data, strategic information, and employee data:
• Account ledgers
• Application development code
• Bank statements
• Change control documentation
• Client or customer deliverables
• Company brochures
• Contracts and SLAs
• Customer data
• HR records
• Network schematics
• Payroll
• Press releases
• Process documentation
• Project plans
• Templates
• Website content
Tagging
Tagging is a process of adding relevant metadata to files so that they can be tracked for compliance. Documents are often tagged so that policies can be applied to the data. For example, under the CMMC and NIST SP800-171, controlled unclassified information (CUI) must be tagged so that systems know it is CUI and can apply appropriate protections.
Of course, when creating policies for tagged data, the first step would be to establish a policy that prevents tags from being removed from the data. Otherwise, users can simply get around the policy by removing a tag and then doing whatever they want.
Legal Holds
Legal holds, also known as litigation holds, are orders to preserve electronically stored information (ESI) from deletion or change when the company has a reasonable expectation that those documents may be relevant to litigation. The company legal team will typically notify IT with the particulars on which documents, e-mails, or other information should be held.
It is important that the team quickly place the legal hold on the information. The company could be guilty of spoliation if the information is not preserved and the court determines that data relevant to the litigation was deleted or modified.
Tools are available from cloud providers that will preserve the data at the point when the legal hold is created on the ESI. Employees can continue working with the data as they usually would, changing or deleting files, but the system will still preserve the original data behind the scenes. Let’s take a look at the process for creating a legal hold in Office 365.
Exercise 12-1: Creating a Legal Hold for a Mailbox in Office 365
In this exercise, we will create a legal hold for a mailbox in Office 365.
1. Log into your Office 365 portal.
2. Select admin at the bottom of the apps list on the left.
3. Expand the eDiscovery section and select eDiscovery. The screen will now show the cases you have defined.
4. Select the Create A Case button to start the eDiscovery wizard.
5. The first step is to give the case a name. For this example, we are calling the case CloudTest. The description is optional, so we are leaving it blank here.
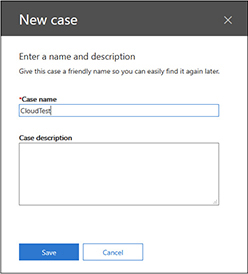
6. Click Save to continue, and the new case will appear in the eDiscovery screen.
7. Click Open next to the CloudTest case.
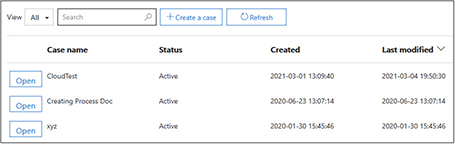
8. Click the Holds tab.
9. On the Holds page, click the Create button.
10. Give the hold a name. In this example, we call it CloudTest Hold.

11. Click the Next button to move to the next step in the wizard. This next screen allows you to select the ESI that will be part of the legal hold.
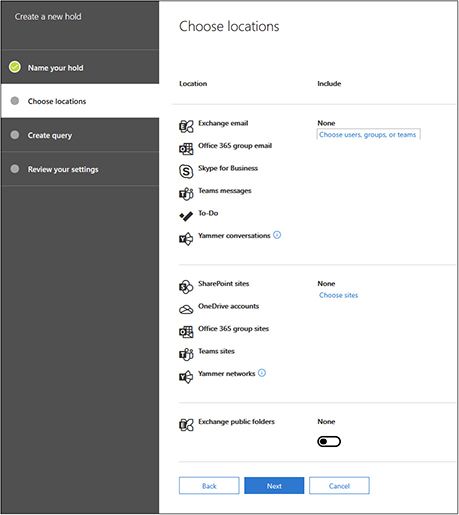
In this example, we are going to choose a user account. Your environment will be different from this example because you will not have the same user accounts. I will choose the Eric Vanderburg account for this example.
12. Click Choose Users, Groups, Or Teams, and a new window will appear.
13. Click Choose Users, Groups, Or Teams under Exchange e-mail in the new window.
14. Type the first few letters of the username until you see the account appear in the lower half of the screen where it says “users, groups, or teams.”
15. Select the user account by checking the box next to it, and then click the Choose button at the bottom.

16. This takes you back to the previous screen, but now you should see the e-mail account you selected in step 15. Click the Done button.
17. You will now see the wizard’s Choose Locations page, but it will show one user selected. Click the Next button to proceed to the Query page of the wizard.
18. On this page, you can establish keywords. Each e-mail that contains those keywords will be preserved as part of the legal hold. Enter these three keywords (note that each word is separated by a comma): Cloud,server,infrastructure

19. Click Next. This screen shows the options we selected. Click Create This Hold.
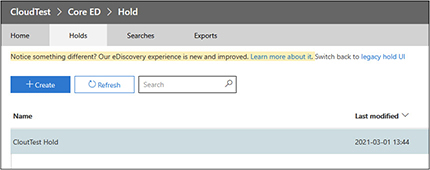
20. The legal hold will now appear in the Holds tab.
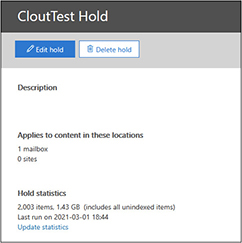
21. Wait a minute for statistics to be gathered and then click the hold to display its statistics in a window that will open on the right. In this example, we see the mailbox we enabled the hold on has 2,003 items. If you do not see the statistics, click the update statistics button.
Keeping Employees and Tools Up to Date
The rapidly evolving landscape of cloud technologies and virtualization presents dangers for cloud security departments that do not stay abreast of changes to both their toolsets and their training. Companies can use new virtualization technologies and tools to more rapidly deploy new software, leading to an acceleration of software development activities in fast-forward-type deployments, known as rapid deployment. See Chapter 9 for more details.
One hazard of rapid deployment is the propensity to either ignore security or proceed with the idea that the organization will enable the system’s functionality immediately, then circle back and improve the security once it is in place. Typically, however, new functionality requests continue to take precedence, and security is rarely or inadequately revisited.
Many networks were initially designed to utilize traditional network security devices that monitor traffic and devices on a physical network. Suppose the intra–virtual machine traffic that those tools are watching for never routes through a physical network. In that case, it cannot be monitored by that traditional toolset. The problem with limiting network traffic to guests within the host is that if the tools are not virtualization or cloud-aware, they will not provide the proper information to make a diagnosis or suggest changes to the infrastructure. Therefore, monitoring and management toolsets (including cloud-based CLIs) must be updated as frequently as the technology that they are designed to control.
Roles and Responsibilities
Security is a complex discipline and involves securing a variety of components, including applications, storage, network connectivity, and server configuration. There are many various security functions, security controls, and security technologies, so it is unlikely that a single person will able to handle all of the company’s security needs. It is also important to evaluate methods for implementing separation of duties, introduced earlier in this chapter, by splitting the responsibilities of those managing security procedures among various people.
There are some benefits to having a different person in charge of each facet of the cloud security environment. Having other people running additional configuration tests creates a system of checks and balances since not just one person has ultimate control. For example, a programmer would be responsible for verifying all of the code within their application and for making sure there are no security risks in the code itself, but the programmer would not be responsible for the web server or database server that is hosting or supporting the application. The person testing code security should be different from the person who wrote the code. Likewise, the person testing cloud service integration security should not be the person who configured it.
Vulnerability Management
In addition to comprehensive testing of all areas affecting service and performance, it is incumbent on an organization to test for vulnerabilities as well. Security testing in the cloud is a critical part of having an optimal cloud environment. It is similar to security testing in a traditional environment in that testing involves components like login security and the security layer in general.
Before doing any security tests, testers should always clearly define the scope, present it to the system owner, and get written permission to proceed. The contract in place with the cloud provider should then be reviewed to determine testing notification requirements. Inform the cloud provider of any planned security penetration testing before actually performing it unless the contract specifies otherwise.
Another thing for an organization to consider is that with a public cloud model, the organization does not own the infrastructure; therefore, the environment the resources are hosted in may not be very familiar. For example, if you have an application hosted in a public cloud environment, that application might make some application programming interface (API) calls back into your data center via a firewall, or the application might be entirely hosted outside of your firewall.
A primary security concern when using a cloud model is who has access to the organization’s data in the cloud and what are the concerns and consequences if that data is lost or stolen. Being able to monitor and test access to that data is a primary responsibility of the cloud administrator and should be taken seriously, as a hosted account may not have all the proper security implemented. For example, a hosted resource might be running an older version of system software with known security issues, so keeping up with the security for the hosted resource and the products running on those resources is vital.
Security testing should be performed regularly to ensure consistent and timely cloud and network vulnerability management. Periodic security testing will reveal newly discovered vulnerabilities and recent configuration issues, enabling administrators to remediate them before (hopefully) attackers have an opportunity to exploit them.
Common testing scenarios include quarterly penetration testing with monthly vulnerability scanning or annual penetration testing with quarterly or monthly vulnerability scanning. It is absolutely necessary to run tests at intervals specified by compliance requirements. Testing should also be conducted whenever the organization undergoes significant changes.
Cloud vendors typically require notification before penetration testing is conducted on their networks. Microsoft Azure recently announced that it no longer needs such notification. Check with your cloud vendor before conducting vulnerability scanning or penetration testing to be sure you have permission.
In this section, you will learn about the following vulnerability management concepts:
• Black-box, gray-box, and white-box testing
• Vulnerability scanning
• Penetration testing
• Vulnerability management roles and responsibilities
Testing Methods
The three basic security testing types in a cloud environment are black-box, gray-box, and white-box testing. They differ based on the amount of information the tester has about the targets before starting the test and how much they cost. Since testing is typically done at regular intervals, companies often perform black-box testing the first time and then perform gray- or white-box testing after that, assuming the testing team already knows the information gained from the first black-box test.
Table 12-3 shows each of the testing methods and their level of information and cost/effort.

Table 12-3 Testing Methods
Black-Box Test
When performing a black-box test, the tester knows as little as possible about the system, similar to a real-world hacker. This typically includes only a company name or domain name. The testers then need to discover the devices to test and determine a priority.
Black-box testing is a good method when the goal is to simulate a real-world attack and uncovers vulnerabilities that are discoverable even by someone who has no prior knowledge of the environment. However, it may not be right for all scenarios because of the additional expense required for research and reconnaissance.
Gray-Box Test
In gray-box testing, the test team begins with some information on the targets, usually what attackers would reasonably be assumed to find out through research, such as the list of target IP addresses, public DNS records, and public-facing URLs. Roles and configurations are not provided to the testing team in a gray-box test.
Gray-box testing can be a cost-effective solution if one can reasonably assume that information such as the list of target IP addresses, public DNS records, and public-facing URLs would be obtained by an attacker. Gray-box testing is faster and cheaper than black-box testing because some research and reconnaissance work is reduced, but it is somewhat more expensive than white-box testing.
White-Box Test
White-box testing is done with an insider’s view and can be much faster than black-box or gray-box testing. White-box testing makes it possible to focus on specific security concerns the organization may have because the tester spends less time figuring out which systems are accessible, their configurations, and other parameters.
Vulnerability Scanning
Vulnerability scanning is the process of discovering flaws or weaknesses in systems and applications. These weaknesses can range anywhere from host and service misconfiguration to insecure application design. Vulnerability scanning can be performed manually, but it is common to use a vulnerability scanning application to perform automated testing.
Automated vulnerability scanning utilizes software to probe a target system. The vulnerability scanning software will send connection requests to a computer and then monitor the responses it receives. It may insert different data types into web forms and analyze the results. This allows the software to identify potential weaknesses in the system.
Vulnerability scanning includes basic reconnaissance tools such as port scanning, a process that queries each TCP/UDP port on a system to see if it is capable of receiving data; footprinting, the process of enumerating the computers or network devices on a target network; and fingerprinting, a process that determines the operating system and software running on a device.
Management may review the vulnerabilities and determine which ones they want to remediate and who will be responsible for remediation. The vulnerability remediation request (VRR) is a formal request to change an application or system to remediate a known vulnerability.
Vulnerabilities are ranked with industry standards, such as the Common Vulnerability Scoring System (CVSS) numbers for vulnerability scoring. These rankings have a risk score associated with them. The CVSS numbers can be used to find additional threat and remediation information on the vulnerability in the National Vulnerability Database (NVD).
This remainder of this section discusses the phases, tools, and scope options for vulnerability scanning.
Phases
The vulnerability scanning process is organized into three phases: intelligence gathering, vulnerability assessment, and vulnerability validation. The phases are shown in Figure 12-2.

Figure 12-2 Vulnerability scanning phases
Intelligence Gathering A vulnerability scanning project begins by gathering information about the targets. Intelligence gathering is a phase of information gathering that consists of passive and active reconnaissance. Depending on your level of knowledge of the targets and the type of test (black box, gray box, or white box), this step may not be necessary.
Vulnerability Assessment The second phase is vulnerability assessment. Vulnerability scanning tools are used at this stage to scan targets for common weaknesses such as outdated or unpatched software, published vulnerabilities, and weak configurations. The vulnerability assessment then measures the potential impact of discovered vulnerabilities. Identified vulnerabilities are classified according to CVSS numbers for vulnerability scoring.
Vulnerability Validation Automated scans alone do not represent a complete picture of the vulnerabilities present on the target machines. Automated scans are designed to be nondisruptive, so they tend to err on the side of caution when identifying the presence of security weaknesses. As a result, conditions that outwardly appear to be security flaws—but which in fact are not exploitable—are sometimes identified as being vulnerabilities. It takes experience in interpreting a tool’s reports, as well as knowledge of the system, to identify vulnerabilities that are likely exploitable.
Some vulnerability validation can be performed with automated tools. Such automation reduces the manual testing burden, but there will still be cases where manual validation is required to ensure a quality deliverable. Tools are discussed in the next section.
Tools
Vulnerability scanning teams rely extensively on tools to perform tasks for them. The intelligence gathering and vulnerability scanning tasks are highly suited to automation through tools because they perform a consistent set of tasks against all targets and then output their results. A wide variety of tools can be used to perform these functions. This section discusses intelligence gathering tools first and then vulnerability assessment tools.
Intelligence Gathering Intelligence gathering tools are used to obtain basic information on targets before other tasks are performed. Two main functions of intelligence gathering include port scanning and detecting service availability. Port scanning reveals the open ports on a machine. Port scans are typically executed against a large number of devices. Tools that detect service availability identify the services that are running behind ports and whether they will respond to commands or queries.
Testers will likely use most of the intelligence gathering tools to gather information about their targets. Snmpwalk uses SNMP messages to obtain information on targets through their MIB data. See Chapter 7 for more information on SNMP. Fierce is used to find internal and external IP addresses for a target DNS name.
Sam Spade is a tool that combines several command-line functions together. These functions include Whois, a command that identifies the owner of a domain name; ping, a tool that tests to determine if a host is responding to ICMP packets; IPBlock, a tool that performs whois operations on a block of IP addresses; dig, a command that obtains resource records for a domain (see Chapter 14); traceroute, a command that identifies each hop from source to destination (see Chapter 14); and finger, a tool that obtains information on the user logged into a target machine. Please note that finger has been disabled on most machines for years now, so this tool is unlikely to work on targets today, but it remains in the Sam Spade suite of tools.
Nmap, Zenmap, and Unicornscan are each used to map a network by identifying the hosts that are online, the operating system they are running, installed applications, and security configuration such as host-based firewalls.
Table 12-4 lists some of the information gathering tools along with their uses and whether they are free or paid.

Table 12-4 Information Gathering Tools
Vulnerability Assessment Tools Some of the vulnerability assessment tools are specific to certain cloud applications. For example, the Amazon Inspector would be used for AWS servers, while the Microsoft Azure Security Center would be used for servers in an Azure environment. Nessus, Nexpose, OpenVAS, and Security Center can scan cloud systems or on-premise systems. Of the four, OpenVAS is open source and available for free. OpenVAS is an excellent tool to use to get familiar with the process.
There are two methods of performing scanning that tools may employ. These are as follows:
• Network-based scanning This form of scanning uses a centralized device that scans all machines that it can reach over the network. Network scans are fast and require no configuration on scan targets. Network scans can target most devices without the need for a compatibility check. However, network scans can be limited in what information they can obtain from devices.
• Agent-based scanning These scans rely upon software that runs locally on each target to report back information on the system, its software, and configuration. Agent-based scanning can usually provide more details than network-based scans, but it requires more effort to deploy the agents to each machine and keep them updated. It is also limited because some systems may not support agents, such as IoT devices. Still others, such as personal laptops or phones, may not be managed by the organization, so agents would not be installed on them.
Table 12-5 lists some of the vulnerability scanning tools along with their uses and whether they are free or paid. A wide variety of the tools listed are open source. Some Linux distributions come with a large number of security tools preinstalled. The most popular security distribution is Kali, but others, such as DEFT, Caine, Pentoo, and the Samurai Web Testing Framework, offer similarly valuable toolsets, albeit with a somewhat different interface. These Linux security distributions can be used as a bootable DVD or can be installed on a system for permanent use. Linux security distributions contain hundreds of security tools, including many for penetration testing, vulnerability scanning, network analysis, and computer forensics.
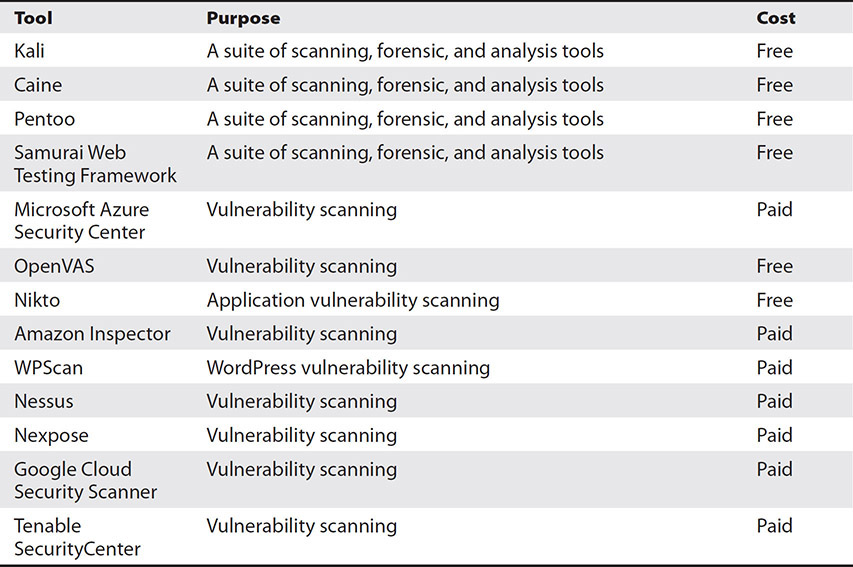
Table 12-5 Vulnerability Scanning Tools
Default and Common Credential Scanning Default or commonly used credentials are a significant vulnerability if they are present on the network. It is common for attackers to attempt password guessing on devices. Attackers try to get into systems by trying passwords in this order:
1. Try default credentials
2. Try commonly used passwords
3. Brute force or dictionary attack to reveal weak passwords
Companies can protect themselves by scanning their own systems or those they have in the cloud for default, commonly used, or weak credentials. They do this by submitting authentication requests using databases of potential passwords. The easiest way to get in is if a device is still using the password supplied by the manufacturer. These are known as the default credentials, and these are public knowledge because they are contained in user manuals and other documentation.
If a system does not accept the default credentials, the testing team will next try to gain access to systems using databases of commonly used credentials. These databases are built by analyzing password dumps from large-scale attacks. For example, the CyberNews investigation team analyzed some of these password dumps. It published the top ten most common passwords as of February 2021. These included the following:
1. 123456
2. 123456789
3. qwerty
4. password
5. 12345
6. qwerty123
7. 1q2w3e
8. 12345678
9. 111111
10. 1234567890
If neither of these methods works, the testing team may attempt to obtain access by performing brute force password cracking, where all possible combinations of passwords are tried, or a dictionary password cracking attack, where a list of passwords obtained from common dictionary words and permutations of those words with common dates, places, and other information is tried against the systems. Suppose users have set a weak password, such as one that is very short or not very complex. In that case, these cracking attempts will identify that password quickly.
Once the scans are complete, the team will provide the company with a list of identified credentials so that those credentials can be changed and users or administrators trained on better password practices.
Scope
A vulnerability scan can cover different scopes such as external scanning, internal scanning, web application scanning, or a combination.
• External vulnerability scan An external scan is conducted from outside the company’s internal network, on Internet-facing nodes such as web servers, e-mail servers, FTP servers, and VPN servers.
• Internal vulnerability scan An internal vulnerability scan is conducted from within the company cloud, targeting servers, workstations, and other devices on the corporate cloud.
• Web application vulnerability scan Web applications are often big targets because they are built to continually interface with the outside world. They often contain valuable information. Web application scans use a different set of tools geared toward assessing the web platforms and the types of applications and frameworks that run on them. Web applications require close attention by the testing team, as there can be significant variations in how each application works depending on its purpose and role. For example, an enterprise resource planning (ERP) system functions much differently than an asset tracking system. The ERP system has many more interconnections and is functionally more complex than the asset tracking system, just to name some of the differences.
Scans can be performed through the cloud provider’s services such as Microsoft Azure Security Center, Google Cloud Security Scanner, or Amazon Inspector. Some of these tools are built to scan the types of systems that reside on the cloud vendor’s network, while others are more flexible. For example, Google Cloud Security Scanner scans Google App Engine apps for vulnerabilities, while Amazon Inspector can analyze any applications running within Amazon Web Services (AWS).
Credentialed and Noncredentialed Scanning Vulnerability scans can be performed with or without valid credentials to the resources. A scan without credentials is called a noncredentialed scan. This simulates what an attacker would see if they did not have access to a valid user session. Credentialed scanning uses one or more valid credentials to determine what vulnerabilities can be identified under that user context. Some scans will include multiple types of credentials, such as a standard user account, an administrative account, and a service account.
Credentialed scanning generally provides more information than a noncredentialed scan, and it can help to eliminate some false positives as well. It is common for noncredentialed scans to identify multiple possible operating systems for a target device or see surface-level vulnerabilities. In contrast, a credentialed scan can more accurately identify version information and configuration settings.
Penetration Testing
Penetration testing evaluates system security at a point in time by attacking target systems as an outside attacker would and then documenting which attacks were successful, how the systems were exploited, and which vulnerabilities were utilized. Penetration testing provides realistic, accurate, and precise data on system security.
A penetration test is a proactive and approved plan to measure the protection of a cloud infrastructure by using system vulnerabilities, together with operating system or software application bugs, insecure settings, and potentially dangerous or naïve end-user behavior to obtain access to systems. Such assessments also help confirm defensive mechanisms’ effectiveness and assess end users’ adherence to security policies.
Tests are usually performed using manual or automated technologies to compromise servers, endpoints, applications, wireless networks, network devices, mobile devices, and alternative potential exposure points. Once vulnerabilities are exploited on a particular system, pen testers might commit to using the compromised system to launch later exploits at other internal resources, in a technique known as pivoting. Pivoting is performed to incrementally reach higher security clearance levels and deeper access to electronic assets and data via privilege increase.
This section’s remainder discusses the phases, tools, scope options, and testing limitations for penetration testing. The section concludes with a discussion on roles and responsibilities. Security testing requires specialized skill sets and should be performed by a team that is independent of DevOps.
Phases
The penetration testing process is organized into seven phases: intelligence gathering, vulnerability assessment, vulnerability validation, attack planning and simulation, exploitation, postexploitation, and reporting. The phases are shown in Figure 12-3.
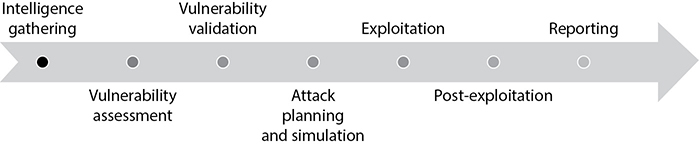
Figure 12-3 Penetration testing phases
As you can see, penetration testing begins with the three phases of vulnerability scanning, covered in the previous section, so they will not be covered again. We will start with phase 4: attack planning and simulation.
Attack Planning and Simulation Once the vulnerabilities have been enumerated and validated, the next step is to determine how the vulnerabilities can best be used together to exploit systems. Some of this comes with experience as penetration testers learn to see the subtle relationships between hosts that automated tools and complex scripts cannot detect. An initial plan of attack is built from this data.
This phase also involves attack plan simulations. Simulations of the exploits outlined in the attack plan are performed in a test environment or automatically in penetration testing tools to eliminate lingering false-positive results and refine the attack plan through the simulations. A full attack strategy can then be put together to be employed in the exploitation phase.
Exploitation In the exploitation phase, penetration testers establish access to a system or resource by employing exploit packages that take advantage of discovered vulnerabilities. Penetration testing activities are performed for the approved scope following the attack strategy.
Postexploitation In this stage, evidence of exploitation of the vulnerabilities is collected and remnants from the exploits are removed. As part of this, penetration testers clean up accounts and resident files that were put in place to perform the exploits.
Reporting The last phase of penetration testing is to put all the details of the tests, including what worked and what didn’t, into the report. Information on the security vulnerabilities that were successfully exploited through penetration testing is collected and documented in the report. The report is provided to a risk manager or someone in charge of security in the organization. This person will then coordinate with other teams to remediate the vulnerabilities, track remediation, and possibly schedule validation tests to ensure that the vulnerabilities identified have been successfully remediated.
Reports rank findings by risk rating and provide recommendations on how to remediate the items.
Tools
A wide variety of tools can be used to perform penetration testing. Table 12-6 lists several popular penetration testing tools. Some tools are large suites with various components, while others perform a particular task. Many tools are command-line driven, requiring familiarity with the command structure and usage.

Table 12-6 Penetration Testing Tools
Penetration testers may try to crack passwords in order to test the strength of passwords users have created. Brute force attempts are usually made on a password database that has been downloaded from a system. Testers first obtain access to the password database and download it. However, most password databases cannot be read because the passwords in them are hashed. Penetration testers use a computer with a powerful CPU or GPU or a network of distributed systems to try all possible combinations until they get in. The number of possible combinations increases exponentially as the number of characters in the password increases.
Scope
A penetration test can cover any of the following different scopes or a combination of them:
• External penetration testing External penetration testing is conducted from the Web, from outside the company’s internal network, with the targets being the company’s web-facing hosts. This may sometimes include web servers, e-mail servers, FTP servers, and VPN servers.
• Internal penetration testing Internal penetration testing is conducted from within the company network. Targets may include servers; workstations; network devices such as firewalls or routers; and IoT devices such as webcams, IP lighting, or smart TVs.
• Web application penetration testing Web application penetration testing is concerned with evaluating web-based applications’ security by issuing attacks against the site and supporting infrastructures, such as database servers, file servers, or authentication devices.
• Wireless penetration testing Wireless penetration testing evaluates wireless access points and common weaknesses in a company’s wireless network. This includes attempting to crack wireless passwords, capture traffic on the wireless network, capture authentication information, and obtain unauthorized access to the network through a wireless connection. Wireless penetration testing also scans for rogue access points and peer-to-peer wireless connections.
• Physical penetration testing Physical penetration testing evaluates an outsider’s ability to obtain direct access to company facilities and areas containing sensitive data.
• Social engineering penetration testing Social engineering penetration testing can involve a person directly interacting with individuals, but it is more common to use remote social engineering tactics, since these are most often employed by attackers.
Remote social engineering evaluates employee response to targeted phishing attacks. The penetration tester requests a listing of e-mail addresses to be tested. A custom phishing e-mail is crafted and sent employing a spoofed source e-mail address or an external one that appears legitimate to every employee. The e-mail message will encourage the user to perform a range of nonsecure activities like clicking a link, visiting an unauthorized website, downloading a file, or revealing their username and password.
Testing Limitations
Testing limitations affect the scope of penetration testing by defining types of testing that are not allowed. Typical testing restrictions exclude from the scope memory corruption tests and similar tests that are likely to cause instability. Such testing is an assumed limitation when testing production environments. Denial of service attacks are also often excluded from the scope of testing.
EXAM TIP The difference between a penetration test and a vulnerability assessment is that a penetration test simulates an attack on the environment.
Roles and Responsibilities
Security testing can be a complicated procedure and involves testing various components, including applications, storage, network connectivity, and server configuration. Security testing requires specialized skill sets and should be performed by a team that is independent of DevOps.
Vulnerability scanning is an easier task to perform than penetration testing, and penetration testing requires vulnerability scanning, so this is an obvious place to define roles. Vulnerability analysts detect and validate vulnerabilities and then pass that information to penetration testers who might be more familiar with specific areas such as operating systems, storage, software development, web services, communications protocols, and so forth. These penetration testers are also familiar with how such services can be exploited, and they stay up to date on new vulnerabilities, exploits, and tools.
The social engineering penetration tester may also be a different role, since this requires a knowledge of human behavior and what will most effectively entice victims to read phishing e-mails and follow the instructions given.
The most crucial detail is that the security testing team should be distinct and independent from the DevOps team. Such a separation of duties ensures that the test accurately represents what an attacker could do. Furthermore, it provides a level of objectivity. It reduces the likelihood of bias from internal knowledge or a conflict of interest that could arise if security testing team members have a personal stake, for example, in an application being launched on time.
Considerations Before You Scan or Test
Penetration tests and vulnerability scans should be designed to have minimal or no impact on the production environment. The following are some of the methods testers use to protect availability and data integrity:
• Confirming in-scope machines, testing times, and duration before testing to ensure that the correct devices are tested.
• Providing operations teams with the IP addresses testers use to conduct penetration tests. This allows the ops team to quickly determine if actions they observe result from penetration testing or an active attack from some other actor. This step will not be performed if the test is designed to test the operations team’s responsiveness.
• Executing scans and other automated tasks slowly to not consume excessive network capacity or other computing resources.
• Subjecting vulnerability exploits to rigorous testing to eliminate methods that might cause harm to customer systems.
• Collecting the minimum evidence necessary to demonstrate the exploitability of a vulnerability.
• Documenting steps performed and actions taken.
Still, no process is perfect, and there is always the potential that something could happen in the test that would affect the availability or data integrity of the systems under test. The goal of a pen test is to identify and determine the exploitability of vulnerabilities in target systems. As such, there is a possibility that such exploits could make changes to customer systems. The following measures can help protect against unforeseeable outcomes in your pen test or vulnerability scan:
• If possible, perform testing on a nonproduction environment, such as a testing system or QA system. This environment should be an exact or very near duplicate of the production environment so that the risks identified in it can be extrapolated to the production environment. However, the environment should be separate so as to not cause interference with production data.
• Test the application for common malicious input before testing. Many unforeseeable issues are caused by a lack of input validation. This includes public-facing web forms that send e-mails or populate data in a database. If proper input validation is not performed on these, automated tests for injection vulnerabilities could result in excessive e-mails or junk data in a database.
• Keep in mind that account permissions will give the tester and any automated tool the ability to perform the same functions of that account. If you are aware of functions that may lead to lack of availability, provide the testing team with a listing of the function and the directory under which it is performed so they may take special care to avoid troublesome input concerning these functions. This may include testing this function individually or manually where necessary.
• Create a backup of this environment prior to testing. This includes, at a minimum, a snapshot of systems, as well as a database backup.
Incident Response
At some point, your company is going to have to deal with a cybersecurity incident. An incident is an event that is deemed to have caused harm to the company or harm to its customers, partners, or stakeholders via company systems or employees. This definition used the term harm a few times. I define harm as the diminished organizational effectiveness, value, or reputation or monetary, physical, reputational, or other tangible loss for employees, members, stakeholders, or partners. It is important to contrast an incident with an event. An event is an observed occurrence that is potentially suspicious. Security Operations Center (SOC) teams may investigate many events without any of them being an incident.
Incident response (IR) consists of the actions taken to handle an incident. This begins before an incident occurs by preparing for an incident. Following the discovery of an event classified as an incident, IR teams will go through a series of steps to resolve the incident. This section covers the preparation steps, followed by a description of different types of incidents. The section concludes by providing you with details on each major step in the incident response procedure. For more information, the National Institute of Standards and Technology (NIST) has produced special publication 800-61 titled “Computer Security Incident Handling Guide.”
Preparation
It is best to prepare for an incident before one occurs. One of the most critical facets of incident handling is preparedness. Preparation allows for an organized and clear response to incidents. It also limits the potential for damage by ensuring that response plans are familiar to all employees.
Companies that prepare for an incident end up resolving incidents faster with fewer mistakes. This results in less impact to operations and their brand image and costs them less money.
Preparation begins with documenting an incident response plan and then training employees and contractors on the roles they will play. Lastly, tabletop exercises help familiarize staff with the plan and identify deficiencies before a real incident occurs.
Documentation
Incident documentation helps guide decision-making during an incident and record the actions taken to investigate and resolve the incident so that the company can provide evidence of their due diligence, properly notify affected individuals or companies, and continuously improve.
Essential incident documentation includes
• Incident response policy
• Incident response plan (IRP)
• Incident reporting form
• Chain of custody
Incident Response Policy The incident response policy outlines the overall company approach to incident response. However, it does not get into how an incident will be handled or specific incident response steps. Those are addressed in the incident response plan. Critical elements of an incident response policy include
• Definitions This includes definitions of what constitutes an event, incident, and a data breach.
• Purpose This section describes why incident response is important and what the organization hopes to achieve with its incident response activities.
• Incident reporting expectations This section outlines when reporting should be performed and who should be notified.
• Roles and responsibilities This section outlines which team members will be involved in incident response and what their jobs will be. This may list people by name, but it is more common to put in their titles, such as CSO, director of information technology, or senior network engineer. Table 12-7 shows some roles and responsibilities that might be included in a policy. It is also essential to establish several incident response contacts who will review incident report forms and potentially contact others to initiate the IR.

Table 12-7 IR Roles and Responsibilities
Incident Response Plan The IRP specifies the steps that will be performed to identify, investigate, and resolve information security incidents. This includes how long it will take to respond to an incident, recovery times, investigation times, the members of the incident response team, how employees are to notify the group of incident indicators, the indicators of an incident, and how the team will vet incidents. The IRP will go through each of the incident response procedures discussed later in this chapter and explain the steps that will be performed.
Data may need to be retrieved from multiple cloud vendors, so the incident response policy will specify how that will take place. This includes how data will be packaged from the cloud provider and how long it will take for it to be delivered to the cloud consumer.
Toward the beginning of an IRP will be a contact list of each person who is a member of the IR team, their role, and contact information. Alternates will be listed for each person so that another person can be contacted if the primary is unavailable. You do not want to be in a situation where one role is not represented.
The IRP will next outline a call tree. This is a diagram showing how each person will be contacted. It does not make sense for one person to call everyone, because that would take too much time. Instead, one person might call two others, who will reach more people so that the message is quickly relayed to the entire team. Figure 12-4 shows a sample call tree. Each person is indicated by their role.
Figure 12-4 Call tree
EXAM TIP The incident response plan must factor in the communication and coordination activities with each cloud provider. This can add significant time to an incident response timeline.
Incident Reporting Form The incident reporting form documents who reported the incident, the date of the incident, and any pertinent facts identified when the incident was reported. The incident report is the document that is provided to the incident response team when it is called together, so it will not contain all the details discovered in the course of the IR, but it will contain those details that were initially discovered. A sample reporting form is provided here.

Chain of Custody Chain of custody documentation tracks when the evidence is acquired, who released the evidence to the forensic person, where the evidence is stored, and each time the evidence is accessed. A sample chain of custody form is shown in Figure 12-5.

Figure 12-5 Chain of custody form
Training
Appropriate training should be provided to technical operations personnel and other relevant staff regularly. Training helps update knowledge and skills in handling security incidents. Each time the incident response plan is updated, training should be performed to cover the changes that were made.
Tabletop Exercises
Tabletop exercises are a great way to test out an IRP and familiarize staff with the process they will need to follow when an actual incident occurs. A tabletop exercise is facilitated by someone who has prepared a scenario that the IR team then works through. For example, the IR team may explore all the steps they would follow in a ransomware incident. They work their way through the IRP and document any steps that are missing details, corrections, and improvements to the plan. The plan is then updated to include these elements.
Incident Types
A security incident involves events that occur either by accident or deliberately that affect systems negatively. An incident may be any event or set of circumstances that threaten the confidentiality, integrity, or availability of information, data, or services. For example, incidents could include unauthorized access to, use, disclosure, modification, or destruction of data or services used or provided by the company.
Additionally, incidents can be classified by the type of threat. These include internal and external threats.
• Internal threat An internal threat is one that occurs from a trusted employee or contractor. Examples of internal threats include users misusing resources, execution of malicious code, or attempts at unauthorized access by organizational accounts. The most severe internal threats involve highly privileged users, known as administrators, misusing their privileges or hiding unauthorized activities.
• External threat An external threat is one that occurs by an actor that is not associated with the organization. Examples of external threats include an unauthorized person attempting to gain access to systems, attacks on availability such as denial of service, phishing, and malware.
Incidents can be further classified into types based on the type of event or service that is targeted. Some of these are provided here as examples:
• Data breach A data breach is an incident involving the disclosure of sensitive information to an unauthorized party. Breaches require notification of affected individuals within a defined period following discovery and typically involve the expertise of an attorney to interpret the regulatory and contractual obligations.
• Criminal activity This could include the presence of illegal material on systems, such as child pornography or illegal software.
• Denial of service Attacks on the availability of systems or other resources.
• Malware Code that is designed to harm organizational systems. Malware includes viruses, Trojans, worms, bots, keyloggers, rootkits, or ransomware.
• Policy violation Organizational policies specify how employees, contractors and others will work with information. Some policies can be enforced through technical controls, but others must be adhered to. When someone does not follow the policy, such as failing to verify ID before providing sensitive information, not encrypting data as required by policy, or failing to report indicators of an incident, the company and its customers can suffer harm.
• Compliance violation This typically involves a privacy concern, such as not following HIPAA procedures or accidental disclosure of personal data to an unauthorized person.
• Rogue services Unknown services, software, or systems identified could have been placed there by a malicious entity.
• Phishing interaction A user that responds to a phishing message or opens attachments in a phishing message.
• Unauthorized access Any access to files or systems from an unauthorized device or user account.
• Vandalism Defacement of a website or destruction of property.
Incident Response Procedures
This section outlines the steps the IR team will go through when handling an incident. Each of these should be outlined in the IRP discussed earlier. These steps include
• Identification
• Preservation
• Investigation
• Containment
• Eradication
• Recovery
• Reflection
Identification
A security incident may not be recognized straightaway; however, there may be security breach indicators, system compromise, unauthorized activity, or signs of misuse within the environment, including cloud resources. Some indicators include
• Excessive or anomalous login activity
• Activity by accounts that have been disabled
• Significantly increased remote access activity
• Computers that are contacting a large number of other network systems
• Excessive file access or modification
• Identification of malware
• Tampering with security systems or other sensitive equipment, such as point of sale (POS) systems
• Lost or stolen devices
• Corrupt backups
• Lost or stolen backups
If a person suspects an incident, they should report the incident to their designated incident response contacts and complete the incident reporting form.
Preservation
The preservation phase is concerned with preserving evidence for the investigation so that important information is not lost. IT professionals are sometimes so concerned with getting things back up and running that they restore systems, eliminating valuable evidence that could help determine the root cause.
Evidence Acquisition In the preservation phase, forensic teams will take forensic images of equipment or virtual machines. This could also include snapshots or forensic copies of log files, packet captures, memory captures, or e-mail exports.
Each piece of evidence that is collected must be tracked for the chain of custody. This ensures that evidence is not modified or handled by unauthorized individuals. Without the chain of custody, the integrity of the evidence cannot be assured. Chain of custody forms track when the evidence is acquired, who released the evidence to the forensic person, where the evidence is stored, and each time the evidence is accessed.
Investigation
The investigation phase is concerned with determining the root cause and the scope. Root cause analysis (RCA) is a process where information is gathered during the containment phase and additional information collected is analyzed. The team determines the factor or factors that led to the incident occurring, such as a vulnerable system, a user clicking on a phishing message, drive-by malware, or someone not following standard operating procedures. If a root cause cannot be determined, multiple potential reasons will be listed and ranked by likelihood.
Scope Scope analysis is concerned with identifying affected individuals, such as the number of persons whose personal information was disclosed or how many credit card numbers were stolen. This information is then provided to legal counsel so that they can determine the company’s notification requirements under the law.
Containment
The containment stage’s primary objective is to limit the scope and magnitude of an incident as quickly as possible. The first step is to determine whether to isolate affected machines and the method for doing so. There are usually three considerations here:
1. Shut down the system.
2. Disconnect the system from the network or disable its network port. In the case of a large number of systems, the switch or switches they are connected to can be turned off.
3. Allow the device to continue to run. This option is only selected when you wish to monitor the system to potentially track attackers or malicious insiders so that they can be prosecuted. The decision of whether to allow this depends on the risk continued operation of the system presents to the company.
One common incident is malware. In such cases, companies will typically move quickly to eradicate malicious code, such as viruses, bots, Trojans, or worms.
Eradication
The next priority, after containing the damage from a security incident, is to remove the cause of the incident. In the case of a virus incident, the company will remove the virus from all systems and media by using one or more proven commercial virus eradication applications or OS reinstallation, as needed. Some of these steps include
• Improve defenses In this step, the IR team implements appropriate protection techniques such as firewall and router access control lists. It will continue monitoring the intrusion detection system.
• Run vulnerability scans The IR team will scan the system for vulnerabilities to shore up defenses and potentially identify an avenue that could’ve been used in the attack.
Recovery
In the recovery phase, the company brings systems back to normal functional states. The recovery steps depend on the nature of the incident, but some include removing malicious code, restoring systems, blocking IP addresses or regions, failing over to secondary equipment or sites, or deploying new systems.
Once systems have been recovered, the next step is to verify that the operation was successful and that the system is back to its normal operating condition. This involves testing the systems and monitoring them for anomalous activity or other indicators of compromise that may have escaped detection. This level of monitoring should be greater than standard monitoring for organizational systems.
Reflection
The last step is to follow up on an incident after recovery to improve incident response procedures. This involves documenting how well the team responded to the incident, as well as the costs associated with the incident. Understanding the costs will help in determining whether it makes sense to invest additional money or other resources into prevention technologies, procedures, or training.
Debrief Following the incident, it is best to sit down with the IR team to review the incident and identify lessons learned throughout the process. This aids in improving future incident response and refining the IRP. The debrief pays particular attention to questions like these:
• Were we sufficiently prepared for the incident?
• Did we meet our time objectives for discovering the incident, resolving the incident, restoration of systems, etc.?
• Would other tools have helped us resolve the incident more quickly?
• Was the incident effectively contained?
• How could we have better communicated during the incident?
Document Costs Following the debrief, the company will review the staff time required to address incidents, losses due to lost productivity, lost customers, regulatory fines, legal work, increased insurance premiums, ransom payments, and other costs associated with the incident. The goal here is to determine whether additional funds should be budgeted for security efforts.
Chapter Review
This chapter covered the concepts of cloud security engineering, security governance and strategy, and vulnerability management. Cloud security engineering is the practice of protecting the usability, reliability, integrity, and safety of information systems, including network and cloud infrastructures and the data traversing and stored on such systems.
One method of engineering secure cloud systems is to harden them. Hardening involves ensuring that the host or guest is configured to reduce the risk of attack from either internal or external sources. Another method is to layer security technologies on top of one another so that systems are protected even if one security system fails because others guard against intrusion. Next, incorporate the principle of least privilege by granting employees only the minimum permissions necessary to do their job. Along with least privilege is a concept called separation of duties, a process that divides the responsibilities required to perform a sensitive task among two or more people so that one person, acting alone, cannot compromise the system.
Security governance and strategy begin with the creation of company security policies. Security policies set the organizational expectations for certain functional security areas.
Data classification can help companies apply the correct protection mechanisms to the data they house and maintain. Data classification is the practice of sorting data into discrete categories that help define the access levels and type of protection required for that data set. An organization establishes security policies to set its expectations for certain functional security areas. Some of these expectations may come out of standards, best practices, or compliance requirements.
Companies perform assessments and audits to identify areas where they are not meeting organizational expectations, contractual agreements, best practices, or regulatory requirements. Regulations such as HIPAA, SOX, and PCI DSS specify requirements for security controls, procedures, and policies that some organizations must comply with.
Cloud security professionals have limited time and much to do. Consider how existing security management processes can be automated. Some examples include removing inactive accounts, eliminating outdated firewall rules, cleaning up obsolete security settings, and maintaining ACLs for target objects.
It is essential to test systems for vulnerabilities and to remediate those vulnerabilities so that systems will be protected against attacks targeting those vulnerabilities. Vulnerability management consists of vulnerability scanning and penetration testing to identify weaknesses in organizational systems and the corresponding methods and techniques to remediate those weaknesses. Vulnerability scanning consists of intelligence gathering, vulnerability assessment, and vulnerability validation. Penetration testing includes the steps in vulnerability scanning, as well as attack planning and simulation, exploitation, postexploitation, and reporting.
Lastly, companies need to prepare for an incident by developing plans, training on those plans, and then executing incident response procedures. These procedures include identification, preservation, investigation, containment, eradication, recovery, and reflection.
Questions
The following questions will help you gauge your understanding of the material in this chapter. Read all the answers carefully because there might be more than one correct answer. Choose the best response(s) for each question.
1. You have been asked to harden a crucial network router. What should you do? (Choose two.)
A. Disable the routing of IPv6 packets.
B. Change the default administrative password.
C. Apply firmware patches.
D. Configure the router for SSO.
2. You are responsible for cloud security at your organization. The chief compliance officer has mandated that the organization utilize layered security for all cloud systems. Which of the following would satisfy the requirement?
A. Implementing ACLs and packet filtering on firewalls
B. Configuring a DMZ with unique ACLs between networks and an IDS/IPS
C. Specifying separation of duties for cloud administration and training additional personnel on security processes
D. Defining a privacy policy, placing the privacy policy on the website, and e-mailing the policy to all current clients
3. Which policy would be used to specify how all employee-owned devices may be used to access organizational resources?
A. Privacy policy
B. Mobile device policy
C. Remote access policy
D. BYOD policy
4. Which policy or set of rules temporarily disables an account when a threshold of incorrect passwords is attempted?
A. Account lockout policy
B. Threshold policy
C. Disabling policy
D. Password complexity enforcement rules
5. Which type of test simulates a network attack?
A. Vulnerability assessment
B. Establishing an attack baseline
C. Hardening
D. Penetration test
6. Which of the following phases are unique to penetration testing? (Choose all that apply.)
A. Intelligence gathering
B. Vulnerability validation
C. Attack planning and simulation
D. Exploitation
7. Which of the following describes a brute force attack?
A. Attacking a site with exploit code until the password database is cracked
B. Trying all possible password combinations until the correct one is found
C. Performing a denial of service (DoS) attack on the server authenticator
D. Using rainbow tables and password hashes to crack the password
Answers
1. B, C. Changing the default passwords and applying patches are important steps in hardening a device.
2. B. Layered security requires multiple overlapping controls that are used together to protect systems. Configuring a DMZ with ACLs along with an IDS/IPS provides multiple layers because an attacker would have to compromise a machine in the DMZ and then pivot from that machine to another machine in the internal network. However, IDS/IPS systems might detect this activity, notify administrators, and block the attacker from making the connection.
3. D. The BYOD policy is the correct answer here. Bring your own device (BYOD) is a device that is employee owned, not owned by the company; this policy governs how those devices may be used to access organizational resources.
4. A. An account lockout policy temporarily disables an account after a certain number of failed logons. For example, if the policy were set to 3, then a user’s account would be temporarily disabled (locked out) after three failed tries until an administrator unlocks it.
5. D. Penetration tests simulate a network attack.
6. C, D. Penetration testing includes all the steps from vulnerability scanning. The two steps that are unique to penetration testing here are attack planning and simulation and exploitation.
7. B. A brute force attack tries all possible combinations of a password. A brute force attack relies on the ability to try thousands or millions of passwords per second. For example, at the time of this writing, the password cracking system that is used at TCDI for penetration testing can try 17 million passwords per minute in a brute force attack.