
If you’re writing an extensible application or have reason to unload code without shutting down an entire process, you’ll likely want to take advantage of application domains. Application domains enable you to isolate groups of assemblies from others running in the same process. Oftentimes, the isolation provided by application domains is used to run multiple applications in the same Win32 process as is done by CLR hosts such as Microsoft ASP.NET and Microsoft SQL Server. However, application domains are useful in a variety of other scenarios as well. For example, some applications use application domains to isolate individual controls running in the same process, whereas others use domains simply to support their requirements for dynamically unloading code.
This book includes two chapters on application domains. This first chapter introduces the concept of an application domain and gives general architectural guidelines to help you make the most effective use of domains within your application. Topics covered in this chapter include the role of application domains, a discussion of their internal structure, guidelines to follow when partitioning a process into multiple application domains, the relationship between domains and threads, and the use of application domains to unload code from a running process. In Chapter 6, I describe the various ways you can customize application domains to fit your particular scenario.
To meet the reliability and security required by modern computing environments, operating systems and other software platforms must provide a means to isolate unrelated applications from one another at run time. This isolation is necessary to ensure that code running in one application cannot adversely affect another, thereby exploiting a security vulnerability or causing that application to crash.
The Microsoft Windows operating system uses processes to enforce this isolation. If you’ve used Microsoft Internet Information Services (IIS) and ASP in the past, you probably recall two configurations you could select that controlled where your application code ran relative to the code for IIS itself. In one configuration you chose to run your application in the same process as IIS. Your other option was to run your application in a different process than IIS. The tradeoff between these two options was one of reliability versus performance. Running in-process with IIS meant no process boundaries were crossed between your application and IIS. However, if some application running in the IIS process had a bug that caused it to access an invalid memory location, not only would that application crash, but the entire IIS process would go down, bringing your application with it. Choosing to run your application in a different process isolates you from this unpredictability, but that isolation comes at a performance cost. In this configuration all calls between your application and IIS must cross a process boundary, which introduces a performance penalty. This tradeoff between reliability and performance doesn’t scale in many situations, including the Web server scenario just described.
One of the reasons process boundaries prove expensive as a way to enforce isolation is related to the way memory accesses are validated. Memory access in the Windows operating system is process-relative. That is, the same value for a memory address maps to two different locations in two different processes—each location is scoped to the process in which it is used. This isolation is essential in preventing one process from accessing another’s memory. This isolation is enforced in hardware. Memory addresses in the Windows operating system are not references into the processor’s physical memory. Instead, every address is virtual, giving the application a flat, contiguous view of memory. So each time memory is accessed by the application, its address must be translated by the processor from a virtual address to a physical address. This translation involves the use of a CPU register and several lookup tables examined by the processor. This CPU register holds a value that points to a list of physical pages available to the process. Each time a process switch occurs in the Windows operating system, the value of this register must be adjusted. In addition, the processor must take a virtual address and break it down into pieces that identify the page and the offset within the page of the physical memory being accessed. These checks must be done at the hardware level to ensure that all memory accesses are to valid memory addresses within the process. The reason that memory access must be validated on the fly in this fashion is because the Windows operating system cannot determine ahead of time which memory in the process the application will access.
Another factor in the cost of using processes as an isolation boundary is the expense of switching the context associated with execution from one thread to another. All threads in the Windows operating system are process-relative—they can run only in the process in which they are created. When processes are used to isolate IIS from your application, the transfer of control between the two processes involves a thread context switch. This thread switch, along with the cost of translating memory address and some overhead associated with communication between processes, accounts for most of the expense associated with using processes to achieve application isolation.
In contrast, the CLR can statically determine how a given process will access memory before it is actually run. This is possible primarily because the Microsoft Intermediate Language (MSIL) is at a higher level and much more descriptive than native processor instructions such as x86 or Intel Architecture 64 (IA-64). The CLR relies on this more descriptive instruction set to tell whether a given assembly is type safe, that is, whether all accesses to memory made from within the assembly go through public entry points to valid objects. In this way, the CLR can ensure that a given assembly cannot access invalid regions of memory within the process. That is, they cannot produce an access violation that can bring down the entire process. The practice of determining program correctness is referred to as verification.
Given code that is verified to be type safe, the CLR can provide the isolation typically associated with a process without having to rely on the process boundary. This is where application domains enter the picture. They are the CLR’s construct for enforcing isolation at a cost lower than that of a process boundary, which means you can run multiple managed applications in the same operating system process and still get the level of isolation that previously was possible only by using a process boundary. In this way, application domains are the reason that applications such as ASP.NET scale much better than their unmanaged predecessors. Because of the isolation they provide within a single process, application domains are often described as subprocesses. Figure 5-1 shows a single Windows process running three separate, unrelated applications. Each application runs in its own application domain.
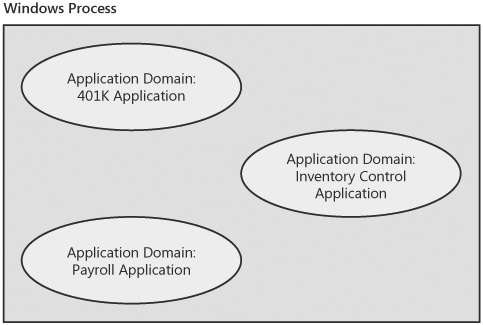
Not all managed assemblies are verifiably type safe, however. If an assembly cannot be verified to be type safe, you cannot rely on application domains for isolation. Such code can make an invalid memory access just as unmanaged code can, causing the entire process to come down. Whether code is verifiable depends in part on the programming language used to write the assembly. The MSIL instruction set is built to support a wide variety of languages, including those that include support for direct pointer manipulation. As a result, your ability to generate verifiable code depends on whether the language you are using exposes some of the unsafe aspects of MSIL. For example, all code generated by the Microsoft Visual Basic.NET compiler is type safe. Visual Basic.NET exposes no language features that let you write unverifiable code. In contrast, C++ is typically not verifiable because C++ code often makes extensive use of pointers. C# is somewhere in the middle. By default, C# produces verifiable code. However, you can use pointers in C# by using the unsafe language keyword.
To leverage the full benefits of application domain isolation, you must ensure that only code that can be verified to be type safe is allowed to run in your process. You do this using the CLR’s Code Access Security (CAS) system. I’ve talked about verifiability mostly from the perspective of reliability, but the ability to verify that code won’t make random memory accesses is critical for security reasons as well. Verification can be relied on to make sure that code won’t overrun buffers or access data it shouldn’t, for example. In fact, CAS depends completely on verifiability—without type-safe code, CAS can offer you little protection. A complete description of CAS is beyond the scope of this book, but for now suffice it to say that the system works by granting a set of permissions to code based on some characteristic of that code that is meaningful to administrators or to the host application. Examples of permissions include the ability to write to the file system or the registry and the ability to read and write data from the network. Because the notion of verifiability is so central to security, one of the permissions defined by the Microsoft .NET Framework is the SkipVerification[1] permission—or the ability to run code that can’t be verified. As a host, you can control which permissions are granted to code running in the application domains you create. Ensuring that nonverifiable code can never run in your process is simply a matter of customizing the CAS system to never grant SkipVerification permission. The details of how to accomplish this are explored in detail in Chapter 10.
In the preceding section, I talked about isolation primarily from the perspective of preventing unwanted memory access. The isolation provided by application domains has many more dimensions, however. Application domains provide isolation for most everything you rely on process isolation to do, including the following:
Type visibility
Configuration data
Security settings
Access to static data and members
Application domains form a boundary around the types that can be called from code running in that domain. Assemblies are always loaded into a process within the context of a domain. If the same assembly is loaded by code in two domains, the assembly is loaded twice.[2] Assemblies loaded into the same domain can freely use each other’s public types and methods. However, a type in one application domain can’t automatically see and use public types in other application domains. Communicating across domains in this way requires a formal mechanism for discovering types and calling them. In the CLR, this formal mechanism is provided by the remoting infrastructure. Just as a process or a machine forms a boundary across which calls must be removed, so does an application domain. In this way, the remote domain must explicitly expose a type so it can be accessed from another domain, thereby enforcing that cross-domain calls come through known entry points.
Each application domain has a configuration file that can be used to customize everything from the local search path for assemblies to versioning and remoting information. In addition, code running within the application domain can store its own settings in the configuration file. Examples of these settings include connection strings to a database or a most recently used files list.
Applications domains can be used to further scope the CAS permissions granted to code running within the domain. This further scoping must be set up explicitly by the extensible application—it is not enabled by default. Permission grants can be customized by the extensible application in two ways. The first is to define custom CAS policy for the domain. This policy maps a notion of code identity (called evidence) to a set of permissions that the code is granted. Examples of evidence include the location from which the code was loaded, its strong-name signature, an Authenticode signature, or any custom evidence provided by the host. Real-world examples of how application domain policy is used include SQL Server 2005 and ASP.NET. In SQL Server 2005, domain policy is used to restrict the permissions that code loaded out of the database is granted. ASP.NET uses domain policy to implement the Minimum, Low, Medium, High, Full permission scheme.
The second way to configure security for an application domain is to set security evidence on the domain itself. This evidence is evaluated by policy just as the evidence from an assembly is. The union of these two evaluations forms the final set of permissions that are granted to the assembly. If the grants from the domain are less than the grants from the assembly, the domain essentially wins. For example, the Microsoft Internet Explorer host uses this feature to make sure that no code running in the domain is granted more permissions than the Web site would get. This is implemented by setting domain-level evidence to the URL of the Web site from which the code was loaded.
The CAS system is so extensible that an entire chapter is dedicated to it later in the book. In Chapter 10, I describe how to implement both application domain CAS policy and domainlevel security evidence.
I’ve discussed how application domains are used to restrict access to types and their members. However, static data and members don’t require instantiation of a type, but still must be isolated per domain to prevent either accidental or malicious leaking of data across domain boundaries. This behavior usually falls out naturally because assemblies are not shared across domains by default. However, when code is loaded domain neutral, the jit-compiled code is shared among all domains in the process to minimize the working set. In this case, the CLR provides this isolation by maintaining a separate copy of each static data member or method for each application domain into which the assembly is loaded.
Not all resources that are isolated to a process in Win32 are isolated to an application domain in the CLR. In some cases, isolating these resources to an application domain isn’t necessary because of type safety or other checks implemented by the runtime. In other cases, resources aren’t isolated to an application domain because they are built on the underlying Win32 primitives, which, of course, have no notion of application domains.
Examples of resources not isolated to an application domain include the garbage collection heap, managed threads, and the managed thread pool. In the case of the garbage collection heap, the notion of type safety can be relied upon so that different heaps need not be maintained for each application domain. In the case of threads and the thread pool, the CLR has knowledge of which application domain a thread is currently running in and takes great care to ensure that no data or behavior is inadvertently leaked when a thread crosses into another domain. I talk more about this later in the "Application Domains and Threads" section.
The .NET Framework libraries provide a number of classes that enable add-ins to create and use synchronization primitives such as events and mutexes. These primitives are examples of managed concepts that are built directly on the unmanaged equivalents. Because the unmanaged notion of an event or mutex clearly has no knowledge of application domains, the managed equivalents are technically not constrained by the application domain boundary. However, application domain isolation of the managed synchronization primitives can be achieved in practice by controlling access to the name you give the object when it is created. For example, if you create an unnamed managed synchronization object, there would be no way that object could be manipulated directly from another domain unless you explicitly pass the underlying operating system handle to the other domain. Perhaps a "truer" notion of application domain–scoped synchronization primitives might show up in the future if the underlying Windows operating system were to add the notion of an application domain to its current process structure.
The other important aspect of process management that hasn’t yet been scoped to the application domain level is debugging. In Win32 when a thread hits a breakpoint in one process, all threads in that process are suspended, but the threads in other processes continue to run. Application domains don’t mirror this same behavior yet, unfortunately. When you set a breakpoint in managed code, all threads in that process stop (regardless of which application domain they are running in at the time) instead of just the one you’re debugging. Clearly, this behavior isn’t ideal and is a significant restriction in many scenarios. There’s no underlying technical reason why this can’t be implemented given the current architecture. It just hasn’t been done because of time constraints and priorities. It’s likely this debugging behavior will be fixed in upcoming releases of the CLR.
Internally, application domains are implemented as a set of data structures and runtime behavior maintained by the CLR. The application domain data structures contain many of the constructs you’d expect after reading the previous section, including a list of assemblies, security policy information, and so on. The elements of the application domain data structure, the fact that memory isolation can be guaranteed through type safety, and the additional checks performed by the CLR for threading-related activities are what enables an application domain to isolate multiple applications in a single process.
A graphical view of a CLR process and the corresponding application domain data structures are shown in Figure 5-2.
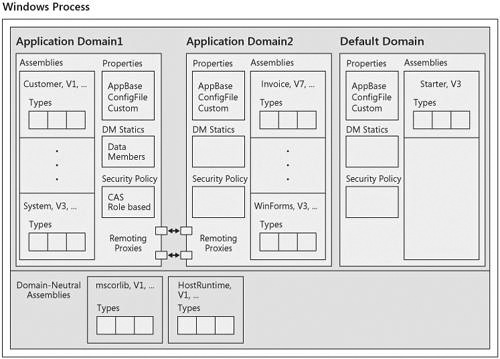
As shown in the figure, each application domain holds several elements related to isolation. These include the following:
A list of assemblies loaded in the application domain
Security policy
Application domain properties
Copies of static data members
Proxies for remote calls
These elements of the application domain data structures are described in the following sections.
Every assembly is loaded within the context of an application domain. The CLR maintains a list of the loaded assemblies per domain. This list is used for many purposes, one of which is to enforce the visibility rules for types within an application domain. The assembly list contains both assemblies that are written as part of the application and those that are shipped by Microsoft as part of the .NET Framework platform.
As described, security policy can be customized per domain. This policy includes both CAS policy and policy for role-based authorization checks.
Each application domain has a list of properties associated with it. These properties fall into two general categories: those properties that are natively understood by the CLR and those properties that are provided by the extensible application for its own use. The properties known to the CLR include the base directory in which to search for assemblies and the file containing the configuration data for the domain. Application domains can be customized in numerous ways by setting these properties. The subject of application domain customization is covered in Chapter 6. In addition to the properties known to the CLR, the application domain includes a general-purpose property bag for use by applications. The property bag is a simple name-object pair and can be used to store anything you need for quick access from any assembly within the domain.
When an assembly is loaded domain neutral, it logically is loaded into every application domain. I say logically because the assembly is physically loaded only once, yet the CLR maintains enough internal data to make it appear to each domain that it contains the assembly. For example, in Figure 5-2, both mscorlib and the assembly called HostRuntime are available to all three domains in the process. So, Application Domain1 really contains the Customer, System, mscorlib, and HostRuntime assemblies.
A critical part of the data that is maintained in each domain for a domain-neutral assembly is a copy of each static data member or field defined in the assembly. As described earlier, this must be done to prevent static data from accidentally leaking between domains. When code in a particular domain accesses a static data member contained in a domain-neutral assembly, the CLR determines in which application domain the referencing code is running and maps that access to the appropriate copy of the static.
All communication between application domains must go through well-known channels. In the CLR these channels are remoting proxies. The CLR maintains a proxy for every object that the application hands out of the domain. Calls coming into the domain are fed through proxies as well. These proxies are an essential part of the domain boundary, both to regulate access and to make sure that application domains are unloaded cleanly. After a domain is unloaded, the proxy maintained by the CLR has enough information to know that the object is it referring to has disappeared. As a result, an exception is thrown back to the caller.
I’ve said that every assembly must be loaded into an application domain. However, it’s likely that you’ve created at least one managed application in which you didn’t think about application domains at all. In fact, the vast majority of programs are written this way. To handle this most common scenario, the CLR creates a default application domain every time a process is started. Unless you take specific steps to load an assembly into an application domain you’ve created yourself, all assemblies end up in the default domain. For example, when you run a managed executable from the command line, the assembly containing the entry point is loaded by the CLR into the default domain. Furthermore, all assemblies statically referenced by that executable are loaded into the default domain as well. The default domain is also used in COM interop scenarios. By default, all managed assemblies that are loaded into a process through COM are loaded into the default domain as well.
The default application domain is very handy in a wide variety of scenarios. However, you should be aware of a key limitation if you are writing an extensible application: the default domain cannot be unloaded from the process before the process is shut down. This can be a hindrance if your architecture requires you to unload application domains during the process lifetime. For this reason, most extensible applications don’t use the default domain to run add-ins. If they did, there’d be no way to ever unload it.
Note

In .NET Framework version 1.0 and .NET Framework version 1.1, the default domain has a second limitation as well: many of the configuration options that can be set on application domains you create yourself couldn’t be set on the default domain. Because the default domain couldn’t be customized in any way, it wasn’t of much use for many extensible applications. Fortunately, the ability to customize the default domain has been added in .NET Framework version 2.0, as discussed later in this chapter.
It’s relatively easy to build a tool to help visualize the relationship among processes, application domains, and assemblies on a running system. The AppDomainViewer tool (appdomainviewer.exe) included with this book shows this relationship in a graphical tree structure. AppDomainViewer is an executable that, when started, enumerates all the processes on the system that are currently running managed code. For each process, AppDomainViewer first enumerates the application domains within the process and then enumerates the assemblies loaded into each application domain.
Figure 5-3 shows the AppDomainViewer running on a machine that runs Microsoft Visual Studio 2005 and a number of purely managed executables.
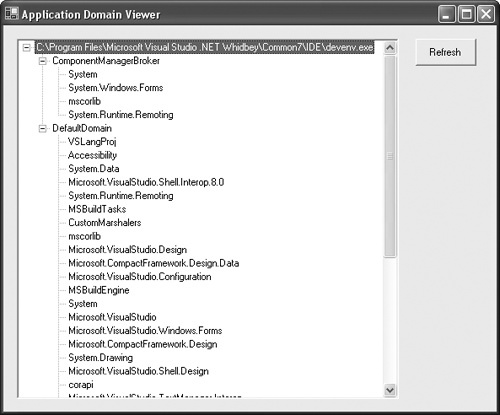
If you expand the tree view, the first level contains the application domains in the process. Notice that every process has at least one application domain. This is the default domain. When an application domain is created, it is assigned a friendly textual name. This is the name displayed in the user interface of AppDomainViewer. In most cases, the name of the default domain is simply Default Domain; however, applications can change this. I discuss how this is done in Chapter 6.
Expanding an application domain in the tree view shows the set of all assemblies loaded into that domain. Looking at the assemblies under each application domain gives me a good chance to expand on the concept of domain-neutral code touched on briefly earlier. Recall that domain-neutral assemblies are loaded once in the process and their code is shared across all application domains to reduce the overall working set of the process. However, from the programmer’s point of view, these assemblies appear in every application domain (recall this is part of application domain isolation). In Figure 5-3, the assemblies mscorlib, System, and so on are loaded domain neutral. Even though these assemblies are loaded only once, they show up under every applicationdomain in the tree view. I cover domain-neutral code in more detail in Chapter 9.
The AppDomainViewer uses the CLR debugging interfaces to get application domain and assembly information out of running processes. It might not occur to you to use the debugging interfaces for this purpose, but it’s the only technique the CLR provides for inspecting processes other than the one in which you are running. Most of the functionality provided by the debugging interfaces is aimed at debugging, of course, but a set of interfaces referred to as the publishing interfaces can be used to look inside other processes.
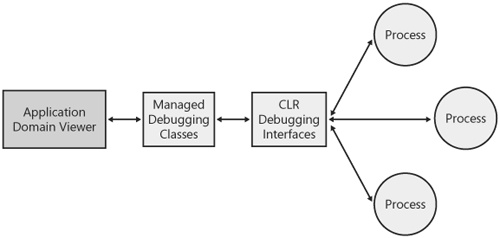
The interfaces (ICorPublish, ICorPublishProcess, ICorPublishAppDomain, and a few others) are all unmanaged COM interfaces. However, the .NET Framework 2.0 software development kit (SDK) includes a set of managed wrappers around these interfaces. The AppDomainViewer is written in managed code and accesses the CLR debugging system through these managed wrappers as shown in Figure 5-4.
Example 5-1 shows the source for the AppDomainViewer. I’ve omitted some of the boilerplate Microsoft Windows Forms code for clarity. The sample is generally straightforward, but there is one twist worth discussing. As described, the CLR debugging interfaces are COM interfaces. The underlying objects that implement these interfaces must run in a multithreaded apartment (MTA). However, the Windows Forms code used to display the user interface must run in a single-threaded apartment. To get around these conflicting requirements, I start an MTA thread whenever I need to call the debugging interfaces, then use the Windows Forms control method Begin.Invoke to marshal the data back to the user interface thread. You can examine this in the code for the RefreshTreeView method and look to see where it’s called.
Example 5-1. AppDomainViewer.cs
using System;
using System.IO;
using System.Drawing;
using System.Collections;
using System.ComponentModel;
using System.Windows.Forms;
using System.Data;
using System.Threading;
// Include the namespaces for the managed wrappers around
// the CLR debugging interfaces.
using Microsoft.Debugging.MdbgEngine;
using Microsoft.Debugging.CorPublish;
using Microsoft.Debugging.CorDebug;
namespace AppDomainViewer
{
public class ADView : System.Windows.Forms.Form
{
// Windows Forms control definitions omitted...
// The background thread used to call the debugging interfaces
private Thread m_corPubThread;
// The list of tree nodes to display in the UI. This list gets populated
// in RefreshTreeView.
private ArrayList m_rootNodes = new ArrayList();
// More Windows Forms setup code omitted...
[STAThread]
static void Main()
{
Application.Run(new ADView());
}
private void ADView_Load(object sender, System.EventArgs e)
{
// Populate the tree view when the application starts.
RefreshTreeView();
}
private void btnRefresh_Click(object sender, System.EventArgs e)
{
// Populate the tree view whenever the Refresh Button is clicked.
RefreshTreeView();
}
private void RefreshTreeView()
{
// The CLR debugging interfaces must be called from an MTA thread, but
// we're currently in an STA. Start a new MTA thread from which to call
// the debugging interfaces.
m_corPubThread = new Thread(new ThreadStart(ThreadProc));
m_corPubThread.IsBackground = true;
m_corPubThread.ApartmentState = ApartmentState.MTA;
m_corPubThread.Start();
}
public void ThreadProc()
{
try
{
MethodInvoker mi = new MethodInvoker(this.UpdateProgress);
// Create new instances of the managed debugging objects.
CorPublish cp = new CorPublish();
MDbgEngine dbg = new MDbgEngine();
m_rootNodes.Clear();
// Enumerate the processes on the machine that are running
// managed code.
foreach(CorPublishProcess cpp in cp.EnumProcesses())
{
// Skip this process—don't display information about the
// AppDomainViewer itself.
if(System.Diagnostics.Process.GetCurrentProcess().Id!=
cpp.ProcessId)
{
// Create a node in the tree for the process.
TreeNode procNode = new TreeNode(cpp.DisplayName);
// Enumerate the domains within the process.
foreach(CorPublishAppDomain cpad in cpp.EnumAppDomains())
{
// Create a node for the domain.
TreeNode domainNode = new TreeNode(cpad.Name);
// We must actually attach to the process
// to see information about the assemblies.
dbg.Attach(cpp.ProcessId);
try
{
// The debugging interfaces (at least for this task) are
// centered on modules rather than assemblies.
// So we enumerate the modules and find out which
// assemblies they belong to. In the general case,
// assemblies can contain multiple modules.
// This code is simpler, however. It assumes one
// module per assembly, which might yield incorrect
// results in some cases.
foreach(MDbgModule m in dbg.Processes.Active.Modules)
{
CorAssembly ca = m.CorModule.Assembly;
// Make sure we include only assemblies in this
// domain.
if (ca.AppDomain.Id == cpad.ID)
{
// Add a node for the assembly under the
// domain node.
domainNode.Nodes.Add(new TreeNode(
Path.GetFileNameWithoutExtension(ca.Name)));
}
}
}
finally
{
// Detach from the process and move on to the next one.
dbg.Processes.Active.Detach().WaitOne();
}
// Add the domain node under the process node.
procNode.Nodes.Add(domainNode);
}
m_rootNodes.Add(procNode);
}
}
// "Notify" the tree view control back on the UI thread that new
// data is available.
this.BeginInvoke(mi);
}
//Thrown when the thread is interrupted by the main thread-
// exiting the loop
catch (ThreadInterruptedException)
{
//Simply exit....
}
catch (Exception)
{
}
}
// This method is called from the MTA thread when new data is
// available.
private void UpdateProgress()
{
// Clear the tree, enumerate through the nodes of the array,
// and add them to the tree. Each of the top-level nodes represents
// a process, with nested nodes for domains and assemblies.
// m_rootNodes is constructed in RefreshTreeView.
treeView.Nodes.Clear();
foreach(TreeNode node in m_rootNodes)
{
treeView.Nodes.Add(node);
}
}
}
}If you’re building an application that relies on application domains for isolation, especially one in which you’ll be running code that comes from other vendors, determining how to partition your process into multiple domains is one of the most critical architectural decisions you’ll make. Choosing your domain boundaries incorrectly can lead to poor performance or overly complex implementations at best, and security vulnerabilities or incorrect results at worst.
Oftentimes, determining your domain boundaries involves mapping what you know about application domain isolation into some existing concept in your application model. For example, if you have an existing application that currently relies on a process boundary for isolation, you might consider replacing that boundary with an application domain boundary for managed code. Earlier in the chapter, I described how the presence of the CLR enabled the ASP team to move from a process boundary in their first few versions to an application domain model in ASP.NET. However, replacing a process boundary with a domain boundary clearly isn’t the only scenario in which application domains apply.
Application domains often fit well into applications that have an existing extensibility model, but haven’t used process isolation in the past because of the cost or other practical reasons. A typical example is an application that supports an add-in model. Consider a desktop application that enables users to write add-ins that extend the functionality of the application. In the unmanaged world, these extensions are commonly written as COM DLLs that are loaded inprocess with the main application. If the user loads multiple add-ins, you’ll end up with several of these DLLs running in the same address space. In many unmanaged applications, often it isn’t practical for the application author to isolate these DLLs in separate processes. Performance is always a concern, but it also might be the case that process isolation just doesn’t fit with the application model. For example, the add-ins might need to manipulate an object model published by the application. Application domains work very well in scenarios such as these because they are lightweight enough to be used for isolation where a process boundary is too costly.
Earlier in the chapter, I talked about the various aspects of domain isolation, including access to types, scoping of configuration data, and security policy. Whether you’re incorporating managed code into an existing extensible application or writing a new application from scratch, these criteria are a primary factor in determining where your domain boundaries lay. However, you must keep in mind other considerations as well. Performance, reliability, and the ability to unload code from a running process are all directly related to application domains and must be carefully considered. In particular, your design should be geared toward reducing the number of calls made between domains and should consider your requirements for unloading code from a running process.
You might need to unload code from a running process in various scenarios, such as when you want to reduce the working set or phase out the use of an older version of an assembly when a new version is available.
To remove managed code from a process, you must unload the entire domain containing the code you want to remove. Individual assemblies or types cannot be unloaded. No underlying technical constraint forces this particular design, and in fact, the ability to unload an individual assembly is one of the most highly requested CLR features. It’s quite possible that some day the CLR will support unloading at a finer granularity, but for now, the application domain remains the unit at which code can be removed from a process.
The nature of an application domain as the unit for unloading almost always plays a very significant role in how you decide to partition your process into multiple application domains. In fact, I’ve seen several cases in which a process is partitioned into multiple application domains for this reason alone. If you have a specific need to unload individual pieces of code, you must load that code into a separate application domain so it can be removed without affecting the rest of the process.
For more details on unloading, including how to unload application domains programmatically, see the section "Unloading Application Domains" later in this chapter.
Calls between objects in different application domains go through the remoting infrastructure just as calls between processes or machines do. As a result, a performance cost is associated with making a call from an object in one application domain to an object in another domain. The cost of the call isn’t nearly as expensive as a cross-process call, but nevertheless, the cost can be significant depending on the number of calls you make and the amount of data you pass on each call. This cost must be carefully considered when designing your application domain model.
Performance isn’t the only reason for minimizing the amount of cross-domain calls, however. As described, the CLR maintains proxies that arbitrate calls between objects in different application domains. One of these proxies exists in the application domain of the code making the call (the caller), and one exists in the domain that contains the code being called (the callee). To provide type safety and to support rich calling semantics, the proxies on either side of the call must have the type definition for the object being called. So, the assembly containing the object you are calling must be loaded into both application domains.
Making an assembly visible to multiple application domains complicates your approach to deployment. Every domain has a property that describes the root directory under which it will search for private assemblies (i.e., assemblies visible only to that domain). In many cases, placing assemblies in this directory or one of its subdirectories is all you need. You’ve probably used this technique either with executables launched from the command line or ASP.NET applications. Deploying assemblies in this way is convenient and extremely easy. Unfortunately, the story isn’t quite as straightforward for assemblies that must be visible to multiple domains. These assemblies are referred to as shared assemblies. Shared assemblies have different naming and deployment requirements than private assemblies do. First, shared assemblies must have a strong name. A strong name is a cryptographically strong, unique name that the CLR uses to uniquely identify the code and to make security checks. Second, unless you customize how assemblies are loaded (see Chapter 8), assemblies with strong names must be placed in either the global assembly cache (GAC) or in a common location identified through a configuration file. When placed in one of these locations, the ability to delete or replicate your application just by moving one directory tree is lost. Furthermore, shared assemblies deployed in this manner are visible to every application on the machine. In general, this might be OK, but it does open the possibility that your assembly could be used for purposes other than you originally intended, which should make you uneasy regarding security attacks. In short, making an assembly visible to more than one application domain requires some extra steps and is harder to manage.
A process is partitioned into application domains most efficiently when the amount of crossdomain communication is limited, for the reasons I’ve just described: the performance is better and the deployment story is more straightforward. However, communication between application domains cannot be completely eliminated. If it were, there would be no way to load and run a type in a domain other than the one in which you were running! Typical extensible applications, whether written entirely in managed code or written using the CLR hosting interfaces, contain at least one assembly that is loaded into every domain in the process. This assembly is part of the implementation of the extensible application and provides basic functionality, including creating and configuring new application domains and running the application’s extensions in those domains. Throughout the remainder of this chapter, I refer to these assemblies as HostRuntime assemblies. In the most efficient designs almost all communication between application domains goes through these HostRuntime assemblies. The key is to partition your process in such a way that the add-ins you load into individual application domains have little or no need to communicate with each other—the less cross-domain communication you have, the better your performance will be. Figure 5-5 shows a scenario in which the communication between domains is limited to the HostRuntime assemblies.
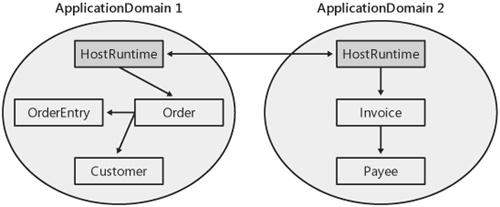
Often, the best way to understand how to partition your process into multiple application domains is to look at some examples of how other products have done it. In this section, I discuss the designs adopted by existing CLR hosts, including ASP.NET, SQL Server, and Internet Explorer.
The Microsoft IIS Web server enables multiple Web sites to be hosted on the same physical machine through virtual roots. Each virtual root appears as its own site when accessing the Web server. Each virtual root has a base directory under which all content and code for that Web application are stored. In ASP.NET each virtual root is mapped to an application domain. That is, all code running in a particular application domain either originates in the virtual root’s base directory (or a subdirectory thereof) or is referenced from a page or code contained in that directory. By aligning virtual roots and application domains, ASP.NET uses domains to make sure that multiple Web applications running in the same process are isolated from each other. Note, too, that all instances of particular Web applications are not necessarily run in the same application domain. That is, ASP.NET load balances instances of the application across multiple domains in multiple processes. So, although it’s always true that a particular domain contains code from only one application, it is not necessarily true that all instances of the application run in the same domain.
ASP.NET’s implementation of application domains is a perfect example of mapping a domain model to an existing construct that defines an application model (i.e., a virtual directory).
SQL Server 2005 maps the database concept of a schema to an application domain. A schema is a collection of database objects that are owned by a single user and form a namespace. These database objects include types, stored procedures, and functions that are written with managed code. A given application domain contains objects that are all from the same schema. In SQL Server it is possible for an object in one schema to reference an object in another schema. Because objects from different schemas are loaded in separate application domains, a remote call is required for calls between schemas. The less a given application calls objects in different schemas, the better its performance generally is.
Internet Explorer is the only CLR host I’m aware of that lets the developer programmatically control where the application domain boundaries lie. By default, an application domain is created per site (as in the ASP.NET model). In the vast majority of cases, this default works well in that it gathers all controls from a particular Web site into a single domain. This means that controls that run in the same Internet Explorer process, but that originate from different sites, cannot discover and access each other.
However, there are hosting scenarios in which it makes sense to define an application to be at smaller granularity than the entire site. Examples of this scenario include sites that allocate particular subdirectories of pages for individual users or corporations. In these scenarios, code running in a particular subsite must be isolated from code running in the rest of the site. To enable these scenarios, the Internet Explorer host lets the developer specify a directory to serve as the application’s root. This directory must be a subdirectory of the site’s directory and is specified by using a <link rel=...> tag to identify a configuration file for the Web application. You’ll see in Chapter 6 how the creator of an application domain can set a property defining the base directory corresponding to that domain. When processing pages from the site, the Internet Explorer host loads all controls from pages that point to the same configuration file in the same application domain. In this way, the Internet Explorer host enables a developer to specify an isolation boundary at a level of granularity finer than a site. A full description of how to use the <link rel= ...> tag can be found in the .NET Framework SDK.
If you’re writing an application involving multiple application domains, you’ll almost certainly want to take advantage of a concept called an application domain manager. An application domain manager makes it easy to provide much of the infrastructure your application will need to manage multiple domains in a process. In particular, an application domain manager helps you do the following:
Implement a host runtime. When you provide an application domain manager, the CLR takes care of loading an instance of your domain manager into each application domain that gets created in the process. This is exactly the behavior I talked about needing in a host runtime. In essence, your application domain manager serves as your host runtime.
Customize individual application domains. An application domain manager enables you to intercept all calls that create application domains in the process. Each time a new application domain is being created, your domain manager is called to give you a chance to configure the new domains as you see fit. An application domain manager even enables you to reuse an existing domain instead of creating a new one when requested. In this way, you can control how many application domains exist in your process and what code runs in each of them. This role of an application domain manager is covered in detail in Chapter 6.
Call into managed code from your CLR host. As described in Chapter 2 and Chapter 3, all CLR hosts contain some unmanaged code that is used to initialize and start the CLR. After the CLR is loaded into the process, the host needs to transition into managed code to run the application extensions the host supports. This is done by calling methods on your application domain manager through the CLR COM Interoperability layer from the unmanaged portion of your host.
Providing an application domain manager requires two steps. First you must implement a managed class that derives from System.AppDomainManager. Once your class is written, you must direct the CLR to use your domain manager for all application domains created in your process. The next few sections describe these steps in detail.
The System.AppDomainManager class provides the framework you need to write an application domain manager. The implementation of System.AppDomainManager doesn’t provide much functionality, but rather is intended to be used as a base class for writing application domain managers for different scenarios. Application domain managers play a key role in many aspects of multidomain applications. In addition to the introduction provided in this chapter, I use an application domain manager in Chapter 10 to customize the security settings for application domains and in Chapter 6 to customize how application domains are created. Table 5-1 describes the methods on System.AppDomainManager and where in the book they are discussed.
Table 5-1. The Methods of System.AppDomainManager
Method | Purpose |
|---|---|
CreateDomain | As you’ll see later in this chapter, application domains are created by calls to the static method System.AppDomain.Create-Domain. Each time this method is called, the CLR calls your application domain manager to enable you to customize the creation of the new application domain. I discuss this method in more detail in Chapter 6. |
InitializeNewDomain | After a new application domain is created, the CLR calls InitializeNewDomain from within the newly created application domain. This method gives you a chance to set up any infrastructure you need within the domain. If you’re writing a CLR host, you can use InitializeNewDomain to pass a pointer to your domain manager out to the unmanaged portion of your host. I show you how to do this later in this chapter when I describe how to associate a domain manager with a process using the CLR hosting APIs. |
Each application domain manager has a set of flags that are used to control various aspects of how the domain manager is initialized. In the "Associating an Application Domain Manager with a Process" section later this chapter, I discuss how InitializationFlags is used to enable communication with a domain manager from unmanaged code | |
ApplicationActivator | The ApplicationActivator property is part of the new CLR infrastructure in .NET Framework version 2.0 that is used for activating application add-ins defined by a formal manifest. I don’t cover activation using a manifest in this book. Details can be found in the .NET Framework SDK. |
HostSecurityManager | This property enables you to return an instance of a HostSecurityManager class that the CLR will use to configure security for application domains as they are created. This property is covered in Chapter 10. |
HostExecutionContextManager | This property enables you to return an instance of a HostExecutionContextManager class that the CLR will call when determining how context information flows across thread transitions. This property is not discussed further in this book. Refer to the .NET Framework SDK for more information on this property. |
CreateDomainHelper | CreateDomainHelper is a protected static method that application domain managers can call to create new application domains. This method is typically called from a domain manager’s implementation of CreateDomain. CreateDomainHelper is discussed in more detail in Chapter 6. |
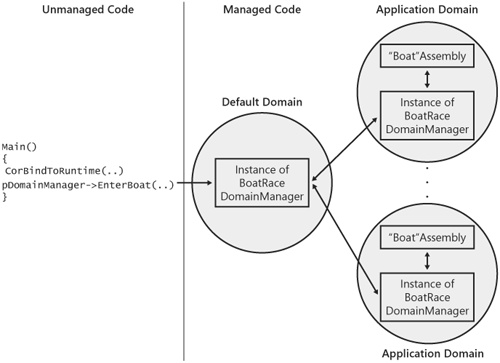
Now that I’ve discussed the role of an application domain manager, I want to dig into the details by writing one. Throughout the remainder of this chapter and into the next (Chapter 6), we’ll build an application domain manager for a game application that simulates a sailboat race. The application will be a CLR host that enables third parties to write assemblies that represent individual sailboats in the race. These assemblies are the add-ins to the application. In particular, the application and its domain manager will have the following characteristics:
Each boat in the race will be loaded into its own application domain. We’ll use application domains to ensure that individual boats are isolated from each other.
Our application domain manager will be the sole means used to communicate between application domains. Therefore, our domain manager will have more methods than just the ones defined in its base class, System.AppDomainManager. We’ll add our own methods that enable us to interact with boats loaded in other application domains.
Our application domain manager will serve as the means for calling from the unmanaged portion of our host into managed code. So our domain manager will derive from an interface that we can call from unmanaged code using the CLR’s COM Interoperability layer.
Only our domain manager will be loaded into the default application domain. The addins (the boats) will be loaded into application domains we create. I’ve chosen this design because the default application domain cannot be unloaded. Were we to load a boat into the default domain, we’d never be able to unload it without shutting down the process. The practice of loading only your host runtime into the default domain is very common among CLR hosts for exactly the reason we’ve chosen to use it in this example.
These characteristics of our boat race host can be seen in the architecture diagram shown in Figure 5-6.
The code for our application domain manager consists of one interface and one class. The interface contains a method we’ll use to communicate between domain managers in different application domains and to communicate with the domain manager in the default domain from the unmanaged portion of our host. I created a separate interface rather than just adding additional methods directly to our domain manager class because we need to call through the interface from COM.[3] As expected, our application domain manager class derives both from this interface and from System.AppDomainManager. The initial interface and a skeletal class definition are shown here:
namespace BoatRaceHostRuntime
{
public interface IBoatRaceDomainManager
{
Int32 EnterBoat(string assemblyFileName, string boatTypeName);
}
public class BoatRaceDomainManager : AppDomainManager,
IBoatRaceDomainManager
{
// Implementation of EnterBoat and other methods omitted for now.
}
}Now that I’ve sketched out what a simple application domain manager looks like, we need to associate our application domain manager class with the process we’re hosting. In this way, the CLR will create an instance of our domain manager in each new application domain for us. In the .NET Framework version 2.0 release of the CLR, all application domains in the process contain the same application domain manager type. In future releases it might be possible to have different application domain managers for different application domains.
You can use either of two approaches to associate your domain manager type with a process: you can specify the name of your type using either the CLR hosting APIs or a set of environment variables. The next two sections describe these two approaches.
CLR hosts use the ICLRControl::SetAppDomainManagerType method to associate an application domain manager with a process. Recall from Chapter 2 that you get a pointer to the ICLRControl interface by calling the GetCLRControl method on the ICLRRuntimeHost pointer returned from CorBindToRuntimeEx. SetAppDomainManagerType takes two string parameters: one that gives the identity of the assembly containing the application domain manager type and one that gives the name of the type itself. Here’s the signature of ICLRControl::SetAppDomainManagerType from mscoree.idl:
interface ICLRControl: IUnknown
{
HRESULT SetAppDomainManagerType(
[in] LPCWSTR pwzAppDomainManagerAssembly,
[in] LPCWSTR pwzAppDomainManagerType);
}If we compiled our domain manager into an assembly with the identity
BoatRaceHostRuntime, Version=1.0.0.0, PublicKeyToken=5cf360b40180107c, culture=neutral
the following code snippet would initialize the CLR and establish our BoatRaceHostRuntime.BoatRaceDomainManager class as the application domain manager for the process:
int main(int argc, wchar_t* argv[])
{
// Initialize the CLR using CorBindToRuntimeEx. This gets us
// the ICLRRuntimeHost pointer we'll need to call Start.
ICLRRuntimeHost *pCLR = NULL;
HRESULT hr = CorBindToRuntimeEx(
L"v2.0.41013,
L"wks",
STARTUP_CONCURRENT_GC,
CLSID_CLRRuntimeHost,
IID_ICLRRuntimeHost,
(PVOID*) &pCLR);
// Start the CLR.
hr = pCLR->Start();
// Get a pointer to the ICLRControl interface.
ICLRControl *pCLRControl = NULL;
hr = pCLR->GetCLRControl(&pCLRControl);
// Call SetAppDomainManagerType to associate our domain manager with
// the process.
pCLRControl->SetAppDomainManagerType(
L BoatRaceHostRuntime, Version=1.0.0.0,
PublicKeyToken=5cf360b40180107c, culture=neutral,
L"BoatRaceHostRuntime.BoatRaceDomainManager"
);
// rest of main() omitted...
}One of the roles of an application domain manager is to serve as the entry point into managed code for CLR hosts. To make this initial transition into managed code, the unmanaged portion of the host must have an interface pointer to the instance of the application domain manager that has been loaded into the default application domain. Given this pointer, we can then call from unmanaged code to managed code using COM interoperability. Obtaining a pointer to an instance of an application domain manager in unmanaged code requires two steps. First, the application domain manager must notify the CLR that it would like a pointer to a domain manager sent out to unmanaged code. This is done by setting the InitializationFlags property on System.AppDomainManager to DomainManagerInitializationFlags.RegisterWithHost. Next, the unmanaged portion of the host must provide an implementation of IHostControl::SetAppDomainManager to receive the pointer. The relationship between these two steps is shown in Figure 5-7.
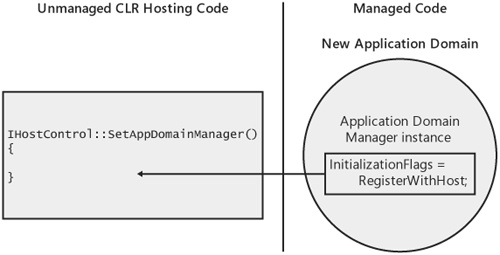
By setting InitializationFlags to RegisterWithHost, you make the unmanaged hosting code in the process aware of the new instance of your application domain manager, and thus that a new application domain has been created. A convenient place to set InitializationFlags is from your domain manager’s implementation of InitializeNewDomain. When a new application domain is created, the CLR creates a new instance of your application domain manager in the new domain and calls its InitializeNewDomain method. This gives your domain manager a chance to initialize any state in the new domain as discussed in Chapter 6. Our BoatRaceDomainManager sets InitializationFlags from InitializeNewDomain as shown in the following code snippet:
public class BoatRaceDomainManager : AppDomainManager,
IBoatRaceDomainManager
{
public override void InitializeNewDomain(AppDomainSetup
appDomainInfo)
{
InitializationFlags = DomainManagerInitializationFlags.RegisterWithHost;
}
}When you set InitializationFlags to RegisterWithHost, the CLR calls the SetAppDomainManager method on your implementation of IHostControl to pass information about the instance of your application domain manager out to the unmanaged portion of your host. Recall from Chapter 2 that IHostControl is one of the CLR hosting interfaces implemented by the host. Here’s the signature for IHostControl:: SetAppDomainManager from mscoree.idl:
interface IHostControl : IUnknown
{
// other methods omitted...
HRESULT SetAppDomainManager(
[in] DWORD dwAppDomainID,
[in] IUnknown* pUnkAppDomainManager);
}SetAppDomainManager has two parameters. The first is a numerical identifier for the application domain that has just been created. Whenever a new domain is created, the CLR generates a unique identifier and assigns it to the domain. This identifier is used to interact with the application domain in various places throughout the CLR hosting interfaces. For example, you can use the unique identifier passed to SetAppDomainManager to later call ICLRRuntimeHost::UnloadAppDomain to unload the application domain from the process. You can determine an application domain’s unique identifier in managed code using the Id property on the System.AppDomain class.
The second parameter to SetAppDomainManager is a COM interface pointer to the new instance of your application domain manager. The type of this pointer is IUnknown. Clearly, we’ll need a pointer to a more specific interface to get real work done. Recall that our application domain manager (BoatRaceDomainManager) is derived from an interface we defined in C# called IBoatRaceDomainManager. This interface has the specific methods we need to interact with the host runtime we implemented in managed code. To call these methods we need to obtain this interface from the IUnknown that was passed to SetAppDomainManager. We do this using the standard COM QueryInterface mechanism. Before we can call QueryInterface, however, we must have a definition of IBoatRaceDomainManager in unmanaged code. The easiest way to get an unmanaged definition of an interface you’ve defined in managed code is to use the tlbexp.exe tool that ships in the .NET Framework SDK. This tool takes a managed assembly as input and generates a COM type library that can be used to interact with managed classes through COM. Running tlbexp.exe on our BoatRaceHostRuntime assembly (the assembly containing our application domain manager) generates a type library called BoatRaceHostRuntime.tlb. We can use the #import directive in C++ to import our type library so we have access to the COM definition of IBoatRaceDomainManager:
#import <BoatRaceHostRuntime.tlb> using namespace BoatRaceHostRuntime;
Now we have all we need to use QueryInterface to get a pointer of type IBoatRaceDomainManager as shown in the following sample implementation of SetAppDomainManager:
HRESULT STDMETHODCALLTYPE CHostControl::SetAppDomainManager(
DWORD dwAppDomainID,
IUnknown *pUnkAppDomainManager)
{
HRESULT hr = S_OK;
IBoatRaceDomainManager *pDomainManager = NULL;
hr = pUnkAppDomainManager->QueryInterface(__uuidof(IBoatRaceDomainManager),
(PVOID*) &pDomainManager);
// pDomainManager can now be used to access the new instance of
// BoatRaceDomainManager.
return hr;
}In hosts involving multiple application domains, the CLR calls IHostControl::SetAppDomainManager multiple times—once for every domain that is created in the process. Most hosts find it useful to save the data needed to access the application domain that the CLR passes to SetAppDomainManager. As I mentioned earlier, the application domain’s unique identifier is used to interact with the domain in various places throughout the hosting APIs. In addition, no APIs provided enable you to enumerate the application domains in the process other than the CLR debugging APIs that were described earlier in the chapter as part of the AppDomainViewer sample. So, the most convenient way to get a list of all application domains in the process is to build up the list yourself by saving the identifiers and interface pointers you obtain from SetAppDomainManager.
You might also find it useful to explicitly save the interface pointer to the instance of the application domain manager that exists in the default application domain. It is likely that the unmanaged portion of your CLR host will interact mostly with the instance of your application domain manager that is loaded in the default application domain. That application domain manager will then do most of the work needed to create other domains and run the application’s add-ins in those domains. This is the approach taken with our boat race example, as shown in Figure 5-7.
The following class is a sample implementation of IHostControl that both maintains a list of all application domain managers (and hence application domains) created in the process and explicitly identifies the application domain manager for the default domain. The list of application domain managers is stored in a Standard Template Library (STL) map that relates the unique identifier for an application domain to the interface pointer used to interact with its application domain manager. Here’s the class definition for our sample implementation of IHostControl:
typedef map<DWORD, IBoatRaceDomainManager *> DomainMap;
class CHostControl : public IHostControl
{
public
// IHostControl
HRESULT STDMETHODCALLTYPE GetHostManager(REFIID riid,
void **ppObject);
HRESULT STDMETHODCALLTYPE SetAppDomainManager(DWORD dwAppDomainID,
IUnknown *pUnkAppDomainManager);
HRESULT STDMETHODCALLTYPE GetDomainNeutralAssemblies(
ICLRAssemblyReferenceList **ppReferenceList);
// IUnknown
virtual HRESULT STDMETHODCALLTYPE QueryInterface(const IID &iid,
void **ppv);
virtual ULONG STDMETHODCALLTYPE AddRef();
virtual ULONG STDMETHODCALLTYPE Release();
CHostControl();
virtual ~CHostControl();
IBoatRaceDomainManager *GetDomainManagerForDefaultDomain();
DomainMap &GetAllDomainManagers();
private:
long m_cRef;
IBoatRaceDomainManager *m_pDefaultDomainDomainManager;
DomainMap m_Domains;
};As you can see from the class definition, CHostControl stores both the pointer to the domain manager in the default application domain and the map of application domain identifiers to interface pointers in the private member variables m_pDefaultDomainDomainManager and m_Domains. The class also provides the public methods GetDomainManagerForDefaultDomain and GetAllDomainManagers that enable the rest of the host to access the data stored in the class.
The following implementations of SetAppDomainManager, GetDomainManagerForDefaultDomain, and GetAllDomainManagers show how both the map and the variable holding the pointer to the default application domain are populated and returned.
HRESULT STDMETHODCALLTYPE CHostControl::SetAppDomainManager(
DWORD dwAppDomainID,
IUnknown *pUnkAppDomainManager)
{
HRESULT hr = S_OK;
// Each time a domain gets created in the process, this method is
// called. We keep a mapping of domainIDs to pointers to application
// domain managers for each domain in the process. This map is handy for
// enumerating the domains and so on.
IBoatRaceDomainManager *pDomainManager = NULL;
hr = pUnkAppDomainManager->QueryInterface(
__uuidof(IBoatRaceDomainManager),
(PVOID*) &pDomainManager);
assert(pDomainManager);
m_Domains[dwAppDomainID] = pDomainManager;
// Save the pointer to the default domain for convenience. We
// initialize m_pDefaultDomainDomainManager to NULL in the
// class's constructor. The first time this method is called
// is for the default application domain.
if (!m_pDefaultDomainDomainManager)
{
m_pDefaultDomainDomainManager = pDomainManager;
}
return hr;
}
IBoatRaceDomainManager* CHostControl::GetDomainManagerForDefaultDomain()
{
// AddRef the pointer before returning it.
if (m_pDefaultDomainDomainManager) m_pDefaultDomainDomainManager->AddRef();
return m_pDefaultDomainDomainManager;
}
DomainMap& CHostControl::GetAllDomainManagers()
{
return m_Domains;
}Now that we’ve built a host control object that enables us to get interface pointers to instances of our application domain manager, let’s take a look at a small sample that shows how to call through those pointers into managed code from a CLR host. Recall that the interface we use to interact with our domain managers, IBoatRaceDomainManager, has a method called EnterBoat that takes the name of the assembly and the type that implement one of our application’s add-ins. The following sample CLR host uses the host control object to get a pointer to the instance of our application domain manager in the default application domain. It then calls the EnterBoat method to add a boat to our simulated boat race.
# include "stdafx.h"
#include "CHostControl.h"
int main(int argc, wchar_t* argv[])
{
// Start the CLR. Make sure .NET Framework version 2.0 is used.
ICLRRuntimeHost *pCLR = NULL;
HRESULT hr = CorBindToRuntimeEx
L"v2.0.41013,
L"wks",
STARTUP_CONCURRENT_GC,
CLSID_CLRRuntimeHost,
IID_ICLRRuntimeHost,
(PVOID*) &pCLR);
assert(SUCCEEDED(hr));
// Create an instance of our host control object and "register"
// it with the CLR.
CHostControl *pHostControl = new CHostControl();
pCLR->SetHostControl((IHostControl *)pHostControl);
// Start the CLR in the process.
hr = pCLR->Start();
assert(SUCCEEDED(hr));
// Get a pointer to our AppDomainManager running in the default domain.
IBoatRaceDomainManager *pDomainManagerForDefaultDomain =
pHostControl->GetDomainManagerForDefaultDomain();
assert(pDomainManagerForDefaultDomain);
// Call into the default application domain to enter a boat in the race.
pDomainManagerForDefaultDomain->EnterBoat("StevensBoat",
"J29.ParthianShot");
// Clean up.
pDomainManagerForDefaultDomain->Release();
pHostControl->Release();
return 0;
}You can associate your application domain manager with a process using a set of environment variables instead of through the CLR hosting APIs. Setting the environment variables requires less code, but you lose the ability to interact with your domain manager from unmanaged code. Specifically, if you haven’t implemented the IHostControl interface, the CLR cannot call out to your unmanaged code to give you a pointer to the domain manager. As a result, specifying an application domain manager using a configuration file is useful only if your extensible application is written completely in managed code or if you’re writing a CLR host but don’t need to interact with your domain manager from unmanaged code.
The environment variables you need to set to associate your application domain manager with a process are called APPDOMAIN_MANAGER_ASM and APPDOMAIN_MANAGER_TYPE. APPDOMAIN_MANAGER_ASM must be set to the fully qualified name of the assembly containing your application domain manager type, whereas APPDOMAIN_MANAGER_TYPE must be set to the name of the type within that assembly that implements your domain manager. For example, if we were to associate our BoatRaceDomainManager type with a process, the two environment variables would have the following values:
APPDOMAIN_MANAGER_ASM=BoatRaceHostRuntime, Version=1.0.0.0, PublicKeyToken=5cf360b40180107c, culture=neutral APPDOMAIN_MANAGER_TYPE= BoatRaceHostRuntime.BoatRaceDomainManager
Setting these values in an unmanaged CLR host is straightforward—just call the Win32 API SetEnvironmentVariable any time before you start the CLR using ICLRRuntimeHost::Start. The following example uses SetEnvironmentVariable to set APPDOMAIN_MANAGER_ASM and APPDOMAIN_MANAGER_TYPE to the values described previously:
int main(int argc, wchar_t* argv[])
{
// Start the CLR. Make sure .NET Framework 2.0 is used.
ICLRRuntimeHost *pCLR = NULL;
HRESULT hr = CorBindToRuntimeEx
L"v2.0.41013
L"wks",
STARTUP_CONCURRENT_GC,
CLSID_CLRRuntimeHost,
IID_ICLRRuntimeHost,
(PVOID*) &pCLR);
assert(SUCCEEDED(hr));
// Use Win32's SetEnvironmentVariable to set up the domain manager.
SetEnvironmentVariable(L"APPDOMAIN_MANAGER_TYPE",
L"BoatRaceHostRuntime.BoatRaceDomainManager");
SetEnvironmentVariable(L"APPDOMAIN_MANAGER_ASM",
L"BoatRaceHostRuntime, Version=1.0.0.0,
PublicKeyToken=5cf360b40180107c,
culture=neutral");
// Start the CLR.
hr = pCLR->Start();
assert(SUCCEEDED(hr));
// The rest of the host's code is omitted.
}If your application is written entirely in managed code, setting APPDOMAIN_MANAGER_ASM and APPDOMAIN_MANAGER_TYPE isn’t as straightforward. You can’t set these environment variables from within your process as we did in the earlier unmanaged example because by the time your managed code is running, it’s too late. The CLR honors the environment variables only if they are set before the default application domain is created. So you must write a small bootstrap application that creates a process to run your real application. Values for APPDOMAIN_MANAGER_ASM and APPDOMAIN_MANAGER_TYPE can be passed into the new process as it’s created. The following example shows how you might accomplish this using the Process and ProcessStartInfo classes from System.Diagnostics:
using System;
using System.Diagnostics;
namespace AppDomainManagerProcess
{
class Launch
{
[STAThread]
static void Main(string[] args)
{
ProcessStartInfo mdProcessInfo = new
ProcessStartInfo("BoatRaceHost.exe");
mdProcessInfo.EnvironmentVariables["APPDOMAIN_MANAGER_ASM"] =
"BoatRaceHostRuntime, Version=1.0.0.0,
PublicKeyToken=5cf360b40180107c, culture=neutral";
mdProcessInfo.EnvironmentVariables["APPDOMAIN_MANAGER_TYPE"] =
"BoatRaceHostRuntime.BoatRaceDomainManager";
mdProcessInfo.UseShellExecute = false;
Process.Start(mdProcessInfo);
}
}
}Application domains are exposed in the .NET Framework programming model through the System.AppDomain class. System.AppDomain has a static method called CreateDomain you can use to create a new application domain. There are several different flavors of AppDomain.CreateDomain, ranging from a simple method that creates a domain with just a friendly name to methods that create domains with custom security evidence or configuration properties. The signatures for CreateDomain are as follows:
public static AppDomain CreateDomain(String friendlyName)
public static AppDomain CreateDomain(String friendlyName,
Evidence securityInfo)
public static AppDomain CreateDomain(String friendlyName,
Evidence securityInfo,
AppDomainSetup info)The parameters to CreateDomain are described in Table 5-2.
Table 5-2. The Parameters to AppDomain.CreateDomain
Parameter | Description |
|---|---|
friendlyName | A textual name to associate with the domain. The contents of this string are completely up to the creator of the domain—the CLR doesn’t require specific formats or conventions to be followed. This name is typically used to display information about application domains in user interfaces. For example, AppDomainViewer uses a domain’s friendly name in its tree view. Similarly, some debuggers use friendly names to display application domains when attached to a process. A domain’s friendly name can be accessed using the friendlyName property. Once an application domain is created, its name cannot be changed. |
securityInfo | Security evidence to be associated with the domain. This parameter is optional in that you can pass null, causing the CLR not to set any evidence. Earlier in the chapter, I talked about two ways to customize the Code Access Security for an application domain—provide a domain-level policy tree and limit the permissions granted to an assembly using application domain evidence. This parameter is the way you set that evidence. Much more information about domain evidence is provided in Chapter 10. |
info | An object of type System.AppDomainSetup that contains all the configuration properties for the domain. Using this object to configure an application domain is a broad subject in and of itself. A complete description of how to use AppDomainSetup is provided in Chapter 6. |
Choosing which flavor of CreateDomain to call is dictated by how much you need to configure the domain upfront. For example, several configuration properties are exposed by AppDomainSetup that can be specified only when the domain is created (more on this in Chapter 6). I typically find that the CreateDomain that takes a friendly name, security evidence, and an AppDomainSetup object is the most useful. When a high degree of application domain configuration is required, this is the only flavor of CreateDomain that gives you full access to all the configuration options. For scenarios in which such customization is not required, any of its three parameters can be set to null.
Calling CreateDomain returns a new instance of System.AppDomain that you use to start interacting with the domain. The following code snippet shows a typical call to CreateDomain. Note that for now I’m passing null for both the security evidence and AppDomainSetup parameters. As described, I cover the details of those parameters in upcoming chapters.
using System;
AppDomain ad = AppDomain.CreateDomain("Stevenpr Domain", null, null);Note
For completeness, it’s worth noting that there is a fourth flavor of CreateDomain that takes just a few of the configuration properties exposed through AppDomainSetup:
public static AppDomain CreateDomain(String friendlyName,
Evidence securityInfo,
String appBasePath,
String appRelativeSearchPath,
bool shadowCopyFiles)This flavor of CreateDomain is not all that useful in my opinion. It was implemented before the AppDomainSetup object was and is kept in place for backward-compatibility reasons. As described, using AppDomainSetup is the preferred way to configure an application domain as it is being created.
Typically, one of the first things you’ll want to do after creating a new domain is load an assembly into it. If you’re writing an extensible application, it’s likely that the assembly you load into the new domain will be an add-in. Recall from earlier discussions about application domain isolation that you typically want the code that loads your add-ins to be running in the domain in which the add-in is to be loaded. Otherwise, a proxy to the new extension would have to be returned across the application domain boundary, thereby requiring the assembly containing the extension to be loaded into multiple domains. The simplest, most efficient way to load an assembly from within its target domain is to take advantage of the host runtime, or application domain managers, discussed in the previous section. Because the CLR automatically creates an instance of an application domain manager in each new application domain, you must simply pass information about which assembly to load into the new domain manager and let it take care of the loading. Remember, too, that this practice also results in a clean design because all communication between application domains is done through the domain managers.
System.AppDomain has a property called DomainManager that returns the instance of the application domain manager for the given application domain. After a new domain is created, you can use this property to get its domain manager with which you can start interacting with the new domain. To see how this works, let’s return to our boat race example and look at the implementation of the EnterBoat method. EnterBoat is responsible for creating a new application domain and loading the new boat into that domain. The implementation of BoatRaceDomainManager.EnterBoat is as follows:
public class BoatRaceDomainManager : AppDomainManager,
IBoatRaceDomainManager
{
// Other methods omitted...
public Int32 EnterBoat(string assemblyFileName, string boatTypeName)
{
// Create a new domain in which to load the boat.
AppDomain ad = AppDomain.CreateDomain(boatTypeName, null, null);
// Get the instance of BoatRaceDomainManager running in the
// new domain.
BoatRaceDomainManager adManager =
(BoatRaceDomainManager)ad.DomainManager;
// Pass the assembly and type names to the new domain so the
// assembly can be loaded.
adManager.InitializeNewBoat(assemblyFileName, boatTypeName);
return ad.Id;
}
}EnterBoat first creates a new application domain for the boat by calling AppDomain.CreateDomain. After the domain is created, AppDomain.DomainManager is used to get the instance of the domain manager in the new domain. Finally, EnterBoat calls a method on BoatRaceDomainManager called InitializeNewBoat, passing the name of the assembly containing the boat and the name of the type that represents the boat. InitializeNewBoat then takes this information and uses the methods on the System.Reflection.Assembly class to load the assembly into the new domain. The discussion of how to load assemblies is broad enough to warrant an entire chapter. I cover this topic in detail in Chapter 7.
Note
You might recall from looking at Table 5-1 that System.AppDomainManager also has a method called CreateDomain. This method is not intended to be called explicitly. Instead, as you’ll see in Chapter 6, the CLR calls AppDomainManager.CreateDomain (or its overrides) whenever a new application domain is created using AppDomain.CreateDomain. This gives the domain manager a chance to configure the new domain as it is being created.
Note
If you’re familiar with the CLR hosting APIs that were provided in the first two versions of the CLR (.NET Framework version 1.0 and .NET Framework version 1.1), you might recall that the ICorRuntimeHost interface includes methods that enable you to create application domains directly from unmanaged code. These methods returned an interface pointer through which you could interact directly with the new domain using COM interoperability. The ability to create an application domain from unmanaged code was occasionally useful, but in practice most hosts created their domains in managed code because the programming model was simpler and tended to perform better because the amount of communication between unmanaged and managed code was less. To encourage this model, and to reduce the number of duplicate ways to do the same thing, Microsoft has removed the ability to create application domains directly from unmanaged code in .NET Framework version 2.0.
One aspect of how the isolation provided by an application domain differs from that provided by a process is in the treatment of operating system threads. You must consider two primary differences when designing your application to use domains most effectively. First, threads are not confined to a particular application domain. In the Windows process model, all threads are specific to a process. A given thread cannot begin execution in one process and continue execution in another process. This is not true in the application domain model. Threads are free to wander between domains as necessary. The CLR does the proper checks and data structure adjustments at the domain boundaries to ensure that information associated with the thread that is intended for use only within a single domain doesn’t leak into the other domain, thereby affecting its behavior. For example, you can store data on a thread using the Alloc(Named)DataSlot methods on the System.Threading.Thread object. These methods and the related methods to retrieve the data provide a managed implementation of thread local storage (TLS). Whenever a domain boundary is crossed, the CLR ensures the managed TLS is removed from the thread and saved in the application domain data structures so that the thread appears "clean" when it enters the new domain. In contrast, some thread-related state should flow between domains. The primary example of this type of state is the data that describes the call that is being made across domains. This data is held in the CLR’s execution context and includes everything from the call stack, to the current Windows token, to synchronization information. For more information on the execution context, see the .NET Framework 2.0 SDK.
The fact that threads wander between application domains does not mean, however, that a given domain can have only one thread running in it at a given time. Just as with a Win32 process, several threads can be running in a single application domain simultaneously.
The second difference in the way threads are treated in the application domain model is that, unlike when you create a new process, creating a new application domain does not result in the creation of a new thread. When you create a new domain and transfer control into it by calling a method on a type in that domain, execution continues on the same thread on which the domain was created. To see how this works, let’s return to the implementation of BoatRaceDomainManager.EnterBoat that we discussed in the previous section. As shown in the following code, the thread on which we’re running switches into the new domain when we invoke the InitializeNewBoat method on the domain manager running in that domain.
public class BoatRaceDomainManager : AppDomainManager,
IBoatRaceDomainManager
{
// Other methods omitted...
public Int32 EnterBoat(string assemblyFileName,
string boatTypeName)
{
// Create a new domain in which to load the boat.
AppDomain ad = AppDomain.CreateDomain(boatTypeName,
null, null);
// Get the instance of BoatRaceDomainManager
// running in the new domain.
BoatRaceDomainManager adManager =
(BoatRaceDomainManager)ad.DomainManager;
// Pass [4] the assembly and type names to the new
// domain so the assembly can be loaded.
adManager.InitializeNewBoat(assemblyFileName,
boatTypeName);
return ad.Id;
}
}The high-level relationship between threads and application domains is shown in Figure 5-8.
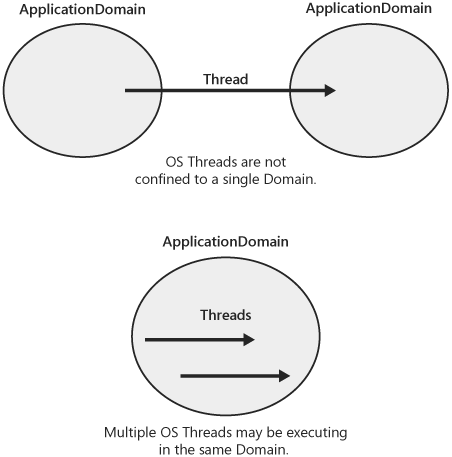
The .NET Framework provides some static members you can use to obtain the current relationship between threads and application domains running in a process. For example, System. AppDomain.CurrentDomain and System.Threading.Thread.GetDomain both return the application domain in which the thread from the calling domain is executing as shown in the following code snippet:
using System; using System.Threading; // Both return the domain in which the current thread is executing. AppDomain currentDomain1 = AppDomain.CurrentDomain(); AppDomain currentDomain2 = Thread.GetDomain();
If you need to obtain the object that represents the current thread running in a domain, use the System.Threading.Thread.CurrentThread method. The System.AppDomain class also has a method called GetCurrentThreadId that returns an identifier for the current thread running in the calling domain. The relationship of this value to the thread identifiers provided in Win32 is undefined and can vary between different versions of the CLR. As a result, it’s not safe to assume a direct mapping between these two concepts of thread identification.
If you’re writing a multithreaded managed application, it’s much easier to achieve high performance and scalability by using the CLR thread pool instead of creating, managing, and destroying threads yourself. There are a few reasons why this is the case. First, creating and destroying threads are expensive. By reusing the threads in the pool, you’re able to minimize drastically the number of times a new thread is created. Second, creating the ideal numbers of threads needed to accomplish a given workload requires a significant amount of tuning to get right. If too many threads are created, time is wasted in excessive context switches between threads. If too few threads are created, the amount of time spent waiting for an available thread can adversely affect performance. The CLR thread pool has been tuned over several years of experience building scalable managed applications. The number of threads in the CLR thread pool is optimized on a case-by-case basis based on the performance characteristics of the hardware on which you’re running and the workload in the process. The thread pool injects new threads into the process when it determines that doing so increases the overall throughput of the work items currently queued to the pool. Experience has shown that most applications can achieve better throughput by leveraging the existing thread pool mechanism instead of dealing with thread management themselves.
The CLR thread pool is represented by the System.Threading.ThreadPool class. The managed thread pool is similar in spirit and functionality to the thread pool provided by Win32. In fact, if you’re familiar with the Win32 thread pool APIs, you’ll feel comfortable with the members of the ThreadPool class in no time.
There is one managed thread pool per process. Because threads aren’t confined to a particular application domain, the thread pool doesn’t need to be either. This enables the CLR to optimize work across the entire process for greater overall performance. It’s very common for a given thread pool thread to service requests for multiple application domains. Whenever a thread is returned to the pool, its state is reset to avoid unintended leaks between domains. Dispatching requests to the thread pool is easy. System.Threading.ThreadPool includes a member called QueueUserWorkItem that takes a delegate. This delegate is queued to the thread pool and executed when a thread becomes available.
Multithread applications that use several application domains often follow a common pattern: first, a request comes in to execute some code. This request varies completely by scenario. For example, in SQL Server the request might result from building a plan to execute a query containing managed code. In the Internet Explorer case, the request might take the form of creating a new instance of a managed control on a Web page. Second, the application determines in which domain the request should be serviced. Depending on how your process is partitioned into multiple application domains, you can choose to execute your new request in an existing domain, or you can choose to create a new one. Next, an instance of the object representing the new request is created in the chosen domain. Finally, a delegate is queued to the thread that calls a method on the object to execute the request.
To illustrate this technique, let’s return again to our implementation of BoatRaceDomainManager.EnterBoat. This time, let’s use the CLR thread pool to initialize our new boat asynchronously:
using System;
using System.Threading;
namespace BoatRaceHostRuntime
{
// Some code omitted for clarity.
// This struct is used to pass request data to the delegate that
// will be executed by the thread pool.
struct ThreadData
{
public BoatRaceDomainManager domainManager;
public string assemblyFileName;
public string boatTypeName;
};
public class BoatRaceDomainManager : AppDomainManager,
IBoatRaceDomainManager
{
// This is the method that gets queued to the thread pool.
static void RunAsync(Object state)
{
ThreadData td = (ThreadData)state;
// Get the domain manager object out of the thread state
// object and call its InitializeNewBoat method.
td.domainManager.InitializeNewBoat(td.assemblyFileName,
td.boatTypeName);
}
public Int32 EnterBoat(string assemblyFileName, string boatTypeName)
{
// Create a new domain in which to load the boat.
AppDomain ad = AppDomain.CreateDomain(boatTypeName, null,
null);
BoatRaceDomainManager adManager =
(BoatRaceDomainManager)ad.DomainManager;
// Gather the domain manager and the name of the assembly
// and type into an object to pass to thread pool.
ThreadData threadData = new ThreadData();
threadData.domainManager = adManager;
threadData.assemblyFileName = assemblyFileName;
threadData.boatTypeName = boatTypeName;
// Queue a work item to the thread pool.
ThreadPool.QueueUserWorkItem(new WaitCallback(RunAsync),
threadData);
return ad.Id;
}
}
}In this version of the implementation, we begin by declaring a structure called ThreadData that we’ll use to pass the data to the new thread that we’ll need to make the call. This data includes the application domain manager for the new domain and the name of the assembly and type containing the implementation of the boat. Next, we need to define a delegate to act as our thread proc. The RunAsync delegate takes a ThreadData structure, pulls out the application domain manager, and calls its InitializeNewBoat method. Now, after we create the new domain for the boat, we get its domain manager as before, but this time instead of calling InitializeNewBoat directly, we save the data needed to make the call into an instance of the ThreadData structure and invoke RunAsync asynchronously by queuing a request to the thread pool using ThreadPool.QueueUserWorkItem.
Clearly, there is much more to the CLR thread pool than I’ve described here. For a more complete description, see the .NET Framework SDK reference material for System.Threading.ThreadPool.
As described, unloading code from a process requires you to unload the application domain in which the code is running. The CLR currently doesn’t support unloading individual assemblies or types. There are several scenarios in which an application might want to unload a domain. One of the most common reasons for wanting to unload an application domain is to reduce the working set of a process. This is especially important if your application has high scalability requirements or operates in a constrained memory environment. Another common reason to unload an application domain is to enable code running in your process to be updated on the fly. The ASP.NET host is a great example of using application domains to achieve this effect. As you might know, ASP.NET enables you to update a Web application dynamically by simply copying a new version of one or more of the application’s DLLs into the bin directory. When ASP.NET detects a new file, it begins routing requests for that application to a new domain. When it determines that all requests in the old application domain have completed, it unloads the domain. In this way, applications can be updated without restarting the Web server. In many cases, this update is completely transparent to the end user. I show you how to implement this feature in your own applications when I talk about the family of shadow copy properties in Chapter 6.
Application domains can be unloaded by calling a static method on System.AppDomain called Unload. AppDomain.Unload takes one parameter—an instance of System.AppDomain representing the domain you want to unload. Application domains can also be unloaded from unmanaged code using the CLR hosting interfaces. ICLRRuntimeHost includes a method called UnloadAppDomain that takes the unique numerical identifier of the application domain you want to unload.
Calls to AppDomain.Unload or ICLRRuntimeHost::UnloadAppDomain cause the CLR to unload the application domain gracefully. By gracefully, I mean that the CLR unloads the domain in an orderly fashion that lets the application code currently running in the domain reach a natural, predictable endpoint. Specifically, the following sequence of events occurs during a graceful shutdown of an application domain:
The threads running in the domain are aborted.
An event is raised to indicate the domain is being unloaded.
Finalizers are run for objects in the application domain.
The CLR cleans up its internal data structures associated with the domain.
These steps are described in the following sections.
The CLR begins the process of unloading an application domain by stopping all code that is currently executing in the domain. Threads running in the domain are given the opportunity to complete gracefully rather than being abruptly terminated. This is accomplished by sending a ThreadAbortException to all threads in the domains. Although a ThreadAbortException signals to the application that the thread is going away, it does not provide a mechanism for the application to catch the exception and stop the thread from aborting. A ThreadAbortException is persistent in that although it can be caught, it always gets rethrown by the CLR if an application catches it.
Code that is running on a thread destined to be aborted has two opportunities to clean up. First, the CLR runs code in all finally blocks as part of thread termination. Also, the finalizers for all objects are run (see the "Step 3: Running Finalizers" section).
Be aware that a ThreadAbortException can be thrown on threads that are currently not even executing in the partially unloaded application domain. If a thread executed in that domain at one point and must return to that domain as the call stack is being unwound, that thread receives a ThreadAbortException. For example, consider the case in which a thread is executing some code in Domain 1. At some later point in time, the thread leaves Domain 1 and begins executing in Domain 2. If AppDomain.Unload is called on Domain 1 at this point, the thread’s stack would look something like the stack shown in Figure 5-9.
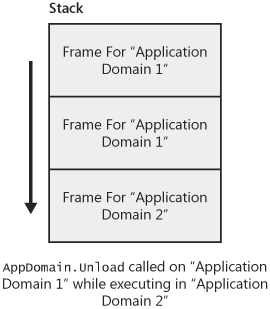
Clearly, aborting this thread is necessary because the stack contains addresses of calls that will be invalid after the domain is completely unloaded.
After the ThreadAbortExceptions have been thrown and the finally blocks have been run, the CLR raises an event to indicate the domain is unloading. This event can be received in either managed code or unmanaged code. I talk more about how to catch this event later in the chapter.
Earlier in the unloading process, the CLR ran all finally clauses as one way to enable the threads running in the domain to clean up before being aborted. In addition to running finallys, the CLR finalizes all objects that live in the domain. This gives the objects a final opportunity to free all resources allocated while the domain was active.
Typically, finalizers are run as a part of a garbage collection. When an object is being collected, all unused objects that reference it are likely being finalized and collected as well. However, the order in which objects are finalized is less well defined when the application domain in which an object lives is being unloaded. As a result, it might be necessary for an object’s finalizer to behave differently depending on whether the object is being finalized because the domain is unloaded or as part of a collection. A finalizer can tell the difference between these two cases by calling the IsFinalizingForUnload method on System.AppDomain. As its name implies, IsFinalizingForUnload returns true if the finalizer from which it is called is being run during application domain unload.
Clearly, running finalizers and finallys during unload enables code contained in add-ins to be run. By default, the CLR makes no guarantees that this code will actually ever terminate. For example, a finalizer could get stuck in an infinite loop, causing the object to stay alive forever. Without customization, the CLR does not impose any timeouts on thread abort or application domain unload. As a result, an attempt to unload an application domain might never actually finish. Fortunately, the CLR hosting interfaces provide an extensible set of customizations related to the way errors are handled and the way attempts to abort threads and unload domains are handled. For example, a host can use these interfaces to specify timeouts for various actions and to cause the CLR to terminate a thread more forcefully when the timeout expires. A host specifies its policy around error handling and unloading using the ICLRPolicyManager interface. I cover the details of how to specify policy using this interface in Chapter 11.
As you’ve seen, the CLR does its best to enable cleanup code to be run as part of unloading an application domain. Although this helps provide for a clean shutdown, the application’s logic is terminated the instant the ThreadAbortException is thrown. As a result, the work the application was doing might be halted prematurely. In the best case, this simply results in a program that safely stops running early. However, it’s easy to imagine scenarios in which the premature termination of the application leaves the system in an inconsistent state. As the author of an application that initiates application domain unloads, it’s in your best interest to unload a domain only when no active threads are running in the domain. This helps you minimize the times when unloading a domain adversely affects the application. The CLR provides no APIs or other mechanisms to help you determine when a domain is empty. You must build additional logic into your application to determine when requests you’ve dispatched to different threads have been completed. When they all complete successfully, you know the domain is safe to unload.
After all finalizers have run and no more threads are executing in the domain, the CLR is ready to unload all the in-memory data structures used in the internal implementation. Before this happens, however, the objects that resided in the domain must be collected. After the next garbage collection occurs, the application domain data structures are unloaded from the process address space and the domain is considered unloaded.
You should be aware of a few exceptions that might get thrown as a result of unloading an application domain. First, once a domain is unloaded, access to objects that used to live in that domain is illegal. When an attempt to access such an object occurs, the CLR will throw an ApplicationDomainUnloadedException. Second, there are a few cases in which unloading an application domain is invalid. For example, AppDomain.Unload cannot be called on the default domain (remember, it must live as long as the process) or on an application domain that has already been unloaded. In these cases, the CLR throws a CannotUnloadAppDomainException.
The CLR raises an event to notify the hosting application that an application domain is being unloaded. This event can be received in either managed or unmanaged code. In managed code, domain unload notifications are raised through the System.AppDomain.DomainUnload event. In unmanaged code, the CLR sends application domain unload notifications to hosts through the IActionOnCLREvent interface. I show you how to use IActionOnCLREvent to catch these notifications in the next section.
The AppDomain.DomainUnload event takes the standard event delegate that includes arguments for the object that originated the event (the sender) and any additional data that is specific to that event (the EventArgs). The instance of System.AppDomain representing the application domain that is being unloaded is passed as the sender parameter. The EventArgs are null. The following code snippet shows a simple event handler that prints the name of the application domain that is being unloaded:
public static void DomainUnloadHandler(Object sender, EventArgs e)
{
AppDomain ad = (AppDomain)sender;
Console.WriteLine("Domain Unloaded Event fired: " + ad.FriendlyName);
}This event is hooked up to the domain using the standard event syntax:
AppDomain ad1 = AppDomain.CreateDomain("Application Domain 1");
ad1.DomainUnload += new EventHandler(DomainUnloadHandler);Because information about the unloaded domain is passed as a parameter, it’s convenient to register the same delegate for all application domains you create. When the event is raised you simply use the sender parameter to tell which domain has been unloaded.
Listening to domain unload events in managed code is much easier to program and therefore is the approach you’re likely to use most. However, you can also receive these events in unmanaged code by providing an object that implements the IActionOnCLREvent interface. IActionOnCLREvent contains one method (OnEvent) that the CLR calls to send an event to a CLR host. Here’s the definition of IActionOnCLREvent from mscoree.idl:
interface IActionOnCLREvent: IUnknown
{
HRESULT OnEvent(
[in] EClrEvent event,
[in] PVOID data
);
}The CLR passes two parameters to OnEvent. The first parameter, event, is a value from the EClrEvent enumeration that identifies the event being fired. The second parameter is the data associated with the event. For application domain unloads, the data parameter is the unique numerical identifier representing the unloaded domain.
You register your intent to receive events by passing your implementation of IActionOnCLREvent to the CLR through the ICLROnEventManager interface. As with all CLR-implemented hosting managers, you obtain this interface from ICLRControl as shown in the following code snippet:
// Get an ICLRRuntimeHost by calling CorBindToRuntimeEx.
ICLRRuntimeHost *pCLR = NULL;
hr = CorBindToRuntimeEx(......,(PVOID*) &pCLR);
// Get the CLR Control object.
ICLRControl *pCLRControl = NULL;
pCLR->GetCLRControl(&pCLRControl);
// Ask for the Event Manager.
ICLROnEventManager *pEventManager = NULL;
pCLRControl->GetCLRManager(IID_ICLROnEventManager,
(void **)&pEventManager);ICLROnEventManager contains two methods. RegisterActionOnEvent enables you to register your object that implements IActionOnCLREvent with the CLR. When you are no longer interested in receiving events, you can unregister your event handler using UnregisterActionOnEvent. Here’s the interface definition for ICLROnEventManager from mscoree.idl:
interface ICLROnEventManager: IUnknown
{
HRESULT RegisterActionOnEvent(
[in] EClrEvent event,
[in] IActionOnCLREvent *pAction
);
HRESULT UnregisterActionOnEvent(
[in] EClrEvent event,
[in] IActionOnCLREvent *pAction
);
}Notice that both methods take a parameter of type EClrEvent. This enables you to register to receive only those events you are interested in.
To demonstrate how to receive application domain events using IActionOnCLREvent, I’ve modified our boat race host sample to unload an application domain that was created for one of the add-ins. Example 5-2 shows the updated sample.
Example 5-2. BoatRaceHost.cpp
#include "stdafx.h"
#include "CHostControl.h"
// This class implements IActionOnCLREvent. An instance of this class
// is passed as a "callback" to the CLR's ICLROnEventManager to receive
// a notification when an application domain is unloaded.
class CActionOnCLREvent : public IActionOnCLREvent
{
public:
// IActionOnCLREvent
HRESULT __stdcall OnEvent(EClrEvent event, PVOID data);
// IUnknown
virtual HRESULT __stdcall QueryInterface(const IID &iid, void **ppv);
virtual ULONG __stdcall AddRef();
virtual ULONG __stdcall Release();
// constructor and destructor
CActionOnCLREvent()
{
m_cRef=0;
}
virtual ~CActionOnCLREvent()
{
}
private:
long m_cRef; // member variable for ref counting
};
// IActionOnCLREvent methods
HRESULT __stdcall CActionOnCLREvent::OnEvent(EClrEvent event, PVOID data)
{
wprintf(L"AppDomain %d Unloaded
", (int) data);
return S_OK;
}
// IUnknown methods
HRESULT __stdcall CActionOnCLREvent::QueryInterface(const IID &iid,void **ppv)
{
if (!ppv) return E_POINTER;
*ppv=this;
AddRef();
return S_OK;
}
ULONG __stdcall CActionOnCLREvent::AddRef()
{
return InterlockedIncrement(&m_cRef);
}
ULONG __stdcall CActionOnCLREvent::Release()
{
if(InterlockedDecrement(&m_cRef) == 0){
delete this;
return 0;
}
return m_cRef;
}
int main(int argc, wchar_t* argv[])
{
// Start the CLR. Make sure .NET Framework version 2.0 is used.
ICLRRuntimeHost *pCLR = NULL;
HRESULT hr = CorBindToRuntimeEx(
L"v2.0.41013,
L"wks",
STARTUP_CONCURRENT_GC,
CLSID_CLRRuntimeHost,
IID_ICLRRuntimeHost,
(PVOID*) &pCLR);
assert(SUCCEEDED(hr));
// Create an instance of our host control object and register
// it with the CLR.
CHostControl *pHostControl = new CHostControl();
pCLR->SetHostControl((IHostControl *)pHostControl);
// Get the CLRControl object. This object enables us to get the
// CLR's OnEventManager interface and hook up an instance of
// CActionOnCLREvent.
ICLRControl *pCLRControl = NULL;
hr = pCLR->GetCLRControl(&pCLRControl);
assert(SUCCEEDED(hr));
ICLROnEventManager *pEventManager = NULL;
hr = pCLRControl->GetCLRManager(IID_ICLROnEventManager,
(void **)&pEventManager);
assert(SUCCEEDED(hr));
// Create a new object that implements IActionOnCLREvent and
// register it with the CLR. We're only registering to receive
// notifications on app domain unload.
CActionOnCLREvent *pEventHandler = new CActionOnCLREvent();
hr = pEventManager->RegisterActionOnEvent(Event_DomainUnload,
(IActionOnCLREvent *)pEventHandler);
assert(SUCCEEDED(hr));
hr = pCLR->Start();
assert(SUCCEEDED(hr));
// Get a pointer to our AppDomainManager running in the default domain.
IBoatRaceDomainManager *pDomainManagerForDefaultDomain =
pHostControl->GetDomainManagerForDefaultDomain();
assert(pDomainManagerForDefaultDomain);
// Enter a new boat in the race. This creates a new application domain
// whose id is returned.
int domainID = pDomainManagerForDefaultDomain->EnterBoat(L"Boats",
L"J29.ParthianShot");
// Unload the domain the boat was just created in. This will
// cause the CLR to call the OnEvent method in our implementation of
// IActionOnCLREvent.
pCLR->UnloadAppDomain(domainID);
// Clean up.
pDomainManagerForDefaultDomain->Release();
pHostControl->Release();
return 0;
}In this sample, the implementation of IActionOnCLREvent is provided by the CActionOnCLREvent class. Notice the implementation of the OnEvent method is very simple—it just prints out the identifier of the application domain that is being unloaded. In the main program an instance of CActionOnCLREvent is created and registered with the CLR by calling the RegisterActionOnEvent method on the ICLROnEventManager pointer obtained from ICLRControl. To trigger the event handler to be called, an application domain is unloaded using ICLRRuntimeHost::UnloadAppDomain.
Application domains are often described as subprocesses because they provide an isolation boundary around a grouping of assemblies in a process. If the code running in the application domain is verifiably type safe, the isolation provided by the domain is roughly equivalent to that provided by a process in Win32. Application domains also provide the ability to unload code from a running process dynamically. As the author of an extensible application, one of the key decisions you’ll make is how to partition your process into multiple application domains. The key is to use application domains to achieve the isolation you want while minimizing the amount of communication between domains because of the cost associated with remote calls.
When writing an extensible application, you’ll likely want to take advantage of a new concept in .NET Framework version 2.0 called an application domain manager. Providing an application domain manager is an easy way to implement the host runtime design pattern because the CLR automatically creates an instance of your domain manager in every application domain. Also, if you’re writing a CLR host, an application domain manager is the mechanism you use to call into managed code from the unmanaged portion of your host.
[1] Technically, SkipVerification isn’t permission itself in the true sense. It’s a state of another permission called SecurityPermission. See the Microsoft .NET Framework SDK for details.
[2] This is true in general; however, an optimization known as domain-neutral loading changes this loading behavior. Domain-neutral loading does not change any semantic behavior with respect to isolation though. I talk about domain-neutral code much more in Chapter 9.
[3] The CLR’s COM Interoperability layer can generate an interface automatically for you based on the class definition, but it’s generally considered a better practice to define the interface explicitly. Automatically generated interfaces can result in versioning problems later when you add methods to a class.
[4] When InitializeNewBoat is called, the thread transfers into the new domain. It then returns to the default domain when the call completes.