
402 Computer Architecture and Organization
In other words, when one software is working on its critical section, the other software interested to
work with the same data base, must wait for the rst one to complete. To achieve this, processors of
multiprocessor system may use lock bit to indicate whether the shared data portion is under use or not.
It is customary for all software to check the lock bit before executing its critical section. Before entering
within the critical section, provided it is free to enter, the concerned processor sets the lock bit so that
no other processor may use the shared data. After completion of execution of the critical section the
processor clears the lock bit, allowing other processor to work with the shared data, if necessary. We
have already discussed about critical section in Chapter 11.
The problem and its solution described above are valid for a shared data base, i.e., when multiple
processors are sharing a common data base. However, when the copy of this data base is available within
different processor’s cache, the solution technique would be different, which we are about to discuss now.
13.4.3 Cache Coherence
In most of the con gurations of parallel processing, processors are equipped with their own cache mem-
ory. Generally, there are different caches designated as instruction cache and data cache. The operations
related to this data cache are likely to change its value. Unless these updated values are echoed back
to their proper original places, other processors requiring dealings with the same data would not be
using with the correct values. Note that this problem is different from the previous problem of shared
data base, as in the present case, there may be multiple copies of the same data, which did not occur in
the previous case. The present problem is designated as the problem of cache coherence and might be
solved in a variety of methods, two most important of which are
R Write-back process
R Write-through process
These two methods were explained in Chapter 7 (Section 7.4.8). In short, for write-back technique, any
change in cache is immediately taken care of and the related portion of the main memory is updated
after that, but at the earliest available chance. Therefore, there is always a time-lag between cache updat-
ing and related main memory updating in write-back process. In case of write-through process, both
cache memory as well as the related portion of the main memory are updated simultaneously, leaving
no scope of any discrepancy between the two.
13.5 SUPER-SCALAR OPERATION
So far in this chapter, we have discussed about parallel processing using multiple processors. In
Chapter 12, we have discussed about the basic principles of pipeline architecture, where using vari-
ous techniques, the throughput of a single-processor-based-system might be enhanced. The super-
scalar operation and processor, which we are about to discuss now, stands in-between these two
poles. Instead of interconnecting multiple processors, in this operation, only one processor is used.
However, within the processor itself, there are multiple processing modules , so that, using pipeline
technique, more instructions are executed concurrently.
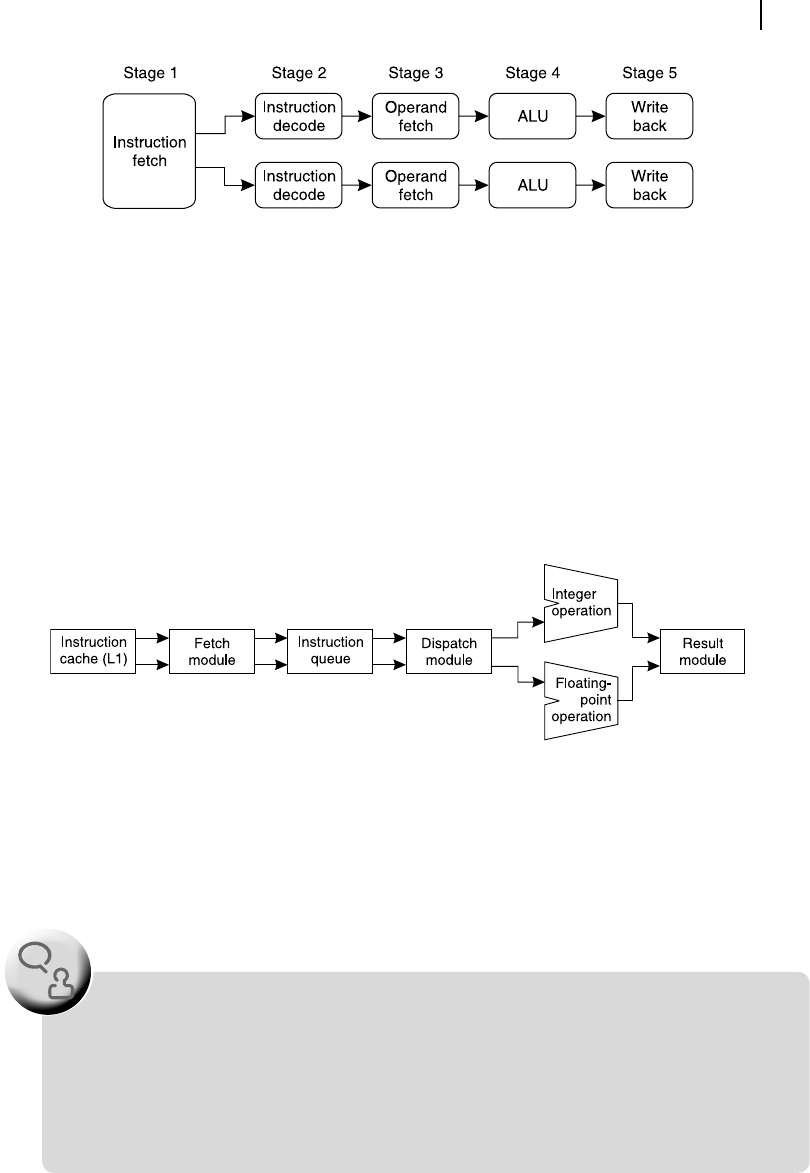
As an example case, Figure 13.11 illustrates dual pipelined super-scalar architecture. This uses a
5-stage pipeline with fetch-decode-operand fetch-execute-write back stages for execution of instruc-
tions. However, the difference with other pipelines, which we have discussed in Chapter 12, is its
instruction fetch unit. Instead of fetching only one instruction at a time, it fetches two instructions at a
time and feeds both pipeline with one instruction each. Therefore, the speed of execution may be con-
sidered to be doubled in such a con guration.
M13_GHOS1557_01_SE_C13.indd 402M13_GHOS1557_01_SE_C13.indd 402 4/29/11 5:26 PM4/29/11 5:26 PM
Parallel Processing and Super-Scalar Operation 403
In this type of pipelines, the designer must be careful about one situation. If the instruction-pair being
processed are dependent upon each other, then a con ict would take place and incorrect result would be
produced. Therefore, in such architecture it is the duty of the compiler to ensure that the instruction-pair
being processed are independent upon each other. In the case of data dependency, only one out of two
instructions, the rst one, may be fed into the pipeline and the remaining instruction of the pair may be exe-
cuted with the following instruction. As a matter of fact, Pentium uses this technique in its dual pipeline.
As an alternative of the above example case, we may consider a processor with two independent inter-
nal modules; one for oating-point operations and another for normal integer operations (Figure 13.12). In
this case both modules may work independently and in parallel. The compiler may rearrange the instruc-
tions in such a fashion that both modules remain busy, increasing the throughput of the processor. Such a
processor is designated as a super-scalar processor and its operation is known as super-scalar operation.
Figure 13.11 Example of a super-scalar architecture with two pipelines
Figure 13.12 Super-scalar operation involving two execution modules
Let us spend some more time for Figure 13.12 . To start with, the reader should observe that two
parallel paths are shown for interconnection for any pair of modules (except the operation-units). This
indicates that the ow of instruction in the pipeline would follow in a parallel track, which is the unique-
ness of super-scalar operation.
Most of the modern processors are super-scalar in their architecture and capable of executing
multiple instructions in single cycle. In general, they are equipped with a special instruction pre-
decoder, which generates multiple instruction queues (or single queue with multiple threads). The
number of ALUs (integer as well as floating point) are multiple and the scheduler is smart enough
to keep all of them busy in most of the tie. Interested reader is requested to go through some of
the appendices of this book regarding some more details about this aspect.
F
O
O
D
F
O
R
T
H
O
U
G
H
T
M13_GHOS1557_01_SE_C13.indd 403M13_GHOS1557_01_SE_C13.indd 403 4/29/11 5:26 PM4/29/11 5:26 PM
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.