
470 Computer Architecture and Organization
C.6 PIPELINE OF POWER PC
Power PC adopted a RISC based super-scalar architecture with three independent pipelines for execu-
tion at a rate of three instructions per cycle. These three independent units of Power PC are:
R Integer unit
R Floating point unit and
R Branch processing unit.
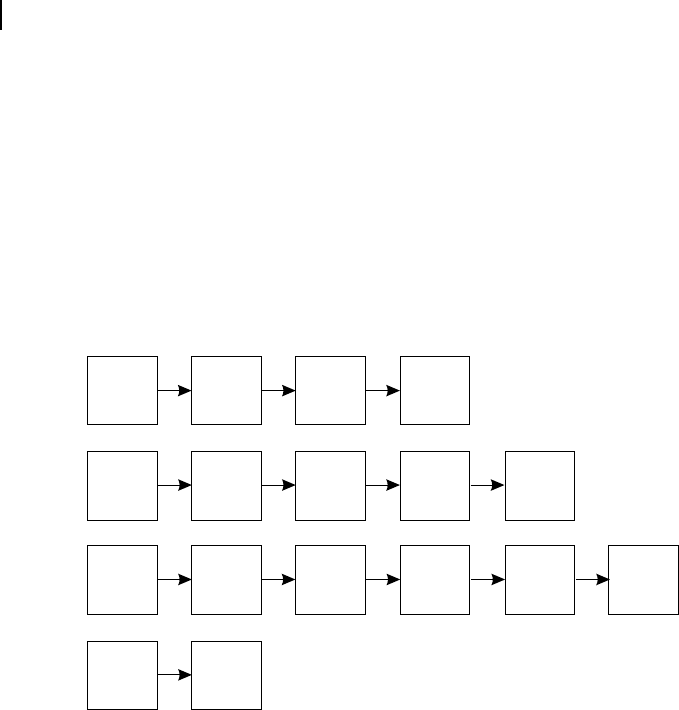
The stages for these three pipelines are different and explained through Figure C.5 . The reader may
compare Figure C.5 with Figure B.4 to note the differences in the pipeline stage architecture between
the two processors, namely Power PC and UltraSPARC.
Figure C.5 Power PC pipeline stages for (a) Integer (b) Load/Store (c) Floating point
and (d) Branch instructions
Fetch
Dispatch/
decode
Execute
Fetch
Dispatch/
decode
Address
generation
Cache
Write back
Write back
Write back
Fetch Dispatch
Fetch
Dispatch
Decode
Execute
Predict
Decode
Execute 1 Execute 2
(a)
(b)
(c)
(d)
Before proceeding further, we should remember that integer type instructions and load/store type
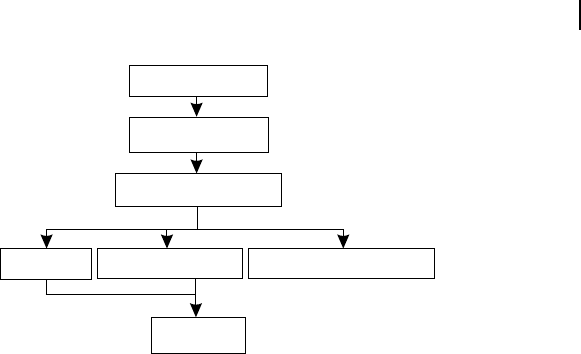
instructions are processed through same pipeline. Schematically, the three pipeline modules are illus-
trated in Figure C.6 . By observing both Figures C.5 and C.6 , we may conclude that Stage 1 of all
three pipelines is the fetch operation, which is common for all. Three instructions are fetched from the
instruction cache and sent to decode and dispatch unit. This unit performs as the second stage of all
pipelines (except oating point type instructions) and for different type of instructions (integer, oating
point or branch processing), they are sent to different queues.
Thereafter, the integer pipeline also takes care of load/store type instructions, as shown in Figure C.5 (a)
and (b). For integer operations it executes and writes back at third and fourth stages. For load/store type
instructions, the same pipeline generates the related address, interacts with the cache (load) and then
writes back (store), using one extra stage in such a case.
Decoding for oating point instructions are carried out as third stage of oating point pipeline [refer
Fig. C.5(c)]. Thereafter two successive stages are devoted for the execution of the instruction and nally
at the sixth stage the result is written back, generally in some internal oating point register of the pro-
cessor, as we have already discussed.
Z03_GHOS1557_01_SE_C18_App_C.indd 470Z03_GHOS1557_01_SE_C18_App_C.indd 470 4/29/11 5:42 PM4/29/11 5:42 PM
Power PC 471
As all three pipelines are independent of each other, the difference in their execution time require-
ment is automatically compensated, permitting Power PC to execute three instructions per cycle.
C.6.1 Branch Processing by Power PC
The real success or ef ciency of any pipeline depends mainly on its branch predicting ef ciency. In
Chapter 12, we have already discussed about common branch predicting algorithms used by many
processors (Section 12.5.2). However, Power PC handles the branch prediction in a different manner,
which is worth discussing.
In Figure C.1 the branch and branch exec. modules of Power PC were shown. The branch processing
unit is also schematically represented in Figure C.6 . This branch processing unit is responsible for han-
dling the branch instructions. It is so designed that in most of the cases branching instructions have no
effect in pipeline execution, which is, generally, referred as zero-cycle branches . To achieve this, Power
PC uses a simple strategy as described below.
The branch unit of Power PC keeps on scanning the dispatch buffer continuously for any eventual branch
instruction. Whenever, any such branch instruction is encountered within the queue, the branch target
addresses are immediately generated, provided processing of no previous branch instruction is pending.
Next, the branch prediction unit tries to nd out if the condition code for the branch is already evalu-
ated or not. Thereafter, one of the three possible cases are processed accordingly. The three possible
cases are
R A branching ill take place
R No branching will take place
R Unable to determine (insuf cient information).
Processing for the rst two cases does not pose any problem. For the third case, the branch prediction
unit checks if the branch address is backward or forward. For all backward jump cases (generally for
loops) the branch prediction unit predicts that the branch would be taking place as this prediction would
fail only once for any loop statements. For all forward jump cases, the prediction is that the branching
would not take place. Further instructions following the branch instruction are passed to the pipeline in
a conditional manner, which may quickly be aborted if the prediction goes wrong.
Instruction cache
Instruction fetch
Decode and dispatch
Data cache
Integer unit
Floating point unit
Branch processing unit
Figure C.6 Schematic representation of Power PC pipelines
Z03_GHOS1557_01_SE_C18_App_C.indd 471Z03_GHOS1557_01_SE_C18_App_C.indd 471 4/29/11 5:42 PM4/29/11 5:42 PM
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.