
Throughout this book, I’ve discussed a number of techniques you can use to customize the CLR for use in a variety of application scenarios. In this chapter, I cover the support the CLR provides for application scenarios that require a high degree of availability—that is, scenarios in which the process must live for a very long time. These scenarios include servers such as database or e-mail servers and operating system processes.
As the CLR continues to be used in more environments with requirements for long process lifetimes, it must provide a set of features that a host can use to ensure that the process stays alive in the face of exceptional conditions such as out of memory or stack overflow errors. As I demonstrate, the CLR leverages the concept of application domain isolation and ensures that a domain can always be unloaded without leaking resources, even in conditions of resource failure. By ensuring that domains can always be safely unloaded, the CLR provides a construct that hosts can use to remove code from the process that has encountered an error that prevents it from continuing to run normally. In this way, the host can isolate faulty code without affecting the integrity of the process itself.
The ability to guarantee that an application domain can be unloaded without leaking resources requires the CLR to expose some new infrastructure to the authors of class libraries. This new infrastructure includes concepts such as safe handles, critical finalizers, and constrained execution regions. As the author of an extensible application, you can choose to use these new concepts to make your host runtime code more reliable in the face of resource exhaustion and other exceptional conditions. In addition, an understanding of these new concepts can help you decide how to deal with add-ins that might not have been explicitly written with this new infrastructure in mind.
In addition to the infrastructure required to unload an application domain cleanly, the CLR provides the ability for a CLR host to customize how various exceptional conditions affect the process. For example, by default, a failure to allocate memory will cause the CLR to throw a System.OutOfMemoryException. If this exception occurs while executing an add-in, the host might not be confident that the add-in was written to handle the exception correctly. As a result, the host can choose to escalate this exception and cause the entire thread on which the exception occurred to be aborted instead. Furthermore, if the exception occurs while the add-in is known to be editing state that is shared across multiple threads, it’s likely that the integrity of that state cannot be guaranteed. So a host might decide it’s safer to unload the entire application domain to guarantee the integrity of the process. The act of dictating how exceptions are handled in this way is referred to as customizing escalation policy.
This chapter covers all of the concepts the CLR introduces in Microsoft .NET Framework 2.0 aimed at enabling you to incorporate the CLR safely into application models with high availability requirements. I start by describing in more detail the motivation behind a reliability model based on unloading application domains. Next, I describe the CLR hosting interfaces you can use to customize escalation policy. Finally, I look at a variety of topics you can use in your own code to ensure that your application runs properly in the face of exceptional conditions such as resource failures.
At first glance, it might seem unnecessary to build a complex infrastructure just to make sure that a process doesn’t crash in the face of exceptional conditions. After all, it would seem easier to simply write your managed code such that it handled all exceptions properly. In fact, this is the path the CLR team started down when it first began the work to make sure that managed code could work well in environments requiring long process lifetimes. However, it was quickly determined that writing large bodies of code to be reliable in the face of all exceptions is impractical. As it turns out, the CLR’s model for executing managed code could, in theory, cause exceptions to be thrown on virtually any line of code that is executed. This situation is primarily caused by the fact that memory can be allocated, and other runtime operations can occur, in places where you wouldn’t expect. For example, memory must be allocated any time Microsoft intermediate language (MSIL) code needs to be jit-compiled or a value type needs to be boxed. The following code snippet simply inserts an integer into a hash table:
hashtable.Add("Entry1", 5);However, because the signature of HashTable.Add specifies that the second parameter is of type Object, the CLR must create a reference type by boxing the value "5" before adding it to the hash table. The act of creating a new reference type requires memory to be allocated from the garbage collector’s heap. If memory is not available, the addition of the value 5 into the hash table would throw an OutOfMemoryException. Also, consider the following example that saves the value of an operating system handle after using PInvoke to call Win32’s CreateSemaphore API:
IntPtr semHandle = CreateSemaphore(...);
In this case, if the call to CreateSemaphore were to succeed but an exception were to be thrown before the value of the handle could be stored in the local variable, that handle would be leaked. Resource leaks such as these can add up over time to undermine the stability of the process. Furthermore, conditions such as low memory can prevent the CLR from being able to run all cleanup code that you might have defined in finally blocks, finalizers, and so on. The failure to run such code can also result in resource leaks over time.
It’s also worth noting that even if it were practical for all of the Microsoft .NET Framework assemblies and the assemblies you write as part of your extensible application to handle all exceptional conditions, you’d never be able to guarantee that the add-ins you host are written with these conditions in mind. So the need for a mechanism by which the host can protect the process from corruption is required.
The first two releases of the CLR (in .NET Framework 1.0 and .NET Framework 1.1) didn’t have the explicit requirement to provide a platform on which you could guarantee long process lifetimes mainly because there weren’t any CLR hosts at the time that needed this form of reliability model. The primary CLR host at the time was Microsoft ASP.NET. High availability is definitely a requirement in Web server environments, but the means to achieve that reliability have been quite different. Historically, at least on the Microsoft platform, Web servers have used multiple processes to load balance large numbers of incoming requests. If the demand were high, more processes would be created to service the requests. In times of low demand, some processes either sat idle or were explicitly killed. This method of achieving scalability works well with Web applications because each request, or connection, is stateless; that is, has no affinity to a particular process. So subsequent requests in the same user session can be safely redirected to a different process. Furthermore, if a given process were to hang or fail because of some exceptional condition, the process could be safely killed without corrupting application state. To the end user, a failure of this sort generally shows up as a "try again later" error message. Upon seeing an error like this, a user typically refreshes the browser, in which case the request gets sent to a different process and succeeds.
Although achieving scalability and reliability through process recycling works well in Web server scenarios, it doesn’t work in some scenarios, such as those involving database servers where there is a large amount of per-process state that makes the cost of starting a new process each time a failure occurs prohibitive. Just as the ASP.NET host drove the process recycling model used in the first two releases of the CLR, Microsoft SQL Server 2005 has driven the .NET Framework 2.0 design in which long-lived processes are a requirement.
As described, the CLR’s strategy for protecting the integrity of a process is to always contain failures to an application domain and to allow that domain to be unloaded from the process without leaking resources. Let’s get into more detail now by looking at the specific techniques the CLR uses to make sure that failures can always be isolated to an application domain.
Given that failures caused by resource exhaustion or other exceptional conditions can occur at virtually any time, hosts requiring long process lifetimes must have a strategy for dealing with such failures in such a way as to protect the integrity of the process. In general, it’s best to assume that the add-ins running in your host haven’t been written to handle all exceptions properly. A conservative approach to dealing with failures is more likely to result in a stable process over time. The host expresses its approach to handling failures through the escalation policy I described in the chapter introduction. In this section, I describe escalation policy as it fits into the CLR’s overall reliability model. Later in the chapter, I discuss the specific CLR hosting interfaces used to express your escalation policy.
In .NET Framework 2.0, all unhandled exceptions are allowed to "bubble up" all the way to the surface, thereby affecting the entire process. Specifically, an exception that goes unhandled will terminate the process. Clearly, this end result isn’t acceptable when process recycling is too expensive.
Note

Allowing all unhandled exceptions to affect the process in this way is new to .NET Framework 2.0. In the first two versions of the CLR, various unhandled exceptions were "swallowed" by the CLR. These exceptions didn’t necessarily bring down the process, but rather often resulted in silent failures or corruption of the process. In .NET Framework version 2.0, the CLR team decided it would be much better to allow these exceptions to surface, thereby making the failures more apparent and easier to debug.
CLR hosts can use escalation policy to specify how these types of failures should be handled and what action the CLR should take when certain operations take longer to terminate than desired. For example, a thread might not ever abort if the finalizer for an object running on that thread enters an infinite loop, thereby causing the thread to hang. The specific failures that can be customized through escalation policy are as follows:
Failure to allocate a resource. A resource, in this case, typically refers to memory or some other resource managed by the operating system, but stack overflows or other exceptional conditions are also considered resource failures.
Failure to allocate a resource in a critical region of code. A critical region is defined as any block of code that might be dependent on state shared between multiple threads. The reason that a failure to allocate a resource while in a critical region is called out explicitly is as follows. Code that relies on state from another thread cannot be safely cleaned up by terminating only the specific thread on which it is running. In other words, if only one of the threads that is cooperating to edit shared state is terminated, the integrity of that state cannot be guaranteed. Later I show that a host can elect to take more conservative steps to guarantee the integrity of the process when shared state is being edited. For example, the SQL Server host uses escalation policy to abort the thread on which a failure to allocate a resource occurs. However, if that thread is in a critical region when the failure occurs, SQL Server decides that it is safer to abort the entire application domain just in case any cross-thread state has become corrupted. It’s also worth noting that the CLR hosting interfaces provide a mechanism by which the add-ins running in a process are prevented from sharing state across threads altogether. This mechanism, known as host protection, is the subject of Chapter 12. One important question regarding shared state remains: how does the CLR determine whether code is in a critical region? That is, how does the CLR know that a given piece of code is relying on state from another thread? The answer lies in the CLR’s ability to detect that code it is executing is waiting on a synchronization primitive such as a mutex, event, semaphore, or any other type of lock. If code that encounters a resource failure is in a region of code that depends on a synchronization primitive, the CLR assumes that the code depends on synchronized access to shared state.
Note
The CLR’s ability to detect when code is waiting on a synchronization primitive requires some additional help from the host. The System.Threading namespace in the .NET Framework includes several classes for creating primitives such as mutexes and events. The CLR can keep track of these locks because they are created directly in managed code. However, add-ins that have been granted full trust in the Code Access Security (CAS) system (or more specifically, those that have been granted the ability to call native code) can use PInvoke to create synchronization primitives by calling Win32 APIs. Locks acquired in this way are outside the realm of managed code and are therefore unknown to the CLR. As a result, any code waiting on such a lock won’t be reported as belonging to a critical region of code should a resource failure occur. So, to make sure the CLR can identify all locks held by managed code, don’t grant add-ins the ability to access native code. More details on how to use the CAS system to prevent access to native code can be found in Chapter 10.
Fatal runtime error. Despite all the infrastructure aimed at increasing the reliability of the process, it’s still conceivable that the CLR can enter a state in which it encounters a fatal internal error that prevents it from continuing to run managed code. Were this to happen, the host could use escalation policy to determine which actions to take. For example, the host might decide to exit the process at this point, or it might determine that sufficient work can be done that doesn’t require managed code. In this case, the host can choose to tell the CLR to disable itself. I describe more about how to disable the CLR later in the chapter when I discuss the specific escalation policy interfaces.
Orphaned lock. I’ve described how a failure to allocate a resource in code that is waiting on a synchronization primitive is likely to leave the application domain in an inconsistent state. Another scenario in which this can occur is when a synchronization primitive is created but never freed because the code that initially created the lock is terminated. For example, consider the case in which a synchronization primitive such as a Mutex or a Monitor is created on a thread that is aborted before the lock is freed. The lock is considered orphaned and can never be freed. Too many orphaned locks can eventually result in resource exhaustion. So the CLR considers an abandoned lock a failure and allows the host to specify the action to take as a result.
Given these failures, a host can choose to take any of a number of actions. The specific actions that can be taken are the following:
Throw an exception. Throwing an exception is the default action the CLR takes when a resource failure occurs. For example, a stack overflow causes a StackOverflowException to be thrown, failure to allocate memory causes an OutOfMemoryException to be thrown, and so on.
Gracefully abort the thread on which the failure occurred. The CLR provides two flavors of thread aborts: a graceful abort and a rude abort. The CLR initiates a graceful abort by throwing a ThreadAbortException on the thread it is terminating. When aborting a thread gracefully, the CLR gives the add-in a chance to free all resources by running all code contained in finally blocks.
Rudely abort the thread on which the failure occurred. In contrast to graceful aborts, the CLR makes no guarantees about which, if any, of an add-in’s cleanup code it will run. It’s best to assume that no code in finally blocks will be run during a rude abort. Rude thread aborts are typically used to remove threads from the process that haven’t gracefully aborted in a host-specified amount of time.
Gracefully unload the application domain in which the failure occurred. There are graceful and rude techniques used to unload an application domain just as there are to abort a thread. A graceful application domain unload involves gracefully aborting all threads in the domain, then freeing the CLR data structures associated with the domain itself. In addition, when gracefully unloading an application domain, the CLR will run all finalizers for objects that lived in the domain. Chapter 5 provides more details on the specific steps taken by the CLR to gracefully unload an application domain.
Rudely unload the application domain in which the failure occurred. A rude application domain unload involves rudely aborting all threads in the domain before freeing the data structures associated with the application domain. Just as rude thread aborts are often used to terminate threads that take too long to gracefully abort, rude application domain unloads are typically used to forcefully remove an application domain from a process that has timed out during the course of a normal shutdown. When rudely unloading an application domain, the CLR does not guarantee that any object finalizers will be run (with the exception of critical finalizers that I discuss later in the chapter).
Gracefully exit the process. In extreme circumstances, such as when a critical failure occurs internal to the CLR, the host might choose to exit the process entirely. Through escalation policy, the host can choose to exit the process either gracefully or rudely. When exiting the process gracefully, the CLR attempts to gracefully unload all application domains. That is, an attempt is made to run all code in finallys and finalizers to give the host and the add-ins a chance to finish any processing necessary for a clean process shutdown, such as flushing any buffers, properly closing files, and so on.
Rudely exit the process. A rude process exit makes no attempt at an orderly shutdown—all application domains are rudely unloaded and the process terminates. In a way, a rude process exit is the equivalent of calling the TerminateProcess API in Win32.
Disable the CLR. Instead of exiting the process entirely, a host can choose to disable the CLR. Disabling the CLR prevents it from running any more managed code, but it does keep the process alive, thereby enabling the host to continue doing any work that doesn’t require managed code. For example, if a critical error were to occur in the CLR while running in the SQL Server process, the SQL host could choose to disable the CLR, but continue running all stored procedures, user-defined types, and so on that were written in T-SQL (native code), which doesn’t require any of the facilities of the CLR to run properly.
In addition to specifying which actions to take in the face of certain failures, escalation policy also enables a host to specify timeouts for certain operations and to indicate which actions should occur when those timeouts are reached. This capability is especially useful to terminate code that appears to be hung, such as code in an infinite loop or code waiting on a sychronization primitive that has been abandoned. A host can use escalation policy to specify a timeout for thread abort (including an abort in a critical region of code), application domain unload, process exit, and the amount of time that finalizers are allowed to run.
Finally, escalation policy can be used to force any of the operations for which timeouts can be specified to take a certain action unconditionally. For example, a host can specify that a thread abort in a critical region of code should always be escalated to an application domain unload.
Now that I’ve covered the basic concepts involved in escalation policy, let’s look at a specific example to see how a host might use those concepts to specify a policy aimed at keeping the process alive in the face of resource failures or other exceptional conditions. Figure 11-1 is a graphical representation of an escalation policy similar to the one used in the SQL Server 2005 host.
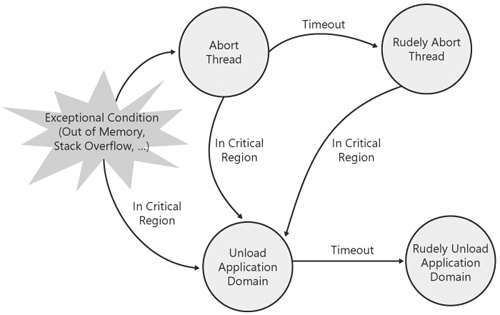
Figure 11-1. Escalation policy is the host’s expression of how failures in a process should be handled.
The key aspects of this policy are as follows:
All exceptional conditions are automatically escalated to thread aborts, unless the failure occurs in a critical region of code, in which case the failure is escalated to an application domain unload.
If a thread doesn’t gracefully abort in a specified amount of time, the thread is rudely aborted. Also, if a thread abort is initiated in a critical region of code, the thread abort is escalated to an application domain unload.
If an application domain doesn’t gracefully unload in a specified amount of time, the application domain is rudely unloaded.
One of the key pieces of infrastructure needed to ensure that application domains can be unloaded without leaking resources is the capability to guarantee that any native handles held by managed code will be closed properly. Several classes in the .NET Framework (not to mention those written by third parties, including those you might have written yourself) logically act as a wrapper around a native resource. For example, the file-related classes in the System.IO namespace hold native file handles, and the classes in System.Net maintain native handles that represent open network sockets. Traditionally, these native handles have been closed using a combination of the Dispose design pattern and object finalizers. However, as I’ve described, the CLR does not guarantee that finalizers will be run when rudely unloading an application domain. If a class that holds a native resource requires a finalizer to run to free the handle, that handle will be leaked when an application domain is rudely unloaded. For this reason, the CLR has introduced some new infrastructure in .NET Framework 2.0 that can be used to guarantee that native handles such as these will always be released, regardless of how the application domain is terminated.
The concepts of critical finalization, safe handles, and constrained execution regions work together to ensure that native handles can always be released. Simply put, a critical finalizer is a finalizer that the CLR will always run. Furthermore, a critical finalizer is always guaranteed to complete. Any type that derives from System.Runtime.ConstrainedExecution.CriticalFinalizer-Object receives the benefits of critical finalization. One such type is System.Runtime.Interop-Services.SafeHandle (and its derivatives). A SafeHandle is a wrapper around a native handle that relies on critical finalization to ensure that the native handle will always be freed. All of the classes in the .NET Framework that hold native handles have been rewritten in version 2.0 to use SafeHandles to wrap those handles. The handles held by those classes will always be freed.
What is it about a critical finalizer that enables the CLR to make the guarantee that it will always be run and that it will always complete? The answer lies in the concept known as a constrained execution region (CER). A CER is a block of code in which the CLR guarantees that exceptions such as OutOfMemoryException or StackOverflowException are never thrown because of a lack of resources. Given this guarantee, you can be sure that the code in the CER will always complete (assuming it handles normal application exceptions, that is).
To guarantee that resource failures will never occur in a CER, the CLR must do two things:
Prepare the CER.
Restrict which operations can be performed inside a CER.
When preparing a CER, the CLR moves the allocation of all resources, such as memory, to a point just before the type containing the CER is created. For example, all code in a CER is jit-compiled before the CER is entered, thereby ensuring that enough memory exists to create the native code needed to execute the methods in the CER. If the creation of a type in a CER succeeds, you can guarantee it will run without failing because of a lack of resources. Note that preparing a type isn’t just a matter of looking at the resource needs of the type; it also requires preparing all types referenced in the CER (recursively) as well. Also, preparing a CER ensures it will run only if the code in the CER doesn’t allocate additional memory by creating new reference types, boxing value types, and so on. So code in a CER is restricted from performing any operations that can allocate memory. In .NET Framework 2.0, there is no mechanism in the CLR to enforce that code in a CER follows these restrictions. However, there likely will be in future releases. For now, the primary way to make sure that code in a CER doesn’t allocate additional resources is by code review.
Given this understanding of CERs, step back and see how this all relates to safe handles. Safe handles guarantee the release of the native handles they wrap because all code in an instance of SafeHandle runs in a CER. If there are enough resources available to create an instance of SafeHandle, there will be enough resources available to run it. In short, the CLR moves the allocation of all resources required for a critical finalizer up to the point where the object containing the finalizer is created, rather than waiting to allocate the resources at the point the finalizer must run.
Given that critical finalizers are guaranteed always to run, why not just make all finalizers critical? Or even better, why invent a new separate notion of a "critical" finalizer at all, and simply guarantee that all finalizers will complete successfully? Although this might seem tempting on the surface, there are two primary reasons why this wouldn’t be practical. The first is performance: preparing a type (and its dependencies) takes time. Furthermore, the CLR might jitcompile code that is never even executed. The second reason that critical finalization can’t become the default behavior is because of the restrictions placed on code running in a CER. The inability to cause memory to be allocated dramatically limits what can be done in a CER. Imagine writing a program that never used new, for example.
One final aspect of critical finalization worth noting is that critical finalizers are always run after normal finalizers. To understand the motivation for this ordering, consider the scenario of the FileStream class in System.IO. Before .NET Framework 2.0, FileStream’s finalizer had two key tasks: it flushed an internal buffer containing data destined for the file and closed the file handle. In .NET Framework 2.0, FileStream encapsulates the file handle using a SafeHandle, thus uses critical finalization to ensure the handle is always closed. In addition, FileStream maintains its existing finalizer that flushes the internal buffer. For FileStream to finalize properly, the CLR must run the normal finalizer first to flush the buffer before running the critical finalizer, which closes the file handle. The ordering of finalizers in this way is done specifically for this purpose.
CLR hosts specify an escalation policy using the failure policy manager from the CLR hosting interfaces. The failure policy manager has two interfaces: ICLRPolicyManager and IHostPolicyManager. As their names imply, ICLRPolicyManager is implemented by the CLR and IHostPolicyManager is implemented by the host.
Hosts obtain a pointer of type ICLRPolicyManager by calling the GetCLRManager method on ICLRControl. The pointer to an ICLRPolicyManager can then be used to call methods that specify timeouts for various operations, the actions to take when failures occur, and so on. The IHostPolicyManager interface is used by the CLR to notify the host of actions taken as a result of escalation policy. The CLR obtains a pointer to the host’s implementation of IHostPolicyManager using IHostControl::GetHostManager. The actions taken on failures are then reported to the host by calling methods on IHostPolicyManager.
The next few sections describe how to specify escalation policy using ICLRPolicyManager and how to receive notifications by providing an implementation of IHostPolicyManager.
Escalation policy consists of three primary concepts: failures, actions, and operations. These concepts were described in general terms earlier in the chapter when I described how escalation policy fits into the CLR’s overall infrastructure to support hosts with requirements for long process lifetimes. Failures refer to exceptional conditions such as the failure to allocate a resource. Actions describe the behavior that the CLR should take when a failure occurs. For example, a host can specify an action of thread abort given a failure to allocate a resource. Operations serve two purposes in the failure policy manager. First, they specify the operations for which timeouts can be specified, such as thread aborts, application domain unloads, and process exit. Second, a host can use operations to escalate the actions taken on failures. For example, a host can specify that a failure to allocate a resource in a critical region of code should always be escalated to an application domain unload.
In terms of the hosting interfaces, these concepts are represented by three enumerations: EClrFailure, EPolicyAction, and EClrOperation. Values from these enumerations are passed to the methods of ICLRPolicyManager to define escalation policy. The methods on ICLRPolicyManager are described in Table 11-1.
Table 11-1. The Methods on ICLRPolicyManager
Method | Description |
|---|---|
SetActionOnFailure | Enables a host to specify the action to take for a given failure. |
SetTimeout | Enables a host to specify a timeout value (in milliseconds) for given operations such as a thread abort or application domain unload. |
SetActionOnTimeout | Enables a host to specify which action should be taken when a timeout for a particular operation occurs. |
SetTimeoutAndAction | Enables a host to specify both a timeout value and a subsequent action in a single method call. SetTimeoutAndAction is a convenience method that combines the capabilities of Set-Timeout and SetActionOnTimeout. |
SetDefaultAction | Enables a host to specify the default action to take for a particular operation. SetDefaultAction is primarily used to override the CLR default behavior for a given action. |
SetUnhandledExceptionPolicy | As described, the behavior of unhandled exceptions is different in .NET Framework 2.0 than it is in .NET Framework 1.0 and .NET Framework 1.1. In particular, unhandled exceptions in .NET Framework 2.0 result in process termination. This behavior isn’t desirable for hosts with requirements for long process lifetimes, so SetUnhandledExceptionPolicy enables a host to turn off this behavior so that unhandled exceptions do not cause the process to exit. |
CLR hosts typically use the following steps to specify escalation policy using ICLRPolicyManager:
Obtain an ICLRPolicyManager interface pointer.
Set the actions to take when failures occur.
Set timeout values and the actions to take when a timeout occurs.
Set any default actions.
Specify unhandled exception behavior.
As described in Chapter 2, CLR hosts obtain interface pointers to the CLR-implemented managers using the ICLRControl interface. The ICLRControl interface is obtained by calling the GetCLRControl method on the ICLRRuntimeHost pointer obtained from the call to CorBindToRuntimeEx. Given a pointer of type ICLRControl, simply call its GetCLRManager method passing the IID corresponding to ICLRPolicyManager (IID_ ICLRPolicyManager) as shown in the following code sample:
// Initialize the CLR and get a pointer of
// type ICLRRuntimeHost.
ICLRRuntimeHost *pCLR = NULL;
HRESULT hr = CorBindToRuntimeEx(
L"v2.0.41013",
L"wks",
STARTUP_CONCURRENT_GC,
CLSID_CLRRuntimeHost,
IID_ICLRRuntimeHost,
(PVOID*) &pCLR);
// Use ICLRRuntimeHost to get the CLR control interface.
ICLRControl *pCLRControl = NULL;
pCLR->GetCLRControl(&pCLRControl);
// Use ICLRControl to get a pointer to the failure policy
// manager.
ICLRPolicyManager* pCLRPolicyManager = NULL;
hr = pCLRControl->GetCLRManager(IID_ICLRPolicyManager,
(PVOID*)&pCLRPolicyManager);Given an interface pointer of type ICLRPolicyManager, a host can now specify which actions the CLR should take given specific failures by calling SetActionOnFailure. As can be seen from the following method signature, SetActionOnFailure takes two parameters. The first parameter is a value from the EClrFailure enumeration describing the failure for which an action is specified. The second parameter is a value from the EPolicyAction enumeration describing the action itself.
interface ICLRPolicyManager: IUnknown
{
HRESULT SetActionOnFailure(
[in] EClrFailure failure,
[in] EPolicyAction action);
// Other methods omitted...
}The values for EClrFailure correspond directly to the failures described earlier in the overview of escalation policy. Specifically, the failures for which an action can be specified are the failure to allocate a resource, the failure to allocate a resource in a critical region of code, a fatal error internal to the CLR, and an abandoned synchronization primitive. Here’s the definition of EClrFailure from mscoree.idl:
typedef enum
{
FAIL_NonCriticalResource,
FAIL_CriticalResource,
FAIL_FatalRuntime,
FAIL_OrphanedLock,
MaxClrFailure
} EClrFailure;The meaning of many of the values from EPolicyAction should also be clear from the overview of escalation policy presented earlier in the chapter. Here’s the definition of EPolicyAction from mscoree.idl:
typedef enum
{
eNoAction,
eThrowException,
eAbortThread,
eRudeAbortThread,
eUnloadAppDomain,
eRudeUnloadAppDomain,
eExitProcess,
eFastExitProcess,
eRudeExitProcess,
eDisableRuntime,
MaxPolicyAction
} EPolicyAction;Values from EPolicyAction that likely require additional explanation are these:
eNoAction and eThrowException. These values are the defaults for various operations that can be customized through escalation policy. For example, eThrowException is the default action for all resource failures. Because these values are defaults, they are primarily used to reestablish default behavior if you had changed it earlier.
eFastExitProcess. In addition to the graceful and rude methods for terminating a process, escalation policy enables a host to specify a third alternative called a fast process exit. The CLR does not run any object finalizers during a fast exit, but it does run other cleanup code such as that in finally blocks. A fast exit is a compromise between a graceful exit and a rude exit both in terms of how quickly the process terminates and in the amount of add-in cleanup code the CLR attempts to run.
With the exception of eClrFailure.FAIL_FatalRuntime, all of the values in EPolicyAction are valid actions for any of the failures indicated by EClrFailure. FAIL_FatalRuntime is a special case in that when a fatal error occurs, the only actions that can be taken are to exit the process or disable the CLR. Specifically, the following values from EPolicyAction are valid when calling SetActionOnFailure for a fatal runtime failure:
eExitProcess
eFastExitProcess
eRudeExitProcess
eDisableRuntime
Now that you understand the parameters to SetActionOnFailure, let’s look at some example calls to see how particular actions can be specified for given failures. The following series of calls to SetActionOnFailure specifies a portion (minus the timeout aspects) of the escalation policy shown in Figure 11-1.
hr = pCLRPolicyManager->SetActionOnFailure(FAIL_NonCriticalResource,
eAbortThread);
hr = pCLRPolicyManager->SetActionOnFailure(FAIL_CriticalResource,
eUnloadAppDomain);
hr = pCLRPolicyManager->SetActionOnFailure(FAIL_OrphanedLock,
eUnloadAppDomain);
hr = pCLRPolicyManager->SetActionOnFailure(FAIL_FatalRuntime,
eDisableRuntime);In particular, these lines of code specify the following actions:
All failures to allocate a resource cause the thread on which the failure occurred to be aborted.
If the failure to allocate a resource occurs in a critical region of code, the failure is escalated to an application domain unload. Recall that a resource failure in a critical region has the potential to leave the application domain in an inconsistent state. Hence, a conservative approach is to unload the entire application domain.
The detection of an abandoned lock also causes the application domain to be unloaded. As with a resource failure in a critical region, an orphaned lock is a pretty good indication that application domain state probably isn’t consistent.
Instead of exiting the process if a fatal internal CLR error is detected, the CLR is disabled, thereby enabling the host to continue any processing unrelated to managed code.
The ability to specify timeout values for operations such as thread aborts and application domain unloads is a key element in the host’s ability to describe an escalation policy that will keep a process responsive over time. As shown in Table 11-1, ICLRPolicyManager has three methods that hosts can use to set timeouts: SetTimeout, SetActionOnTimeout, and SetTimeoutAndAction. Each of these methods enables a host to specify a timeout value in milliseconds for an operation described by the EClrOperation enumeration. The definition of EClrOperation is as follows:
typedef enum
{
OPR_ThreadAbort,
OPR_ThreadRudeAbortInNonCriticalRegion,
OPR_ThreadRudeAbortInCriticalRegion,
OPR_AppDomainUnload,
OPR_AppDomainRudeUnload,
OPR_ProcessExit,
OPR_FinalizerRun,
MaxClrOperation
} EClrOperation;Timeouts can be specified only for a subset of the values in EClrOperation. For example, it wouldn’t make sense to specify a timeout for any of the operations that represent rude thread aborts or application domain unloads because those operations occur immediately. The values from EClrOperation for which a timeout can be specified are as follows:
OPR_ThreadAbort
OPR_AppDomainUnload
OPR_ProcessExit
OPR_FinalizerRun
In general, hosts that require a process to live for a long time are likely to want to specify timeout values for at least OPR_ThreadAbort, OPR_AppDomainUnload, and OPR_FinalizerRun because there are no default timeout values for these operations. That is, unless a host specifies a timeout, attempts to abort a thread or unload an application domain could take an infinite amount of time. The CLR does have a default timeout for OPR_ProcessExit, however. If a process doesn’t gracefully exit in approximately 40 seconds, the process is forcefully terminated.
The following series of calls to SetTimeoutAndAction specifies timeout values and the actions to take for the operations indicated by the escalation policy specified in Figure 11-1.
hr = pCLRPolicyManager->SetTimeoutAndAction (OPR_ThreadAbort, 10*1000,
eRudeAbortThread);
hr = pCLRPolicyManager->SetTimeoutAndAction (OPR_AppDomainUnload, 20*1000,
eRudeUnloadAppDomain);In particular, these statements specify the following:
If an attempt to abort a thread doesn’t complete in 10 seconds, the thread abort is escalated to a rude thread abort.
If an attempt to unload an application domain doesn’t complete in 20 seconds, the unload is escalated to a rude application domain unload.
The SetDefaultAction method of ICLRPolicyManager can be used to specify a default action to take in response to a particular operation. In general, this method is used less than the other methods on ICLRPolicyManager because the CLR’s default actions are sufficient and because escalation is usually specified in terms of either particular failures or timeouts. However, if you’d like to change the defaults, you can do so by calling SetDefaultAction with a value for EPolicyAction describing the action to take in response to an operation defined by a value from EClrOperation. For example, the following call to SetDefaultAction specifies that the entire application domain should always be unloaded whenever a rude thread abort occurs in a critical region of code:
hr = pCLRPolicyManager->SetDefaultAction (OPR_ThreadRudeAbortInCriticalRegion,
eUnloadAppDomain);SetDefaultAction can be used only to escalate failure behavior; it cannot be used to downgrade the action to take for a given operation. For example, it’s not valid to use SetDefaultAction to request an action of EAbortThread for an operation of OPR_AppDomainUnload. Table 11-2 describes which values from EPolicyAction represent valid actions for each operation from EClrOperation.
Table 11-2. Valid Combinations of Actions and Operations for SetDefaultAction
Value of eClrOperations | Valid Values from EPolicyAction |
|---|---|
OPR_ThreadAbort | eAbortThread eRudeAbortThread eUnloadAppDomain eRudeUnloadAppDomain eExitProcess eFastExitProcess eRudeExitProcess eDisableRuntime |
OPR_ThreadRudeAbortInNonCriticalRegion OPR_ThreadRudeAbortInCriticalRegion | eRudeAbortThread eUnloadAppDomain eRudeUnloadAppDomain eExitProcess eFastExitProcess eRudeExitProcess eDisableRuntime |
OPR_AppDomainUnload | eUnloadAppDomain eRudeUnloadAppDomain eExitProcess eFastExitProcess eRudeExitProcess eDisableRuntime |
OPR_AppDomainRudeUnload | eRudeUnloadAppDomain eExitProcess eFastExitProcess eRudeExitProcess eDisableRuntime |
eExitProcess eFastExitProcess eRudeExitProcess eDisableRuntime | |
OPR_FinalizerRun | eNoAction eAbortThread eRudeAbortThread eUnloadAppDomain eRudeUnloadAppDomain eExitProcess eFastExitProcess eRudeExitProcess eDisableRuntime |
The change in the way unhandled exceptions are treated in .NET Framework 2.0 was implemented to make application exceptions more obvious and easier to debug. Previously, the CLR caught, and thereby hid, unhandled exceptions; often this completely masked the problem such that the end user or developer wasn’t even aware the error occurred. Enabling unhandled exceptions always to be visible makes it possible for these errors to be discovered and fixed. Although this is a positive step in general, hosts that require the process to live for a long time would rather have unhandled exceptions masked in these cases rather than having the process terminated. As I’ve shown, escalation policy provides the host with the means to unload any code that might be in a questionable state because of an unhandled exception. The SetUnhandledExceptionPolicy method on ICLRPolicyManager enables the host to revert to the behavior for treating unhandled exceptions that was implemented in versions of the .NET Framework earlier than version 2.0. The definition of SetUnhandledExceptionPolicy is shown here:
interface ICLRPolicyManager: IUnknown
{
HRESULT SetUnhandledExceptionPolicy(
[in] EClrUnhandledException policy);
// Other methods omitted...
}As you can see, hosts specify their desired behavior with respect to unhandled exceptions by passing a value from the EClrUnhandledException enumeration to SetUnhandledExceptionPolicy. EClrUnhandledException has two values as shown in the following definition from mscoree.idl:
typedef enum
{
eRuntimeDeterminedPolicy,
eHostDeterminedPolicy,
} EClrUnhandledException;The eRuntimeDeterminedPolicy value specifies the .NET Framework 2.0 behavior, whereas the eHostDeterminedPolicy value specifies that unhandled exceptions should not be allowed to proceed to the point where the process will be terminated.
The following call to SetUnhandledExceptionPolicy demonstrates how a host would use the API to specify that unhandled exceptions should not result in process termination:
pCLRPolicyManager->SetUnhandledExceptionPolicy(eHostDeterminedPolicy);
Hosts that specify an escalation policy using ICLRPolicyManager can receive notifications whenever an action was taken as a result of that policy. These notifications are sent to the host through the IHostPolicyManager interface. Table 11-3 describes the methods the CLR calls to notify the host of actions taken as a result of escalation policy.
Table 11-3. The Methods on IHostPolicyManager
Method | Description |
|---|---|
OnDefaultAction | Notifies the host that an action was taken in response to a particular operation. The action taken and the operation to which it applied are passed as parameters. |
OnTimeout | Notifies the host that a timeout has occurred. The operation that timed out and the action taken as a result are passed as parameters. |
OnFailure | Notifies the host that a failure has occurred. The particular failure that occurred and the action taken as a result are passed as parameters. |
To receive these notifications, a host must complete the following two steps:
These steps are described in more detail in the next two sections.
To provide an implementation of IHostPolicyManager, simply write a class that derives from the interface and implement the OnDefaultAction, OnTimeout, and OnFailure methods. As described earlier, the CLR calls these methods for informational purposes only. Although no direct action can be taken in the implementation of the methods, it is useful to see when your escalation policy is being used by the CLR. This information can be helpful in tuning your policy over time. The following code snippet provides a sample definition for a class that implements IHostPolicyManager:
class CHostPolicyManager : public IHostPolicyManager
{
public:
// IHostPolicyManager
HRESULT STDMETHODCALLTYPE OnDefaultAction(EClrOperation operation,
EPolicyAction action);
HRESULT STDMETHODCALLTYPE OnTimeout(EClrOperation operation,
EPolicyAction action);
HRESULT STDMETHODCALLTYPE OnFailure(EClrFailure failure,
EPolicyAction action);
// IUnknown
virtual HRESULT STDMETHODCALLTYPE QueryInterface(const IID &iid,
void **ppv);
virtual ULONG STDMETHODCALLTYPE AddRef();
virtual ULONG STDMETHODCALLTYPE Release();
};After you’ve written a class that implements IHostPolicyManager, you must notify the CLR of your intent to receive notifications related to escalation policy. As with all host-implemented interfaces, the host returns its implementation when the CLR calls the GetHostManager method on IHostControl (refer to Chapter 2 for a refresher on how the CLR discovers which managers a host implements). The following partial implementation of IHostControl::GetHost-Manager creates an instance of the class defined earlier when asked for an implementation of IHostManager:
HRESULT STDMETHODCALLTYPE CHostControl::GetHostManager(REFIID riid,void **ppv)
{
if (riid == IID_IHostPolicyManager)
{
// Create a new instance of the class that implements
// IHostPolicyManager.
CHostPolicyManager *pHostPolicyManager = new CHostPolicyManager();
*ppv = (IHostPolicyManager *) pHostPolicyManager;
return S_OK;
}
// Checks for other interfaces omitted...
return E_NOINTERFACE;
}Now that I’ve notified the CLR of the implementation of IHostPolicyManager, it will call the implementation each time an action is taken in response to the escalation policy defined using ICLRPolicyManager.
In many cases, the capability to specify an escalation policy is required primarily to protect against add-ins that weren’t written explicitly with high availability in mind. For example, I’ve discussed how a host can cause a resource failure to be escalated to a request to unload an entire application domain if the code in question happens to be updating shared state when the resource failure occurs. Ideally, these situations would never occur in the first place, and hence, the escalation policy wouldn’t be needed. After all, terminating an application domain likely results in some operations failing and having to be retried from the user’s perspective. Although you generally can’t guarantee that all the add-ins you load into your host will be written with high availability in mind, you can follow some guidelines when writing your own managed code to ensure that the situations causing an application domain to be unloaded are kept to a minimum and that no resources you allocate are leaked if an application domain unload does occur.
In particular, the following guidelines can help you write code to function best in environments requiring long process lifetimes:
Use SafeHandles to encapsulate handles to native resources.
Use the synchronization primitives provided by the .NET Framework.
Ensure that all calls you make to unmanaged code return to the CLR.
Annotate your libraries with the HostProtectionAttribute.
As described earlier in the chapter, SafeHandles leverage the concepts of critical finalization and constrained execution regions to ensure that native handles are properly released when an application domain is unloaded. In general, you probably won’t have to make explicit use of SafeHandles because the classes provided by the .NET Framework that wrap native resources all use SafeHandles on your behalf. For example, the classes in Microsoft.Win32 that provide registry access wrap registry handles in a SafeHandle, and the file-related classes in System.IO use SafeHandles to encapsulate native file handles. However, if you are accessing a native handle in your managed code without using an existing .NET Framework class, you have two options for wrapping your native handle in a SafeHandle. First, the .NET Framework provides a few classes derived from System.Runtime.InteropServices for wrapping specific types of handles. For example, the SafeFileHandle class in Microsoft.Win32.SafeHandles encapsulates a native file handle. There are also classes that wrap Open Database Connectivity (ODBC) connection handles, COM interface pointers, and so on. However, if one of the existing SafeHandle-derived classes doesn’t meet your needs, writing your own is relatively straightforward.
Writing a class that leverages SafeHandle to encapsulate a new native handle type requires the following four steps:
Create a class derived from System.Runtime.InteropServices.SafeHandle.
Provide a constructor that enables callers to associate a native handle (typically represented by an IntPtr) with your SafeHandle.
Provide an implementation of the ReleaseHandle method.
Provide an implementation of the IsInvalid property.
IsInvalid and ReleaseHandle are abstract members that all classes derived from SafeHandle must implement. IsInvalid is a boolean property the CLR accesses to determine whether the underlying native handle is valid and therefore needs to be freed. The ReleaseHandle method is called by the CLR during critical finalization to free the native handle. Your implementation of ReleaseHandle will vary depending on which Win32 API is required to free the underlying handle. For example, if your SafeHandle-derived class encapsulates registry handles, your implementation of ReleaseHandle will likely call RegCloseKey. If your class wraps handles to device contexts used for printing, your implementation of ReleaseHandle would call Win32’s DeleteDC method, and so on.
Both IsInvalid and ReleaseHandle are executed within a constrained execution region, so make sure that your implementations do not allocate memory. In most cases, IsInvalid should require just a simple check of the value of the handle, and ReleaseHandle should require only a PInvoke call to the Win32 API required to free the handle you’ve wrapped.
The following class is an example of a SafeHandle that can be used to encapsulate many types of Win32 handles. In particular, this class works with any handle that is freed using Win32’s CloseHandle API. Examples of handles that can be used with this class include events, processes, files, and mutexes. My SafeHandle-derived class, along with a portion of the definition of SafeHandle itself, is shown here:
[SecurityPermission(SecurityAction.InheritanceDemand, UnmanagedCode=true)]
[SecurityPermission(SecurityAction.LinkDemand, UnmanagedCode=true)]
public abstract class SafeHandle : CriticalFinalizerObject, IDisposable
{
public abstract bool IsInvalid { get; }
protected abstract bool ReleaseHandle();
// Other methods on SafeHandle omitted...
}
public class SafeOSHandle : SafeHandle
{
public SafeOSHandle(IntPtr existingHandle, bool ownsHandle)
: base(IntPtr.Zero, ownsHandle)
{
SetHandle(existingHandle);
}
// Handle values of 0 and -1 are invalid.
public override bool IsInvalid
{
get { return handle == IntPtr.Zero || handle == new IntPtr(-1); }
}
[DllImport("kernel32.dll"), SuppressUnmanagedCodeSecurity]
private static extern bool CloseHandle(IntPtr handle);
// The implementation of ReleaseHandle simply calls Win32's
// CloseHandle.
override protected bool ReleaseHandle()
{
return CloseHandle(handle);
}
}Several aspects of SafeOSHandle are worth noting:
SafeHandle is derived from CriticalFinalizerObject. By deriving from CriticalFinalizerObject, the finalizers for all SafeHandle classes are guaranteed to be run, even when a thread or application domain is rudely aborted.
All classes derived from SafeHandle require the permission to call unmanaged code. SafeHandle is annotated with both an InheritanceDemand and a LinkDemand that require the ability to call unmanaged code. In practice, partially trusted callers likely wouldn’t be able to derive from SafeHandle anyway because the implementation of ReleaseHandle often involves calling a Win32 API through PInvoke, which requires the ability to access unmanaged code.
The constructor has an ownsHandle parameter. The ownsHandle parameter is set to false in scenarios where you are using an instance of SafeHandle to wrap a handle you didn’t explicitly create yourself. When ownsHandle is false, the CLR will not free the handle during critical finalization.
The call to CloseHandle is annotated with SuppressUnmanagedCodeSecurityAttribute. Generally, calls through PInvoke to unmanaged APIs cause the CLR to perform a full stack walk to determine whether all callers on the stack have permission to call unmanaged code. However, the dynamic nature of the stack walk can cause additional resources to be required, which should be avoided while running in a CER. The SuppressUnmanagedCodeSecurityAttribute has the effect of moving the security check from the time at which the method is called to the time at which it is jit-compiled. This happens because SuppressUnmanagedCodeSecurityAttribute causes a link demand to occur instead of a full stack walk. So the security check happens when the method is prepared for execution in a CER instead of while running in the CER, thereby avoiding potential failures when the method is executed.
I’ve shown how hosts can use the escalation policy interfaces to treat resource failures differently if they occur in a critical region of code. Recall that a critical region of code is defined as any code that the CLR determines to be manipulating state that is shared across multiple threads. The heuristic the CLR uses to determine whether code is editing shared state is based on synchronization primitives. Specifically, if a resource failure occurs on a thread in which code is waiting on a synchronization primitive, the CLR assumes the code is using the primitive to synchronize access to shared state. However, this heuristic is useful only if the CLR can always detect when code is waiting on a synchronization primitive. So it’s important always to use the synchronization primitives provided by the .NET Framework instead of inventing your own. In particular, the System.Threading namespace provides the following set of primitives you can use for synchronization:
Monitor
Mutex
ReaderWriterLock
If you synchronize access to shared state using a mechanism of your own, the CLR won’t be able to detect that you are editing shared state should a resource failure occur. So the escalation policy defined by the host for resource failures in critical regions of code will not be used, thereby potentially leaving an application domain in an inconsistent state.
Throughout this chapter, I’ve discussed how the CLR relies on the ability to abort threads and unload application domains to guarantee process integrity. However, in some cases a thread can enter a state that prevents the CLR from being able to abort it. In particular, if you use PInvoke to call an unmanaged API that waits infinitely on a synchronization primitive or performs any other type of blocking operation, the CLR won’t be able to abort the thread. Once a thread leaves the CLR through a PInvoke call, the CLR is no longer able to control all aspects of that thread’s execution. In particular, all synchronization primitives created out in unmanaged code will be unknown to the CLR. So the CLR cannot unblock the thread to abort it. You can avoid this situation primarily by specifying reasonable timeout values whenever you wait on a blocking operation in unmanaged code. Most of the Win32 APIs that allow you to wait for a particular resource enable you to specify timeout values. For example, consider the case in which you use PInvoke to call an unmanaged function that creates a mutex and uses the Win32 API WaitForSingleObject to wait until the mutex is signaled. To ensure that your call won’t wait indefinitely, your call to WaitForSingleObject should specify a finite timeout value. In this way, you’ll be able to regain control after a specified interval and avoid all situations that would prevent the CLR from being able to abort your thread.
In Chapter 12, I discuss how hosts can use a feature called host protection to prevent APIs that violate various aspects of their programming model. For example, hosts can use the host protection feature to prevent an add-in from using any API that allows it to share state across threads. If an add-in is not allowed to share state in the first place, the host portion of escalation policy dealing with critical regions of code will never be required, thus resulting in fewer application domain unloads (or whatever other action the host specified).
For host protection to be effective, all APIs that provide capabilities identified by a set of host protection categories must be annotated with a custom attribute called the HostProtectionAttribute. Refer to Chapter 12 for more a complete description of the host protection categories and how to use HostProtectionAttribute to annotate your managed code libraries properly.
.NET Framework 2.0 is the first version in which the CLR needs to provide a solution for hosts whose reliability model requires long process lifetimes. These requirements were primarily driven by the integration of the CLR into SQL Server 2005 and the anticipation of other hosts with similar requirements in the future. Before .NET Framework 2.0, CLR hosts that required high availability used a model based on process recycling. This model worked great for hosts such as ASP.NET in which virtually no per-process state was kept, so it really didn’t matter which process was used to process a particular incoming request.
To support hosts for which a process recycling model is inadequate, the .NET Framework 2.0 version of the CLR introduces a reliability model based on application domain recycling. In this model, the CLR guarantees that an application domain can be unloaded from a process without leaking any resources. If the integrity of an application domain becomes questionable because of an exceptional condition such as the failure to allocate a resource, the application domain can simply be removed from the process without affecting the integrity of the process. One of the technical challenges of the application domain recycling model is to provide the guarantee that handles to native resources, such as files and kernel objects held by managed code, can always be freed when an application domain is unloaded. Providing this guarantee requires the introduction of new infrastructure in the form of critical finalization, SafeHandles, and constrained execution regions. These three new concepts work together to guarantee that the code required to free a handle to a native resource will always be run, regardless of how quickly an application domain must be unloaded.
Another critical piece of the CLR’s design to support long process lifetimes is the notion of escalation policy. CLR hosts use the hosting interfaces to specify a set of rules known as escalation policy that dictate the actions taken by the CLR in the face of various exceptional conditions. Hosts can tailor these actions to their specific requirements to guarantee process integrity.
As you’ll see in the next chapter, hosts can use another new .NET Framework 2.0 feature called host protection to restrict the set of APIs an add-in can use, thereby reducing the possibility of having to unload an application domain to maintain process integrity at all.