
Parallel Processing and Super-Scalar Operation 407
In this relation, the + symbol denotes logical OR operation. The reader should note that in this sys-
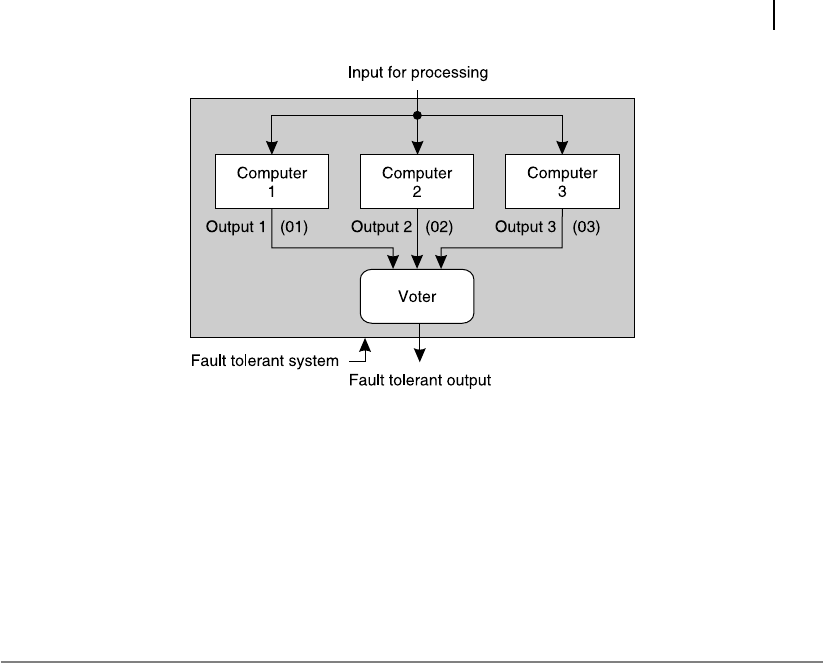
tem, purpose of two extra computers is to ensure correct output in spite of eventual malfunctioning of
the third one. As these two extra computers are not contributing in any other manner but just to ensure
standard output, they are designated as redundant .
SUMMARY
Parallel processing is a special type of computer architecture, essential for high-speed computing
involving very large data set. Multiple processors are to be interconnected and the software to be
properly sub-divided and dispatched to maintain its ef ciency. Four basic models, SISD, SIMD, MISD
and MIMD (known a Flynn’s classi cation) are possible for implementing the parallel processing archi-
tecture, out of which MIMD is the most ef cient one. There may be three different con gurations of it,
designated as UMA, NUMA and distributed memory system.
For the purpose of interconnections, various topologies are available, some of which are single bus,
tree, mesh, hypercube, crossbar, multi-stage, ring and so on. In some of these topologies, e.g., single
bus, or ring, processors are directly interfaced with each other. In other cases, like mesh or multi-stage,
separate switches serve the purpose of interconnections.
One of the most dif cult task for implementing parallel processing is to subdivide the executable
program into several modules that might be processed by different processors concurrently. Sometimes
the programs are developed in that manner with indicative statements (PARBEGIN and PAREND) to
serve this purpose with lesser effort. In other cases, the compiler or the operating system has to nd
suitable sub-divisions within the executable software.
In super-scalar operation one processor with multiple execution units are employed with multiple
instruction fetch at same clock cycle to enhance the performance. In the case of array processing,
several smaller processors are interfaced with and controlled by a larger central processor. In the
case of vector processors, large vector register set and pipelined ALU operation saves time for vector
operations.
Figure 13.15 Example of a fault tolerant system (hardware fault)
M13_GHOS1557_01_SE_C13.indd 407M13_GHOS1557_01_SE_C13.indd 407 4/29/11 5:26 PM4/29/11 5:26 PM
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.