
Up to this point, we have taken a modeling approach to the design of concurrent programs. Models are constructed, so that we can focus on actions, interaction and concurrency before proceeding to implementation and adding the details concerned with data representation, resource usage and user interface. We use the model as a basis for program construction by identifying a mapping from model processes to Java threads and monitor objects. However, we do not demonstrate other than by testing and observation that the behavior of the implementation corresponds to the behavior predicted by the model. Essentially, we rely on a systematic translation of the model into Java to ensure that the program satisfies the same safety and progress properties as the model.
In this chapter, we address the problem of verifying implementations, using FSP and its supporting LTSA tool. In doing verification, we translate Java programs into a set of FSP processes and show that the resulting FSP implementation model satisfies the same safety and progress properties that the design model satisfied. In this way, we can show that the program is a satisfactory implementation of its design model.
Chapter 4 of the book took exactly this approach of translating a Java program into an FSP model to investigate the problem of interference. To perform verification, we need to model the Java program at the level of variables, monitor locks and condition synchronization. In Chapter 4, we showed how to model variables and monitor locks. This chapter develops a model for condition synchronization so that we can verify Java programs that use wait(), notify() and notifyAll(). This implementation model is used in verifying the bounded buffer and Readers–Writers Java programs from Chapters 5 and 7. To allow us to structure the more complex sequences of actions that arise in verification of implementations, we first introduce sequential composition of FSP processes.
Although abstractly a process always means the same thing, for pragmatic implementation reasons FSP divides processes into three types: local processes that define a state within a primitive process, primitive processes defined by a set of local processes and composite processes that use parallel composition, relabeling and hiding to compose primitive processes. A local process is defined using STOP, ERROR, action prefix and choice. We now extend our definition of processes to include sequential processes.
Note
A sequential process is a process that can terminate. A process can terminate if the local process END is reachable from its start state.
The local process END denotes the state in which a process successfully terminates. A process engages in no further actions after END. In this respect it has the same semantics as STOP. However, STOP denotes a state in which a process has halted prematurely, usually due to communication deadlock. In earlier chapters, to simplify presentation, we used STOP to indicate termination of a process. It would be more precise to replace these uses of STOP with END. With the introduction of a state describing successful termination, the need to use STOP explicitly in process description largely disappears. Figure 13.1 depicts an example of a sequential process together with its LTS, where E is used to denote END.
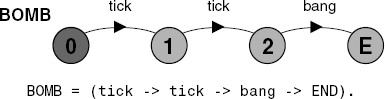
Note
If P is a sequential process and Q is a local process, then P;Q represents the sequential composition such that when P terminates, P;Q becomes the process Q.
If we define a process SKIP = END then P;SKIP ≡ P and SKIP;P ≡ P. A sequential composition in FSP always takes the form:
SP1;SP2;..SPn;LP
where SP1,.., SPn are sequential processes and LP is a local process. A sequential composition can appear anywhere in the definition of a primitive process that a local process reference can appear (for example, processes P123 and LOOP in Figure 13.2).
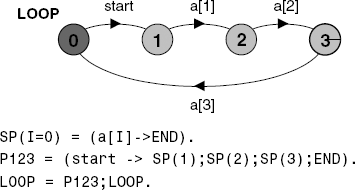
Sequential composition can be used in a recursive context as in Figure 13.3, where process R is defined as the sequential composition of sequential processes R(I) for values of I from 0 to 2 and the local process END when I=3.
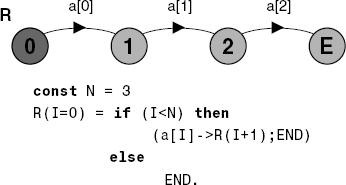
Note
The parallel composition SP1||SP2 of two sequential processes SP1 and SP2 terminates when both of these processes terminate. If termination is reachable in SP1||SP2 then it is a sequential process.
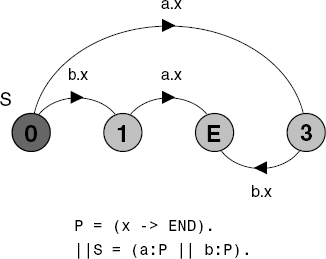
Figure 13.4 gives an example of parallel composition of sequential processes. Note that a composite process that terminates can appear in the definition of a primitive process.
While a reachable STOP state is a safety violation resulting in the LTSA generating a counter example trace, a reachable END state is not a safety violation. However, a trace to a reachable END state will be generated during progress analysis since the END state violates all progress properties.
In Chapter 5, we explained how a guarded action in a design model can be translated into a synchronized method as shown below:
FSP:whencond act-> NEWSTAT Java:public synchronizedvoid act()throwsInterruptedException {while(!cond) wait(); // modify monitor data notifyAll() }
We noted that if an action modifies the data of the monitor, it can call notifyAll() to awaken all other threads that may be waiting for a particular condition to hold with respect to this data. We also noted that if it is not certain that only a single thread needs to be awakened, it is safer to call notifyAll() than notify() to make sure that threads are not kept waiting unnecessarily. We use an implementation model to investigate this particular aspect further in the rest of this chapter.
To verify that a program using this translation satisfies the required safety and progress properties, we must model the behavior of wait(), notify() and notifyAll(). We can then rigorously check the use of notify() versus notifyAll(). A model for the interaction of these methods is developed in the following. Firstly, we define a process ELEMENT to manage the BLOCKED state of each thread that accesses a monitor.
ELEMENT
= (wait -> BLOCKED | unblockAll -> ELEMENT),
BLOCKED
= ({unblock,unblockAll} -> UNBLOCK),
UNBLOCK
= (endwait -> ELEMENT).The wait action, representing a call to wait(), puts the process into the BLOCKED state. Then either an unblock action caused by a notify() or an unblockAll action caused by a notifyAll() causes the process to move to UNBLOCK and signal the return of the wait() method by the endwait action. We will deal with the way that the monitor lock is released and acquired by wait() later.
The CONTROL process manages how notify and notifyAll actions, representing the eponymous Java methods, cause unblock and unblockAll actions:
CONTROL = EMPTY,
EMPTY = (wait -> WAIT[1]
| {notifyAll,notify} -> EMPTY
),
WAIT[i:1..Nthread]
= (when (i<Nthread) wait -> WAIT[i+1]
|notifyAll -> unblockAll -> EMPTYSince we can only check systems with a finite set of states, we must define a static set of identifiers Threads to represent the set of threads that can potentially access a monitor object. The cardinality of this set is defined by the constant Nthread. The CONTROL process maintains a count of the number of processes in the BLOCKED state. If there are no blocked processes then notify and notifyAll have no effect. If there are many blocked processes then a notify action unblocks any one of them. The set of threads waiting on a monitor and the effect of the wait(), notify() and notifyAll() methods are modeled by the composition:
constNthread = 3//cardinality ofThreadssetThreads = {a,b,c}//set of thread indentifierssetSyncOps = {notify,notifyAll,wait} ||WAITSET = (Threads:ELEMENT || Threads::CONTROL) /{unblockAll/Threads.unblockAll}.
The composition defines an ELEMENT process for each thread identifier in the set Threads. The CONTROL process is shared by all the threads in this set. The relabeling ensures that when any thread calls notifyAll(), then all waiting threads are unblocked. The behavior of WAITSET is best illustrated using the animation facilities of LTSA.
Figure 13.5 shows a trace in which thread b calls wait, then thread a calls wait. A call by thread c to notify unblocks thread a. Note that while thread b was blocked before a, it is a that is unblocked first. In other words, the model does not assume that blocked threads are held in a FIFO queue, although many Java Virtual Machines implement thread blocking this way. The Java Language Specification specifies only that blocked threads are held in a set and consequently may be unblocked in any order by a sequence of notifications. An implementation that assumes FIFO blocking may not work correctly on a LIFO implementation. The WAITSET model permits all possible unblocking orders and consequently, when we use it in verification, it ensures that if an implementation model is correct, it is correct for all possible orders of blocking/unblocking actions.
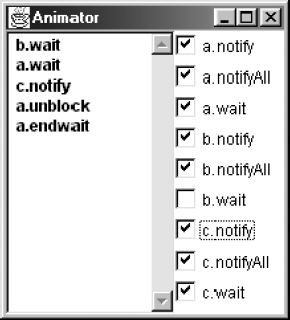
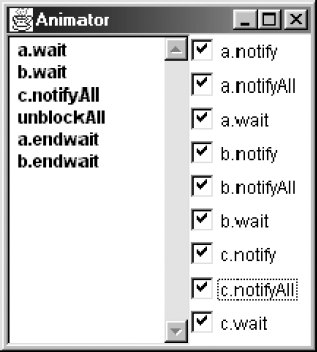
Figure 13.6 illustrates the behavior for notifyAll when threads a and b are blocked.
Variables are modeled in exactly the same way as presented in Chapter 4. However, for convenience, we add actions to model incrementing and decrementing integer variables. An integer variable is modeled as follows:
constImax = 5// a maximum value that variable can takerangeInt = 0..ImaxsetVarAlpha = {read[Int],write[Int],inc,dec}
VAR(Init=0)= VAR[Init], VAR[v:Int] = (read[v] ->VAR[v]// v|inc ->VAR[v+1]// ++v|dec ->VAR[v-1]// --v|write[c:Int]->VAR[c]// v = c).
A boolean variable is modeled by:
constFalse = 0constTrue = 1rangeBool = False..TruesetBoolAlpha = {read[Bool],write[Bool]} BOOLVAR(Init=False) = BOOLVAR[Init], BOOLVAR[b:Bool] = (read[b] ->BOOLVAR[b]// b|write[c:Bool]->BOOLVAR[c]// b = c).
In Chapter 4, we noted that synchronized methods acquire the monitor lock before accessing the variables of a monitor object and release the lock on exit. We will use the same simple model of a lock used in Chapter 4, ignoring the detail that locks in Java support recursive locking:
set LockOps = {acquire,release}
LOCK = (acquire -> release ->LOCK).We can now model the state of a monitor by the set of processes that represent its wait set, lock and variables. For example, the state for a monitor M that encapsulates a single boolean variable cond is modeled as follows:
||Mstate = (Threads::LOCK || WAITSET
|| Threads::(cond:BOOLVAR)
).The definition of the Java wait() operation in Chapter 5 requires that a waiting thread releases the synchronization lock. We model this as a sequential process that releases the lock when it blocks and acquires it again when it unblocks and finishes waiting.
WAIT = (wait ->release ->endwait ->acquire ->END).
In Java, the notification and waiting operations are only valid when the thread calling these operations holds the lock for the monitor object on which the operations are invoked. The following safety property checks that this is the case in the implementation models we construct:
property SAFEMON
= ([t:Threads].acquire -> HELDBY[t]),
HELDBY[t:Threads]
= ([t].{notify,notifyAll,wait} -> HELDBY[t]
|[t].release -> SAFEMON
).A synchronized method of the form:
synchronizedvoid act()throwsInterruptedException {while(!cond) wait();// modify monitor datanotifyAll() }
can now be modeled by the following FSP sequential process. As in Chapter 4, alphabet extension ensures that only intended interactions occur since it is usually the case that a process modeling a synchronized method will only use a subset of the data access actions (in this case only read is used on the boolean condition) and synchronization actions (in this case only notifyAll is used).
ACT// act()= (acquire -> WHILE),// monitor entry– acquire lockWHILE = (cond.read[b:Bool] ->// while (!cond) wait();if!bthenWAIT;WHILEelseCONTINUE ), CONTINUE = (// modify monitor datanotifyAll// notifyAll()-> release// monitor exit– release lock-> END ) + {SyncOps, LockOps, cond.BoolAlpha}.
Note that with the above constructions, while we can now model monitors in some detail, we are still ignoring the effect of InterruptException occurrence and handling. In the book, we have only used this mechanism to terminate all the threads that constitute the concurrent Java program. At the end of this chapter we discuss the problems that can arise if only a subset of threads is terminated in this way.
Program 13.1 below reproduces the bounded buffer implementation from Chapter 5, Program 5.6 published in the first printing and first edition of this book. In this section, we develop a detailed model of the synchronization of this program and investigate its properties. As usual, we abstract from the details of what items are stored in the buffer and how these items are stored. Consequently, the only variable that we need to consider modeling is the variable count that stores the number of items currently stored in the buffer. The state of the buffer monitor implementation is as follows with the count variable initialized to zero:
constSize = 2// number of buffer slots||BUFFERMON = ( Threads::LOCK || WAITSET || SAFEMON ||Threads::(count:VAR(0)) ).
The alphabet for each thread is defined by:
set BufferAlpha = {count.VarAlpha, LockOps, SyncOps}We can now translate the put() and get() methods of Program 13.1 into FSP into a reasonably straightforward way. Since we have abstracted from the details of storing items in the buffer, we replace the actions to place an item in the buffer with the action put and the actions to remove an item with the action get.
Example 13.1. Buffer interface and BufferImpl class.
publicvoid put(Object o)throwsInterruptedException;//put object into bufferpublicObject get()throwsInterruptedException;//get object from buffer}classBufferImplimplementsBuffer {protectedObject[] buf;
protectedint in = 0;protectedint out= 0;protectedint count= 0;protectedint size; BufferImpl(int size) { this.size = size; buf =newObject[size]; }public synchronizedvoid put(Object o)throwsInterruptedException {while(count==size) wait(); buf[in] = o; ++count; in=(in+1) %size; notify(); }public synchronizedObject get()throwsInterruptedException {while(count==0) wait(); Object o =buf[out]; buf[out]=null; --count; out=(out+1) %size; notify(); return (o); } }
/*put method*/ PUT = (acquire -> WHILE), WHILE = (count.read[v:Int] ->// while (count == size) wait();if v==Size then WAIT;WHILE else CONTINUE ), CONTINUE = (put// buf$,$[in] = o; in=(in+1) %size;-> count.inc// ++count;-> notify -> release -> END ) + BufferAlpha.
/*get method*/ GET = (acquire -> WHILE), WHILE = (count.read[v:Int] ->// while (count == 0 )wait()if v==0 then WAIT;WHILE else CONTINUE ), CONTINUE = (get// Object[o] = buf$,$[out]; buf$,$[out]=null;-> count.dec// --count;-> notify -> release -> END ) + BufferAlpha.
To investigate the properties of the bounded buffer implementation, we model systems consisting of one or more producer threads and one or more consumer threads. The producer threads call put() and the consumer threads call get () as shown below.
PRODUCER = PUT;PRODUCER.
CONSUMER = GET;CONSUMER.We noted in section 13.2.1 that we must explicitly define the set of threads that will access the monitor being modeled. For the bounded buffer example, we have a set of producer threads, which put items into the buffer, and a set of consumer threads, which take items out of the buffer, identified as follows:
constNprod = 2// #producersconstNcons = 2// #consumerssetProd = {prod[1..Nprod]}// producer threadssetCons = {cons[1..Ncons]}// consumer threadsconstNthread = Nprod + NconssetThreads = {Prod,Cons}
The producer and consumer processes are composed with the processes modeling the buffer monitor by:
||ProdCons = (Prod:PRODUCER || Cons:CONSUMER
|| BUFFERMON).To verify our implementation model of the bounded buffer, we need to show that it satisfies the same safety and progress properties as the design model. However, the bounded buffer design model was specified in Chapter 5, which preceded the discussion of how to specify properties. Consequently, we simply inspected the LTS graph for the model to see that it had the required synchronization behavior. The LTS of the implementation model is much too large to verify by inspection. How then do we proceed? The answer with respect to safety is to use the design model itself as a safety property and check that the implementation satisfies this property. In other words, we check that the implementation cannot produce any executions that are not specified by the design. Clearly, this is with respect to actions that are common to the implementation and design models – the put and get actions. The property below is the same BUFFER process shown in Figure 5.11, with the addition of a relabeling part that takes account of multiple producer and consumer processes.
propertyBUFFER = COUNT[0], COUNT[i:0..Size] = (when(i<Size) put->COUNT[i+1] |when(i>0) get->COUNT[i-1] )/{Prod.put/put,Cons.get/get}.
The LTS for this property with two producer processes, two consumer processes and a buffer with two slots (Size = 2) is shown in Figure 13.7.
We are now in a position to perform a safety analysis of the bounded buffer implementation model using the composition:
||ProdConsSafety = (ProdCons || BUFFER).
With two producer processes (Nprod=2), two consumer processes (Ncons=2) and a buffer with two slots (Size=2), safety analysis by the LTSA reveals no property violations or deadlocks. In this situation, the implementation satisfies the design. However, safety analysis with two producer processes (Nprod=2), two consumer processes (Ncons=2) and a buffer with only one slot (Size=1) reveals the following deadlock:
Trace to DEADLOCK:
cons.1.acquire
cons.1.count.read.0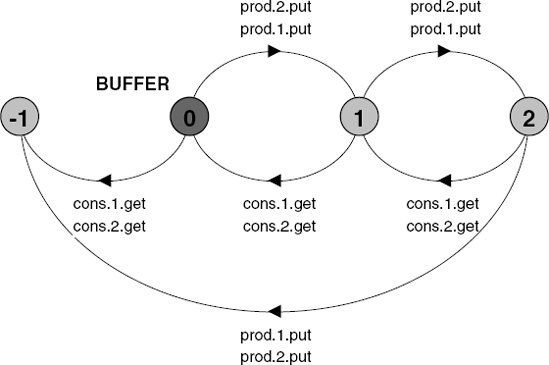
cons.1.wait// consumer 1 blockedcons.1.release cons.2.acquire cons.2.count.read.0 cons.2.wait// consumer 2 blockedcons.2.release prod.1.acquire prod.1.count.read.0 prod.1.put// producer 1 inserts itemprod.1.count.inc prod.1.notify// producer 1 notifies item availableprod.1.release prod.1.acquire prod.1.count.read.1 cons.1.unblock// consumer 1 unblocked by notifyprod.1.wait// producer 1 blocks trying to insert 2nd itemprod.1.release prod.2.acquire prod.2.count.read.1 prod.2.wait// producer 2 blocks trying to insert itemprod.2.release cons.1.endwait cons.1.acquire cons.1.count.read.1
cons.1.get// consumer 1 gets itemcons.1.count.dec cons.1.notify// consumer 1 notifies space availablecons.1.release cons.1.acquire cons.1.count.read.0 cons.2.unblock// consumer 2 unblocked by notifycons.1.wait cons.1.release cons.2.endwait cons.2.acquire cons.2.count.read.0 cons.2.wait// consumer 2 blocks since buffer is emptycons.2.release
The deadlock occurs because at the point that the consumer process calls notify to indicate that a space is available in the buffer, the wait set includes the second consumer process as well as both the producer processes. The consumer is unblocked and finds that the buffer is empty and goes back to waiting. At this point no further progress can be made and the system deadlocks since neither of the producer processes can run. This deadlock occurs if either the number of producer processes or the number of consumer processes is greater than the number of slots in the buffer. Clearly in this situation, the implementation given in the first printing of Chapter 5 was incorrect!
To correct the bounded buffer program of Chapter 5, to handle the situation of a greater number of producer or consumer threads than buffer slots, we need to replace the calls to notify() with calls to notifyAll(). This unblocks both consumer and the producer threads, allowing an insertion or removal to occur. Replacing the corresponding actions in the implementation model removes the deadlock and verifies that the Java program is now correct.
The lesson here is that it is always safer to use notifyAll() unless it can be rigorously shown that notify() works correctly. We should have followed our own advice in Chapter 5! The general rule is that notify() should only be used if at most one thread can benefit from the change of state being signaled and it can be guaranteed that the notification will go to a thread that is waiting for that particular state change. An implementation model is a good way of doing this.
The corrected model satisfies the following progress properties, which assert lack of starvation for put and get actions:
progressPUT[i:1..Nprod] = {prod[i].put}progressGET[i:1..Ncons] = {cons[i].get}
Program 13.2 reproduces the version of the Readers–Writers program from Chapter 7, Program 7.8 that gives Writers priority. This version is again taken from the first printing, first edition of this book.
Example 13.2. Class ReadWritePriority.
classReadWritePriorityimplementsReadWrite{privateint readers =0;privateboolean writing = false;privateint waitingW = 0;// no of waiting Writers.public synchronizedvoid acquireRead()throwsInterruptedException {while(writing || waitingW>0) wait(); ++readers; }public synchronizedvoid releaseRead() { --readers;if(readers==0) notify(); }public synchronizedvoid acquireWrite()throwsInterruptedException { ++waitingW;while(readers>0 || writing) wait(); --waitingW; writing = true; }public synchronizedvoid releaseWrite() { writing = false; notifyAll(); } }
To verify this program, we proceed as before and translate the Java into FSP using the model construction developed in sections 13.2 and 13.3. The first step is to model the state of the monitor. This consists of the wait set, the monitor lock and the variables specific to the ReadWritePriority class. The class has three variables – readers, writing and waitingW –which all play a part in synchronization. Consequently, in this example, we model the state of the monitor by:
||RWPRIORMON = ( Threads::LOCK || WAITSET || SAFEMON
||Threads::( readers:VAR
||writing:BOOLVAR
||waitingW:VAR
)
).The set Threads is defined by:
constNread = 2// #readersconstNwrite = 2// #writerssetRead = {reader[1..Nread]}// reader threadssetWrite = {writer[1..Nwrite]}// writer threadsconstNthread = Nread + NwritesetThreads = {Read,Write}
The alphabet that must be added to each monitor method is:
set ReadWriteAlpha =
{{readers,waitingW}.VarAlpha, writing.BoolAlpha,
LockOps, SyncOps,
acquireRead,acquireWrite,releaseRead,releaseWrite
}The next step in verifying an implementation is to derive an FSP sequential process for each monitor method. These processes for acquireRead(), releaseRead(), acquireWrite() and releaseWrite() are listed below.
/*
* acquireRead() method
*/
ACQUIREREAD
= (acquire -> WHILE),
WHILE // while (writing || waitingW$>$0) wait();
= (writing.read[v:Bool] -> waitingW.read[u:Int] ->if(v || u>0)thenWAIT;WHILE else CONTINUE ), CONTINUE = (acquireRead -> readers.inc// ++readers;-> release -> END ) + ReadWriteAlpha. /* *releaseRead() method*/ RELEASEREAD = (acquire -> releaseRead -> readers.dec// --readers;-> readers.read[v:Int] ->// if (readers==0) notify();if(v==0)then(notify -> CONTINUE) else CONTINUE ), CONTINUE = (release -> END) + ReadWriteAlpha. /* *acquireWrite() method*/ ACQUIREWRITE// ++waitingW;= (acquire -> waitingW.inc -> WHILE), WHILE// while (readers$>$0 || writing) wait();= (writing.read[b:Bool] -> readers.read[v:Int]->if(v>0 || b)thenWAIT;WHILE else CONTINUE ), CONTINUE = (acquireWrite -> waitingW.dec// --waitingW;-> writing.write[True]// writing = true;-> release -> END )+ ReadWriteAlpha. /* *releaseWrite() method*/ RELEASEWRITE = (acquire -> releaseWrite -> writing.write[False]// writing = false;-> notifyAll// notifyAll();-> release-> END ) + ReadWriteAlpha.
We have included the actions acquireRead, acquireWrite, releaseRead and releaseWrite in the model, which correspond to the actions in the design model of Chapter 7.
Models for READER and WRITER processes are listed below. In this case, we have included actions to represent the calling of the monitor method in addition to modeling the execution of the method. We will see in the next section that these actions are needed to define the required progress property analysis conditions.
READER = (acquireRead.call -> ACQUIREREAD;READING),
READING = (releaseRead.call -> RELEASEREAD;READER).
WRITER = (acquireWrite.call -> ACQUIREWRITE;WRITING),
WRITING = (releaseWrite.call -> RELEASEWRITE;WRITER).To verify that the implementation model satisfies the desired safety properties, we use the safety property RW_SAFE originally specified in section 7.5.1 to check the correct behavior of the design model.
propertySAFE_RW = (acquireRead -> READING[1] |acquireWrite->WRITING ), READING[i:1..Nread] = (acquireRead -> READING[i+1] |when(i>1) releaseRead -> READING[i-1] |when(i==1) releaseRead -> SAFE_RW ), WRITING = (releaseWrite -> SAFE_RW).
The system we perform safety analysis on consists of the reader and writer threads, the monitor state and the safety property as shown below:
||RWSYS = (Read:READER || Write:WRITER
|| RWPRIORMON
|| Threads::SAFE_RW
).Safety analysis detects the following deadlock:
Trace to DEADLOCK:
reader.1.acquireRead.call
reader.1.acquire
reader.1.writing.read.0
reader.1.waitingW.read.0
reader.1.acquireRead
reader.1.readers.inc
reader.1.release // reader 1 acquires RW lock
reader.1.releaseRead.call
reader.2.acquireRead.call
writer.1.acquireWrite.call
writer.1.acquire
writer.1.waitingW.inc
writer.1.writing.read.0
writer.1.readers.read.1
writer.1.wait // writer 1 blocked as reader has RW lock
writer.1.release
reader.2.acquire
reader.2.writing.read.0
reader.2.waitingW.read.1
reader.2.wait // reader 2 blocked as writer 1 waiting
reader.2.release
writer.2.acquireWrite.call
writer.2.acquire
writer.2.waitingW.inc
writer.2.writing.read.0
writer.2.readers.read.1
writer.2.wait // writer 2 blocked as reader has RW lock
writer.2.release
reader.1.acquire
reader.1.releaseRead
reader.1.readers.dec
reader.1.readers.read.0
reader.1.notify // reader 1 releases RW lock & notifies
writer.2.release
reader.1.release
reader.1.acquireRead.call
reader.1.acquire
reader.1.writing.read.0
reader.1.waitingW.read.2
reader.2.unblock // reader 2 unblocked by notify
reader.1.waitreader.1.release
reader.2.endwait
reader.2.acquire
reader.2.writing.read.0
reader.2.waitingW.read.2
reader.2.wait // reader 2 blocks as writers waiting
reader.2.releaseThe deadlock happens because the notify operation performed by Reader 1 when it releases the read–write lock unblocks another Reader rather than a Writer. This unblocked Reader subsequently blocks again since there are Writers waiting. The solution is again to use a notifyAll to awake all waiting threads and thus permit a Writer to run. Changing the notify action to notifyAll in the RELEASEREAD part of the model and rerunning the safety analysis confirms that the deadlock does not occur and that the implementation model satisfies the safety property.
Why did we not observe this deadlock in the actual implementation of Read-WritePriority when running the demonstration applet? The reason is quite subtle. In most Java Virtual Machines, the set of threads waiting on notification is implemented as a first-in-first-out (FIFO) queue. With this queuing discipline, the deadlock cannot occur as for the second Reader to block, a Writer must have previously blocked. This Writer will be unblocked by the notification when the first Reader releases the read–write lock and, consequently, the deadlock does not occur. However, although the implementation works for some JVMs, it is not guaranteed to work on all JVMs since, as noted earlier, the Java Language Specification specifies only that blocked threads are held in a set. Our implementation would exhibit the deadlock on a JVM that used a stack for the wait set. Consequently, the implementation is clearly erroneous and the notify() in the releaseRead() method should be replaced with notifyAll(). Again the lesson is that notify() should only be used with extreme care! However, it should be noted that the use of notify() in the ReadWriteSafe version of the read–write lock is correct since it is not possible in that implementation to have both Readers and Writers waiting simultaneously.
Having demonstrated that the implementation model satisfies the required safety properties, it now remains to show that it exhibits the same progress properties as the design model. These properties assert lack of starvation for acquireRead and acquireWrite actions.
progressWRITE[i:1..Nwrite] = writer[i].acquireWriteprogressREAD [i:1..Nwrite] = reader[i].acquireRead
The adverse scheduling conditions needed to check progress in the presence of competition for the read–write lock are arranged by making the actions, representing calls to release read and write access to the lock, low priority:
||RWPROGTEST = RWSYS > {Read.releaseRead.call,
Write.releaseWrite.call}.Progress analysis reveals that the RWPROGTEST system satisfies the WRITE progress properties but violates the READ progress properties. In other words, the Writers priority implementation of the read–write lock satisfies its design goal of avoiding Writerstarvation, but, as with thedesign model, it permits Reader starvation.
This chapter has presented a way of verifying that Java implementations satisfy the same safety and progress properties as the design models from which they were developed. The approach is to translate the Java program into a detailed FSP model that captures all aspects of the Java synchronization mechanisms – in particular, monitor locks and notification. This implementation model is then analyzed with respect to the same safety and progress properties used in analyzing the design model. We also showed in the bounded buffer example that the design model itself can be used as a safety property when verifying the implementation model.
Implementation models are considerably more detailed than design models and as such generate much larger state spaces during analysis. It is in general only possible to analyze small parts of an implementation. This is why in the book we have advocated a model-based design approach in which properties are investigated with respect to a design model and then this model is used as a basis for program implementation. Clearly, as we have demonstrated in the examples contained in this chapter, errors can be introduced in going from design model to implementation. Interestingly, the two bugs discovered both arise from the use of notify() in place of notifyAll(). Perhaps the most important lesson from this supplement is that strict attention must be paid to the rule that notify() should only be used if at most one thread can benefit from the change of state being signaled and it can be guaranteed that the notification will go to a thread that is waiting for that particular state change in the monitor class itself or in any subclasses.
Finally, as illustrated in the implementation models, sequential composition can be seen to provide a convenient means for structuring complex sequences of actions from simpler fragments of sequential processes.
We are indebted to David Holmes for initially pointing out the problems with the bounded buffer and read–write lock that we have exposed in this chapter. He also motivated this chapter by suggesting that we should address the problem of verifying implementations. David is a Senior Research Scientist at the Cooperative Research Centre for Enterprise Distributed Systems Technology (DSTC Pty Ltd.), located in Brisbane, Australia.
We pointed out in this chapter that our model of notification ignores the effect of an interrupt exception. It is possible, for a thread waiting to be notified, to be interrupted before actually returning from the wait() call. As a result it returns via an InterruptedException not a normal return and essentially, the notification is lost even though other uninterrupted threads may be waiting. This means that programs that use notify() and allow InterruptedException to be thrown directly are not guaranteed to work correctly. Although we use this technique in the book, it does not result in inconsistencies since in all cases, the interrupt exception is used to terminate all active threads. However, it is another reason for using notifyAll() rather than notify(). This may sometimes result in a large number of unnecessary thread activations and consequently be inefficient. For example, in the semaphore program of section 5.2.2, a better way to deal with the lost notification problem is to catch the InterruptedException and perform an additional notify() before rethrowing the exception. Thanks again to David for pointing this out.
The earliest attempt to prove a program correct appears to be that of Turing who presented a paper, Checking a large routine, on 24 June 1949 at the inaugural conference of the EDSAC computer at the Mathematical Laboratory, Cambridge. He advocated the use of assertions "about the states that the machine can reach". The formal foundations for techniques for program correctness were laid in the 1960s with contributions by pioneers such as McCarthy, Naur, Floyd, Dijkstra and Hoare (Morris and Jones, 1984). Again, the essence of the approach is to associate logical assertions, pre- and post-conditions, with the statement blocks in a program. Invariants are used to characterize the properties preserved by loops, later extended to characterize objects and monitors (see Chapter 5). This work was initially targeted at proving the correctness of sequential programs, and involved both a proof of satisfaction of the program post-condition and a proof of termination. The correctness of concurrent programs is more complex, requiring that the techniques deal with nonterminating and nondeterministic programs. The foundations were again laid in the 1960s by the insights of researchers such as Dijkstra and Petri, but it was in 1977 that Lamport proposed that correctness of concurrent programs should be argued for two sorts of properties: safety and liveness.
Since those early pioneering days, much research work and experience have been gained. The 1996 state-of-the-art papers on concurrency (Cleaveland, Smolka, et al.) and formal methods (Clarke, Wing, et al.) provide an excellent overview. All these techniques have had major impact on the design of programming languages and programming methods. However, because of the effort involved, the impact on practice has been limited to a relatively small number of specific circumstances, such as safety-critical software, software which is difficult or impossible to update or software to be used in vast numbers of consumer products. The advance of techniques and technology in theorem proving and model checking over the last ten years has made program verification more accessible and practical.
The approach adopted by many current researchers is to try to extract a model directly from the code. Techniques used vary from code annotation, which provides the mapping between code and model, to various abstraction techniques which hide program detail irrelevant to the particular property or concern. Notable amongst these are the FeaVer Toolset for C programs (Holzmann and Smith, 2002), FLAVERS for Ada programs (Cobleigh, Clarke and Osterweil, 2002), the Java PathFinder tool (Havelund and Pressburger, 2000) and the Bandera toolset (Corbett, Dwyer, Hatcliff, et al., 2000) for Java programs.
Other approaches are attempting to develop verification tools tailored to work directly on a program in a specific programming language. A second version of the Java PathFinder tool (Brat, Havelund, Park, et al., 2000), Microsoft's SLAM project for C (Ball and Rajamani, 2002), and the Blast tool for C (Henzinger, Jhala, Majumdar, et al., 2003) are examples of this work.
13.1 Simplify the verification model developed in section 13.5 such that it is a model of the Java program
ReadWriteSafe(Program 7.7). Show that this model does not violate the propertySAFE_RWand that it violates theWRITEprogress property.13.2 Develop a verification model for the
Semaphoreclass (Program 5.3) and use it in verifying that theSEMADEMOprogram of Chapter 5 preserves the mutual exclusion property (section 7.1.2):propertyMUTEX = (p[i:1..3].enter->p[i].exit->MUTEX).In addition, generate an error trace for the situation in which the semaphore is initialized to 2.
13.3 The following FSP specifies the safety property for barrier synchronization. Each process must execute its
beforeaction before all processes execute the commonsyncaction.Pspec = (before -> sync -> Pspec). property ||SAFEBARRIER = (p[1..3]:Pspec) /{sync/p[1..3].sync}{sync}.Verify that the monitor
Barrierwith asyncmethod that implements barrier synchronization (as required in the solution to Exercise 5.5) satisfies the above property.13.4 Verify that the
SimpleAllocatormonitor of Program 9.1 satisfies the propertyALLOCATORin the systemCHECK, both shown below:propertyALLOCATOR(M=3) = BALL[M], BALL[b:0..M] = (when (b>0) get[i:1..b] -> BALL[b-i] |put[j:1..M] -> BALL[b+j] ). PLAYER(I=1) = (get.call -> GET(I);PLAYING), PLAYING = (put.call -> PUT(I);PLAYER). ||CHECK = (player[1..3]:PLAYER(1) ||player[4..Nthread]:PLAYER(3) ||SimpleAllocator(N) ||player[1..N]::ALLOCATOR(N) ).In addition, determine which of the following progress properties are satisfied by the system
CHECKLIVEshown below:progressEXPERT = {player[1..3].get[1..N]}progressNOVICE = {player[4..N].get[1..N]} ||CHECKLIVE = CHECK > {player[1..N].put.call}.